YOLO снова борется с туманной погодой | Улучшение данных IA-YOLO + предполагаемая потеря, обновление сцены детектора YOLO можно безболезненно завершить в туманную погоду

В этой статье авторы предлагают новую сеть обнаружения объектов, распознающую туман, под названием FogGuard, целью которой является решение проблем, возникающих в условиях тумана. Системы автономного вождения в значительной степени полагаются на точные алгоритмы обнаружения объектов, но неблагоприятные погодные условия могут существенно повлиять на надежность глубоких нейронных сетей (DNN). Существующие методы в основном делятся на две категории.
- Улучшение изображения, например IA-YOLO;
- Методы, основанные на адаптации предметной области.
Методы улучшения изображения пытаются создавать изображения без дымки. Однако восстановить изображения без дымки из туманных изображений гораздо сложнее, чем обнаружить объекты на туманных изображениях. С другой стороны, методы, основанные на адаптации предметной области, не используют помеченные наборы данных в целевой предметной области. Оба типа подходов пытаются решить более сложную версию проблемы. FogGuard специально разработан для компенсации тумана, присутствующего на сцене, обеспечивая надежную работу даже в туманную погоду. Авторы используют YOLOv3 в качестве базового алгоритма обнаружения целей и вводят новую систему потери восприятия «учитель-ученик» для повышения точности обнаружения целей на туманных изображениях. В ходе обширных оценок общих наборов данных, таких как PASCAL VOC и RTTS, мы демонстрируем улучшение производительности нашей сети. Авторы продемонстрировали, что FogGuard достиг 69,43% mAP в наборе данных RTTS, а YOLOv3 — 57,78%. Кроме того, авторы показывают, что, хотя авторский метод обучения увеличивает временную сложность, он не вносит никаких дополнительных накладных расходов во время вывода по сравнению с обычной сетью YOLO.
I Introduction
Неблагоприятные погодные условия, такие как дождь, снег и туман, создают опасность для вождения. Одной из них является снижение видимости, которая при автономном вождении может ухудшить обнаружение объектов. Это чрезвычайно опасно; необнаруженные объекты невозможно избежать, а объекты, которые расположены или классифицированы неточно, могут привести к тому, что автомобиль отреагирует поворотом или «фантомным торможением». В этой работе авторы акцентируют внимание на улучшении обнаружения объектов в туманную погоду.
Авторы акцентируют внимание на использовании только камер для повышения точности обнаружения объектов. Не все беспилотные автомобили оснащены несколькими типами датчиков, но почти все они оснащены камерами. Это делает исследование авторов широко применимым, в том числе к транспортным средствам с другими типами датчиков; обнаружение объектов на основе камеры всегда можно комбинировать с другими системами для повышения общей точности за счет объединения нескольких датчиков. В других исследованиях изучалось использование дополнительных датчиков, специфичных для тумана, таких как новые радары миллиметрового диапазона.
Сообщество специалистов по обработке изображений исследовало проблемы устранения дымки, устранения дымки и улучшения изображений еще до успеха методов глубокого обучения. Привнося в область обучения методы, основанные на обработке изображений, IA-YOLO объединяет модуль обработки изображений с конвейером обучения, позволяющим анализировать изображения без дымки перед подачей их в обычные детекторы объектов, такие как YOLO. Авторы считают, что проблема рассуждений об устранении дымки изображений гораздо сложнее, чем обнаружение объектов на туманных изображениях. Очевидно, что задача обнаружения и классификации ограничивающей рамки на туманном изображении как определенного класса объекта (например, автомобиля) намного проще, чем восстановление каждого пикселя этого автомобиля. Кроме того, методы, основанные на удалении дымки, обычно требуют значительных вычислительных затрат для получения лучшего качества изображения.
Чтобы улучшить эффект обнаружения целей на туманных изображениях, автор модифицировал процесс обучения сети YOLO-v3, чтобы она могла адаптироваться к туманным изображениям. Улучшенный тренировочный процесс авторов предлагает две новые идеи:
- Потеря восприятия Воли обобщается на потерю восприятия между учителем и учеником (Раздел IV-A)
- улучшение данных с помощью реального тумана с учетом глубины (раздел IV-B)
Авторы используют потерю восприятия, основываясь на интуитивном понимании того, что семантическая информация в туманных изображениях такая же, как и в четких изображениях. Поэтому авторы стремятся минимизировать потерю восприятия между четким изображением и его затуманенной версией. Увеличение данных необходимо, поскольку наборы данных обнаружения туманных объектов, такие как RTTS (изображения примерно 3 КБ), меньше, чем наборы данных четких изображений, такие как PASCAL VOC (приблизительно 16 КБ изображений) и MS-COCO (приблизительно 116 КБ изображений). Гораздо больше. Наши исследования в области абляции показывают, что каждый из наших вкладов помогает повысить точность обнаружения объектов в условиях тумана.
Мы оцениваем и сравниваем производительность предлагаемого нами метода с современными методами, такими как IA-YOLO, DE-YOLO и SSD-Entropy, в наборе данных RTTS. Автор обнаружил, что FogGuard на 11,64% точнее, чем IA-YOLO, и на 14,27% точнее, чем [4], при этом работает в 5 раз быстрее.
II Related Work
Традиционные алгоритмы обнаружения объектов часто недостаточно эффективны в суровых погодных условиях, таких как туман, дождь, снег и при слабом освещении. Для решения этих вопросов соответствующую литературу можно разделить на четыре основные категории:
- Анализировать методы обработки изображений,
- подход, основанный на обучении,
- адаптация домена,
- Методы улучшения изображений, основанные на обучении.
Iii-A1 Analytical image processing techniques
Методы аналитической обработки изображений использовались для улучшения обнаружения объектов за счет улучшения качества изображения. Например, Ю и др. [20] представили адаптивный метод настройки контрастности медицинских изображений, который также можно применять для улучшения обнаружения объектов в условиях низкой освещенности. Чжан и др. [21] предложили метод эффективного управления уклоном кромки для повышения четкости и снижения шума, что может принести пользу в условиях тумана или снега. Аналогичным образом, темный канал [22] для удаления дымки изображения также используется Ченом и др. [23] для восстановления изображений для обнаружения объектов.
Однако эти методы, хотя и эффективны для улучшения отдельных аспектов изображения, все же неспособны справиться со сценами с густым туманом. Более того, они в значительной степени полагаются на физические модели, которым требуется точная информация о сцене (например, атмосферный свет и коэффициенты рассеяния), что делает их зависимыми от настройки или оценки гиперпараметров, что уступило место методам, основанным на обучении.
Iii-A2 Learning based image-enhancement approaches
Благодаря успеху алгоритмов обучения было предложено несколько методов улучшения изображений, основанных на обучении. Методы обучения использовались для поиска правильных фильтров обработки изображений и оценки гиперпараметров для устранения дымки, улучшения условий освещения и улучшения цвета и тона изображений. Эти методы дополнительно улучшаются за счет использования многомасштабных сверточных нейронных сетей (CNN), остаточных блоков или многомасштабной U-Net для устранения дымки.
В этом направлении исследований два широко цитируемых и недавних метода — это IA-YOLO и DE-YOLO. IA-YOLO использует 5-слойную сверточную нейронную сеть (CNN) для оценки гиперпараметров модуля дифференцируемой обработки изображений (DIP), который передает очищенное от дымки изображение в алгоритм обнаружения объектов, в частности YOLO-v3. Этот DIP-модуль включает фильтры удаления дымки, баланс белого, гамму, оттенок и фильтры резкости.
Аналогично, DE-YOLO использует «пирамиду Лапласа для разложения входного изображения на низкочастотную (НЧ) составляющую и несколько высокочастотных (ВЧ) составляющих». Низкочастотные компоненты (считающиеся независимыми от тумана) используются для усиления высокочастотных компонентов за счет остаточных блоков. Эти различные частотные компоненты объединяются в реконструированное улучшенное изображение. Это улучшенное изображение передается в алгоритмы обнаружения объектов, такие как YOLOv3, для улучшения обнаружения объектов.
Методы улучшения изображения, основанные на физике или обучении, решают более сложную проблему, особенно в условиях густого тумана. Например, представьте себе автомобиль в тумане, и видны только две противотуманные фары автомобиля. Восстановить изображение автомобиля в тумане гораздо сложнее, чем просто обнаружить присутствие автомобиля. Чтобы отремонтировать автомобиль, вам нужно знать его цвет, марку и форму. А для обнаружения автомобиля может быть достаточно расположения противотуманных фар на ожидаемой высоте. В результате эти алгоритмы часто создают зашумленные изображения, и их результаты ненадежны.
Iii-A3 Domain Adaptation
Идея неконтролируемой адаптации домена посредством обратного распространения ошибки, разработанная в [30], была применена для обнаружения объектов на туманных изображениях. Проблема адаптации домена состоит в следующем: рассмотрим исходный домен (например, обнаружение объектов на четких изображениях) и целевой домен (обнаружение объектов на туманных изображениях). Предположим, у автора есть тег GT для исходного домена, но нет целевого домена. Адаптация предметной области направлена на поиск способа обучения модели в целевой предметной области, используя сходство с исходной предметной областью. Ганин и др. [30] формулируют адаптацию предметной области как минимаксную задачу между двумя конкурирующими сетями: экстрактором признаков и классификатором предметной области. Классификаторы доменов пытаются отделить входные данные от исходных и целевых доменов, а экстракторы признаков пытаются сделать их неотличимыми. Функции, создаваемые экстрактором функций, также используются для оценки меток исходного домена.
Есть несколько работ, в которых методы адаптации предметной области применяются для обнаружения объектов на туманных изображениях. Хнева и др. [31] изучили сдвиги между распределениями исходных данных и предложили несколько путей адаптации, вводимых классификаторами предметных областей в разных масштабах. Чжоу и др. [32] предложили решение по адаптации полуконтролируемого домена для обнаружения целей, в котором они применили метод дистилляции знаний для получения характеристик немеченого целевого домена. FogGuard тесно связан с адаптацией предметной области, но отличается от нее. При адаптации домена целевые метки не предоставляются.
Для обнаружения объектов на туманных изображениях авторы пометили доступные наборы данных, такие как RTTS. Хотя такие методы, как адаптация домена, также требуют маркировки изображений RTTS и аннотирования количества тумана на каждом изображении, это не предусмотрено в наборе данных RTTS. Хотя наборы данных, такие как RTTS, намного меньше, чем MS-COCO и Pascal VOC, авторы все равно могут использовать эти наборы данных для тонкой настройки.
Таким образом, в отличие от методов адаптации домена, авторы используют метки целевого домена. Но, как и в случае с адаптацией домена, автор усиливает сходство функций между исходным доменом и целевым доменом, синтезируя функции генерации тумана и потери восприятия учитель-ученик.
III Problem formulation and Notation
Автор получил два помеченных набора данных для обнаружения целей: один представляет собой набор данных четкого изображения,
, другой — набор данных туманного изображения
. Эти два набора данных независимо и одинаково распределены из двух разных и неизвестных распределений.
и
при извлечении набор данных туманного изображения намного меньше, чем набор данных четкого изображения.
. Авторы также предполагают доступ к (приблизительно) генератору синтетического тумана.
, который преобразует четкие изображения в туманные изображения,
,в
это из данного четкого изображения
Параметр плотности тумана
Синтетическое изображение туманной погоды.
Остальная часть задачи аналогична задаче обнаружения объектов, предложенной Лю и др. [19], входными данными является цветное изображение.
. Этикетка
,в автор сформировал по изображению
В каждой ячейке сетки находится
метка ограничивающей рамки. Каждая метка ограничительной рамки
размерный, в
это количество категорий. Вектор метки ограничивающей рамки включает в себя 2D-позицию и 2D-размер ограничивающей рамки.
, горячий вектор вероятности класса
и переменная-индикатор наличия или отсутствия каждой ограничивающей рамки.
。
Целью обнаружения объекта является оценка ограничивающей рамки заданного тестового изображения с высокой точностью. Задача обнаружения объектов состоит в том, чтобы найти функцию, которая максимально корректно оценивает все ограничивающие рамки изображения. Учитывая параметризованную модель обнаружения целей
, авторы стремятся найти параметры, которые минимизируют ожидаемые потери при обнаружении цели, когда входное изображение представляет собой туманное изображение.
。
Среди них потеря позиционирования
потеря доверия
определяется как,
здесь,
— это матрица перестановок, которая жадно сопоставляет предсказанные ограничивающие рамки с предсказанными ограничивающими рамками;
— количество реальных ограничивающих рамок на изображении;
размер
идентичная матрица;
это
Вектор-столбец, состоящий из единиц;
– произведение Кронекера;
– поэлементное произведение;
является гиперпараметром,
Это сумма поэлементных потерь Хубера.
IV Methodology
FogGuard основан на двух основных идеях. первый,Во-вторых, смысловая дистанция между туманными и четкими изображениями должна быть сведена к минимуму;,Необходимо использовать все доступныеданныенастроен на обучение методу。FogGuardв алгоритме1резюмировано в。здесь,Автор постепенно выстраивает законченный метод от тонкой настройки только на туманном наборе данных до использования комбинации точной настройки и потери восприятия.

Простой способ решить эту проблему — использовать два набора данных.
туманно
и с помощью функции генерации синтетического тумана
Воля
Отрегулируйте ближе к
. Передача набора данных четких изображений через случайное количество тумана
беспокоить,
. Смешанный набор данных представляет собой объединение нарушенного ясного набора данных и туманного набора данных.
。
Однако этот подход основан на синтетическом тумане.
Очень верно. Другими словами, этот подход не заставляет сеть явно игнорировать эффекты синтетического тумана. Чтобы устранить это ограничение, авторы использовали подход обучения «учитель-ученик». Во-первых, автор использует смешанный набор данных «ясно-туманно».
Обучите сеть как сеть учителей,
Во-вторых, автор в формулу (1) добавляет слагаемое потерь преподавателя и ученика.
, так что сеть учеников оценивает те же объекты на туманных изображениях, которые сеть учителей обнаруживает на четких изображениях.
Одним из ограничений этой функции потерь является то, что связь между сетью учителя и сетью учеников ограничена выходными данными последнего слоя. В целях дальнейшей интеграции преподавателей и учащихся,Автор черпает вдохновение из осознанной утраты,А взаимодействие учителя и ученика «Воля» распространяется на несколько уровней.
Teacher-student perceptual loss
закажи один
слойная сеть
Каждый слой выражается как
,так
. делать
Указывает от 1-го уровня до 1-го уровня.
слойная сеть. Используйте предварительно обученную сеть
два изображения
и
Потеря восприятия [13] между
Конечный слой
Разница между активациями.
В формуле
Представляет собой первый
Количество активаций слоев. Потеря восприятия была использована для кодирования двух смысловых изображений. дистанция между ними.проходитьсосредоточиться наглубокийслойная сеть Высота каждого этажа Level функции, которые обеспечивают значительные улучшения в ряде задач, таких как передача стиля, тем самым способствуя лучшему пониманию изображений. [13]。
Автор Воля обобщает потерю восприятия на потерю восприятия между учителем и учеником и использует ее для наказания четких изображений.
Синтезируйте туманное изображение с соответствующим
смысловая дистанция между ними.
Обратите внимание, что
Это верно
час
Особый случай. Таким образом, совместная целевая функция автора становится:
Потеря восприятия между учителем и учеником наказывает студенческую сеть, если она не может обрабатывать туманные изображения так же, как сеть учителя может обрабатывать четкие изображения. Другими словами, авторы призывают сеть устранять эффекты тумана и наказывать фильтры, соответствующие функциям, обнаруживающим туман.
Depth-aware realistic fog
Как указано в формулировке вопроса, авторы предполагают доступ к генератору синтетического тумана.
. Авторы выбирают следующую широко используемую в литературе модель генерации синтетического тумана [11]:
В формуле
это пиксель
Интенсивность туманного образа,
это пиксель
четкой интенсивности изображения,
Это атмосферный свет (туман), а
— это коэффициент пропускания, часть света, которая не достигает камеры из-за рассеяния тумана.
Уведомление,
Помимо создания тумана, его также можно использовать для создания различных неблагоприятных погодных условий, таких как снег и дождь. В этой работе автор сосредоточился на тумане, оставив Воле исследование снега и дождя. Для генерации тумана
, автор использует константу
. пропускание
С глубиной
Индекс упал.
Когда туман однородный и
является мерой плотности тумана. первый предмет
Оно известно как прямое затухание и описывает затухание излучения сцены в среде. Второй предмет
Известный как воздушный свет, он представляет собой изменение цвета сцены, вызванное ранее рассеянным светом.
Вычисление изображений туманной погоды
Зависит от информации о глубине
, но наборы данных RTTS, MS-COCO или PASCAL-VOC, используемые для обучения обнаружению объектов, не предоставляют информацию о глубине. Такие методы, как IA-YOLO, вместо этого используют модель псевдоглубины, которая имеет максимальную глубину в центре и радиально уменьшающуюся глубину к краям.
В этой статье
Представляет ширину изображения,
представляет высоту, в то время как
является центром изображения. Для оценки глубины авторы использовали MiDaS — модель нейронной сети, способную оценивать глубину по одному изображению. Автор показывает эффект тумана, созданный этим методом, на рисунке 1, и визуальный эффект выглядит реалистично. Авторы также демонстрируют важность использования этой истинной глубины в исследованиях абляции (раздел VI-B4).
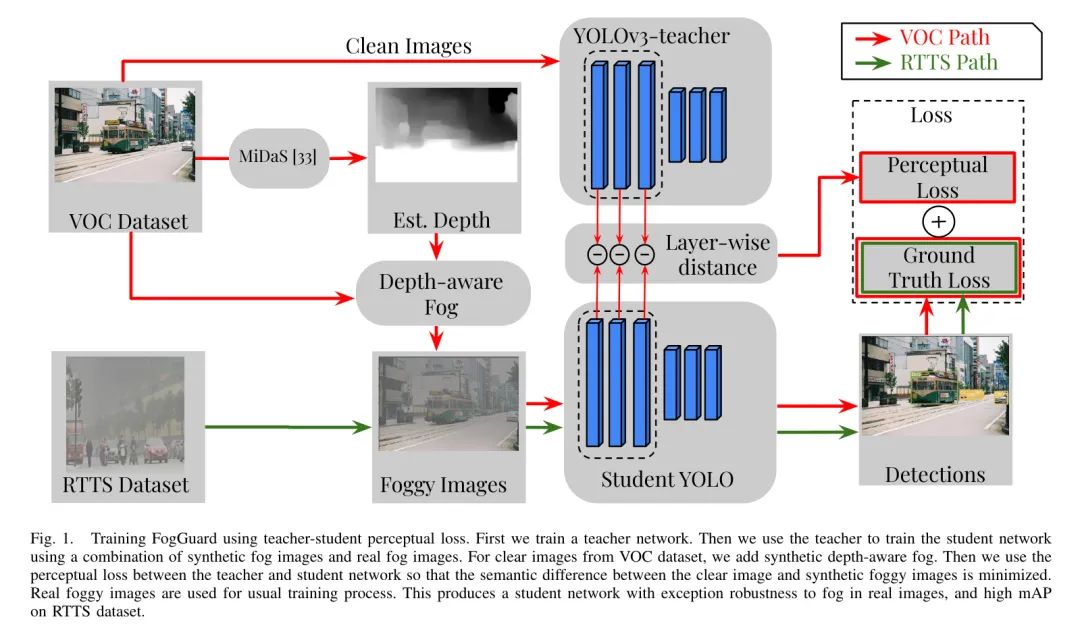
V Experiments
Авторы протестировали FogGuard — FogGuard — посредством оценки большого количества экспериментов. Прежде чем описывать результаты экспериментов авторов,Автор Воля обсуждает общие аспекты экспериментальных установок,Включает выбранный набор целевых объектов обнаружения, детали реализации и показатели оценки.
Datasets
Автор в основном полагается на два набора данных, один из которых — набор данных четкого изображения.
, представленный PASCAL VOC (16 552 изображения), другой — набор данных туманного изображения;
, представленный RTTS (3026 изображений). Авторы создали гибридный набор данных, объединив эти два набора данных.
. Затем этот смешанный набор данных был разделен на части 80-20 для обучения и проверки посредством выборки с заменой.
Наконец, для оценки автор зарезервировал 4952 изображения из PASCAL VOC и 432 изображения из RTTS в качестве набора тестовых данных.
В некоторых экспериментах автор также использовал PASCAL. Три варианта набора данных VOC: замена всех изображений эффектами синтетического тумана с использованием
. Автор Воля Эти три варианта набора данных называются
, соответственно LowFog_、_MediumFog и _HeavyFog_, соответствующий
。
Implementation Details
Автор использует сеть YOLO-v3 в качестве основной базовой архитектуры нейронной сети. Веса сети, инициализированные авторами, были предварительно обучены на наборе данных MS-COCO, который представляет собой более крупный набор данных для обнаружения объектов. Обучение FogGuard начинается с обучения сети учителей. Сеть учителей
— это оптимизатор стохастического градиентного спуска (SGD) для смешанных наборов данных.
Прошёл обучение
цикл. Скорость обучения установлена на
, размер партии
. Студенческая сеть, а именно FogGuard, имеет те же характеристики и обучается с использованием того же набора данных. Автор использует Pytorch для реализации авторской сети и запускает ее на A100. Проведите эксперименты на графическом процессоре. Все эксперименты повторялись 3 раза.,Среднее значение отчетаистандартное отклонение как ошибка。
Evaluation metric
Основной метрикой, используемой авторами, является средняя средняя точность (mAP), как описано Руссаковским и др. [34]. Для расчета mAP авторы следуют двухэтапному процессу. Во-первых, для данного порога
, все обнаруженные ограничивающие рамки сопоставляются с реальными ограничивающими рамками с помощью жадного алгоритма. Если коэффициент пересечения двух ограничивающих рамок больше порога
, они считаются совпадающими. Расчет mAP происходит «путем изменения порога
Затем усредните значения по всем категориям объектов. Здесь отзыв — это отношение количества правильных ограничивающих рамок к количеству истинных ограничивающих рамок. Точность — это отношение количества правильных ограничивающих рамок к количеству предсказанных ограничивающих рамок.
VI Results
Авторы обсуждают результаты сравнения методов авторов в трех типах экспериментов:
- Сравнение с современным базовым уровнем,
- абляционные исследования и
- Анализ эффективности.
Comparison against baseline methods
Автор сравнил FogGuard с четырьмя современными базовыми методами: IA-YOLO, DE-YOLO и SSD+Entropy на двух наборах данных: (1) RTTS и (2) VOC。
Иа-Йоло ИА-ЙОЛО PASCAL VOC и RTTS Оценка выполнялась на наборе данных, а обученная сеть была предоставлена автором этой статьи. Для того, чтобы сравнение было более справедливым, автор сделал RTTS Дополнительные данные были предоставлены в сети
циклы тонкой настройки и сообщают о наилучшей производительности для обоих наборов данных.
В авторских экспериментах,Автор использовал предоставленную сеть предварительно обученных весов для проверки метода DE-YOLO. без дополнительной подготовки,Автор оценил его производительность на тестовом наборе данных VOC и производительности набора данных RTTS.,Потому что автор не предоставил сценарий обучения.
Метод Ssd+Entropy был разработан на основе исследований Bijelic et al.,Это воля неопределенности энтропии встроена в архитектуру SSD. Однако,В отличие от их исследования, в котором используются мультимодальные входные данные,авторский Baseline Сосредоточьтесь на вводе одномодальных изображений с использованием набора VOCиRTTSданные.
В таблице 1 автор суммировал различия между FogGuard и RTTSиPASCAL. о ЛОС Baseline mAP(%) по сравнению с методом. FogGuard превосходит все рассмотренные по RTTSиVOC Baseline Методы, включая IA-YOLO, DE-YOLO и SSD-Etropy.
Ablation Studies
Авторы провели пять исследований абляции, чтобы понять важность различных компонентов в разработке авторов.
Vi-B1 Comparison against the teacher network
Авторы сравнили FogGuard с гибридным набором данных.
Преподаватели прошли обучение по YOLOв3сеть производительность (используйте (2)). Автор показывает каждую сеть автора в ЛОС.、RTTS в сочетании с LogFog、mAP(%) оценивается при возмущениях MediumFog и HeavyFog.
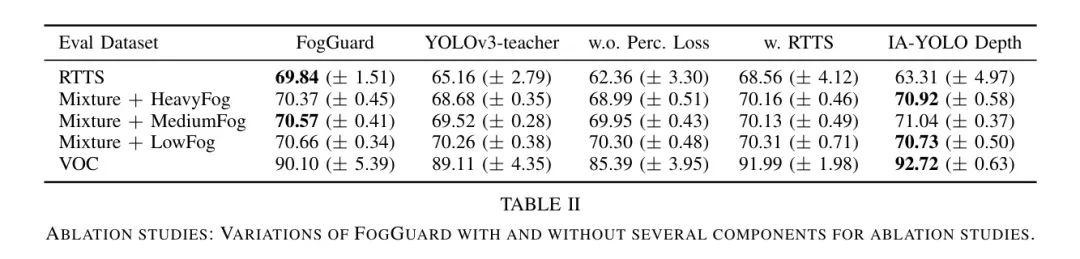
поверхность2первый столбец в(FogGuard)ивторой столбец(YOLOv3-teacher)показалFogGuardпо сравнению сYOLOv3-teacherбезразличныйданныепревосходство в оценке наборапроизводительность。Это подчеркиваетво время Тренировки используют синтетический туман, чтобы учесть важность воспринимаемой потери. Что особенно примечательно, так это то, что,В случае RTTSданного набора,FogGuard значительно лучше, чем модель учителя YOLOv3.,разрыв в производительности почти
。
Vi-B2 Importance of the Teacher-Student Perceptual Loss
В третьем столбце таблицы 2 авторы показывают влияние обучения сети FogGuard без учета потери восприятия. Удалив из сети потерю восприятия, авторы получают набор данных, использующий только гибридные возмущения.
ипотеря(1)подготовленные преподавателисеть(w.o. Perc. Потеря). Обучение FogGuard без учета потерь восприятия эквивалентно обучению обычной сети YOLOv3 только с увеличением данных на основе тумана. Исключение потерь восприятия вредно для производительности сети авторов, поскольку сеть FogGuard работает лучше, чем (w.o. Perc. Потеря) сети.
Vi-B3 Including RTTS dataset in Perceptual loss hurts performance
Как упоминалось в (6), потеря восприятия учителя и ученика наблюдается только в наборе данных четких изображений.
Рассчитайте дальше. Автор поднял вопрос: Воля туманного изображения набор данных RTTS включен в термин потери восприятия,Потеряет ли он производительность или увеличит производительность? В четвертом столбце таблицы 2 показаны,ВоляRTTS включена в расчет потерь восприятия,Автор проиграл в оценке RTTS
, полученное в ЛОС
。
Это показывает, что FogGuard немного более точен при работе в настоящую туманную погоду и немного менее точен при работе с четкими изображениями. Однако сеть автора, как правило, более устойчива к реальной туманной погоде, поскольку стандартное отклонение сети в Таблице 2 для набора данных RTTS почти в 3 раза больше, чем у сети в Таблице 2.
Vi-B4 Importance of realistic depth in fog generation
Как обсуждалось в разделе IV-B, для создания изображений с более реалистичными эффектами тумана авторам необходимо иметь информацию о глубине изображения. Информация о глубине требуется только на этапе обучения FogGuard, а не на этапе вывода. Авторы получают информацию о глубине от MiDaS [33], тогда как IA-YOLO использует псевдоглубину, как описано уравнением (9). IA-YOLO предполагает максимальную глубину в центре, уменьшающуюся радиально наружу.
В последнем столбце таблицы 2 показано, что mAP сети в RTTS падает при использовании метода IA-YOLO для генерации синтетического тумана.
,А вот ЛОС увеличился на 2,62%. Это открытие подчеркивает важность улучшения способности точно обнаруживать объекты в условиях тумана на истинной глубине. Используйте псевдоглубинучас,Увеличение mAP на изображениях ясного и синтетического тумана удивляет. Одна из гипотез заключается в том,,Туман на основе MiDaS более сложен, чем туман псевдоглубины.,Сложнее понять и удалить. Это ухудшает качество изображения при наборе четких данных и синтетическом тумане.
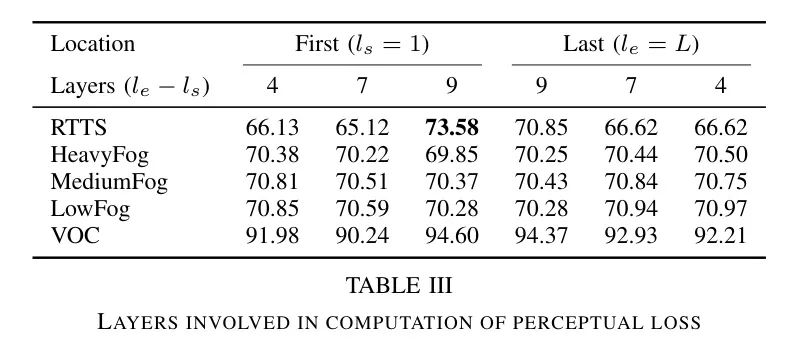
Vi-B5 Location and number of layers used in Perceptual loss
Наконец, авторы исследуют влияние положения и количества слоев, учитываемых при расчете потерь восприятия в FogGuard. Потери восприятия, определенные в (5), зависят от начального слоя.
Конечный слой
. Авторы оценили два места: во-первых, первые несколько слоев.
, затем последние несколько слоев
. Автор также изменил количество слоев.
Диапазон от 4 до 9. Результаты показаны в таблице 3.
Для этого эксперимента,Автор Воля Количество тренировочных часов зафиксировано 300 (исходный эксперимент был 600),Обнаружено, что включение большего количества слоев для расчета потерь восприятия обычно приводит к лучшему обнаружению объектов. Однако,В процессе обучения при вычислении разницы всех слоев в сети учитываются только компромиссы между некоторыми слоями. Автор нашел,При использовании 9 слоев вместо 4 часов,Продолжительность эксперимента увеличилась почти втрое.
Efficiency Analysis
FogGuard не имеет накладных расходов по сравнению с исходным YOLO во время вывода. Эта сеть имеет точно такое же количество параметров, что и оригинал.,Добавление дополнительных блоков, как это видно в IA-YOLO, не требует затрат. Однако,во время тренировки,FogGuard по-прежнему необходимо поддерживать две разные YOLOсети.,т. е. сеть учителей и сеть учеников,для расчета предполагаемых потерь.
В результате FogGuard работает так же быстро, как и его базовая сеть YOLO-v3; Эта функция с нулевыми издержками также позволяет легко адаптировать FogGuard к другим сценариям, требующим повышенной точности или скорости. В данном случае авторы просто заменили базовую сеть YOLO-v3 и обучили новую сеть, чтобы сделать ее более устойчивой к неблагоприятным условиям.
Чтобы продемонстрировать эффективность FogGuard,Автор сравнил время выполнения FogGuardиIA-YOLO на 100 сэмплах. В этом эксперименте,Скорость выполнения FogGuard в 5,1 раза выше, чем у IA-YOLO (139,68 секунды против 27,42 секунды).
VII Conclusion
Автор предложил FogGuard,Это новый метод эффективного обнаружения объектов в сложных погодных условиях. FogGuard использует архитектуру «учитель-ученик», в которой сеть учащихся учитывает потерю восприятия.,для повышения устойчивости к неблагоприятным погодным условиям. производительность за счет синтеза реалистичных эффектов тумана во входном изображении и имитации сети учителя,FogGuard достигает замечательных результатов.
посредством строгих экспериментов,Автор демонстрирует превосходство авторского оптимизированного метода обучения и тщательно разработанного набора данных.,Значительно превосходит существующие методы. Автор также заявил,FogGuard не обременяет базовую YOLOсеть,Это делает его подходящим подходом к решению реальных проблем, таких как автономное вождение.
ссылка
[1].FogGuard: guarding YOLO against fog using perceptual loss.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
