[Весна] SpringBoot интегрирует ShardingSphere и реализует многопоточную вставку 10 000 фрагментов данных в пакетном режиме (выполнение операций с базой данных и таблицами).
ShardingSphere — это экосистема, состоящая из набора промежуточных программных решений для распределенных баз данных с открытым исходным кодом. Она состоит из трех независимых продуктов: Sharding-JDBC, Sharding-Proxy и Sharding-Sidecar (планируется). Все они обеспечивают стандартизированное сегментирование данных, распределенные транзакции и функции управления базами данных и могут применяться к различным сценариям приложений, таким как изоморфизм Java, гетерогенные языки, контейнеры, облачные решения и т. д. ShardingSphere позиционируется как промежуточное программное обеспечение для реляционных баз данных, целью которого является полное и разумное использование вычислительных возможностей и возможностей хранения реляционных баз данных в распределенных сценариях, а не реализация новой реляционной базы данных. Он сосуществует с NoSQL и NewSQL, но не является взаимоисключающим. Поскольку NoSQL и NewSQL находятся в авангарде исследования новых технологий, настоятельно рекомендуется смотреть в будущее и принимать изменения. Напротив, можно посмотреть на проблему и по-другому, посмотреть в будущее, сосредоточиться на вещах, которые остаются неизменными, а затем уловить суть вещей. Реляционные базы данных сегодня по-прежнему занимают огромный рынок и являются краеугольным камнем основного бизнеса каждой компании. В будущем их будет трудно поколебать. На данном этапе мы больше сосредоточены на приращениях, основанных на исходной основе, а не на подрывной деятельности. ----От официального
1.Sharding-JDBC
Позиционируемый как облегченная платформа Java, он предоставляет дополнительные сервисы на уровне Java JDBC. Он использует клиент для прямого подключения к базе данных и предоставляет услуги в виде jar-пакетов без дополнительного развертывания и зависимостей. Его можно понимать как расширенную версию драйвера JDBC, и он полностью совместим с JDBC и различными платформами ORM.
- Применимо к любой платформе ORM на основе Java, такой как: JPA, Hibernate, Mybatis, Spring JDBC Template или напрямую использовать JDBC.
- Пул соединений на основе любой сторонней библиотеки данных, такой как: DBCP, C3P0, BoneCP, Druid, HikariCP и др.
- Поддерживает любую библиотеку данных, реализующую спецификацию JDBC. В настоящее время поддерживает MySQL,Oracle,SQLServer и PostgreSQL.
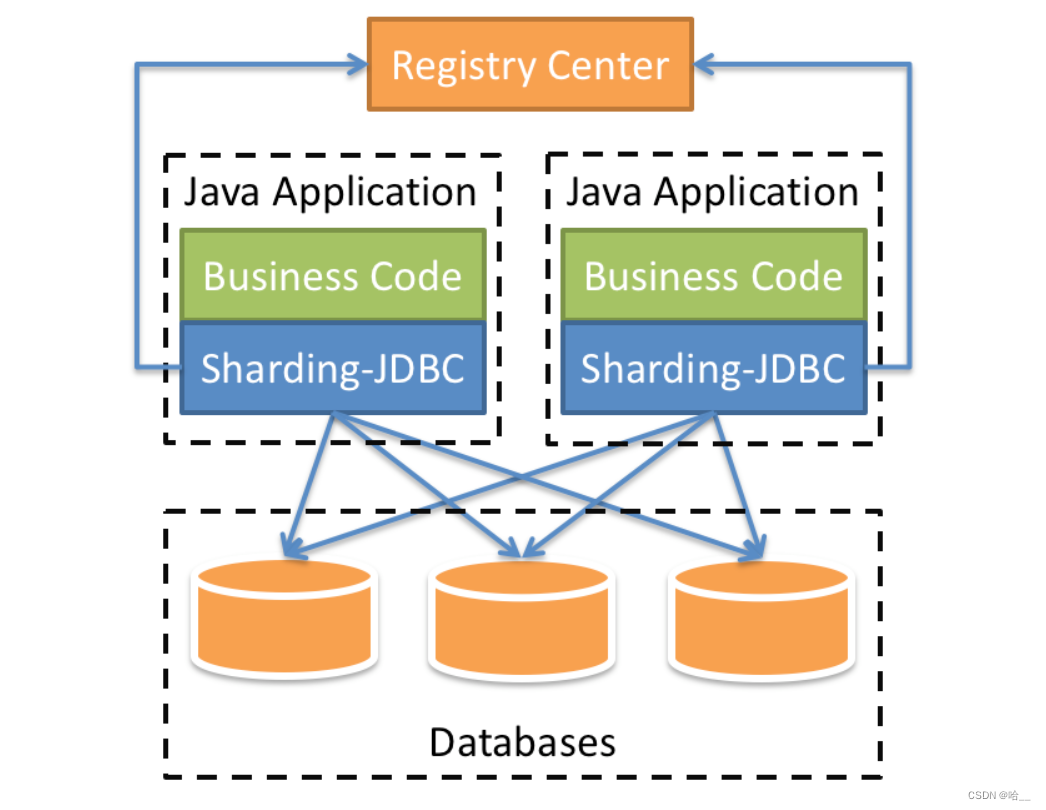
2.Sharding-Proxy
Позиционируясь как прозрачный агент базы данных, он предоставляет серверную версию, которая инкапсулирует двоичный протокол базы данных для поддержки гетерогенных языков. В настоящее время первой предоставляется версия MySQL, которая может использовать любой клиент доступа, совместимый с протоколом MySQL (например, MySQL Command Client, MySQL Workbench и т. д.), для работы с данными, что делает его более удобным для администраторов баз данных.
- Он полностью прозрачен для приложения и может использоваться непосредственно как MySQL.
- Работает с любым клиентом, совместимым с протоколом MySQL.
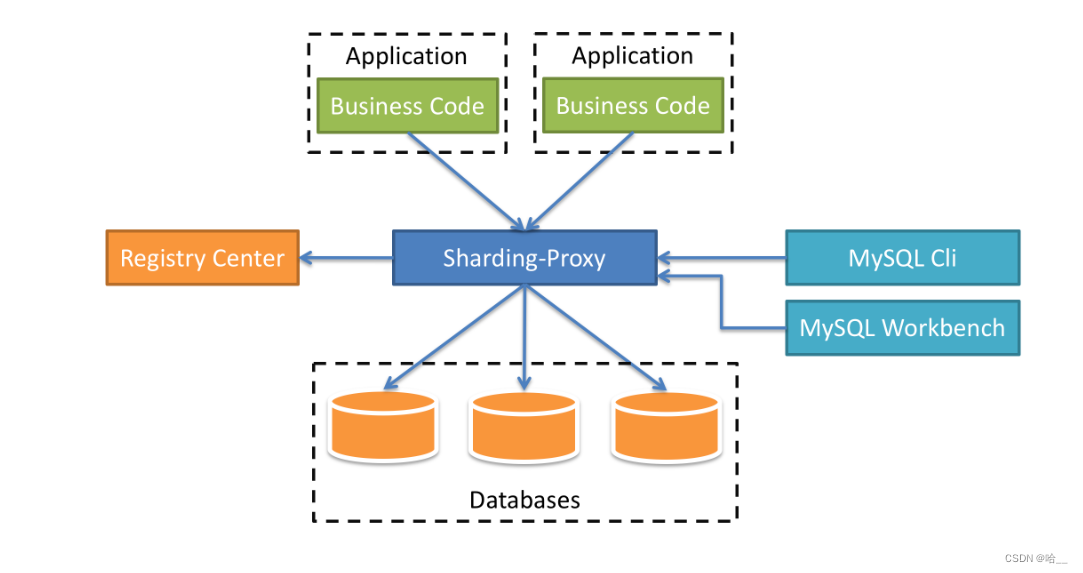
3.Sharding-Sidecar(TBD)
Позиционируясь как облачный прокси-сервер базы данных для Kubernetes или Mesos, он проксирует весь доступ к базе данных в форме DaemonSet. С помощью бесцентрового решения с нулевым вмешательством мы предоставляем уровень взаимодействия, который взаимодействует с базой данных, а именно сетку базы данных, также известную как сетка данных. Основное внимание в Database Mesh уделяется органическому соединению приложений распределенного доступа к данным и базам данных. Он больше фокусируется на взаимодействии и эффективной сортировке взаимодействий между беспорядочными приложениями и базами данных. При использовании сетки базы данных приложения и базы данных, которые обращаются к базе данных, в конечном итоге образуют огромную сеточную систему. Приложения и базы данных необходимо только зарегистрировать в сеточной системе. Все они являются объектами, управляемыми слоем сетки.
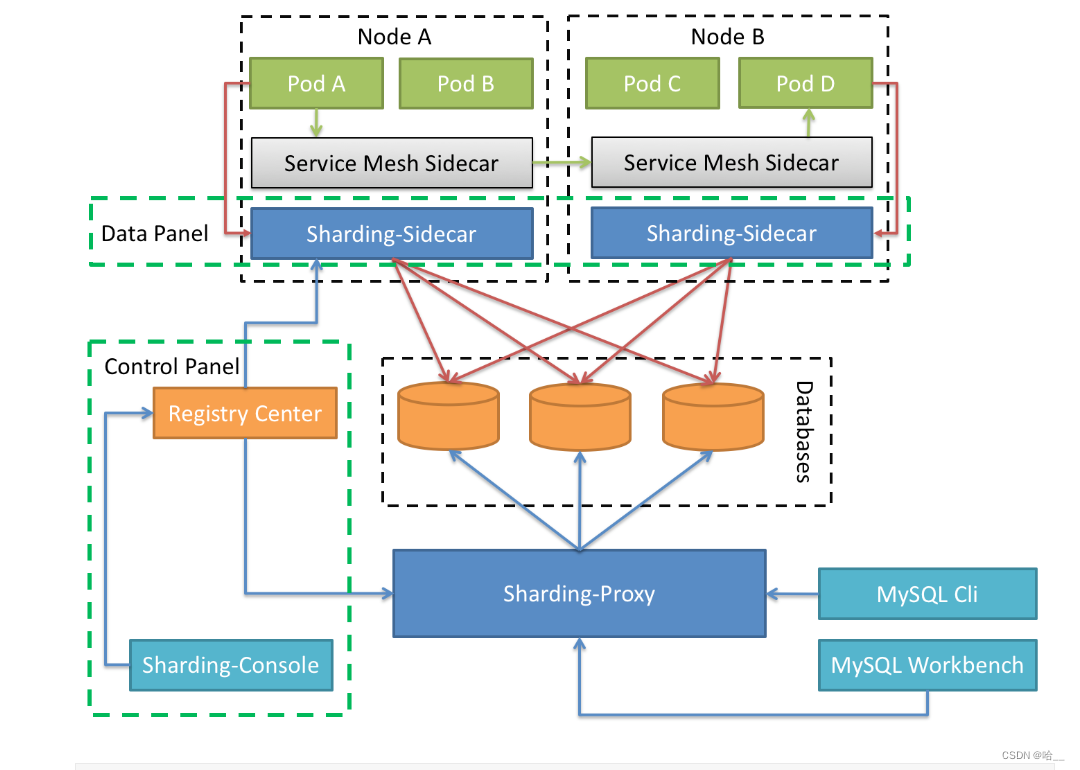
2. Зачем использовать ShardingSphere?
С точки зрения производительности, поскольку большинство реляционных баз данных используют индексы типа дерева B+, когда объем данных превышает пороговое значение, увеличение глубины индекса также приведет к увеличению количества обращений к диску ввода-вывода, что приведет к снижению производительности запросов; В то же время высокий уровень одновременных запросов на доступ также делает централизованную базу данных самым узким местом системы. С точки зрения доступности, тип сервиса без сохранения состояния позволяет добиться произвольного расширения при относительно небольших затратах, что неизбежно приведет к конечному давлению системы на базу данных. Однако единый узел данных или простая архитектура «главный-подчиненный» становятся все более недоступными. Доступность базы данных стала ключом ко всей системе. С точки зрения затрат на эксплуатацию и обслуживание, когда объем данных в экземпляре базы данных превышает пороговое значение, нагрузка на администратора базы данных при эксплуатации и обслуживании возрастает. Временные затраты на резервное копирование и восстановление данных будут становиться все более неконтролируемыми с увеличением размера данных. Вообще говоря, порог данных для одного экземпляра базы данных находится в пределах 1 ТБ, что является разумным диапазоном. Когда традиционные реляционные базы данных не могут удовлетворить потребности интернет-сценариев, появляется все больше и больше попыток хранить данные в NoSQL, который изначально поддерживает распространение. Однако несовместимость NoSQL с SQL и несовершенство экосистемы не позволили им нанести смертельный удар в игре с реляционными базами данных, а статус реляционных баз данных остается непоколебимым.
3. Фрагментация данных
Горизонтальное шардинг также называют горизонтальным разделением. Он больше не классифицирует данные по бизнес-логике, а распределяет данные по нескольким библиотекам или таблицам через определенное поле (или определенные поля) и по определенным правилам, причем каждый шард содержит только часть данных. Например: на основе сегментирования первичного ключа записи с четными первичными ключами помещаются в базу данных 0 (или таблицу), а записи с нечетными первичными ключами — в базу данных 1 (или таблицу), как показано на рисунке ниже.
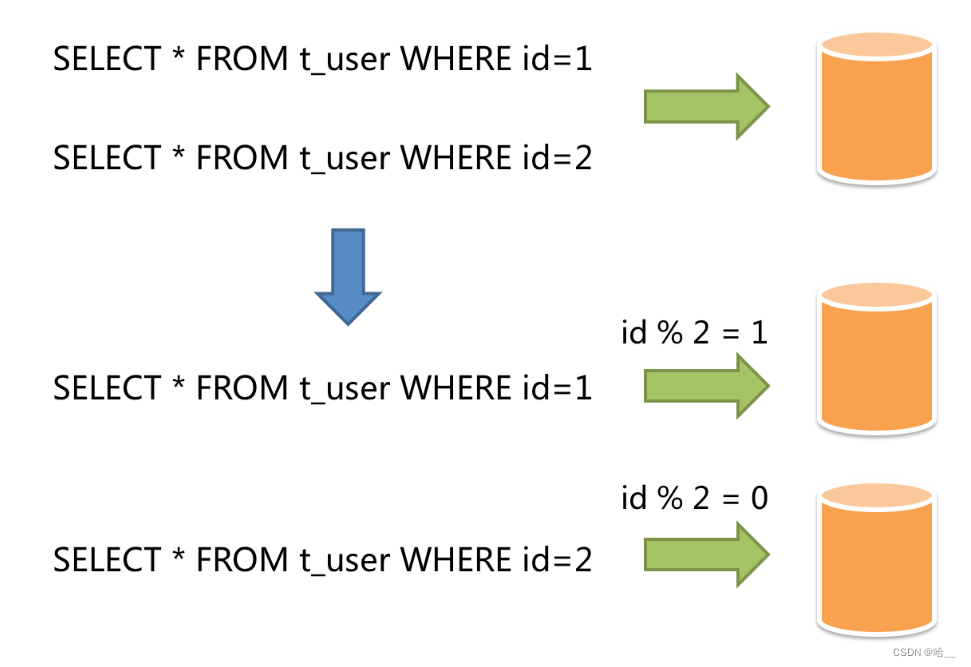
Проще говоря, горизонтальный шардинг — это горизонтальное разрезание данных большой таблицы и добавление разных частей в разные таблицы. Возьмем пример: в банке, только открытый. Поскольку объем бизнеса вначале был небольшим, один. окна было достаточно, чтобы решить все проблемы дня. Однако, благодаря отличным деловым навыкам продавцов, все больше и больше людей стали приходить в этот банк для ведения бизнеса. Когда одного окна недостаточно, нужно еще несколько окон. быть открытым, чтобы разделить давление бизнеса. Давайте настроим это так. Всего открыто 5 окон. В какое окно вы перейдете, зависит от последней цифры идентификационной карты человека, %5 + 1. Если это X, то перейдите непосредственно к окну № 1. .
То же самое справедливо и для нас в реальном бизнесе. Для таблицы заказов мы можем выполнять операции с остатками и распределять таблицы на основе номера заказа.
Помимо разделения таблиц, мы также можем разделить базы данных, и конкретные идеи остаются теми же.
4. SpringBoot интегрирует ShardingSphere.
1. Создаем наши базы данных ds0 и ds1. Создадим наши таблицы order0, order1, order2 соответственно. (Запустите обе базы данных)
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_order0
-- ----------------------------
DROP TABLE IF EXISTS `t_order0`;
CREATE TABLE `t_order0` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Table structure for t_order1
-- ----------------------------
DROP TABLE IF EXISTS `t_order1`;
CREATE TABLE `t_order1` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Table structure for t_order2
-- ----------------------------
DROP TABLE IF EXISTS `t_order2`;
CREATE TABLE `t_order2` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;2. Введение зависимостей
Зависимость здесь предназначена для достижения нашей цели — выполнения многопоточной вставки подбиблиотеки и подтаблицы.
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.0.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.18</version>
</dependency>3. Добавьте файл конфигурации. Создать application.yml
Позвольте мне объяснить, что делают эти файлы конфигурации, и все они прокомментированы.
spring:
shardingsphere:
props:
#dPrint SQL-заявление
sql-show: true
datasource:
#Создаем наш исходник ds0данный
ds0:
#Это все старые порядки
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/ds0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 2020
type: com.zaxxer.hikari.HikariDataSource
username: root
#Создаем наш исходник ds1данный
ds1:
# Та же старая процедура
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/ds1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 2020
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
#Это более важно. Вот правила, которые определяют наши подбазы данных и таблицы.
rules:
sharding:
#Алгоритм шардинга
sharding-algorithms:
#Определяем алгоритм для подбиблиотеки Как разделена библиотека?
custom-db-inline:
props:
# Вот конкретный алгоритм: разделяем базу данных по остатку userId. Остаток делится на ds.
algorithm-expression: ds$->{user_id%2}
type: INLINE
# Как разделить стол
custom-table-inline:
props:
# Получить таблицу остатков на основе orderId
algorithm-expression: t_order$->{order_id%3}
type: INLINE
tables:
# Это наша логическая таблица Поскольку таблицы t_order у нас вообще нет, это наш t_order0 1 2 абстрактно
t_order:
# Это наш настоящий стол
actual-data-nodes: ds$->{0..1}.t_order$->{0..2}
database-strategy:
standard:
# Название алгоритма шардинга То есть тот, что выше
sharding-algorithm-name: custom-db-inline
sharding-column: user_id
table-strategy:
standard:
# Название алгоритма разделения таблицы
sharding-algorithm-name: custom-table-inline
sharding-column: order_id
async:
executor:
thread:
core_pool_size: 5
max_pool_size: 20
queue_capacity: 90000
name:
prefix: async-
mybatis-plus:
global-config:
db-config:
id-type: assign_id4. Создайте нашу структуру структуры
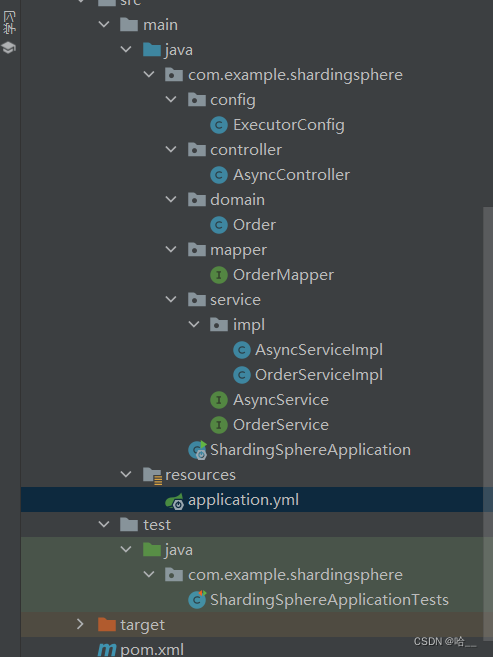
Код трехуровневого Ордена следующий.
// Объект заказа
@Data
@TableName("t_order")
@SuppressWarnings("serial")
public class Order extends Model<Order> {
@TableId(type = IdType.ASSIGN_ID)
private Long orderId;
private Integer userId;
private String orderName;
@Override
public Serializable pkVal() {
return this.orderId;
}
}
//mapper
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
//Интерфейс сервиса заказа
public interface OrderService extends IService<Order> {
}
//реализация интерфейса
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}ExecutorConfig, настраиваем наш пул потоков.
@Configuration
public class ExecutorConfig {
@Value("${async.executor.thread.core_pool_size}")
private int corePoolSize;
@Value("${async.executor.thread.max_pool_size}")
private int maxPoolSize;
@Value("${async.executor.thread.queue_capacity}")
private int queueCapacity;
@Value("${async.executor.thread.name.prefix}")
private String namePrefix;
@Bean(name = "asyncServiceExecutor")
public Executor asyncServiceExecutor() {
// Изменить здесь
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//Настраиваем количество основных потоков
executor.setCorePoolSize(corePoolSize);
//Настраиваем максимальное количество потоков
executor.setMaxPoolSize(maxPoolSize);
//Настраиваем размер очереди
executor.setQueueCapacity(queueCapacity);
//Настраиваем префикс имени потока в пуле потоков
executor.setThreadNamePrefix(namePrefix);
// политика отклонения: когда пул достиг максимума Как справляться с новыми задачами, когда размер
// CALLER_RUNS: задача не выполняется в новом потоке, а выполняется потоком, в котором находится вызывающая сторона.
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//Выполняем инициализацию
executor.initialize();
return executor;
}
}Создайте интерфейс AsyncService и класс реализации.
public interface AsyncService {
void add(List<Order> orderList, CountDownLatch countDownLatch);
}@Service
@Slf4j
public class AsyncServiceImpl implements AsyncService {
@Resource
private OrderServiceImpl orderService;
@Async("asyncServiceExecutor")
@Transactional(rollbackFor = Exception.class)
@Override
public void add(List<Order> orderList, CountDownLatch countDownLatch) {
try {
log.debug(Thread.currentThread().getName()+"Начать вставку данных");
orderService.saveBatch(orderList);
log.debug(Thread.currentThread().getName()+"Вставка данных завершена");
}finally {
countDownLatch.countDown();
}
}
}Чтобы использовать многопоточные асинхронные вызовы, добавьте аннотации к программе запуска.
@SpringBootApplication
@EnableAsync
@EnableTransactionManagement
public class ShardingSphereApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingSphereApplication.class, args);
}
}Теперь давайте посмотрим на наш AysncController. Я определил метод getData для имитации генерации наших данных. Конечно, имена, которые я установил, одинаковы. Всего имеется 10 000 фрагментов данных. База данных разделена по user_id, а таблица разделена по order_id. Индекс цикла for orderId использует последовательность идентификаторов, сгенерированную алгоритмом снежинки.
В методе testAsyncInsert. Используйте метод ListUtils для выполнения фрагментов данных, вырезания каждых двух тысяч фрагментов данных в список, а затем выполнения асинхронной операции сложения. После завершения выполнения всех потоков выведите оператор вывода.
@RestController
public class AsyncController {
@Autowired
private AsyncService asyncService;
@GetMapping("/test")
public String testAsyncInsert(){
CountDownLatch c;
try {
List<Order> data = getData();
List<List<Order>> partition = ListUtil.partition(data, 2000);
c= new CountDownLatch(partition.size());
for (List<Order> list : partition) {
asyncService.add(list,c);
}
c.await();
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("Все данные вставлены");
}
return «Выполнение завершено»;
}
private List<Order> getData(){
List<Order> list = new ArrayList<>();
for(int i = 0;i<10000;i++){
Order o = new Order();
o.setOrderName("яблоко"+i);
o.setUserId(i+1);
list.add(o);
}
return list;
}
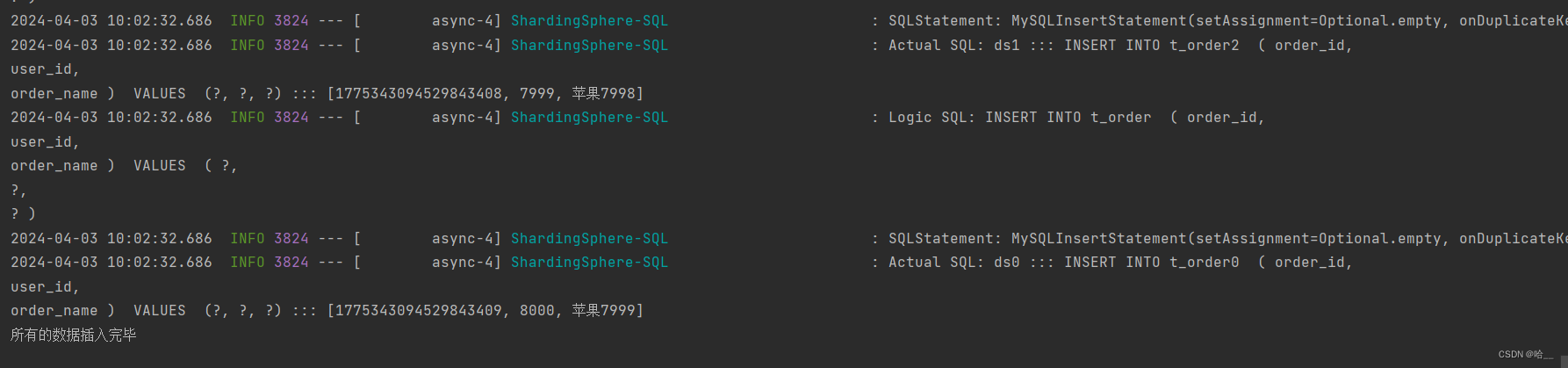
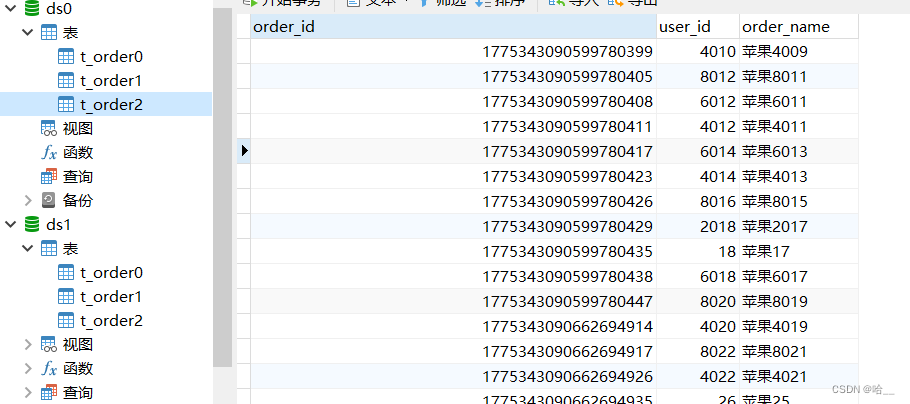
}Посмотрите на результаты. Вы можете убедиться в этом сами.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
