Волшебный трансформер! 9 решений по оптимизации моделей для ускорения и повышения эффективности
Трансформер в настоящее время стал основной моделью в области искусственного интеллекта и широко используется. Однако механизм внимания в Transformer требует больших вычислительных затрат, и по мере увеличения длины последовательности объем вычислений будет продолжать увеличиваться.
Чтобы решить эту проблему, в отрасли было проведено множество преобразований Трансформатора для оптимизации эффективности работы Трансформатора. На этот раз я поделюсь с вами 9 улучшенными статьями, которые оптимизируют эффективность модели Трансформера, чтобы вы могли более эффективно использовать модель и находить инновационные моменты в статье.
В статье в основном рассматриваются четыре направления: механизм разреженного внимания, обработка длинного текста Трансформатором, повышение эффективности работы Трансформатора и свертка Внимание. Исходный текст и исходный код скомпилированы.
1. Механизм скудного внимания
1.1 Longformer: The Long-Document Transformer
Трансформатор длинных документов
«Краткое описание метода». Модели на основе преобразователей испытывают трудности с обработкой длинных последовательностей, поскольку их операции самообслуживания имеют квадратичную зависимость от длины последовательности. Longformer решает эту проблему, вводя механизм внимания, который линейно масштабируется в зависимости от длины последовательности, что позволяет ему легко обрабатывать документы из тысяч токенов и более. Longformer хорошо работает при моделировании языка на уровне символов и достигает самых современных результатов при выполнении множества последующих задач. Кроме того, Longformer также поддерживает задачи последовательной генерации длинных документов и продемонстрировал свою эффективность на наборе данных создания сводных данных arXiv.

1.2 Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Улучшите локальность и устраните узкое место памяти Transformer при прогнозировании временных рядов.
«Краткое описание метода:» Прогнозирование временных рядов является важной проблемой во многих областях, включая прогнозирование выработки энергии солнечными электростанциями, потребления электроэнергии и пробок на дорогах. В этой статье предлагается метод использования Transformer для решения этой проблемы прогнозирования. Хотя предварительные исследования показывают впечатляющую производительность, авторы обнаружили, что у него есть два основных недостатка: нечувствительность к локальности и узкие места в памяти. Чтобы решить эти две проблемы, авторы предлагают сверточное самообслуживание и LogSparse Transformer, которые могут лучше обрабатывать локальный контекст и снижать затраты памяти. Эксперименты показывают, что эти методы имеют преимущества при прогнозировании временных рядов.
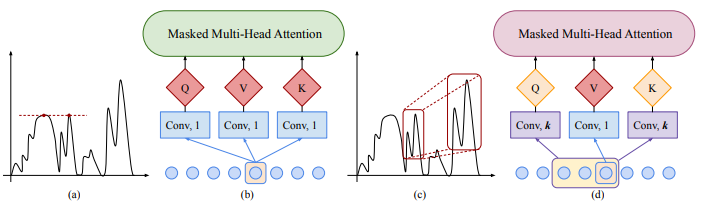
1.3 Adaptive Attention Span in Transformers
Адаптивная концентрация внимания в Трансформерах
«Краткое описание метода»: В статье предлагается новый механизм самообслуживания, который может научиться оптимальной продолжительности внимания. Это позволяет нам значительно расширить максимальный размер контекста, используемый в Transformers, сохраняя при этом контроль над объемом памяти и временем вычислений. Мы демонстрируем эффективность нашего подхода на задаче моделирования языка на уровне символов, где мы достигаем современной производительности на text8 и enwiki8, используя контексты длиной до 8 тысяч символов.
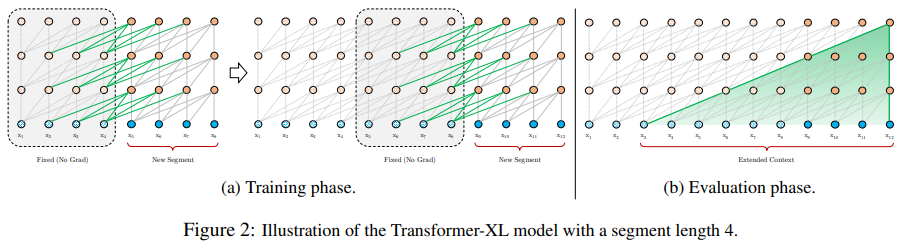
2. Трансформатор обрабатывает длинный текст
2.1 Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Языковые модели внимания за пределами контекста фиксированной длины
«Краткое описание метода»: Трансформаторы ограничены контекстом фиксированной длины в языковом моделировании. Автор предлагает новую архитектуру нейронной сети Transformer-XL, которая может изучать зависимости, выходящие за пределы фиксированной длины. Он состоит из механизма зацикливания на уровне сегмента и новой схемы позиционного кодирования, которая способна фиксировать более длинные зависимости и решать проблемы фрагментации контекста. Этот метод не только обеспечивает лучшую производительность как на коротких, так и на длинных последовательностях, но также в 1800+ раз быстрее, чем обычные Трансформеры во время оценки.
3. Повышение эффективности работы трансформатора.
3.1 REFORMER: THE EFFICIENT TRANSFORMER
Эффективный трансформатор
«Краткое описание метода:» Стоимость обучения больших моделей Трансформеров высока, особенно в длинных последовательностях. В документе предлагаются два метода повышения эффективности: использование локально-зависимого хеширования для замены внимания на скалярное произведение, снижение сложности с O(L^2) до O(L log L) с использованием обратимого остаточного слоя для замены стандартного остатка; позволяет; сохраняется только одна активация. Полученная в результате модель реформатора работает сравнимо с длинными последовательностями, но более эффективно использует память и работает быстрее.

3.2 RETHINKING ATTENTION WITH PERFORMERS
Переосмысление механизма внимания: модель исполнителя
«Краткое описание метода»: В документе представлены Performers, архитектура Transformer, которая может оценивать обычные (softmax) Трансформаторы внимания полного ранга с доказуемой точностью, но только с использованием линейной пространственной и временной сложности. Чтобы аппроксимировать ядро внимания softmax, Performers использует новый метод быстрого внимания с помощью ортогональных случайных функций (FAVOR+), который можно использовать для эффективного моделирования механизмов внимания, допускающих ядро.
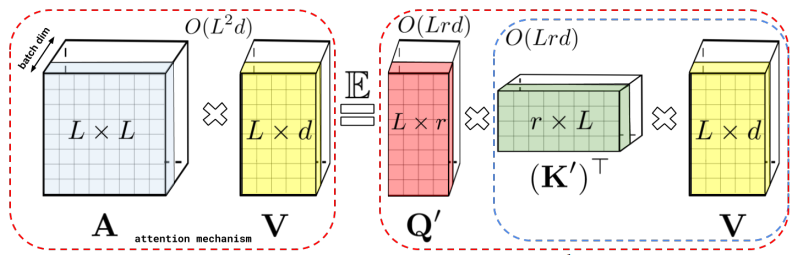
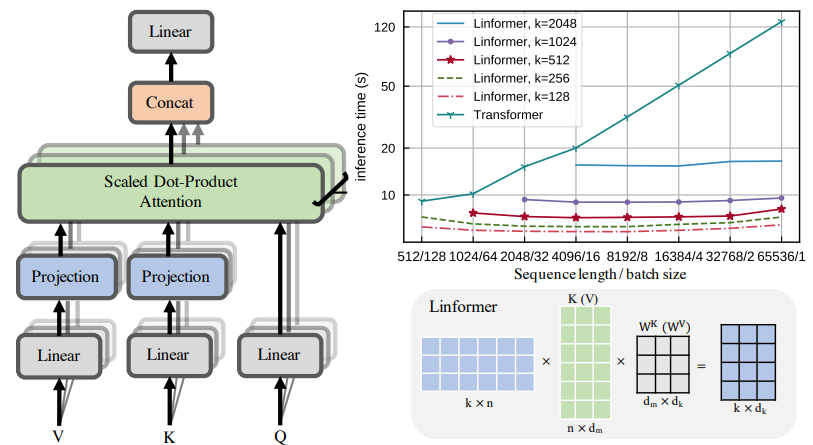
3.3 Linformer: Self-Attention with Linear Complexity
Механизм самообслуживания с линейной сложностью
«Краткое описание метода». Модели больших трансформаторов хорошо работают в приложениях обработки естественного языка, но затраты на обучение и развертывание длинных последовательностей высоки. В этой статье предлагается новый механизм самообслуживания, который снижает сложность с O(n^2) до O(n), сохраняя при этом ту же производительность. Полученный Linformer более эффективен по времени и памяти, чем стандартный Transformer.
4. Внимание к свертке
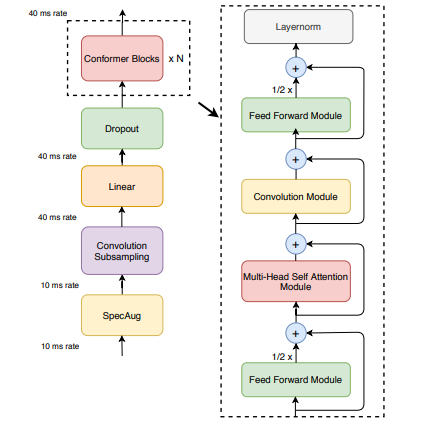
4.1 Conformer: Convolution-augmented Transformer for Speech Recognition
Сверточный расширенный преобразователь для распознавания речи
«Краткое описание метода:» Конформер — это модель, сочетающая в себе сверточные нейронные сети и Трансформер для распознавания речи. Он способен одновременно фиксировать локальные и глобальные зависимости аудиопоследовательностей и достигать высочайшей точности. В тесте LibriSpeech Conformer достиг показателя WER 2,1%/4,3% без использования языковой модели и показателя WER 1,9%/3,9% с внешней языковой моделью. Кроме того, у него есть конкурентоспособная небольшая модель всего с 10M параметрами.
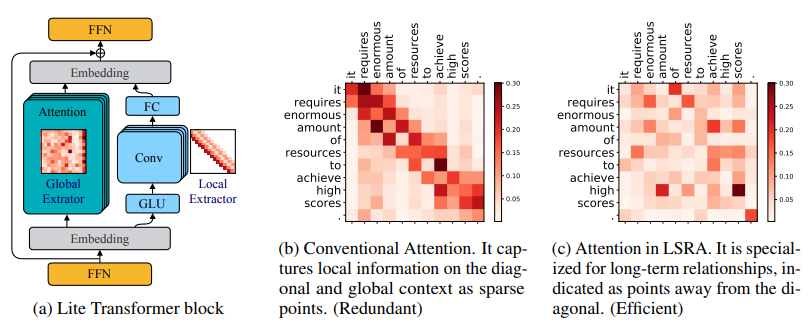
4.2 LITE TRANSFORMER WITH LONG-SHORT RANGE ATTENTION
Легкий трансформер с вниманием на дальних и ближних дистанциях.
«Краткое описание метода». В этом документе предлагается эффективная мобильная архитектура обработки естественного языка Lite Transformer, которая использует внимание на дальнем и близком расстоянии (LSRA) для повышения производительности. LSRA выделяет один набор глав для моделирования локального контекста (посредством свертки), а другой набор глав — для моделирования долгосрочных отношений (посредством внимания). По трем языковым задачам Lite Transformer стабильно превосходит обычный Transformer. В условиях ограниченных ресурсов Lite Transformer превзошел Transformer на 1,2/1,7 балла BLEU в задаче перевода WMT’14 с английского на французский язык.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
