Возможности понимания многоязычного текста в мультимодальных больших моделях еще предстоит пройти долгий путь. Byte и Huake совместно выпустили MTVQA Bench.
введение
В последнее время мультимодальные большие модели (MLLM) добились значительного прогресса в области визуального понимания текста, такие как модели с открытым исходным кодом InternVL 1.5, MiniCPM-Llama3-V 2.5, TextMonkey, модели с закрытым исходным кодом GPT-4o, Claude и т. д., а также даже в некоторых аспектах продемонстрировал сверхчеловеческие способности. Однако текущие оценки в основном сосредоточены на английской и китайской языковой среде, а исследования более сложных многоязычных сред относительно недостаточны.
В современном глобализованном мире многоязычная среда все чаще появляется в повседневной жизни людей, что также создает большие проблемы для развития искусственного интеллекта. На этом фоне появился эталонный тест MTVQA (Многоязычный текстово-ориентированный визуальный ответ на вопросы). Он ориентирован на многоязычный визуальный ответ на вопросы, ориентированный на текст, и направлен на заполнение пробелов в существующих тестах оценки в области многоязычного визуального текста.
MTVQA охватывает 9 языков, включая арабский, корейский, японский, тайский, вьетнамский, русский, французский, немецкий и итальянский, а также собирает и систематизирует многоязычные изображения с форматированным текстом в естественных сценах и сценах документов, таких как меню, дорожные знаки и карты. , счета, PPT, документы, диаграммы и т. д. Пары вопросов и ответов тщательно аннотируются экспертами, чтобы обеспечить высокую степень согласованности между визуальным текстом и вопросами и ответами.
Результаты тестов MTVQA показывают, что будь то модель с открытым исходным кодом или самая совершенная модель с закрытым исходным кодом, такая как GPT-4o (27,8%), точность составляет менее 30%, а производительность модели с открытым исходным кодом документ эксперт большая модель также неудовлетворительна.
Как ни посмотри, в понимании многоязычного текста еще есть много возможностей для улучшения. MTVQA фокусируется на широко используемых языках, помимо китайского и английского, в надежде способствовать развитию возможностей понимания многоязычного текста и распространению результатов мультимодальных больших моделей на большее количество стран и регионов.

- Ссылка на статью: https://arxiv.org/abs/2405.11985.
- Ссылка на проект: https://bytedance.github.io/MTVQA/

Рисунок 1 Пример отображения разных языков и сценариев в MTVQA
Предыстория
Способность визуального понимания текста является ключевым параметром возможностей мультимодальных больших моделей. Существующие тесты, такие как DocVQA, TextVQA, STVQA и т. д., использовались при оценке передовых MLLM с закрытым и открытым исходным кодом, таких как GPT-4o. Gemini и Internlm VL. Он играет важную роль в оценке способности к визуальному пониманию текста мультимодальных больших моделей в различных измерениях. Однако все они сосредоточены на оценке навыков китайского и английского языков и не имеют контрольного показателя, который мог бы оценить понимание. способность других языков.
В ответ на эти недостатки исследователи из Byte и Huake предложили MTVQA, первый тест для всесторонней оценки возможностей визуального понимания текста в нескольких сценариях и на нескольких языках.
Процесс строительства MTVQA
а) Сбор данных
Тестовый набор включает 1220 панорамных изображений и 876 изображений естественных сцен. Источники данных можно разделить на три части:
- Картинки, собранные из Интернета, например PPT, бумага, логотип и т. д.
- Сбор и съемка фотографий, в том числе различных сцен, на месте проводятся с марта 2023 года по март 2024 года.
- Существующая публикаданные,Из ИКДАР На общедоступных изображениях MLT19 представлены некоторые типичные текстовые изображения сцен.
б) Аннотация данных
Все данные контроля качества аннотируются обученными носителями языка и проходят несколько раундов перекрестной проверки, чтобы гарантировать разнообразие вопросов и точность ответов.
Правила маркировки:
- Вопрос должен быть связан с текстовым содержанием на картинке
- Каждая картинка включает в себя 3 вопроса, на которые можно ответить напрямую, и 2 вопроса, требующие рассуждения.
- Ответ должен максимально соответствовать тексту на картинке.
- Старайтесь отвечать как можно короче, не повторяя содержание вопроса.
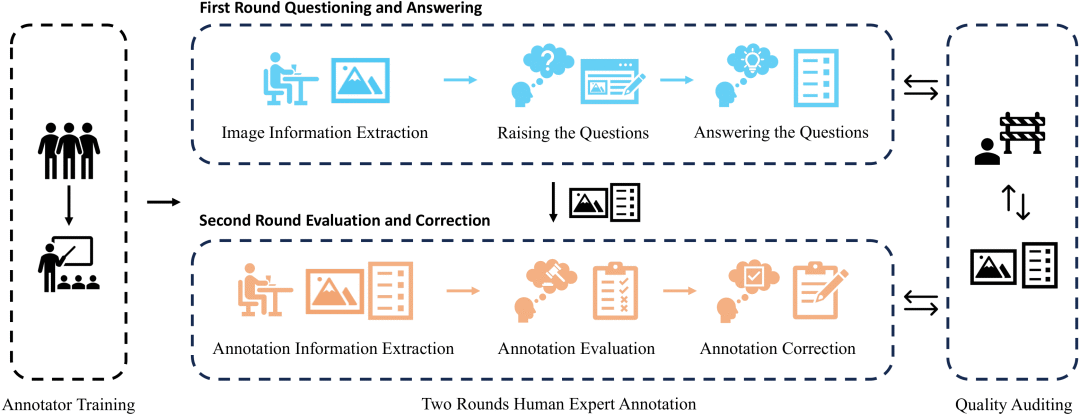
Рис. 2. Процесс аннотирования данных MTVQA
Перекрестная оценка и пересмотр:
- Оценить релевантность текстового контента в вопросах и изображениях
- Оценивайте ответы на точность и полноту.
- Моральная оценка, суждение о том, соответствует ли она человеческой этике.
в) Обзор набора данных
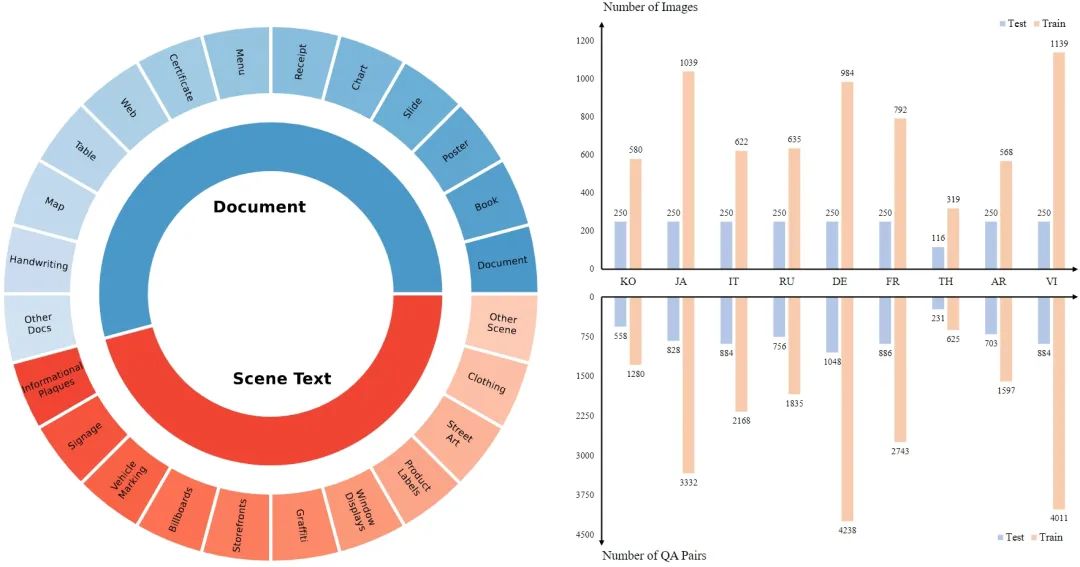
Рисунок 3. Богатые сценарии, охватываемые MTVQA, и количество проверок качества на разных языках.

Рисунок 4. Облако слов.
Показатели MLLM на стенде MTVQA
На MTVQA оценили 19 продвинутых MLLM, в том числе Открытый исходный коди закрытый исходный код Модель,Результаты оценки следующие:
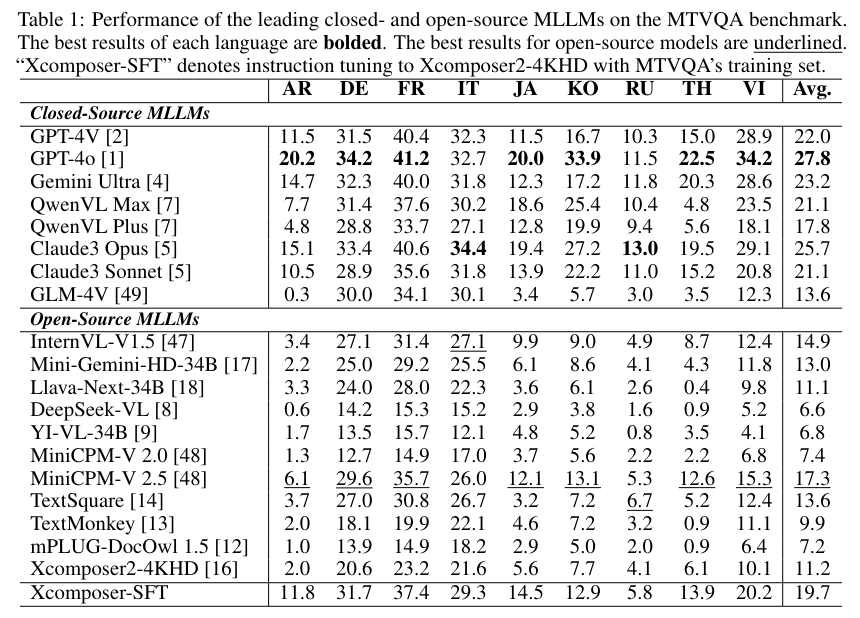
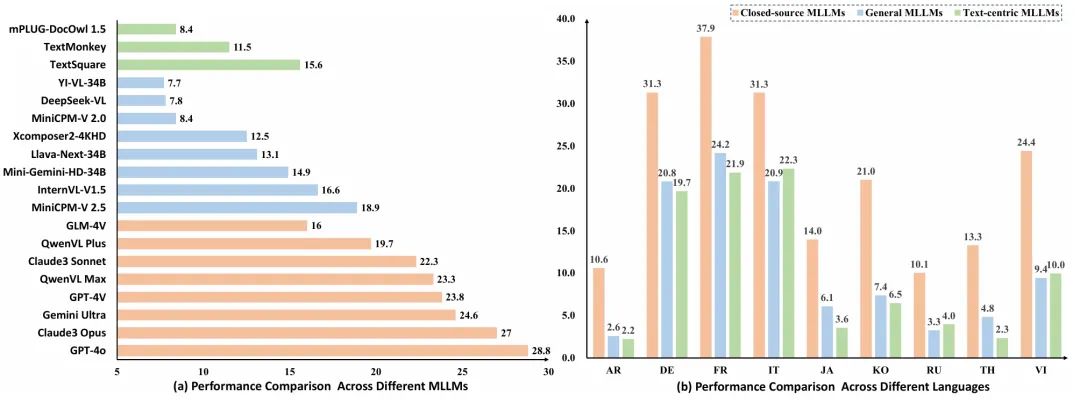
Результаты эксперимента показали:
а. Понимание многоязычного текста на данном этапе все еще остается очень сложной задачей.хотяGPT-4oЗанял первое место по большинству языков и общим результатам,Но средняя точность всего 27,8.,По сравнению с мультимодальной способностью понимания английского языка в большой модели,Разрыв очевиден,Не говоря уже о разрыве с людьми.
б. Существует большой разрыв между моделью с открытым исходным кодом и моделью с закрытым исходным кодом.оптимальный Открытый исходный код МодельдаMiniCPM-V 2.5, набрал 18,9%, но это далеко от лучших моделей с закрытым исходным кодом, таких как QwenVL. Max, Gemini Ultra, Claude3 Opus, GPT-4o и другие все еще находятся относительно далеко.
в. Мультимодальные большие модели, ориентированные на понимание текста, не имеют очевидных преимуществ.Исследователи выбрали самые последние3визуальное понимание текста, ориентированное на пониманиеMLLM,mPLUG-DocOwl 1.5, TextMonkey, TextSquare, найдите оптимальный TextSquare по сравнению с обычным MLLM MiniCPM-V 2,5 не имеет преимущества (15,6 vs. 18.9)。
г. Существует очевидный разрыв в понимании разных языков.Латинские языки, такие как итальянский、немецкий、Французский язык работает намного лучше, чем нелатинские языки, такие как японский.、корейский、Русский. Вероятно, это связано с тем, что латинские языки больше похожи на английский как визуально, так и семантически.
Подвести итог
Исследователи из ByteDance и Хуачжунского университета науки и технологий предложили новый эталон оценки MTVQA Bench для задач визуального понимания многоязычного текста, а также оценили и проанализировали производительность мультимодальных больших моделей.
Исследования показали, что задачи визуального понимания на нескольких языках очень сложны. Современные большие мультимодальные модели работают плохо и все еще далеки от человеческого уровня. Исследователи ожидают, что последующие исследования и разработки мультимодальных больших моделей будут уделять больше внимания многоязычным сценариям и расширять сферу применения мультимодальных больших моделей, чтобы люди в большем количестве стран и регионов могли участвовать и делиться удобствами, предоставляемыми искусственным интеллектом.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
