Выбор модели внедрения, которая лучше всего соответствует вашим данным: сравнительный тест OpenAI и многоязычных внедрений с открытым исходным кодом
OpenAIнедавно выложил ихиз Встроенное новое поколение Модельembedding v3,Они описывают ее как самую эффективную встраиваемую модель.,Имеет более высокую производительность на нескольких языках. Эти модели разделены на две категории: меньшие называются text-embeddings-3-маленький, большие и высокие называются text-embeddings-3-large.
О том, как разрабатываются и обучаются эти модели, раскрывается мало информации, а доступ к моделям возможен только через платные API. Итак, существует множество моделей внедрения с открытым исходным кодом. Но как эти модели с открытым исходным кодом соотносятся с моделью с закрытым исходным кодом OpenAI?
В этой статье эмпирически сравнивается производительность этих новых моделей с моделями с открытым исходным кодом. Мы создадим рабочий процесс поиска данных, в котором наиболее релевантные документы в корпусе должны быть найдены на основе запроса пользователя.
Нашим корпусом является Европейский закон об искусственном интеллекте, который в настоящее время находится на завершающей стадии утверждения. Помимо того, что этот корпус является первой в мире нормативно-правовой базой по искусственному интеллекту, он также имеет важную особенность: он доступен на 24 языках. Таким образом, мы можем сравнить точность поиска данных на разных языках.
Мы сгенерируем индивидуальный набор синтетических вопросов/ответов на основе многоязычного текстового корпуса данных.,Сравните OpenAI и современную точность в этом специальном наборе. Полный код будет предоставлен в конце.,Потому что метод из, использованный в этой статье, можно применить и к другим корпусам данных.
Создание пользовательских наборов данных вопросов и ответов
Давайте сначала начнем с создания набора данных вопросов и ответов (Q/A) с настраиваемыми данными. Преимущество создания настраиваемого набора данных заключается в том, чтобы избежать предвзятости, гарантируя, что набор данных не является частью обучения модели внедрения, что может произойти по ссылке. такие тесты, как MTEB. И мы можем адаптировать оценку к конкретному массиву данных, который может иметь отношение к таким ситуациям, как приложения для расширения поиска (RAG).
Мы будем использовать простой процесс, предложенный Llama Index в его документации. Корпус сначала делится на части. Затем для каждого фрагмента с помощью большой языковой модели (LLM) генерируется набор синтетических вопросов, так что ответы лежат в соответствующем фрагменте:
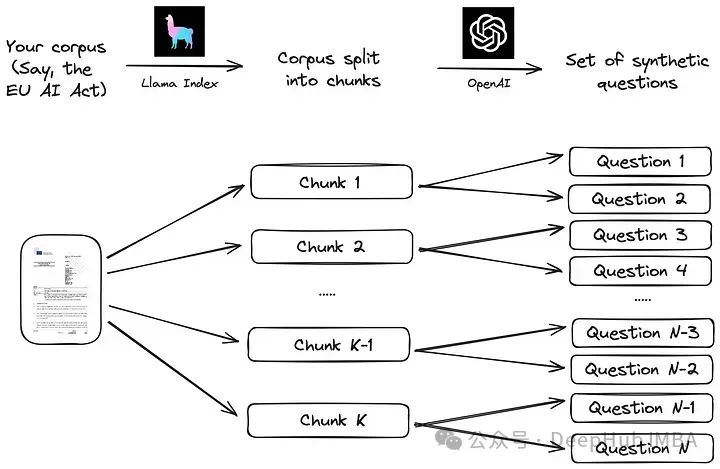
Реализация этой стратегии с использованием фрейма данных LLM, такого как Llama Index, очень проста, как показано в коде ниже.
from llama_index.readers.web import SimpleWebPageReader
from llama_index.core.node_parser import SentenceSplitter
language = "EN"
url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206"
documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc])
parser = SentenceSplitter(chunk_size=1000)
nodes = parser.get_nodes_from_documents(documents, show_progress=True)Корпус представляет собой английскую версию Закона ЕС об искусственном интеллекте, полученную непосредственно из Интернета по этому официальному URL-адресу. В этой статье используется черновая версия от апреля 2021 года, поскольку окончательная версия пока доступна не на всех европейских языках. Таким образом, выбранная нами версия может заменять язык в URL-адресе на любой из других 23 официальных языков ЕС, получая текст на разных языках (BG для болгарского, ES для испанского, CS для чешского и т. д.).

Используйте объект SentenceSplitter, чтобы разделить документ на фрагменты по 1000 токенов каждый. Для английского языка это генерирует около 100 фрагментов. Затем каждый блок предоставляется в качестве контекста для следующего приглашения (подсказка по умолчанию, предлагаемая в библиотеке Llama Index):
prompts={}
prompts["EN"] = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, generate only questions based on the below query.
You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination.
The questions should be diverse in nature across the document. Restrict the questions to the context information provided."
"""Это приглашение может генерировать вопросы о фрагментах документации. Количество вопросов, которые должны быть сгенерированы для каждого фрагмента, передается как параметр «num_questions_per_chunk», для которого мы установили значение 2. Затем вопросы можно сгенерировать, вызвав функциюgenerate_qa_embedding_pairs в библиотеке Llama Index:
from llama_index.llms import OpenAI
from llama_index.legacy.finetuning import generate_qa_embedding_pairs
qa_dataset = generate_qa_embedding_pairs(
llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),
nodes=nodes,
qa_generate_prompt_tmpl = prompts[language],
num_questions_per_chunk=2
)Для этой задачи мы полагаемся на OpenAI GPT-3.5-turbo-0125, и результирующий объект qa_dataset содержит пары вопросов и ответов (фрагменты). В качестве примера сгенерированного вопроса, вот результаты для первых двух вопросов (где «ответ» — это первая часть текста):
- What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
- How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
Модель внедрения OpenAI
Функция оценки также соответствует документации Llama Index: сначала вложения всех ответов (фрагменты документов) сохраняются в VectorStoreIndex для эффективного поиска. Затем функция оценки проходит через все запросы, извлекает k самых похожих документов и оценивает точность поиска на основе MRR (среднего взаимного ранга). Код выглядит следующим образом:
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):
# Get corpus, queries, and relevant documents from the qa_dataset object
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
# Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddings
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(
nodes, embed_model=embed_model, insert_batch_size=insert_batch_size
)
retriever = index.as_retriever(similarity_top_k=top_k)
# Prepare to collect evaluation results
eval_results = []
# Iterate over each query in the dataset to evaluate retrieval performance
for query_id, query in tqdm(queries.items()):
# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documents
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
# Check if the expected document was among the retrieved documents
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query
# Calculate the Mean Reciprocal Rank (MRR) and append to results
if is_hit:
rank = retrieved_ids.index(expected_id) + 1
mrr = 1 / rank
else:
mrr = 0
eval_results.append(mrr)
# Return the average MRR across all queries as the final evaluation metric
return np.average(eval_results)Модель внедрения передается в функцию оценки через параметр embed_model, который для моделей OpenAI представляет собой объект OpenAIEmbedding, инициализированный именем модели и ее размерами.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
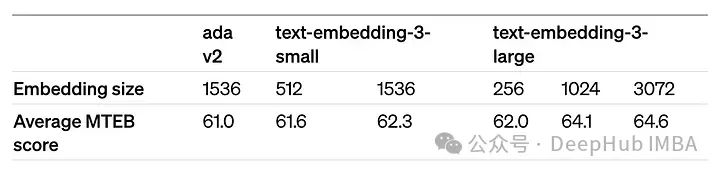
dimensions=model_spec['dimensions'])Параметр Dimensions позволяет сократить вложение (т. е. удалить некоторые числа из конца последовательности) без потери свойств концептуального представления вложения. OpenAI в своем объявлении предполагает, что встраивания можно сократить до размера 256, при этом превосходя по производительности несокращенное встраивание text-embedding-ada-002 (размер 1536) в тесте MTEB.
Мы запускаем функцию оценки на четырех различных моделях внедрения:
Две версии text-embedding-3-large: одна с минимально возможным размером (256), а другая с максимально возможным размером (3072). Они называются «ОАИ-большой-256» и «ОАИ-большой-3072».
OAI-small: text-embedding-3-small, размерность — 1536.
OAI-ada-002: Традиционное встраивание текста text-embedding-ada-002, размерность — 1536.
Каждая модель оценивается на четырех разных языках: английском (EN), французском (FR), чешском (CS) и венгерском (HU), охватывая примеры из германских, романских, славянских и уральских языков соответственно.
embeddings_model_spec = {
}
embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256}
embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072}
embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536}
embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
# Get model
embed_model = OpenAIEmbedding(model=model_spec['model_name'],
dimensions=model_spec['dimensions'])
# Assess embedding score (in terms of MRR)
score = evaluate(qa_dataset, embed_model)
results.append([language, model_name, score])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])Точность MRR следующая:
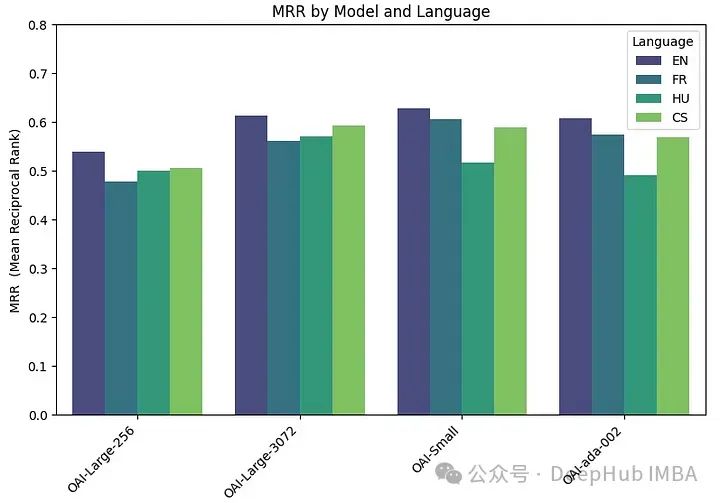
Чем больше встроенный размер, тем выше производительность.
Модель внедрения с открытым исходным кодом
Исследования открытого исходного кода в области встраивания также очень активны, и в таблице лидеров MTEB Hugging Face часто публикуются новейшие модели встраивания.
Для сравнения в этой статье мы выбираем набор из четырех недавно опубликованных моделей встраивания (2024 г.). Критериями отбора были средний балл в рейтинге MTEB и способность обрабатывать многоязычные данные. Ниже приведены основные характеристики выбранных моделей.

e5-mistral-7b-instruct: Эта модель внедрения E5 от Microsoft инициализируется из Mistral-7B-v0.1 и точно настроена на многоязычном смешанном наборе данных. Модель показывает лучшие результаты в рейтинге MTEB, но также является и самой большой (14 ГБ).
multilingual-e5-large-instruct (ML-E5-large): еще одна модель E5 от Microsoft, которая лучше обрабатывает многоязычные данные. Он инициализируется из xlm-roberta-large и обучается на нескольких многоязычных наборах данных. Он намного меньше, чем E5-Mistral (10x), а размер контекста намного меньше (514).
BGE-M3: Эта модель была разработана Пекинским научно-исследовательским институтом искусственного интеллекта и является их самой совершенной моделью многоязычного внедрения данных, поддерживающей более 100 рабочих языков. По состоянию на 22 февраля 2024 года не вошел в рейтинг MTEB.
nomic-embed-text-v1 (Nomic-embed): эта модель, разработанная Nomic, превосходит OpenAI Ada-002 и text-embedding-3-small и имеет размер всего 0,55 ГБ. Эта модель является первой полностью воспроизводимой и проверяемой (открытые данные и обучающий код с открытым исходным кодом).
Код, используемый для оценки этих моделей с открытым исходным кодом, аналогичен коду, используемому для моделей OpenAI. Основные изменения заключаются в параметрах модели:
embeddings_model_spec = {
}
embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token',
'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}}
embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}}
results = []
languages = ["EN", "FR", "CS", "HU"]
# Loop through all models
for model_name, model_spec in embeddings_model_spec.items():
print("Processing model : "+str(model_spec))
# Get model
tokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])
embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs'])
if model_name=="Nomic-Embed":
embed_model.to('cuda')
# Loop through all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
start_time_assessment=time.time()
# Assess embedding score (in terms of hit rate at k=5)
score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type'])
# Get duration of score assessment
duration_assessment = time.time()-start_time_assessment
results.append([language, model_name, score, duration_assessment])
df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])Результаты следующие:
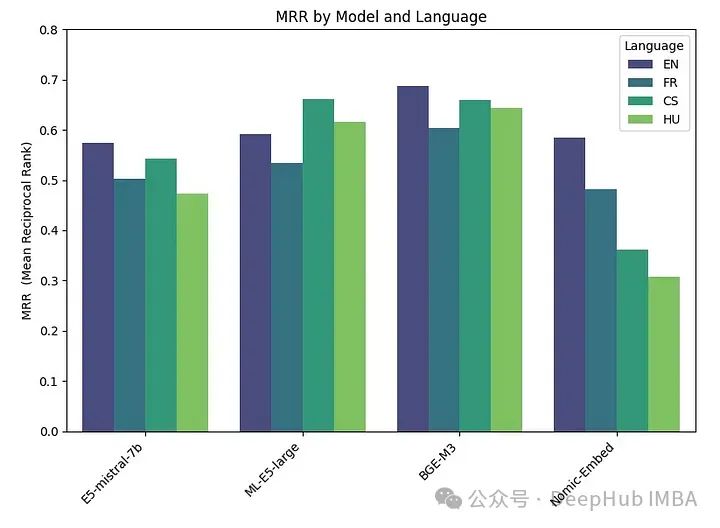
Лучше всего показал себя BGE-M3, за ним следуют ML-E5-Large, E5-mistral-7b и Nomic-Embed. Модель BGE-M3 еще не оценивалась в рейтинге MTEB, и наши результаты показывают, что она может занять более высокое место, чем другие модели. Хотя BGE-M3 оптимизирован для многоязычных данных, он также лучше работает на английском языке, чем другие модели.
Поскольку модели с открытым исходным кодом обычно необходимо запускать локально, мы также намеренно записывали время обработки каждой встроенной модели.
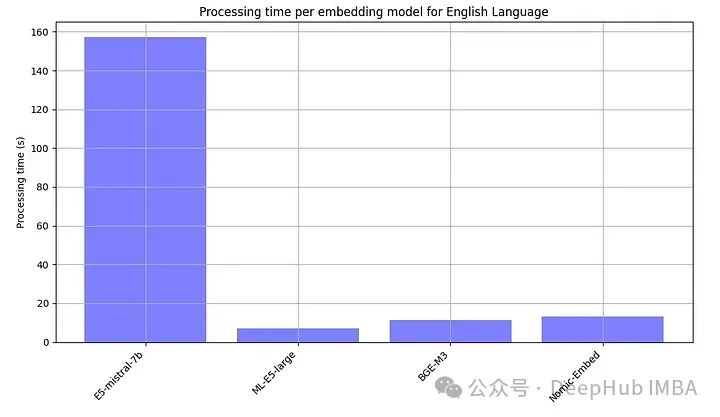
Е5-мистраль-7б более чем в 10 раз больше других моделей, поэтому быть самым медленным — это нормально
Подвести итог
Подведем все итоги
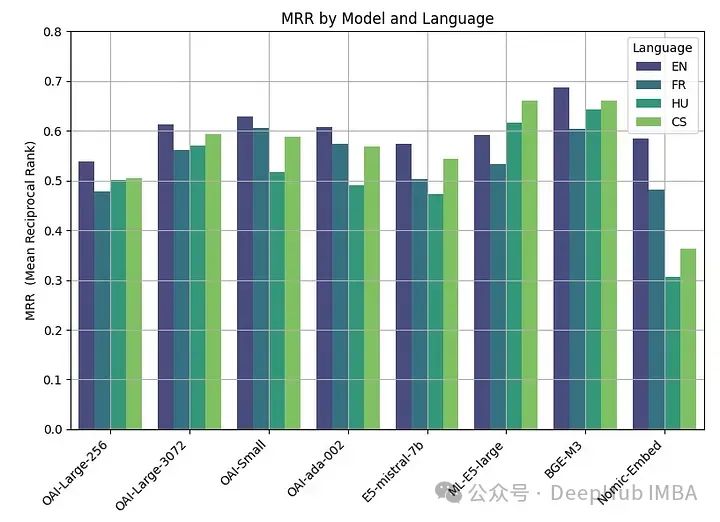
Наилучшая производительность была получена при использовании моделей с открытым исходным кодом, при этом модель BGE-M3 показала лучшие результаты. Эта модель имеет ту же длину контекста (8 КБ), что и модель OpenAI, и имеет размер 2,2 ГБ.
Производительность больших (3072), малых и ada моделей OpenAI очень схожа. Уменьшение размера встраивания big (256) приводит к снижению производительности и не так хорошо, как говорит OpenAI.
Почти все модели (кроме ML-E5-large) лучше всего работают на английском языке. В таких языках, как чешский и венгерский, существуют существенные различия в производительности, возможно, из-за меньшего количества данных для обучения.
Должны ли мы платить за подписку на OpenAI или разместить свою собственную?
Недавняя корректировка цен OpenAI делает их API более доступным,Стоимость миллиона токенов теперь составляет 0,13 доллара США. Если вы обрабатываете миллион запросов в месяц (при условии, что каждый запрос включает около 1 тыс. токенов),Не так, стоимость составляет около 130 долларов. Таким образом, вы можете выбрать, будет ли размещаться Модель развития с открытым исходным кодом, исходя из реальных потребностей.
Конечно, экономическая эффективность – не единственный критерий. Возможно, необходимо учитывать и другие факторы, такие как задержка, конфиденциальность и контроль над рабочими процессами обработки данных. Модель с открытым исходным кодом предлагает преимущества полного контроля данных, повышенной конфиденциальности и настройки.
Говоря о задержке, API OpenAI также имеет проблемы с задержкой, что иногда приводит к увеличению времени отклика, поэтому иногда API OpenAI не обязательно является самым быстрым вариантом.
Подводя итог, выбор между моделями с открытым исходным кодом и проприетарными решениями, такими как OpenAI, — непростая задача. Встраивание с открытым исходным кодом предлагает отличный вариант, который сочетает в себе производительность и больший контроль над вашими данными. И продукты OpenAI по-прежнему могут понравиться тем, кто отдает предпочтение удобству, особенно если вопросы конфиденциальности являются второстепенными.
Код для этой статьи: https://github.com/Yannael/multilingual-embeddings.
Автор: Янн-Аэль Ле Борнь



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
