YOLOv10 — истинное сквозное обнаружение целей в реальном времени (введение в принципы + детали кода + структурная блок-схема)
💡💡💡Основное содержание этой статьи: Сквозное обнаружение целей в режиме реального времени (введение в принцип + подробности кода + структурная блок-схема) | Как YOLOv10 обучает свой собственный набор данных (в данном случае NEU-DET)
1.Введение YOLov10

бумага: https://arxiv.org/pdf/2405.14458
Код: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
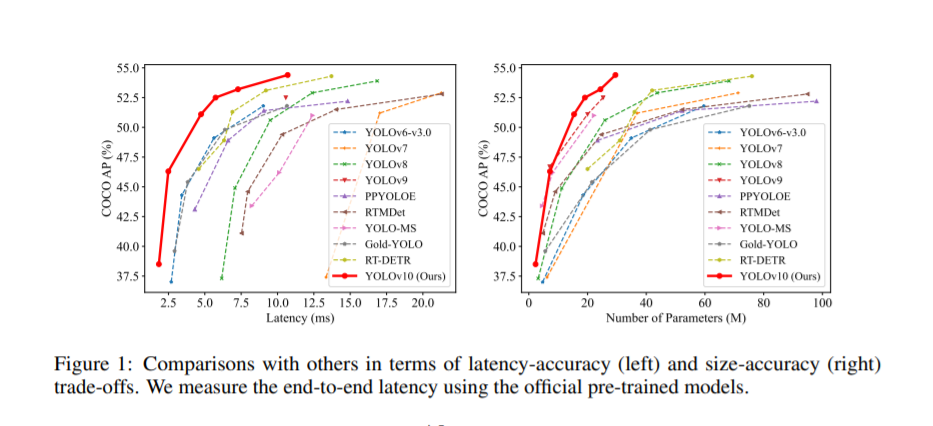
краткое содержание:в последние несколько лет,Благодаря эффективному балансу между вычислительными затратами и производительностью обнаружения.,YOLOS стал ведущей парадигмой в области обнаружения объектов в реальном времени. Исследователи изучили архитектурный дизайн YOLOS, цели оптимизации, стратегии увеличения данных и т. д.,и добились значительного прогресса. Однако,Использование немаксимального подавления (NMS) для постобработки препятствует сквозному развертыванию YOLOS и влияет на задержку вывода.также,В конструкции каждого компонента YOLOS отсутствует всесторонняя и тщательная проверка.,что приводит к значительной вычислительной избыточности,ограничивает производительность модели. Это приводит к неоптимальной эффективности,и значительный потенциал для улучшения производительности. в этой работе,Наша цель — еще больше расширить границы производительности и эффективности YOLOS как с точки зрения постобработки, так и с точки зрения архитектуры модели. с этой целью,Мы впервые предложилиНепрерывное двойное назначение для обучения YOLO без NMS,Такой подход приводит к конкурентной производительности и низкой задержке вывода. также,Мы также представляем общую стратегию проектирования моделей YOLOS, ориентированную на эффективность и точность. Мы полностью оптимизировали каждый компонент YOLOS с точки зрения эффективности и точности.,Значительно снижает вычислительные затраты,Улучшения производительности. Результатом наших усилий стала серия YOLO следующего поколения для сквозного обнаружения объектов в реальном времени.,Позвонил YOLOV10. Обширные эксперименты показывают,YOLOV10 обеспечивает высочайшую производительность и эффективность в различных масштабах моделей. Например,Под аналогичным AP на COCO,Наш YOLOV10-S в 1,8 раза быстрее, чем RT-DETR-R18.,Также имеет в 2,8 раза меньше параметров и FLOPS. По сравнению с YOLOV9-C,YOLOV10-B имеет такую же производительность.,Задержка уменьшена на 46 %,Параметры были уменьшены на 25%.
Какие улучшения есть в YOLOv10?
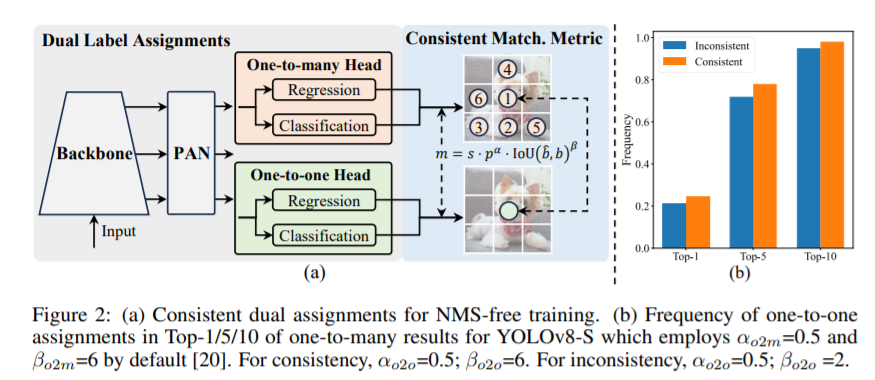
1.1 Назначение двойной метки
В процессе обучения YOLO [20, 59, 27, 64] обычно используют TAL [14] (обучение назначению задач). Назначьте несколько положительных образцов для каждого экземпляра. Использование распределения «один ко многим» может генерировать богатые сигналы мониторинга,провести оптимизацию и повысить производительность. Использование постобработки NMS приводит к неудовлетворительной эффективности вывода о развертывании. Хотя предыдущие исследования [49,60,73,5]Исследование соответствия один к одному для подавления избыточных прогнозов,Но они часто приводят к дополнительным затратам на вывод или приводят к неоптимальной производительности. в этой работе,Мы предлагаем стратегию тренировок йоло без НМС с назначением двойных меток и последовательной метрикой соответствия.,Достигаются высокая эффективность и конкурентоспособность.
1.2 Разработка модели, ориентированной на эффективность
Компоненты YOLO включают в себя начальный слой, слой понижающей дискретизации, сцену с основными строительными блоками и голову. Начальный слой требует минимальных вычислительных затрат, поэтому для остальных трех частей мы разрабатываем модель, ориентированную на эффективность.
(1) Упрощенная классификационная головка: в YOLO головки классификации и головки регрессии обычно имеют одну и ту же архитектуру. Однако они демонстрируют существенные различия в вычислительных затратах. Например, в YOLOv8-S количество FLOP (5,95G) и количество параметров (1,51M) главы классификации в 2,5 раза и 2,4 раза больше, чем у головы регрессии (2,34G/0,64M) соответственно. Однако после анализа влияния ошибок классификации и ошибок регрессии (см. Таблицу 6) мы обнаружили, что высота регрессии более важна для производительности YOLO. Таким образом, мы можем уменьшить накладные расходы на заголовок классификации без чрезмерного ущерба для производительности. Поэтому мы просто принимаем облегченную архитектуру для головы классификации, которая состоит из двух разделенных по глубине сверток [24, 8] с размером ядра свертки 3 × 3, за которыми следует свертка 1 × 1.
(2) Понижающая дискретизация с пространственным разделением каналов: YOLO обычно используют обычную стандартную свертку 3×3 с шагом 2 для одновременной реализации пространственной понижающей дискретизации (от H×W до H/2×W/2) и преобразования канала (от C до). 2С). Это приводит к значительным вычислительным затратам O(9HWC^2) и количеству параметров O(18C^2). Вместо этого мы предлагаем разделить операции уменьшения пространства и увеличения каналов, чтобы добиться более эффективной понижающей дискретизации. В частности, мы сначала используем двухточечную свертку для настройки размеров канала, а затем используем отделимую по глубине свертку для пространственной понижающей дискретизации. Это снижает вычислительные затраты до O(2HWC^2 + 9HWC), а количество параметров — до O(2C^2 + 18C). В то же время это максимизирует сохранение информации во время понижающей дискретизации, тем самым уменьшая задержку, сохраняя при этом конкурентоспособную производительность.
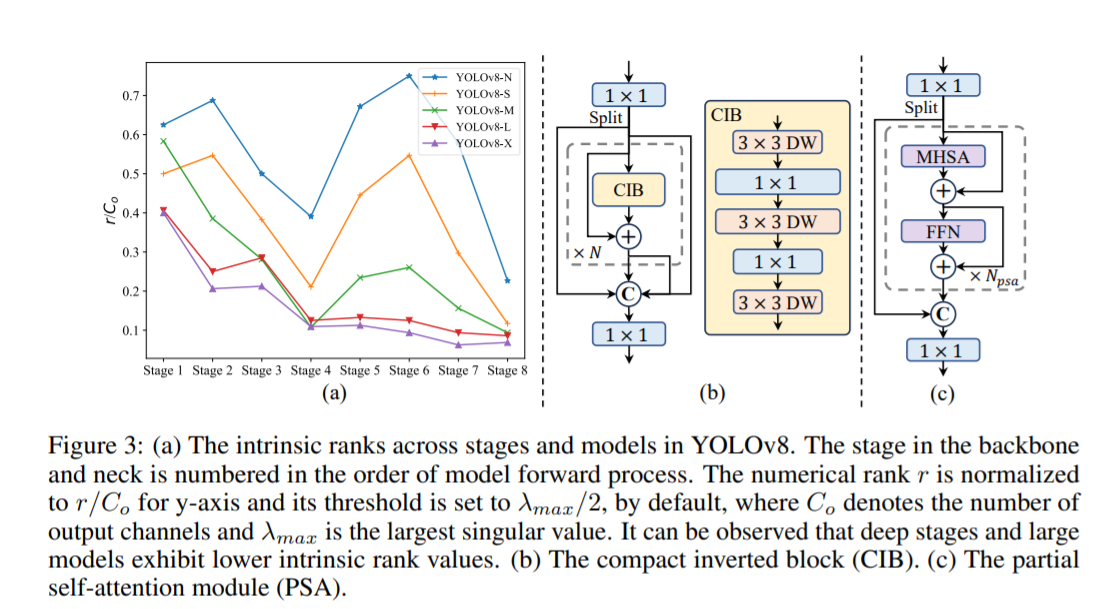
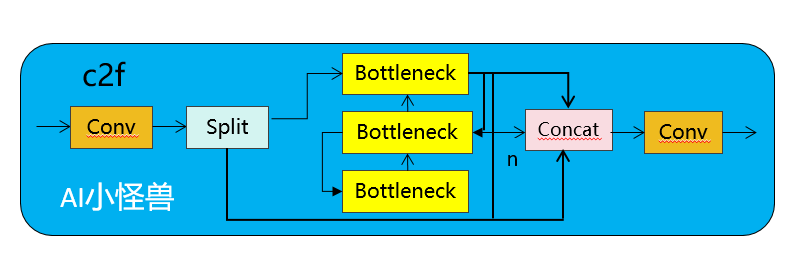
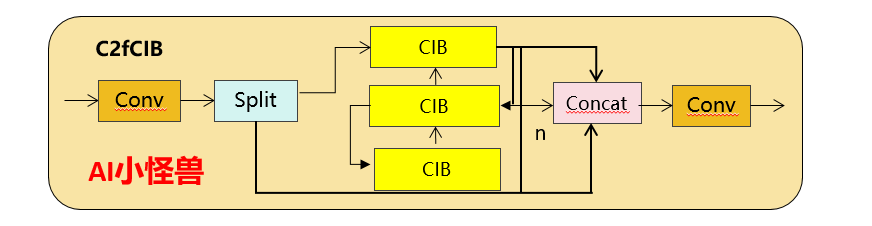
(3) Разработка модулей на основе рангов: YOLO обычно используют одни и те же базовые строительные блоки на всех этапах, например, блок «узких мест» в YOLOv8. Чтобы тщательно проверить эту однородную структуру YOLO, мы используем внутренний ранг для анализа избыточности каждого этапа. В частности, мы вычисляем числовой ранг последней свертки последнего базового блока на каждом этапе, который подсчитывает количество сингулярных значений, превышающих порог. На рисунке 3.(a) показаны результаты YOLOv8, показывающие, что глубокие этапы и большие модели с большей вероятностью будут проявлять большую избыточность. Это наблюдение предполагает, что простое применение одной и той же конструкции блока для всех этапов неоптимально для достижения оптимального компромисса между производительностью и эффективностью. Чтобы решить эту проблему, мы предлагаем схему блочного проектирования на основе рангов, целью которой является снижение сложности этапов, которые оказываются избыточными за счет компактного архитектурного проектирования. Сначала мы предлагаем структуру компактного инвертированного блока (CIB), в которой используются дешевые отделимые по глубине свертки для пространственного микширования и экономичные свертки «точка-точка» для микширования каналов, как показано на рисунке 3.(b). Он может служить эффективным базовым строительным блоком, например, встроенным в структуры ELAN (рис. 3.(b)). Затем мы выступаем за стратегию распределения блоков на основе рангов для достижения оптимальной эффективности при сохранении конкурентоспособности. В частности, для данной модели мы упорядочиваем все этапы в порядке возрастания в соответствии с их внутренним рангом. Далее рассмотрим изменения производительности при замене основных блоков ведущей ступени на CIB. Если ухудшения производительности по сравнению с заданной моделью нет, переходим к замене следующего этапа, в противном случае останавливаем процесс. В результате мы можем реализовать адаптивные компактные блочные конструкции на разных этапах и размерах моделей, достигая более высокой эффективности без ущерба для производительности.
1.3 Точное проектирование модели
(1) Свертка с большим ядром. Использование свертки с большим ядром, отделяемой по глубине, является эффективным способом расширения рецептивного поля и расширения возможностей модели. Однако простое их использование на всех этапах может привести к загрязнению мелких функций, используемых для обнаружения небольших объектов, а также к значительным накладным расходам ввода-вывода и задержкам на этапе высокого разрешения. Поэтому мы предлагаем использовать в CIB на глубокой стадии отделимые по глубине свертки с большим ядром. В частности, мы увеличиваем размер ядра второй отделимой по глубине свертки 3×3 в CIB до 7×7, следуя [37]. Кроме того, мы применяем метод структурной репараметризации, чтобы ввести еще одну отделимую по глубине ветвь свертки 3 × 3, чтобы облегчить проблему оптимизации без увеличения накладных расходов на вывод. Более того, по мере увеличения размера модели ее восприимчивое поле естественным образом расширяется, а выгода от использования больших сверток ядра уменьшается. Поэтому мы используем большие свертки ядра только для моделей небольшого размера.
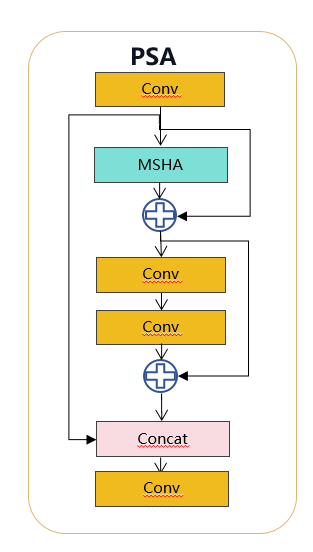
(2) Частичное самообслуживание (PSA). Механизм самообслуживания широко используется в различных визуальных задачах благодаря своим превосходным возможностям глобального моделирования. Однако он демонстрирует высокую вычислительную сложность и объем памяти. Чтобы решить эту проблему, учитывая повсеместную избыточность головы внимания, мы предлагаем эффективную конструкцию модуля частичного самообслуживания (PSA), как показано на рисунке 3.(c). В частности, мы разделяем объекты на две части равномерно после свертки 1×1. Мы только часть его передаем в блок NPSA, состоящий из многоголовочного модуля самообслуживания (MHSA) и сети прямой связи (FFN). Затем две части соединяются и сливаются с помощью свертки 1×1. Кроме того, мы следуем [21] для присвоения размеров запросов и ключей половине значений и заменяем LayerNorm на BatchNorm для быстрого вывода. Кроме того, PSA размещается только после этапа 4 с самым низким разрешением, что позволяет избежать чрезмерных накладных расходов, вызванных вторичной вычислительной сложностью самообслуживания. Таким образом, возможности обучения глобальному представлению могут быть включены в YOLO с низкими вычислительными затратами, что значительно расширяет возможности модели и повышает производительность.
2. Объяснение кода YOLOV10
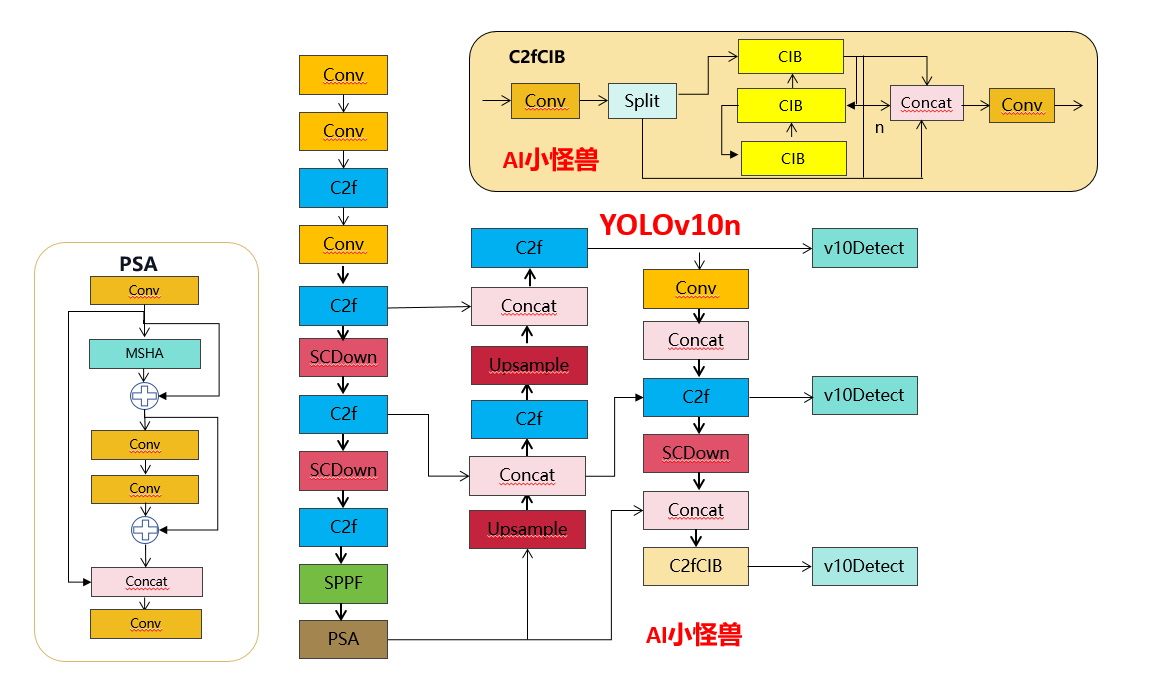
2.1 Знакомство с C2fUIB
C2fUIB просто заменяет структуру «узкого места» C2f в YOLOv8 на структуру CIB.
Код реализации ultralytics/nn/modules/block.py
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))2.2 Введение в PSA
В частности, мы разделяем объекты на две части равномерно после свертки 1×1. Мы только часть его передаем в блок NPSA, состоящий из многоголовочного модуля самообслуживания (MHSA) и сети прямой связи (FFN). Затем две части соединяются и сливаются с помощью свертки 1×1. Кроме того, следуйте инструкциям, чтобы назначить размеры запросов и ключей половине значений, и замените LayerNorm на BatchNorm для быстрого вывода.
Код реализации ultralytics/nn/modules/block.py
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))2.3 SCDown
OLO обычно используют обычные стандартные свертки 3×3 с шагом 2, реализуя при этом пространственную понижающую дискретизацию (от H×W до H/2×W/2) и преобразование каналов (от C до 2C). Это приводит к значительным вычислительным затратам O(9HWC^2) и количеству параметров O(18C^2). Вместо этого мы предлагаем разделить операции уменьшения пространства и увеличения каналов, чтобы добиться более эффективной понижающей дискретизации. В частности, мы сначала используем двухточечную свертку для настройки размеров канала, а затем используем отделимую по глубине свертку для пространственной понижающей дискретизации. Это снижает вычислительные затраты до O(2HWC^2 + 9HWC), а количество параметров — до O(2C^2 + 18C). В то же время это максимизирует сохранение информации во время понижающей дискретизации, тем самым уменьшая задержку, сохраняя при этом конкурентоспособную производительность.
Код реализации ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))
3. Как тренировать YOLov10
3.1 Конфигурация среды
Загрузка исходного кода:
GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
Установка окружающей среды:
conda create -n yolov10 python=3.9
conda activate yolov10
pip install -r requirements.txt
pip install -e .
3.2 NEU-DET обучает собственную модель YOLOv10
3.2.1 Введение в наборы данных
Вы можете использовать его, напрямую перенеся v8
3.2.2 Модификация гиперпараметра
Расположение следующее: default.yaml
3.2.3 Как тренироваться
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOv10
if __name__ == '__main__':
model = YOLOv10('ultralytics/cfg/models/v10/yolov10n.yaml')
model.load('yolov10n.pt') # loading pretrain weights
model.train(data='data/NEU-DET.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
Оригинальная ссылка:
https://blog.csdn.net/m0_63774211/article/details/139225704



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
