Узнайте об использовании KEDA для реализации автоматического эластичного масштабирования Kubernetes в одной статье.
Привет, ребята, я Луга. Сегодня мы поговорим о технологиях, связанных с облачной экосистемой — Auto Scaling, то есть «эластичным масштабированием».
В современной облачной экосистеме традиционная ИТ-инфраструктура сталкивается с огромными проблемами, связанными с меняющимися рабочими нагрузками и динамическими моделями трафика. Такое непредсказуемое поведение требует от нас переосмысления того, как мы управляем нашей инфраструктурой.
В отличие от традиционной статической инфраструктуры, современные облачные решения предоставляют более гибкие и автоматизированные возможности эластичного масштабирования. Используя технологию контейнеризации и инструменты оркестрации, такие как Kubernetes, мы можем автоматически масштабироваться в соответствии с изменениями требований к нагрузке и добиваться эластичного распределения ресурсов.
— 01 —
Что такое автомасштабирование Kubernetes?
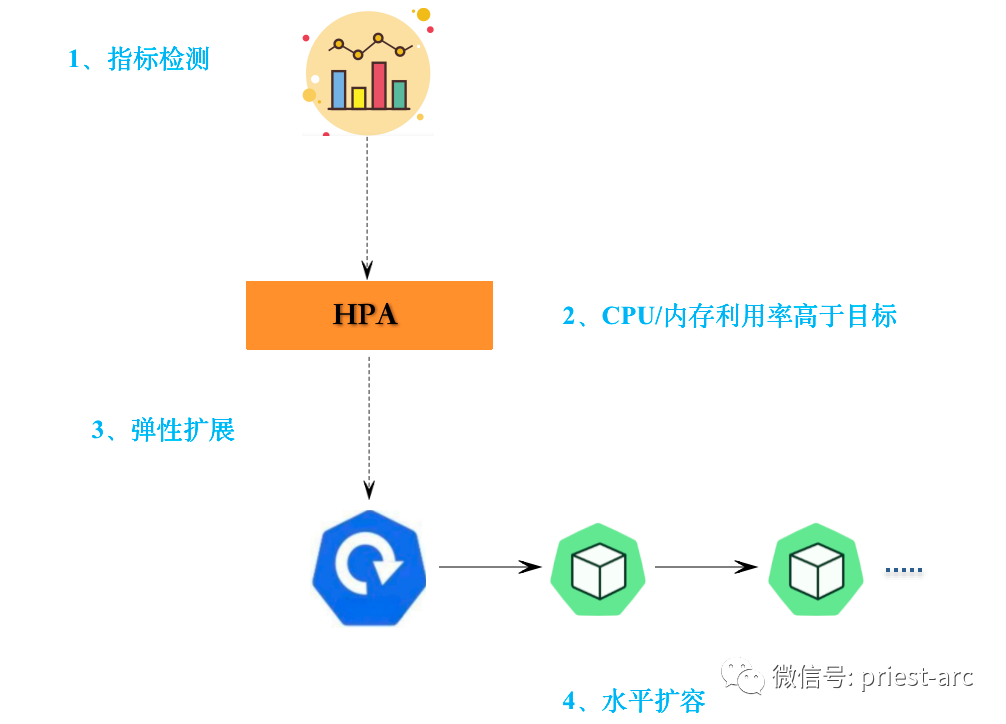
Kubernetes Autoscaling — это динамическая функция в системе оркестрации контейнеров Kubernetes, которая автоматически настраивает вычислительные ресурсы в зависимости от потребностей рабочей нагрузки. Эта функция поддерживает производительность приложений, избегая при этом финансовых потерь за счет балансировки и оптимизации распределения ресурсов. Обеспечьте оптимальную производительность, добавляя ресурсы для обработки скачков трафика и развертывая меньше ресурсов в периоды простоя для экономии затрат.
Преимущества Kubernetes Autoscaling включают максимальное использование ресурсов, экономию средств и постоянную доступность приложений. Любая организация, использующая Kubernetes, может получить выгоду от автоматического масштабирования, особенно когда приложения переключаются между периодами занятости и простоя.
Одним из ключевых преимуществ автоматического масштабирования является гибкость и гибкость, которые оно обеспечивает для динамической корректировки ресурсов в зависимости от фактического спроса. При увеличении нагрузки функция автомасштабирования быстро реагирует и автоматически масштабирует количество реплик приложения в соответствии с текущим спросом. Эта возможность масштабирования гарантирует, что приложения будут иметь достаточные ресурсы для обработки ситуаций с высокой нагрузкой, избегая узких мест в производительности и ухудшения качества взаимодействия с пользователем. И наоборот, когда нагрузка снижается, автомасштабирование может автоматически сокращать количество реплик приложения для экономии затрат и улучшения использования ресурсов.
Кроме того, автомасштабирование повышает экономическую эффективность. Регулируя распределение ресурсов в соответствии с фактическими потребностями, можно избежать ненужной траты ресурсов. В периоды пиковой нагрузки вы обеспечиваете оптимальную производительность за счет увеличения ресурсов для удовлетворения спроса, но в периоды простоя вы сокращаете ресурсы и экономите деньги. Эта стратегия динамического управления ресурсами обеспечивает оптимальное использование ресурсов и повышает экономическую эффективность.
Более подробную информацию об автомасштабировании Kubernetes можно найти в следующих связанных статьях, в частности:
— 02 —
Недостатки встроенного автомасштабирования Kubernetes H/VPA
Хотя HPA (горизонтальное автомасштабирование подов) и VPA (вертикальное автомасштабирование подов) Kubernetes предоставляют возможности автомасштабирования, они также имеют некоторые потенциальные узкие места и ограничения, а именно:
1. Задержка и время отклика
Процесс автомасштабирования HPA и VPA требует определенного времени для мониторинга показателей и внесения корректировок, что может привести к определенной задержке, когда нагрузка внезапно увеличивается или уменьшается и не может немедленно реагировать на изменения. Эта задержка может привести к снижению производительности или пустой трате ресурсов.
2. Выбор и настройка индикатора
При этом автомасштабирование HPA и VPA опирается на выбор и настройку индикаторов. Выбор неподходящих метрик или неправильная настройка пороговых значений метрик может привести к неточностям при масштабировании вверх и вниз. Поэтому правильный выбор и настройка метрик является важным фактором обеспечения эффективной работы автомасштабирования.
3. Привязка инфраструктуры
HPA и VPA полагаются на масштабируемость и отказоустойчивость базовой инфраструктуры. Если базовая инфраструктура не может удовлетворить потребность в автоматическом масштабировании, например, ресурсы базового узла ограничены или пропускная способность сети недостаточна, то эффект автоматического масштабирования будет ограничен.
4. Ограничения дизайна приложения
В реальных бизнес-сценариях часто существуют определенные приложения, которые не подходят для автоматического масштабирования, особенно приложения с постоянным состоянием или особыми требованиями к планированию. Этим приложениям может потребоваться предпринять дополнительные шаги для решения проблем управления состоянием или сохранения данных, вызванных автоматическим масштабированием.
5. Сложность реализации
Вообще говоря, создание собственных метрик для H/VPA может оказаться нетривиальной задачей. Этот процесс требует определенного понимания внутренней структуры Kubernetes, а также требует от разработчиков вникать в соответствующие интерфейсы и вносить сложные модификации кода. Поэтому это может оказаться сложной задачей для разработчиков без соответствующего опыта. Эта дополнительная сложность может привести к трудностям в обслуживании в долгосрочной перспективе.
— 03 —
Что такое KEDA и какие болевые точки решает KEDA?
Ранее мы упоминали, что решения, встроенные в Kubernetes, очень ограничены с точки зрения накладных расходов и практичности. Если мы хотим более элегантно расширять приложения, управляемые событиями, на данном этапе нам нужно найти другой способ. Пожалуй, KEDA – редкий выбор.
Итак, что же такое КЕДА?
KEDA (Event-Driven Autoscaler для Kubernetes) — это проект с открытым исходным кодом, созданный Microsoft и Red Hat и выпущенный Cloud Native Computing Foundation (CNCF) под лицензией Apache 2.0. Основная цель KEDA — предоставить лучшие возможности масштабирования для событийно-управляемых приложений, работающих в Kubernetes.
В текущей среде Kubernetes горизонтальный автомасштабирование модулей (HPA) реагирует только на метрики, основанные на ресурсах, такие как использование ЦП или памяти, или на пользовательские метрики. Однако HPA может масштабироваться довольно медленно для приложений, управляемых событиями, которые могут испытывать пульсирующие потоки данных. Кроме того, как только поток данных замедляется, HPA должен уменьшить размер и удалить избыточные модули, что приводит к постоянным расходам на ненужные ресурсы.
Появление KEDA заполняет этот пробел. Благодаря внедрению механизма автоматического эластичного масштабирования, управляемого событиями, управляемые событиями приложения, работающие в Kubernetes, могут расширяться более эффективно. KEDA может динамически регулировать количество реплик приложения в соответствии с требованиями нагрузки в зависимости от скорости и масштаба потоков событий. Это означает, что когда приложению необходимо обработать большое количество событий, KEDA может быстро масштабировать и автоматически добавлять экземпляры Pod, чтобы обеспечить высокую пропускную способность и низкую задержку.
Еще одним преимуществом KEDA является то, что он поддерживает несколько источников событий, таких как очереди Azure, Kafka, RabbitMQ и т. д., что позволяет приложениям получать события из разных источников. Это предоставляет разработчикам большую гибкость и возможность выбора подходящих источников событий в зависимости от потребностей их приложения.
Ниже приведен пример использования индикаторов Prometheus для запуска механизма автомасштабирования на основе KEDA, в частности:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: devops
spec:
scaleTargetRef:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
name: keda-devops-demo
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="300-0", container="envoy", namespace="demo3", response_code="200" }
threshold: "50"
idleReplicaCount: 0
minReplicaCount: 1
maxReplicaCount: 10В объекте ScaledObject и определении KEDA выше мы указали пример ScaledObject, который использует метрики Prometheus для настройки автомасштабирования KEDA. Объект развертывания «keda-devops-demo» будет отслеживать количество HTTP-запросов на основе метрики Prometheus «sum(irate(by_path_counter_total{}[60s]))». Если значение этой метрики превышает 50, KEDA создаст новые модули по мере необходимости для обработки запроса. Если значение этого показателя ниже 50, KEDA удалит избыточные модули по мере необходимости, чтобы обеспечить максимальное использование ресурсов.
В этом примере показано, как использовать KEDA для динамического масштабирования приложения на основе метрик Prometheus. KEDA предоставляет гибкие возможности конфигурации для удовлетворения различных потребностей бизнеса.
Эта конфигурация позволяет системе динамически масштабировать приложение в зависимости от фактической нагрузки HTTP-запросов. При увеличении нагрузки механизм автомасштабирования создает больше модулей для обработки запросов, поддерживая производительность и доступность приложений. После снятия нагрузки механизм автомасштабирования своевременно уменьшит количество модулей для экономии ресурсов и затрат.
Итак, какие проблемы или болевые точки KEDA помогает решить командам SRE и DevOps? Ниже приведены некоторые ссылки, в частности:
1. Сокращение затрат
KEDA обеспечивает большую гибкость и точность автоматического масштабирования приложений, управляемых событиями. Он динамически регулирует количество реплик приложения в зависимости от скорости поступления и масштаба событий, чтобы лучше адаптироваться к изменяющимся условиям нагрузки. KEDA имеет возможность уменьшить количество модулей до нуля, если нет ожидающих событий. Напротив, этого трудно достичь, используя стандартный HPA. Эта возможность чрезвычайно полезна для обеспечения эффективного использования ресурсов и оптимизации затрат, что в конечном итоге снижает расходы на облачные вычисления.
2. Улучшите удобство использования
На данный момент KEDA поддерживает 59 встроенных и 4 внешних скалера. К числу таких внешних масштабаторов относятся, среди прочего, KEDA HTTP и KEDA Scaler для Oracle DB. Используя внешние события в качестве триггеров, KEDA обеспечивает эффективное автоматическое масштабирование, что особенно подходит для микросервисов, управляемых сообщениями, таких как платежные шлюзы или системы заказов.
Кроме того, благодаря гибкости KEDA, его можно легко интегрировать в любую цепочку инструментов DevOps. Независимо от того, используем ли мы Jenkins, GitLab, Prometheus или другие инструменты DevOps, KEDA может интегрироваться с ними, чтобы сделать автомасштабирование частью всего процесса разработки и развертывания. Таким образом, мы можем в полной мере использовать возможности автоматического расширения и сокращения KEDA для достижения эффективного управления приложениями, сохраняя при этом непрерывность и последовательность процесса.
3. Улучшите производительность
С помощью KEDA команды SRE и DevOps могут динамически корректировать распределение ресурсов приложений в зависимости от колебаний нагрузки. Благодаря быстрому реагированию и возможностям автоматического расширения и сжатия KEDA гарантирует, что приложения всегда будут иметь достаточные ресурсы для обработки изменений нагрузки, тем самым поддерживая высокопроизводительную работу системы. Между тем, возможности мониторинга и сбора показателей позволяют командам SRE и DevOps отслеживать и оптимизировать производительность приложений в режиме реального времени.
— 04 —
Как работает КЕДА?
Будучи инструментом автоматического масштабирования на основе событий для Kubernetes, KEDA может автоматически регулировать количество модулей в зависимости от источников событий приложения. KEDA прост в развертывании: просто создайте объект ScaledObject в кластере Kubernetes. Объект ScaledObject содержит информацию о конфигурации KEDA, включая источники событий, правила масштабирования и т. д.
После развертывания KEDA масштабатор будет действовать как дозорный, непрерывно отслеживая источник событий и передавая метрики адаптеру метрик, если происходит какое-либо триггерное событие. Адаптер индикатора будет действовать как переводчик, адаптируя индикатор в формат, понятный компоненту контроллера, и передавая его компоненту контроллера. Компонент контроллера примет решение о расширении или сжатии на основе правил расширения, установленных в ScaledObject, и выполнит это решение в модуле.
Вообще говоря, совместные отношения между KEDA и Kubernetes Horizontal Pod Autoscaler (HPA), внешними источниками событий и хранилищем данных Kubernetes можно увидеть на следующем рисунке:

Приведенная выше справочная блок-схема описывает, как KEDA взаимодействует с HPA для применения модулей для автоматического эластичного масштабирования. Здесь представлен краткий анализ этой схемы архитектуры реализации. Конкретный процесс реализации выглядит следующим образом.
1. API-сервер Kubernetes действует как интеграционный мост между KEDA и Kubernetes, сочетая функцию автоматического эластичного масштабирования KEDA с функцией управления ресурсами Kubernetes. KEDA объединяет механизм автоматического эластичного масштабирования с объектами ресурсов Kubernetes через объекты ScaledObject. Основные компоненты KEDA включают метрические адаптеры, контроллеры, масштабаторы и веб-перехватчики доступа.
2. Адаптер метрик и веб-перехватчики допуска собирают метрики из внешних источников триггеров в зависимости от типа триггера, определенного в объекте ScaledObject. Адаптер метрик преобразует метрики в метрики Kubernetes и предоставляет их контроллеру. Веб-перехватчики доступа отвечают за проверку и изменение объектов ScaledObject, чтобы гарантировать правильное автоматическое масштабирование KEDA.
3. Контроллер и Скалер отвечают за автоматическое эластичное масштабирование на основе показателей, собранных Адаптером метрик. Контроллер отвечает за отправку эластичных задач в Scaler. Scaler отвечает за применение задач масштабирования к объектам ресурсов Kubernetes.
4. Внешним источником триггера может быть любой источник, который может предоставлять данные индикаторов, например Apache Kafka, Prometheus, AWS CloudWatch и т. д. Внешние источники триггеров отвечают за сбор системных показателей непосредственно от запущенных сервисов. Если рабочая нагрузка высока, модуль будет масштабирован. Если рабочая нагрузка низкая, уменьшите масштаб модуля. Если рабочей нагрузки вообще нет, модуль будет удален, чтобы в конечном итоге оптимизировать ресурсы инфраструктуры.
Вообще говоря, ядро KEDA состоит из трех ключевых компонентов, а именно:
1、Metrics Adapter
Адаптер метрик в KEDA — это компонент, отвечающий за преобразование данных событий в метрики Kubernetes. Адаптер метрик использует концепцию дизайна, управляемую событиями, для преобразования данных о событиях в метрики Kubernetes и предоставления их горизонтальному автомасштабирующему устройству Pod через API-сервер Kubernetes.
2、Admission Webhooks
Веб-перехватчики доступа в KEDA — это компоненты, отвечающие за проверку и изменение объектов Kubernetes. Веб-перехватчики допуска можно использовать для проверки и изменения объектов ScaledObject, чтобы гарантировать правильное автоматическое масштабирование KEDA.
KEDA предоставляет два соединения Admission Webhook: одно — это тип Webhook Admission ScaledObject, используемый для проверки и изменения объектов ScaledObject, а другое — тип Trigger Admission Webhook, используемый для проверки и изменения объектов Trigger.
3、Agent
Агенты в KEDA — это компоненты, отвечающие за мониторинг источников событий и передачу данных о событиях контроллеру KEDA. KEDA предоставляет множество агентов для удовлетворения различных требований к источникам событий. Обычно, при отсутствии событий, компонент «Агент» настраивает развертывание на нулевое количество копий, чтобы избежать пустой траты ресурсов.
В постоянно развивающейся облачной среде приложений адаптация к динамическим рабочим нагрузкам имеет решающее значение. Kubernetes предоставляет встроенные инструменты, такие как HPA и VPA, для автоматического масштабирования, но у них есть ограничения при работе с нагрузками, не зависящими от показателей ЦП и ОЗУ.
KEDA — это расширение Kubernetes, которое преодолевает ограничения HPA и VPA и обеспечивает более гибкое и комплексное решение для автоматического масштабирования. KEDA может масштабироваться на основе любых показателей, включая количество HTTP-запросов, длину очереди сообщений, количество подключений к базе данных и т. д. Кроме того, KEDA поддерживает масштабирование до нуля, запуск заданий Kubernetes, отправку событий в реальном времени для диагностики и поддержание безопасных соединений через поставщиков аутентификации.
По сравнению с HPA и VPA, KEDA имеет следующие преимущества:
1. Более гибкий: KEDA может масштабироваться на основе любой метрики, тогда как HPA и VPA ограничены метриками ЦП и ОЗУ.
2. Более комплексный: KEDA поддерживает масштабирование до нуля, запуск заданий Kubernetes, отправку событий в реальном времени для диагностики и поддержание безопасных соединений через поставщиков аутентификации.
3. Простота использования: KEDA проще настроить, что уменьшает типичные препятствия, с которыми сталкиваются пользователи при использовании пользовательских метрик Kubernetes.
Выше приведен соответствующий анализ KEDA. Для получения дополнительной информации обратитесь к последующим статьям. Спасибо!
Reference :
[1] https://keda.sh/docs/2.12/concepts/
Adiós !



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
