[Заметки BBuf по CUDA] Четырнадцать, вводные заметки OpenAI Triton, три FusedAttention
0x0.
Продолжая изучение Тритона, на этот раз мы подошли к https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html туториалу. То есть, как использовать Triton для реализации FlashAttention V2. В Интернете уже есть много представлений о FlashAttention и FlashAttention V2. Если вам интересно, я рекомендую FlashAttention V1 прочитать «Иллюстрированная серия по ускорению вычислений на больших моделях: FlashAttention V1, от аппаратного обеспечения до вычислительной логики» https://zhuanlan. zhihu.com /p/669926191 Пояснения к этой статье и FlashAttention V2 см. в разделе «Иллюстрированная серия ускоренных вычислений больших моделей: Flash Attention». V2, От принципов к параллельным вычислениям» https://mp.weixin.qq.com/s/5K6yNj23NmNLcAQofHcT4Q. Принципы и вывод формул очень ясны, но все же требуются некоторые усилия, чтобы прочитать их за один раз. В то же время вы также можете найти более актуальную информацию по адресу https://github.com/BBuf/how-to-optim-algorithm-in-cuda (кроме того, быстрое отслеживание обучающих инфраструктур Infra, таких как Meagtron -LM и DeepSpeed также иллюстрируют FlashAttention. Эта серия работ имеет огромное влияние), например:

Вставьте сюда описание изображения
Основная проблема этой статьи — понять, как использовать Triton для реализации пересылки FlashAttention V2, поэтому я не буду повторять детали формулы FlashAttention, а с более инженерной точки зрения, как следует реализовать код FlashAttention Forward. Я — этот процесс. также будет представлена простейшая реализация FlashAttention V1/V2 на языке Python, позволяющая интуитивно понять процесс написания кода. На этой основе мы начнем интерпретировать реализацию Triton FlashAttention. Давайте начнем. (Если будут силы, о реализации Backward я тоже напишу позже.
Ссылки на документы для FlashAttention V1/V2: https://arxiv.org/abs/2205.14135 и https://tridao.me/publications/flash2/flash2.pdf. Экспериментальный код, использованный в этой статье, можно найти в моем личном репозитории: https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/triton. Вы также можете поставить ему звездочку. .
0x1. BenchMark
Я запустил тест FlashAttention V2 в этом руководстве https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html.
Для Flash Attention V2 Forward с Batch=4, Head=48, HeadDim=64 и causal=True сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
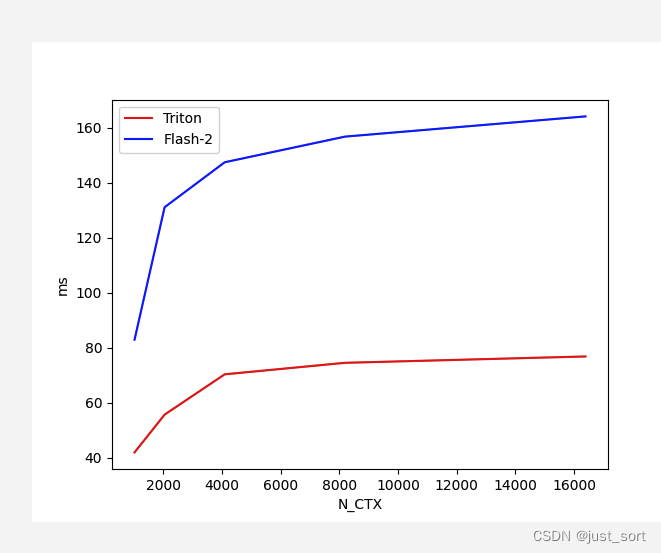
Вставьте сюда описание изображения
Для Flash Attention V2 Forward с Batch=4, Head=48, HeadDim=64, Causeal=False сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
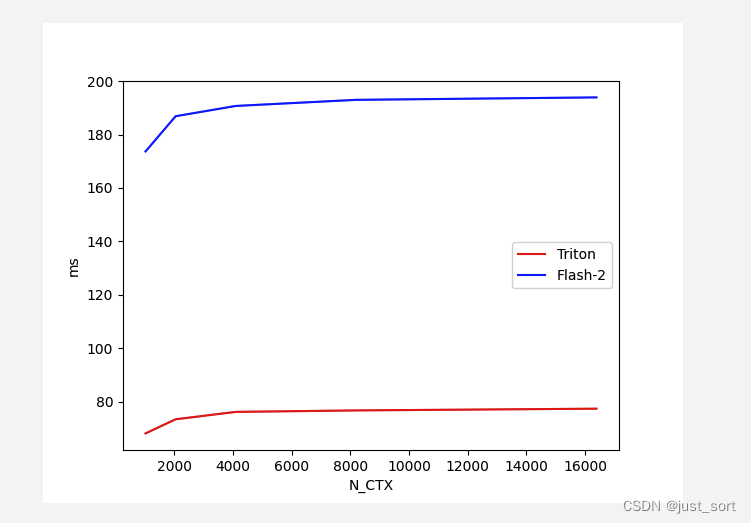
Вставьте сюда описание изображения
Для Flash Attention V2 Backward с Batch=4, Head=48, HeadDim=64 и causal=True сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
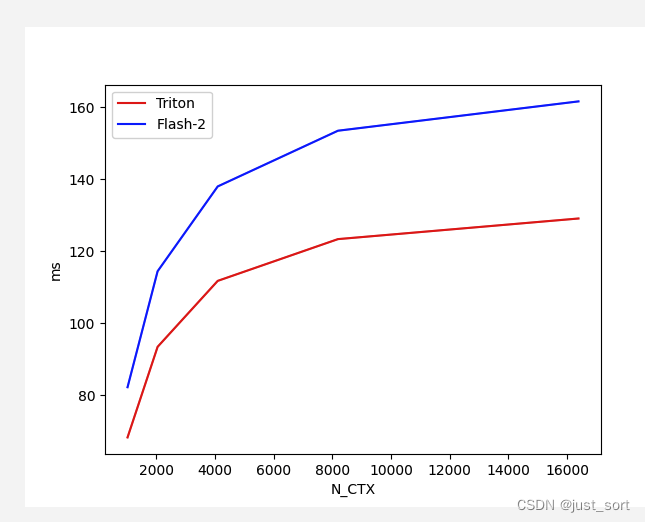
Вставьте сюда описание изображения
В этой конфигурации Тритон работает в различных последовательностях. LengthВсе получилось лучше, чемcutlassлучшепроизводительность,ЗатемсуществоватьTritonизkernelЕсть реализацияassert Lk in {16, 32, 64, 128},То естьTritonиз实现需要注意力头из隐藏层维度существовать[16, 32, 64, 128], я протестирую здесь группу из 16 человек, чтобы увидеть производительность.
Для Flash Attention V2 Forward с Batch=4, Head=48, HeadDim=16 и causal=True сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
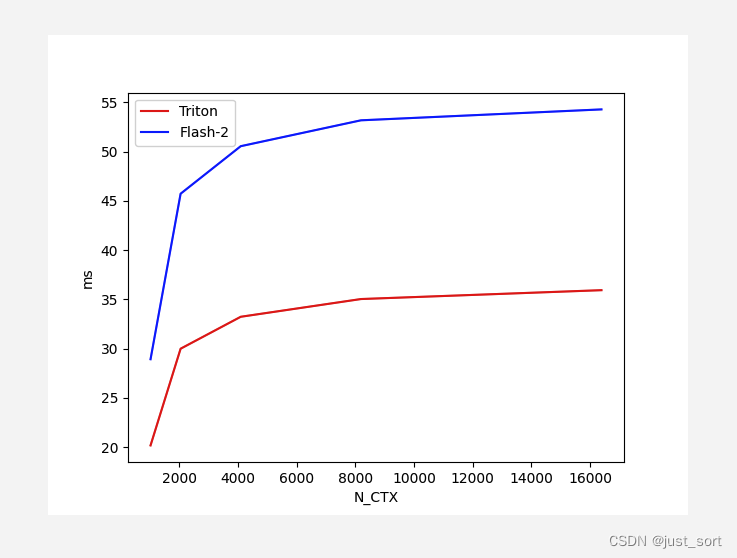
Вставьте сюда описание изображения
Для Flash Attention V2 Forward с Batch=4, Head=48, HeadDim=16, Causeal=False сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
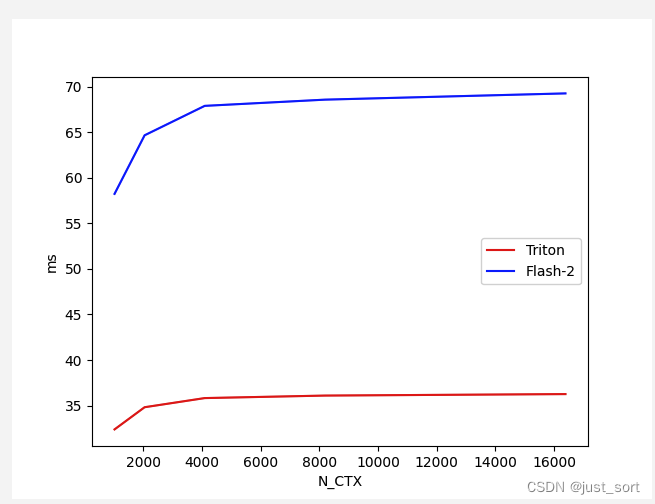
Вставьте сюда описание изображения
Для Flash Attention V2 Backward с Batch=4, Head=48, HeadDim=16 и causal=True сравните производительность реализации Triton и версии реализации Cutlass при различной длине последовательности:
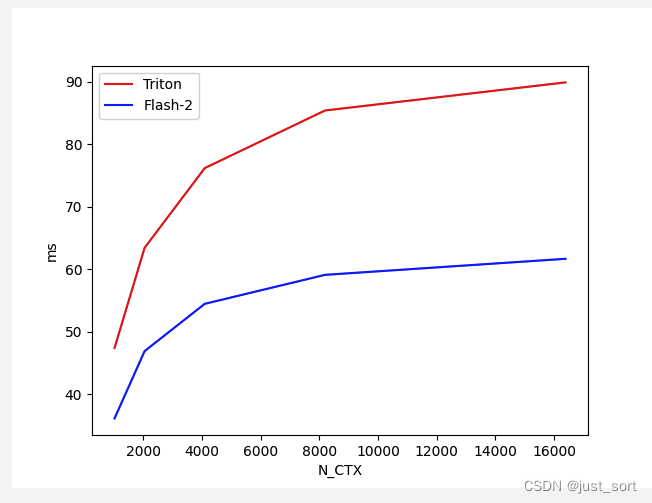
Вставьте сюда описание изображения
В этом наборе случаев, хотя пас вперед быстрее, чем Тритон, пас назад быстрее, чем абордаж.
Кроме того, в задаче Тритона, если HeadDim=128, Bakcward Тритона будет намного медленнее, чем абордаж: https://github.com/openai/triton/issues/1975 , параметры установлены на BATCH, N_HEADS, N_CTX, D_HEAD = 8, 32, 4096, 128 Также проверьте это здесь:
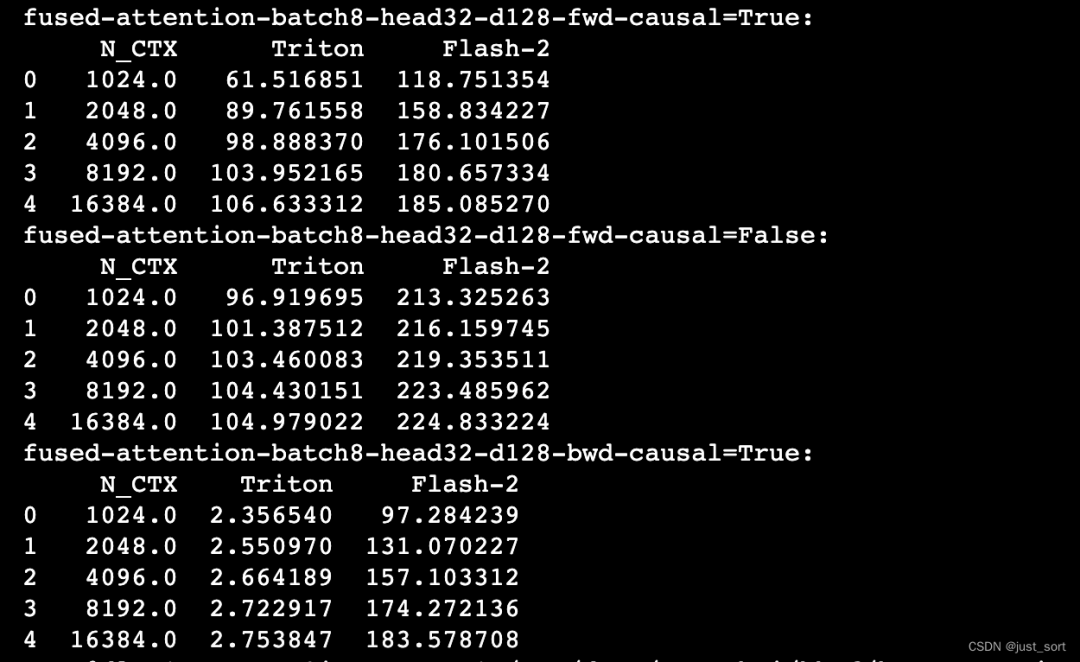
Вставьте сюда описание изображения
Обратная трудоемкая сравнительная таблица:
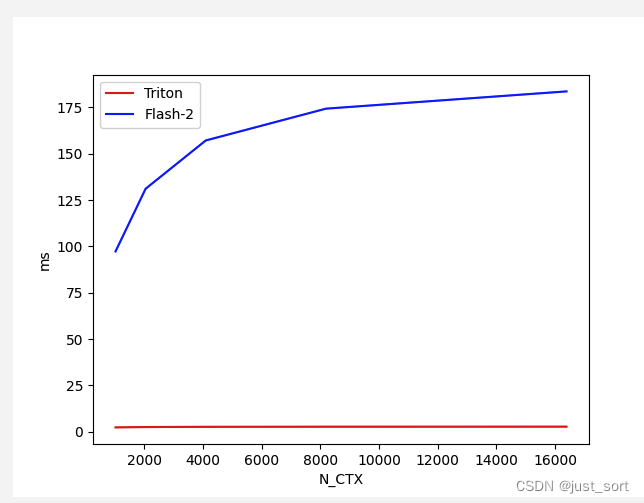
Вставьте сюда описание изображения
Результат потрясающий. Разница во времени обратного хода очень велика, а скорость Тритона намного лучше, чем у Катласа. По мере увеличения длины последовательности время обратного хода Тритона становится почти постоянным. . На всякий случай рекомендуется использовать реализацию, предоставляемую официальной библиотекой FlashAttention. В настоящее время я использую версию Triton 2.1.0.
0x2. Стандартный процесс внимания и минималистская реализация Python.
Сделайте скриншот стандартного процесса Attention из статьи FlashAttention:

Вставьте сюда описание изображения
Я опишу процесс здесь еще раз. Сначала загрузите его из HBM.
,
матрица, затем выполните
расчет и результат
Тогда напишите обратно в HBM;
Затем прочитайте его из HBM и выполните
расчет, а затем
Тогда напишите обратно в HBM;
и
Прочитайте из HBM и выполните
расчет и, наконец, запишите результаты обратно в HBM. для,
, их размеры все
, промежуточные переменные
и
Размеры все есть
. Другая проблема здесь в том, что для SиP могут быть еще какие-то операции типа MaskиDropout, поэтому упомянутых выше фьюзов очень много. Работа с ядром, например softmaxиmask сгореть. Наконец, softmax здесь — это оператор softmax PyTorch, который также безопасен. Реализация softmax: безопасно значит наивно Softmac основан на вычитании максимального значения всех исходных входных значений из каждого исходного входного значения в индексе. Пожалуйста, обратитесь к изображению ниже для получения подробной информации, полученной из https://arxiv.org/pdf/2205.14135.pdf :

Вставьте сюда описание изображения
Для безопасного softmax все значения вычитаются из максимального значения во входном векторе, гарантируя, что максимальное значение экспоненциальной части равно 0, избегая числового переполнения.
Для того, чтобы проверить корректность, я написал скрипт, где в качестве примера использован классический GPT2, а в качестве примера использовано железо А100. Вот
и
Ставим 1024и64 соответственно.,Тогда Q,K,Все формы буквы V
,SиPРазмеры все есть
。
Реализация кода следующая:
import torch
N, d = 1024, 64 # Обновить значение Nид
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
def standard_softmax_attention(Q, K, V):
"""
Внедрить стандартный Pytorch softmax расчет внимания.
"""
expected_softmax = torch.softmax(Q @ K.T, dim=1)
expected_attention = expected_softmax @ V
return expected_softmax, expected_attention
def safe_softmax_attention(Q, K, V):
"""
执ХОРОШО安全изsoftmax расчет внимания.
"""
S_mat = Q @ K.T
row_max = torch.max(S_mat, dim=1).values[:, None]
input_safe = S_mat - row_max
softmax_numerator = torch.exp(input_safe)
softmax_denominator = torch.sum(softmax_numerator, dim=1)[:, None]
safe_softmax = softmax_numerator / softmax_denominator
matmul_result = safe_softmax @ V
return safe_softmax, matmul_result
# Рассчитано с использованием стандартного softmaxиattention.
expected_softmax, expected_attention = standard_softmax_attention(Q_mat, K_mat, V_mat)
# Вычисление с использованием безопасного softmaxвнимания
safe_softmax, safe_attention = safe_softmax_attention(Q_mat, K_mat, V_mat)
# Убедитесь, что результаты softmax и внимания, рассчитанные двумя методами, близки.
assert torch.allclose(safe_softmax, expected_softmax), "error in safe softmax"
assert torch.allclose(safe_attention, expected_attention), "error in safe attention"
Тест проходит правильно,Это также объясняетPyTorchизtorch.softmax算子из确да用safe Это достигается с помощью метода softmax.
0x3. FlashAttention V1 Forward Pass и минималистская реализация Python.
FlashAttention V1 методом блочного расчета разрезает Q и KиV на множество маленьких частей и помещает эти разделенные маленькие части в SRAM (разделяемую память). Расчет выполняется в памяти) и, наконец, записывается обратно в HBM. Алгоритм работы следующий:

Вставьте сюда описание изображения
Если вы хотите полностью понять все тонкости этого псевдокода, рекомендуется прочитать эту статью https://zhuanlan.zhihu.com/p/669926191, но с точки зрения реализации исходного кода этот псевдокод достаточно близок . Нужно только знать, что эти, казалось бы, странные формулы обусловлены тем, что каждый раз при обходе блока вычисляется часть токена, а конечный результат, рассчитанный механизмом самообслуживания, находится среди всех токенов, поэтому он обновляется с локального на глобальный. будет использоваться онлайн-алгоритм softmax, а окончательный результат будет обновляться онлайн. Это также является источником сложных формул, приведенных выше.
Здесь я пытаюсь использовать Python для моделирования процесса этого алгоритма. После реализации это будет полезно для реализации Triton, потому что, судя по урокам Triton в предыдущих разделах, по сравнению с простой реализацией ядра Triton на Python, там нет. это всего лишь еще один уровень блока. Это всего лишь процесс запуска ядра. Используйте настройки GPT2 из предыдущего раздела,
и
Ставим 1024и64 соответственно.,Тогда Q,K,Все формы буквы V
,Обратите внимание, что в существующем FlashAttention нет глобального SиP. Предположим, что аппаратное обеспечение A100.,A100изShared Размер памяти 192КБ=196608Б, тогда вы можете рассчитать Flash здесь Размер фрагмента внимания — это первая строка приведенного выше псевдокода.
,
。
Затем строка 2 псевдокода инициализирует выходную матрицу всеми нулями.
, размер формы также
и инициализировал
и
Матрица, размеры все
,но
инициализируется нулевой матрицей,
инициализируется отрицательной бесконечностью.
Далее его можно рассчитать непосредственно на основе вышеуказанных параметров.
и
, соответствующий строке 3 псевдокода,
,
。
Я поместил следующий анализ псевдокода непосредственно в следующую реализацию Python. Каждая строка кода может соответствовать приведенному выше псевдокоду:
import torch
N, d = 1024, 64 # Обновить значение Nид
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
def standard_softmax_attention(Q, K, V):
"""
Внедрить стандартный Pytorch softmax расчет внимания.
"""
expected_softmax = torch.softmax(Q @ K.T, dim=1)
expected_attention = expected_softmax @ V
return expected_softmax, expected_attention
def flash_attention(Q, K, V, B_r=64, B_c=768):
"""
Выполнить прошивку с использованием блочного расчета исуществовать коррекцию softmax строки алгоритм внимания.
"""
O = torch.zeros((N, d)) # Инициализируйте выходную матрицу, соответствующую строке 2 псевдокода.
l = torch.zeros((N, 1)) # Сохраните знаменатель softmax, соответствующий строке 2 псевдокода.
m = torch.full((N, 1), -torch.inf) # Сохраните максимальное значение каждого блока, соответствующее второй строке псевдокода.
# Соответствует строке 5 псевдокода, для 1<=j<=T_c,Обратите внимание, что здесьK, V разделен на блоки T_c=[N/B_c], размер каждого блока равен [B_c, г] Такой большой
# Поэтому, когда реализуется существованиеpython, он обрабатывается напрямую в цикле с размером шага B_c.
for j in range(0, N, B_c):
# Следующие три строки соответствуют строке 6 псевдокода Load Kj, Vj from HBM to on-chip SRAM
# Но вот простота python Реализация, у нас невозможно реально поставить этот кусок памяти из HBM в SRAM
# Это всего лишь логическое объяснение псевдокода, вы можете сделать вид, что оно это делает, потому что существующий Triton действительно может делать это в существующем слое Python.
j_end = j + B_c
Kj = K[j:j_end, :]
Vj = V[j:j_end, :]
# Соответствует строке 7 псевдокода, для 1<=i<T_r,Обратите внимание, что Q разделен на блоки Tr=[N/B_r],每一块из大小да[B_r, г] Такой большой
# Поэтому, когда реализуется существованиеpython, он обрабатывается напрямую в цикле с размером шага B_r.
for i in range(0, N, B_r):
i_end = i + B_r
mi = m[i:i_end, :]
li = l[i:i_end, :]
Oi = O[i:i_end, :]
Qi = Q[i:i_end, :]
# Соответствует строке 9 псевдокода: on chip, compute Sij, форма Sij — [B_r, B_c]
Sij = Qi @ Kj.T
# Соответствует строке 10 псевдокода
mij_hat = torch.max(Sij, dim=1).values[:, None]
pij_hat = torch.exp(Sij - mij_hat)
lij_hat = torch.sum(pij_hat, dim=1)[:, None]
# В соответствии со строкой 11 псевдокода находится операция mi_new. Обратите внимание, что здесь необходимо найти общий максимум двух тензоров, поэтому существует эта операция стека.
mi_new = torch.max(torch.column_stack([mi, mij_hat]), dim=1).values[:, None]
# По строке 11 псевдокода найдите операцию li_new
li_new = torch.exp(mi - mi_new) * li + torch.exp(mij_hat - mi_new) * lij_hat
# В соответствии со строкой 12 псевдокода O_i обновляется. Здесь возникает вопрос. В псевдокоде есть операция диагностики. Почему она игнорируется в следующей реализации?
# Это связано с тем, что эта диаграмма используется для существующего вектора. На самом деле она соответствует верхнему измерению в существующем псевдокоде, а реализация PyTorch является автоматической.
# Поддерживается механизм тензорной трансляции, поэтому его можно рассчитать прямо здесь.
O_i = (li * torch.exp(mi - mi_new) * Oi / li_new) + (torch.exp(mij_hat - mi_new) * pij_hat / li_new) @ Vj
# В соответствии со строкой 13 псевдокода обновляются m_i, l_i, O_i.
m[i:i_end, :] = mi_new
l[i:i_end, :] = li_new
O[i:i_end, :] = O_i
return O
# выполнить флэш расчет внимания
flash_attention_output = flash_attention(Q_mat, K_mat, V_mat)
# Внедрить стандартный Pytorch softmaxирасчет внимания
expected_softmax, expected_attention = standard_softmax_attention(Q_mat, K_mat, V_mat)
# вспышка подтверждения расчет вниманияиз结果与标准вычислить结果да否接近
assert torch.allclose(flash_attention_output, expected_attention), "error in flash attention calculation"
Следует отметить, что операции Dropout и Mask не учитываются в описанном выше процессе Attention Forward Pass. Если эти две операции учитывать, общий процесс будет иметь некоторые изменения, как показано в Алгоритме 2 в документе Flash Attention V1:

Вставьте сюда описание изображения
По сравнению с алгоритмом1,Дополнительные операции MaskиDropout,Больше ничего не изменилось.
0x4. FlashAttention V2 Forward Pass и минималистская реализация Python.
Если вы хотите четко понять принципы улучшения, лежащие в основе FlashAttention V2, прочтите «Иллюстрированная серия по ускорению вычислений на больших моделях: Flash Attention V2, от принципов к параллельным вычислениям» https://mp.weixin.qq.com/s/5K6yNj23NmNLcAQofHcT4Q. Здесь я проведу лишь простой принципиальный анализ, сосредоточив внимание на изменениях на уровне кода по сравнению с прямым проходом FlashAttention V1 и реализацией прямого прохода FlashAttention V2 на основе версии FlashAttention V1.
С учетом кода, приведенного в предыдущем разделе, прямой проход Flash Attention V1 фактически можно абстрагировать в следующую диаграмму (скопированную из приведенной выше статьи «Иллюстрированная серия ускорения вычислений на больших моделях: Flash Attention V2, от принципов к параллельным вычислениям»). :
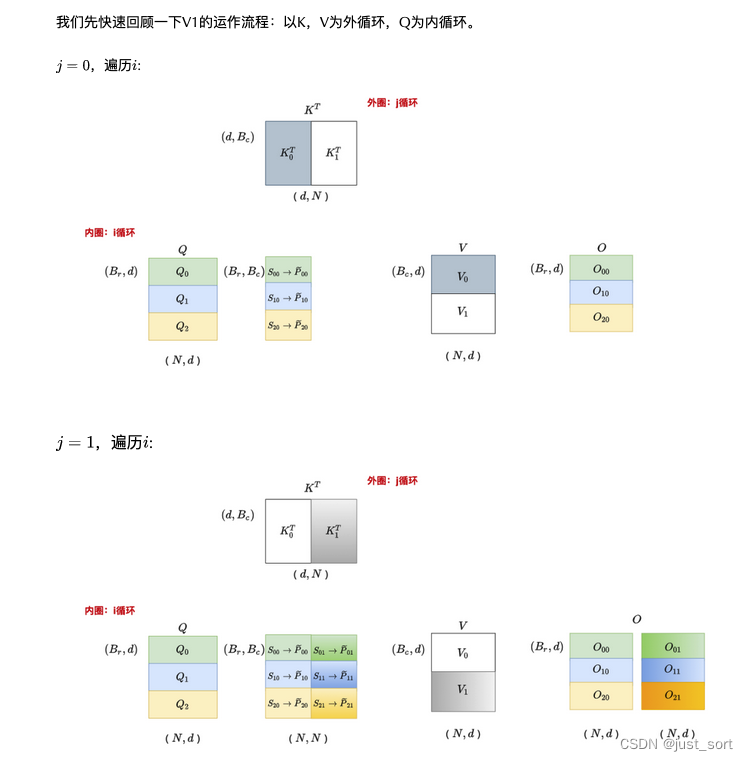
Вставьте сюда описание изображения
Эта картинаи我们изFlash Attention Реализация V1 полностью соответствует. Следует отметить, что на картинке 6 маленьких блоков О, но на самом деле горизонтальная О только одна и она здесь постепенно обновляется, чтобы отразить идею. блокировка.
здесь с
Например, мы можем видеть
и
Общий
,FlashAttention Версия 2 адаптировала Flash на основе этого наблюдения. Attention Можем ли мы избежать повторного доступа к Q в последовательности циклов V1, теперь, когда внешний цикл пересекает Q? Настройка порядка обучения — это просто FlashAttention Одна из операций V2, две другие, более важные операции, — переписать формулу расчета, чтобы минимизировать не-matmul Флопы, особенно при расчете локального внимания, не учитывают знаменатель softmax и сдвигают время масштабирования назад. Могу только посетовать, что математика автора слишком сильна. Подробности можно найти в «Подробном объяснении FlashAttention2 (сравнение улучшенной производительности»). с FlashAttention)» 200%)》https://zhuanlan.zhihu.com/p/645376942 В этой статье объясняется алгоритм. Кроме того, в документе также упоминается важное улучшение параллелизма, а именно добавление параллелизма последовательностей. FlashAttention V1 существовать batch и heads Распараллеливание выполняется в двух измерениях с использованием одного блока потоков для обработки одной головы внимания. Общее количество требуемых блоков потоков равно произведению пакета и головок внимания. Каждый блок запланирован для запуска на SM, например A100. На графическом процессоре 108 SM. Этот метод планирования эффективен, когда количество блоков велико (например, ≥80), поскольку он может эффективно использовать почти все вычислительные ресурсы графического процессора. Однако, когда существуют ручки ввода длинной последовательности (в настоящее время обучается 100 000, потребность в модели длинного текста 200 000 постепенно увеличивается), из-за ограничений памяти количество пакетных головок и головок внимания обычно уменьшается, поэтому степень распараллеливания графического процессора снижается. Исходя из этого, FlashAttention-2существовать распараллеливается по размеру длины последовательности, что существенно улучшает параллелизм работы графического процессора и повышает производительность. Мы все можем добиться того, чтобы эти улучшения существовали. https://github.com/openai/triton/blob/main/python/tutorials/06-fused-attention.py Эта реализация Triton найдена, подробности существуют в следующем разделе.
Здесь мы по-прежнему публикуем псевдокод алгоритма Flash AttentionV2 и используем Python для моделирования процесса.

Вставьте сюда описание изображения
Соответствующий код и процесс Python выглядят следующим образом. Поскольку здесь рассматривается только прямой проход, код вычисляет только выходной сигнал O и не вычисляет logsumexp L (это для обратного прохода):
import torch
N, d = 1024, 64 # Обновить значение Nид
Q_mat = torch.rand((N, d))
K_mat = torch.rand((N, d))
V_mat = torch.rand((N, d))
def standard_softmax_attention(Q, K, V):
"""
Реализация стандартного PyTorch softmax расчет внимания.
"""
expected_softmax = torch.softmax(Q @ K.T, dim=1)
expected_attention = expected_softmax @ V
return expected_softmax, expected_attention
def flash_attention_v2(Q, K, V, B_r=64, B_c=768):
"""
Выполнить прошивку с использованием блочного расчета исуществовать коррекцию softmax строки attention алгоритм v2.
"""
O = torch.zeros((N, d)) # Инициализируйте O как (N, Форма d) фактически соответствует инициализации O в строке 5 псевдокода.
l = torch.zeros((N, 1)) # Инициализация l в форме (N) фактически соответствует инициализации l в строке 5 псевдокода.
m = torch.full((N, 1), -torch.inf) # Сохраните максимальное значение каждого блока, инициализированное отрицательной бесконечностью, соответствующее строке 5 псевдокода.
# Соответствует строке 3 псевдокода, для 1<=i<T_r,Обратите внимание, что Q разделен на блоки Tr=[N/B_r],每一块из大小да[B_r, г] Такой большой
# Поэтому, когда реализуется существованиеpython, он обрабатывается напрямую в цикле с размером шага B_r.
for i in range(0, N, B_r):
Qi = Q[i:i+B_r, :]
# Соответствует псевдокоду 6 ОК, для 1<=j<=T_c,Обратите внимание, что здесьK, V разделен на блоки T_c=[N/B_c], размер каждого блока равен [B_c, г] Такой большой
# Поэтому, когда реализуется существованиеpython, он обрабатывается напрямую в цикле с размером шага B_c.
for j in range(0, N, B_c): # Внутренний цикл пересекает блоки Q
Kj = K[j:j+B_c, :]
Vj = V[j:j+B_c, :]
# Соответствует псевдокоду8ХОРОШО:on chip, compute Sij, форма Sij — [B_r, B_c]
Sij = Qi @ Kj.T
# Соответствует псевдокоду9ХОРОШОпроситьm_i^(j)из操作,mi_newизформадаB_r
mi_new = torch.max(torch.column_stack([m[i:i+B_r], torch.max(Sij, dim=1).values[:, None]]), dim=1).values[:, None]
# Соответствует псевдокоду9ХОРОШОпроситьPij_hatиз操作,Форма Пидж_хата равна (B_r x B_c)., и Sij непротиворечив
Pij_hat = torch.exp(Sij - mi_new)
# Соответствует псевдокоду9ХОРОШОпроситьlijиз操作
l[i:i+B_r] = torch.exp(m[i:i+B_r] - mi_new) * l[i:i+B_r] + torch.sum(Pij_hat, dim=1)[:, None]
# Соответствует строке 10 псевдокодапроситьO_ijиз操作
O[i:i+B_r] = O[i:i+B_r] * torch.exp(m[i:i+B_r] - mi_new) + Pij_hat @ Vj
m[i:i+B_r] = mi_new
O = O / l # В соответствии со строкой 12 псевдокода выходные данные корректируются в соответствии со знаменателем softmax.
return O
# выполнить флэш расчет внимания
flash_attention_v2_output = flash_attention_v2(Q_mat, K_mat, V_mat)
# Реализация стандартного PyTorch softmaxирасчет внимания
_, expected_attention = standard_softmax_attention(Q_mat, K_mat, V_mat)
# вспышка подтверждения расчет вниманияиз结果与标准вычислить结果да否接近
assert torch.allclose(flash_attention_v2_output, expected_attention), "Error in flash attention calculation"
Затем Есть два раздела, посвященные параллелизму графических процессоров в FlashAttention V2. Прежде чем рассматривать реализацию Triton, я сначала переведу эти два раздела.

Вставьте сюда описание изображения
Перевод: FlashAttention V1Существовать дозаторы распараллеливаются в двух измерениях: с помощью потока блокировать обработку внимания голова, всего ниток нужно Количество блоков равно пакету size × number of головы. Каждый блок запланирован для запуска на SM, например A100. На графическом процессоре 108 SM. Когда количество блоков велико (например, ≥80), этот метод планирования эффективен, поскольку можно эффективно использовать почти все вычислительные ресурсы графического процессора.
Но когда существование обрабатывает ввод длинной последовательности,из-за ограничений памяти,Обычно размер партии уменьшается. sizeиhead, поэтому распараллеливание сокращается. Поэтому FlashAttention V2 также распараллеливает измерение длины последовательности, что значительно повышает скорость вычислений. Кроме того, когда партия Когда количество размеров и головок невелико, увеличение параллелизма по длине последовательности может помочь увеличить загрузку графического процессора.
Forward pass Вероятно, это означает, что FlashAttention В псевдокоде V1 есть два цикла: K, Vсуществовать внешний цикл j, Qсуществовать внутренний цикл i. FlashAttention V2 перемещает Q во внешний цикл i, K и V во внутренний цикл. j, благодаря улучшенному алгоритму варпам больше не нужно взаимодействовать друг с другом для обработки, поэтому внешний цикл может помещать разные thread block начальство. Метод оптимизации для этого обмена был разработан Филом TilletсуществоватьTriton提出并实现из,Это код Тритона, который будет интерпретирован в следующем разделе. Будем смотреть, пока не запустится ядро и сетка потоков не станет двухмерной.,Одним из измерений является длина последовательности.,Другое измерение — это продукт партии и внимания.

Вставьте сюда описание изображения
Перевод: бумага В разделе 3.2 обсуждается, как распределять потоки. блокировать, однако каждая нить существует Внутри блока нам также необходимо решить, как распределить работу между разными варпами. Мы обычно существуем в каждой теме Используйте в блоке 4 или 8 основ, как показано на рисунке 3.
FlashAttention forward pass. Чтобы упростить это здесь, как показано на рисунке 3, внешний цикл проходит входную последовательность K и Vсуществовать, а внутренний цикл проходит QсуществоватьN. Для каждого блока FlashAttention V1 делит Ки В на 4 варпа.,И все варпы могут получить доступ к Q. Деформация K, умноженная на Q, дает нам часть S.
,Затем
После локального softmax его нужно умножить на часть V, чтобы получить
. Однако каждый раз, когда внешний цикл
Все нужно обновить один раз
(Относительно прошлого раза
Сначала измените масштаб, а затем добавьте текущее значение), что приводит к тому, что каждый варп требует частого чтения и записи из HBM.
Для накопления окончательных результатов эту схему еще называют схемой «Сплит-К». Она в целом неэффективна, поскольку всем варпам приходится часто читать и записывать промежуточные результаты из HBM.
. FlashAttention V2 перемещает Q во внешний цикл i, K и V во внутренний цикл j и делит Q на 4 деформации. Все деформации имеют доступ к K и V. Преимущество этого подхода в том, что каждый раз, когда FlashAttention выполняет цикл i++, это приводит к
также трансформировать (пока
Нужно читать и писать через HBM), теперь существование обрабатывается j++ каждый раз во внутреннем цикле
,в это время
Он хранится в SRAM, а стоимость намного меньше, чем у HBM.
0x5. Интерпретация реализации FlashAttention V2 Forward Pass Triton.
Используя вышеуказанную основу, мы можем непосредственно рассмотреть реализацию Triton. Здесь мы сосредоточимся только на этом. Forward Пройти часть,Tritonиз核心вычислить逻辑существовать下面из这个函数:
@triton.jit
def _attn_fwd_inner(acc, l_i, m_i, q, #
K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr, BLOCK_N: tl.constexpr, #
STAGE: tl.constexpr, offs_m: tl.constexpr, offs_n: tl.constexpr, #
N_CTX: tl.constexpr):
# range of values handled by this stage
# На основе значения STAGE функция определяет диапазон ключей (K) и значений (V), подлежащих обработке.
# Разные ЭТАПЫ соответствуют разным диапазонам обработки, поддерживая причинное и непричинное внимание к себе.
if STAGE == 1: # causal = True
lo, hi = 0, start_m * BLOCK_M
elif STAGE == 2:
lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
lo = tl.multiple_of(lo, BLOCK_M)
# causal = False
else:
lo, hi = 0, N_CTX
# Используйте функцию tl.advance для настройки положения указателя KиV для корректной загрузки данных из соответствующей ячейки памяти.
K_block_ptr = tl.advance(K_block_ptr, (0, lo))
V_block_ptr = tl.advance(V_block_ptr, (lo, 0))
# loop over k, v and update accumulator
# существуют В цикле функция загружает блок ключей (K), вычисляет скалярное произведение запроса (Q) и этого блока ключей,
# Затем скорректируйте результаты расчета на основе текущего ЭТАПА. Если это ЭТАП 2 и причинно-следственная связь верна, маска применяется для блокировки будущей информации.
for start_n in range(lo, hi, BLOCK_N):
start_n = tl.multiple_of(start_n, BLOCK_N)
# -- compute qk ----
k = tl.load(K_block_ptr)
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
qk += tl.dot(q, k)
if STAGE == 2:
mask = offs_m[:, None] >= (start_n + offs_n[None, :])
qk = qk * qk_scale + tl.where(mask, 0, -1.0e6)
m_ij = tl.maximum(m_i, tl.max(qk, 1))
qk -= m_ij[:, None]
else:
# В соответствии с вычислением m_ij в строке 9 псевдокода потока алгоритма, разница между псевдокодом и псевдокодом заключается в том, что здесь применяется qk_scale.
m_ij = tl.maximum(m_i, tl.max(qk, 1) * qk_scale)
qk = qk * qk_scale - m_ij[:, None]
# Рассчитать р,Соответствует псевдокоду9ХОРОШОизpизвычислить
p = tl.math.exp2(qk)
l_ij = tl.sum(p, 1)
# -- update m_i and l_i
alpha = tl.math.exp2(m_i - m_ij)
l_i = l_i * alpha + l_ij
# -- update output accumulator --
acc = acc * alpha[:, None]
# update acc
v = tl.load(V_block_ptr)
acc += tl.dot(p.to(tl.float16), v)
# update m_i and l_i
m_i = m_ij
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
return acc, l_i, m_i
需要说明изда这个_attn_fwd_inner函数负责изда一小块Q(入参中изq)иKVизвычислить,Цикл for в коде соответствует циклу KV в псевдокоде.,Цикл Q фактически отражает настройки существующего запуска ядра Triton.,См. код и комментарии ниже:
# Определен класс _attention, который наследуется от torch.autograd.Function. Это позволяет нам настраивать прямое и обратное распространение операции.
# (то есть способ расчета градиентов), что позволяет легко интегрировать его с системой автоматического расчета градиентов PyTorch.
class _attention(torch.autograd.Function):
@staticmethod
# Метод Forward определяет логику прямого распространения этой пользовательской операции. ctx — это объект контекста, используемый для хранения информации, используемой для обратного распространения ошибки.
# q, k, v соответственно представляет запрос, key, value имеет три входных тензора, а causalism_scale — дополнительный управляющий параметр.
def forward(ctx, q, k, v, causal, sm_scale):
# shape constraints
# Эти строки кода проверяют последнее измерение входного тензора, чтобы убедиться, что они имеют одинаковый размер и определенное значение (16, 32, 64, или 128). Это связано с необходимостью оптимизации производительности для конкретной реализации.
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
assert Lq == Lk and Lk == Lv
assert Lk in {16, 32, 64, 128}
# Инициализируйте пустой Tensoro той же формы и типа, что и q, чтобы сохранить выходные результаты.
o = torch.empty_like(q)
# Эти строки устанавливают несколько ключевых параметров настройки производительности, включая размер блока обработки (BLOCK_M, BLOCK_N)и
# Подсчитайте количество этапов (num_stages). num_warps относится к каждому CUDA Количество варпов в блоке.
BLOCK_M = 128
BLOCK_N = 64 if Lk <= 64 else 32
num_stages = 4 if Lk <= 64 else 3
num_warps = 4
stage = 3 if causal else 1
# Согласно возможностям устройства CUDA (здесь проверяются вычислительные возможности 9.x, т.е. NVIDIA Архитектура Volta и более поздние архитектуры), далее настройте num_warpsиnum_stages.
# Tuning for H100
if torch.cuda.get_device_capability()[0] == 9:
num_warps = 8
num_stages = 7 if Lk >= 64 else 3
# Рассчитать Тритон Размер сетки ядра. triton.cdiv — это вспомогательная функция, которая вычисляет деление путем округления в большую сторону.
# q.shape[2] — длина последовательности, q.shape[0] и q.shape[1] — партия и последовательность соответственно. length
grid = (triton.cdiv(q.shape[2], BLOCK_M), q.shape[0] * q.shape[1], 1)
# Инициализируйте еще один TensorM, который используется для хранения промежуточных результатов в процессе расчета.
M = torch.empty((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
# Позвоните Тритону kernel _attn_fwd执ХОРОШО实际израсчет внимания。这里传递了大量изпараметр,Включить вводTensorиз各个维度、шагать、форма、Параметры настройки и т. д..
_attn_fwd[сетка](
q, k, v, sm_scale, M, o, #
q.шаг(0), q.шаг(1), q.шаг(2), q.шаг(3), #
k.stride(0), k.stride(1), k.stride(2), k.stride(3), #
v.stride(0), v.stride(1), v.stride(2), v.stride(3), #
o.stride(0), o.stride(1), o.stride(2), o.stride(3), #
q.shape[0], q.shape[1], #
N_CTX=q.shape[2], #
БЛОК_М=БЛОК_М, #
БЛОК_Н=БЛОК_Н, #
BLOCK_DMODEL=Лк, #
ЭТАП = этап, #
num_warps=num_warps, #
num_stages=num_stages #
)这里изtriton.cdiv(q.shape[2], BLOCK_M)其实就даверноQ进ХОРОШО分块,Следует отметить, что здесь введен Q.,K,Форма V: (Batch, NHeads, Seq, HeadDim).,Таким образом, сетка потоков, начатая здесь, имеет два измерения, оба из которых имеют значения.,КромеxРазмерыtriton.cdiv(q.shape[2], BLOCK_M),它изyРазмерыq.shape[0] * q.shape[1]из乘积(这里изxдасуществовать序列维度上切分也导致了后面构造内存指针из时候有一个特殊изorder=(1, 0),параметр)。То есть这里изBlock数量其实да比较多из,Легче полностью использовать SM графического процессора.,Этот метод запуска аналогичен методу запуска, упомянутому в документе FlashAttention V2.,Подробную информацию можно найти в разделе перевода в конце предыдущего раздела. Что касается,Сколько перекосов мы используем при расчете,Это также соответствует настройкам iPaper,Обычно используется 4,Используйте только 8 для H100. Кроме того, в связи с текущим Q существования,K,Vформаиpaper中из
разные, поэтому и количество блоков тоже разное. Вот количество записанных блоков:
BLOCK_M = 128
BLOCK_N = 64 if Lk <= 64 else 32
Наконец-то есть один_attn_fwdРазобрать,Содержание следующее:
@triton.jit
# Определена функция _attn_fwd. Эта функция представляет собой ядро, реализующее прямой проход механизма внимания. Параметры функции включают входные тензоры запроса (Q), ключа (K) и значения (V).
# коэффициент масштабирования softmax (sm_scale), промежуточный результат расчета (M) и выходной тензор (Out), а Также несколько параметров шага и другие константы конфигурации для этих тензоров.
def _attn_fwd(Q, K, V, sm_scale, M, Out, #
stride_qz, stride_qh, stride_qm, stride_qk, #
stride_kz, stride_kh, stride_kn, stride_kk, #
stride_vz, stride_vh, stride_vk, stride_vn, #
stride_oz, stride_oh, stride_om, stride_on, #
Z, H, #
N_CTX: tl.constexpr, #
BLOCK_M: tl.constexpr, #
BLOCK_DMODEL: tl.constexpr, #
BLOCK_N: tl.constexpr, #
STAGE: tl.constexpr #
):
# Обратите внимание, что ZиH во входных параметрах означает партию соответственно. размерколичество голов внимания
# start_m представляет текущее ядро program Смещение измерения seq, соответствующего экземпляру, а off_hz представляет собой смещение измерения партия*головки.
start_m = tl.program_id(0)
off_hz = tl.program_id(1)
# 这些ХОРОШОвычислить了两个偏移量off_zиoff_h,Они соответственно представляютсуществоватьbatch(илиheads)中из位置。
off_z = off_hz // H
off_h = off_hz % H
# Вычислите смещение, используемое для поиска текущего блока обработки в тензорах Q, KиV. Это основано на ранее вычисленном смещении и предоставленном параметре шага.
qvk_offset = off_z.to(tl.int64) * stride_qz + off_h.to(tl.int64) * stride_qh
# block pointers
# Используйте tl.make_block_ptr, чтобы создать указатель на текущий блок обработки Q-тензора. Этот вызов функции определяет базовый адрес, форму, шаг, смещение, форму блока и т. д. также Как получить доступ к этому блоку данных в памяти.
# N_CTX — это q.shape[2], который представляет длину последовательности, а BLOCK_DMODEL — это Lk, который представляет размерность скрытого слоя каждой головки внимания.
# Следующие тензоры, созданные make_block_ptr, аналогичны, а именно для K, Vа ТакжеOutputO создает указатель на текущий блок обработки.
Q_block_ptr = tl.make_block_ptr(
base=Q + qvk_offset,
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_qm, stride_qk),
offsets=(start_m * BLOCK_M, 0),
block_shape=(BLOCK_M, BLOCK_DMODEL),
order=(1, 0),
)
V_block_ptr = tl.make_block_ptr(
base=V + qvk_offset,
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_vk, stride_vn),
offsets=(0, 0),
block_shape=(BLOCK_N, BLOCK_DMODEL),
order=(1, 0),
)
K_block_ptr = tl.make_block_ptr(
base=K + qvk_offset,
shape=(BLOCK_DMODEL, N_CTX),
strides=(stride_kk, stride_kn),
offsets=(0, 0),
block_shape=(BLOCK_DMODEL, BLOCK_N),
order=(0, 1),
)
O_block_ptr = tl.make_block_ptr(
base=Out + qvk_offset,
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_om, stride_on),
offsets=(start_m * BLOCK_M, 0),
block_shape=(BLOCK_M, BLOCK_DMODEL),
order=(1, 0),
)
# initialize offsets
# Вычислите начальное смещение элементов, которые должен обрабатывать каждый поток, в измерении M (последовательное измерение).
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
# Вычислите смещение элементов, которые должен обрабатывать каждый поток, в измерении N (размерность партии*головок).
offs_n = tl.arange(0, BLOCK_N)
# initialize pointer to m and l
# Инициализируйте вектор m, m используется для хранения максимального логита в каждом измерении m и инициализируется отрицательной бесконечностью.
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
# Инициализируйте вектор l, l используется как знаменатель совокупного softmax и инициализируется значением 1.
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0
# Инициализируйте аккумулятор для накопления весов внимания. Обратите внимание, что здесь фигура (BLOCK_M, BLOCK_DMODEL)
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
# load scales
qk_scale = sm_scale # Загрузите коэффициент масштабирования softmax.
qk_scale *= 1.44269504 # Умножьте коэффициент масштабирования softmax на 1/log(2) для последующих вычислений.
# load q: it will stay in SRAM throughout
q = tl.load(Q_block_ptr) # Загрузите текущий блок Q-матрицы в SRAM, эти данные остаются неизменными на протяжении всего расчета.
# stage 1: off-band
# For causal = True, STAGE = 3 and _attn_fwd_inner gets 1 as its STAGE
# For causal = False, STAGE = 1, and _attn_fwd_inner gets 3 as its STAGE
if STAGE & 1:
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, BLOCK_DMODEL, BLOCK_N, #
4 - STAGE, offs_m, offs_n, N_CTX #
)
# stage 2: on-band
if STAGE & 2:
# barrier makes it easier for compielr to schedule the
# two loops independently
tl.debug_barrier()
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, BLOCK_DMODEL, BLOCK_N, #
2, offs_m, offs_n, N_CTX #
)
# epilogue
m_i += tl.math.log2(l_i)
acc = acc / l_i[:, None]
m_ptrs = M + off_hz * N_CTX + offs_m
tl.store(m_ptrs, m_i)
tl.store(O_block_ptr, acc.to(Out.type.element_ty))
Что требует особого внимания, так это то, что последняя часть эпилога этого кода соответствует FlashAttention. V2伪代码中из12ХОРОШО以后из内容,Исправьте вывод в соответствии со знаменателем softmax. также,Tritonиз实现里面考虑了一些paper里面没有из东西比如qk_scale,causal mask,верноQ*Kиз结果Sприменен минусm,Это значительно усложняет всю реализацию.,Но общая логика алгоритма, настройки параллельности и бумага остались прежними.
0x6.
Эта статья в основном посвящена FlasAttention. V1/V2 выполняет простой анализ принципов и оптимизированную реализацию Python, основное внимание уделяется чтению FlashAttention. Код Triton V2 был реализован и протестирован.
0x7.
- https://zhuanlan.zhihu.com/p/646084771
- https://tridao.me/publications/flash2/flash2.pdf
- https://zhuanlan.zhihu.com/p/681154742
- https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html
- https://mp.weixin.qq.com/s/5K6yNj23NmNLcAQofHcT4Q



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
