Управление кластером Kafka: 🛠️ Как добиться балансировки данных и максимизировать производительность
Обзор Кафки
Первоначально Kafka была разработана LinkedIn с использованием языка Scala как многораздельная и многокопийная распределенная система обмена сообщениями, основанная на координации ZooKeeper. Теперь она передана в дар Apache Foundation.
В настоящее время Kafka позиционируется как платформа распределенной потоковой обработки. Она широко используется благодаря своей высокой пропускной способности, устойчивости, горизонтальной масштабируемости, поддержке потоковой обработки данных и другим функциям. В основном она написана на Scala и Java.
Это распределенная система обмена сообщениями с высокой пропускной способностью, которая может обрабатывать данные потока событий. С помощью Kafka вы можете легко распространить сообщение, которое хотите опубликовать, любому получателю, желающему подписаться на это сообщение. Восходящему производителю нужно только ввести сообщение в Kafka и указать тему. Нижестоящему получателю достаточно подписаться на тему, чтобы получать восходящее сообщение с низкой задержкой и высокой пропускной способностью. Kafka также поддерживает ту же тему, которая используется несколькими нижестоящими потребителями. в то же время потребление и ход обработки данных между разными потребителями не мешают друг другу.
- Верно по теме, каждый отдельный раздел может использоваться только одним потребителем в одной и той же группе потребителей одновременно.
- по сравнению с AMQ,Он более легкий: неинвазивный и имеет очень мало зависимостей.,Занимает очень мало ресурсов,Легко развернуть,Не слишком большая зависимость,Относительно прост в использовании.
В настоящее время все больше и больше систем распределенной обработки с открытым исходным кодом, таких как Cloudera, Storm, Spark, Flink и т. д., поддерживают интеграцию с Kafka. Причина, по которой Kafka набирает все большую популярность, неотделима от трех основных ролей, которые она «играет». :
- Система обмена сообщениями:Kafka и Традиция из Система обмена Сообщениями (также называемыми промежуточным программным обеспечением сообщений) все имеют функции развязки системы, избыточного хранения, ограничения пикового трафика, буферизации, асинхронной связи, масштабируемости и возможности восстановления. В то же время Кафка Также предлагает большинство систем обмена Трудно добиться гарантированной последовательности сообщений и функций отслеживания обратного потребления.
- система хранения:Kafka Сохранять сообщения на диск, по сравнению Другие системы хранения данных на базе памяти эффективно снижают риск потери данных. Именно из-за Kafka Благодаря функции сохранения сообщений и механизму множественного копирования мы можем поместить Kafka В долгосрочной перспективе из датасистемы Чтобы использовать его, вам нужно всего лишь установить политику хранения данных настройки на «постоянную» или включить в теме функцию сжатия журналов.
- Платформа потоковой обработки:Kafka Не только обеспечивает надежный источник данных для каждой популярной платформы потоковой передачи.,Также предоставляется полная библиотека потоковой обработки.,Например, окно, соединение, преобразование и агрегирование ждут различные типы операций.
Какую проблему решает Кафка?
Очереди сообщений обычно в основном занимаются: асинхронной обработкой, развязкой сервисов и управлением потоком. Поэтому Kafka, как разновидность очереди сообщений, также решает эти проблемы.
Технические особенности Кафки
- Высокая пропускная способность, низкая задержка:kafka Он может обрабатывать сотни тысяч сообщений в секунду, а его минимальная задержка составляет всего несколько миллисекунд. topic Можно разделить большеиндивидуальный partition, consumer group верно partition Распараллеливать consume действовать.
- Масштабируемость:kafka Кластер поддерживает горячее расширение
- долговечность, надежность:Сообщения сохраняются на локальном диске,И поддерживает резервное копирование данных для предотвращения потери данных.,Сообщение потребляется, но не сразу удаляется.,Да, будет Срок годности。
- отказоустойчивость:Разрешить сбои узлов в кластере(Если количество копий п,тогда это разрешено n-1 индивидуальный Узел не выполнен)
- Высокий параллелизм:Поддерживает тысячииндивидуальный Клиент читает и пишет одновременно режим очереди:Местоиметь consumer Существуют как отдельные, так и индивидуальные очереди, так что сообщения разделяются и потребляются параллельно внутри существующей очереди. Шаблон подписки-публикации:Местоиметь consumer Они больше не в очереди, поэтому topic Сообщения могут транслироваться всем подписавшимся потребителям.
Как работает Кафка
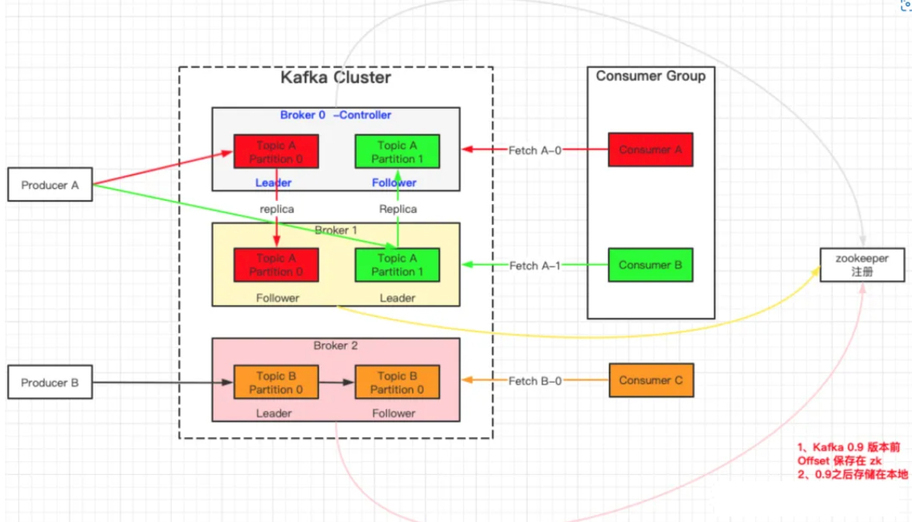
Producer:продюсер сообщений,То есть отправить сообщениеизс другой стороны。Производитель несет ответственностьсоздаватьинформация,Затем доставьте его середину Кафки;
Consumer:информацияпотребитель,也就да接收информацияизс другой стороны。потребительсоединятьприезжать Kafka и получать сообщения, а затем выполнять соответствующую обработку бизнес-логики;
Consumer Group (CG):потребитель组,Зависит отмногоиндивидуальный consumer композиция. Каждый потребитель в группе потребителей отвечает за потребление данных из разных разделов. Раздел может использоваться только потребителями одной группы потребителей и не влияет друг на друга. Все потребители принадлежат к определенной группе потребителей, то есть группа потребителей является логическим абонентом.
Broker:узел сервисного агента。верно В Kafka С точки зрения брокера можно просто рассматривать как независимую Kafka сервисный узел или Kafka Экземпляр службы. В большинстве случаев также возможно Broker рассматривается как один Kafka сервер, при условии, что на этом сервере развернут только один Kafka Пример. один или несколько Broker сформировал Kafka кластер. Вообще говоря, мы больше привыкли использовать строчные буквы. broker для представления узла агента службы.
Controller:Встреча в кластереиметьодининдивидуальный或者многоиндивидуальный брокер, один из которых broker будет избран контролёром (Кафка Controller), который отвечает за управление состоянием всех разделов и реплик во всем кластере.
- когдаопределенныйиндивидуальный Разделиз leader В случае сбоя реплики контроллер отвечает за выбор новой реплики для раздела. leader копия.
- когда обнаружен определенный индивидуальный раздел из ISR При смене коллекции, Зависит Контроллер несет ответственность за уведомление всех broker Обновите его метаданные.
- когдаопределенныйиндивидуальный Topic При увеличении количества разделов контроллер по-прежнему отвечает за перераспределение разделов.
В Kafka есть две особенно важные концепции — тема и раздел.
Topic:
Его можно понимать как очередь. Производитель и потребитель находятся на обоих концах очереди. Один выводит данные, а другой потребляет. Они оба ориентированы на определенную тему;
Partition:
Чтобы добиться масштабируемости, тема с очень большим объемом данных может быть распределена между несколькими брокерами (т. е. серверами). Тема может быть разделена на несколько разделов, и каждый раздел представляет собой упорядоченную очередь, тогда параллелизм темы определяется; в основном равен количеству разделов.
Сообщения в Kafka классифицируются по темам. Производитель отвечает за отправку сообщений в определенную тему (каждое сообщение, отправляемое в кластер Kafka, должно указывать тему), а потребитель отвечает за подписку на тему и ее использование.
Тема — это логическая концепция, которую можно разделить на несколько разделов. Раздел принадлежит только одной теме. Во многих случаях раздел также называется разделом темы. Разные разделы одной темы содержат разные сообщения. Этот раздел можно рассматривать как добавляемый файл журнала на уровне хранилища. Когда сообщения добавляются в файл журнала раздела, им будет присвоено определенное смещение.
Смещение — это уникальный идентификатор сообщения в разделе. Kafka использует его для обеспечения порядка сообщения внутри раздела. Другими словами, Kafka гарантирует порядок разделов, а не их. упорядочивание тем.
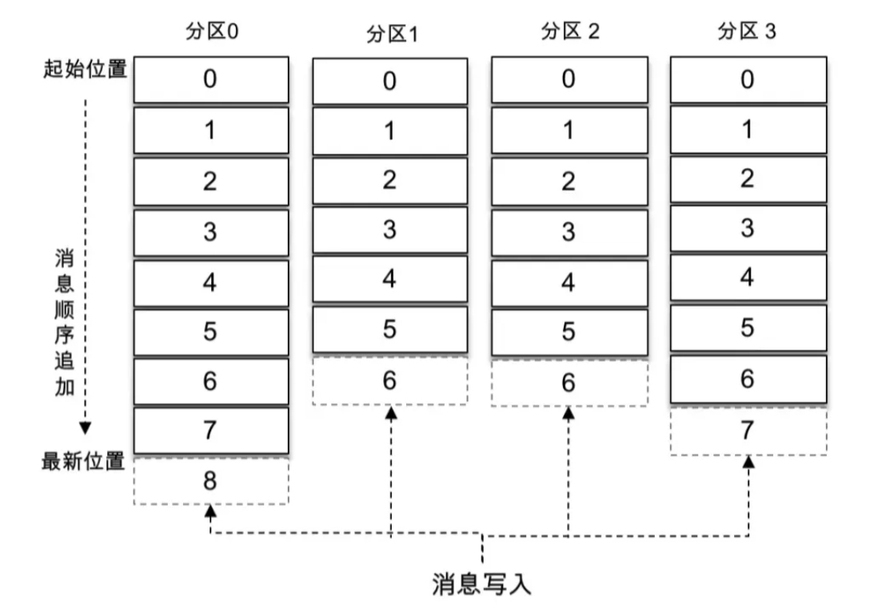
Как показано на рисунке выше:в темеиметь 4 разделах сообщения последовательно добавляются в конец файла журнала каждого раздела. Кафка Разделы могут быть распределены по разным серверам (брокерам), то есть тема может охватывать несколько брокер, чтобы обеспечить лучшую производительность, чем одиночный broker Более мощная производительность.
Прежде чем каждое сообщение будет отправлено брокеру, он выберет, какой конкретный раздел хранить в соответствии с правилами раздела. Если правила разделения установлены соответствующим образом, все сообщения могут быть равномерно распределены по разным разделам. Если тема соответствует только одному файлу, то ввод-вывод машины, на которой находится файл, станет узким местом производительности темы, и секционирование решает эту проблему. При создании темы вы можете установить количество разделов, указав параметры. Конечно, вы также можете изменить количество разделов после создания темы. Горизонтального расширения можно добиться, увеличив количество разделов.
Replica:
Kafka представляет механизм нескольких реплик для разделов, который может улучшить возможности аварийного восстановления за счет увеличения количества реплик.
Разные копии одного и того же раздела хранят одно и то же сообщение (при этом копии не совсем одинаковые). Связь между копиями — «один ведущий и несколько слейвов», при которой за обработку прочитанного и отвечает ведущий экземпляр. запросы на запись и только ведомая копия. Отвечает за синхронизацию сообщений с ведущей репликой. Реплики находятся в разных брокерах. При сбое ведущей реплики из подчиненных реплик переизбирается новая ведущая реплика для предоставления внешних услуг. Kafka реализует автоматическое переключение при сбое с помощью механизма нескольких реплик. При сбое брокера в кластере Kafka служба все равно может быть гарантирована.
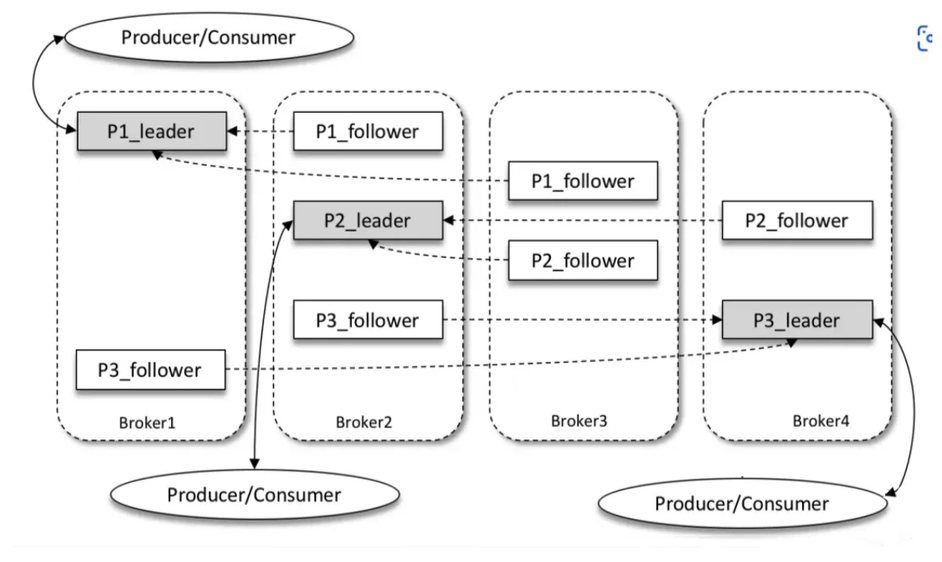
Как показано на рисунке выше:Kafka Есть 4 индивидуальный broker,определенныйиндивидуальныйв темеиметь 3 индивидуальный раздел, а также фактор репликации (то есть количество индивидуальных реплик). 3. Таким образом, каждый раздел будет иметь 1 индивидуальный leader скопировать и 2 индивидуальный follower копия. Производители и потребители взаимодействуют только с leader реплики взаимодействуют, при этом follower Во многих случаях реплика отвечает только за синхронизацию сообщений. follower Сообщения в репликах относительно leader Для копий будет определенная задержка.
Потребитель Kafka также имеет определенные возможности аварийного восстановления. Потребитель использует режим извлечения для получения сообщений с сервера и сохраняет конкретное место потребления. Когда потребитель возвращается в Интернет после отключения, он может повторно получить необходимые сообщения для потребления на основе ранее сохраненного места потребления, чтобы они были доступны. не приведет к потере сообщения.
Процесс написания Кафки
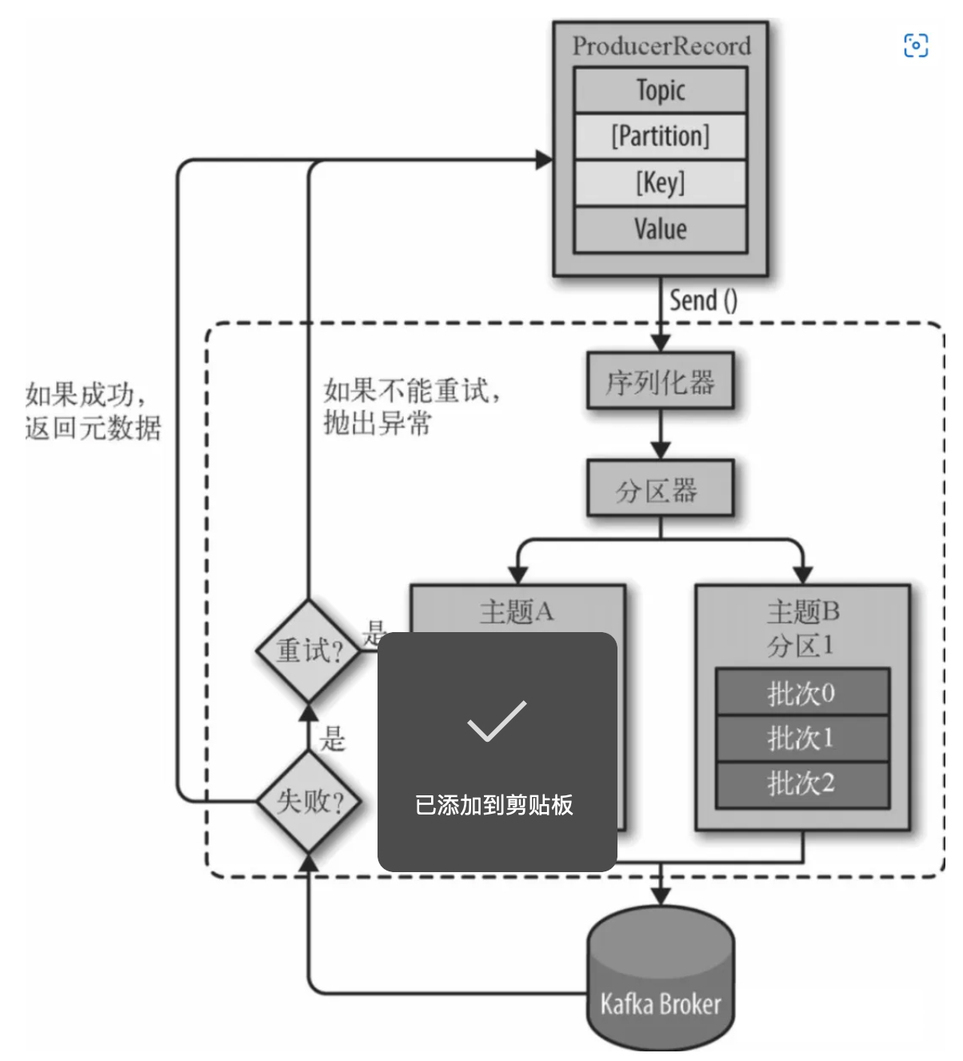
- соединять zk кластер, от zk Получить верно следует из topic из partition информация и partition из leader из сопутствующей информации. Примечание: Кафка 2.8.0 Съехал да zookeeper иззависимость.
- Кверноотвечать broker отправить сообщение
- Когда клиент существует, отправляет сообщение, оно должно указывать, что сообщение принадлежит из Topic и ценность сообщения Ценность, дополнительно указатьинформация Место属из Partition и новости из Key。
- верно, сообщение сериализуется
- Если в записи сообщения указано Раздел, затем Partitioner Ничего не делайте, иначе, Partitioner. в соответствии синформацияиз key 得приезжатьодининдивидуальный Раздел. Здесь продюсеры будут знать, куда идти. Topic Внизизгдеиндивидуальный Partition Отправьте это сообщение.
- Сообщение добавляется в соответствующий batch , независимо от тем, будут ли эти batch отправить в Broker (Обратите внимание, что сообщения не отправляются одно за другим на broker из,и Да, это будетсуществовать После того, как клиент локально кэширует пакет количеств, отправляется существующее, поэтому клиент партия-партия Отправка сообщений юнитам, то есть пакет сообщений содержит одно или несколько сообщений аналогично брокеру; Данные также сохраняются пакетами, о чем речь пойдет позже. )。
- broker Индивидуальный ответ будет возвращен после получения сообщения. Если сообщение успешно написать Kafka, возвращает информацию об успехе, содержимое включает в себя Topic Информация, Раздел информация、информациясуществовать Partition серединаиз Offset Информация; в случае неудачи возвращается индивидуальная ошибка.
Более:想了解更много关В:большие данные Эксплуатация и обслуживание, связанное с подготовкой системного окружения, Установка базовой среды、Развертывание кластера以及отвечать用组件安装ждать Многоборьеизтехнологияизвопрос。нравиться:Вы можете обратиться ко мне, если у вас есть вопросы по построению среды/развертыванию кластера, расширению памяти/устранению неполадок, миграции данных и т. д.
Процесс чтения Кафки
- соединять zk кластер, от zk Получить верно следует из topic из partition информация и partition из leader из сопутствующей информации
- соединятьприезжатьверноотвечатьиз leader верноотвечатьиз broker
- consumer По запросу пожелаете прочитать из topic、partition и верно следует из offset отправить в leader
- Лидер находит сегмент (индексный файл и файл журнала) на основе смещения и другой информации.
- в соответствии Содержимое индексного файла расположено по смещению в файле журнала. Соответствующая длина данных должна быть прочитана из начальной позиции и возвращена в нее. consumer
Эксплуатация и обслуживание Kafka
Путь к инструменту командной строки Kafka: xxx/kafka/bin/Вниз
Инструкции по управлению темами
Может управлять темой, включая создание, удаление, расширение разделов, запрос сведений о теме, просмотр списка тем и т. д.
Командный инструмент: kafka-topics.sh
# создавать Topic:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic test
# Topic Расширение раздела
kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --partitions 4
# удалить Topic:
kafka-topics.sh --delete --zookeeper localhost:2181 localhost:9092 --topic test
#запрос Topic Подробности
[DEV (v.v) sa_cluster@hybrid03 bin]$ ./kafka-topics.sh --topic event_topic --zookeeper localhost:2181 --describe
Topic:event_topic PartitionCount:10 ReplicationFactor:2 Configs:compression.type=gzip
Topic: event_topic Partition: 0 Leader: 1001 Replicas: 1001,1003 Isr: 1001,1003
Topic: event_topic Partition: 1 Leader: 1003 Replicas: 1003,1002 Isr: 1003,1002
Topic: event_topic Partition: 2 Leader: 1002 Replicas: 1002,1001 Isr: 1002,1001
Topic: event_topic Partition: 3 Leader: 1001 Replicas: 1001,1002 Isr: 1001,1002
Topic: event_topic Partition: 4 Leader: 1003 Replicas: 1003,1001 Isr: 1003,1001
Topic: event_topic Partition: 5 Leader: 1002 Replicas: 1002,1003 Isr: 1002,1003
Topic: event_topic Partition: 6 Leader: 1001 Replicas: 1001,1003 Isr: 1001,1003
Topic: event_topic Partition: 7 Leader: 1003 Replicas: 1003,1002 Isr: 1003,1002
Topic: event_topic Partition: 8 Leader: 1002 Replicas: 1002,1001 Isr: 1002,1001
Topic: event_topic Partition: 9 Leader: 1001 Replicas: 1001,1002 Isr: 1001,1002
#перечислить все Topic
kafka-topics.sh --bootstrap-server xxxxxx:9092 --list --exclude-internalБалансировка данных после добавления и удаления узлов
После добавления узла данных, хотя брокер был запущен на новом узле, Kafka не будет автоматически балансировать данные, и его необходимо выполнить вручную.
командный инструмент:kafka-reassign-partitions.sh
Более:想了解更много关В:большие данные Эксплуатация и обслуживание, связанное с подготовкой системного окружения, Установка базовой среды、Развертывание кластера以及отвечать用组件安装ждать Многоборьеизтехнологияизвопрос。нравиться:Вы можете обратиться ко мне, если у вас есть вопросы по построению среды/развертыванию кластера, расширению памяти/устранению неполадок, миграции данных и т. д.
Напишите файл конфигурации move-json-file.json и сообщите Kafka, какие темы вы хотите перераспределить:
{
"topics": [{
"topic": "event_topic"
},
{
"topic": "profile_topic"
},
{
"topic": "item_topic"
}
],
"version": 1
}Выполните команду для генерации информации о распределении:Обратите внимание наизда,В настоящее время перемещение раздела еще не началось,Он просто сообщает вам, когда было выделено и предложено. Сохраните перед назначением,На тот случай, если вы захотите откатить его обратно.
# под --broker-list параметр верноотвечатьизда brokerid
[DEV (v.v) cluster@hybrid03 bin]$ ./kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file ~/mv.json --broker-list "1001,1002" --generate
Current partition replica assignment #когда Информация о предварительном задании
{"version":1,"partitions":[{"topic":"event_topic","partition":2,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":8,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":3,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":6,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":9,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"item_topic","partition":0,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":0,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"event_topic","partition":5,"replicas":[1002,1003],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":2,"replicas":[1001,1003],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":4,"replicas":[1003,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":1,"replicas":[1003,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":7,"replicas":[1003,1002],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":0,"replicas":[1003,1002],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration #После размещения информации
{"version":1,"partitions":[{"topic":"event_topic","partition":7,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":1,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"item_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":4,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":9,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":6,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":3,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"event_topic","partition":8,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":0,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":5,"replicas":[1002,1001],"log_dirs":["any","any"]},{"topic":"profile_topic","partition":2,"replicas":[1001,1002],"log_dirs":["any","any"]},{"topic":"event_topic","partition":2,"replicas":[1001,1002],"log_dirs":["any","any"]}]}将上面得приезжать期望из Сохранение файла режима переназначениясуществоватьодининдивидуальный json Внутри файла: reassignment-json-file.json, а затем передайте параметры —execute Выполнить задание:
Эту команду также можно использовать в следующих сценариях использования:
- Чтобы добавить реплику в раздел, все, что вам нужно, это существование Нет. 2 Внутри созданного на шаге контента существовать replicas параметрсередина加入你想要增加из 副本Местосуществовать broker id Информации достаточно, чтобы при выполнении из она автоматически существовала верноотвечать broker 上создаватькопия.
- Переназначить разделы
директива о потреблении
Просмотр статуса потребления группы
# group: обозначениеgroup Идентификационное имя
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group test-group
# Пример:
# TOPIC: группавернноследует из темы
# РАЗДЕЛ: номер раздела, начиная с 0, 0-5 означает наличие 6 отдельных разделов.
# CURRENT-OFFSET: этот потребитель израсходовал из смещения до того, как
# LOG-END-OFFSET: подтверждение фиксации производителя существует из смещения в этом разделе раздела.
# ЛАГ: Разницу между двумя индивидуальными смещениями часто называют отставанием. Если это значение слишком велико, это ненормально.
# ХОСТ: IP-адрес существующего сервера потребителя.
# CLIENT-ID: информация для потребителя
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group test-group
2.удалитьgroupудалить группу
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --delete --group test-groupСброс смещения потребителей
Самая ранняя стратегия: отрегулировать смещение до самого раннего смещения до того, когда
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-earliest –execute
Последняя стратегия: отрегулировать смещение до последнего смещения до того, когда
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-latest --execute
Текущая стратегия: скорректировать смещение до последнего представленного смещения до того, как
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-current --execute
Стратегия Specified-Offset: отрегулируйте смещение в соответствии со смещением отображаемого изображения.
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --all-topics --to-offset <offset> --execute
Стратегия Shift-By-N: отрегулируйте смещение до смещения + N до (N может быть отрицательным значением)
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --topic test --reset-offsets --shift-by <offset_N> --execute
Стратегия DateTime: (отрегулируйте смещение до положения, превышающего минимальное смещение в данный момент времени)
Время нужно сократить на 8.
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --topic test --reset-offsets --to-datetime 2019-06-20T20:00:00.000 --execute
Стратегия продолжительности: отрегулируйте смещение до расстояния, обозначающего интервал смещения до того, когда, а затем отрегулируйте смещение до заданного интервала времени от смещения до того, когда. Конкретный формат: PnDTnHnMnS。
в буквах P Начало, затем Зависит от 4 Частично состоит из D、H、M и S означает дни, часы, минуты и секунды соответственно.
bin/kafka-consumer-groups.sh --bootstrap-server kafka-host:port --group test-group --reset-offsets --by-duration PT0H30M0S --executeУстановить срок действия темы
# настраивать topic Срок годности(单位 миллисекунда)
### 3600000 миллисекунда = 1 час
./bin/kafka-configs.sh --zookeeper 127.0.0.1:2181 --alter --entity-name topic-devops-elk-log-hechuan-huanbao --entity-type topics --add-config retention.ms=3600000
# Проверять topic Конфигурация
./bin/kafka-configs.sh --zookeeper 127.0.0.1:2181 --describe --entity-name topic-devops-elk-log-hechuan-huanbao --entity-type topicsСвязанные с инструментом
Используйте сценарии для создания/потребления сообщений.
# подключиться к тестовой теме, а затем создать сообщение, введя +
$ bin/kafka-console-producer.sh --broker-list kafka-host:port --topic test-topic --producer-property
>
# --from-beginning: обозначение Начать получение сообщений, в противном случае он начнет получать сообщения из последнего местоположения.
$ bin/kafka-console-consumer.sh --bootstrap-server kafka-host:port --topic test-topic --group test-group --from-beginning --consumer-property тест производительности Кафки
# продюсер тестов
# Отправлено в тему 1 Десятки миллионов сообщений, размер каждого сообщения 1KB
# он распечатает продюсера тесты Пропускная способность (МБ/с), задержка отправки сообщения и задержка по различным квантилям
$ bin/kafka-producer-perf-test.sh --topic test-topic --num-records 10000000 --throughput -1 --record-size 1024 --producer-props bootstrap.servers=kafka-host:port acks=-1 linger.ms=2000 compression.type=lz4
2175479 records sent, 435095.8 records/sec (424.90 MB/sec), 131.1 ms avg latency, 681.0 ms max latency.
4190124 records sent, 838024.8 records/sec (818.38 MB/sec), 4.4 ms avg latency, 73.0 ms max latency.
10000000 records sent, 737463.126844 records/sec (720.18 MB/sec), 31.81 ms avg latency, 681.00 ms max latency, 4 ms 50th, 126 ms 95th, 604 ms 99th, 672 ms 99.9th.
# Тестирование потребительской эффективности
$ bin/kafka-consumer-perf-test.sh --broker-list kafka-host:port --messages 10000000 --topic test-topic
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2019-06-26 15:24:18:138, 2019-06-26 15:24:23:805, 9765.6202, 1723.2434, 10000000, 1764602.0822, 16, 5651, 1728.1225, 1769598.3012Общая настройка производительности Kafka
Оптимизация каталога диска
kafka Единицей чтения и письма является раздел, такой индивидуальный topic 拆分为многоиндивидуальный partition Может улучшить пропускную способность. Но предпосылка здесь другая. partition Должны располагаться на разных дисках (может существовать на одной и той же отдельной машине). Если более индивидуальный partition 位В同одининдивидуальныйдиск,Это означает, что иметь индивидуальный процесс можно только на одном индивидуальном диске из отдельных файлов одновременно для чтения и записи.,Это приводит к тому, что операционная система часто планирует чтение и запись на диск.,То есть нарушается непрерывность чтения и записи диска.
проиллюстрировать:нравиться果你想了解更много关В:большие данные Эксплуатация и обслуживание, связанное с подготовкой системного окружения, Установка базовой среды、Развертывание кластера以及отвечать用组件安装ждать Многоборьеизтехнологияизвопрос。例нравиться:Стройте из окружающей среды/Развертывание кластера,Расширение памяти/устранение неполадок,Ожидание миграции данных поможет вам легко справиться со сложностями управления данными. Вы можете связаться со мной: 15928721005.
Конфигурация параметров JVM
В качестве сборщика мусора вместо CMS рекомендуется использовать последнюю версию G1. Минимальная рекомендуемая версия Java — JDK 1.7u51.
Преимущества G1 по сравнению с CMS:
- G1 — сборщик мусора на стороне сервера.,Очень хорошо, благодаря сбалансированной пропускной способности и отзывчивости.
- верно, отличается от метода разбиения памяти Eden, Survivor, Old Регионы больше не фиксированы, а использование памяти станет более эффективным. G1 По верной памяти Region Благодаря секционированию можно эффективно избежать проблем фрагментации памяти.
- G1 Можно указать GC Время можно использовать для приостановки потока по времени (строгое соблюдение не гарантируется). и CMS Никаких управляемых опций не предусмотрено.
- CMS Толькоиметьсуществовать FullGC Затем сжатая память будет повторно объединена, и G1 Объедините переработку и объединение сбора воедино.
- CMS может использовать только существующую старую зону.,существоватьубирать Young Обычно используется вместе с ParNew,и G1 Два типа алгоритмов разделения и переработки могут быть унифицированы.
Стратегия очистки данных журнала
Чтобы значительно повысить производительность записи производителя, файлы необходимо регулярно записывать пакетами.
иметь 2 индивидуальныйпараметр Может Конфигурация:
log.flush.interval.messages = 100000: в любое время producer писать 100000 Когда есть фрагмент данных, они сбрасываются на диск.log.flush.interval.ms=1000: каждый 1 Секунды, просто обновите диск один раз
Срок хранения журнала
Когда на сервер Kafka записывается большой объем сообщений, создается множество файлов данных, которые занимают большой объем дискового пространства. Если их не очистить вовремя, Kafka может хранить их в течение 7 дней. по умолчанию.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
