Введение в глубокое обучение: рекуррентная нейронная сеть ------ обзор RNN, уровень внедрения слов, уровень рекуррентной сети и практический пример! (Подробное объяснение в десять тысяч слов!)
🍔Обзор РНН
1.1 рекуррентная нейронная сеть 🐼 рекуррентная нейронная сеть(Recurrent Nearal Networks, RNN)это специализированный метод обработки последовательностейданныеиз Архитектура нейронной сети。Соединяется введением петли,Позволяет сети захватывать последовательность серединаиз временной зависимости и контекстную информацию. В RNN скрытый слой каждого временного шага не только получает текущий входной сигнал, но также получает выходные данные скрытого слоя предыдущего временного шага. Этот механизм позволяет сети «запоминать» прошлую информацию, тем самым эффективно обрабатывая текст, речь. и временные ряды. RNN широко используется в обработке естественного языка (например, машинном переводе, анализе настроений), распознавании речи, прогнозировании временных рядов и других областях, демонстрируя мощные возможности моделирования последовательностей.
1.2 Обработка естественного языка
🐼 Обработка естественного языка (Природа language Processing, NLP)Исследоватьиз В основном с помощью компьютерных алгоритмов для понимания естественного языка.。Для естественного языка,Обработка изданных в основном человечна из-за языка,Например: китайский, английский, французский и т. д.,Поскольку этот тип не похож на структурированный файл или изображение, с которыми мы сталкивались ранее, его можно легко оцифровать. так,существовать Эта глава,В основном мы учимся тому, как численно обрабатывать текстовые данные с помощью технологии встраивания слов и как моделировать текстовые данные на основе рекуррентной сетевой модели.
Наконец, мы выполним задачу генерации текста, используя изученную технологию, а именно: введем слово, и модель предскажет текст указанной длины.
🍔 Слой внедрения слов
цели обучения 🍀 Знать концепцию встраивания слов 🍀 Мастер-API для встраивания слов PyTorch
Когда мы обрабатываем текстовые данные, нам необходимо преобразовать текст в значения данных, а затем выполнить последующую работу по обучению. Функция слоя внедрения слов заключается в преобразовании текста в векторы.
2.1 Использование слоя встраивания слов
Слой внедрения слов сначала построит векторную матрицу слов на основе количества входных слов. Например: у нас есть 100 слов, и каждое слово нужно преобразовать в 128-мерный вектор. Тогда форма построенной матрицы будет следующей: 100*128, входные данные Каждое слово соответствует вектору в этой матрице.
В PyTorch мы можем использовать слой внедрения слов nn.Embedding для реализации векторизации входных слов. Далее мы научимся преобразовывать слова в векторы слов.
Шаги следующие: 💘 Сначала разбейте корпус на слова и постройте сопоставление между словами и индексами. Мы можем назвать это сопоставление словарем. Каждому слову в словаре соответствует уникальный индекс; 💘 Затем используйте nn.Embedding для построения матрицы встраивания слов. Вектор, соответствующий индексу слова, является числовым векторным представлением, соответствующим слову.
Например, наши текстовые данные таковы: «Индикатор выполнения зимних Олимпийских игр в Пекине прошел половину пути, и многие иностранные спортсмены возвращаются домой после завершения соревнований. Далее давайте посмотрим, как использовать слой встраивания слов для преобразования его в вектор». представительство.
Шаги следующие: 💘 Сначала разбейте текст на слова; 💘 Затем на основе слов составьте список слов; 💘 Наконец, используйте слой внедрения, чтобы преобразовать текст в векторное представление.
При построении объекта nn.Embedding имеется два основных параметра:
- num_embeddings представляет количество слов
- embedding_dim указывает, сколько размерных векторов используется для представления каждого слова.
nn.Embedding(num_embeddings=10, embedding_dim=4)Далее реализуем требования прямо сейчас💯 :
import torch
import torch.nn as nn
import jieba
if __name__ == '__main__':
text = Шкала прогресса зимних Олимпийских игр в Пекине прошла половину пути, и многие иностранные спортсмены вернулись домой после завершения собственных соревнований. '
# 1. сегментация текста
words = jieba.lcut(text)
print('сегментация текста:', words)
# 2. Пополняйте словарный запас
index_to_word = {}
word_to_index = {}
# Сегментация слов удаляет дублирование и сохраняет первоначальный порядок слов.
unique_words = list(set(words))
for idx, word in enumerate(unique_words):
index_to_word[idx] = word
word_to_index[word] = idx
# 3. Построить слой внедрения слов
# num_embeddings: Указывает общее количество словарных слов из
# embedding_dim: Представляет встраивание слов из измерения
embed = nn.Embedding(num_embeddings=len(index_to_word), embedding_dim=4)
# 4. Преобразование текста в векторное представление слов
print('-' * 82)
for word in words:
# Получить слово, соответствующее индексу
idx = word_to_index[word]
# Получить вектор встраивания слов
word_vec = embed(torch.tensor(idx))
print('%3s\t' % word, word_vec)Результат вывода программы💯:
сегментация текста: ['Пекин', «Зимние Олимпийские игры», 'из', 'Прогресс', 'уже', «Больше половины», ',', 'довольно много', 'чужая страна', 'спортсмен', 'существовать', 'Заканчивать', 'Собственный', 'из', 'Конкурс', 'назад', 'ступить на ногу', «Возвращение домой», '。']
----------------------------------------------------------------------------------
Пекин tensor([-0.9270, -0.2379, -0.6142, -1.4764], grad_fn=<EmbeddingBackward>)
зимние олимпийские игры tensor([ 0.3541, -0.4493, 0.7205, 0.1818], grad_fn=<EmbeddingBackward>)
из tensor([-0.4832, -1.4191, 0.6283, 0.0977], grad_fn=<EmbeddingBackward>)
индикатор выполнения tensor([ 1.4518, -0.3859, -0.6866, 1.1921], grad_fn=<EmbeddingBackward>)
уже tensor([ 0.3793, 1.6623, -0.2279, -0.2272], grad_fn=<EmbeddingBackward>)
Более половины tensor([ 0.0732, 1.4832, -0.7802, 0.6884], grad_fn=<EmbeddingBackward>)
, tensor([ 0.6126, 1.0175, -0.4427, 0.6719], grad_fn=<EmbeddingBackward>)
Довольно много tensor([ 1.0787, -0.2942, -1.0300, -0.6026], grad_fn=<EmbeddingBackward>)
чужая страна tensor([-0.0484, -0.1542, 1.0033, -1.2332], grad_fn=<EmbeddingBackward>)
спортсмен tensor([-1.3133, 0.3807, 0.3957, 1.1283], grad_fn=<EmbeddingBackward>)
существовать tensor([ 0.0146, -1.7078, -0.9399, 1.5368], grad_fn=<EmbeddingBackward>)
Заканчивать tensor([-0.1084, -0.0734, -0.1800, -0.5065], grad_fn=<EmbeddingBackward>)
Собственный tensor([ 0.8480, -0.4750, -0.1357, 0.4134], grad_fn=<EmbeddingBackward>)
из tensor([-0.4832, -1.4191, 0.6283, 0.0977], grad_fn=<EmbeddingBackward>)
Конкурс tensor([0.0928, 0.8925, 1.1197, 2.5525], grad_fn=<EmbeddingBackward>)
назад tensor([ 0.8835, 0.7304, 1.3754, -1.7842], grad_fn=<EmbeddingBackward>)
ступить на tensor([ 1.0809, -0.3135, 0.6346, 0.3923], grad_fn=<EmbeddingBackward>)
вернуться домой tensor([ 0.1834, -1.2411, -0.9244, -0.0265], grad_fn=<EmbeddingBackward>)
。 tensor([ 0.0290, 0.1881, -1.3138, 0.6514], grad_fn=<EmbeddingBackward>)2.2 Мысли о слое встраивания слов
По умолчанию наш слой внедрения слов использует для инициализации нормальное распределение со средним значением 0 и стандартным отклонением 1, что также можно понимать как случайную инициализацию.
🐻 Некоторые ученики могут задаться вопросом, может ли этот текст, используемый для обозначения слова, действительно передать значение этого слова?
- Векторное представление каждого слова в nn.Embedding генерируется случайным образом.
- При вводе слова для представления слова будет использоваться случайно сгенерированный вектор.
- Этот вектор слов участвует в вычислении последующих задач.
- После расчета последующей задачи она будет сравниваться с целевым результатом, чтобы вызвать потерю.
- Затем обновите все параметры сети посредством обратного распространения ошибки. Параметры здесь включают представление вектора слов в nn.Embedding.
Таким образом, благодаря повторным прямым вычислениям, обратному распространению ошибки и обновлению параметров наше векторное представление каждого слова в конечном итоге станет более разумным.
Раздел 2.3
🍬 В этом разделе в основном объясняется использование слоев встраивания слов, которые часто используются в задачах обработки естественного языка. Его основная функция — сопоставить входные слова с векторами слов для облегчения вычислений в сетевой модели.
🍬 Следует отметить, что векторное представление в слое встраивания слов является обучаемым и не фиксированным.
🍔 Рекуррентный сетевой уровень
цели обучения 🍀 Освоить принципы сети RNN 🍀 Освоение PyTorch RNN api
Ранее мы узнали о слое внедрения слов, который может отображать текстовые данные в числовые векторы, которые затем можно отправить в сеть для расчета. Однако проблема все еще существует. Текстовые данные имеют характеристики последовательности. Например: «Я люблю тебя», эта текстовая строка имеет отношение последовательности. «Любовь» должна идти после «Я», а «Ты» должна идти после «Я». после слова «любовь». Позже, если порядок изменить на противоположный, может быть выражено другое значение.
для того, чтобы иметь возможность выразитьданныеиз Для отношений последовательности нам нужно использоватьрекуррентная нейронная сеть(Recurrent Nearal Networks, RNN) Чтобы смоделировать данные, RNN Это сеть с функцией памяти, которая обрабатывает данные образца с характеристиками последовательности.
В этом разделе мы подробно познакомим вас с принципами и процессом расчета уровня рекуррентной сети RNN, а также с тем, как использовать уровень RNN в PyTorch.
3.1 Принцип сети RNN
3.1.1 Процесс расчета RNN
Как выглядит процесс расчета RNN, когда мы хотим использовать рекуррентную сеть для выполнения семантического извлечения фразы «Я люблю тебя»?
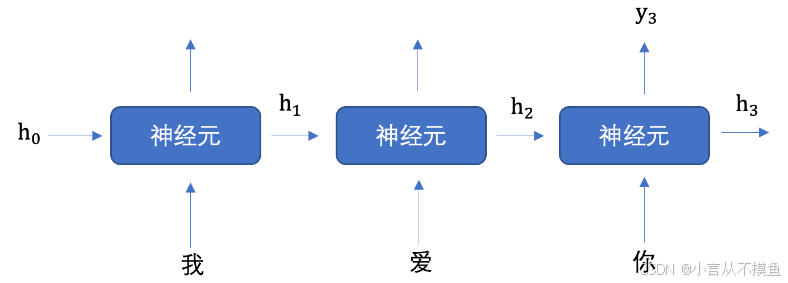
На рисунке выше h представляет скрытое состояние. Каждый вход будет содержать два значения: скрытое состояние предыдущего временного шага, входное значение текущего состояния и скрытое состояние выхода текущего временного шага.
На рисунке выше, чтобы было легче понять, хотя я нарисовал 3 нейрона, на самом деле нейрон только один. Три слова «Я люблю тебя» неоднократно вводятся в один и тот же нейрон.
Далее давайте рассмотрим пример, чтобы понять рабочий процесс, показанный на рисунке выше. Предположим, мы хотим реализовать генерацию текста, то есть ввести два слова «Я люблю», чтобы предсказать «ты», как показано на рисунке ниже:
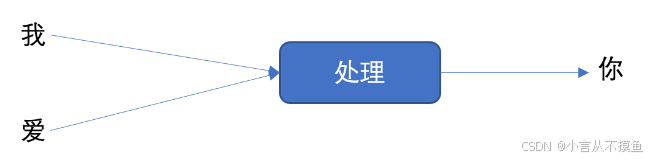
Мы разложим приведенный выше рисунок на разные временные шаги, как показано на рисунке ниже:
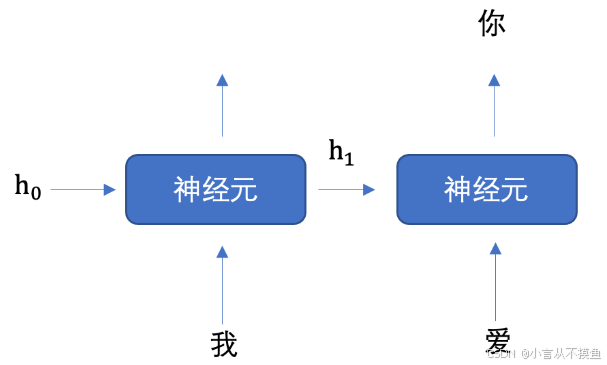
Сначала мы инициализируем первое скрытое состояние, которое обычно представляет собой вектор, состоящий из всех нулей, затем встраиваем «I» в векторное представление, отправляем его на первый временной шаг, а затем выводим скрытое состояние h1. Затем вводим h1 и «любовь». на второй временной шаг, чтобы получить скрытое состояние h2, и отправить h2 в полностью подключенную сеть, чтобы получить прогнозируемую вероятность «вас».
Итак, вы можете подумать, может ли рекуррентная сеть иметь только один нейрон?
Наша рекуррентная сетевая сеть может иметь несколько нейронов, как показано ниже:
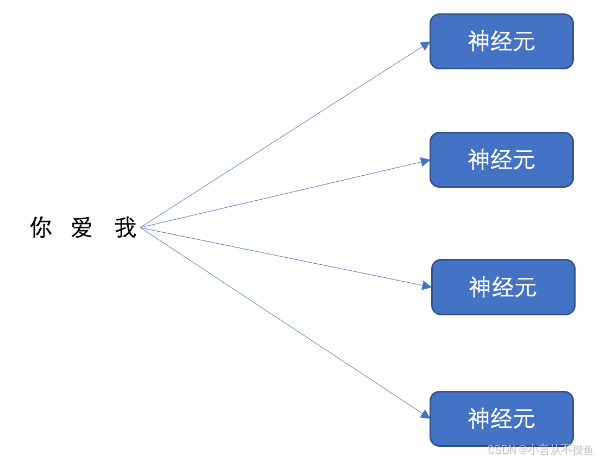
Мы в свою очередь будем "Я тебя люблю" Эти три слова отправляются каждому нейрону для расчета, предполагая встраивание слов: «Я». тебя люблю" Размеры 128, после велосипедной сети, "Я тебя люблю" Размерность вектора слова из трех символов станет 4. так, Разбираемся рекуррентная нейронная Количество нейронов будет влиять на выходное измерение.
3.1.2 Как рассчитать внутреннюю часть нейрона
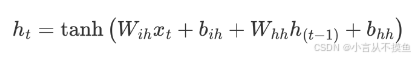
В приведенной выше формуле:
- Wih означает ввод данныхиз веса
- bih означает смещение входных данных
- Whh представляет вес входного скрытого состояния.
- bhh представляет собой смещение входного скрытого состояния
Наконец, используйте функцию активации tanh, чтобы вычислить выходной результат и получить выходные данные нейрона.
3.2 Использование слоя PyTorch RNN
Далее мы узнаем, как использовать слой RNN PyTorch.
Уведомление: RNN Ввод данных в слой имеет три измерения: (seq_len, batch_size, input_size).
Пример кода выглядит следующим образом:
import torch
import torch.nn as nn
# 1. RNN Подайте одиночные данные
def test01():
# Введите размеры данных 128, Выходные размеры 256
rnn = nn.RNN(input_size=128, hidden_size=256)
# Первый номер: Указывает длину предложения
# Второй номер: Количество партии
# Третий номер: Представляет измерение данных
inputs = torch.randn(1, 1, 128)
hn = torch.zeros(1, 1, 256)
output, hn = rnn(inputs, hn)
print(output.shape)
print(hn.shape)
# 2. Уровень RNN подается в пакетные данные.
def test02():
# Введите размеры данных 128, Выходные размеры 256
rnn = nn.RNN(input_size=128, hidden_size=256)
# Первый номер: Указывает длину предложения
# Второй номер: Количество партии
# Третий номер: Представляет измерение данных
inputs = torch.randn(1, 32, 128)
hn = torch.zeros(1, 32, 256)
output, hn = rnn(inputs, hn)
print(output.shape)
print(hn.shape)
if __name__ == '__main__':
test01()
test02()Результат вывода программы💯:
torch.Size([1, 1, 256])
torch.Size([1, 1, 256])
torch.Size([1, 32, 256])
torch.Size([1, 32, 256])Раздел 3.3
🍬 В этой главе мы узнали об слоях RNN и их принципах, а также изучили основы использования сетевых слоев RNN в PyTorch.
🍔Генерация регистрового текста
цели обучения 🍀 Освоить процесс построения модели генерации текста
Задача генерации текста — обычная изобработка. естественного языка Задача,Ввод начального слова может предсказать последовательность слов назадиз. В этом случае Воля будет использовать рекуррентную нейронная сетьосознать Джей Чоу歌词生成Задача。
Набор данных следующий:
я хочу вертолет Я хочу полететь во вселенную с тобой Я хочу растаять с тобой раствориться во вселенной Я думаю о тебе каждый день, каждый день Такая сладость Заставь меня поверить в судьбу слава гравитации позволь мне прикоснуться к тебе Прекрасная женщина, настолько красивая, что я краснею.
Всего набор данных состоит из 5819 строк.
4.1 Словообразовательный словарь
Прежде чем выполнять задачи по обработке естественного языка, первое, что мы делаем, — это пополняем словарный запас. Так называемый словарный список предназначен для сегментирования корпуса на слова, а затем присвоения уникального номера каждому слову, чтобы мы могли отправить его на уровень встраивания слов.
Наконец, наш словарь в основном содержит:
- word_to_index: хранит сопоставление слов с числами.
- index_to_word: сохраняет сопоставление числа со словом.
Общий процесс формирования словарного запаса выглядит следующим образом:
- Очистка корпуса, удаление ненужного контента
- Сегментируйте корпус
- Пополняйте словарный запас
Далее мы следуем описанным выше шагам, чтобы создать список слов для корпуса данных текстов Джея Чоу💯:
# Создать словарь
def build_vocab():
file_name = 'data/jaychou_lyrics.txt'
# 1. Чистый текст
clean_sentences = []
for line in open(file_name, 'r'):
line = line.replace('〖Перевод корейского рэпа〗','')
# Удалите символы, кроме середина, английского языка, цифр и некоторых знаков препинания.
line = re.sub(r'[^\u4e00-\u9fa5 a-zA-Z0-9!?,]', '', line)
# Заменить последовательные пробелы на 1
line = re.sub(r'[ ]{2,}', '', line)
# Удалить пробелы и разрывы строк с обеих сторон
line = line.strip()
# Удалить отдельное слово из строк
if len(line) <= 1:
continue
# Удалить повторяющиеся строки
if line not in clean_sentences:
clean_sentences.append(line)
# 2. упреждающее причастие
index_to_word, all_sentences = [], []
for line in clean_sentences:
words = jieba.lcut(line)
all_sentences.append(words)
for word in words:
if word not in index_to_word:
index_to_word.append(word)
# сопоставление слов с индексами
word_to_index = {word: idx for idx, word in enumerate(index_to_word)}
# Количество слов
word_count = len(index_to_word)
# Представление индекса предложения
corpus_idx = []
for sentence in all_sentences:
temp = []
for word in sentence:
temp.append(word_to_index[word])
# существовать Добавляйте пробелы между каждой строкой текста
temp.append(word_to_index[' '])
corpus_idx.extend(temp)
return index_to_word, word_to_index, word_count, corpus_idx
def test01():
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
print(word_count)
print(index_to_word)
print(word_to_index)
print(corpus_idx)4.2 Создание объекта набора данных
Во время обучения, чтобы облегчить чтение корпуса и отправку его в сеть, мы создадим объект Dataset и используем этот объект для создания объекта DataLoader. Затем перебираем объект DataLoader, чтобы получить корпус и отправить его в сеть.
Без лишних слов, вот демонстрация кода:
class LyricsDataset:
def __init__(self, corpus_idx, num_chars):
# корпусданные self.corpus_idx = corpus_idx
# длина корпуса
self.num_chars = num_chars
# Количество слов
self.word_count = len(self.corpus_idx)
# количество предложений
self.number = self.word_count // self.num_chars
def __len__(self):
return self.number
def __getitem__(self, idx):
# Исправьте значение индекса на: [0, self.word_count - 1]
start = min(max(idx, 0), self.word_count - self.num_chars - 2)
x = self.corpus_idx[start: start + self.num_chars]
y = self.corpus_idx[start + 1: start + 1 + self.num_chars]
return torch.tensor(x), torch.tensor(y)
def test02():
_, _, _, corpus_idx = build_vocab()
lyrics = LyricsDataset(corpus_idx, 5)
lyrics_dataloader = DataLoader(lyrics, shuffle=False, batch_size=1)
for x, y in lyrics_dataloader:
print('x:', x)
print('y:', y)
break4.3 Построение сетевой модели
Сетевая модель, которую мы используем для реализации «Генерации текстов», в основном включает три уровня:
- Слой внедрения слов: используется для преобразования корпуса в векторы слов.
- Рекуррентный сетевой уровень: извлечение семантики предложений
- Полностью связный слой: выводит прогнозируемую вероятность для каждого слова в словаре.
Ранее мы узнали о слое Dropout, который обладает эффектом регуляризации, поэтому на нашем сетевом уровне мы будем выполнять вычисления Dropout на выходных результатах слоя внедрения слов и рекуррентного сетевого уровня.
Пример кода выглядит следующим образом:
class TextGenerator(nn.Module):
def __init__(self, vocab_size):
super(TextGenerator, self).__init__()
# Инициализировать внедрения слов
self.ebd = nn.Embedding(vocab_size, 128)
# рекуррентный сетевой уровень
self.rnn = nn.RNN(128, 128, 1)
# выходной слой
self.out = nn.Linear(128, vocab_size)
def forward(self, inputs, hidden):
# Выходные размеры: (1, 5, 128)
embed = self.ebd(inputs)
# слой регуляризации
embed = F.dropout(embed, p=0.2)
# Изменить размеры: (5, 1, 128)
output, hidden = self.rnn(embed.transpose(0, 1), hidden)
# слой регуляризации
embed = F.dropout(output, p=0.2)
# Входные размеры: (5, 128)
# Выходные размеры: (5, 5682)
output = self.out(output.squeeze())
return output, hidden
def init_hidden(self):
return torch.zeros(1, 1, 128)
def test03():
index_to_word, word_to_index, word_count, corpus_idx = build_vocab()
_, _, _, corpus_idx = build_vocab()
lyrics = LyricsDataset(corpus_idx, 5)
lyrics_dataloader = DataLoader(lyrics, shuffle=False, batch_size=1)
model = TextGenerator(word_count)
for x, y in lyrics_dataloader:
hidden = model.init_hidden()
print(x.shape)
model(x, hidden)
break4.4. Построение функции обучения
После того, как предыдущие приготовления завершены, мы можем написать обучающую функцию. Функция обучения в основном отвечает за запись итерации данных, отправку их в сеть, расчет потерь, обратное распространение ошибки и обновление параметров. Этот процесс в основном относительно фиксирован.
Поскольку мы хотим добиться генерации текста, генерация текста по существу включает в себя ввод строки текста и прогнозирование следующего текста, что также является проблемой классификации. Поэтому мы используем многоклассовую функцию перекрестной энтропии. Методы оптимизации Мы изучили SGB, AdaGrad, Adam и т. д. Здесь мы выбираем адаптивный алгоритм Адама по скорости обучения и градиенту в качестве метода оптимизации.
После завершения обучения мы используем метод torch.save для постоянного сохранения модели.
def train():
# Создать словарь
index_to_word, word_to_index, word_count,corpus_idx = build_vocab()
# данные集 тексты песен = LyricsDataset (corpus_idx, 32)
# Инициализировать модель
model = TextGenerator(word_count)
# функция потерь
criterion = nn.CrossEntropyLoss()
# Метод оптимизации
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Количество тренировочных раундов
epoch = 200
# Итеративная печать
iter_num = 300
# Журнал тренировок
train_log = 'lyrics_training.log'
file = open(train_log, 'w')
# Начать обучение
for epoch_idx in range(epoch):
# загрузчик данных
lyrics_dataloader = DataLoader(lyrics, shuffle=True, batch_size=1)
# время тренировки
start = time.time()
# Количество итераций
iter_num = 0
# потеря тренировки
total_loss = 0.0
for x, y in lyrics_dataloader:
# Скрытое состояние
hidden = model.init_hidden()
# Расчет модели
output, hidden = model(x, hidden)
# Рассчитать потери
loss = criterion(output, y.squeeze())
# Градиент четкий
optimizer.zero_grad()
# Обратное распространение ошибки
loss.backward()
# Обновление параметров
optimizer.step()
iter_num += 1
total_loss += loss.item()
message = 'epoch %3s loss: %.5f time %.2f' % \
(epoch_idx + 1,
total_loss / iter_num,
time.time() - start)
print(message)
file.write(message + '\n')
file.close()
# Хранение модели
torch.save(model.state_dict(), 'model/lyrics_model_%d.bin' % epoch)4.5. Построение функции прогнозирования
На последнем этапе мы загружаем обученную модель с диска и делаем прогнозы. Функция прогнозирования, вводим первое указанное слово, вводим это слово в сеть, предсказываем следующее слово, затем снова отправляем предсказанное слово в сеть, предсказываем следующее слово и так далее, пока предсказанное слово не укажем длину содержание.
def predict(start_word, sentence_length):
# Создать словарь
index_to_word, word_to_index, word_count, _ = build_vocab()
# Построить модель
model = TextGenerator(vocab_size=word_count)
# Загрузить параметры
model.load_state_dict(torch.load('model/lyrics_model_200.bin'))
# Скрытое состояние
hidden = model.init_hidden()
# слово для индексации
word_idx = word_to_index[start_word]
generate_sentence = [word_idx]
for _ in range(sentence_length):
output, hidden = model(torch.tensor([[word_idx]]), hidden)
word_idx = torch.argmax(output)
generate_sentence.append(word_idx)
for idx in generate_sentence:
print(index_to_word[idx], end='')
print()
if __name__ == '__main__':
предсказать('расставание', 50)Результаты запуска программы:
Расставание похоже на словесное насилие Я ничего не могу сделать, чтобы поднять этот вопрос снова решить середина, разорвать знакомство Джей Чоу Джей Чоу Один шаг, два шага, три шага, четыре шага, глядя на небо. посмотри на звезды Один, два, три, четыре Подключиться в линию Один шаг, два шага, три шага, четыре шага, глядя на небо. посмотри на звезды Один, два, три, четыре Раздел 4.6
Эта книга «Раздел» предназначена для использования и изучения всеми желающими. нейронная сетьиз Знание, построила проект «Lyrics Generation».
Процесс реализации данного проекта выглядит следующим образом: 🍬 Пополняйте словарный запас 🍬 Создание объектов данных 🍬 Написать модель сети 🍬 Написать обучающую функцию 🍬 Напишите функцию прогнозирования
Ребята~ Если статья вам полезна, пожалуйста, оставьте свое внимание~ Ваше внимание - моя самая большая мотивация!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
