Введение в обычную библиотеку Intel DPDK Hyperscan
Гиперскан это Intel изВысокопроизводительная библиотека сопоставления регулярных выражений,Доступно на x86 бегать на платформе и опорах Perl Совместимость с регулярными выражениями (PCRE) Синтаксис, одновременное сопоставление групп регулярных выражений и потоковые операции. это в BSD Выпущено как программное обеспечение с открытым исходным кодом по лицензии. Гиперскан обеспечивает гибкий C API и несколько различных режимов работы, чтобы гарантировать его применимость в реальных сетевых сценариях. Кроме того, особое внимание уделяется эффективным алгоритмам и технологиям Intel®. Streaming SIMD Расширения (Intel® Использование SSE) позволяет Hyperscan Возможность достижения высокого соответствияпроизводительность.Подходит для глубокой проверки пакетов (DPI), системы обнаружения вторжений (IDS), системы предотвращения вторжений (IPS), межсетевого экрана.и т. д. сценарии использования,Внедряется в глобальные решения в области кибербезопасности.。Hyperscan Также интегрирован в широко используемый открытый исходный код. IDS и IPS в таких продуктах, как Snort * иSuricata *。
под капотом
Рабочий процесс Hyperscan можно разделить на две части: время компиляции и время компиляции.
время компиляции
Hyperscan с C++ Написан компилятор регулярных выражений. Как показано на картинке 1 Как показано, в качестве входных данных принимается регулярное выражение. На основе доступного Intel® Функции архитектурной платформы, определяемая пользователем схема и функции схемы, Hyperscan Соответствующая база шаблонов создается посредством сложного анализа формы изображения и процесса оптимизации. данных。созданныйбаза данные также могут быть сериализованы и сохранены в памяти для последующего использования при разработке.
Узнайте больше об Intel Знания, связанные с dpdkиvpp, приветствуются нас:

картина1:Процесс компиляции гиперскана

картина 2:Hyperscan бегатьчас
бегать
Hyperscan пробег используется, когда C язык развит. картина 2 показывать Понятнобегатьчас主要组件извысокий级框картина。Вам нужно отсканироватьчас使用изВременная информация предварительно выделяется в рабочем пространстве, а затем скомпилированная база данных используется для вызова API сканирования Hyperscan для запуска внутреннего механизма сопоставления (недетерминированный конечный автомат (NFA), детерминированный конечный автомат (DFA) и т. д.). ) для соответствия корпусу。Hyperscan С помощью одной инструкции несколько данных предоставляются процессорами Intel. (SIMD) Инструкции ускоряют эти механизмы и передают совпадения пользовательскому приложению для обработки через предоставляемую пользователем функцию обратного вызова. потому что Hyperscan База данных схемы доступна только для чтения, и пользователи могут создавать несколько CPU Совместное использование базы данных между ядрами или несколькими потоками для повышения соответствующей масштабируемости.
особенность
Многофункциональный
Hyperscan Поддерживает несколько Intel Процессор кросс-компилируется со специальной оптимизацией для разных наборов команд. Он не имеет ограничений операционной системы и поддерживает сценарии как виртуальных машин, так и контейнеров, охватывая большинство PCRE грамматика,и поддерживает включение“.*”и“[^>] *» и другие сложные синтаксические выражения. Предоставляет различные режимы работы (поток, блок и вектор) для удовлетворения потребностей различных сценариев. При запросе с использованием каждого флага режима гиперсканирование Начальную и конечную позицию соответствующих данных можно найти во входном потоке. Для получения дополнительной информации см. Гиперсканирование. Текущая версия Справочного руководства для разработчиков 。
Крупномасштабное сопоставление
В зависимости от сложности Hyperscan может поддерживать сопоставление большого количества правил. В отличие от большинства традиционных механизмов сопоставления, Hyperscan поддерживает сопоставление по нескольким шаблонам. После присвоения уникального идентификатора каждому правилу Hyperscan может скомпилировать правила в базу данных и вывести все совпадающие в данный момент идентификаторы правил во время процесса сопоставления.

картина 3:данные разбросаны по разным блокам в хронологическом порядке
потоковый режим
Hyperscan Поддерживает три режима работы: блочный режим, потоковый режим и векторный режим.。Блочный режим — самый простой,который сканирует один непрерывный блок данных,совпадение найденочас Вернуть совпадение вызывающему абоненту。Streaming Шаблон предназначен для межпакетного сопоставления в сетевых сценариях, где сканируемые данные делятся на несколько пакетов. В потоковом режиме Hyperscan Можно сохранить состояние соответствия текущего блока данных и использовать его в качестве начального состояния соответствия при поступлении нового блока данных. Такие как картина 3 Как показано, потоковый режим может гарантировать согласованность окончательного совпадения независимо от того, как данные «xxxxabcxxxxxxxdefx» разбиваются на пакеты с течением времени. Кроме того, Гиперскан Сохраненное состояние соответствия можно сжать, чтобы уменьшить объем памяти приложения.。Работа в потоковом режиме обеспечивает Понятно一种简单из方法来扫描一段час间内到达изданные,Повторно сканируйте пакеты данных без буферизации или ограничивайте сканирование фиксированным окном исторических данных. наконец,Также есть векторный режим.,Он обеспечивает последовательное сканирование набора несмежных блоков данных в памяти.
Высокая производительность и масштабируемость
Hyperscan требует как минимум набора инструкций Intel® Streaming SIMD Extensions 3 и использует инструкции SIMD для ускорения сопоставления производительности. Ниже мы приводим краткое описание общедоступной демонстрации производительности «Анализ производительности Hyperscan с помощью hsbench».
Мы проводим этот анализ, используя три различных набора шаблонов.
- Литералы Snort — это набор из 3316 шаблонов литералов, извлеченных из образца набора правил, поставляемого с системой обнаружения сетевых вторжений Snort* 3.
- Snort PCRE – это группа 847 индивидуальныйрегулярное выражение, оно также состоит из Snort 3 Извлечено из образца набора правил для HTTP Правила дорожного движения.
- Teakettle 2500 это группа 2,500 Синтетический паттерн, генерируемый скриптом, генерирующим регулярки ограниченной сложности. выражение. мы alexa200.db Эти наборы шаблонов были протестированы на большой выборке трафика, созданной автоматизированным Web Браузер PCAP Создан для захвата данных браузера Alexa* Подмножество лучших веб-сайтов, перечисленных выше.
картина 4 Показан Intel® Ксеон® процессор E5-2699 v4 @ 2.20 GHz в блочном режиме Hyperscan соответствие производительности (Gbps)。

картина 4:Производительность гиперсканирования в блочном режиме на разных наборах правил.
изображение 4 показать Hyperscan может добиться хорошей одноядерной производительности, используя различные наборы правил.,Это очень масштабируемый,Его соответствующая производительность растет практически линейно с увеличением количества используемых ядер.
Интеграция Hyperscan и DPDK
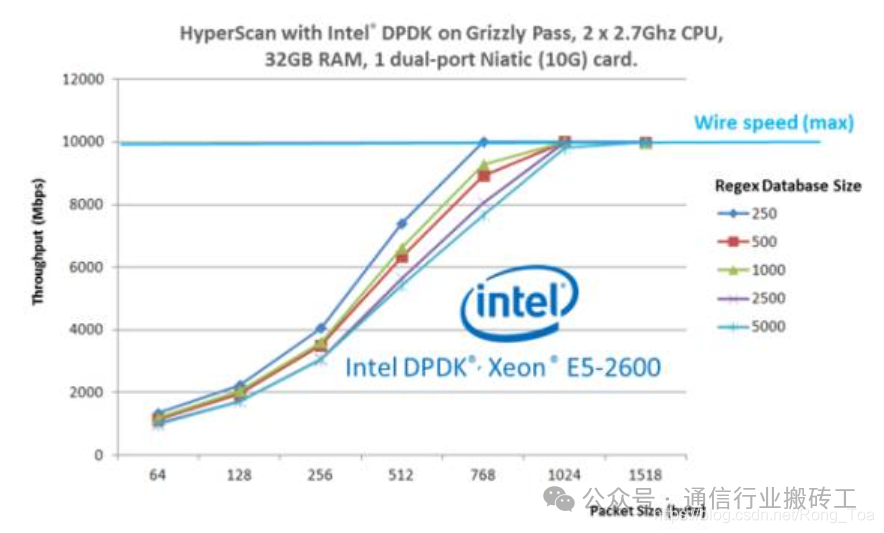
картина 5:Hyperscan иданные Graphic Development Kit Интегрированная производительность
существоватьКомплект разработки плоскости данных (DPDK)Обеспечивает высокоскоростную обработку сетевых пакетов.и Вперед,исуществовать Широко используется в промышленности。Hyperscan и DPDK Может быть интегрирован в высокопроизводительную DPI в растворе. картина 5 Шоу имеет интегрированные решения для повышения производительности. При тестировании мы используем реальный режим и HTTP трафик в качестве входных данных. Интеграция Hyperscan и DPDKпоставлять Понятновысокийпроизводительность,и в этом тесте,В пакете для данных большего размера,производительность может достигать линейной скорости.
обобщать
Hyperscan предоставляет гибкую и простую в использовании библиотеку.,Позволяет сопоставлять большое количество шаблонов одновременно с высокой производительностью и хорошей масштабируемостью.,И предоставляет уникальные функции для обработки сетевых пакетов данных. Hyperscan и DPDK также предоставляют зрелые и эффективные решения для DPI, IDS, IPS и других сопутствующих продуктов.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
