В отличие от OpenAI, веса, данные и коды имеют открытый исходный код, а модель встраивания Nomic Embed, которую можно прекрасно воспроизвести, находится здесь.
Отчет о сердце машины
Монтажер: Чэнь Пин, Сяочжоу
Параметры модели составляют всего 137M и могут быть обучены за 5 дней.
Неделю назад OpenAI распространила преимущества среди большинства пользователей. После окончательного решения проблемы ленивости GPT-4 он также добавил 5 новых моделей, включая меньшую и более эффективную модель встраивания текста-3-маленького размера.
Мы знаем, что вложения — это последовательности чисел, которые представляют концепции в таких вещах, как естественный язык или код. Встраивания упрощают моделям машинного обучения и другим алгоритмам понимание того, как связан контент, и выполнение таких задач, как кластеризация или извлечение. Видно, что внедрение очень важно в области НЛП.
Однако модель внедрения OpenAI не является бесплатной для всех. Например, text-embedding-3-small взимает 0,00002 доллара США за 1 тыс. токенов.
Теперь появится лучшая модель встраивания, чем text-embedding-3-small, и она будет бесплатной.
AI-стартап Nomic AI объявляет о запуске Nomic Embed, первой модели с открытым исходным кодом, открытыми данными, открытыми весами, открытым обучающим кодом, полностью воспроизводимой и проверяемой моделью внедрения с длиной контекста 8192, в тестах с коротким и длинным контекстом. Превосходит текст OpenAI. embedding-3-small и text-embedding-ada-002.

Встраивание текста является неотъемлемой частью современных приложений НЛП, обеспечивающих генерацию с расширенным поиском (RAG) для LLM и семантического поиска. Этот метод кодирует семантическую информацию о предложениях или документах в низкоразмерные векторы, которые затем используются в последующих приложениях, таких как кластеризация для визуализации данных, классификации и поиска информации. В настоящее время самой популярной моделью встраивания текста с длинным контекстом является text-embedding-ada-002 от OpenAI, которая поддерживает длину контекста 8192. К сожалению, Ada имеет закрытый исходный код, и данные обучения не подлежат проверке.
Более того, наиболее эффективные модели встраивания длинного контекста с открытым исходным кодом (такие как E5-Mistral и jina-embeddings-v2-base-en) либо не подходят для общего использования из-за размера модели, либо не могут превзойти производительность своих аналогов OpenAI.
Выпуск Nomic-embed меняет ситуацию. Модель имеет всего 137 миллионов параметров, ее очень легко развернуть и ее можно обучить за 5 дней.

Адрес статьи: https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf.
Название диссертации: Nomic Embed: обучение воспроизводимого устройства для внедрения длинного контекстного текста
Адрес проекта: https://github.com/nomic-ai/contrastors
Как построить nomic-embed
Одним из основных недостатков существующих кодировщиков текста является то, что они ограничены длиной последовательности, которая ограничена 512 токенами. Чтобы обучить модель более длинным последовательностям, первое, что нужно сделать, — это настроить BERT так, чтобы она могла обрабатывать длинные последовательности. Целевая длина последовательности для этого исследования составляла 8192.
Обучение BERT с длиной контекста 2048
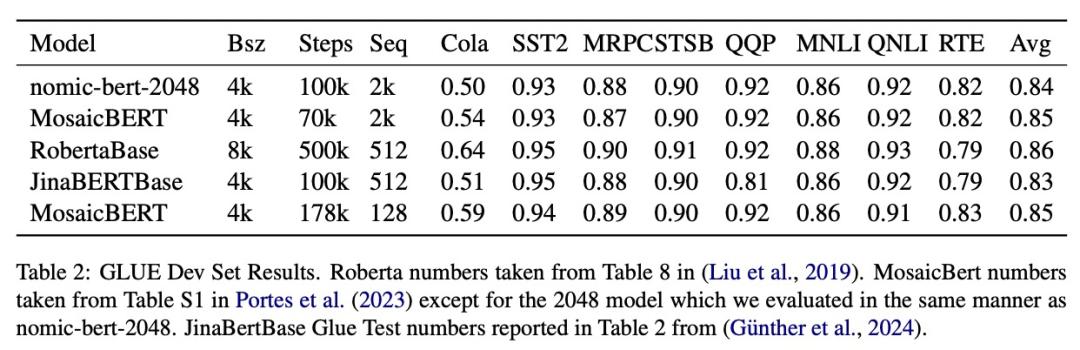
В этом исследовании используется многоэтапный контрастный процесс обучения для обучения nomic-embed. Сначала исследование выполнило инициализацию BERT. Поскольку bert-base может обрабатывать только контекст длиной до 512 токенов, в исследовании было решено обучить собственный BERT с длиной контекста 2048 токенов — nomic-bert-2048.
Вдохновленная MosaicBERT, исследовательская группа внесла некоторые изменения в процесс обучения BERT, в том числе:
- Используйте встраивание повернутой позиции, чтобы обеспечить экстраполяцию длины контекста;
- используйте активацию SwiGLU, поскольку было показано, что она улучшает производительность Модели;
- Установите отсев на 0.
И были сделаны следующие оптимизации обучения:
- использовать Deepspeed и FlashAttention проводить обучение;
- к BF16 精度проводить обучение;
- Увеличьте размер словарного запаса до 64 изнесколько;
- Размер обучающего пакета — 4096;
- При моделировании замаскированного языка коэффициент маскировки составляет 30% вместо 15%;
- Не использовать цель прогнозирования следующего предложения.
В ходе исследования все этапы обучались с максимальной длиной последовательности 2048 во время обучения и использовали динамическую интерполяцию NTK для расширения до длины последовательности 8192 во время вывода.
эксперимент
Исследование оценило качество nomic-bert-2048 в стандартном тесте GLUE и обнаружило, что его производительность сопоставима с другими моделями BERT, но с преимуществом значительно большей длины контекста.
контрастивная тренировка с использованием nomic-embed
В этом исследовании используется nomic-bert-2048 для инициализации обучения nomic-embed. Набор данных для сравнения состоит примерно из 235 миллионов текстовых пар, и его качество во время сбора тщательно проверялось с помощью Nomic Atlas.
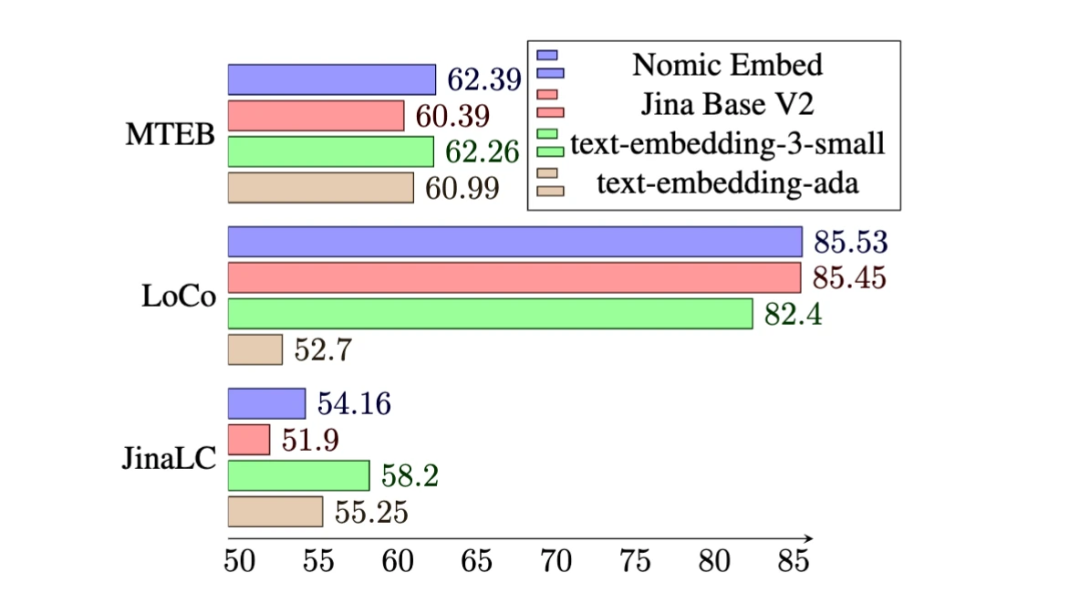
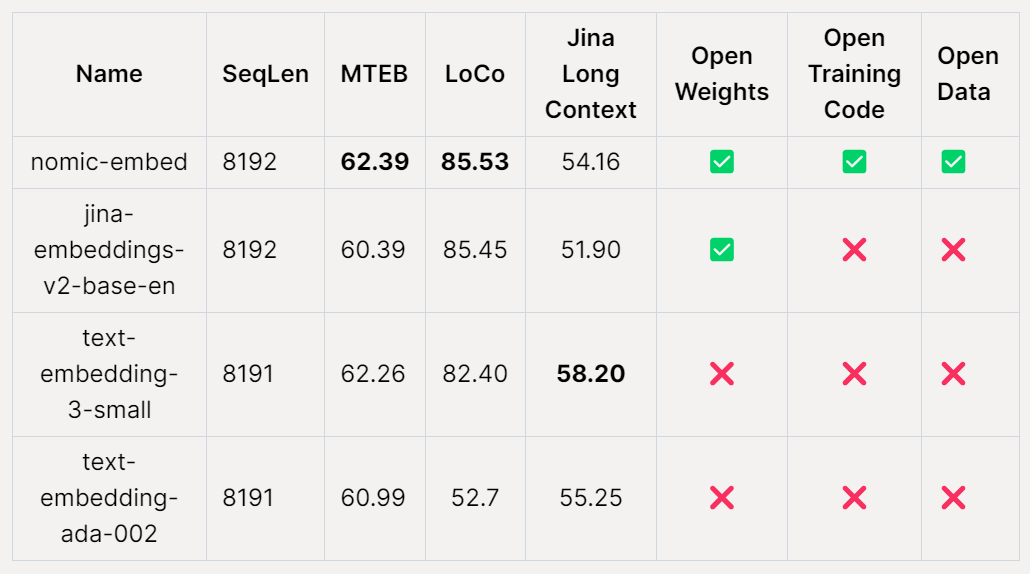
В тесте MTEB nomic-embed превосходит text-embedding-ada-002 и jina-embeddings-v2-base-en.
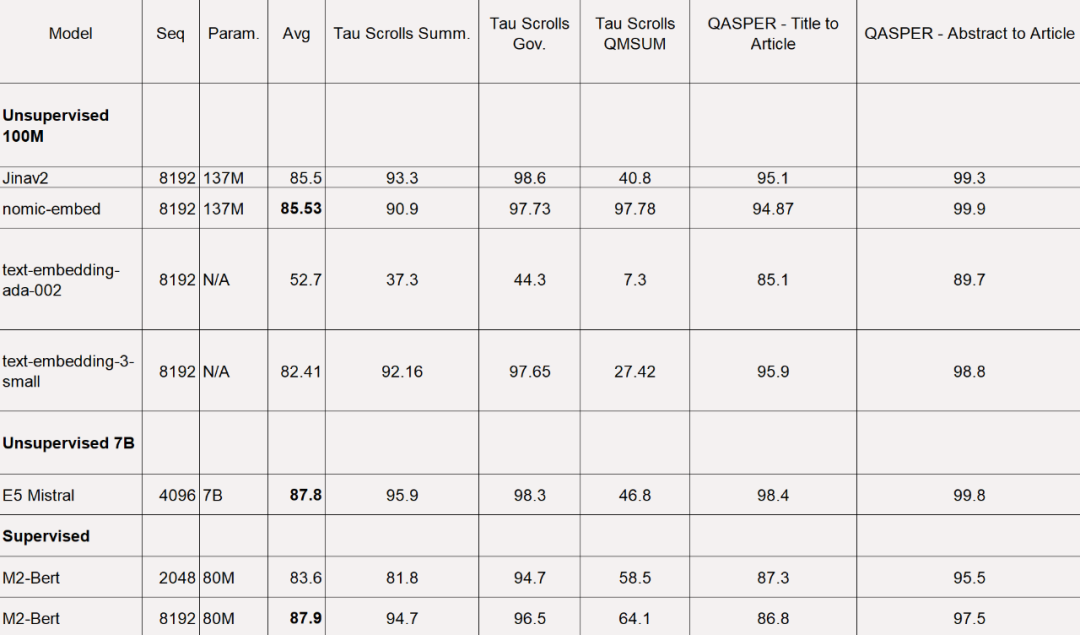
Однако MTEB не может оценивать задачи с длинным контекстом. Таким образом, в этом исследовании nomic-embed оценивается в недавно выпущенном тесте LoCo, а также тесте Jina Long Context.
Для теста LoCo исследование оценивается отдельно по категориям параметров и по тому, выполняется ли оценка в контролируемых или неконтролируемых условиях.
Как показано в таблице ниже, Nomic Embed является наиболее эффективной неконтролируемой моделью с параметрами 100M. Примечательно, что Nomic Embed сопоставим с лучшими моделями в категории параметров 7B, а также с моделями, специально обученными на тесте LoCo в контролируемой среде:
Nomic Embed также в целом работает лучше, чем jina-embeddings-v2-base-en в тесте Jina Long Context, но Nomic Embed не работает лучше, чем OpenAI ada-002 или text-embedding-3- в этом тесте small:
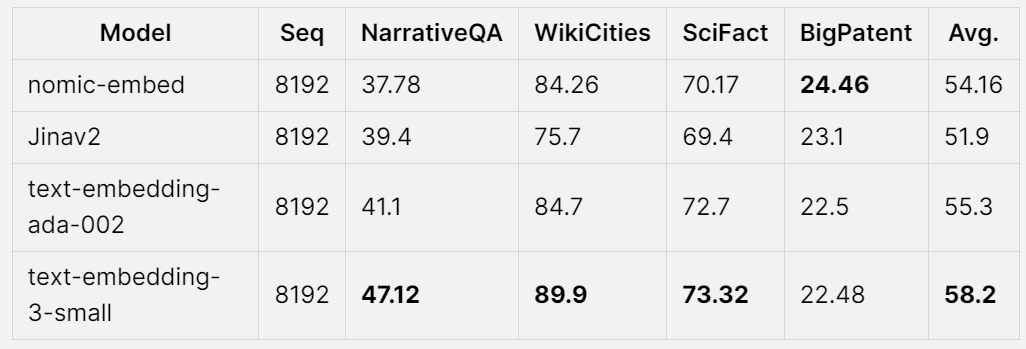
В целом Nomic Embed превосходит OpenAI Ada-002 и text-embedding-3-small на 2/3 тестов.
В исследовании говорится, что лучшим вариантом использования Nomic Embed является Nomic Embedding API, который доступен следующим образом:

Наконец, есть доступ к данным: для доступа ко всем данным в исследовании пользователям были предоставлены ключи доступа Cloudflare R2 (сервис объектного хранилища, подобный AWS S3). Чтобы получить доступ, пользователям необходимо сначала создать учетную запись Nomic Atlas и следовать инструкциям в репозитории контрасторов.
адрес контрасторов: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
Справочные ссылки:
https://blog.nomic.ai/posts/nomic-embed-text-v1
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
