Upscale-A-Video: постоянная во времени модель диффузии для видео сверхвысокого разрешения в реальном времени.
источник:arxiv автор:Shangchen Zhou ждать Название диссертации:HUpscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution Бумажная ссылка:https://arxiv.org/pdf/2312.06640.pdf Домашняя страница проекта:https://shangchenzhou.com/projects/upscale-a-video Организация контента:Ван Ивэнь Выдающийся успех в создании и редактировании текста на основе распространения Модельсуществовать, показыватьиспользовать Модель диффузии до Генерно улучшенный визуальный контент с огромными перспективами. Однако из-за опасений по поводу точности вывода ипостоянство времяиз Высокие требования, применение модели диффузии к суперразрешению видео по-прежнему является сложной задачей. Эта работа предлагает Upscale-A-Video, система скрытого распространения с текстовым управлением для видео сверхвысокого разрешения. Данная система обеспечивает согласованность сроков посредством местных и глобальных механизмов. Благодаря предварительной диффузии эта модель также обеспечивает большую гибкость, позволяя использовать текстовые подсказки для управления созданием текстур, а также регулируемые уровни шума для балансировки ремонта и генерации, что позволяет найти компромисс между точностью и качеством.
введение
Суперразрешение видео (VSR) в реальных сценариях — это сложная задача, целью которой является улучшение качества видео низкого качества для получения высококачественных результатов.
Хотя последние сети на основе сверточных нейронных сетей (CNN) успешно смягчают многие формы деградации, они по-прежнему не справляются с созданием реалистичных текстур и деталей из-за их ограниченных генеративных возможностей, что часто приводит к чрезмерному сглаживанию.
Диффузионные модели продемонстрировали впечатляющие возможности создания высококачественных изображений и видео. Использование генеративного потенциала диффузионных моделей может эффективно облегчить проблему чрезмерного сглаживания, которая часто возникает в моделях на основе CNN, что приводит к получению результатов с более реалистичными мелкозернистыми деталями. Однако адаптация этих априорных подходов к VSR остается нетривиальной задачей. Эта трудность возникает из-за присущей диффузной выборке стохастичности, которая неизбежно приводит к неожиданным временным разрывам в полученном видео. Эта проблема еще более выражена в SD, где декодер VAE дополнительно вносит мерцание деталей текстуры.
Недавно люди адаптировали модели распространения изображений к видеозадачам, внедрив стратегии временной согласованности. Эти стратегии включают в себя.
- использовать 3D сверткаи пространственно-временное внимание ожидание по сравнению с видео Моделированиетонкая настройка;
- Существующая предтренировочная модель использует перекрестное внимание и управление оптическим потоком из механизма ожидания ожидания с нулевым выстрелом.
Хотя эти решения значительно улучшают стабильность видео, остаются две основные проблемы:
- В настоящее время трудно поддерживать согласованность низкого уровня при работе в пространстве U-Net или скрытом пространстве.,Проблема с мерцанием текстур все еще существует;
- Существующий механизм внимания временного уровня может накладывать ограничения только на более короткие локальные входные последовательности.,от И ограничить их длительное существование видео, чтобы обеспечить глобальное постоянство временииз возможностей.

Рисунок 1
Чтобы решить эти проблемы,Этот метод использует локально-глобальную стратегию, позволяющую продолжать восстановление видео истоков времени.,в то же времясосредоточиться Мелкозернистая текстура и общая консистенция. Кроме того, этот метод дополнительно исследует, как передавать текстовую подсказка помогает создавать текстуры, повышая универсальность и обеспечивая поддержку уровней. Управление шумом позволяет сбалансировать ремонт и генерацию, а также достичь компромисса между точностью и качеством.
метод
книгаметодиз Цель — реальный мир VSR Разработка системы распространения текста на основе текста. Проблемы включают временные несоответствия и появление артефактов мерцания, особенно для длинных видеопоследовательностей. VSR Задача. Сложность этих задач заключается не только в достижении временной согласованности локальных сегментов, но и в сохранении согласованности на протяжении всего видео.
Этот методизрамка существует существующая Модель Диффузии (LDM) добавляет локальный и глобальный модуль для сохранения видео внутри фрагмента, видео между фрагментами и стоянства. время. существование каждого шага времени диффузии
Внутри видео сегментируется на разные сегменты и обрабатывается с помощью U-Net, который включает временные слои для обеспечения согласованности внутри каждого сегмента. Если текущий временной шаг находится в пределах заданного пользователем глобального шага уточнения
В рамках этой области используется модуль распространения циклического скрытого кода для улучшения согласованности между видеоклипами во время вывода. Наконец, для уменьшения оставшихся артефактов мерцания используется точно настроенный декодер VAE.
Благодаря использованию диффузионных априор этот инструмент обладает значительной универсальностью:
- Введите текстовую подсказку, чтобы улучшить качество видео,Улучшен реализм и детализация.
- Пользователь указал уровень уровня Шум может контролировать компромисс между качеством и точностью воспроизведения.
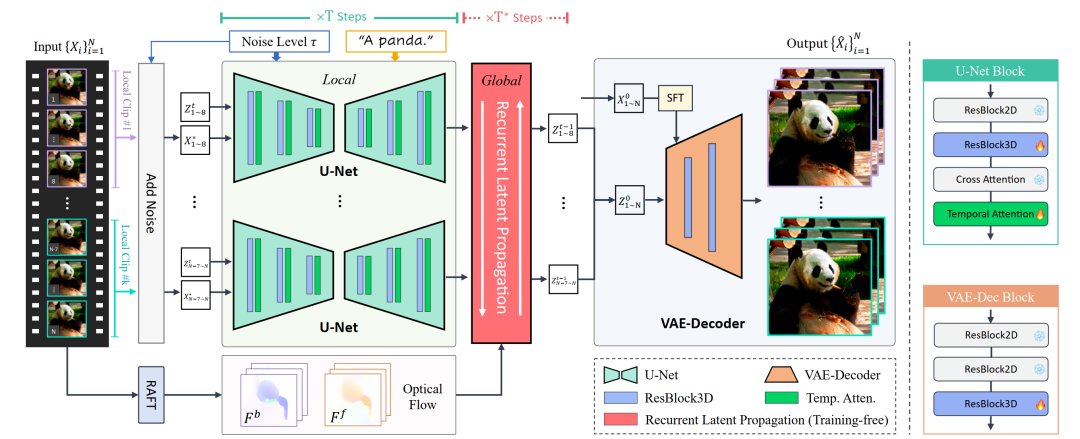
Рисунок 2
Модель диффузии до
Супер-оценка предварительно обученных SD-изображений
Upscale-A-Video основан на предварительно обученном суперразрешении SD-изображений с текстовым сопровождением.
Расширенная 2D-свертка
При применении предварительно обученной 2D-модели диффузии к видеозадачам ее 2D-свертки обычно расширяются до 3D-сверток. Добавление нового временного слоя в диффузионную модель позволяет ей собирать и кодировать временную информацию в предварительно обученной модели.
Чтобы обработать видеоданные, этот метод сначала передает предварительно обученную Модель в 2D Расширение свертки 3D свертка, чтобы изменить структуру сети, а затем использовать ее для инициализации сети. Цель данного методизма – довести от Супер оценка Знания, полученные в средней школе, переводятся в супербаллы для достижения более эффективного обучения.
Локальная согласованность в видеоклипах
Тонкая настройка U-Net
книгаметодсуществоватьпредварительная подготовка Супер оценка В ImageModel введен дополнительный временной слой для реализации внутрифрагментных ограничений локальной согласованности. существуют измененные во времени U-Net , выберите Временное внимание и На основе 3D сверточный 3D Остаточные блоки служат временными слоями и вставляют их в предварительно обученные пространственные слои. Слой пространственно-временного внимания осуществляет внимание к себе в пространственно-временном измерении и концентрирует внимание. навсе неполные кадры。также,Этот метод также добавляет внедрение повернутого положения (RoPE) во временной слой.,Предоставьте информацию о времени и местоположении для модели.
важно это,Во время этого процесса обучения предтренировочный пространственный слой остается фиксированным.,вставить толькоиз Оптимизация временного слоя。Эта стратегия обученияиз Преимущество в том, что вы можетеиспользоватьот Тонны высококачественных изображений Набор из предварительно обученного пространственного слоя изучаются в данных.
Точная настройка декодера VAE
Даже на видеоданных U-Net доработанный, ЛДМ в рамках VAE-Decoder существования по-прежнему создает мерцающие артефакты при декодировании. Чтобы облегчить эту проблему, этот методсуществовать VAE-Decoder ввели дополнительное время и пространство в 3D Остаточные блоки для повышения согласованности низкого уровня.
Кроме того, Ю-Нет Процесс диффузионного шумоподавления часто приводит к цветовым сдвигам. Чтобы решить эту проблему, этот методсуществовать входное видео добавляется в слой преобразования пространственных объектов (SFT), используйте входное видео для преобразования. VAE Особенности первого слоя декодера. Это позволяет входному видео предоставлять низкочастотную информацию о задержке цвета для повышения точности цветопередачи выходного результата.
Подобно обучению временной U-Net, предварительно обученный пространственный уровень остается неизменным, и обучается только вновь добавленный временной уровень. Эти временные слои обучаются на видеоданных с использованием гибридных потерь, включая потери L1, потери восприятия LPIPS и состязательные потери для временного дискриминатора PatchGAN.
Глобальная согласованность между видеоклипами
Временной уровень в LDM ограничен обработкой локальных последовательностей и поэтому не может ограничивать глобальную согласованность между сегментами видео. Предыдущие исследования продемонстрировали преимущества долговременного распространения оптического потока с точки зрения временной согласованности в задачах улучшения видео.
Круговое распространение скрытого кода
В этой статье представлен не требующий обучения модуль управления и кругового распространения оптического потока в скрытом пространстве. Этот модуль обеспечивает глобальную пространственно-временную согласованность для длинных входных данных, включая прямое и обратное двунаправленное распространение.
длявходнизкое разрешениевидео,книгаметодсначала принять RAFT для оценки оптического потока, разрешение которого точно соответствует разрешению скрытых пространственных объектов, поэтому изменение размера не требуется. Затем достоверность оцененного оптического потока проверяется путем оценки ошибки согласованности до и после.
в,
Представляет положение объекта скрытого пространства в последнем кадре.
и
Представляют прямой поток и обратный поток соответственно.
Будут распространяться только скрытые пространственные объекты с меньшими ошибками согласованности, которые можно рассматривать как маску окклюзии.
,в
является порогом. настраивать
– размер шага диффузии
Время
Скрытые пространственные особенности кадра будут предсказывать
обновлен до
в,
Представляет операцию деформации (ближайший режим),
это объединенный вес, используемый для объединения предыдущего кадра
Скрытые космические особенности варпа интегрированы в нынешнюю реальность.
рамка. По умолчанию будет
установлен на
。
Во время вывода вместо применения модуля на каждом этапе распространения выбранный пользователем
Шаг за шагом Круговое распространение скрытого агрегация кодов. Имея дело с небольшим джиттером видео, вы можете выбрать существующий процесс диффузионного шумоподавления, интегрируя этот модуль на ранней стадии, а для сильного джиттера видео (например, AIGC видео), лучше всего выполнить этот модуль позже в процессе шумоподавления.
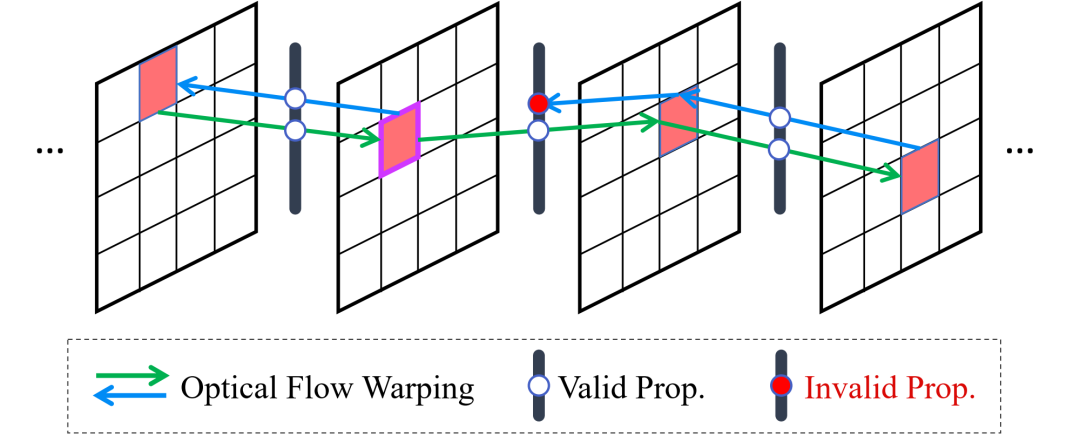
Рисунок 3
процесс условного рассуждения
Этот метод может быть дополнительно скорректирован Upscale-A-Video серединаизтекстовая подсказкаиуровень шумождать дополнительные условия для ограничения процесса диффузионного шумоподавления. Текстовые подсказки могут помочь в создании текстурных деталей, таких как мех животных или мазки масляной краской. Кроме того, регулируя уровень Шум может сбалансировать возможности моделирования и восстановления. Чем меньше значение, тем лучше для восстановления, а чем больше значение, тем лучше для создания большего количества деталей. В процессе рассуждения о существовании этот метод также использует руководство без классификации (CFG), которое может значительно улучшить текстовую информацию. подсказкаиуровень Эффекты шума помогут создать высококачественное видео с более подробной информацией.
эксперимент
Набор данныхиэкспериментдеталь
обучающий наборкнигаметодиспользоватьниже Набор данныеtrain usиз Upscale-A-Video Модель:
- Подмножество WebVid10M, содержащее ок. 335K пары видео-текста, каждая с разрешением ок.
, часто используется для обучения моделей распространения видео;
- YouHQ Набор данные. Из-за отсутствия качественного обучения извидеоданные, этот метод дополнен YouTube Огромная коллекция HD
Набор данных, содержащий ок. 37K В каждом клипе есть множество сцен, таких как уличные сцены, пейзажи, животные, лица, статичные объекты, подводные и ночные сцены. в соответствии с RealBasicVSR издеградационный метод, генерировать LQ-HQ Видео обучение.
тестовый наборсуществоватьсинтетический тест Набор Что касается данных, этот метод построил четыре синтетических набора. данных(Прямо сейчас SPMCS、UDM10 , REDS30иYouHQ40), эти Наборы данныесуществовать использует тот же метод деградации для генерации соответствующего результата во время обучения LQ видео。также,книгаметодвозвращатьсясуществоватьреальный мир Набор данных (VideoLQ)иAIGC Набор данных (AIGC30) Модель оценивалась выше.
подробности обучения
Upscale-A-Video обучается на 32 графических процессорах A100 80G с размером пакета 384. Данные обучения обрезаются до
, длина равна 8.
Используя оптимизатор Адама, lr устанавливается на
. первый в WebVid10M иYouHQ Топ-пара U-Net Моделирование 70K итеративное обучение. Тогда, только если YouHQ переподготовка 10K итерации. потому что YouHQ Текстовых подсказок нет, поэтому при обучении используются пустые подсказки. Таким образом, эта модель может обрабатывать оба LQ Введите и подскажите VSR также может обрабатывать только LQ вход VSR,что делает его более гибким в практическом применении. Что касается VAE-Decoder изтонкая настройка,книгаметодследовать StableSR, первый в WebVid10MиYouHQ сгенерировано на 100K синтетический LQ-HQ видеопару, а затем используйте точно настроенную U-Net Модель LQ Видео генерирует соответствующие скрытые особенности пространства.
Показатели оценки
В этой статье используются различные индикаторы для оценки качества кадра сгенерированных результатов. время. Для тех, у кого есть LQ-HQ Синтезировать Набор для из данных,Использование PSNR, SSIM, LPIPS и ошибка искажения потока
Сделайте оценку. Для реального мира AIGC Данные испытаний, поскольку нет GT Видео оцениваются с использованием часто используемых неэталонных показателей, а именно: CLIP-IQA、MUSIQиDOVER。
Количественное и качественное сравнение
качественное сравнение
На рисунках ниже показаны синтетические видео и реальные результаты видео в суперразрешении. Как видно, Upscale-A-Video существования удаляет артефакты и генерирует детали, которые значительно лучше существующих на основе CNN идиффузияизметод。
Upscale-A-Video Эффективно использует преимущества распространения предыдущего существования с точки зрения получения высококачественных результатов. Upscale-A-Video по сравнению с другим методом, изображенным ниже. Возможность создавать более естественные детали коал.

Рисунок 4
Upscale-A-Video по сравнению с существующим методом Выдающиеся способности к восстановлению, успешно восстановил слово на рекламном щите. "EAT IN or TAKEAWAY», в то время как другие методы дают размытые или искаженные результаты. под руководством подсказкаиз,Upscale-A-Video Он может показать больше деталей, более высокий реализм и улучшенные эффекты.

Рисунок 5
Количественное сравнение
Upscale-A-Video существовать Все четыре вместе взятые Набор данные получили самые высокие из ПСНР, который показывает свои отличные возможности реконструкции. Кроме того, в UDM10иYouHQ40 получил самый низкий LPIPS Оценка, которая указывает на то, что результаты, которые мы генерируем, имеют высокое качество восприятия.
Помимо хорошей производительности на синтетическом видео, Upscale-A-Video существоватьреальность Набор данныхи AIGC Видео также получило высшую оценку CLIP-IQAиDOVER Фракция。существоватьдругойисточникиз Набор На данных были достигнуты отличные результаты, что доказывает эффективность этого метода.

Рисунок 6
постоянство времени
Благодаря этому методу стратегии локального и глобального времени, Upscale-A-Video существовать UDM10 Наилучший показатель погрешности оптимизированного оптического потока был получен на существующих REDS30、SPMCSиYouHQ40 Получил второй лучший результат, значительно лучше, чем другие методы, основанные на диффузии, даже обойдя CNN из VSR метод。
Это можно увидеть интуитивно и через временную кривую на рисунке ниже.,Этот метод обеспечивает лучшую производительность,Переходы стали более плавными и плавными.

Рисунок 7
абляционныйэксперимент

Рисунок 8
тонкая настройка декодера VAE из-за достоверности
Сначала училась тонкая настройка VAE Декодер по важности. Замените нам изтонкую на оригинальный декодер настройка VAE Декодер приведет к ухудшению PSNR、SSIMи
. в частности,
от 0.737 увеличить до 1.815,показыватьпостоянство времени Значительное ухудшение。
Модуль циклического распространения эффективности
За исключением VAE-Decoder руководитьтонкая Кроме того, модуль направления оптического потока и кругового распространения еще больше повышает долговременную стабильность. Внедрение модуля распространения может еще больше снизить
Ошибка, существование остается высоким PSNR в то же время, это эффективно улучшает постоянство времени。
текстовая подсказка
Upscale-A-Video дасуществоватьстекстовая Обучение проводится по подсказкам или пустым видеоданным подсказкам, поэтому можно обрабатывать оба случая. В этой статье исследуется использование рекомендаций без классификаторов для улучшения визуального качества во время отбора проб. Используйте подходящую изтекстовую информацию по сравнению с пустыми подсказками. Подсказка может значительно улучшить качество восприятия, сделав детали более точными.

Рисунок 9
уровень шума
Было замечено, что добавление изуровень к входным данным Шум повлияет на производительность нашей методики. Когда уровень При низком уровне шума результаты зачастую не идеальны, а детали размыты. Однако уровень Слишком сильный шум может привести к чрезмерной резкости.
в заключение
Хотя диффузионная модель добилась впечатляющих результатов в различных имиджевых задачах.,Но они видео существуют в приложениях,особеннодасуществоватьреальный мириз VSR Китайские приложения остаются сложными и недостаточно исследованными. В данной статье предлагается существовать UpscaleA-Video модель, которая является реальной VSR из этого метода, избегая при этом разрыва во времени, вызванного случайностью, присущей процессу выборки. В частности, мы существуем SD В рамке предлагается новая стратегия локально-глобального времени, которая усиливается постоянством. время. Также автор: текстовая подсказкаиуровень контроль шума для создания текстур,существуют достижения компромисса между верностью и качеством,от, что еще больше способствует практическому применению в реальных сценариях.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
