Выпущен самый мощный AI-чип NVIDIA H200: емкость HBM увеличена на 76%, производительность крупных моделей увеличена на 90%!

Согласно новостям от 14 ноября, Nvidia официально представила новый графический процессор H200 и обновленную линейку продуктов GH200 на конференции «Supercomputing 23» утром 13-го числа по местному времени.
Среди них H200 по-прежнему построен на существующей архитектуре Hopper H100, но добавляет больше памяти с высокой пропускной способностью (HBM3e) для лучшей обработки больших наборов данных, необходимых для разработки и внедрения искусственного интеллекта, что позволяет запускать большие модели. Общая производительность. улучшен на 60–90 % по сравнению с предыдущим поколением H100. Обновленный GH200 также станет основой следующего поколения суперкомпьютеров с искусственным интеллектом. В 2024 году будет введено в эксплуатацию более 200 эксафлопс вычислительной мощности ИИ.
H200: емкость HBM увеличена на 76 %, производительность крупных моделей увеличена на 90 %
В частности, новый H200 предлагает в общей сложности до 141 ГБ памяти HBM3e с эффективной скоростью примерно 6,25 Гбит/с и общей пропускной способностью 4,8 ТБ/с на каждый графический процессор в шести стеках HBM3e. Это огромное улучшение по сравнению с H100 предыдущего поколения (с 80 ГБ HBM3 и пропускной способностью 3,35 ТБ/с), увеличивающее емкость HBM более чем на 76%. Официальные данные показывают, что при использовании больших моделей H200 обеспечит улучшение от 60% (GPT3 175B) до 90% (Llama 2 70B) по сравнению с H100.


Хотя некоторые конфигурации H100 предлагают больше памяти, например H100 NVL, который объединяет две платы и предлагает в общей сложности 188 ГБ памяти (94 ГБ на графический процессор), даже по сравнению с вариантом H100 SXM новый H200 SXM обеспечивает на 76% больше памяти. объем памяти и увеличенная на 43% пропускная способность.
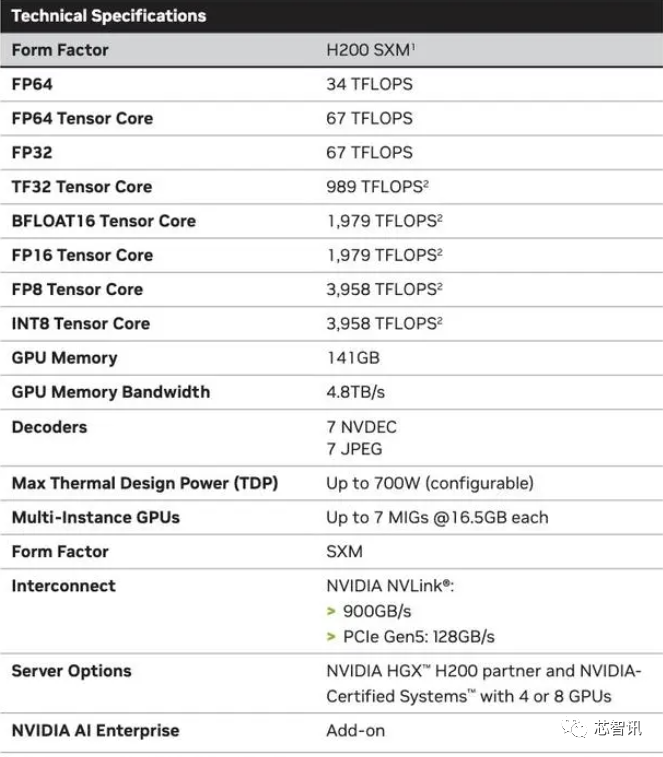
Следует отметить, что вычислительная производительность H200, похоже, не сильно изменилась. Единственный слайд, показанный Nvidia, показывающий производительность вычислений, был основан на конфигурации HGX 200 с использованием восьми графических процессоров с общей производительностью «32 PFLOPS FP8». Исходный H100 обеспечивал 3958 терафлопс вычислительной мощности FP8, поэтому восемь таких графических процессоров также обеспечивают около 32 терафлопс вычислительной мощности FP8.
Итак, какие же улучшения принесет увеличение памяти с более высокой пропускной способностью? Это будет зависеть от рабочей нагрузки. Для больших моделей (LLM), таких как GPT-3, увеличение объема памяти HBM принесет большую пользу. Nvidia заявила, что производительность H200 при использовании GPT-3 будет в 18 раз выше, чем у оригинального A100, а также примерно в 11 раз быстрее, чем у H100. Также есть трейлер грядущего Blackwell B100, но пока он состоит только из более высокой панели, которая затемняется до черного цвета, что примерно в два раза больше, чем у H200.

Мало того, H200 и H100 совместимы друг с другом. Другими словами, компании, занимающиеся искусственным интеллектом, которые используют модель обучения/вывода H100, могут легко перейти на новейший чип H200. Поставщикам облачных услуг не нужно вносить какие-либо изменения при добавлении H200 в свой портфель продуктов.
Nvidia заявила, что с запуском новых продуктов она надеется идти в ногу с ростом размера наборов данных, используемых для создания моделей и сервисов искусственного интеллекта. Расширенные возможности памяти сделают H200 быстрее в процессе передачи данных в программное обеспечение — процессе, который помогает обучать искусственный интеллект выполнению таких задач, как распознавание изображений и речи.
«Интеграция более быстрой и большой памяти HBM может помочь повысить производительность при выполнении ресурсоемких задач, включая генеративные модели искусственного интеллекта и высокопроизводительные вычислительные приложения, одновременно оптимизируя использование и эффективность графического процессора», — сказал вице-президент NVIDIA по высокопроизводительным вычислительным продуктам Ян Бак.
«Когда вы посмотрите на то, что происходит на рынке, вы увидите, что масштаб моделей быстро увеличивается», — сказал Дион Харрис, руководитель отдела продуктов для центров обработки данных Nvidia. «Это часть нашего постоянного быстрого внедрения новейших технологий. величайшая технология. «Еще один пример».
Ожидается, что производители мэйнфреймов и поставщики облачных услуг начнут использовать H200 во втором квартале 2024 года. Партнеры-производители серверов NVIDIA (включая Evergreen, Asus, Dell, Eviden, Gigabyte, HPE, Hongbai, Lenovo, Wenda, MetaVision, Wistron и Wiwing) могут использовать H200 для обновления существующих систем, в то время как Amazon, Google, Microsoft, Oracle и т. д. станет первым поставщиком облачных услуг, принявшим H200.
Учитывая текущий высокий рыночный спрос на чипы NVIDIA AI и новый H200 с добавлением более дорогой памяти HBM3e, H200 определенно будет дороже. Nvidia не называет цену, но предыдущее поколение H100 стоило от 25 000 до 40 000 долларов.
Представитель Nvidia Кристин Утияма отметила, что окончательные цены будут определяться производственными партнерами Nvidia.
Что касается того, повлияет ли запуск H200 на производство H100, Кристин Утияма сказала: «В течение года вы увидите увеличение наших общих поставок».
Высокопроизводительные чипы искусственного интеллекта от Nvidia всегда считались лучшим выбором для эффективной обработки больших объемов данных, обучения больших языковых моделей и инструментов создания искусственного интеллекта. Когда был выпущен H200, компании, занимающиеся искусственным интеллектом, все еще отчаянно искали на рынке чипы A100/H100. . В центре внимания рынка по-прежнему остается вопрос о том, сможет ли Nvidia обеспечить клиентов достаточным количеством поставок для удовлетворения рыночного спроса. Следовательно, будет ли H200 по-прежнему в дефиците, как H100? NVIDIA не дала на этот ответ ответа.
Однако следующий год может стать более благоприятным периодом для покупателей графических процессоров. Согласно сообщению Financial Times за август, NVIDIA планирует утроить производство H100 в 2024 году, а с 2023 года план производства составит около 500 000 единиц. Увеличение до 2 миллионов. в 2024 году. Но генеративный искусственный интеллект по-прежнему процветает, и спрос, вероятно, будет выше в будущем.
Например, недавно запущенный GPT-4 обучается примерно на 10 000–25 000 блоков A100; большая модель AI Meta требует примерно 21 000 блоков A100; Stability AI использует примерно 5 000 блоков A100; обучение Falcon-40B использует 384 блока A100.
По словам Маска, для GPT-5 может потребоваться 30 000–50 000 блоков H100. Котировка Morgan Stanley — 25 000 графических процессоров.
Сэм Альтман отрицал обучение GPT-5, но отметил, что «OpenAI испытывает серьезную нехватку графических процессоров, и чем меньше людей будут использовать наши продукты, тем лучше».
Конечно, помимо NVIDIA, на рынок искусственного интеллекта активно выходят AMD и Intel, чтобы составить конкуренцию NVIDIA. MI300X, ранее выпущенный AMD, оснащен 192 ГБ HBM3 и пропускной способностью памяти 5,2 ТБ/с, что значительно превосходит H200 по емкости и пропускной способности.
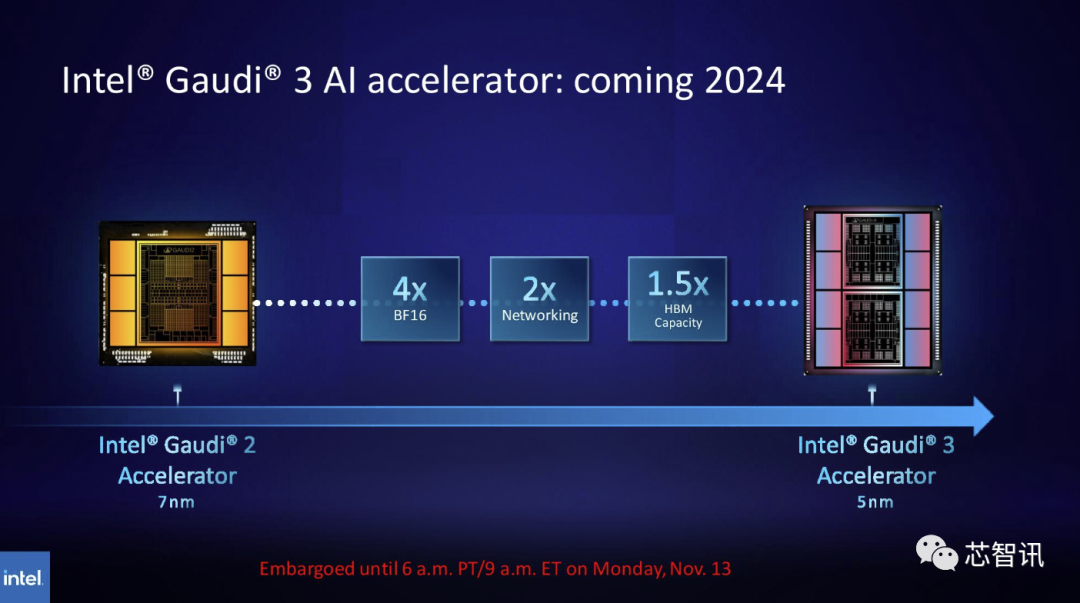
Аналогично, Intel также планирует увеличить производительность HBM чипов Gaudi AI. Последняя опубликованная информация показывает, что Gaudi 3 основан на 5-нм техпроцессе, а его производительность в рабочих нагрузках BF16 будет в четыре раза выше, чем у Gaudi 2, а его сетевая производительность увеличится. также будет вдвое больше, чем у Gaudi 2 (Gaudi 2 имеет 24 встроенных сетевых адаптера 100 GbE RoCE) и имеет в 1,5 раза большую емкость HBM, чем Gaudi 2 (Gaudi 2 имеет 96 ГБ HBM2E). Как мы видим на изображении ниже, Gaudi 3 перешёл на дизайн на основе чиплетов с двумя вычислительными кластерами, а не на однокристальное решение, которое Intel использовала для Gaudi 2.
Новый суперчип GH200: основа нового поколения суперкомпьютеров с искусственным интеллектом
В дополнение к новому графическому процессору H200 NVIDIA также представила обновленный суперчип GH200, который использует соединение чипа NVIDIA NVLink-C2C и сочетает в себе новейший графический процессор H200 и процессор Grace (неясно, является ли это новым поколением суперчипа GH200). также будет включать в общей сложности 624 ГБ памяти.

Для сравнения, GH200 предыдущего поколения основан на графическом процессоре H100 и 72-ядерном процессоре Grace, обеспечивая 96 ГБ HBM3 и 512 ГБ LPDDR5X, интегрированных в одном корпусе.
Хотя Nvidia не представила подробную информацию о процессоре Grace в суперчипе GH200, Nvidia провела некоторые сравнения между GH200 и «современными двухпроцессорными процессорами x86». Видно, что GH200 улучшил производительность ICON в 8 раз, а MILC, квантовое преобразование Фурье, вывод RAG LLM и т. д. улучшили производительность в десятки или даже сотни раз.
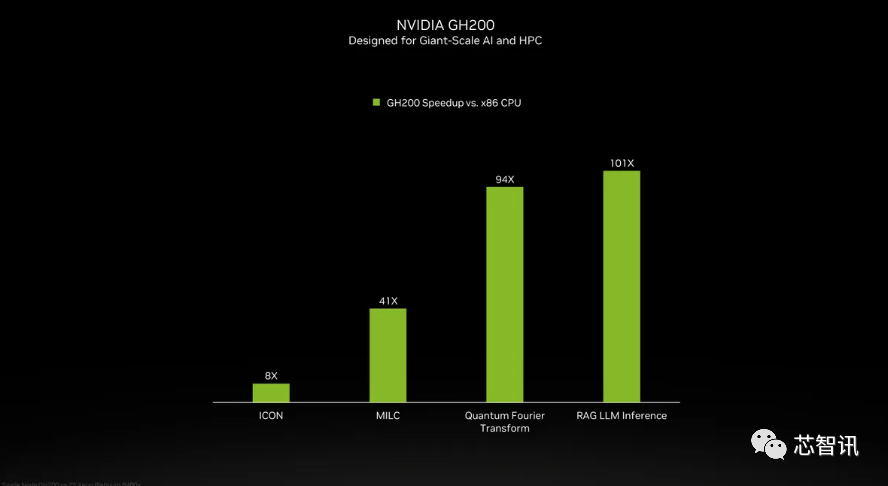
Но следует отметить, что речь идет об ускоренных и «неускоренных системах». что это значит? Мы можем только предполагать, что на серверах x86 используется не полностью оптимизированный код, особенно если учесть, что мир искусственного интеллекта быстро развивается и новые достижения в оптимизации появляются регулярно.
Новый GH200 также будет использоваться в новой системе HGX H200. Говорят, что они «полностью совместимы» с существующими системами HGX H100, а это означает, что HGX H200 можно использовать в одной установке для повышения производительности и объема памяти без необходимости перепроектирования инфраструктуры.
По имеющимся данным, суперкомпьютер Alps в Швейцарском национальном суперкомпьютерном центре может стать одним из первых суперкомпьютеров Grace Hopper на базе GH100, которые будут введены в эксплуатацию в следующем году. Первой системой GH200, которая будет введена в эксплуатацию в США, станет суперкомпьютер Venado в Национальной лаборатории Лос-Аламоса. Система Vista Техасского вычислительного центра (TACC) также будет использовать только что анонсированные суперчипы Grace CPU и Grace Hopper, но неясно, будут ли они основаны на H100 или H200.

В настоящее время самым большим суперкомпьютером, который будет установлен, является суперкомпьютер «Юпитер» в Суперкомпьютерном центре Юлиха. В нем будет размещено «почти» 24 000 суперчипов GH200, что в общей сложности составит 93 эксафлопс вычислений ИИ (предположительно с использованием FP8, хотя большинство ИИ все еще использует BF16 или FP16). Он также обеспечит 1 экзафлопс традиционных вычислений FP64. Он будет использовать плату Quad GH200 с четырьмя суперчипами GH200.
В целом, Nvidia ожидает, что установка этих новых суперкомпьютеров обеспечит производительность вычислений на базе искусственного интеллекта более 200 эксафлопс в течение следующего года или около того.
Редактор: Core Intelligence — Меч Руруни



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
