Вводный практический курс по тонкой настройке большой модели GLM4 (полный код)
GLM4Это большая языковая модель, исходный код которой недавно был открыт командой Tsinghua Wisdom Team.。
Использование GLM4 в качестве базовой модели,проходитьИнструкция по тонкой настройкеСпособы высокоточной классификации текста,Это обучениеТочная настройка LLMвводные задания。

Требования к видеопамяти относительно высокие, около 40 ГБ.
В этой статье мы будем использовать GLM4-9b-Chat модель в Фуданьские китайские новости Выполните инструкцию по набору данных по тонкой настройкетренироваться,Используйте одновременноSwanLabКонтролируйте тренировочный процесс、Оцените производительность модели.
- код: Полный код можно найти в разделе 5 этой статьи. или Github、Jupyter Notebook
- Процесс журнала эксперимента:GLM4-Fintune - SwanLab
- Модель:Modelscope
- Набор данных:zh_cls_fudan_news
- SwanLab:https://swanlab.cn
Похожие статьи:Qwen2Инструкция по тонкой настройке
Пункт знаний: Что такое точная настройка инструкций?
Инструкция по доводке большой модели (Инструкция Tuning)Это своего рода масштабная подготовка к производству.тренироватьсяязык Модельтехнология тонкой настройки,Его основная цель – повыситьМодель понимает и выполняет определенные инструкции.способность,Позвольте модели точно и правильно генерировать соответствующие выходные данные и выполнять связанные задачи на основе инструкций на естественном языке, предоставленных пользователем.
Инструкция по тонкой настройкеособенныйсосредоточиться на улучшение модели Следуйте инструкциям последовательно и точно, тем самым расширяя модель Способность к обобщению и практичность в различных сценариях применения.
в практическом применении,Насколько я понимаю,Инструкция по тонкой настройке Еще горсткиLLMрассматривается как одинБолее разумная и мощная традиционная модель НЛП (например, Берта),осознатьЗадачи прогнозирования текста с более высокой точностью。Таким образом, сценарии применения этого типа задач охватывают прошлое.NLPМодельсцена,Многие команды даже используют егоМаркировка интернет-данных。
Вот настоящее боевое видео:
1. Установка среды
Этот случай основан наPython>=3.8,Пожалуйста, установите Python на свой компьютер,И есть видеокарта NVIDIA (требования к памяти не высокие),Он может работать примерно с 10 ГБ).
Нам необходимо установить следующие библиотеки Python. Прежде чем сделать это, убедитесь, что в вашей среде установлены pytorch и CUDA:
swanlab
modelscope
transformers
datasets
peft
accelerate
pandas
tiktokenКоманда установки в один клик:
pip install swanlab modelscope transformers datasets peft pandas accelerate tiktokenЭтот случай был протестирован на modelscope==1.14.0, Transformers==4.41.2, datasets==2.18.0, peft==0.11.1, ускорение==0.30.1, Swanlab==0.3.10, tiktokn== 0,7 ,0,Более подробную информацию об окружающей среде можно просмотретьздесь
2. Подготовьте набор данных
В этом случае используетсяzh_cls_fudan-newsНабор данных,Этот набор данных в основном используется для обучения моделей классификации текста.
zh_cls_fudan-news состоит из тысяч фрагментов данных, каждый фрагмент данных содержит три столбца: текст, категория и вывод:
- текст — это обучающий корпус,Контент — это текстовое содержание книг и новостей.
- категория — это список нескольких альтернативных типов текста
- вывод — единственный реальный тип текста

Пример набора данных выглядит следующим образом:
"""
[PROMPT]Text: Завершились полуфиналы 4-го Национального футбольного турнира крупных предприятий: 4 победили команду Чэндуского металлургического экспериментального завода и вошли в четверку лучших. В битве между Шанхаем и Чэнду обе стороны были равны, без победителей и проигравших в течение 90 минут. В итоге стороны обменялись пенальти, и шанхайская команда победила с преимуществом в один гол. В трех других играх полуфинала команда Цинхайского Шаньчуаньского станколитейного завода одержала победу над командой хозяев Лоянского горно-машинного завода со счетом 3:0, команда Циндаоского литейного машиностроительного завода победила команду №3 Шицзячжуанского полиграфического и красильного завода: 1, а команда Уханьского мясного завода с небольшим перевесом победила команду Тяньцзиньского второго металлургического машиностроительного завода. В двух играх, проведенных сегодня для определения девятого-двенадцатого мест, команда Баотоуского завода стальных бесшовных стальных труб и команда шахты № 1 Хэнаньского горнодобывающего бюро Пиндиншань победили команду Хэнаньского завода нейлоновых кордных тканей Пиндиншань и команду завода общего радиооборудования Цзянсу Яньчэн соответственно. . 4-го числа пройдут два полуфинала, в которых команды Цинхайского станкостроительного завода Шаньчуань и команды Циндаоского литейного машиностроительного завода будут соревноваться с командой Уханьского мясного завода и командой Шанхайского машиностроительного завода Далун соответственно. Этот конкурс завершится 6-го числа. (над)
Category: Sports, Politics
Output:[OUTPUT]Sports
"""Наша задача обучения — надеяться, что точно настроенная большая модель сможет предсказать правильный результат на основе слов-подсказок, состоящих из текста и категории.
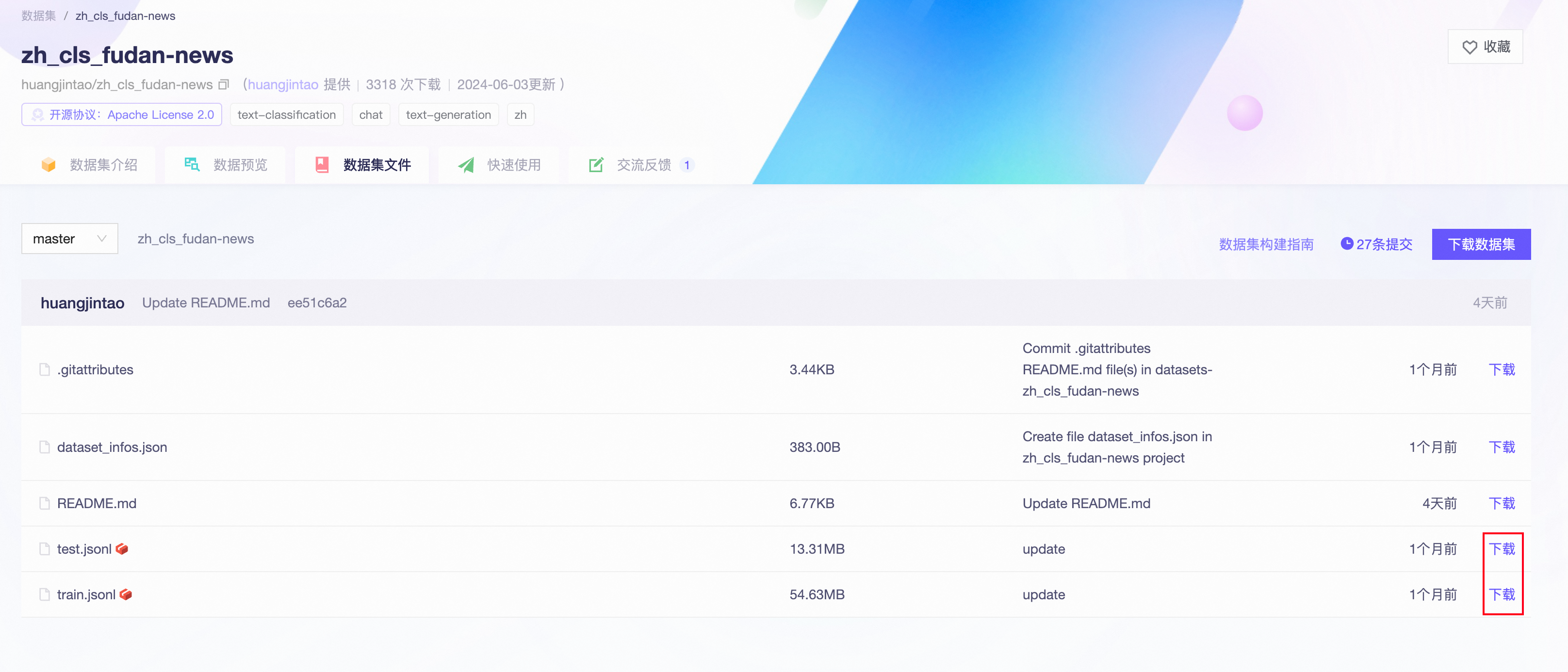
нас Воля Набор данных Загрузить в локальный каталог。Чтобы скачать, перейдите по ссылкеzh_cls_fudan-news - Магическое сообщество ,Воляtrain.jsonlиtest.jsonlЗагрузите его в локальный корневой каталог.:
3. Загрузите модель
Здесь мы используем modelscope для загрузки модели GLM4-9b-Chat (modelscope находится в Китае, поэтому за скорость и стабильность при загрузке можно не беспокоиться), а затем загружаем ее в Трансформеры для обучения:
from modelscope import snapshot_download, AutoTokenizer
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
# Загрузите модель GLM на modelscope в локальный каталог.
model_dir = snapshot_download("ZhipuAI/glm-4-9b-chat", cache_dir="./",revision="master")
# TransformersЗагрузить вес модели
токенизатор = AutoTokenizer.from_pretrained("./ZhipuAI/glm-4-9b-chat/", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./ZhipuAI/glm-4-9b-chat/", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)4. Настройте инструменты визуализации обучения.
Мы используем SwanLab для мониторинга всего процесса обучения и оценки конечного эффекта модели.
Это реализовано напрямую с помощью интеграции SwanLab и Transformers:
from swanlab.integration.huggingface import SwanLabCallback
swanlab_callback = SwanLabCallback(...)
trainer = Trainer(
...
callbacks=[swanlab_callback],
)Если вы используете SwanLab впервые,Тогда нам еще нужно идтиhttps://swanlab.cnЗарегистрируйте аккаунт на,существоватьПользовательские настройкистраницакопироватьтвойAPI Введите ключ и вставьте его, когда начнется обучение:
5. Полный код
Структура каталогов при начале обучения:
|--- train.py
|--- train.jsonl
|--- test.jsonltrain.py:
import json
import pandas as pd
import torch
from datasets import Dataset
from modelscope import snapshot_download, AutoTokenizer
from swanlab.integration.huggingface import SwanLabCallback
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
import os
import swanlab
def dataset_jsonl_transfer(origin_path, new_path):
"""
Преобразование исходного набора данных в новый набор данных в формате данных, необходимом для точной настройки большой модели.
"""
messages = []
# Чтение старых файлов JSONL
with open(origin_path, "r") as file:
for line in file:
# Анализируйте данные JSON каждой строки
data = json.loads(line)
context = data["text"]
catagory = data["category"]
label = data["output"]
message = {
"instruction": «Вы являетесь экспертом в области классификации текста. Вы получите текст и несколько возможных вариантов классификации. Пожалуйста, выведите правильный тип текстового контента»,
"input": f"Текст:{контекст},Выбор типа:{катагория}",
"output": label,
}
messages.append(message)
# Сохраните восстановленный файл JSONL.
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")
def process_func(example):
"""
Предварительная обработка набора данных
"""
MAX_LENGTH = 384
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|system|>\nВы эксперт в классификации текстов,Вы получите текст и несколько возможных вариантов классификации.,Пожалуйста, выведите правильный тип текстового контента<|endoftext|>\n<|user|>\n{example['input']}<|endoftext|>\n<|assistant|>\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = (
instruction["attention_mask"] + response["attention_mask"] + [1]
)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # сделать усечение
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
return response
# Загрузите модель GLM на modelscope в локальный каталог.
model_dir = snapshot_download("ZhipuAI/glm-4-9b-chat", cache_dir="./",revision="master")
# TransformersЗагрузить вес модели
токенизатор = AutoTokenizer.from_pretrained("./ZhipuAI/glm-4-9b-chat/", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./ZhipuAI/glm-4-9b-chat/", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
model.enable_input_require_grads() # Этот метод необходимо выполнять, когда включена контрольная точка градиента.
# Загрузка и обработка наборов данных и тестовых наборов
train_dataset_path = "train.jsonl"
test_dataset_path = "test.jsonl"
train_jsonl_new_path = "new_train.jsonl"
test_jsonl_new_path = "new_test.jsonl"
if not os.path.exists(train_jsonl_new_path):
dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)
if not os.path.exists(test_jsonl_new_path):
dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)
# Получить обучающий набор
train_df = pd.read_json(train_jsonl_new_path, lines=True)
train_ds = Dataset.from_pandas(train_df)
train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["query_key_value", "dense", "dense_h_to_4h", "activation_func", "dense_4h_to_h"],
inference_mode=False, # режим обучения
r=8, # Lora классифицировать
lora_alpha=32, # Lora алаф, информацию о конкретных функциях см. Lora принцип
lora_dropout=0.1, # Dropout Пропорция
)
model = get_peft_model(model, config)
args = TrainingArguments(
output_dir="./output/GLM4-9b",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=2,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="none",
)
swanlab_callback = SwanLabCallback(
project="GLM4-fintune",
experiment_name="GLM4-9B-Chat",
описание="Использовать модель GLM 4-9B-Chat Точная настройка набора данных вzh_cls_fudan-news. ",
config={
"model": "ZhipuAI/glm-4-9b-chat",
"dataset": "huangjintao/zh_cls_fudan-news",
},
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback],
)
trainer.train()
# Используйте первые 10 элементов тестового набора для проверки модели.
test_df = pd.read_json(test_jsonl_new_path, lines=True)[:10]
test_text_list = []
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
messages.append({"role": "assistant", "content": f"{response}"})
result_text = f"{messages[0]}\n\n{messages[1]}\n\n{messages[2]}"
test_text_list.append(swanlab.Text(result_text, caption=response))
swanlab.log({"Prediction": test_text_list})
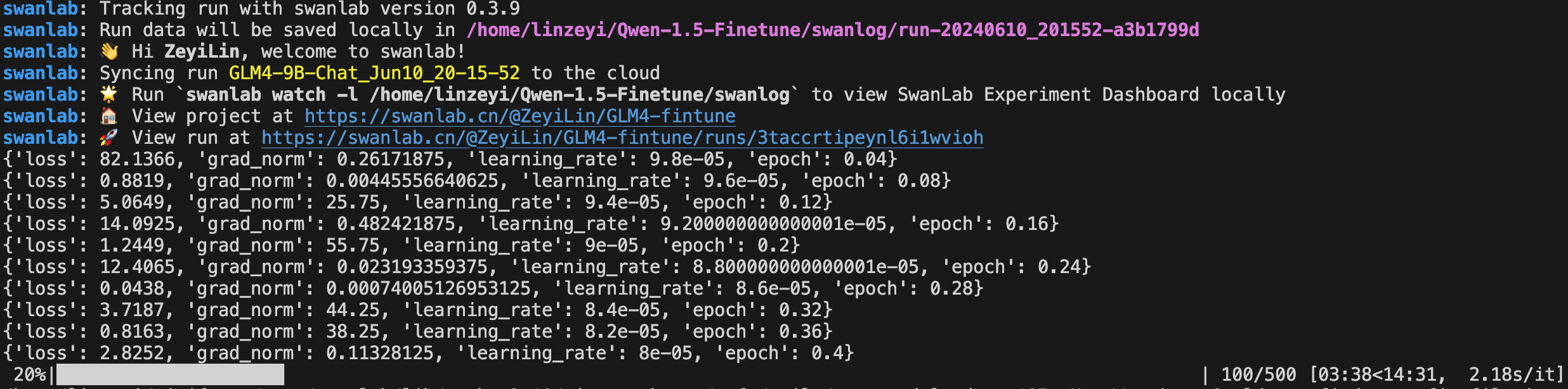
swanlab.finish()Вид индикатора выполнения ниже означает, что обучение началось. Потеря, grad_norm и другая информация будут распечатаны на определенном этапе:
6. Демонстрация результатов обучения
существоватьSwanLabПосмотреть финалтренироватьсярезультат:
Видно, что через 2 эпохи потери glm2 после тонкой настройки сократились до хорошего уровня — конечно, для больших моделей реальная оценка эффекта зависит от субъективного эффекта.
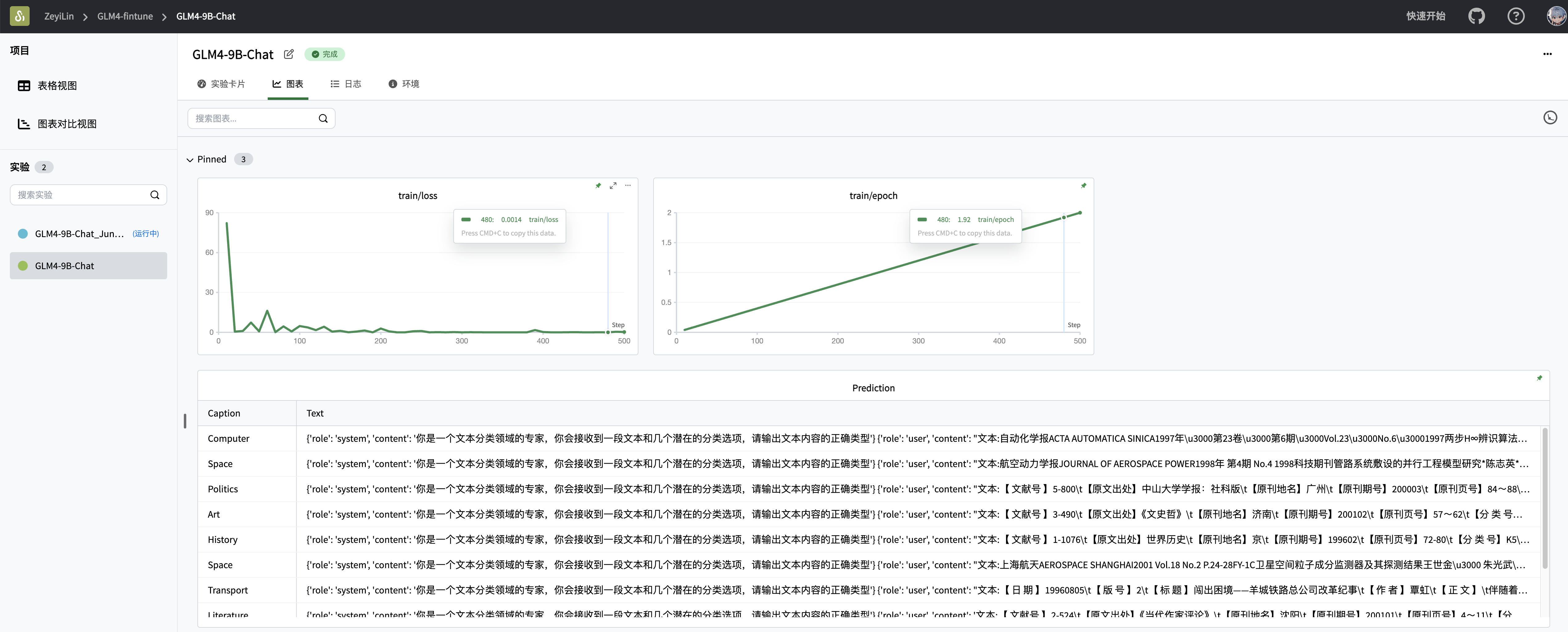
Видно, что на некоторых тестовых образцах доработанный glm2 может выдавать точные типы текста:
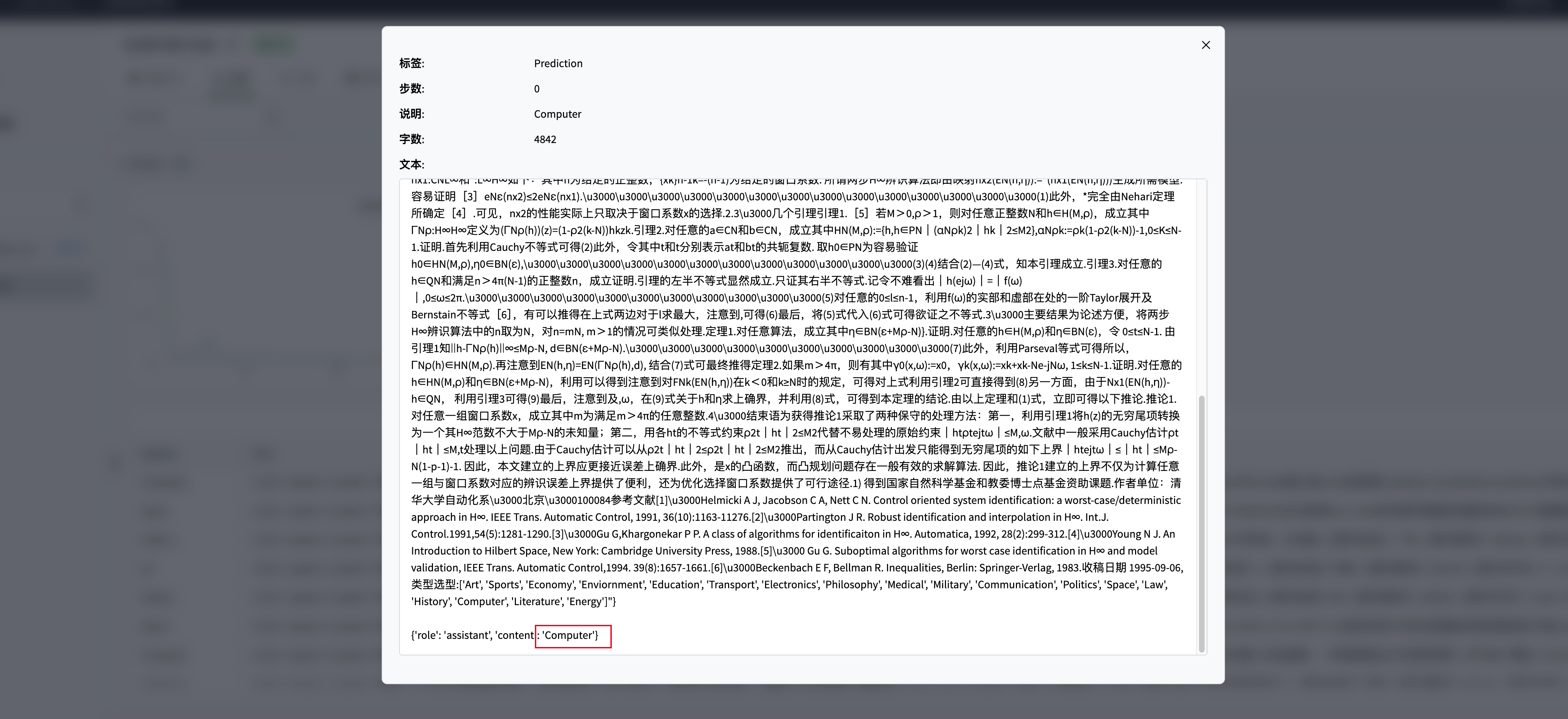
На этом этапе вы завершили обучение тонкой настройке инструкций GLM4!
Ссылки по теме
- код: Полный код можно найти в разделе 5 этой статьи.
- Процесс журнала эксперимента:GLM4-Fintune - SwanLab
- Модель:Modelscope
- Набор данных:zh_cls_fudan_news
- SwanLab:https://swanlab.cn



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
