Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей
В настоящее время модели большого языка (LLM) широко используются в различных приложениях. Однако в этом случае использования возникает дилемма: как найти баланс между защитой активов владельца модели и обеспечением конфиденциальности пользовательских данных. На конференции RSA 2024 года технические сотрудники Zama Бенуа Шевалье-Мамес и Джордан Фрери рассказали, как они используют технологию полного гомоморфного шифрования (FHE) для дальнейшей защиты интеллектуальной собственности и конфиденциальности пользователей и поставщиков моделей. Они продемонстрировали осуществимость и практичность этого подхода с целью обеспечить более комплексную поддержку безопасности для услуг LLM.
1. Справочная информация
С быстрым развитием технологий искусственного интеллекта,Модель большого языка (LLM) все чаще используется в различных областях. Из простых письменных пособий,для сложных задач, таких как редактирование резюме и оптимизация кода,LLM Служить постепенно становится неотъемлемой частью повседневной жизни и работы людей. Однако,Большая часть LLM Служить, которую используют люди, поступает от платных API, предоставляемых поставщиками LLM Служить. Доступ таким способом неизбежно требует от пользователей загрузки своего контента в конец Служить.,Существует риск утечки имущества,Например, известен инцидент, когда звездный сотрудник слил исходный код при использовании ChatGPT. в общем,LLM Служить Существует противоречие, которое необходимо взвесить,Прямо сейчасЭто требует как возможностей больших моделей, так и защиты конфиденциальности пользователей.。
В настоящее время существует три основных метода решения этой проблемы компромисса:
Используйте LLM собственной разработки
Создание и обучение вашего собственного LLM с нуля для собственного использования, безусловно, может избежать проблемы утечки конфиденциальности и собственности пользователей, но стоимость этого чрезвычайно высока и неприемлема. Вот почему в настоящее время на рынке существует лишь несколько производителей, способных разрабатывать LLM самостоятельно, а другие более мелкие пользователи не могут разрабатывать LLM самостоятельно.
Используйте LLM с открытым исходным кодом
В настоящее время в сообществе открытого исходного кода есть несколько программ LLM с открытым исходным кодом, такие как Llama от Meta, Grok от xAI, отечественный Qwen и т. д. Существование моделей с открытым исходным кодом эффективно снижает порог. Пользователи, не имеющие достаточных вычислительных ресурсов и профессиональных знаний, могут легко получать, использовать и изменять эти модели для решения своих собственных проблем. Однако нельзя отрицать, что в большинстве случаев возможности моделей с открытым исходным кодом обычно уступают бизнес-моделям с закрытым исходным кодом.

Рисунок 1. Ранжирование возможностей крупных моделей.
Используйте коммерческий LLM
В большинстве случаев пользователи предпочитают использовать LLM с более широкими возможностями для лучшего выполнения задач, поэтому они по-прежнему предпочитают использовать общепринятые бизнес-модели. Однако это приводит к тому, что пользователям приходится подвергать риску конфиденциальность своей интеллектуальной собственности.
Поэтому для достижения цели защиты конфиденциальности интеллектуальной собственности пользователей при использовании сервисов LLM Зама предложил метод использования полностью гомоморфного шифрования при использовании бизнес-модели.
2. Полностью гомоморфное шифрование.
Гомоморфное шифрование — это инновационная технология шифрования, которая обеспечивает уникальную возможность выполнять вычисления в то время, когда данные зашифрованы, — способность, которая имеет решающее значение для защиты конфиденциальности данных при одновременной их обработке. Гомоморфное шифрование имеет широкий спектр применений, особенно в области облачных вычислений и обработки данных с сохранением конфиденциальности, поскольку пользователи могут использовать ресурсы облачных вычислений для обработки данных, не доверяя поставщику услуг. Гомоморфное шифрование можно разделить на частично гомоморфное шифрование и иерархическое гомоморфное шифрование, которые соответственно поддерживают неограниченное количество операций одного типа (например, только сложение или только умножение) или ограниченное количество операций сложения и умножения над зашифрованными данными. Однако эти формы гомоморфного шифрования имеют определенные ограничения в практическом применении, поскольку они не поддерживают сколь угодно сложные вычисления. Полностью гомоморфное шифрование (FHE) — это усовершенствованная форма технологии гомоморфного шифрования. Она позволяет выполнять любое количество операций сложения и умножения над зашифрованными данными без теоретического ограничения на количество операций.
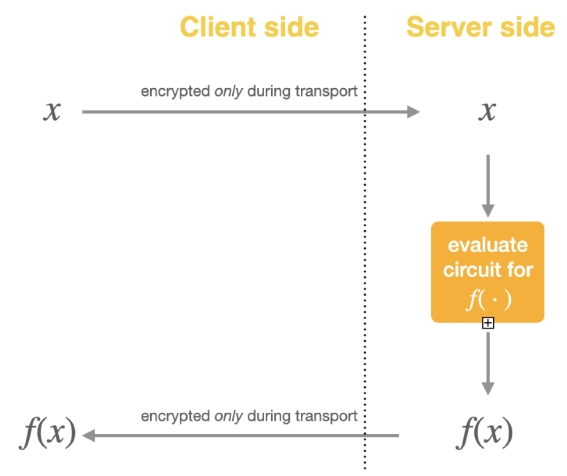
Рисунок 2. Данные шифруются только во время передачи.
В настоящее время, когда пользователи используют услуги LLM, данные шифруются и защищаются только во время передачи. На стороне сервера данные, введенные пользователем, будут расшифрованы в обычный текст, а затем переданы в большую модель для обработки и генерации соответствующего ответа. Это означает, что независимо от того, являются ли они входными или выходными, вся конфиденциальность пользователя сохраняется в данные прозрачны для поставщика LLM. После использования FHE пользователь сначала зашифрует входные данные, а сторона модели будет использовать LLM для их обработки и получения зашифрованных выходных данных, а пользователь может использовать свой собственный ключ для расшифровки выходных данных и получения выходного открытого текста. Вся сторона модели не может получить доступ к простому тексту ввода и вывода, что обеспечивает безопасность интеллектуальной собственности и конфиденциальность пользователей.
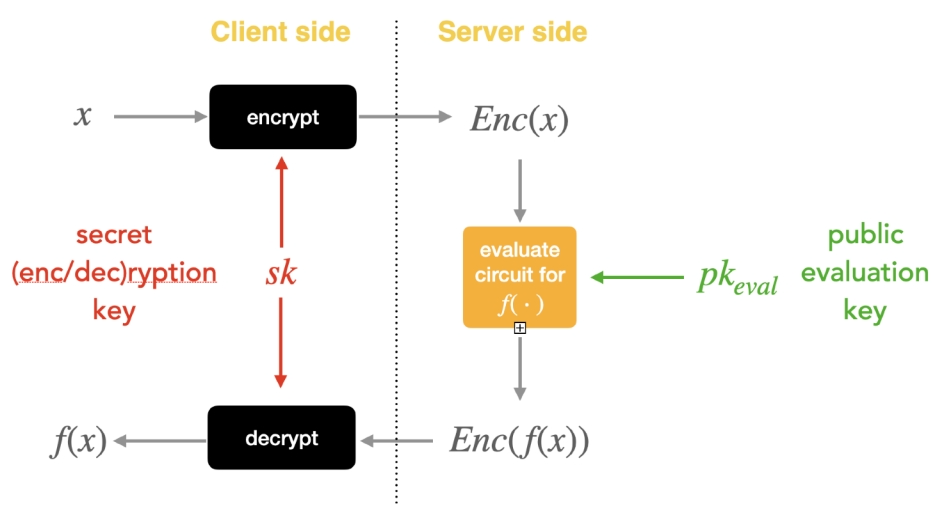
Рисунок 3. Сервис LLM после применения полностью гомоморфного шифрования.
3. Использование полностью гомоморфного шифрования в больших моделях.
Структура Transformer, на которую опирается LLM, намного сложнее, чем обычное сложение и умножение. Поэтому для анализа возможности применения FHE в сервисах LLM требуется демонтировать все операции в Transformer. В общем, LLM в основном состоит из трех операций: встраивания, прямой связи и внимания.
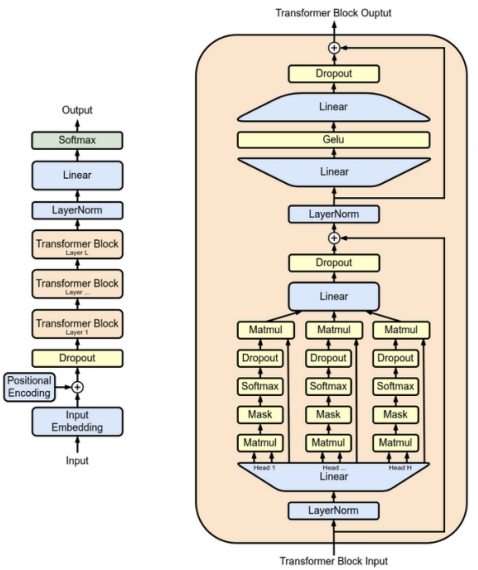
Рисунок 4. Структура трансформатора LLM.
Встраивание
В LLM ввод естественного языка делится на ряд токенов меньшего размера посредством сегментации слов (токенизация). Чтобы преобразовать эти токены в форму, которую модель может понимать и использовать, модель сопоставляет эти токены с уникальными целочисленными идентификаторами путем запроса предопределенного словаря (словаря). Словарь представляет собой список, содержащий токены и соответствующие им идентификаторы в диапазоне от десятков до сотен тысяч. Каждый токен имеет уникальный идентификатор в словаре, и этот идентификатор можно использовать для получения вектора внедрения, связанного с каждым токеном. Вектор внедрения — это представление внутри модели, которое кодирует каждый токен в плотный вектор, обычно массив действительных чисел фиксированного размера, который может отражать значение и использование токена в контексте.
В общем, операции внедрения в LLM представляют собой в основном простые операции запроса таблицы и не включают в себя сложные операции, поэтому к этой части операции возможно применить решение FHE. Используя такие методы, как зашифрованный словарь и запросы, LLM по-прежнему может быстро получить необходимые векторы внедрения, не тратя дополнительного времени, обычно на уровне миллисекунд.
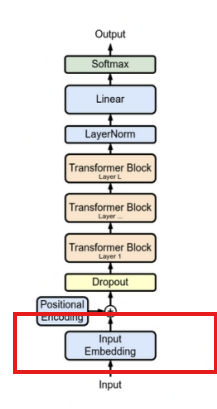
Рис. 5. Встраивание
Прямая связь
Структура LLM обычно имеет несколько слоев модулей Transformer. В каждом модуле за слоем внимания (Attention) обычно следует нейронная сеть прямого распространения (Feed-Forward Neural Network), которая используется для получения выходных данных слоя внимания. и пропустить его через два полносвязных слоя, которые его обрабатывают. Первый полностью связанный слой расширяет входное измерение до большего размера, а затем выполняет нелинейное преобразование с помощью функции активации. Второй полностью связный слой уменьшает размеры до исходных входных размеров. Это «расширение-сжатие» представляет собой операцию прямой связи, которая обрабатывает данные в различных пространствах представления для захвата более богатых функций, расширяет выразительные возможности модели и обрабатывает локальные функции и является причиной того, почему модель Трансформатора может успешно использоваться. ключевые компоненты для решения задач понимания естественного языка.
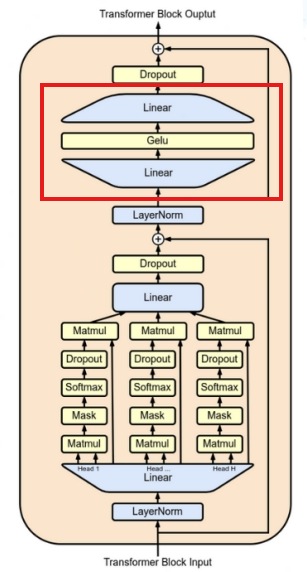
Рис. 6. Упреждающая связь
Говоря математическим языком, работа полносвязного слоя — это не что иное, как линейное преобразование, то есть введение смещения и выполнение матричного умножения. Технология полностью гомоморфного шифрования может поддерживать этот тип линейного преобразования, выполняя произвольные сложения и умножения зашифрованного текста. Функция активации представляет собой операцию нелинейного преобразования. В контексте полностью гомоморфного шифрования реализовать зашифрованную версию нелинейной функции является непростой задачей. Однако, чтобы сделать FHE более практичным, исследователи реализовали некоторые зашифрованные версии нелинейных функций, включая функции активации ReLU, Sigmoid и Tanh, выбрав операции сравнения, разложение в ряд Тейлора, полиномиальную аппроксимацию и другие методы. Короче говоря, применение FHE в режиме прямой связи также возможно, но эффективность расчета нелинейной функции активации в зашифрованном состоянии может быть низкой, и для повышения производительности LLM обычно подключает большое количество модулей Transformer в серии, что приводит к большому количеству вычислений. Функции активации обычно занимают более нескольких секунд или даже десятков секунд.
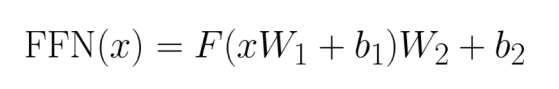
Рис. 7. Расчет прямой связи
Внимание внимание
Поскольку механизм внимания был предложен в 2017 году, он получил широкое распространение в LLM. Он имитирует то, как люди концентрируют свое внимание, позволяя модели улавливать долгосрочные зависимости в предложениях, сосредотачиваясь на важных частях, игнорируя при этом неважное содержание. В модели Трансформера механизм внимания реализован через три понятия «запрос (Q)», «ключ (K)» и «значение (V)».
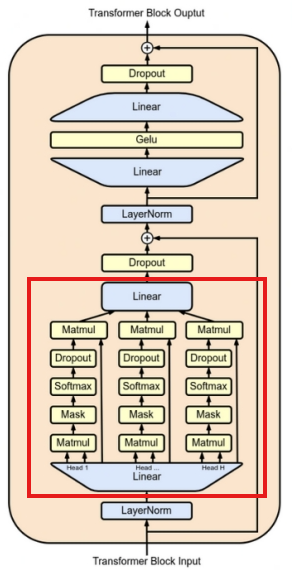
Рисунок 8 Внимание
В операции «Внимание» входные данные модели X сначала преобразуются три раза, чтобы получить Q, K и V соответственно. Поскольку эти преобразования включают умножение матриц и являются линейными операциями, полностью гомоморфное шифрование (FHE) может быть введено относительно легко и эффективно для получения зашифрованных Q, K, V. Однако, поскольку сегодняшние модели начинают поддерживать все более и более длинные контексты, произведение Q и K станет чрезвычайно большим. Хотя один расчет не очень длинный (менее 1 секунды), он окажет существенное влияние на вычислительную производительность FHE из-за необходимости большого количества повторных вычислений. Хотя функция Softmax является нелинейной операцией и требует много времени для расчета, к счастью, количество вычислений относительно невелико. Аналогичным образом, огромные результаты при умножении на V также могут привести к снижению производительности FHE. В целом время расчета механизма внимания значительно увеличится после применения технологии FHE. Простое предсказание следующей операции токена может занять минуты или даже часы, а время генерации полного ответа увеличивается в геометрической прогрессии. Таким образом, механизм внимания является основным узким местом при применении FHE в области LLM.
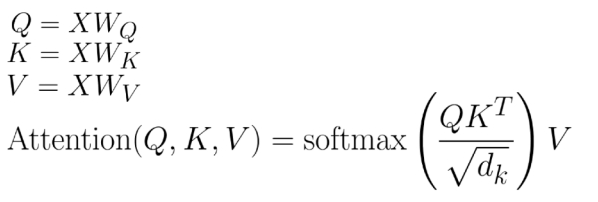
Рисунок 9. Расчет внимания
4. Более быстрый метод – гибридная модель
Чтобы защитить конфиденциальность интеллектуальной собственности пользователей, не нанося ущерба интересам коммерческих поставщиков услуг LLM, Зама предложил подход гибридной модели. В этом методе операции с большим количеством параметров модели, такие как Feed-Forward и Attention, выполняются на стороне сервера с использованием полностью гомоморфного шифрования (FHE). Тем временем другие операции выполняются на стороне пользователя. Таким образом, большинство параметров модели защищены, а также защищены права интеллектуальной собственности и конфиденциальность пользователя.
На примере модели gemma-7b от Google распределение ее параметров выглядит следующим образом:
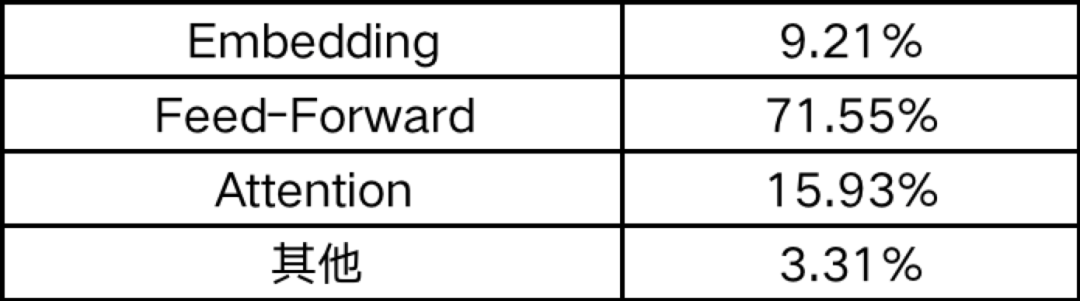
Видно, что вес в основном сосредоточен на Feed-Forward и Attention. Следовательно, в гибридной модели эти две части операций могут выполняться на стороне сервиса с использованием FHE, тогда как остальные операции выполняются на стороне пользователя. Конечно, в соответствии с потребностями пользователя операции внедрения также могут выполняться на стороне сервиса.
Например, в одном сценарии пользовательская сторона хочет запросить LLM, чтобы получить внимание. Пользователи могут выполнять сегментацию слов локально и шифровать полученный идентификатор (целое число) с помощью ключа перед передачей его на сторону службы. Затем сервисная сторона выполнит соответствующие операции внедрения и внимания на основе этих зашифрованных текстов и передаст результаты зашифрованного текста обратно на сторону пользователя. После того, как пользовательская сторона использует свой собственный ключ для расшифровки, она может продолжить шифрование и передать его на сервер для операции прямой связи или напрямую использовать свою собственную нейронную сеть прямой связи локально для следующей операции без повторного шифрования.
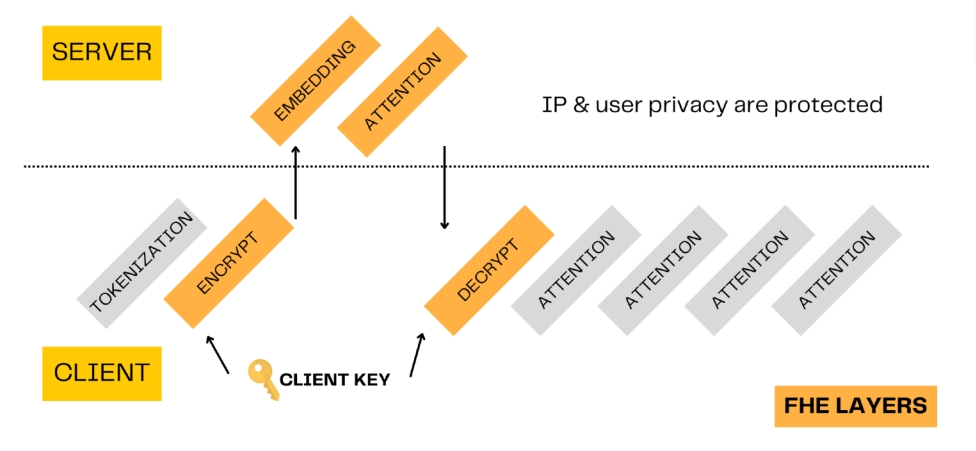
Рисунок 10. Смешанная модель.
5. Резюме
Технический персонал Zama предложил инновационное решение, использующее технологию полностью гомоморфного шифрования (FHE) для защиты интеллектуальной собственности и конфиденциальности пользователей и поставщиков моделей в сервисах больших языковых моделей (LLM), и проверил осуществимость этого решения. Внедряя подход гибридной модели, это решение переносит некоторые операции на сторону службы и выполняет другие операции на стороне пользователя. Это не только защищает большинство параметров модели, но также защищает права интеллектуальной собственности и конфиденциальность пользователей. Этот революционный метод обеспечивает новое направление для будущего развития услуг LLM и, как ожидается, будет способствовать широкому применению технологий искусственного интеллекта при одновременной защите конфиденциальности.
О Заме
Zama — молодая компания, основанная во Франции в 2019 году. Она специализируется на области полного гомоморфного шифрования (FHE) и стремится предоставлять пользователям эффективные и удобные продукты FHE. Команда Zama состоит из экспертов по криптографии и инженеров со всего мира, обладающих обширным опытом и знаниями в области полностью гомоморфного шифрования. За последние четыре года более 30 докторов наук и экспертов по криптографии совершили десятки прорывов в области FHE. Продукты и услуги Zama в основном ориентированы на предоставление решений полностью гомоморфного шифрования. Эти решения имеют широкий потенциал применения в блокчейне, облачных вычислениях, анализе данных и других областях. Zama предлагает инновационные решения в области безопасности данных и защиты конфиденциальности благодаря своей передовой технологии полностью гомоморфного шифрования. Ее технологии и продукты имеют широкие перспективы применения и далеко идущее влияние и, как ожидается, сыграют важную роль в будущем цифровом обществе. .
Ссылки
[1] https://www.rsaconference.com/events/2024-usa/agenda/session/IP%20Protection%20and%20Privacy%20in%20LLM%20Leveraging%20Fully%20Homomorphic%20Encryption
[2] https://www.zama.ai/
[3] https://huggingface.co/blog/encrypted-llm



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
