Введение, тонкая настройка, количественная оценка и выводы Google Gemma
Последняя модель Gemma от Google — это первая программа LLM с открытым исходным кодом, созданная с использованием тех же исследований и технологий, что и модель Gemini. Эта серия моделей в настоящее время выпускается в двух размерах: 2B и 7B, и предоставляет базовую версию для чата и версию для команд.

Подвести одним предложением Итог Джемма: ученая Лама 2 и Мистраль Преимущество 7B заключается в том, что для обучения лучшей модели 7B (8,5B) используется больше токенов и слов. Итак, в этой статье мы представим модель Gemma, а затем покажем, как использовать модель Gemma, включая использование QLoRA, умозаключений и количественной точной настройки.
Джемма 7B на самом деле 8,5B.
1. Детали модели
Более подробная информация о модели представлена в техническом отчете, опубликованном Google.
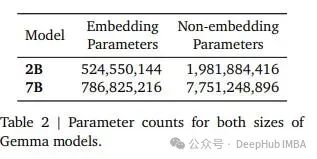
Вы можете увидеть Google итог определяет количество параметров для каждой модели и различает встроенные и невстроенные параметры. Для 7BМодель имеется 7.7B невстроенных параметров. Если рассматривать общее количество параметров, Gemma 7B имеет параметры 8,54B...
Для сравнения, Джемма ближе к 9В. Выпуск Gemma как LLM «7B» можно расценить как заблуждение, но это тоже понятно, ведь вам обязательно захочется сравнить свой LLM с ранее выпущенным 7B, а большее количество параметров часто означает лучшую производительность, что хорошо для Бара.
Для удобства сравнения мы просуммировали общее количество параметров для других популярных моделей «7Б»:
- Llama 2 7B: 6.74B
- Mistral 7B: 7.24B
- Qwen-1.5 7B: 7.72B
- Gemma 7B: 8.54B
Видно, что Gemma 7B на самом деле имеет на 1,8B больше параметров, чем Llama 2 7B. Согласно теории, чем больше параметров, тем лучше производительность, неизбежно, что Gemma лучше других моделей.
Архитектура модели также подробно представлена в отчете Google:
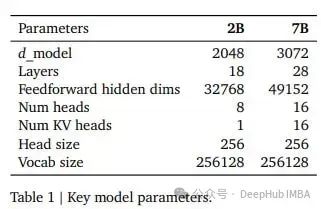
Может обрабатывать контексты до 8 тыс. токенов. Для эффективного масштабирования они используют внимание к нескольким запросам и встраивание RoPE и совместимы с FlashAttention-2.
Словарь встраивания Gemma является самым большим среди существующих моделей с открытым исходным кодом и насчитывает 256 тысяч слов. Он в 8 раз больше словарного запаса Ламы 2 и в 1,7 раза больше словарного запаса Квен-1.5, который и без того считается очень большим. Если не считать размера словаря, архитектура Gemma очень стандартна. Больший словарь внедрения обычно означает, что модель обучена быть многоязычной. Но Google утверждает, что эти модели в первую очередь предназначены для задач на английском языке.
Но, судя по моделям, выпущенным на данный момент, Google действительно обучал модель на данных, охватывающих несколько языков, и, если ее настроить для многоязычных задач, она должна обеспечить хорошую производительность.
2. Данные тренировок Джеммы
Gemma 2B и 7B были обучены на 2 триллионах и 6 триллионах токенов соответственно. Это означает, что Gemma 7B принимает в 3 раза больше жетонов, чем Llama 2. Причины здесь предполагаются следующие:
Поскольку словарь очень велик, модель необходимо дольше обучать, чтобы лучше изучить встраивания для всех токенов в словаре. Потеря должна еще уменьшиться после расширения жетонов обучения, что также соответствует очень большому словарному запасу. Мы можем понять, что чем больше словарный запас, тем больше жетонов обучения может потребоваться и, конечно же, производительность может быть выше.
Для версии модели с инструкциями они выполнили контролируемую точную настройку набора данных инструкций, состоящего из человеческих и синтетических данных, с последующим обучением с подкреплением с обратной связью от человека (RLHF).

3. Производительность на данных общедоступных испытаний
Google оценил Gemma по стандартным критериям и сравнил результаты с Llama 2 (в статье пишется как Lama-2…) и Mistral 7B.
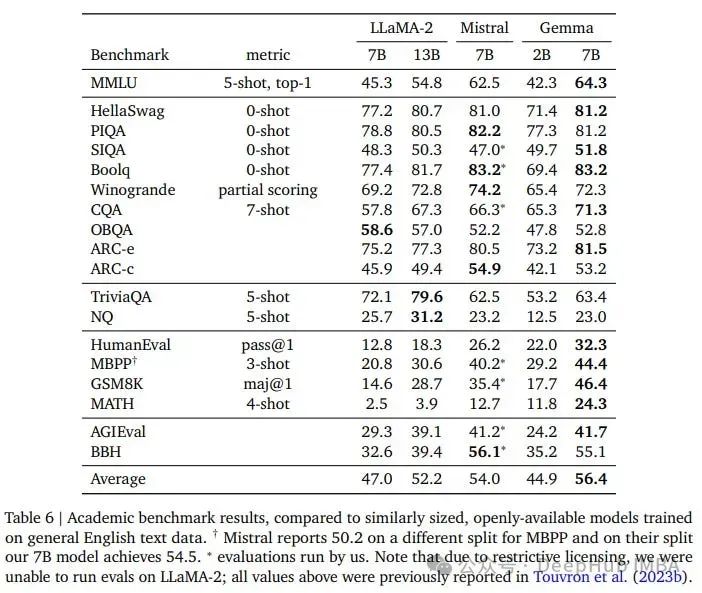
В большинстве задач Gemma 7B показала лучшие результаты, чем другие модели. Но здесь есть 2 проблемы:
1. Нам по-прежнему приходится относиться к этим контрольным показателям с долей скептицизма. Потому что Google не сообщает нам, как он рассчитывает эти оценки.
2. Еще проблема с параметрами модели. Теоретически 8,5В должно быть лучше 7В, поэтому рост показателя - это нормально.
Запуск Gemma 2B и 7B локально
Трансформеры Hugging Face и vLLM уже поддерживают модель Gemma, а аппаратное обеспечение — графический процессор на 18 ГБ.
Давайте сначала представим vLLM
import time
from vllm import LLM, SamplingParams
prompts = [
"The best recipe for pasta is"
]
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, top_k=20, max_tokens=150)
loading_start = time.time()
llm = LLM(model="google/gemma-7b")
print("--- Loading time: %s seconds ---" % (time.time() - loading_start))
generation_time = time.time()
outputs = llm.generate(prompts, sampling_params)
print("--- Generation time: %s seconds ---" % (time.time() - generation_time))
for output in outputs:
generated_text = output.outputs[0].text
print(generated_text)
print('------')А еще есть Трансформеры
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(1234) # For reproducibility
prompt = "The best recipe for pasta is"
checkpoint = "google/gemma-7b"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.float16, device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=150)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)Он очень прост в использовании и в основном такой же, как и другие модели с открытым исходным кодом.
Количественное определение Gemma 7B
AutoGPTQ и AutoAWQ — две наиболее часто используемые библиотеки для количественной оценки GPTQ и AWQ, но в настоящее время (2.29) они не поддерживают Gemma. Таким образом, мы можем квантовать Gemma 7B только с помощью битов и байтов NF4.
Блочное квантование формата GGUF также можно выполнить с помощью llama.cpp. Google выпускает версию Gemma в формате GGUF в том же репозитории, что и исходная версия.
В битах и байтах Gemma 7B по-прежнему требует 7,1 ГБ оперативной памяти графического процессора. Итак, еще раз: правильно ли название «7B»?
Ниже приведен код для квантовой загрузки и вывода.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed, BitsAndBytesConfig
set_seed(1234) # For reproducibility
prompt = "The best recipe for pasta is"
checkpoint = "google/gemma-7b"
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, quantization_config=bnb_config, device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=150)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)Точная настройка Gemma 7B с помощью QLORA
Квантование битов и байтов уже работает, поэтому мы можем использовать QLoRA для точной настройки Gemma 7B. Конечно, Gemma 7B также можно точно настроить на потребительском оборудовании с использованием LoRA (т. е. без квантования), если используется небольшой размер обучающего пакета и короткая max_seq_length.
Вот код, который я использовал для тестирования тонкой настройки QLoRA с помощью Gemma 7B:
import torch
from datasets import load_dataset
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
AutoTokenizer,
TrainingArguments,
)
from trl import SFTTrainer
model_name = "google/gemma-7b"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, add_eos_token=True, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer.padding_side = 'left'
ds = load_dataset("timdettmers/openassistant-guanaco")
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name, quantization_config=bnb_config, device_map={"": 0}
)
model = prepare_model_for_kbit_training(model)
#Configure the pad token in the model
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = False # Gradient checkpointing is used by default but not compatible with caching
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"]
)
training_arguments = TrainingArguments(
output_dir="./results_qlora",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
log_level="debug",
save_steps=50,
logging_steps=50,
learning_rate=2e-5,
eval_steps=50,
max_steps=300,
warmup_steps=30,
lr_scheduler_type="linear",
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
eval_dataset=ds['test'],
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=512,
tokenizer=tokenizer,
args=training_arguments,
)
trainer.train()300 шагов обучения (размер обучающего пакета — 4) занимают менее 1 часа.
Подвести итог
Многие платформы уже хорошо поддерживают модели Gemma, и скоро будет выпущено квантование GPTQ и AWQ. После квантования Gemma 7B можно будет использовать на графическом процессоре с памятью 8 ГБ.
Нельзя отрицать, что выпуск модели Gemma — это шаг вперед для Google. Gemma 7B выглядит неплохим конкурентом Mistral 7B, но не будем забывать, что у нее еще и параметров на 1 миллиард больше, чем у Mistral 7B. Кроме того, я никогда не понимал, каков вариант использования Gemma 2B. Ее производительность превосходит другие модели аналогичного размера (этот 2B может быть действительно 2B), и видно, что производительность этих двух моделей Google невелика. параметры не хорошие, но производительность хорошая. Есть еще много параметров. Такая игра слов показывает, что Google действительно отстает и беспокоится на треке ИИ, и в настоящее время нет возможности его превзойти.
Вот отчет gemma, официально выпущенный Google. Если вам интересно, вы можете его проверить.
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Автор: Бенджамин Мари



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
