Унифицированные метаданные: происхождение данных
Предыстория
Происхождение данных(Данные Lineage):управление даннымисередина Подкатегория в области управления метаданными.,Это процесс отслеживания данных,Получить ссылку для генерации данных,Откройте для себя взаимосвязи данных,Цель состоит в том, чтобы решить"Три философских вопроса о данных":кто я,откуда я родом,Куда мне идти?
Общие линии передачи данных в основном включают две категории:
- Родословная SQL:на основеSQL-анализASTсинтаксическое дерево,получатьSQLстол、полевая родословная;
- Бизнес-линия:частона основе Планирование задачDAGОтношения сгенерированных потоков данных;
Отраслевые решения
Решения по внедрению в отрасли, сравнение родословных данных проектов с открытым исходным кодом
проект | способность крови |
|---|---|
Apache Atlas | Реализовано на основе движка Hive, поддерживает только ограничение происхождения и типа Hive (Query, CreateTable/View). |
LinkedIn DataHub | Поддержка планирования задач, Родословная Поддержка SQL слабая и не поддерживает полевую родословная |
Lyft Amundsen | Поддерживает только линию планирования задач. |
Апач Производство родословной Улья Атласа в качестве примера。Hive Информация о кровном родстве, сгенерированная Хуком, будет отправлена в сообщение промежуточного программного обеспечения середина.,на основеHiveроднойHookContextсерединаполучать Информация о родословной,SQL типа Hive, который поддерживает анализ родословной:
- CREATETABLE_AS_SELECT: создать таблицу Hive на основе Select;
- CREATE_MATERIALIZED_VIEW: создание материализованного представления.
- CREATEVIEW: Создать представление;
- ALTERVIEW_AS: изменить таблицу просмотра;
- ЗАГРУЗКА/ЭКСПОРТ/ИМПОРТ: загрузка данных, импорт, экспорт;
- ЗАПРОС: сложный оператор запроса;
на основеLineageRESTКласс предоставляет запрос кровного родства объекта сущности.REST APIинтерфейс,на основеинтерфейсAtlasLineageService#getAtlasLineageInfo Реализуйте операции просмотра метаданных. Для получения более подробной информации см.«Управление отраслевыми метаданными: обзор разработки решения»
SQLFlowЭто коммерческий продукт,Родословная SQL-анализ для нескольких диалектов,поддерживать Родство、полевая родословная:
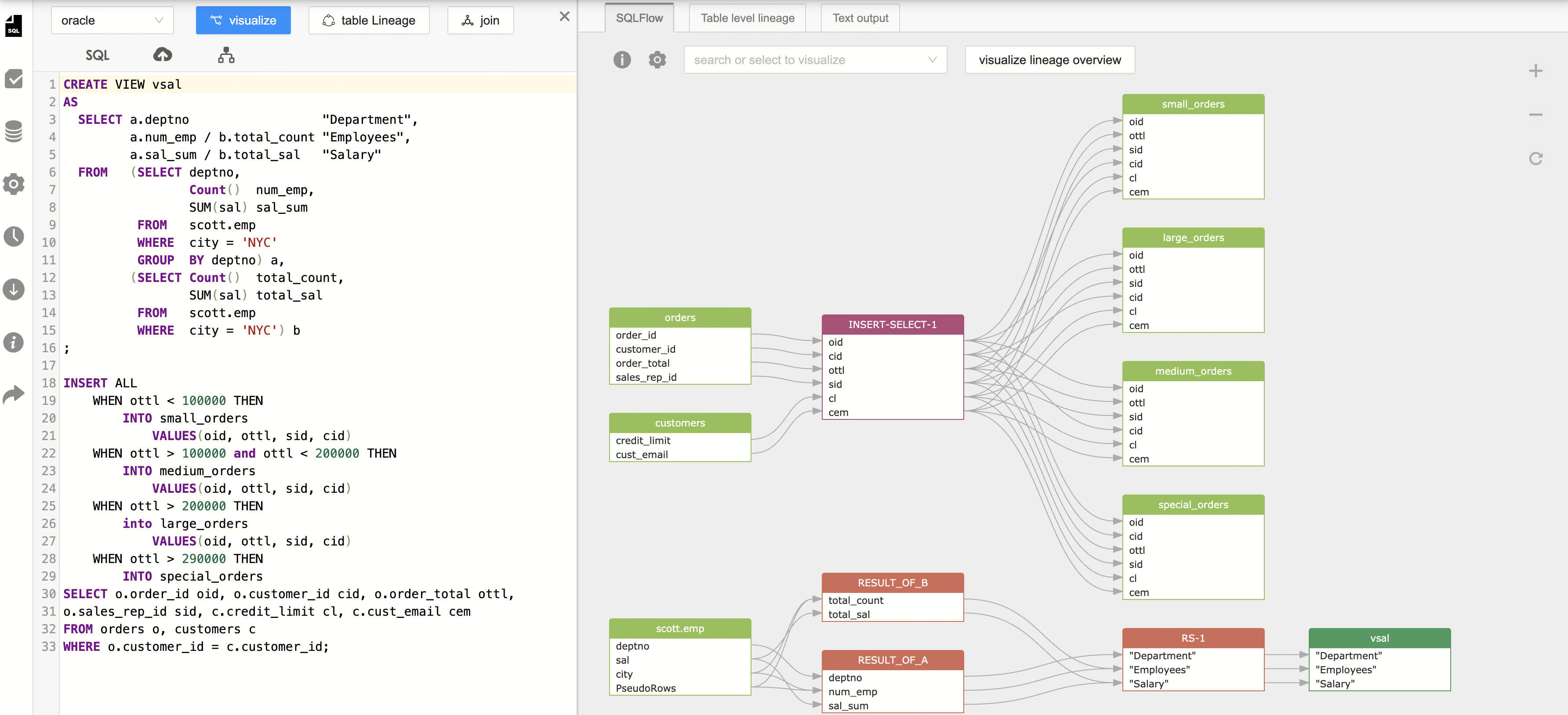
Родословная SQL
Более распространенные методы анализа происхождения задач включают в себя:1. Серия задач на основе системы планирования 2. Отслеживание на основе скрытых точек URL-запись。Потому что метод его реализации тесно связан с конкретным бизнесом.,Нет универсального шаблона проектирования,Поэтому я пока не буду вдаваться в подробности.。 Далее основное внимание будет уделено Родословной. SQL-анализ для уточнения.
Родословная SQL-анализ Ядро реализации:На основе абстрактного синтаксического дерева AST определите кровное родство таблиц и полей.。Поэтому анализ кровного родства требует как минимум следующих способностей::
- SQL-анализ:ВоляSQLЗаявление преобразуется вASTабстрактныйсинтаксическое дерево
- идентификация родословной:ТраверсASTсинтаксическое дерево,Определите соответствующую информацию о таблицах и полях.,Связывание восходящих и нисходящих родословных через древовидную структуру AST
- Хранение родословной:Информация о родословной обычно предоставляется вершиной(поверхность/Поле)Хебиан(Отношения вверх по течению и вниз по течению)композиция,поддерживатьструктура графаинформация о происхождении
в публичном облаке,Столкновение с разнообразными потребностями,определять Родословная SQL-анализ Цель:Поддержка происхождения данных для нескольких диалектов SQL, включая происхождение таблиц и происхождение полей.。 Для достижения этой цели план проведения демонтажа следующий.
SQL-анализ
Потому что разные диалекты SQL имеют разный синтаксический анализ.,Реализация синтаксического и семантического анализа непосредственно на основе собственного механизма SQL.,будет существоватьПроблема с сильным заеданием двигателя.
- Синтаксический анализ: если обработан на этом этапе,Посетитель для семантического анализа различных кровных родств, которому должен соответствовать каждый диалект.,рабочая Линейный рост
- Семантический анализ: если обработан на этом этапе,Сильная зависимость от метаданных,Объект кровного родства, полученный после семантического анализа, является неполным.,И есть только один слой крови
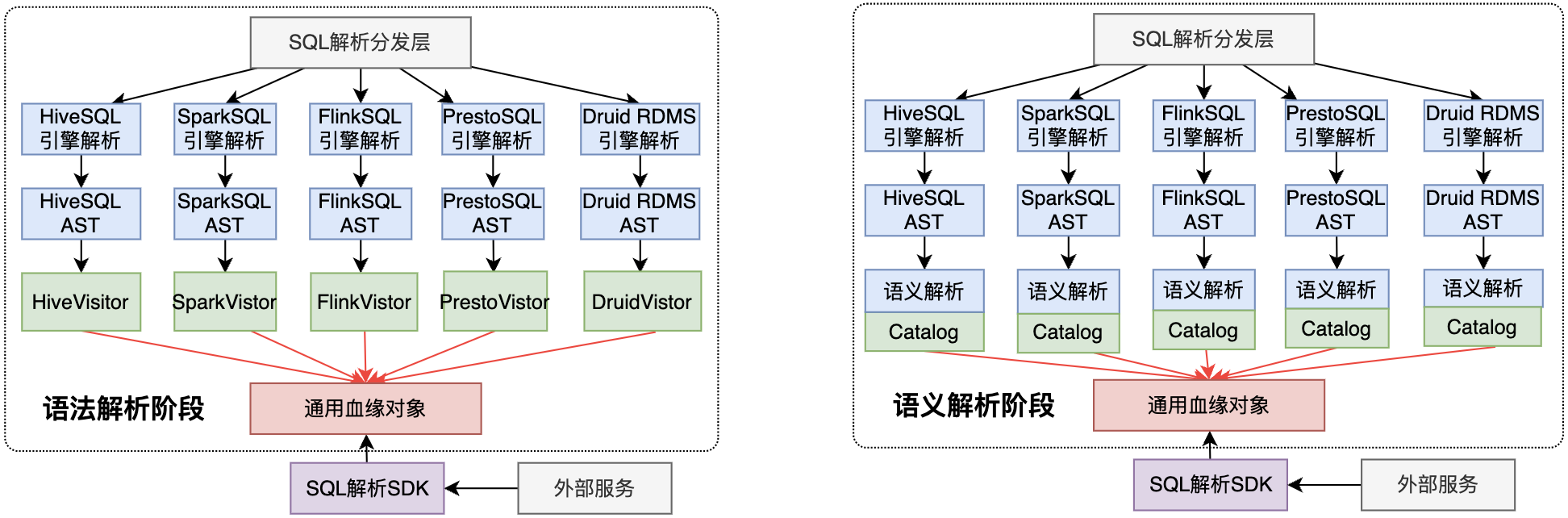
Согласно вышеизложенному,Выполняется на основе возможностей SQL-анализа каждого механизма.,Для многихSQLАнализ родословной диалектов невозможен.。Поэтому окончательный выбор был основан на конкретной реализации компонента SQL-анализа.,Сравнение решений для разных компонентов парсинга выглядит следующим образом:
Параметры | Структура компиляции | производительность | Универсальность | Поддержка диалектов | рабочая нагрузка |
|---|---|---|---|---|---|
Calcite | JavaCC | отличный | отличный+ | Средний+ | Высокий+ |
JSqlParser | JavaCC | отличный | середина- | отличный- | высокий |
Marble | JavaCC | отличный | Средний+ | Плохо+ | высокий- |
Hqlsql | ANTLR | середина | середина | Средний+ | Средний+ |
SparkSQL | ANTLR | середина | середина- | Плохо+ | высокий- |
PrestoSQL | ANTLR | середина | середина- | Плохо+ | высокий- |
Druid | Без рамки | отличный+ | Средний+ | отличный | середина |
Alibaba DruidЭто платформа облачных вычислений Alibaba.DataWorksПродюсировано командой,Пул соединений с базой данных для мониторинга。Druid SQL — это встроенный уровень SQL.,Хотя у него нет полного SQLотличного функционала.,Но с хорошим SQL большая поддержка диалектов.,Поддерживает преобразование нескольких диалектов в абстрактное синтаксическое дерево AST. поэтому,С Друидом Уровень SQL может более удобно реализовать структуру разрешения кровного родства.
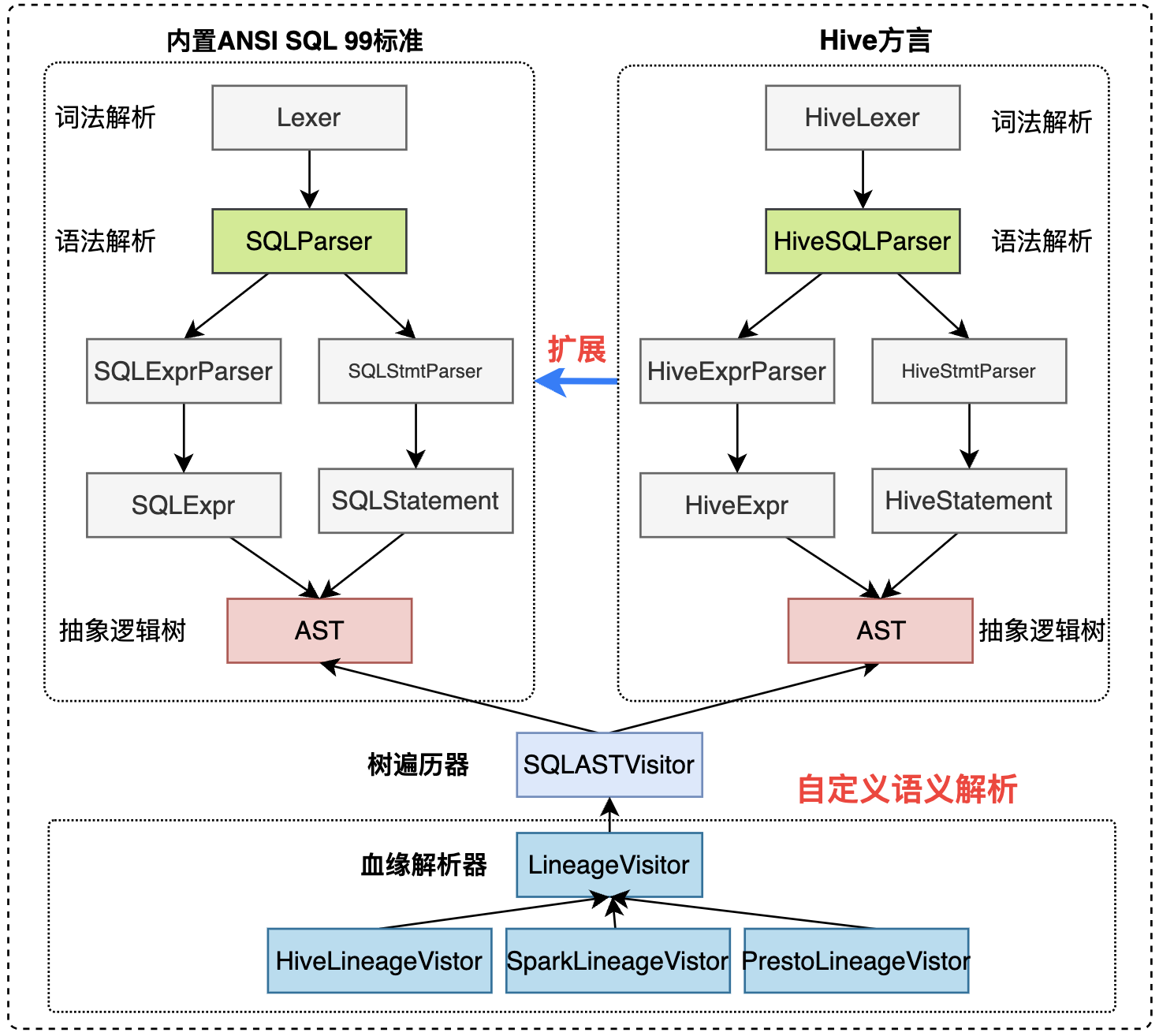
Druid SQL Можно разделить на три модуля: Парсер, AST, Посетитель.
- Parser:ВоляSQLПреобразовать вASTабстрактныйсинтаксическое дерево,Парсер состоит из двух частей,Парсер и Лексер,ЧтосерединаLexer реализует лексический анализ,Парсер реализует синтаксический анализ。
- AST:абстрактныйсинтаксическое дерево,Представлять смысл операторов SQL на основе древовидной структуры.
- Visitor:ТраверсASTозначает,Самый удобный режим обработки AST,Посетитель может быть настроен,Например, LineageVisitor для анализа кровного родства.,После прохождения AST получаются отношения поля и Родства.
Кальцит также может поддерживать анализ происхождения данных.,Поскольку Calcite в основном ориентирован на единый диалект SQL,Слаб против родного поли. Поддержка диалектов.,Так что будет много рабочей нагрузки, расширяющей собственный диалект SQL.,К этой реализации можно отнести Linkedin Coral иметь дело с. Кальцит JavaCC SQL-анализ зависимости В файлах конфигурации FMPP и файлах шаблонов FreeMarker официальные лица рекомендуют настраивать расширения шаблонов и стараться избегать изменения файла Parser.jj.
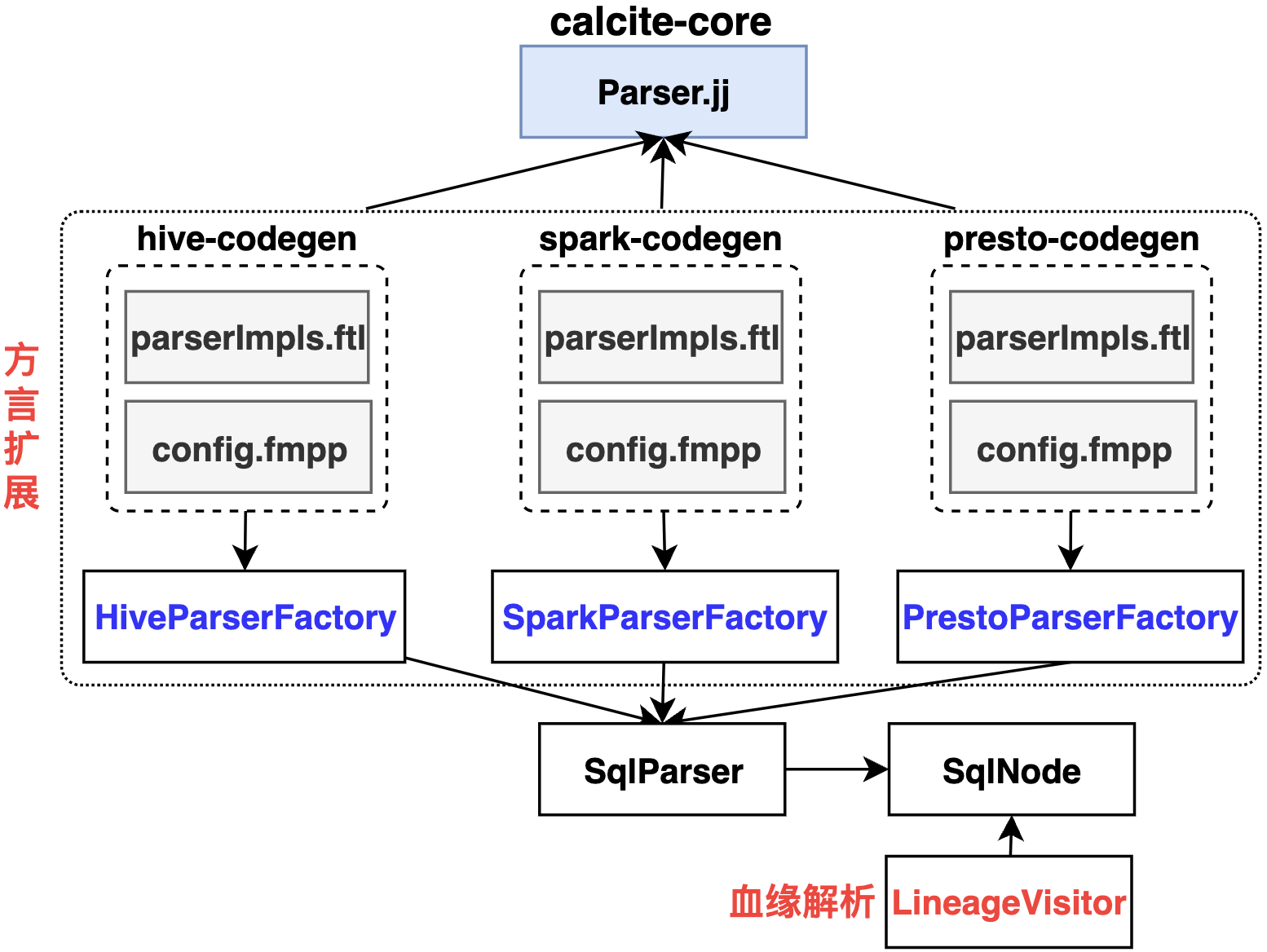
Примечание:Если бизнес-сценарий имеет только одинSQLАнализ родословной диалектов,Больше рекомендуетсяна основеCalciteиметь дело с. Кальцит Более подробную информацию можно найти в графе«Анатомия кальцита».
идентификация родословной
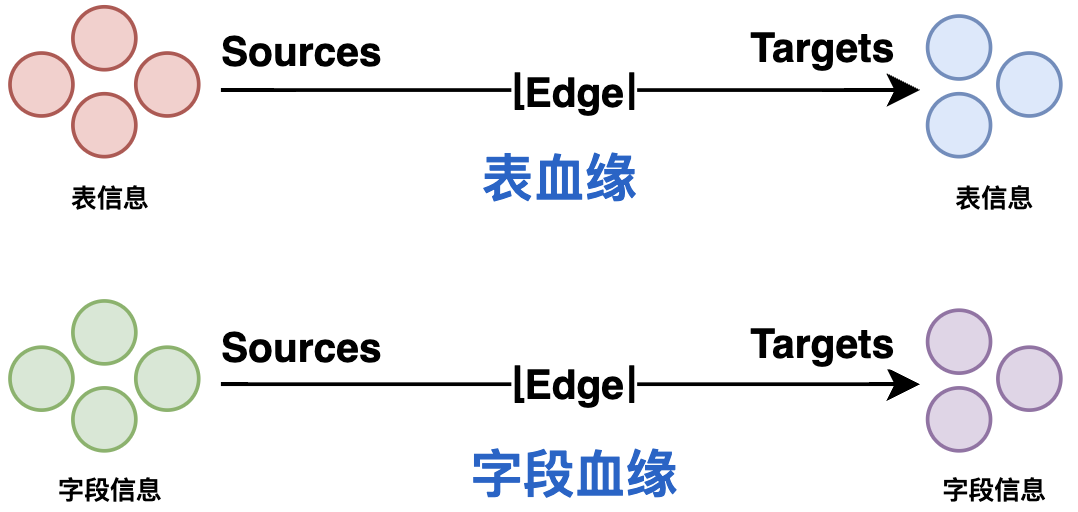
идентификация родословной обходит древовидную структуру AST на основе режима Посетителя для получения Родства, полевой родословная информация. Диаграмма происхождения включает в себя:
- Родство:поверхностьинформация как кульминация,Отношения между таблицами как ребрами,Такие как создать table B as select * from A, тогда источником является таблица A, а целью — таблица B;
- полевая родословная:Полекак вершина,Отношения между полями как ребрами,Связь между полями наследуется от связи таблицы.,Например, источником является поле id таблицы A.,target — поле идентификатора таблицы B;
идентификация родословнойVisitorмодельМожет пересекать кровные родства на основе восходящей рекурсии,Сохраняйте информацию о происхождении на основе узлов таблицы и узлов полей.
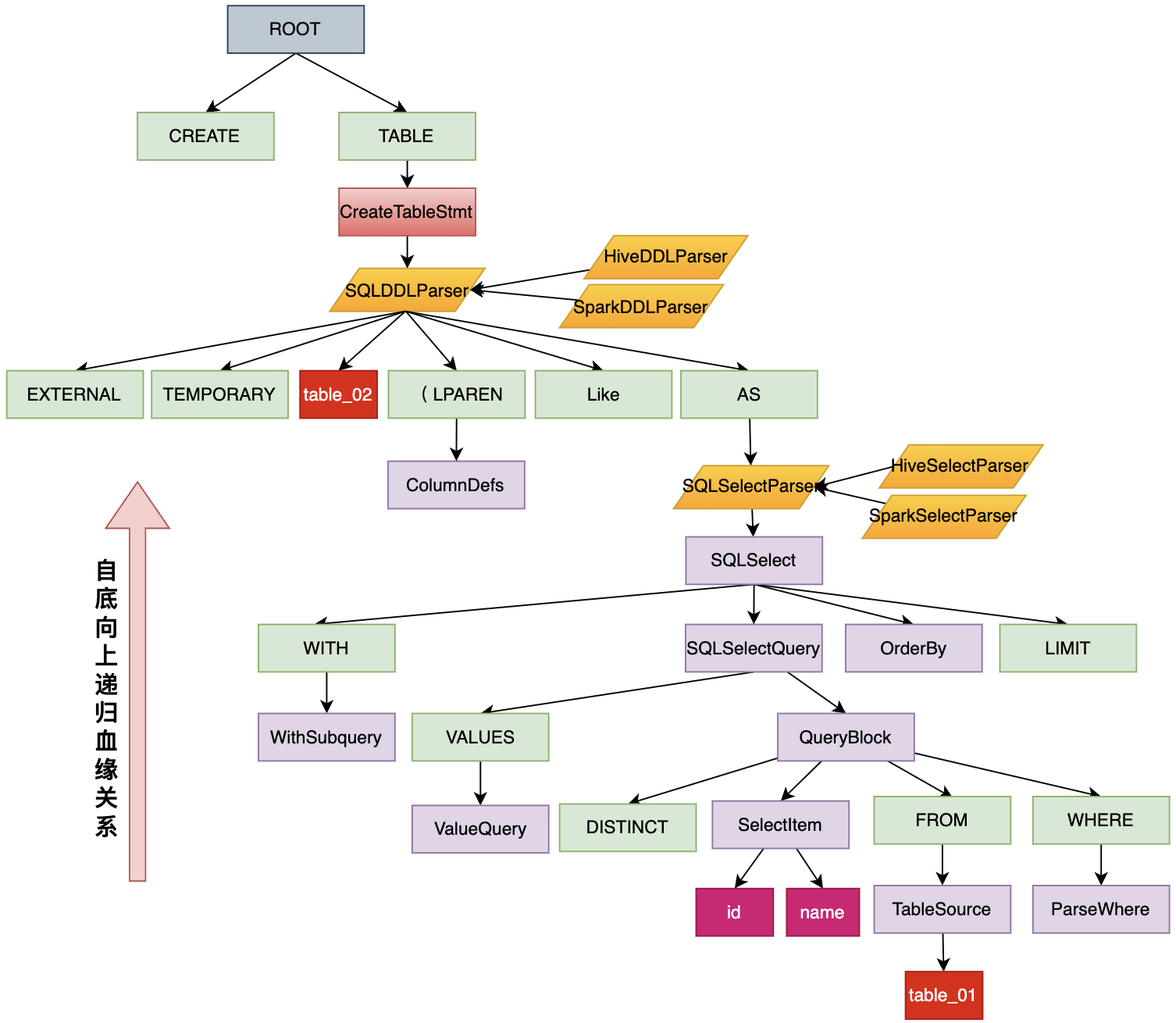
Пример(CREATE AS SELECT заявление): создать table table_02 as select id,name from table_01,получатьГрамматически разобранный ASTнравиться Вниз:
- ROOT: информация о корневом узле AST.,Отправная точка SQL-анализа;
- Ключевые слова SQL (зеленый прямоугольник): например, CREATE, TABLE, EXTERNAL и т. д.;
- Выражение SQL (фиолетовый прямоугольник). Каждое выражение SQL содержит информацию о родительском узле;
- Инструмент SQL-анализа (желтый прямоугольник): анализирует указанный тип оператора SQL.,В зависимости от парсера SQLParser,Могут быть созданы различные поддеревья AST;
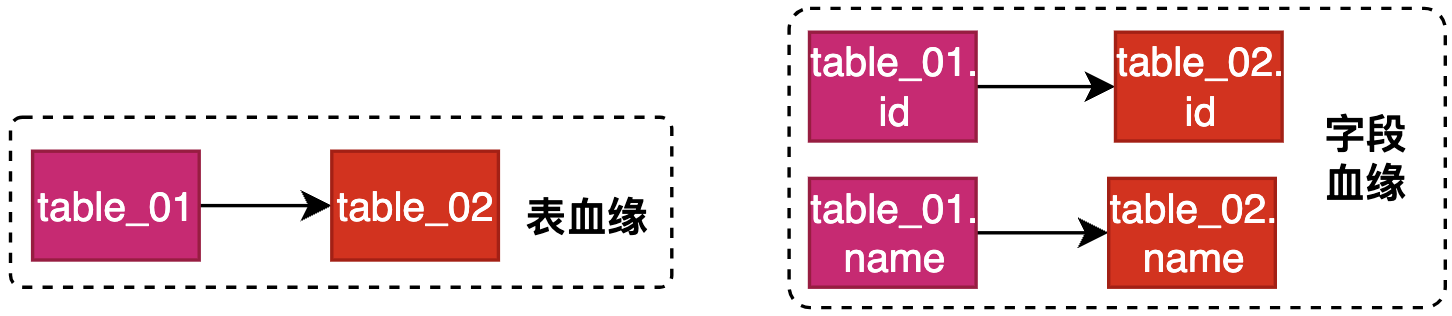
Обходя синтаксическое дерево AST, мы можем получить следующее
- Родство:table_01 → table_02
- полевая родословная:table_01.id → table_02.id;table_01.name → table_02.name;
Хранение родословной
Данные о происхождении в основном поддерживают отношения между вершинами и ребрами.,Соответствующие данные поддерживают сохранение в реляционной базе данных середина.。нонравитьсяфруктовые отношенияслойуровень превышает3слой,Узкое место в производительности возникает при запросе,Дополнительное хранилище графовой базы данных。
База данных графов — это база данных, использующая структуру база данных графа для семантических запросов,Он использует узлы, ребра и атрибуты для представления и хранения данных. Ключевым понятием этой системы является граф,Он напрямую хранит элементы данных середина.,Связан с узлом данных и набором ребер, представляющих отношения между узлами.
в соответствии сТип языка базы данных графаДелимыйнравиться Вниз类型:
- Gremlin: Janus Graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+) 、Amazon Neptune
- Cypher: Neo4j、RedisGraph、AgensGraph
- nGQL: Nebula Graph
Архитектура приложения
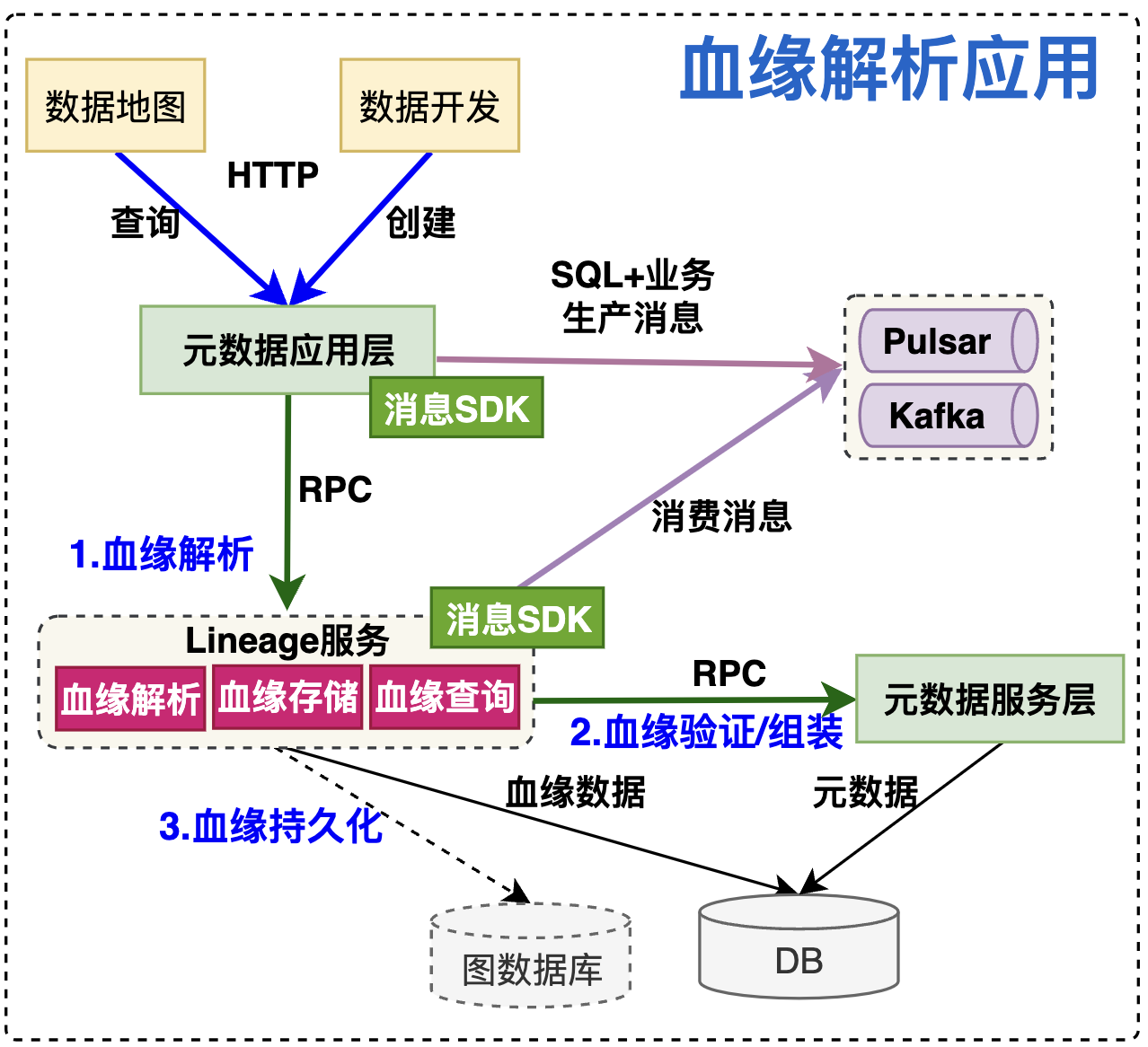
В связи с ограниченной своевременностью данных,,И объем данных обычно большой,Обычно для обработки разделения выбирается промежуточное программное обеспечение середина сообщений.。Процесс подачи заявления на анализ родословнойнравиться Вниз:
- производственные данные:начальствослой Карта данных、Разработка данных и другие функции находятся вSQLи процесс задачисередина,Активно переходить на прикладной уровень метаданных,Уровень приложения метаданных создает соответствующие данные для промежуточного программного обеспечения середина сообщений на основе фиксированного формата сообщения;
- данные о потреблении:Срок службы родословной из сообщениясерединапромежуточное программное обеспечениеданные о потребление для обработки, кроме того, он также поддерживает прямой RPC-интерфейс прикладного уровня для вызова службы крови для анализа;
- Анализ данных:служба кровина основе Инструменты для анализа происхождения,Проверка достоверности кровного родства и организация на основе уровня службы метаданных,В конечном итоге информация о происхождении будет сохранена.。
Службу кровного родства можно разделить на три модуля: анализ кровного родства, «Хранение родословной» и расследование кровного родства.
Подвести итог
Происхождение данных — одно из важных применений управления данными.,Зависимости между таблицами можно четко определить с помощью информации о происхождении.,Отслеживайте происхождение и поток данных. Происхождение данных играет важную роль в управлении качеством данных, соблюдении требований и безопасности данных. В сложных средах данныхсередина,Поддержание точной информации о происхождении данных является сложной проблемой. В этой статье сначала рассказывается об истории происхождения данных, а во-вторых, об отраслевых решениях;,против Родословная Подробно объяснен принцип реализации SQL, который в основном включает в себя три процесса: SQL-анализ、идентификация родословной、Хранение Родословной Наконец, общий обзор данных линии Архитектура; приложения。



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
