Внутренняя система ускорения обучения моделей Goose Factory размером в триллион долларов запущена в общедоступном облаке!


👉Введение Тэн Сяоюнь
С появлением ChatGPT люди обращают все больше и больше внимания на важность моделей обучения с большими параметрами. Однако по мере того, как масштаб параметров продолжает увеличиваться, требования к вычислительной мощности и памяти, необходимые для модели, также растут. Чтобы снизить затраты на обучение больших моделей, Tencent запустила AngelPTM Тренировочная рамка. Учитывая горячую тенденцию в последнее время в сфере Большая Модель, мы решили внедрить внутреннюю зрелую систему. AngelPTM рамкапропаганда большинству людей публичное пользователей облака, чтобы помочь энтузиастам разработки сократить бизнес-затраты и повысить эффективность.
👉Посмотрите каталог и нажмите «Избранное»
1 Введение в технические принципы AngelPTM
1.1 ZeRO-Cache Стратегия оптимизации
1.2 Единое перспективное управление хранилищем
1.3 Единое перспективное управление хранилищем
1.4 Единое перспективное управление хранилищем
1.5 Единое перспективное управление хранилищем
1.6 Единое перспективное управление хранилищем
1.7 От кластерно-ориентированного к прикладно-ориентированному планированию и оркестровке
2 Эффект ускорения обучения большой модели
3 Резюме
В последнее время ChatGPT добился больших успехов во многих областях благодаря своим мощным возможностям понимания языка, генерации текста, диалоговым возможностям и т. д., положив начало новой волне искусственного интеллекта. ChatGPT, GPT3 и GPT3.5 объединены на основе архитектуры Transformer. Исследования показали, что по мере увеличения объема обучающих данных и емкости модели способность модели к обобщению и выражению может постоянно улучшаться, а исследования больших моделей стали тенденцией за последние два года. Ведущие технологические компании в стране и за рубежом имеют планы на этот счет и выпустили несколько крупных моделей масштабом более 100 миллиардов, как показано на рисунке ниже:
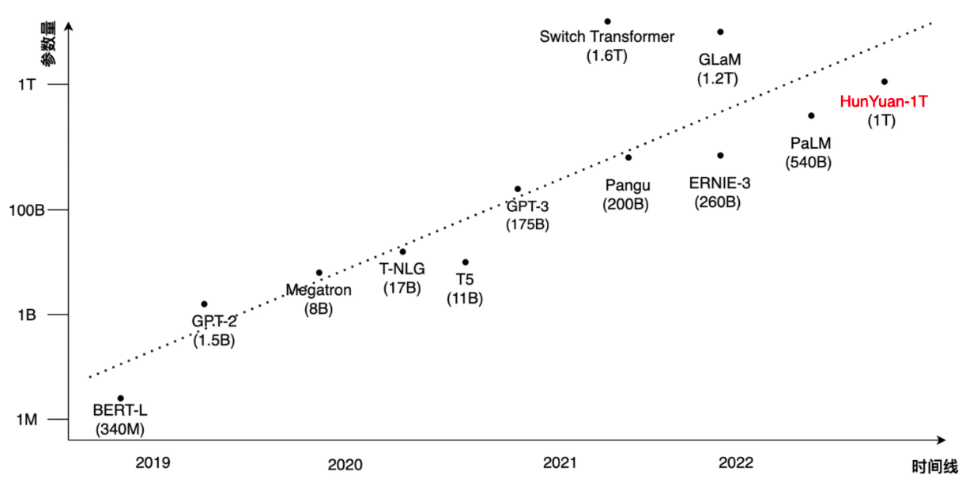
В последние годы масштаб моделей предварительного обучения НЛП вырос с сотен миллионов до триллионов параметров. В частности, максимальное количество параметров модели BERT в 2018 году составляло 340 миллионов, а GPT-2 в 2019 году представляла собой модель с миллиардами параметров. Среди выпущенных в 2020 году — T5 и T-NLG с десятками миллиардов параметров, а также GPT-3 с сотнями миллиардов параметров. В конце 2021 года Google выпустила SwitchTransformer, который впервые увеличил размер модели до триллионов параметров. Однако скорость разработки аппаратного обеспечения графических процессоров трудно удовлетворить потребности масштабной разработки моделей трансформаторов. За последние четыре года количество параметров модели увеличилось в 100 000 раз, однако объем памяти графического процессора увеличился всего в 4 раза.

Например, для обучения модели масштаба в триллион требуется более 1,7 ТБ места для хранения только параметров и статуса оптимизатора, что требует не менее 425 A100-40G. Это не включает хранилище, необходимое для значений активации, сгенерированных в процессе обучения. В этом контексте обучение больших моделей ограничено не только огромными вычислительными мощностями, но и огромными требованиями к хранению данных.
Решения для предварительного обучения крупных моделей в отрасли в основном включают в себя DeepSpeed от Microsoft и Megatron-LM от NVIDIA. DeepSpeed представляет оптимизатор ZeRO (Zero Redundancy Optimizer) для распределения параметров модели, градиентов и статуса оптимизатора по различным обучающим картам по требованию для удовлетворения экстремальных требований к хранению больших моделей. Megatron-LM основан на 3D-параллельности (тензорной параллели, Конвейерный параллелизм, параллелизм данных) разделяет параметры модели для удовлетворения требований обучения больших моделей в условиях ограниченных ресурсов видеопамяти.
Tencent также имеет большой бизнес по предварительному обучению крупных моделей. Чтобы обучать большие модели с наименьшими затратами и максимальной производительностью, существует платформа машинного обучения Taiji. DeepSpeed и Megatron-LM Проведены и запущены глубокая настройка и оптимизация AngelPTM учебный кадр 2022 года. Год 4 Опубликовано TencentБольшая модель Hunyuan AIудобныйдана основе AngelPTM рамкаобученная. Ниже приведено подробное представление:
01
Введение в технические принципы AngelPTM
1.1 ZeRO-Cache Стратегия оптимизации
ZeRO-Cache да Инструмент для сверхкрупномасштабного обучения Модели, как показано на рисунке ниже, он управляет памятью и видеопамятью с единой точки зрения, существует, устраняет избыточность состояния Модели, одновременно расширяя верхний предел доступного пространства хранилища для одной машины, посредством Contiguous Memory Менеджер видеопамяти, управляет выделением/освобождением видеопамяти параметров Модели для уменьшения фрагментации видеопамяти, балансирует нагрузку каждого аппаратного ресурса посредством многопотоковой передачи и использует положение SSD Дальнейшее расширение возможностей автономных моделей.
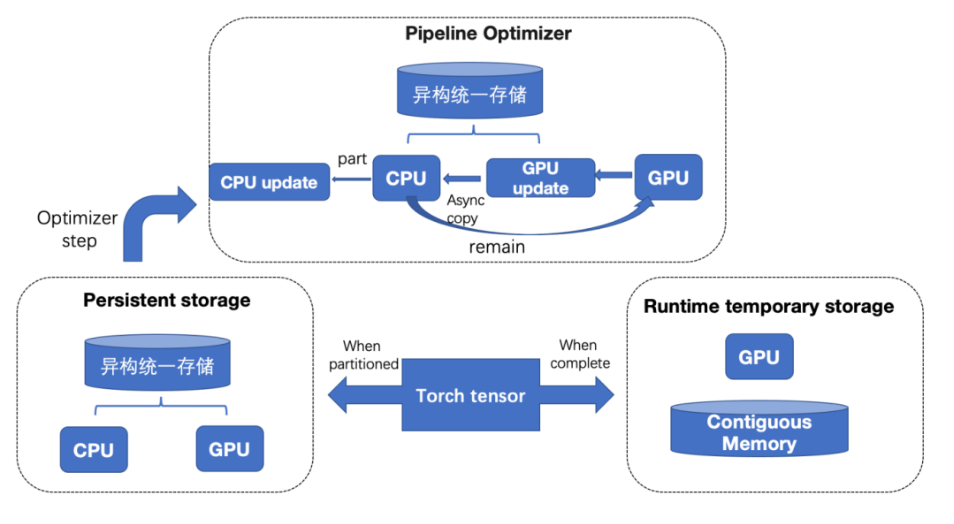
Обзор ZeRO-Cache
1.2 Единое перспективное управление хранилищем
При обучении большой модели статус модели находится по адресу CPU В память он будет скопирован во время обучения GPU видеопамять, что приводит к избыточному хранению состояния модели (ЦП и GPU Одновременно имеется один экземпляр), кроме того, большое количество pin memory,pin memory Использование улучшит производительность, но также приведет к большой трате физической памяти. Как использовать ее научно и рационально? pin memory да ZeRO-Cache важная проблема, которую нужно решить.
Основанный на концепции устранения чрезмерной избыточности, AngelPTM представил chunk Управляйте памятью и видеопамятью, чтобы гарантировать, что все состояния Модели будут использоваться только хранилищем. Обычно Модель будет хранить существующую память. or На видеопамяти ZeRO-Cache представлять Гетерогенное единствохранилище,Используйте память и видеопамять вместе в качестве места хранения.,Ломая барьеры гетерогенных хранилищ,Значительно расширено доступное пространство в Модельхранилище.,Как показано в левой части рисунка ниже:
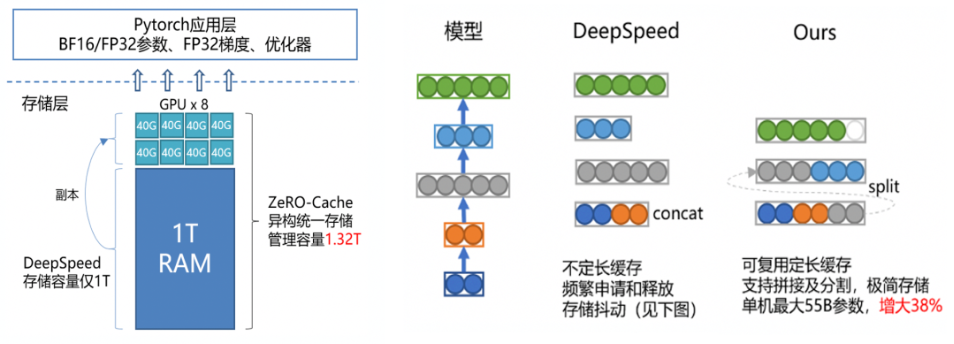
Единое управление визуальным хранилищем
Базовый механизм хранения собственного Tensor в ЦП крайне нестабилен в отношении фактического использования занимаемого пространства памяти. Чтобы решить эту проблему, AngelPTM реализует базовое сегментированное хранилище Tensor, которое значительно расширяет доступное пространство хранения на одной машине и позволяет избежать ненужных потерь. Объем памяти контактов значительно увеличивает верхний предел модели, которую может загрузить одна машина, как показано в правой части рисунка выше.
1.3 ZeRO-Cache Менеджер видеопамяти
PyTorch В комплекте менеджер видеопамяти Может Cache Почти вся видеопамять выделяется в два раза быстрее. Когда нагрузка на видеопамять невелика, этот метод выделения видеопамяти может обеспечить оптимальную производительность. Однако для очень крупномасштабных параметров это приведет к резкому увеличению нагрузки на видеопамять. из-за градиента Частое выделение параметров видеопамяти приводит к значительному увеличению фрагментации видеопамяти, PyTorch Allocator Увеличение количества неудачных попыток выделения видеопамяти приводит к резкому снижению производительности обучения.
Для этого ZeRO-Cache Представлен Contiguous Memory Менеджер видеопамяти, как показано на картинке ниже, ее существование PyTorch Allocator Управление выделением вторичной видеопамяти выполняется выше. Все выделение и освобождение видеопамяти, необходимые для параметров во время процесса обучения, выполняются с помощью. Contiguous Memory Единое управление, которое не используется при реальном обучении больших моделей. Contiguous Memory Графическая память, эффективность распределения и фрагментация были значительно улучшены, а также значительно улучшена скорость обучения модели.
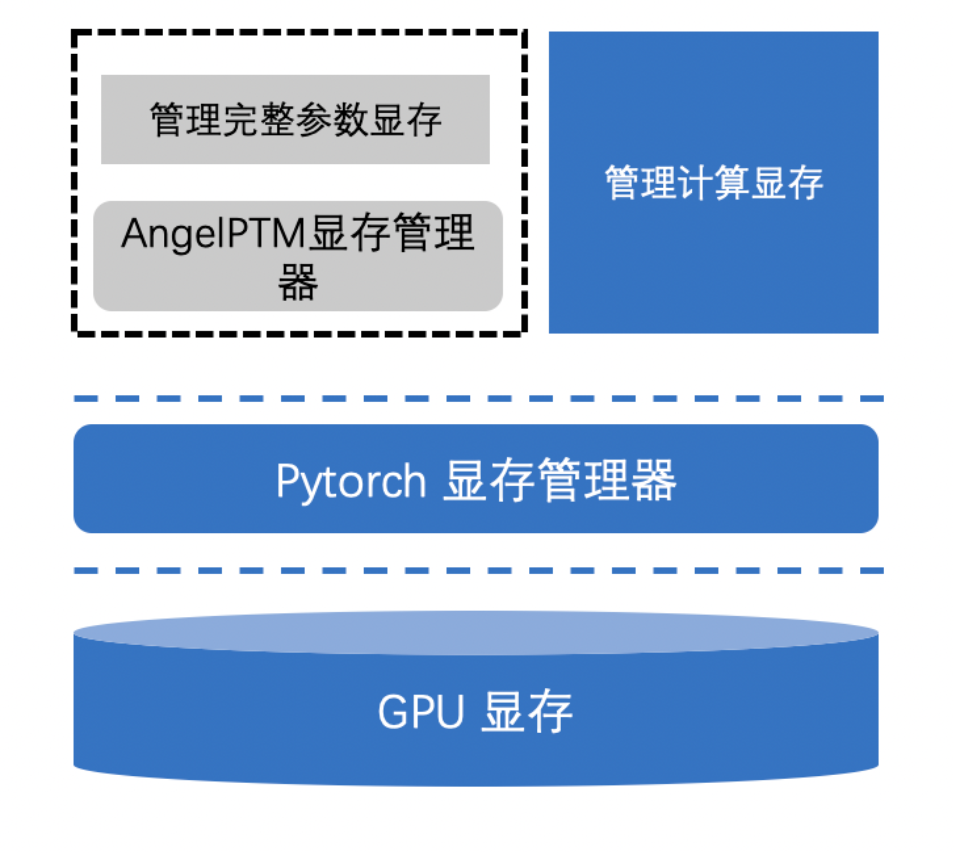
ZeRO-Cache Менеджер видеопамяти
1.4 PipelineOptimizer
ZeRO-Infinity использовать GPU или CPU Обновите параметры Модели, особенно да для большой Модели, которую можно только передать. CPU обновить параметры, потому что CPU Скорость обновления параметров связана с GPU В обновлении параметров наблюдается разрыв в десятки раз, а обновление параметров может составлять почти половину всего времени обучения модели. CPU При обновлении параметров GPU В режиме ожидания видеопамять простаивает, что приводит к огромной трате ресурсов.
Как показано на рисунке ниже, ZeRO-Cache Он начнется после расчета градиента параметров модели. Cache Статус оптимизатора модели достигает GPU видеопамяти и асинхронно при обновлении параметров Host и Device Передача данных о состоянии модели между CPU и GPU Параметры обновляются одновременно. ZeRO-Кэш pipeline статус модели H2D, обновление параметров, статус модели D2H,Максимизируйте аппаратные ресурсы,Не оставляйте аппаратные ресурсы бездействующими.
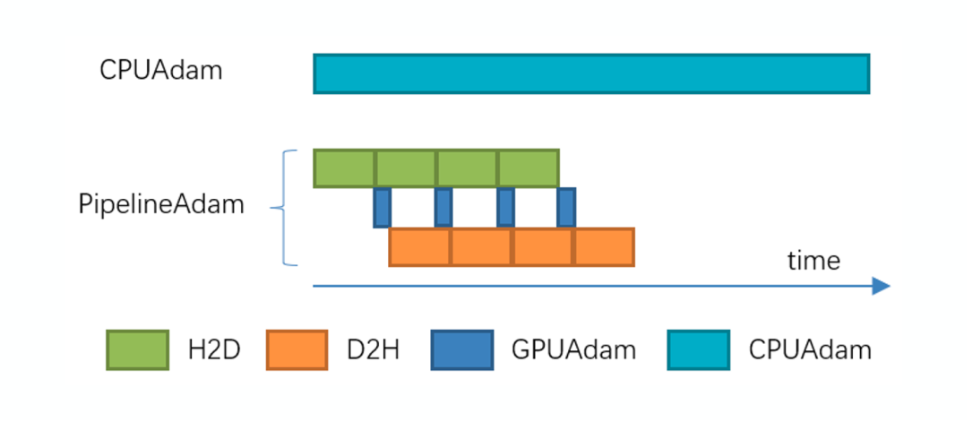
PipelineAdam
Кроме того, Ангел ПТМ Саморазвитые гетерогенные Adafactor Оптимизатор, как показано ниже, поддерживает CPU и GPU Параметры обновляются одновременно, что может уменьшить 33% Пространство для хранения состояний модели также может повысить точность обучения модели.
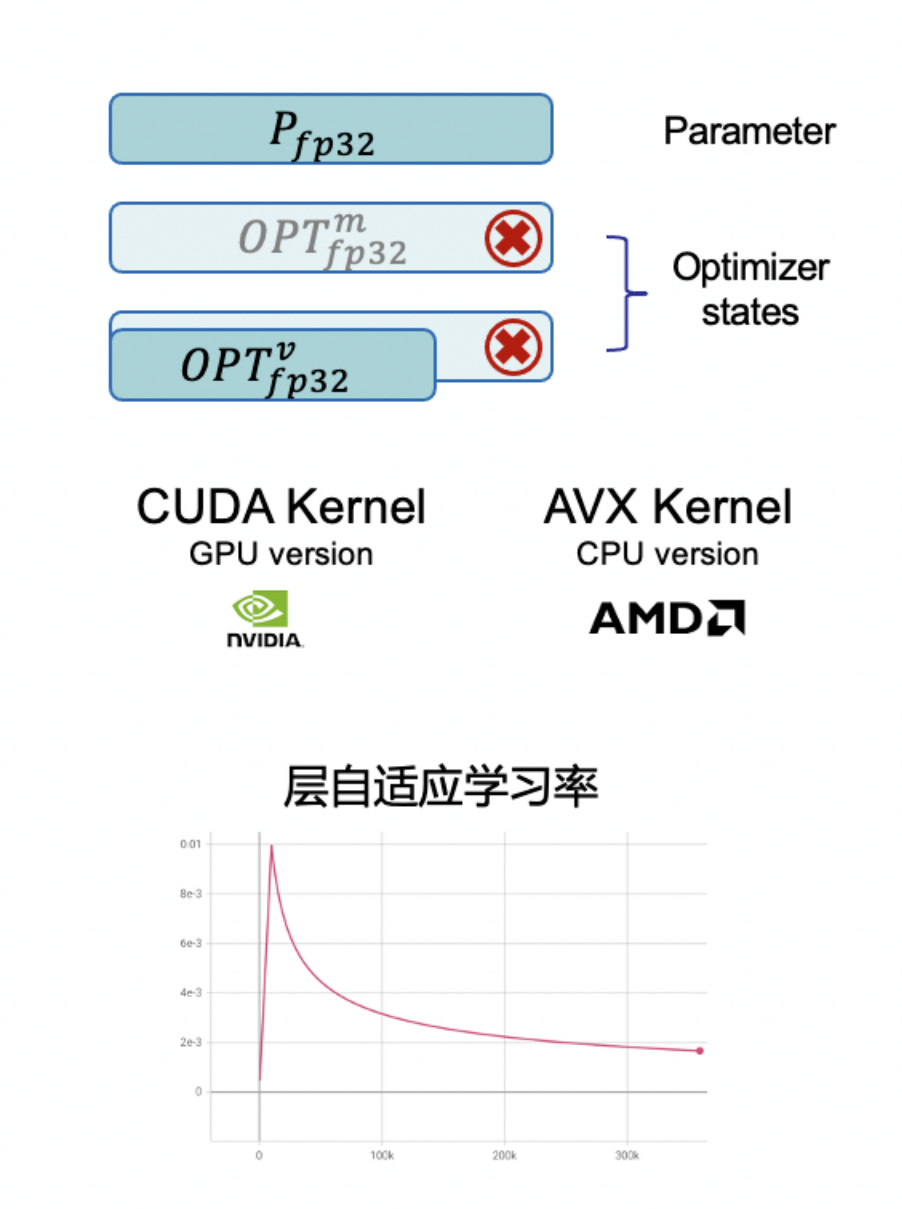
Гетерогенный Адафактор
1.5 Многопоточный асинхронный
большой Модель训练过程中有большой量的计算икоммуникация,включать GPU Вычисления, H2D и D2H Автономная связь, NCCL Многомашинная связь и т. д., используемое оборудование GPU、CPU、PCIE ждать.
Как показано на рисунке ниже, ZeRO-Cache Чтобы максимально использовать аппаратное обеспечение, Многопоточный асинхронный GPU Вычисления, H2D и D2H Автономная связь, NCCL Межмашинная связь, предварительная выборка параметров использует механизм синхронизации времени, а градиентная постобработка использует межмашинную связь. buffer механизм, копия состояния оптимизатора использует многопоточный механизм.

Многопотоковые вычислительные коммуникации
1.6 ZeRO-Cache SSD рамка
Чтобы расширить параметр «Модель» более экономично, как показано на рисунке ниже, ZeRO-Cache Далеепредставил SSD В качестве третичного хранилища для GPU Высокая вычислительная производительность, высокая пропускная способность связи SSD Низкий PCIE пропускная способность между GAP,ZeRO-Cache разместить все fp16 параметры и градиент в память, пусть foward и backward На расчет не влияет SSD Низкое влияние на полосу пропускания, смягчаемое сжатием состояния оптимизатора с половинной точностью. SSD Влияние чтения и письма на производительность.
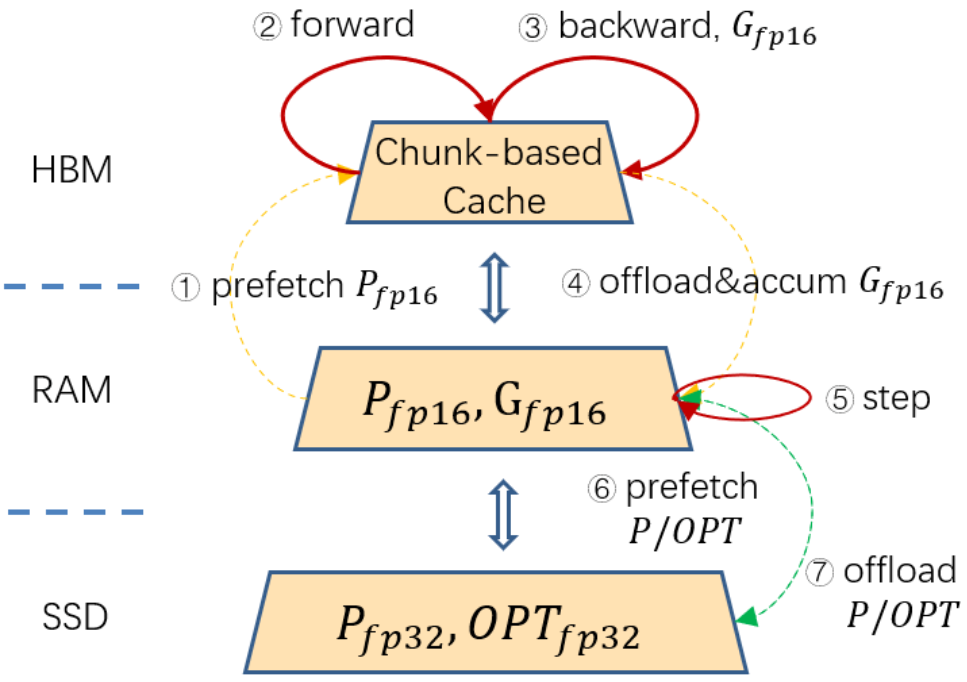
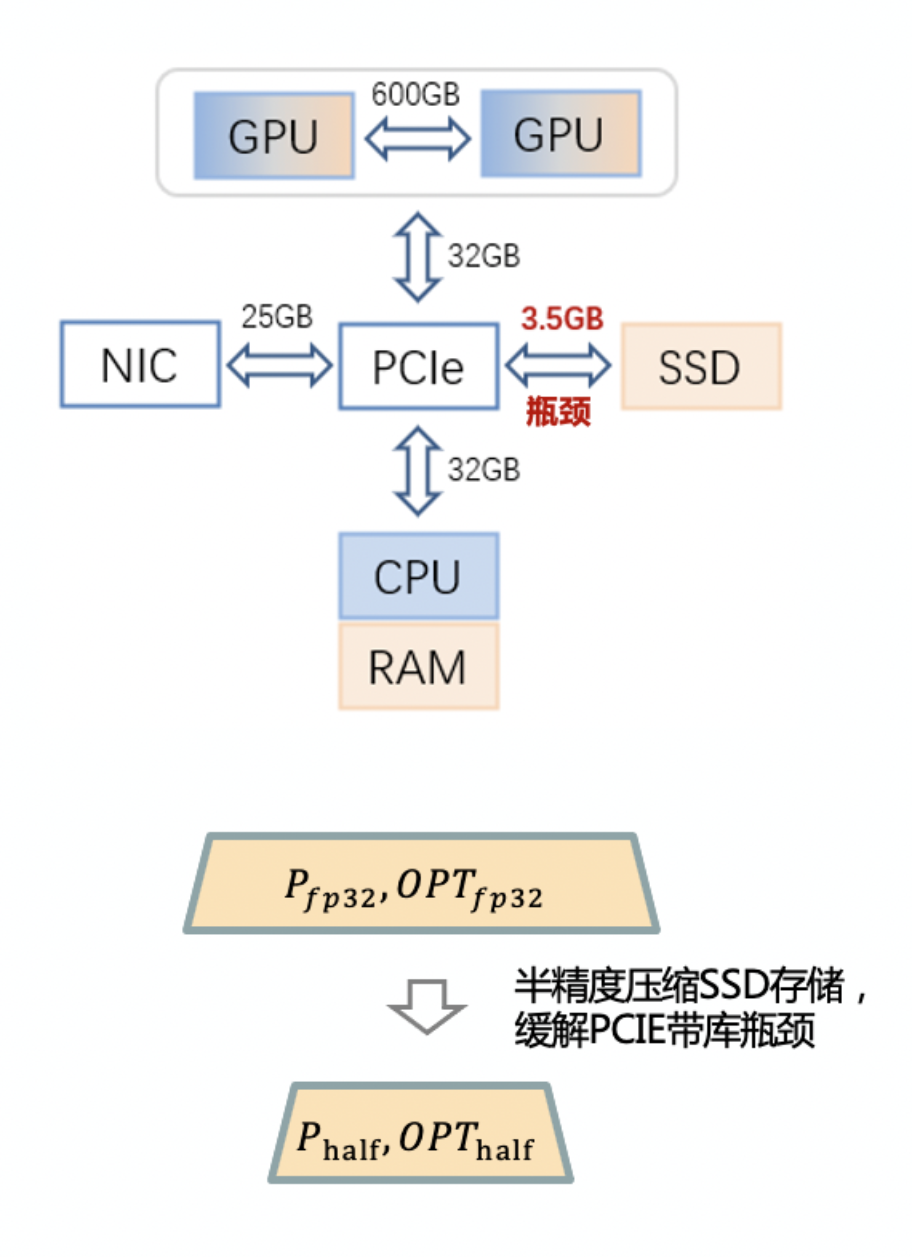
ZeRO-Cache SSDрамка
02
Эффект ускорения обучения большой модели
Информация о версии решения, используемая в тесте, следующая:
план | DeepSpeed | Megatron-DeepSpeed |
|---|---|---|
сообщество | 0.8.1+258d2831 | 7212b58 |
AngelPTM план | 0.6.1+474caa20 | c5808e0 |
Примечание. Версии других сред, например OS/python/CUDA/cuDNN/pytorch и т. д., согласованы. |
|---|
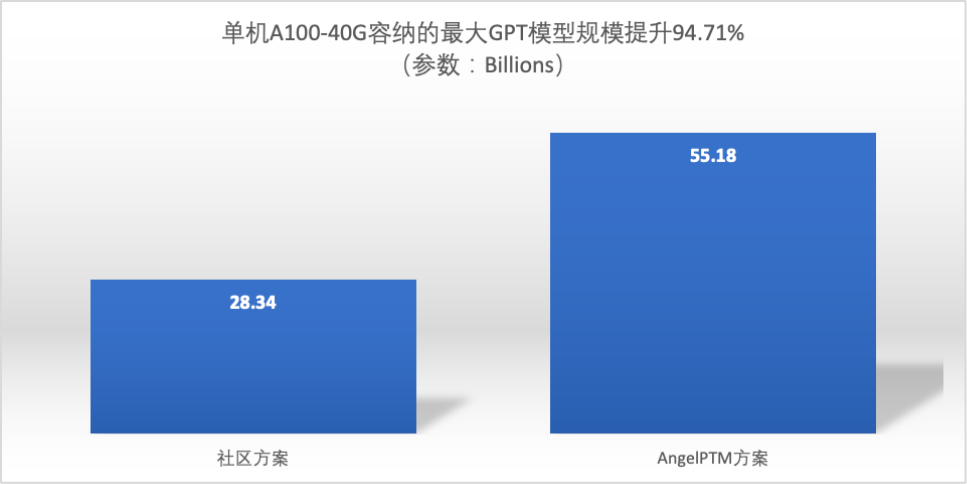
Максимальный размер модели
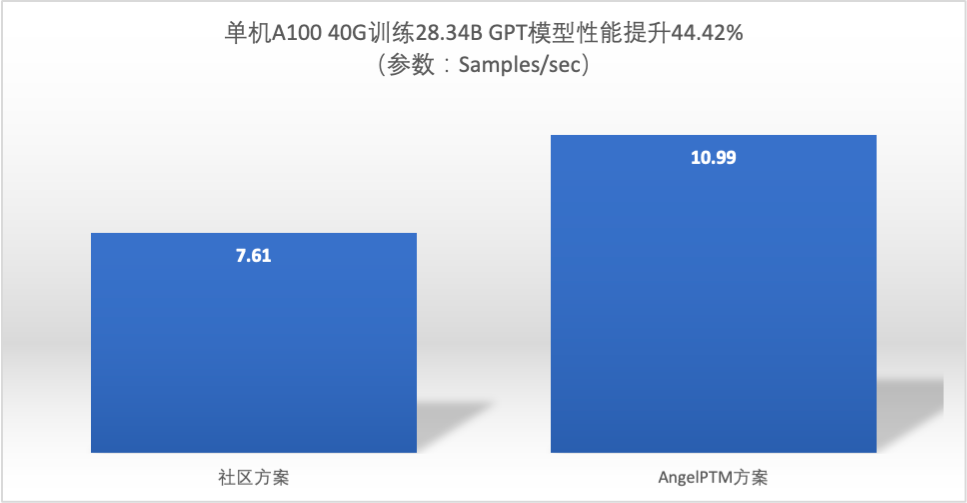
Производительность обучения на модели того же размера
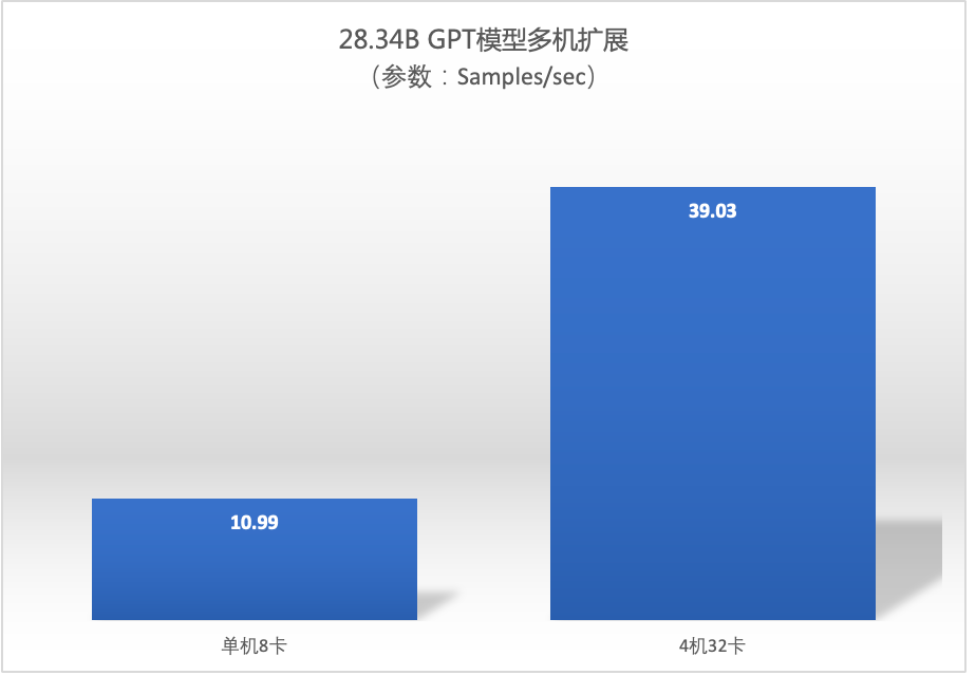
Коэффициент расширения нескольких машин
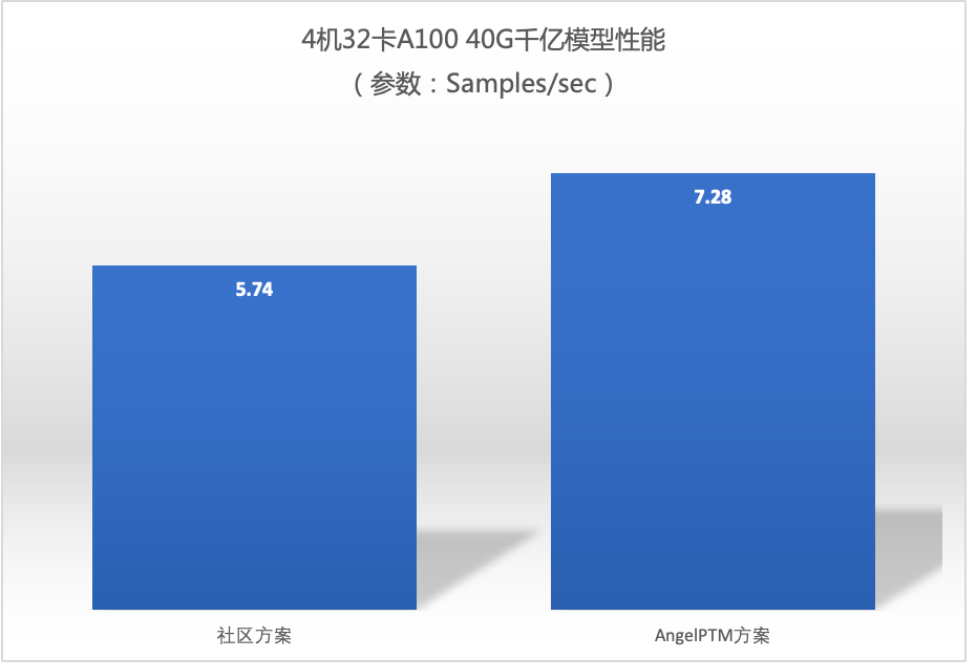
Сотни миллиардов производительности модели
Примечание. Степень улучшения (26,8%) производительности обучения на 4 машинах с 32 картами снизилась по сравнению с производительностью на одной машине, главным образом из-за ограничений пропускной способности сети. да использовал здесь 100Gbps RDMA Network, Tencent Cloud в будущем запустит более высокую пропускную способность RDMA Ожидается, что повышение производительности высокопроизводительного вычислительного кластера будет близко к повышению производительности одной машины. |
|---|
03
Подвести итог
В AngelPTM добавлен компонент ускорения TACO Train, который помогает значительно улучшить лимит памяти и производительность обучения больших моделей.
Tencent Cloud придерживается первоначального намерения решать практические бизнес-задачи клиентов и создавать дополнительную ценность. Оно не только позволяет клиентам надежно вести свой бизнес в облаке, но также помогает клиентам по-настоящему воспользоваться преимуществами экономичных вычислительных мощностей облачных серверов. . мы надеемся пройти TACO Train、TACO Infer、qGPU Общие технологии и другие программные продукты с добавленной стоимостью,Помогите клиентам повысить эффективность вычислений,Сократите расходы бизнеса,Сформировать модель долгосрочного сотрудничества для устойчивого развития.
TACO Train добавляет компонент ускорения обучения AngelPTM в сочетании с высокопроизводительным вычислительным кластером HCC для достижения:
- AngelPTM Будет автономным A100 40G, можно разместить Модель увеличена на 94,71%
- на на основе плана сообщества наибольший размер модели, который может вместиться, AngelPTM производительностьулучшенный44.42%
- Сотни миллиардов Модельв масштабе,AngelPTM Коэффициент расширения нескольких машин близок к линейному
будущее, кроме AngelPTM Компонент ускорения большой модели, TACO Train Также будет запущен TCCL Библиотека связи с коллекцией, функция динамической компиляции поддерживает ожидание. TACO Train Постоянное развитие и использование TACO Train Прирост производительности будет все выше и выше.
Вышеупомянутое да на этот раз делится всем контентом,Приглашаем всех поделиться и пообщаться в области комментариев. Если вы считаете контент полезным,Добро пожаловать вперед ~
-End-
Первоначальный автор | Инженер-эксперт по гетерогенным вычислениям Tencent Cloud Фэн Кэхуань
Технический редактор Tencent, эксперт по облачным гетерогенным вычислениям Фэн Кэхуань




WeChat недавно был обновлен
Многие друзья-разработчики сообщили, что не могут получать наши обновленные статьи.
большой家МожетСледуй и зажги звезду
Никогда не пропустите экспресс-презентацию Сяоюнь🥹





Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
