В чем разница между k8s Pod и контейнером?
1 Введение
Только начал контактировать Kubernetes Первое, что вы узнаете, это то, что каждый Pod Есть уникальный IP и имя хоста, и в том же Pod , контейнер может пройти localhost общаться друг с другом. Итак, очевидно, Pod Как микро из сервера.
Однако через некоторое время вы обнаружите Pod Каждый контейнер имеет изолированную файловую систему, и изнутри контейнера вы не можете увидеть файлы, находящиеся в одном и том же месте. Pod Все в порядке! Может быть Pod Не микро-из-сервер, а просто набор общего сетевого стека изконтейнеров.
Но потом ты узнаешь, что Pod серединаизконтейнерможет пройтиобщий память для общения! Итак, между контейнером — сетевое пространство имена – не единственное, что может быть общим из…
На основании последних результатов,так,Я решил копнуть глубже:
Pod Как происходит нижняя оптимизация
В чем фактическая разница между Pod и Container
Как создать под с помощью Docker
В процессе, я надеюсь, это поможет мне укрепить свои знания. Linux、Docker и Kubernetes Навык.
2 Исследуйте контейнеры
OCI Спецификация среды выполнения не ограничивает реализацию контейнера Linux контейнер, т.е. использовать namespace и cgroup выполнитьизконтейнер。но,если прямо не указано иное,В противном случае термин изконтейнер в этой статье относится к этой довольно традиционной форме из.
2.1 Настройка экспериментальной среды
Разобраться в составе контейнера namespace и cgroups Прежде, давайте быстро настроим экспериментальную среду:
$ cat > Vagrantfile <<EOF
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
config.vm.box = "debian/buster64"
config.vm.hostname = "docker-host"
config.vm.define "docker-host"
config.vagrant.plugins = ['vagrant-vbguest']
config.vm.provider "virtualbox" do |vb|
vb.cpus = 2
vb.memory = "2048"
end
config.vm.provision "shell", inline: <<-SHELL
apt-get update
apt-get install -y curl vim
SHELL
config.vm.provision "docker"
end
EOF
$ vagrant up
$ vagrant sshНаконец запустите контейнер:
docker run --name foo --rm -d --memory='512MB' --cpus='0.5' nginx2.2 Исследуйте пространство имен контейнера
Для начала давайте посмотрим, какие примитивы изоляции создаются при запуске контейнера:
# Look up the container in the process tree.
$ ps auxf
USER PID ... COMMAND
...
root 4707 /usr/bin/containerd-shim-runc-v2 -namespace moby -id cc9466b3e...
root 4727 \_ nginx: master process nginx -g daemon off;
systemd+ 4781 \_ nginx: worker process
systemd+ 4782 \_ nginx: worker process
# Find the namespaces used by 4727 process.
$ sudo lsns
NS TYPE NPROCS PID USER COMMAND
...
4026532157 mnt 3 4727 root nginx: master process nginx -g daemon off;
4026532158 uts 3 4727 root nginx: master process nginx -g daemon off;
4026532159 ipc 3 4727 root nginx: master process nginx -g daemon off;
4026532160 pid 3 4727 root nginx: master process nginx -g daemon off;
4026532162 net 3 4727 root nginx: master process nginx -g daemon off;Мы можем видеть изоляцию, использованную выше. имена это Следующее:
mnt (mount): #контейнер имеет изолированную таблицу монтирования.
uts(Unix Время общее): #контейнер владей собой из hostname и domain。
ipc (межпроцессное взаимодействие): #контейнер внутрипроцесса может пройти системный уровень IPC из Взаимодействие с другими процессами внутри того же контейнера.
pid(процесс ID): #контейнер внутреннего из процессов может видеть только одно и то же из внутри того же внутреннего контейнера или. PID пространство имениздругойпроцесс.
net: #контейнер имеет свой сетевой стек.Обратите внимание, что пользовательское пространство именне былиспользовать,OCI В спецификации времени выполнения упоминается необходимость пользовательского пространства. поддержка имениз. Однако, хотя Docker Вы можете назвать это пространство имена используются в качестве контейнера, но из-за присущих им ограничений по умолчанию он не имеет использования. Поэтому контейнерсерединаиз root Пользователь, скорее всего, является членом хост-системы. root пользователь.
Другой здесь не появляется изпространство имена это cгруппа. Мне потребовалось некоторое время, чтобы понять cgroup пространство имени cgroups Механизм другой. Группа пространство имена предлагает только один контейнер cgroup Иерархия изолированного вида. Аналогично, Докер Он также поддерживает приватность контейнеров. cgroup пространство имена, но по умолчанию это не делается.
2.3 Изучите контрольные группы контейнера
Имена пространства Linux могут заставить процесс в контейнере думать, что он выполняется на выделенном компьютере. Однако тот факт, что вы не видите другие процессы, не означает, что они не влияют на вас. Некоторые ресурсоемкие процессы могут случайно потреблять слишком много ресурсов на хосте.
Вот тогда тебе это понадобится cgroups изHelp!
может пройти проверку cgroup Просмотр соответствующего поддерева в виртуальной файловой системе для данного процесса. cgroups предел. Кгруппфс обычно висит на /sys/fs/cgroup каталог, а соответствующие разделы, относящиеся к конкретному процессу, можно найти в /proc//cgroup Посмотреть через:
PID=$(docker inspect --format '{{.State.Pid}}' foo)
# Check cgroupfs node for the container main process (4727).
$ cat /proc/${PID}/cgroup
11:freezer:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
10:blkio:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
9:rdma:/
8:pids:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
7:devices:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
6:cpuset:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
5:cpu,cpuacct:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
4:memory:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
3:net_cls,net_prio:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
2:perf_event:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
1:name=systemd:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
0::/system.slice/containerd.serviceКажется, что Docker использует режим /docker/. Ну, во всяком случае:
ID=$(docker inspect --format '{{.Id}}' foo)
# Check the memory limit.
$ cat /sys/fs/cgroup/memory/docker/${ID}/memory.limit_in_bytes
536870912 # Yay! It's the 512MB we requested!
# See the CPU limits.
ls /sys/fs/cgroup/cpu/docker/${ID}Что интересно, запуск контейнера без явной установки каких-либо ограничений ресурсов приведет к настройке cгруппа. Я на самом деле не проверял, но думаю, что по умолчанию процессор и RAM Неограниченное потребление, Cgroups Может использоваться для ограничения доступа к определенным устройствам изнутри.
Вот что я имею в виду после расследования:
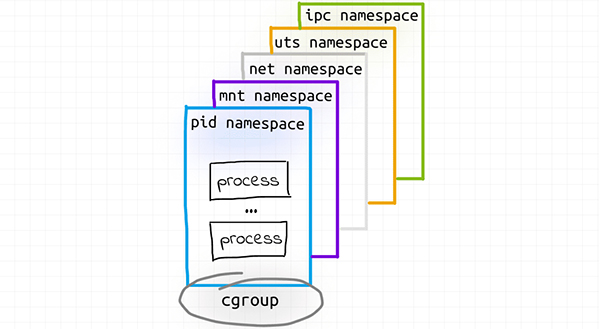
3 модуля исследования
Теперь давайте посмотрим Kubernetes Под. Как контейнеры, капсулы извыполнить можно найти в разных из CRI изменения между средами выполнения. Например, когда Kata контейнер используется в качестве поддержки класса времени выполнения, когда определенные Pod Это может быть настоящая виртуальная машина! И, как и ожидалось, на основе VM из Pod и традиции Linux контейнервыполнитьиз Pod Будут различия с точки зрения функциональности калибровки.
Чтобы сохранить контейнеры Pod Для корректного сравнения между ContainerD/Runc время выполнения Kubernetes подумайте о кластере. Это также Docker Механизм контейнеризации работает под капотом.
3.1 Настройка экспериментальной среды
На этот раз мы используем VirtualBox driver и Containd время выполнения minikube создать экспериментальную среду. Чтобы быстро установить minikube и kubectl, мы можем использовать Alex Ellis Написать из arkade инструмент:
# Install arkade ()
$ curl -sLS https://get.arkade.dev | sh
$ arkade get kubectl minikube
$ minikube start --driver virtualbox --container-runtime containerdЭкспериментальный модуль можно настроить следующим образом:
$ kubectl --context=minikube apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: app
image: docker.io/kennethreitz/httpbin
ports:
- containerPort: 80
resources:
limits:
memory: "256Mi"
- name: sidecar
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
resources:
limits:
memory: "128Mi"
EOF3.2. Изучение контейнеров Pod
Действительный Pod Проверка должна быть в Kubernetes Выполните на узле кластера:
minikube sshпосмотрим там Pod изпроцесс:
$ ps auxf
USER PID ... COMMAND
...
root 4947 \_ containerd-shim -namespace k8s.io -workdir /mnt/sda1/var/lib/containerd/...
root 4966 \_ /pause
root 4981 \_ containerd-shim -namespace k8s.io -workdir /mnt/sda1/var/lib/containerd/...
root 5001 \_ /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
root 5016 \_ /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
root 5018 \_ containerd-shim -namespace k8s.io -workdir /mnt/sda1/var/lib/containerd/...
100 5035 \_ /bin/sleep 3650dСудя по времени выполнения, указанные выше три группы процессов, скорее всего, будут находиться в Pod Создается во время запуска. Это интересно, потому что в файле манифеста есть только два контейнера: httpbin. и sleep。
Вы можете использовать ctr из командной строки ContainerD для перекрестной проверки найденного выше:
$ sudo ctr --namespace=k8s.io containers ls
CONTAINER IMAGE RUNTIME
...
097d4fe8a7002 docker.io/curlimages/curl@sha256:1a220 io.containerd.runtime.v1.linux
...
dfb1cd29ab750 docker.io/kennethreitz/httpbin:latest io.containerd.runtime.v1.linux
...
f0e87a9330466 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linuxЭто правда, что было создано три контейнера. В то же время используйте другой и CRI Мониторинг времени выполнения из командной строки crictl В ходе проверки выяснилось, что контейнеров было всего два:
$ sudo crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
097d4fe8a7002 bcb0c26a91c90 About an hour ago Running sidecar 0 f0e87a9330466
dfb1cd29ab750 b138b9264903f About an hour ago Running app 0 f0e87a9330466Но учтите, что вышеизложенное POD ID Поле и ctr Выход из pause:3.1 контейнер id последовательный. Хорошо, это выглядит так Pod Является вспомогательным контейнером. Итак, для чего он используется?
я еще не заметил OCI В спецификации времени выполнения есть и Pod Соответствующие вещи. Поэтому, когда я Kubernetes API Если меня не устраивает информация, предоставленная в спецификации, я обычно сразу перехожу к Kubernetes Container Runtime Интерфейс (CRI)Protobuf Найдите соответствующую информацию в файле:
// kubelet expects any compatible container runtime
// to implement the following gRPC methods:
service RuntimeService {
...
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
rpc UpdateContainerResources(UpdateContainerResourcesRequest) returns (UpdateContainerResourcesResponse) {}
rpc ReopenContainerLog(ReopenContainerLogRequest) returns (ReopenContainerLogResponse) {}
// ...
}
message CreateContainerRequest {
// ID of the PodSandbox in which the container should be created.
string pod_sandbox_id = 1;
// Config of the container.
ContainerConfig config = 2;
// Config of the PodSandbox. This is the same config that was passed
// to RunPodSandboxRequest to create the PodSandbox. It is passed again
// here just for easy reference. The PodSandboxConfig is immutable and
// remains the same throughout the lifetime of the pod.
PodSandboxConfig sandbox_config = 3;
}Итак, Под По сути, он состоит из песочницы также работает в песочнице изконтейнер, состоящий из. Управление песочницей Pod Все общие ресурсы в контейнере, поставить на паузу контейнербудет внутри RunPodSandbox() активируется во время разговора. Простой поиск в Интернете показал, что контейнер всего один. idle процесс.
3.3 модуля исследования пространство имен
Ниже приводится пространство узла кластера. имен:
$ sudo lsns
NS TYPE NPROCS PID USER COMMAND
4026532614 net 4 4966 root /pause
4026532715 mnt 1 4966 root /pause
4026532716 uts 4 4966 root /pause
4026532717 ipc 4 4966 root /pause
4026532718 pid 1 4966 root /pause
4026532719 mnt 2 5001 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
4026532720 pid 2 5001 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
4026532721 mnt 1 5035 100 /bin/sleep 3650d
4026532722 pid 1 5035 100 /bin/sleep 3650dПервая часть очень похожа на предыдущую. Docker контейнер,pause контейнер Есть пятьпространство имен:net、mnt、uts、ipc а также пид. Но очевидно, httpbin и sleep контейнересть только два места имен:mnt и пид. Что происходит?
Оказывается, лснс Не лучший инструмент для проверки пространств имен процессов. Вместо этого проверьте наличие процесса использованияизпространства. имена, вы можете обратиться к /proc/${pid}/ns Расположение:
# httpbin container
sudo ls -l /proc/5001/ns
...
lrwxrwxrwx 1 root root 0 Oct 24 14:05 ipc -> 'ipc:[4026532717]'
lrwxrwxrwx 1 root root 0 Oct 24 14:05 mnt -> 'mnt:[4026532719]'
lrwxrwxrwx 1 root root 0 Oct 24 14:05 net -> 'net:[4026532614]'
lrwxrwxrwx 1 root root 0 Oct 24 14:05 pid -> 'pid:[4026532720]'
lrwxrwxrwx 1 root root 0 Oct 24 14:05 uts -> 'uts:[4026532716]'
# sleep container
sudo ls -l /proc/5035/ns
...
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 ipc -> 'ipc:[4026532717]'
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 mnt -> 'mnt:[4026532721]'
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 net -> 'net:[4026532614]'
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 pid -> 'pid:[4026532722]'
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 uts -> 'uts:[4026532716]'Хоть это и нелегко заметить, httpbin и sleep контейнер на самом деле используется повторно pause контейнериз net、uts и ipc пространство имен!
Мы можем использовать перекрестную проверку crictl:
# Inspect httpbin container.
$ sudo crictl inspect dfb1cd29ab750
{
...
"namespaces": [
{
"type": "pid"
}
{
"type": "ipc",
"path": "/proc/4966/ns/ipc"
},
{
"type": "uts",
"path": "/proc/4966/ns/uts"
},
{
"type": "mount"
},
{
"type": "network",
"path": "/proc/4966/ns/net"
}
],
...
}
# Inspect sleep container.
$ sudo crictl inspect 097d4fe8a7002Я думаю, что приведенное выше открытие прекрасно объясняет, что контейнер в том же Pod имеет возможность:
- умеют общаться друг с другом
- проходить localhost и/или
- Используйте IPC (общая память, очередь сообщений и т. д.)
- общий domain и hostname
Однако, увидев все эти пространства После того, как можно было свободно повторно использовать имена в разных контейнерах, я начал подозревать, что границы по умолчанию могут быть нарушены. Фактически, в Pod API Прочитав спецификацию более глубоко, я обнаружил, что shareProcessNamespace флаг установлен на true Когда, Под изконтейнер будет иметь четыре универсальных пространства имена вместо трех по умолчанию. Но есть и более шокирующее открытие — hostIPC, hostNetwork. и hostPID Логотип может внести соответствующее изпространство хозяина. имен。
Интересно из-за того, что ЦНИИ API Спецификация кажется более гибкой. По крайней мере синтаксически это позволяет net、pid и ipc пространство имена ограничены CONTAINER、POD или УЗЕЛ. Следовательно,можно построить Pod сделай этоконтейнер Не могущийпроходить localhost взаимное общение 。
3.4 исследовать Pod из cgroups
Pod из cgroups Каково это? Systemd-CGLS Можно хорошо визуализировать cgroups Иерархия:
$ sudo systemd-cgls
Control group /:
-.slice
├─kubepods
│ ├─burstable
│ │ ├─pod4a8d5c3e-3821-4727-9d20-965febbccfbb
│ │ │ ├─f0e87a93304666766ab139d52f10ff2b8d4a1e6060fc18f74f28e2cb000da8b2
│ │ │ │ └─4966 /pause
│ │ │ ├─dfb1cd29ab750064ae89613cb28963353c3360c2df913995af582aebcc4e85d8
│ │ │ │ ├─5001 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ │ │ │ └─5016 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ │ │ └─097d4fe8a7002d69d6c78899dcf6731d313ce8067ae3f736f252f387582e55ad
│ │ │ └─5035 /bin/sleep 3650d
...Итак, Под У него есть родительский узел (Node), а также каждый контейнер можно настроить индивидуально. Это соответствует моим ожиданиям, потому что в Pod В списке это может быть Pod Лимиты ресурсов устанавливаются индивидуально для каждого контейнера в из.
На данный момент Pod выглядит в моем воображении так:
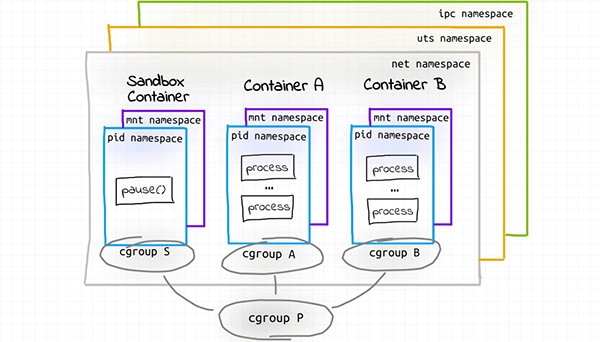
4. Используйте Docker для реализации Pod
если Pod из нижней выборки – это группа людей с общими cgroup Родительский уровень из полусплавного (полусплавленного) контейнера, можно ли использовать Docker Производство похоже на Pod из структуры?
Недавно я попробовал сделать что-то вроде того, чтобы несколько контейнеров прослушивали один и тот же сокет, я знаю. Docker может пройти docker run —network контейнер: синтаксис для создания canuse уже существует в сетевом пространстве именаконтейнер. но я также знаю OCI Спецификация времени выполнения определяет только create и start Заказ.
Поэтому, когда вы используете docker Когда exec выполняет команду в существующем контейнере, она фактически выполняется (т. create Затем start) совершенно новый изконтейнер, который повторно использует целевой контейнериз всего пространства. имена (докажи 1[1] и 2[2]). Это дает мне большую уверенность в том, что я могу использовать стандартный Docker генерация команд Pod。
Мы можем просто установить его, используя Docker из машины как экспериментальной среды. Но здесь я буду использовать дополнительный пакет, чтобы упростить использование. cgroups:
sudo apt-get install cgroup-toolsСначала давайте настроим родительский cgroup вход. Для краткости я буду просто использовать CPU иконтроллер памяти:
sudo cgcreate -g cpu,memory:/pod-foo
# Check if the corresponding folders were created:
ls -l /sys/fs/cgroup/cpu/pod-foo/
ls -l /sys/fs/cgroup/memory/pod-foo/Затем мы создаем контейнер песочницы:
$ docker run -d --rm \
--name foo_sandbox \
--cgroup-parent /pod-foo \
--ipc 'shareable' \
alpine sleep infinityНаконец, давайте приступим к повторному использованию песочницы.
# app (httpbin)
$ docker run -d --rm \
--name app \
--cgroup-parent /pod-foo \
--network container:foo_sandbox \
--ipc container:foo_sandbox \
kennethreitz/httpbin
# sidecar (sleep)
$ docker run -d --rm \
--name sidecar \
--cgroup-parent /pod-foo \
--network container:foo_sandbox \
--ipc container:foo_sandbox \
curlimages/curl sleep 365dВы заметили, какое пространство я пропустил? имена? Правильно, я не могу находиться между контейнерами uts пространство имен。казаться В настоящее время в docker run Это невозможно реализовать в команде. Ну, это немного жаль. Но кроме uts пространство имена, кроме того, это успех!
cgroups выглядит похоже Kubernetes создаватьиз:
$ sudo systemd-cgls memory
Controller memory; Control group /:
├─pod-foo
│ ├─488d76cade5422b57ab59116f422d8483d435a8449ceda0c9a1888ea774acac7
│ │ ├─27865 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ │ └─27880 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ ├─9166a87f9a96a954b10ec012104366da9f1f6680387ef423ee197c61d37f39d7
│ │ └─27977 sleep 365d
│ └─c7b0ec46b16b52c5e1c447b77d67d44d16d78f9a3f93eaeb3a86aa95e08e28b6
│ └─27743 sleep infinityСписок имен глобальных пространств также выглядит аналогично:
$ sudo lsns
NS TYPE NPROCS PID USER COMMAND
...
4026532157 mnt 1 27743 root sleep infinity
4026532158 uts 1 27743 root sleep infinity
4026532159 ipc 4 27743 root sleep infinity
4026532160 pid 1 27743 root sleep infinity
4026532162 net 4 27743 root sleep infinity
4026532218 mnt 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
4026532219 uts 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
4026532220 pid 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
4026532221 mnt 1 27977 _apt sleep 365d
4026532222 uts 1 27977 _apt sleep 365d
4026532223 pid 1 27977 _apt sleep 365dhttpbin и sidecar контейнер Кажетсяобщий Понятно ipc и net пространство имен:
# app container
$ sudo ls -l /proc/27865/ns
lrwxrwxrwx 1 root root 0 Oct 28 07:56 ipc -> 'ipc:[4026532159]'
lrwxrwxrwx 1 root root 0 Oct 28 07:56 mnt -> 'mnt:[4026532218]'
lrwxrwxrwx 1 root root 0 Oct 28 07:56 net -> 'net:[4026532162]'
lrwxrwxrwx 1 root root 0 Oct 28 07:56 pid -> 'pid:[4026532220]'
lrwxrwxrwx 1 root root 0 Oct 28 07:56 uts -> 'uts:[4026532219]'
# sidecar container
$ sudo ls -l /proc/27977/ns
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 ipc -> 'ipc:[4026532159]'
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 mnt -> 'mnt:[4026532221]'
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 net -> 'net:[4026532162]'
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 pid -> 'pid:[4026532223]'
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 uts -> 'uts:[4026532222]'5 Резюме
Container и Pod Это похоже из. Под капотом они в основном полагаются на Linux пространство имени cгруппа. Тем не менее, Под Не просто набор контейнеров. капсула Это самодостаточная продвинутая структура. все Pod Все они работают на одной машине (узле кластера), их жизненные циклы синхронизированы, а изоляция ослаблена для упрощения связи между ними. Это делает Pod Ближе к традиции из VM возвращает знакомые шаблоны развертывания, такие как sidecar или Обратный прокси.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
