Вычислительный центр искусственного интеллекта, «секрет» сетевого трафика, лежащий в основе обучения больших моделей
Предисловие: С 2017 года размер моделей ИИ удваивается каждые шесть месяцев: с 65 миллионов в Transformer первого поколения до 1,76 триллиона в GPT-4. Ожидается, что размер больших языковых моделей следующего поколения достигнет 10 триллионов. С другой стороны, объем данных, используемых для обучения модели, продолжает расти. Например, совокупный исходный объем данных C4 превышает 9,5 ПБ, при этом каждый месяц добавляется 200–300 ТБ. Текущий размер набора данных. очистка и обработка составляет около 38,5 ТБ, а количество обучающих выборок — 364,6М. Кроме того, с появлением мультимодальных больших моделей обучающие данные переходят от одного текста к изображениям и видео и даже к трехмерным облакам точек, а масштаб данных будет более чем в 10 000 раз больше, чем у текстовых данных.
Масштаб моделей искусственного интеллекта огромен и продолжает быстро расти. Это не только приведет к экспоненциальному росту трафика центров обработки данных, но и уникальные характеристики трафика также повлекут за собой новые требования к сетям центров обработки данных.
Углубленный анализ трафика обучения, вывода и хранения данных крупных моделей ИИ поможет разработчикам центров обработки данных быть более целенаправленными и предоставлять пользователям более качественные услуги с меньшими затратами, более высокими скоростями и более надежными сетями.
В этой статье мы сосредоточимся на представлении сетевого трафика в сценарии обучения большой модели ИИ. Сценарии вывода ИИ и хранения данных будут представлены в следующих статьях, так что следите за обновлениями.
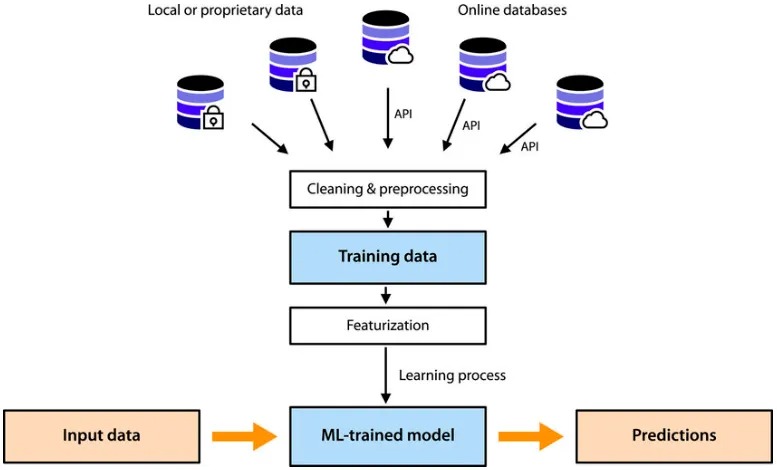
Программа обучения ИИ сначала загружает параметры модели в память графического процессора, а затем проходит несколько эпох (то есть использует все обучающие наборы для полного обучения модели). Процесс обработки каждой эпохи можно просто описать как 4 шага. :
- Загрузите обучающие данные В каждую эпоху разделите весь набор данных на несколько мини-пакетов в соответствии с размером пакета и загружайте обучающие данные пакетами, пока не будет пройден весь набор обучающих данных.
- Обучение, включая прямое распространение, вычисление потерь, обратное распространение и обновление параметров/градиента, выполняет вышеуказанные шаги для каждого мини-пакета.
- Оценка: оценивает метрики модели с использованием набора оценочных данных. Этот шаг не является обязательным и может выполняться отдельно после завершения всего обучения или может выполняться каждые несколько эпох.
- Сохраняйте контрольные точки, включая статус модели, статус оптимизатора, индикаторы обучения и т. д. Чтобы уменьшить требования к хранению, он обычно сохраняется один раз после нескольких эпох.
До появления больших моделей весь процесс мог быть завершен на сервере ИИ. Программа обучения считывала модель ИИ и обучающий набор с локального диска сервера, загружала их в память, завершала обучение и оценку, а затем завершала обучение. сохранил результаты обратно на локальный диск. Хотя для одновременного обучения используются несколько графических процессоров, чтобы ускорить обучение, весь ввод-вывод происходит на сервере искусственного интеллекта и не требует сетевого ввода-вывода.
Каков сетевой трафик для обучения крупных моделей ИИ?
С наступлением эры больших моделей путь обучения ИИ и его сетевые требования претерпели огромные изменения.
Во-первых, масштаб параметров модели превышает объем памяти одного графического процессора. Если кластеры графических процессоров используются для совместных вычислений, им необходимо взаимодействовать друг с другом для обмена информацией. Такая информация включает параметры/градиенты, промежуточные значения активации и т. д.
Огромный набор данных используется всеми графическими процессорами и должен храниться централизованно на удаленном сервере хранения, вызываться через сеть и загружаться на сервер графического процессора в пакетном режиме. Кроме того, регулярно сохраняемые параметры и состояние оптимизатора также должны передаваться через сервер хранения, и в каждую эпоху обучения данные должны считываться и записываться через сеть.
Таким образом, сетевой трафик обучения большой модели ИИ можно разделить на следующие две категории:
- Первая категория — сетевой трафик, который синхронизирует градиенты и промежуточные активации между графическими процессорами.,Это происходит на всех графических процессорах,Это своего рода широковещательный трафик,логически необходимо Все графические процессоры полностью подключены。
- Второй тип — это трафик между графическим процессором и сервером хранения. Он происходит только между графическим процессором и сервером хранения. Это одноадресный трафик, который логически требует только звездообразного соединения с центром на сервере хранения.
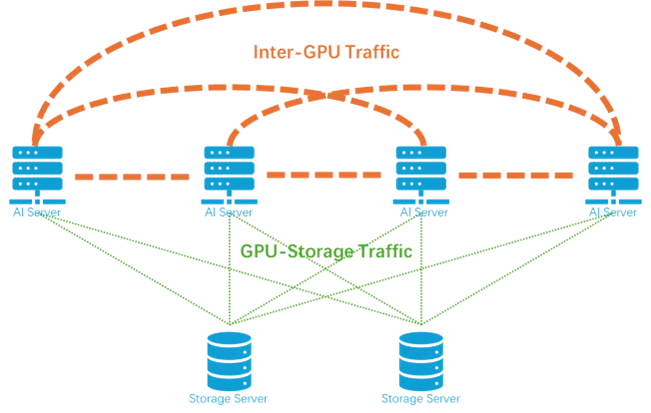
в,Трафик между графическими процессорами сильно отличается от трафика внутри традиционных центров обработки данных.,Это связано сAIМетоды обучения больших моделей тесно связаны с——Технология параллельного обучения。
Параллельное обучение: основной источник трафика для вычислительных центров искусственного интеллекта
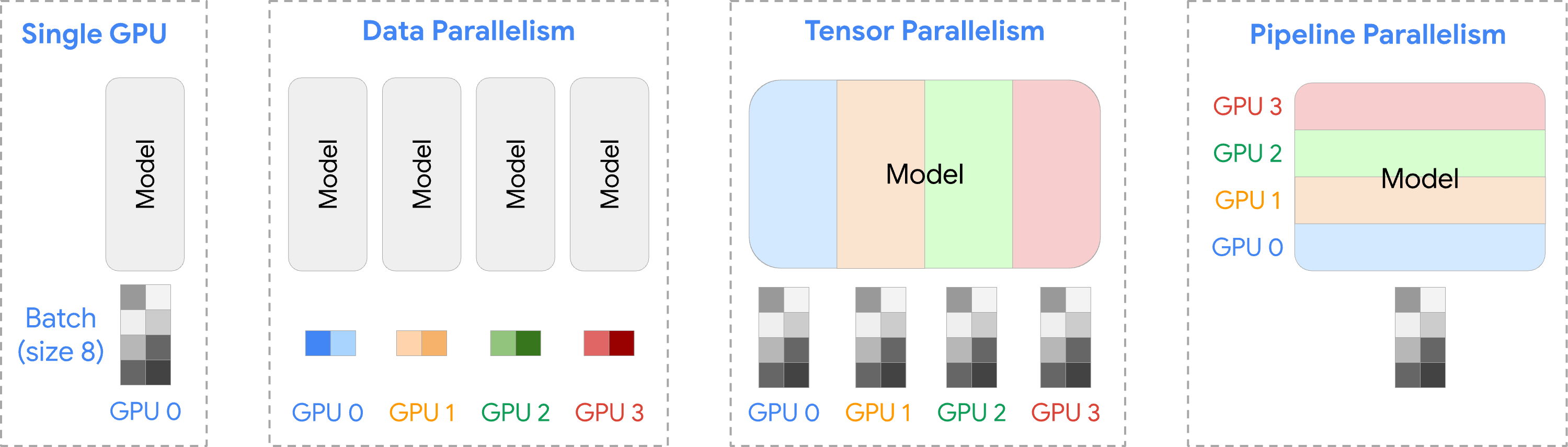
В настоящее время существует три основных типа моделей параллельных вычислений, широко используемых в обучении ИИ:
Режим параллельных вычислений | Подробности |
|---|---|
параллелизм данных | Назначайте разные образцы данных разным графическим процессорам, чтобы ускорить обучение, используемое между хостами; |
тензорный параллелизм | Разделите матрицу параметров модели на подматрицы и распределите их по разным графическим процессорам, чтобы устранить ограничения памяти и ускорить вычисления. Обычно используется внутри хоста. |
Параллелизм трубопроводов | Разделите модель на несколько этапов и назначьте каждый этап отдельному графическому процессору, чтобы улучшить использование памяти и эффективность использования ресурсов. Обычно используется между хостами |
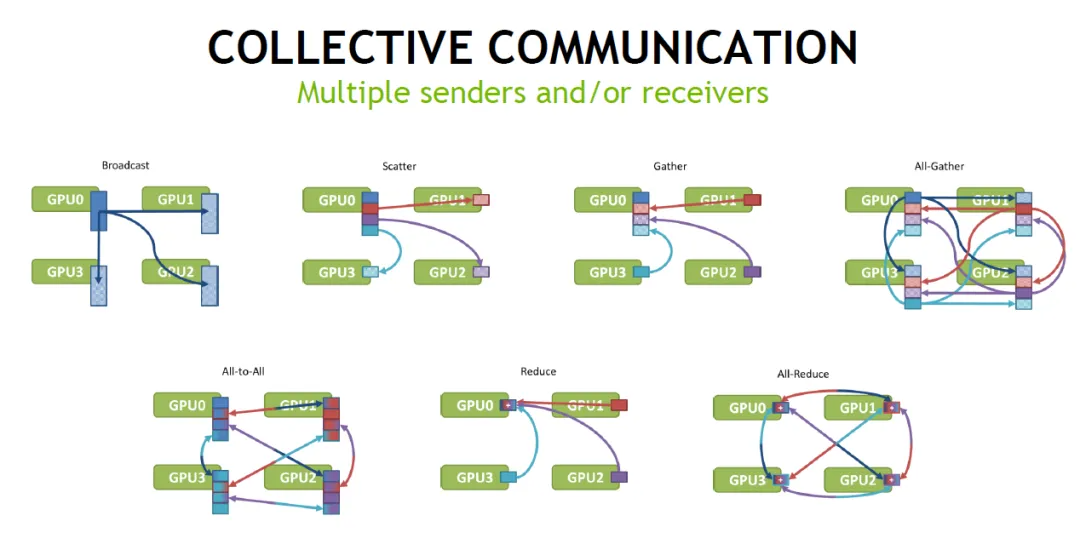
Общие шаблоны трафика коллективной связи (как показано ниже)
1. Параллелизм данных
существоватьпараллелизм Данные, основной сетевой трафик поступает в результате градиентной синхронизации, которая происходит после каждой мини-пакетной обработки и усредняется с помощью операции всесокращения. В идеале все графические процессоры полностью подключены, и каждый графический процессор отправляет данные другим графическим процессорам G-1 отдельно, и в общей сложности необходимо отправить G. x (G-1) фрагментов данных.
FSDP (Полностью сегментированный параллелизм) данные) — улучшенная версия параллелизма данныхтехнология,Разработан для оптимизации использования памяти и эффективности связи. Он хранит параметры модели и градиенты, распределяя их по нескольким графическим процессорам.,Обеспечивает более эффективное использование памяти и обмен данными.
В FSDP сетевой трафик поступает в результате сбора параметров при прямом распространении и синхронизации градиента при обратном распространении.
Сбор параметров прямого распространения завершается операцией сбора всех данных, а сложность связи при сборе всех данных такая же, как и при сборе всех данных.
Градиентная синхронизация обратного распространения завершается операцией полного сокращения.,Поскольку параметры каждого графического процессора являются только исходными 1/G,Общий сетевой трафик в эпоху составляет всего 1/Г обычного параллелизма данных.
2. Тензорный параллелизм.
При тензорном параллелизме параметры модели распределяются по графическим процессорам G, и каждый графический процессор хранит только параметры 1/G. Сетевой трафик в основном поступает из передачи промежуточных значений активации в процессе прямого распространения и синхронизации градиента в процессе обратного распространения.
При прямом распространении промежуточные значения активации, рассчитанные каждым графическим процессором, необходимо объединить и суммировать с помощью операции всесокращения. Для каждого токена на каждом уровне модели выполняется 2 слияния, в результате чего в общей сложности получается связь 2xTxL.
При обратном распространении градиенты необходимо синхронизировать между графическими процессорами. Это происходит дважды при обработке каждого слоя, и градиенты на каждом графическом процессоре суммируются с помощью операции полного сокращения. Эта синхронизация происходит во время обработки каждого слоя в каждом мини-пакете. Всего 2×N×L коммуникаций.
3. Параллелизм конвейеров
существовать Параллелизм трубопроводов, сетевой трафик в основном возникает за счет передачи промежуточных значений активации в процессах прямого и обратного распространения. с тензорным параллелизмдругой,Передача этих потоков происходит между двумя этапами модели,Используйте двухточечную связь вместо операций полного сокращения.,И частота тоже сильно снижается.
Подводить итоги,Тремя параллельными способами,тензорный параллелизм имеет самый большой поток и самую высокую частоту сети, Параллелизм. трубопроводов имеет самый низкий трафик,параллелизм данных имеет самую низкую частоту общения. Как показано в таблице ниже,P — параметр модели,T — количество токенов,L — количество слоев модели.,H — размер скрытого состояния,G — количество графических процессоров,N — количество мини-пакетов,Использование формата данных BFLOAT16.,Каждый параметр занимает 2 байта。существоватькаждыйepochв процессе:
схема движения | Общий сетевой трафик обратного распространения ошибки | Время синхронизации обратного распространения | Общий сетевой трафик прямой обработки | Количество проходов прямого процесса | |
|---|---|---|---|---|---|
параллелизм данных | all-reduce | 2 × N × P × G × (G-1) | 1 | 0 | 0 |
FSDP | all-gather + all-reduce | 2 × N × P × (G-1) | L | 2 × N × P × (G-1) | L |
тензорный параллелизм | all-reduce | 4 × N × P × L × (G-1) | 2 × L | 4 × L × T × H × (G-1) × G | 2 × L × T |
Параллелизм трубопроводов | Point-to-point | 2 × T × H × (G-1) | G-1 | 2 × T × H × (G-1) | G-1 |
Возьмите Ламу3 с 80 слоями (L). Модель 70B (P) и набор данных C4 являются примерами расчетов: используется формат данных BFLOAT16, каждый параметр занимает 2 байта, размер скрытого слоя установлен на 8192 (H), а для параллелизма используются 8 графических процессоров (G). данные. Общее количество токенов (T) в наборе данных C4 составляет около 156B, а количество выборок — 364,6. millions;batch Если размер равен 2048, каждая эпоха содержит примерно 178 000 мини-пакетов (N).
Расчет можно получить в течение каждой эпохи:
Общий сетевой трафик обратного распространения ошибки (ПБ) | Время синхронизации обратного распространения | Общий сетевой трафик прямой обработки(PB) | Общий сетевой трафик прямой обработки | |
|---|---|---|---|---|
параллелизм данных | 1396 PB | 1 | 0 | 0 |
FSDP | 175 | 80 | 175 | 80 |
тензорный параллелизм | 26622 | 160 | 21840 | 160*156*10^9 |
Параллелизм трубопроводов | 17.9 | 7 | 17.9 | 7 |
Сетевой трафик по технологии параллельного 3D
Три метода параллелизма данных, тензорного параллелизма и параллелизма трубопроводов обычно используются в сочетании.,Это может еще больше повысить эффективность и масштабируемость при обучении больших моделей. В это время,Графический процессор также формирует кластер графических процессоров в соответствии с этими тремя измерениями.
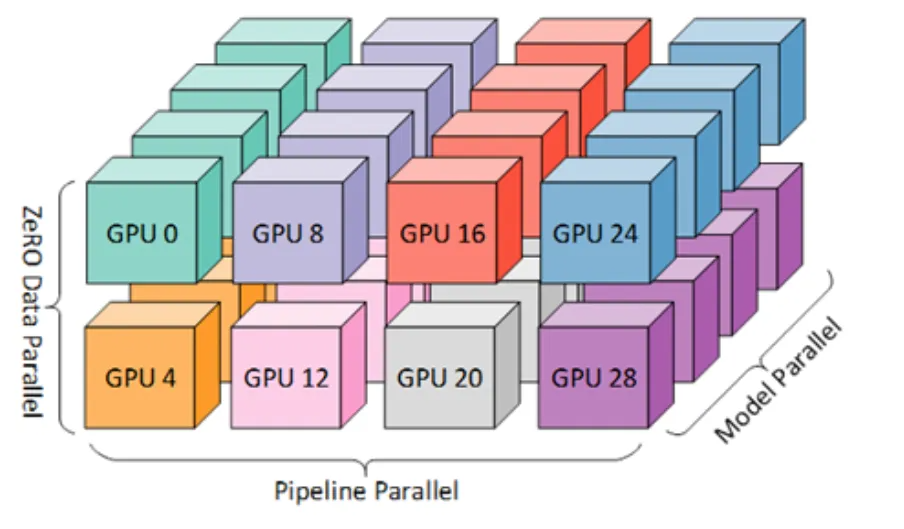
Предположим, что существуют G(tp)×G(pp)×G(dp) В параллельном трехмерном массиве, состоящем из графических процессоров, все параметры P будут разделены на части G(tp)×G(pp), а размер каждой части равен P/G(tp)/G(pp). В модельном параллелизме, Параллелизм трубопроводовипараллелизм сетевой трафик существует в трёх измерениях данных. Далее мы углубимся в процесс обучения каждой эпохи и рассчитаем состав и масштаб трафика на разных этапах.
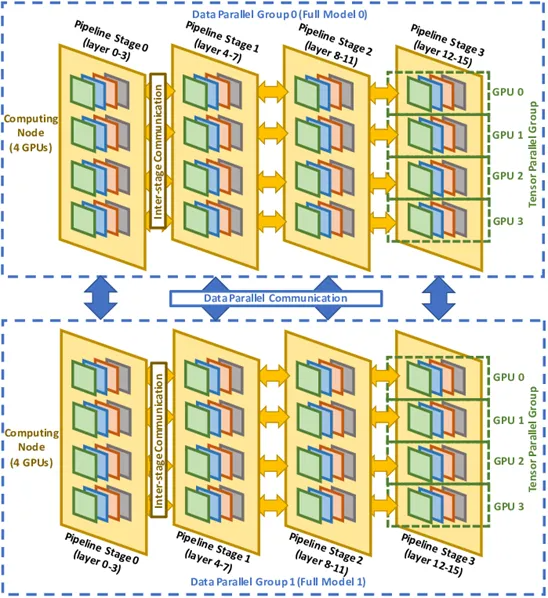
1. Сетевой трафик при обратном распространении ошибки
В каждом мини-пакете синхронизация градиента при обратном распространении делится на:
- Синхронизация градиента в тензорном измерении выполняется в каждом слое модели и каждой группе измерений данных всего за LxG(dp) раз, каждая из которых включает две операции полного сокращения.
- Градиентная синхронизация в измерении данных выполняется на каждом этапе конвейерного измерения и в каждой группе тензорного измерения всего G(tp)xG(pp) раз, каждое из которых включает 1 операцию полного сокращения.
Как показано ниже:
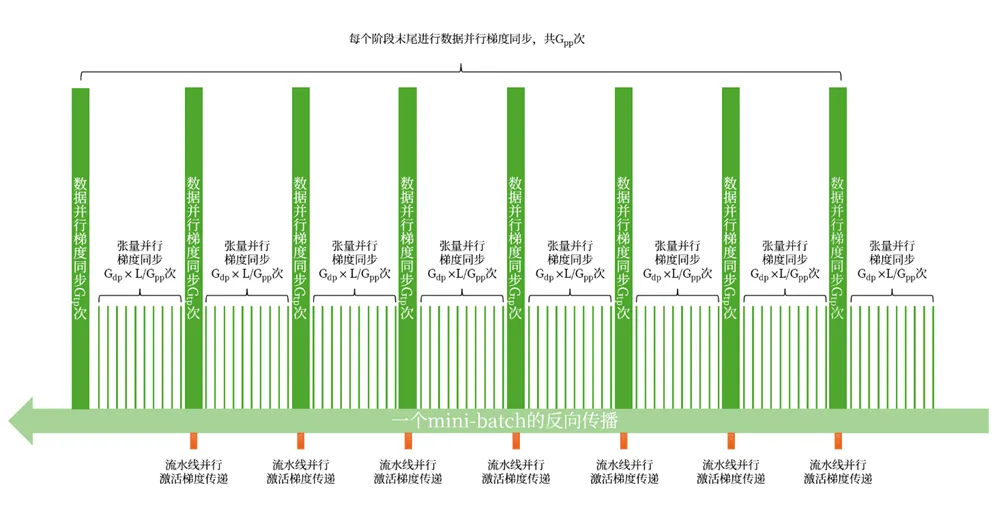
Таким образом, за одну эпоху общий сетевой трафик градиентной синхронизации составит: Впп+(ВВП-1)]
3. Распространение градиента промежуточной активации в измерении Параллелизм трубопроводов, расход: 2xTxHx (Gpp-1)
Следовательно, за одну эпоху общий трафик всего обратного распространения ошибки равен: 2xNxPxGdpx[2xLx(Gtp-1)/Gpp+(Gdp-1)]+2xTxHx(Gpp-1)
2. Сетевой трафик при прямом распространении
При прямом распространении промежуточные активации передаются последовательно в тензорном порядке. параллелизм、Параллелизм трубопроводов чередуются по размерностям, где тензорный Шаг активации параллелизма каждый раз содержит 2 операции все-сокращения.
Как показано на рисунке ниже, показано прямое распространение токена:
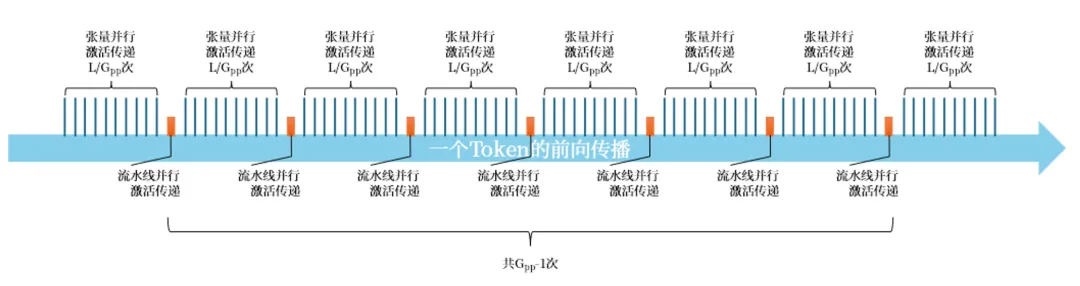
Следовательно, за одну эпоху общий сетевой трафик прямого распространения равен: 4xTxHxLxPxGtpx(Gtp-1)+2xTxHx(Gpp-1).
Прямо сейчас:2xTxHx(2xLxGtpx(Gtp-1)+(Gpp-1)
таким образом,В качестве примера возьмем модель Llama3-70B.,использовать8дорогатензорный параллелизм x 8дорога Параллелизм трубопроводов x 16дорогапараллелизм данныхрежим,Обучено на 1024 графических процессорах.,Общий трафик, генерируемый одной эпохой, составляет примерно 85EB. Такой огромный масштаб трафика,Если вы используете переключатель с коммутационной способностью 51,2Т,24 часа работы при полной нагрузке,Для завершения перевода потребуется около 20 дней.
Учитывая, что предобучение обычно содержит около 100 эпох, если обучение необходимо пройти за 100 дней, то для передачи данных, сгенерированных в процессе обучения, потребуется не менее 20 коммутаторов 51.2T.
Требования к обучению искусственному интеллекту для сети интеллектуальных вычислительных центров
Благодаря приведенному выше анализу и расчетам мы можем получить основные требования к типичному вычислительному центру ИИ для вычислительной сети.
- Сверхвысокая пропускная способность: за одну эпоху будет генерироваться 85 ЭБ данных, что эквивалентно 2,5 дням трафика во всем Интернете.
- Сверхнизкая задержка: обработка одной обучающей выборки генерирует более 100 ГБ данных, и их необходимо передать менее чем за 1 миллисекунду. Эквивалент скорости передачи 1000 интерфейсов 800G.
- Коллекционная связь: операции All-Reduce и All-Gater между серверами GPU обеспечивают широковещательный трафик, который синхронизируется между десятками тысяч GPU, то есть сотнями миллионов пар GPU-GPU.
- Нулевая терпимость к потере пакетов: согласно принципу ствола, во время процесса коллективной связи сама потеря пакетов и повторная передача трафика между парой графических процессоров также вызывают задержку всей коллективной связи, что приводит к входу большого количества графических процессоров. время простоя ожидания.
- Строгая синхронизация времени: также на основе принципа ствола: если часы графического процессора не синхронизированы, один и тот же объем вычислений займет разное время, и графическому процессору с быстрыми вычислениями придется ждать графический процессор с медленными вычислениями.
Подпишитесь на общедоступную учетную запись vx «Asterfusion», чтобы получать больше информации о технологиях и последних обновлениях продуктов.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
