Вопрос-сценарий: Как повысить эффективность Kafka?
Kafka популярен благодаря своей высокой пропускной способности, низкой задержке и масштабируемости. Kafka играет ключевую роль в анализе данных в реальном времени, сборе журналов или в архитектуре, управляемой событиями.
Однако если Kafka используется неправильно, он также может столкнуться с узкими местами в производительности, влияющими на общую эффективность системы. Итак, понимаете, как повысить эффективность Kafka? Крайне важно как для использования в производственной среде, так и для проведения интервью.
Итак, каковы эффективные способы улучшить производительность Kafka? Дальше давайте посмотрим.
Основные средства настройки производительности
Основные методы настройки производительности Kafka следующие:
- Расширение раздела
- Пакетная отправка сообщений (важно)
- Получение пакета сообщений (важно)
- Настройка конфигурации
- Настройка JVM
1. Расширение раздела
существовать Kafka в архитектуре,Используйте несколько разделов для реализации сегментирования данных。То есть Kafka Несколько сообщений будут храниться одновременно в нескольких Broker(Kafka услуги) Partition Чтобы реализовать функцию параллельных операций, это значительно улучшает возможности чтения и записи всей системы, как показано на следующем рисунке:
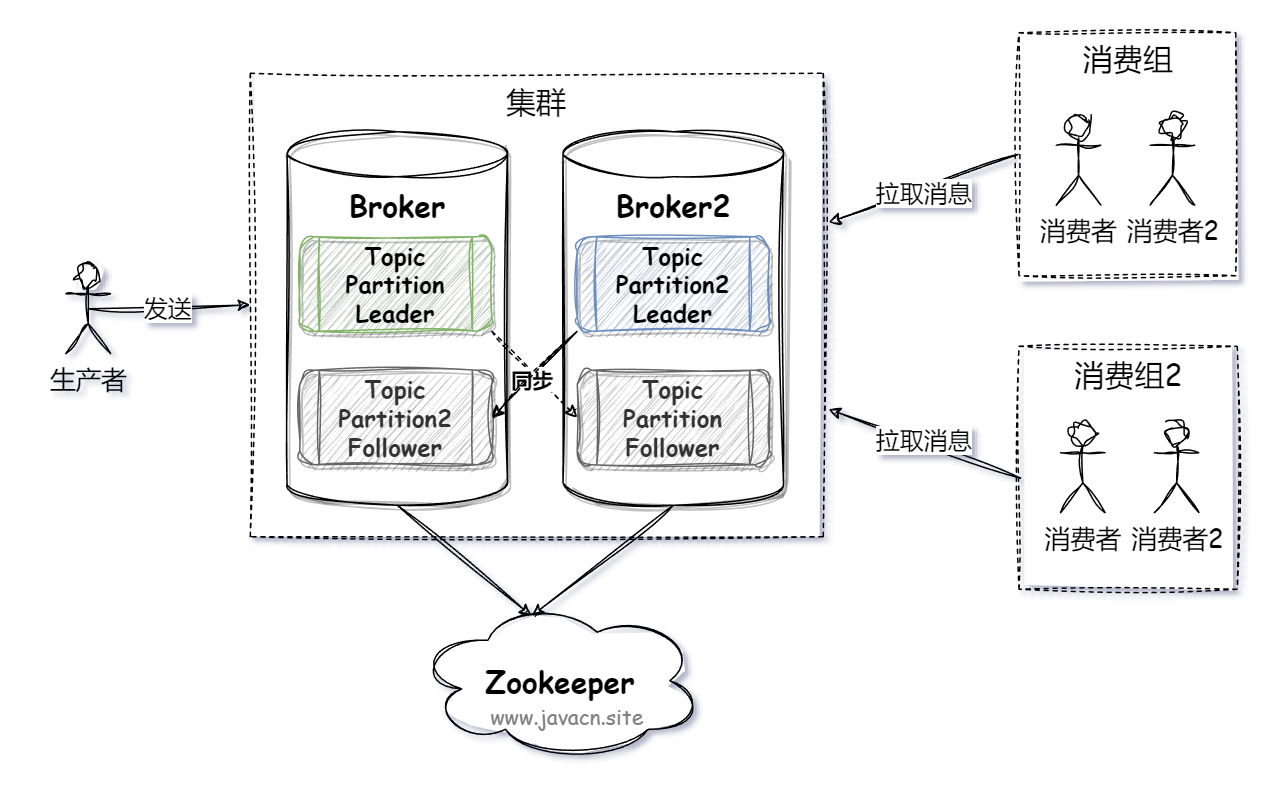
Шардинг данных — это метод разделения больших данных на более мелкие, более управляемые части (называемые «осколками»).,И хранить осколки на разных серверах,Это обеспечивает горизонтальное разделение данных. Через сегментирование данных,Он может эффективно решить проблемы производительности, ограничения хранилища и проблемы высокой доступности одной базы данных.
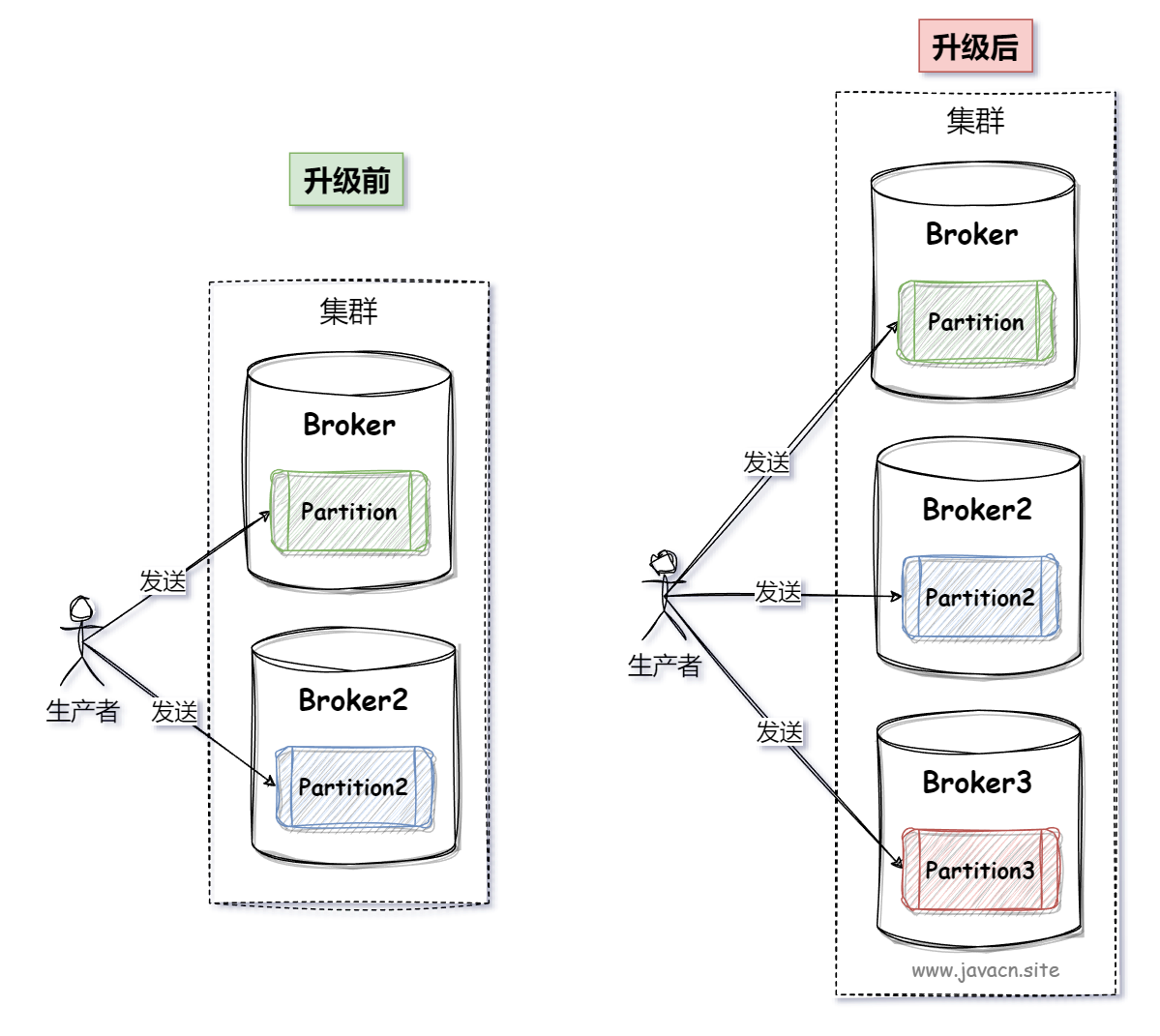
Следовательно, добавление большего количества брокеров и расширение большего количества разделов являются ключом к повышению производительности Kafka, как показано на следующем рисунке:
2. Пакетная отправка сообщений (важно)
Kafka по умолчанию не поддерживает пакетную отправку сообщений. Однако включение пакетной отправки сообщений может повысить общую эффективность работы Kafka.
Зачем отправлять сообщения оптом?
Пакетная отправка сообщений имеет следующие преимущества:
- Уменьшите нагрузку на сеть:Когда производитель отправляет сообщение Kafka , если вы отправляете только одно сообщение за раз, вам нужно установить его один раз TCP Соединение, которое включает в себя трехэтапный процесс установления связи. А если использовать пакетную отправку, то можно существовать один раз TCP Отправка нескольких сообщений в одном соединении сокращает время установления и отключения сетевого соединения, тем самым уменьшая сетевые издержки.
- Сокращение операций ввода-вывода:Массовая отправка означает написание один раздействовать Может обрабатывать больше данных。это для диска I/O Это преимущество, поскольку одна большая операция записи более эффективна, чем несколько небольших операций записи.
- Повышение пропускной способности:потому чтоуменьшать Количество коммуникаций,Пакетная отправка может увеличить количество сообщений, отправляемых в единицу времени.,То есть пропускная способность улучшается.
Тогда, чтобы реализовать пакетную отправку сообщений Kafka, вам нужно всего лишь правильно настроить следующие три параметра:
- batch-size:определенный Kafka Максимальный размер (в байтах) сообщений, которые производитель пытается отправить пакетами. Когда производитель соберет достаточно сообщений для достижения этого размера, он попытается отправить их. Kafka Брокер, значение по умолчанию: 16KB。
- buffer-memory:назначенный Kafka Общий объем памяти, который производитель может использовать для буферизации отправляемых сообщений. Если сообщение, которое пытается отправить производитель, превышает этот предел, производитель блокируется до тех пор, пока не станет достаточно места или пока не будет отправлено значение по умолчанию. 32MB。
- linger.ms:продюсерсуществовать Максимальное время ожидания перед попыткой отправки сообщения(в миллисекундах)。По умолчанию,linger.ms Значение 0, что означает отправку немедленно. выше 3 Если какой-либо из параметров соблюден, он будет отправлен немедленно (пакетами).
Поэтому, если нам нужно сопоставить и отправить, основным параметром, который необходимо настроить, является linger.ms, как показано в следующей конфигурации:
spring:
kafka:
bootstrap-servers: localhost:9092 # Адрес сервера Кафки
consumer:
group-id: my-group # Идентификатор группы потребителей
auto-offset-reset: earliest # Автоматически сбрасывать смещение к самому раннему доступному сообщению.
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # Десериализатор ключей
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # Десериализатор значений
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # сериализатор для ключей
value-serializer: org.apache.kafka.common.serialization.StringSerializer # сериализатор значений
batch-size: 16384
buffer-memory: 33554432
properties:
linger:
ms: 20003. Получение пакета сообщений (важно)
По умолчанию Kafka извлекает по одному сообщению за раз, а использование пакетного получения сообщений может эффективно повысить эффективность работы Kafka.
Зачем получать сообщения пакетами?
Пакетное получение сообщений имеет следующие преимущества:
- Уменьшите накладные расходы на обработку клиентов:Для клиента,Каждый раз при обработке сообщения выполняется серия действий.,Такие как распаковка, синтаксический анализ, логика обработки и т. д. Если вы извлекаете только одно сообщение за раз,Клиент будет часто выполнять эти действия.,Увеличение накладных расходов на обработку. При пакетном получении сообщений,Клиент может обрабатывать несколько сообщений одновременно,уменьшить Как часто обрабатывается одно сообщение,Это снижает накладные расходы на обработку клиентов.
- Уменьшите количество сетевых обращений туда и обратно.:Каждый раз, когда сообщение извлекается,Клиенту требуется несколько сетевых обращений к серверу Kafka.,В том числе отправка запросов, получение ответов и т. д. Эти сетевые обходы вызывают некоторую задержку. При пакетном получении сообщений,Клиент может получить несколько сообщений одновременно,уменьшить Количество сетевых обращений туда и обратно,Это уменьшает задержку сети.
- Оптимизировать использование памяти:Пакетное извлечение сообщений позволяет лучше планироватьи Используйте память。Клиент может одновременно выделить достаточно памяти для хранения сообщений, извлеченных пакетами.,Избегайте частого выделения и освобождения небольших блоков памяти. Это может повысить эффективность использования памяти.,уменьшить Генерация фрагментации памяти,А потом улучшать операционную систему эффективность。
- Повышение пропускной способности:Пакетное извлечение сообщений может увеличить количество сообщений, обрабатываемых в единицу времени.,тем самым улучшая Kafka пропускная способность.
Если вы хотите читать данные в пакетном режиме, вам необходимо сделать следующие два шага:
- Установите пакетное чтение в файле конфигурации существования: Spring.kafka.listener.type=batch
- потребительское использование List<ConsumerRecord<?, ?>> Для получения сообщений используется следующий код реализации: @KafkaListener(topics = TOPIC)
public void listen(List<ConsumerRecord<?, ?>> consumerRecords) {
for (int i = 0; i < consumerRecords.size(); i++) {
System.out.println("Прослушано сообщение:" + consumerRecords.get(i).value());
}
System.out.println("------------end------------");
}Результаты выполнения вышеуказанной программы следующие:
d”Распечатать,Это показывает Kafka За раз извлекается пакет данных, а не один фрагмент данных, иначе будет несколько «концов». 4. Настройка конфигурации Разумные настройки Kafka Конфигурацию также можно в определенной степени улучшить. Kafka эффективность, например следующие конфигурации:
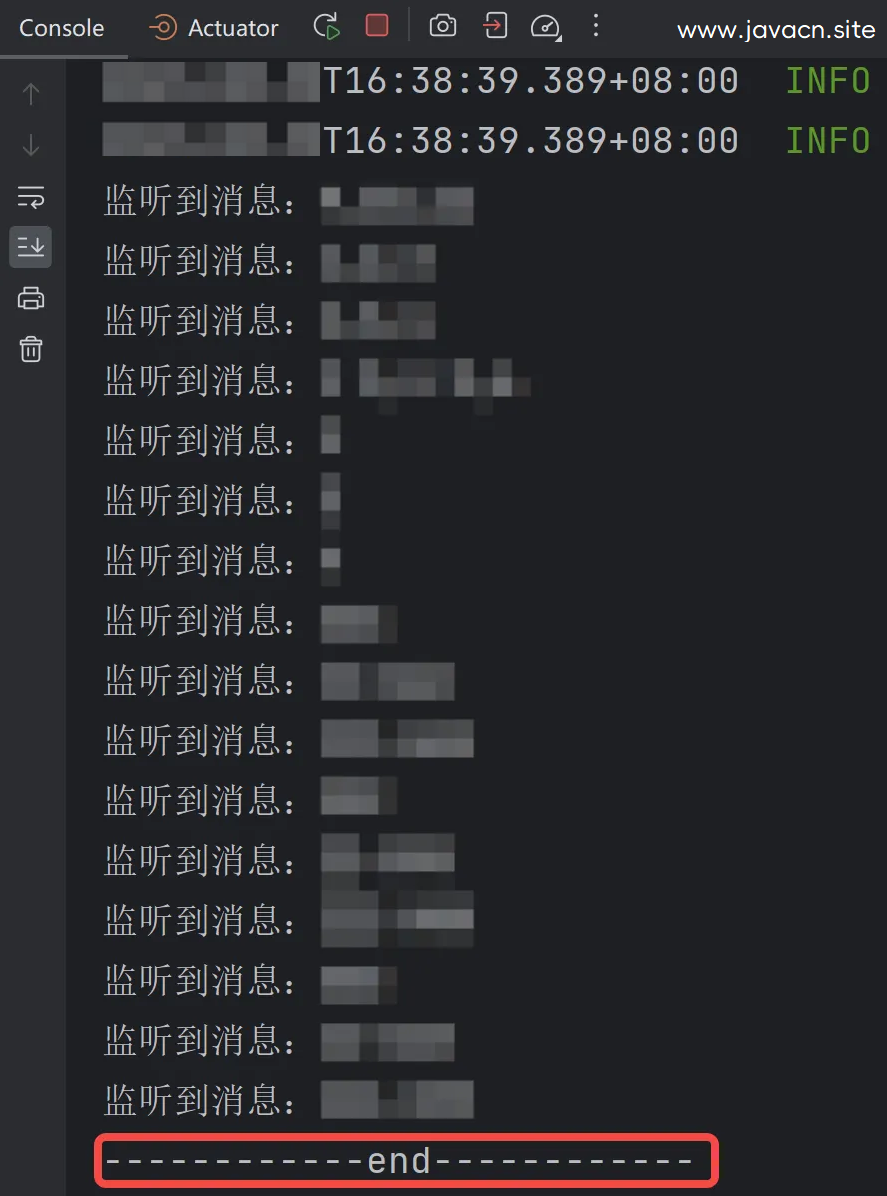 image.png
image.png - Стратегия очистки файла конфигурации:Корректирование flush.ms и flush.messages параметр,Управляет записью данных на диск. Меньшие значения уменьшают задержку,иБольшие значения могут повысить пропускную способность.。
- Оптимизация конфигурации потоков операций сети и ввода-вывода:num.network.threads должно быть установлено на CPU Количество ядер плюс 1. Полноценно использовать аппаратные ресурсы. Корректирование socket.send.buffer.bytes и socket.receive.buffer.bytes Чтобы оптимизировать размер сетевого буфера, чем больше буфер, тем выше пропускная способность. 5. Настройка JVM, потому что Kafka используется Java и Scala написано на двух языках,при этом Java и Scala Все бегутсуществовать JVM включено, так что это гарантировано JVM Эффективная работа и разумная настройка сборщика мусора также могут косвенно обеспечить Kafka эффективность работы. Например, для машины с большой памятью вы можете использовать G1 Сборщик мусора компактнее GC Время паузы,И оставьте достаточно памяти для операционной системы кэширования страниц. Мысли после занятий В дополнение к вышеперечисленным методам,мы все еще можемИспользуйте сжатие сообщений и другие средства для повышения эффективности работы Kafka.。Тогда возникает вопрос,Как включить Kafka сжатие сообщений? Как установить уровень сжатия сообщений?
Эта статья была включена на мой сайт интервью. www.javacn.site,Включенное содержимое: Redis, JVM, одновременно, одновременно, MySQL, Spring, Spring. MVC、Spring Boot、Spring Облако, MyBatis, шаблоны проектирования, очередь сообщений и другие модули.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
