Введение в распределенную базу данных HBase
Один、Простойпредставлять
HBase — это высоконадежная, высокопроизводительная, столбцово-ориентированная, масштабируемая, распределенная база данных NOSQL для чтения и записи в реальном времени.
Используйте Apache HBase, когда вам нужен произвольный доступ для чтения и записи к большим данным в режиме реального времени.
эффект:В основном используется для хранения неструктурированных、Полуструктурированные и структурированные из свободных данных (столбцовое хранилище из данных базы NoSQL)
Объяснение имени:
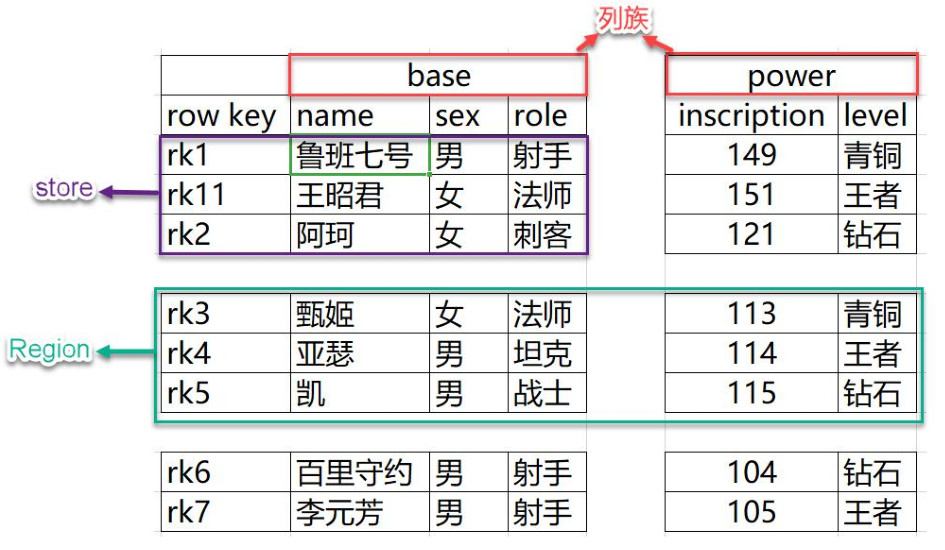
- NameSpace Пространство имен, эквивалентное реляционной базе данных В базе данных есть несколько таблиц в каждом пространстве имен. Hbase Пространство имен по умолчанию hbase и default;hbase хранится в HBase Встроенная таблица, по умолчанию Пространство имен, используемое пользователями по умолчанию.
- Region Таблицы аналогичны реляционным базам данных, за исключением того, что HBase Определение означает, что необходимо объявить только семейство столбцов и не нужно объявлять какие-либо конкретные столбцы. Столбцы можно указывать динамически по мере необходимости HBase; Больше подходит для сценариев, в которых поля часто меняются. Для начала создания таблицы одной таблице соответствует одна регион, когда таблица увеличится до определенного значения, она будет разделена на две части region。
- Row HBase Каждая строка данных в таблице называется ряд, состоит из RowKey Несколько Column Состав, данные основаны на RowKey хранятся в словарном порядке, а запросы могут основываться только на RowKey выполнить поиск, так что RowKey Дизайн имеет решающее значение.
- Column Столбцы состоят из семейств столбцов (Колонка Family) и квалификатор столбца (Column Классификатор), например: база: имя, база: пол. Это означает, что необходимо определить только семейство столбцов, а квалификатор столбца не нужно определять заранее.
- Cell Столбец в строке называется Ячейка (ячейка), состоящая из {rowkey, столбец Family:columnqualifier,timestamp} определяет единицу измерения. Клетка В нем нет определенного типа, все хранится в виде байт-кода (массива байтов).
- TimeStamp Используется для идентификации различных версий данных. При записи каждого фрагмента данных, если метка времени не указана, система автоматически добавит к нему это поле с записанным значением. HBase время.
2. Модель данных HBase
Логически модель данных HBase очень похожа на реляционную базу данных. Данные хранятся в таблице со строками и столбцами. Но с точки зрения базовой физической структуры хранения (ключ-значение) HBase больше похож на карту.
Логическая структура HBase следующая:
Физическая структура хранения HBase
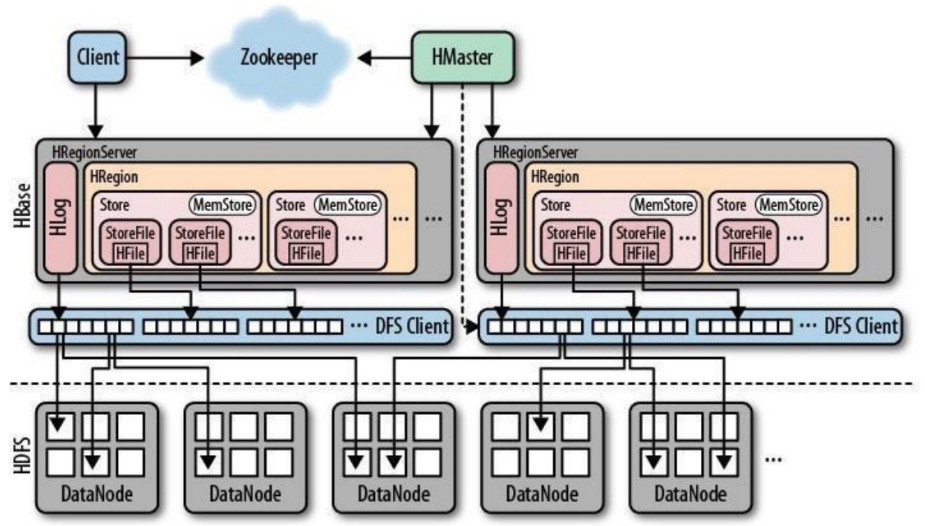
3. Архитектура HBase
- client
1) Содержит интерфейс для доступа к HBase для доступа к HBase 2) Клиент получает информацию о кластере HBase, запрашивая информацию в Zookeeper.
- zookeeper
1) Убедитесь, что в кластере всегда есть только один мастер. 2) Сохраните записи адресации всех регионов. 3) Отслеживайте онлайн- и оффлайн-информацию RegionServer в режиме реального времени и уведомляйте HMaster в режиме реального времени. 4) Сохраните схему HBase и метаданные таблицы.
- Master
1) Назначьте регион RegionServer 2) Отвечает за балансировку нагрузки RegionServer. 3) Обнаружьте неисправный RegionServer и перераспределите на нем регионы. 4) Управляйте операциями пользователей по добавлению, удалению и изменению таблиц.
- RegionServer
1) RegionServer поддерживает регионы и обрабатывает запросы ввода-вывода к этим регионам. 2) RegionServer отвечает за разделение Региона, который в процессе работы становится слишком большим.
- HLog(WAL Log)
1) Файл HLog — это обычный файл последовательности Hadoop. Ключ файла последовательности — это объект HLogKey. HLogKey записывает информацию о владельце записанных данных. Помимо имен таблиц и регионов, он также включает порядковый номер и. timestamp. Временная метка — «запись «Введите время», начальное значение порядкового номера — 0 или последний порядковый номер, сохраненный в файловой системе. 2) Значением HLog SequenceFile является объект KeyValue HBase, который соответствует KeyValue в HFile.
- Region
1) HBase автоматически делит таблицу на несколько регионов (регионов) по горизонтали. Каждый регион сохраняет в таблице определенный фрагмент непрерывных данных. Каждая таблица имеет только один регион в начале. Поскольку данные в таблицу непрерывно вставляются, это регион. продолжает расти, когда он достигнет порога, Регион будет разделен на два новых Региона (деление). 2) По мере увеличения строк в таблице Регионов будет все больше и больше. Такая полная таблица сохраняется на нескольких серверах региона.
- Memstore&StoreFile
1) Регион состоит из нескольких магазинов, и один магазин соответствует одному CF (семейству столбцов) 2) Store включает в себя memstore, расположенный в памяти, и storefile, расположенный на диске. Операция записи сначала записывается в Memstore. Когда данные в Memstore достигают определенного порога, HRegionserver запускает процесс flashcache для записи в файл хранилища. Каждая запись формирует отдельный файл хранилища. 3) StoreFile доступен только для чтения и не может быть изменен после создания. Таким образом, обновление Hbase на самом деле представляет собой непрерывную операцию добавления. Когда количество файлов Storefile в Магазине увеличивается до определенного порога, система объединяется (незначительное, крупное сжатие). В процессе слияния будет выполняться объединение и удаление версий (majar), а также будут вноситься изменения в один и тот же ключ. объединены вместе, образуя больший файл хранилища. 4) Когда сумма размеров всех файлов хранилища в регионе превышает определенный порог, текущий регион будет разделен на два и распределен hmaster на соответствующий сервер региона для достижения балансировки нагрузки. 5) Когда клиент получает данные, он сначала ищет их в хранилище памяти, а затем ищет файл хранилища, если не может его найти. 6) HRegion — наименьшая единица распределенного хранилища и балансировки нагрузки в HBase. Наименьшая единица означает, что разные HRegions могут быть распределены на разных серверах HRegionServer. 7) HRegion состоит из одного или нескольких магазинов, в каждом магазине хранится семейство столбцов. 8) Каждое хранилище состоит из memStore и от 0 до нескольких StoreFiles.
4. Процесс записи HBase
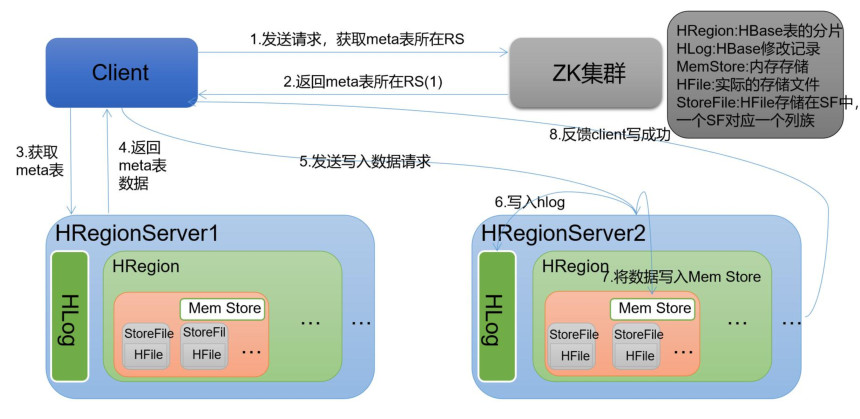
1. Клиент отправляет запрос на получение адреса HMaster и адреса RegionServer, где находится метатаблица, от Zookeeper, а также отправляет запрос на запись данных на HRegionServer.
2. Данные записываются в MemStore HRegion, а также в HLog.
3. Данные из MemStore сбрасываются в StoreFile.
4. Когда MemStore достигает порогового значения, данные сбрасываются в файл хранилища. Когда несколько файлов StoreFile достигают определенного размера, запускается операция компактного слияния. После сжатия постепенно формируется все больший и больший файл хранилища.
5. После того, как размер StoreFile превысит определенный порог, запускается операция разделения, которая разделяет текущий HRegion на 2 новых HRegion. Родительский HRegion будет отключен, а 2 дочерних HRegion из нового разделения будут выделены соответствующему HRegionServer. HMaster, чтобы исходное 1 Давление одного HRegion можно было распределить на два HRegion.
6. Если данные в MemStore утеряны, их можно восстановить из HLog.
5. Процесс чтения HBase
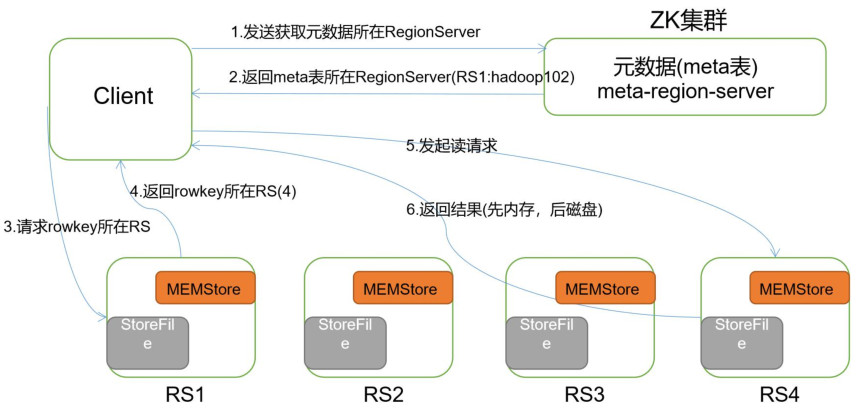
1. Клиент сначала находит местоположение региона метатаблицы у Zookeeper, а затем считывает данные в метатаблице. Мета хранит информацию о регионе пользовательской таблицы.
2. Найдите информацию о регионе, для которого записаны данные, согласно данным в метатаблице на основе пространства имен, имени таблицы и ключа строки.
3. Найдите соответствующий RegionServer, найдите соответствующий Region, сначала найдите данные из Memstore, а если нет, прочтите данные из StoreFile.
6. Мелкое и крупное слияние HBase
Когда клиент записывает данные в HBase, они сначала записываются в HLog и Memstore. В хранилище, когда память Memstore заполнена, данные будут записаны на диск для формирования нового файла хранения данных (StoreFile With the memstore). При перепрошивке будет создано множество файлов хранилища. Когда файлы хранилища в хранилище достигнут определенного порога, изменения одного и того же ключа будут объединены в один большой файл хранилища. Наконец, когда размер файла хранилища достигнет определенного порога. , файл хранилища будет разделен на два файла хранилища.
Поскольку обновления в таблицу постоянно добавляются, при слиянии вам необходимо получить доступ ко всем файлам хранилища и хранилищам памяти в хранилище и объединить их по ключам строк. Поскольку файлы хранилища и хранилища памяти сортируются, а файлы хранилища имеют индексы в памяти, процесс слияния. относительно быстро.
Поскольку файл хранилища не может быть изменен, HBase не может просто удалить данные, удалив определенный ключ/значение. Вместо этого он ставит метку удаления на удаленные данные, чтобы указать, что данные были удалены. Во время процесса извлечения метка удаления закрывается. данные, клиент не может прочитать данные.
По мере того как данные в memstore продолжают записываться на диск, будут создаваться все новые и новые файлы storeFile, HBase внутренне решает эту проблему с небольшими файлами, объединяя несколько файлов в один файл большего размера. следует:
незначительное слияние
Незначительное слияние отвечает за объединение нескольких файлов StoreFile в Магазине. Когда количество файлов StoreFile достигает значения hbase.hstore.compaction.min (значение по умолчанию — 3), они будут объединены в один большой файл StoreFile. При таком слиянии несколько небольших файлов в основном перезаписываются в меньшее количество больших файлов, чтобы уменьшить количество хранимых файлов. Поскольку каждый файл в StoreFile классифицируется, скорость слияния очень высокая и в основном зависит от производительности дискового ввода-вывода.
крупное слияние
Перезапишите несколько небольших объединенных больших файлов StoreFile кластера столбцов (соответствующего Store) в регионе в новый StoreFile. Более того, основное слияние может сканировать все пары ключ/значение и перезаписывать все данные последовательно. В процессе перезаписи данные, помеченные для удаления, будут пропущены.
7. Метатаблица целевой таблицы HBase
Таблица каталога hbase:meta существует как таблица HBase и отфильтровывается из команд списка оболочки hbase (аналогично показу таблиц), но на самом деле это таблица, подобная любой другой таблице.
Таблица hbase:meta (ранее .META.) содержит список всех регионов в системе. Информация о местоположении hbase:meta хранится в Zookeeper, hbase:meta представляет собой точку входа для всех запросов.
Структура таблицы следующая:
key:
регионизключ, структура следующая: [таблица],[регион start key,end key],[region id]
values:
info:regioninfo (сериализация текущего региона из экземпляра HRegionInfo)
info:server (содержит текущий регионизRegionServerизserver:port)
info:serverstartcode (содержит текущий регион, процесс RegionServer, время запуска)Во время разделения таблицы создаются два дополнительных столбца с именами info:splitA и info:splitB, которые представляют два дочерних региона, и значения этих столбцов также являются сериализованными экземплярами HRegionInfo. Эта строка будет удалена после разделения региона.
a,,endkey
a,startkey,endkey
a,startkey,Пустой ключ используется для обозначения начала и конца таблицы. Регион с нулевым начальным ключом является первым регионом в таблице. Если регион имеет как нулевой начальный, так и нулевой конечный ключ, это единственный регион в таблице.
8. Возможности HBase
- Строго согласованное чтение/запись HBase, а не «конечно согласованная» база данных (DataStore). Он идеально подходит для таких задач, как высокоскоростное агрегирование счетчиков.
- Автоматическое шардинг: HBase стол пройден region распределены по кластеру, и по мере роста данных регионы Будет автоматически разделен и перераспределен. Автоматический RegionServer Аварийное переключение.
- Интеграция Hadoop/HDFS: HBase поддерживает HDFS в качестве распределенной файловой системы.
- MapReduce:HBase поддержка через MapReduce Выполните массовую параллельную обработку для HBase Использовать в качестве источника данных и сохранять хранилище данных из базы данных.
- Java Client API: HBase поддерживает простой в использовании Java API для программного доступа.
- Thrift/REST API:HBase Также поддерживает не- Java внешний интерфейс Thrift и REST。
- Кэш блоков и фильтр Блума: HBase Поддержка блочного кэша и фильтров Блума для оптимизации запросов большого объема.
- Управление эксплуатацией и техническим обслуживанием: HBase Предоставляет встроенные веб-страницы для мониторинга эксплуатации и технического обслуживания. JMX индекс.
- HBase не поддерживает межстрочные транзакции.
9. Сценарии использования HBase
HBase подходит для сценариев, требующих обработки огромных объемов данных и требующих высокой надежности и производительности. Например:
- хранилище объектов:например, новости、веб-страница、Изображения и другие данные сохраняются.
- Портрет пользователя:особенно пользователиизизображение,Это относительно большая разреженная матрица.
- Хранение сообщений/заказов:в сфере телекоммуникаций、В банковской сфере многие запросы заказов требуют базового хранилища и связи.、Приложения синхронизации сообщений могут быть созданы на базе HBase.
В целом HBase — это высокопроизводительная, высоконадежная и масштабируемая распределенная база данных, которая подходит для обработки огромных объемов неструктурированных или структурированных данных и может отвечать требованиям управления чтением и записью практически в реальном времени.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
