Ультра-жесткий базовый анализ модели согласованности Apache Hudi (часть 1)
Тот факт, что Hudi более сложен, не означает, что Iceberg лучше, просто требуется больше работы для усвоения дизайна. Основная причина сложности заключается в том, что Hudi добавляет больше функциональности к базовой спецификации. Iceberg в настоящее время представляет собой просто формат таблиц, а Hudi — полноценный формат размещенных таблиц с несколькими типами запросов. Если вы хорошо разбираетесь во внутреннем устройстве Delta Lake, вы заметите, что дизайн Hudi во многом похож на дизайн Delta Lake.
Объем анализа
В этом анализе не обсуждается производительность и не обсуждается, как Hudi поддерживает различные варианты использования, такие как пакетная и потоковая обработка. Он фокусируется только на модели согласованности Худи, уделяя особое внимание сценариям с несколькими авторами. В настоящее время он также ограничен таблицами копирования при записи (COW). Я начал с COW, потому что он проще, чем Merge-On-Read, и, следовательно, лучше подходит для начала анализа.
- • Нет 1 часть - Логика построения таблиц копирования при записи Модель.
- • Нет. 2 часть - Монотонность временных меток. [1]
- • Нет. 3 часть - верно TLA+ Спецификации для проверки моделирования. [2]
Я мог бы расширить анализ, включив в него объединение таблиц при чтении, а также синхронные и асинхронные службы таблиц (очистка, сжатие и т. д.).
Основное обсуждение
Мы изучим основы графика времении Файловая группа и то, как их можно совместно использовать на стороне записи для выполнения операций чтения и записи. Цель данной статьи – формирование логического мышления. Модель алгоритмов выполнения чтения и письма.
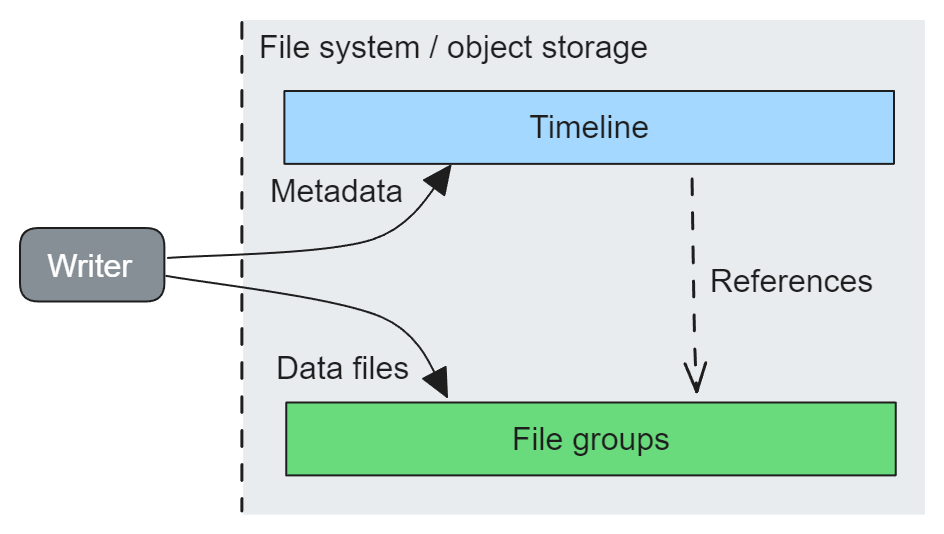
картина 1. Средство записи записывает метаданные о файле данных в график. время (заранее написанный журнал)
график времени — это журнал упреждающей записи, содержащий метаданные о выполненных операциях и расположении файлов данных, составляющих таблицу. Если на файл данных не ссылается временная шкала, файл нечитабельен. Худи Основная идея того, как это работает:
- • Сторона записи записывает в файл данных (обычно Паркет) и прописав местоположение файла в график. время предоставить эти документы.
- • Читать график бокового сканирования времени, чтобы найти последний снимок существующих файлов данных, а затем прочитать эти файлы для удовлетворения запроса.
гарантия транзакции ACID
Худи утверждает, что поддерживает транзакции ACID, и этот анализ проверит это утверждение.
Посмотреть график времении Файловая Основы группы Как работать, очевидно, что атомарность легко достигается, как и у Apache. То же самое и с Айсбергом. существовать Hudi Операции средней записи могут только добавлять новые файлы, но никогда не обновляют и не удаляют файлы. Несмотря на то, что писал в два места, Hudi Операции записи являются атомарными, потому что верографик Окончательное написание времени делает Файловую Любые новые файлы в группе видны. Мы получаем эту атомарность, потому что ни один из существующих файлов не изменяется, а окончательная фиксация одного файла делает все новые файлы видимыми одновременно. Если пишущая сторона выйдет из строя наполовину, это не верный график. время выполняет окончательную запись, и незафиксированные файлы останутся невидимыми для последующей очистки службой таблиц. Это связано с Apache Iceberg подход аналогичен в том смысле, что если Iceberg На стороне записи происходит сбой до обновления корня дерева через каталог, тогда изменения становятся нечитаемыми.
Если предположить, что все используют эти форматы таблиц в облачных хранилищах объектов, постоянство также выглядит довольно безопасным. или другую аналогичную резервную систему хранения высокой доступности.
Таким образом, согласованность и изоляция — это оставшиеся свойства ACID, которые вы хотите понять и проверить. В сценарии с одной стороной записи, который является основным шаблоном использования Hudi, эти два варианта также могут быть тривиальными. Но оставшаяся часть этого анализа посвящена желанию понять согласованность и изоляцию в сценарии с одновременной записью нескольких записей.
первичный ключ
существовать Apache Hudi Каждая запись в имеет первичный ключ,каждый ключсопоставлено с Один раздел и Файловая группа (подробнее об этом позже). Худи Гарантированное существование в большинстве случаев первичный Ключевая строка уникальна, но, как мы увидим позже, есть несколько крайних случаев, которые могут привести к дублированию. Но в целом помните Hudi первичный Дизайн ключа полезен, это можно сделать самостоятельно Apache Iceberg и Delta Lake дифференцировать. существующие будут включены в этот анализ ключ просто называется ключом.
график времени
Все операции, включая операции по обслуживанию таблиц, проходят через график времени. график времени Вместо простого добавления журналов Оглавление файла имеет правила сортировки на основе имен файлов.
Каждая операция кодируется как набор «мгновенных» объектов с именем файла в формате: [метка времени операции в миллисекундах]. [тип операции]. [Рабочее состояние]. Это имя файла формирует мгновенный идентификатор. Обратите внимание, что в документации обсуждается использование временных меток с миллисекундным разрешением, но также можно использовать логические временные метки.
Существует много видов операций,Некоторые из них связаны с операциями по обслуживанию столов. существуют В этой статье,мы будем только смотреть Commit Тип операции, который используется для COW Таблица выполняет операции вставки, обновления и удаления.
Существует три рабочих состояния:
- • Requested
- • Inflight
- • Completed
Успешная операция фиксации запишет каждый статус операции в отдельный мгновенный файл на графике в порядке, описанном выше. время. «Завершенный» момент операции фиксации содержит местоположение файла, созданного при фиксации. Сторона чтения и сторона записи могут сканировать график. времени, чтобы найти завершенные моменты фиксации, чтобы узнать, какие файлы были зафиксированы и где они находятся. график время — это просто набор файлов в файловой системе или хранилище изображений, поэтому график Порядок времени зависит от имени файла с использованием следующих приоритетов:
- • Временная метка операции.
- • Рабочее состояние.
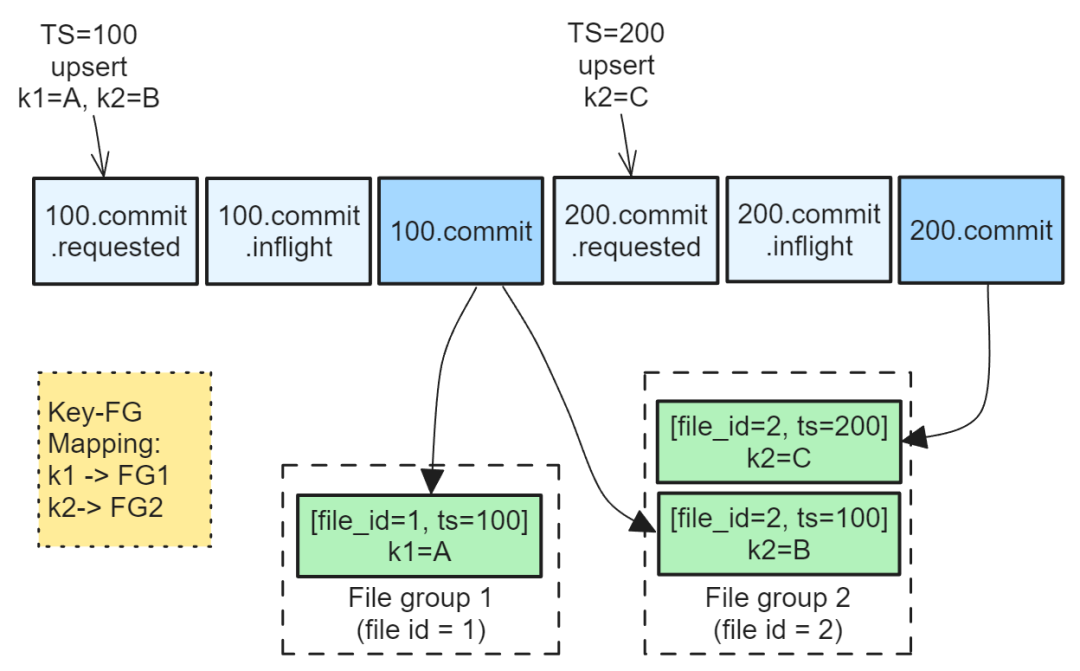
Временная метка 100 и 101 Две успешные операции записи создадут график в следующем порядке время (независимо от порядка вставки):
- 1. 100.commit.requested
- 2. 100.commit.inflight
- 3. 100.commit
- 4. 101.commit.requested
- 5. 101.commit.inflight
- 6. 101.commit
Обратите внимание, что статус «завершенной» операции не указывается в имени мгновенного файла. Худи В спецификации указано,Временные метки операций должны монотонно увеличиваться. Что это означает существование в реальном мире?,Сначала я этого не знал. Его можно интерпретировать как:
- • Вариант 1) Выдача временной метки. Когда средство записи получает временную метку, оно получает (глобальную) монотонно увеличивающуюся временную метку.
- • Параметры 2) график временивставлять。график Порядок вставки времени основан на монотонно возрастающих временных метках. Другими словами, порядок вставки соответствует временным меткам, полученным на стороне записи. Например, тс=1 Момент не будет существовать ts=2 добавляется на временную шкалу после.
Мы также предположим, что это означает, что две пишущие стороны никогда не будут использовать одну и ту же метку времени. - Конфликт временных меток. Возникает вопрос: если попытаться написать больше, чем 1000 раз (и мы используем доступные миллисекунды за одну секунду), что происходит. Это не текущая загрузка Работа, подходящая ни для одного из этих форматов таблиц. Если да, то логическая временная метка будет хорошим выбором. Временная метка – это, по сути, int64, сам алгоритм не заботится о значении числа. Логические временные метки проблематичны только тогда, когда требуется чтение на основе времени настенных часов. Параметры 1 Этого можно добиться разными способами, например, с помощью OLTP База данных, DynamoDB даже Apache ZooKeeper прилавок. Но даже если временные метки получения монотонны, два одновременно записывающих конца не обязательно будут писать график в одном и том же порядке. время. Пример
- • W1 получает ts=100 от ZK
- • W2 получает ts=101 от ZK
- • W2 Оставьте 101.commit.requested
- • W1 Оставьте 100.commit.requested
- • W2 Выход из 101.commit.inflight
- • W2 Выход из 101.commit
- • W1 Выход из 100.commit.inflight
- • W1 ставит 100.commit
Помните, график время — это просто Оглавление (как префикс) в файловой системе или хранилище изображений и не может само по себе навязывать порядок. сортировать читает существующий график клиента время файла выполняется сортировкой.
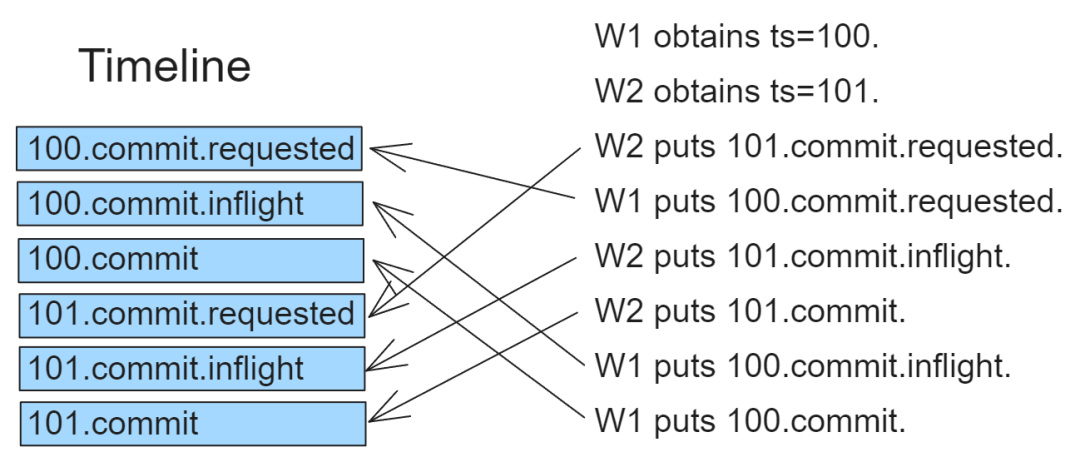
картина 2. Сортировка на временной шкале осуществляется по временной метке, а не по порядку вставки.
Внедрить строгий порядок размещения (опция 2) Единственный путь – через пессимистический блокировка, эта блокировка обертывает весь набор операций, включая получение метки времени. Худи Не делая этого, мы должны поэтому заключить, что монотонные временные метки применяются ко времени выпуска, а не времени записи. Позже мы рассмотрим значение монотонных и немонотонных временных меток, а также блокировку параметров. Хотя в этом анализе обсуждается тема немонотонных временных меток и конфликтов временных меток, важно помнить, что немонотонные временные метки нарушают Hudi v5 спецификация. В настоящее время нам нужно охватить более базовую механику. Далее, как записать файл данных.
Файловая группа
Файлы данных организованы в разделы и Файловая. группа, любой данный первичный ключ Всесопоставлено содин Файловая группа。существоватьв этой статье,Я в основном игнорирую разделы,чтобы все было как можно проще,Потому что модельный ряд постоянен.
существовать COW В таблицу вставьте, обновите и удалите данную Файловую Ключ для группы приведет к записи новой версии. Parquet документ. Пишущая сторона должна прочитать текущий Parquet файл, объедините новые/обновленные/удаленные строки и запишите их обратно как новый файл. Эти версии файлов называются фрагментами файлов, где временная метка выступает в качестве номера версии. Чтобы найти правильный фрагмент файла для объединения, сторона записи сканирует временную шкалу на предмет метки времени последнего завершенного момента. Эта временная метка является временной меткой фиксации слияния и используется для поиска фрагмента целевого файла слияния, который будет объединен для формирования нового фрагмента файла. Целью слияния является та, у которой самая высокая временная метка. <= Объедините фрагменты зафиксированных файлов с метками времени фиксации. Представленный фрагмент файла является существующим графиком. время указано в завершенном моменте фрагментов файлы. После завершения слияния в памяти средство записи записывает новые фрагменты файлов в хранилище.
Файловая группа по своим файлам ID Идентификация, части файлов идентифицируются следующими способами:
- • Что Файловая группа (документ ID)
- • Токен записи (счетчик, который увеличивается при каждой попытке записи в файл).
- • Временная метка операции, которая его создала.
Формат имени файла фрагмента файла::[file_id][write_token][timestamp].[file_extension] Теперь существование будет игнорировать записи и повторы файлов, которые часто цитируются в формате [file_id=N, ts=M] фрагменты файлов.
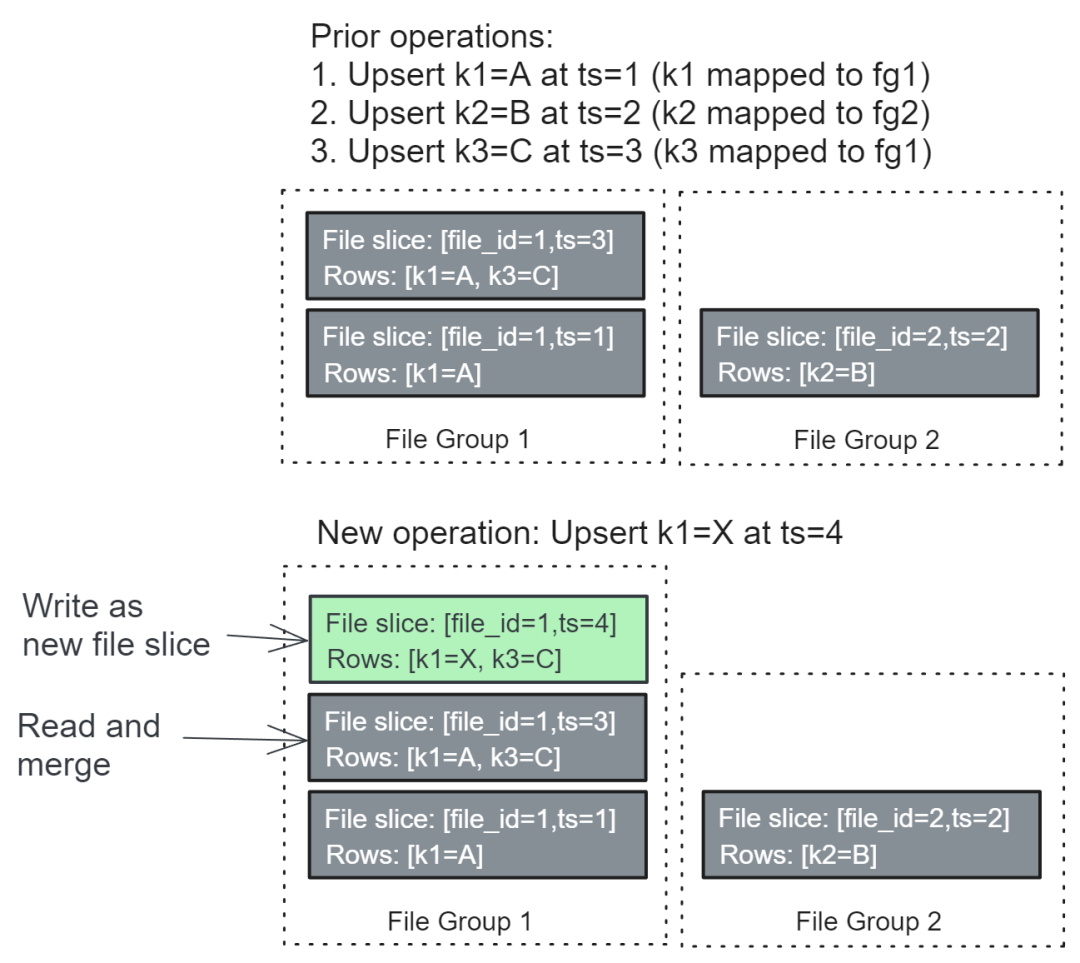
картина 3. Операция: нажмите клавишу k1 обновить до значения Х. ключ k1 сопоставлено с ФГ1. Средство записи загружает текущий фрагмент файла [file_id=1, ts=3], объединить k1 новое значение и записывает новый фрагмент файла [file_id=1, ts=4]
Удаление аналогично таблицам COW.
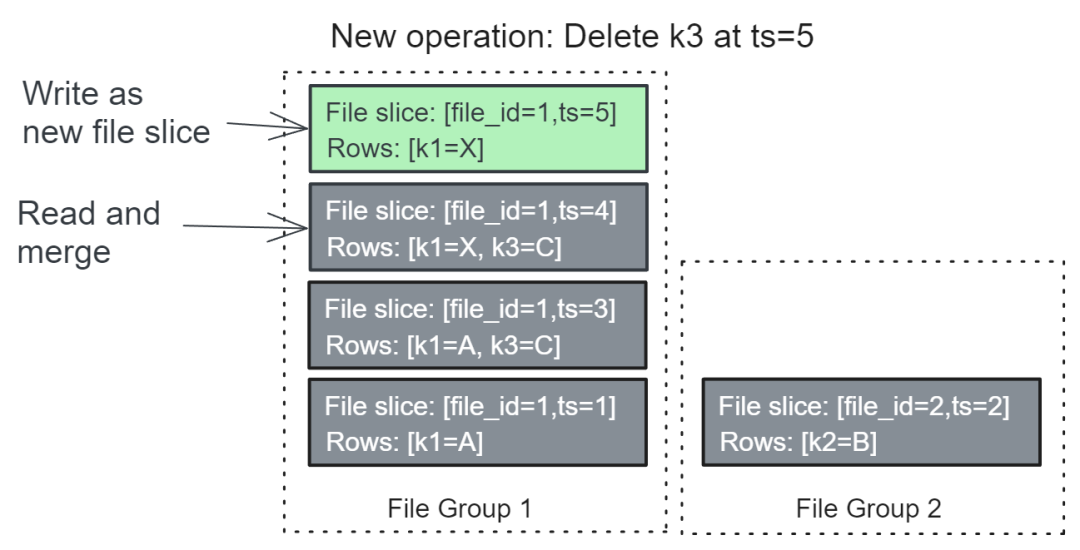
картина 4. Удалить операцию для объединения частей файла. [file_id=1, ts=4] и напишите новый фрагмент файла [file_id=1, ts=5]
Hudi Операция отправки от не распространяется на Файловую Файлы данных в группе, там можно только добавлять новые файлы. Удаление файлов — это работа табличных сервисов (таких как очистка, сжатие и кластеризация).
график времении Файловая группасуществовать Вместе
Читатель и писатель используют график времени, чтобы понять, какие фрагменты файла актуальны в данную временную метку.
картина 5. Момент завершения временной шкалы указывает на неизменяемый файл данных.
Срез файла без соответствующей завершенной мгновенной записи не читается и не может использоваться в качестве цели слияния для операции COW.

Операция существования изображения 6.ts=150 завершилась неудачно непосредственно перед завершением записи.,поэтому Что文件切片仍然不可读
Чтения могут путешествовать во времени, поскольку данный ключ можно прочитать из фрагмента файла, соответствующего временной метке чтения.

картина 7. Каждая операция чтения выполняется по заданной временной метке, что позволяет читателю переместиться во времени в более раннее состояние.
Простая логическая модель путей записи
«Все модели неверны, некоторые полезны».
Мы постараемся построить Hudi Упрощенная модель дизайна для понимания Hudi Последовательность и изоляция. Логика записи разбита на несколько этапов. Эти шаги различаются в зависимости от выбранного Управления. Механизм параллелизма варьируется. Управление не всегда необходимо параллелизм, например, использование единой установки на стороне записи, которая встраивает задание обслуживания таблиц в записывающее устройство. Но в сценарии существования нескольких писателей требуется Управление. параллелизмом。Должен Модель Следующимчастькомпозиция:
- • Поставщик временных меток
- • Поставщик блокировки
- • Одно и несколько окончаний записи,每个конец письма Все有一些逻辑:
- • Операция записи разделена на несколько этапов.
- • Управление параллелизмом(никто、оптимизм、пессимистичный)
- • 存储
- • Каталог временной шкалы
- • Файловая группа
- • Индикаторы
- • Поддерживает ли хранилище Поставить Если Отсутствует. Когда хранилище поддерживает PutIfAbsent При записи конец записи сохранит любое существующее имя файла графика, которое было сохранено. времениили Файловая группа запись прервана. В противном случае он автоматически перезапишет существующие файлы с тем же именем/путем.
- • Операция на основе KV да, с функциями обновления, вставки и удаления. Каждый ключ верно должен иметь один первичный ключ, значение верно должно быть связано с не- PK значение столбца.
Запишите путь с использованием оптимистического управления параллелизмом (OCC)
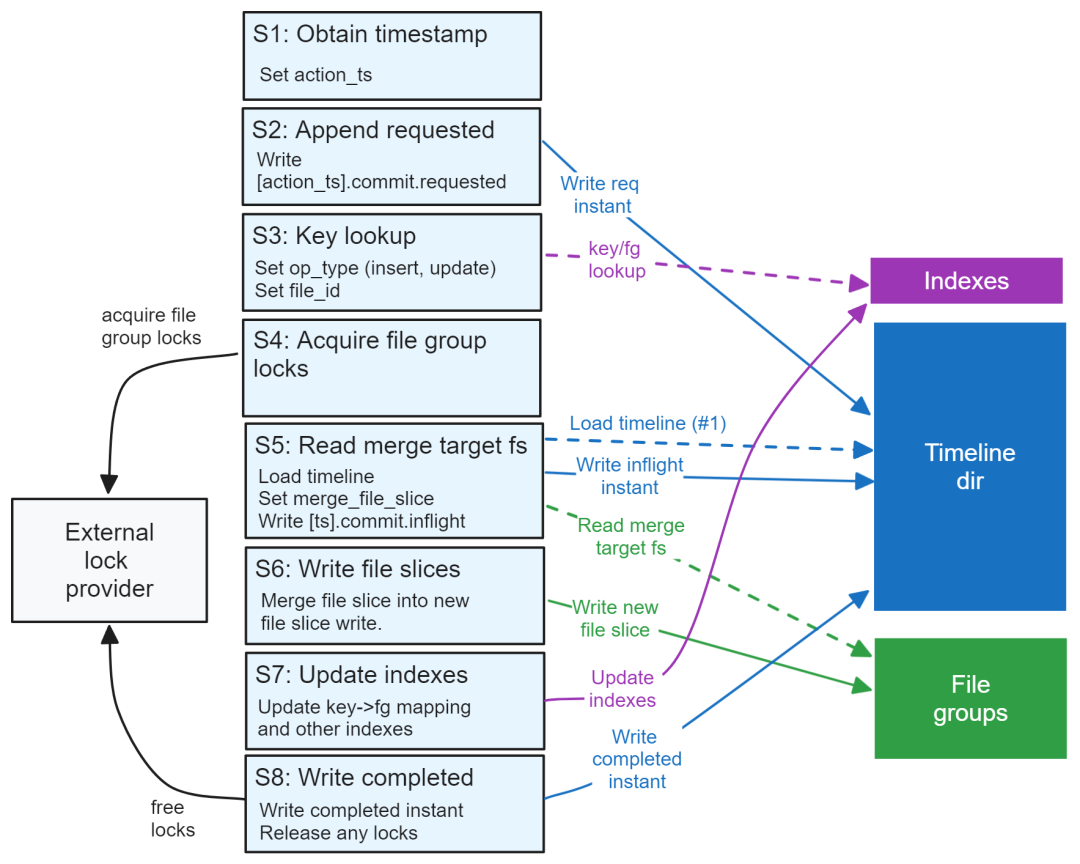
я использовал OCC Смоделируйте логический путь записи как 9 шаги. Это может показаться много, но стоит помнить, что Худи изпервичный Дизайн ключа добавляет дополнительную работу. первичный Ключевая поддержка – одна из целей проекта.

картина 8.упрощать Модельизнаписать путь, с оптимизмом Управление параллелизмом
шаг:
- 1. Получить временную метку. Напишите решение стороны вернопервичный ключ Выполните операцию и получите метку времени.
- 2. Немедленно добавьте запрос. Пишущая сторона сразу записывает запрошенную информацию в график. времени。
- 3. ключевой поиск。конец письмаверноключ для выполнения поиска:
- • Проверьте, существует ли ключ (используется для пометки вставки обновления как вставки или обновления).
- • Получить Файловую группа, если файл вставлен, присваивается Файловая группа。Воля Файловая Когда группе назначается новая клавиша, записывающая сторона выберет одну из фиксированного пула. Это не определено (существовать в реальном мире существует множество Файловая стратегия группового картирования и реализация).
- 4. Чтение фрагментов целевого файла объединения。Воляслить目标文件切片读取到内存середина(Если сохранитьсуществовать)
- • Загрузить график времени в память (при первой загрузке).
- • Сканируйте график, чтобы узнать временные метки фиксации слияния. время. Это Самый последний завершенный момент Временной метка операции.
- • Сканировать график время, поиск и целевые файлы ID контакт и Временная метка <= Время завершения фиксации слияния. Если набор не пуст, средство записи выберет момент с самой высокой временной меткой из набора в качестве фрагмента целевого файла слияния. Если набор пуст, перейдите к следующему шагу.
- • Проверьте, не является ли временная метка объединенного фрагмента целевого файла ниже, чем временная метка автора. метка операции.可以找到要слитьиз文件切片,Временная метка этого фрагмента файла выше, чем собственная временная метка операции записи (из-за одновременной записи),если так,Окончание записи должно быть прервано.
- • Считайте объединенные фрагменты целевого файла в память.
- 5. Записать фрагмент файла. Объединить операцию с загруженным фрагментом файла (если он существует) и записать как Файловая Новые фрагменты файлов для группы. Если это новая Файловая группа,тогда нечего объединять,Только новые данные.
- 6. Получите блокировку стола.
- 7. 更新索引。
- • Если это вставлено, карта файла, назначенная для этого ключа, должна быть отправлена в индекс карты файла.
- 8. оптимизм Управление параллелизмомисследовать
- 1. график нагрузки время (Нет. Вторичная загрузка)
- 2. Сканируйте временную шкалу, чтобы найти цель группа接触из任何已完成时刻,Чтодействовать Временная метка>Объединение временных меток фрагмента целевого файла(вместо метки времени слияния фиксации)。
- 3. Если есть такой момент как существование, то это означает, что другая пишущая сторона представила конфликтные фрагменты. файлов.поэтому,Проверка не удалась,Писатель прерван. Если нет такого мгновения,Проверка проходит.
- 9. Запись завершается немедленно. Запишите завершенный момент в график времени,并包含写入из新文件切片из位置。
- • Снимите блокировку часов
пожалуйста, обрати внимание,Вышеупомянутое предполагает, что существует только один фрагмент целевого файла слияния.,из-за этого Модель В настоящее время содержит только одинпервичный ключдействовать。если Управление параллелизм не понятен, буду существовать ниже Управление Часть параллелизма описывает это более подробно.
Записать путь, используя пессимистическую блокировку
Разница между этим методом существования заключается в,существуют Чтение и объединение любых фрагментов файлов.,а затем перед записью нового фрагмента файла,конец письма会获取每个Файловая блокировка группы. Тогда нет необходимости проверять это позже, например OCC Ситуация та же. Эти блокировки удерживаются до момента завершения записи или прерывания операции.
картина 9.OCC Заменена проверка и блокировка таблицы на Файловую. группа Замок
пессимистическая блокировка обычно не используется, так как Файловая может быть сотни, тысячи или даже миллионы. группа。大型действовать需要получать大量Замок,это не идеально。поэтомуоптимизм Управление параллелизм является предпочтительным методом.
Краткий обзор формул следующего состояния TLA+
Следующая формула состояния спецификации TLA+ отражает описанный путь записи.

картина 10.TLA+ Каноническая формула следующего состояния
Сообщите проверщику модели выше,существовать на каждом шагу,Он должен недетерминированно выбирать один из концов записи.,И существование выполняет возможную операцию недетерминированно в этот момент. Например, если пишущая сторона только что сразу написала Requested, то можно проверить возможной следующей операцией будет KeyLookup или WriterFail.
Управление параллелизмом
Управление параллелизмом (CC) Это гарантирует, что несколько операций не накладываются друг на друга, вызывая проблемы согласованности. Контакт непересекающийся Файловая Две операции группового набора не мешают друг другу, поэтому их CC Проверка пройдет. Только если две операции имеют общую Файловую Конфликты могут возникать только тогда, когда группа.
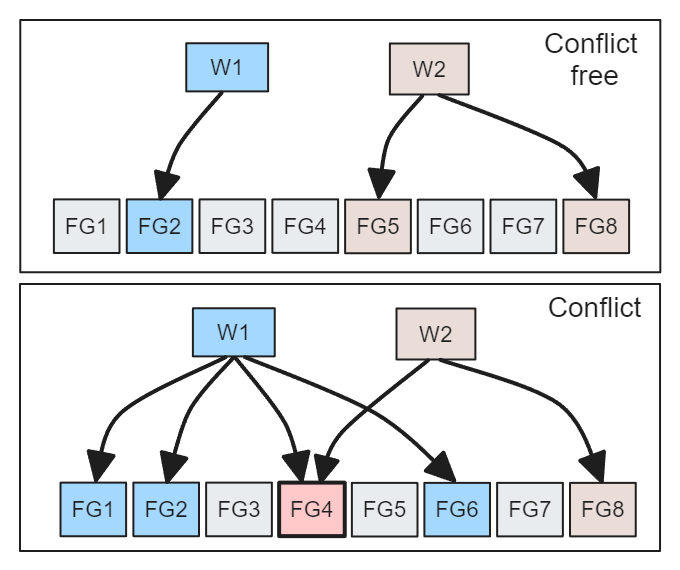
картина 11. Непересекающаяся Файловая группа представлена без конфликтов
Это Hudi Очень хорошее свойство, думаю, оно существует каждый раз, когда я пишу Файловую. небольшая часть группы помогает в сценариях с участием нескольких авторов. Но там, где существование выполняет большие пакеты на каждой стороне записи, я думаю, что это преимущество снижается, поскольку каждая операция может включать в себя большое количество Файловая группа。v5 В спецификации упоминаются два типа Управления. параллелизмом:
- • оптимизм Управление параллелизмом
- • пессимистическая блокировка
оптимизм Управление параллелизмом (OCC)
Проверка оптимистического параллелизма работает следующим образом:
- 1. Два писателя (W1 и W2) Некоторые изменения необходимо объединить в Файловую группа 1 Средний (w1 существовать ts=100 Когда, w2 существовать ts=101 час). Каждый файл идентифицирует Файловую, которую нужно объединить. Существующая часть файла (цель объединения) группы. существуют. В этом примере оба разрезают файл [file_id=1, ts=50] Идентифицирован как цель слияния.
- 2. W1 оптимистично записывает фрагмент файла [file_id=1, ts=100]
- 3. W2 оптимистично записывает фрагмент файла [file_id=1, ts=101]
- 4. Оба фрагмента файла являются незафиксированными и остаются нечитаемыми, поскольку они существуют и не имеют соответствующего завершенного момента времени. Также обратите внимание, что если оба существуют, читайте график в разное время. время они могут распознавать разные цели слияния, что приводит к их достоверному изображению. Каждый взгляд на время различен.
- 5. W2 сначала получает блокировку таблицы.
- 6. W2 снова график нагрузки времени。оно проходит Сканировать график временинайти Временная метка 50 завершенное время, которое касается file_id=1,>осуществлять CC исследовать. Он ничего не может найти, поэтому его CC Проверка завершается успешно и записывается в момент завершения. фрагмент файла [file_id=1, ts=101] Теперь отправлено и доступно для чтения. П1 Снимите блокировку стола.
- 7. W1 Получите блокировку стола. П1 график нагрузки времени。оно проходит Сканировать график временинайти Временная метка 50 завершенное время, которое касается file_id=1,>осуществлять CC исследовать. он нашел ts=101, следовательно CC Проверка не удалась и была прервана, и удалите блокировку стола.
Например,существуют В сцене ниже,w1 или w2 Теперь существующие могут получить блокировку таблицы и успешно завершить операцию.

изображение 11.w1 или w2 Теперь существующие могут получить блокировку таблицы и успешно завершить операцию.
Но как только писатель завершает свою работу,Нет. Два автора существуют, выполняют проверки OCC, когда.,Воля看到Временная метка> 50 зафиксированных фрагментов файла, поэтому он должен быть прерван.
Это то, что мы видим в существовании Внизкартина. П2 Дело сделано. П1 Что будет дальше OCC исследовать,它Воля Сканировать график время найти с FG1 接触из已完成时刻,Временная метка> 50. он найдет 101, поэтому прервано. П1 Теперь существование должно очистить незафиксированные фрагменты файлов. [file_id=1,ts=100], в противном случае задание службы таблиц выполнит эту операцию позже.
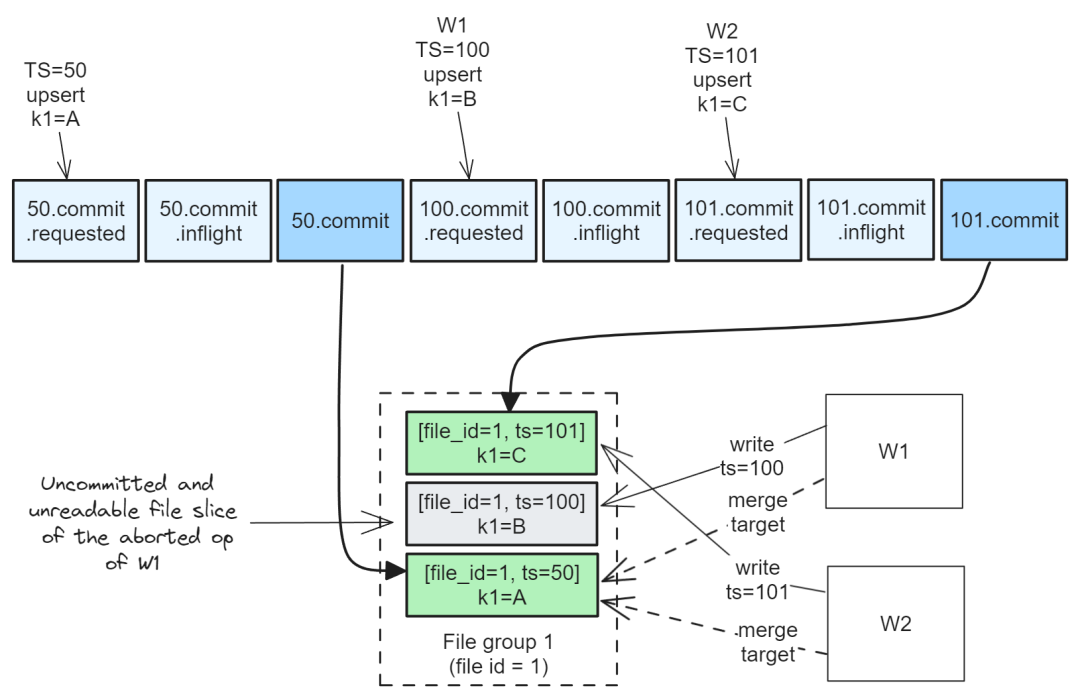
картина 12.ts=100 Операция в существовании не может быть отправлена, поскольку ее OCC Проверка не пройдет
В результате фрагменты файла могут быть зафиксированы только в порядке временных меток. использовать OCC, невозможно зафиксировать временную метку ниже, чем существующие зафиксированные фрагменты фрагмента файла. файлов.
пессимистическая блокировка
Другая стратегия –существовать Начать читать>-слить->Получите каждый из них, прежде чем писать процесс нарезки файлов.Файловая блокировка группы. Это гарантирует, что никакая другая часть процесса записи не сможет внести конфликтующие изменения в срез файла. Но, как я уже упоминал ранее, может потребоваться слишком много блокировок, поэтому OCC Обычно предпочтительнее.
первичный ключконфликт检测
除了Файловая Помимо группового конфликта, вы также можете выбрать управление первичным конфликтом. ключевой конфликт. Когда вставка одновременно на разных сторонах записи приводит к присвоению одной и той же клавиши разным Файловая группа может возникнуть при первичном ключконфликт。существовать TLA+ В спецификации будет существовать файл записи. группа неуверенно выбирает Файловую при назначении на новую клавишу группа. Это может привести к дублированию операций чтения, как описано здесь. существует эта простая Модельсередина,первичный Проверка keyconflict гарантирует, что существование добавляет сопоставление в индекс раньше других Файловая группасередина不存существоватьключ к Файловая Картирование группы.
Простая логическая модель пути чтения
Смоделируйте логический путь чтения как 3 шаги. Чтение заканчивается первым отграфиком временисередина识别相关из文件切片,Затем прочитайте эти фрагменты файла в памяти.,и применить логику запроса к этим строкам. существовать в реальном мире,Сокращение фрагментов файла на основе статистики разделов и файлов (например, статистики мин/макс столбцов в файле метаданных) будет использоваться для сокращения количества фрагментов файла, которые фактически необходимо прочитать.
пожалуйста, обрати внимание,этот Модель Не включенографик время архива и чистки файлов, предполагается график время завершено.
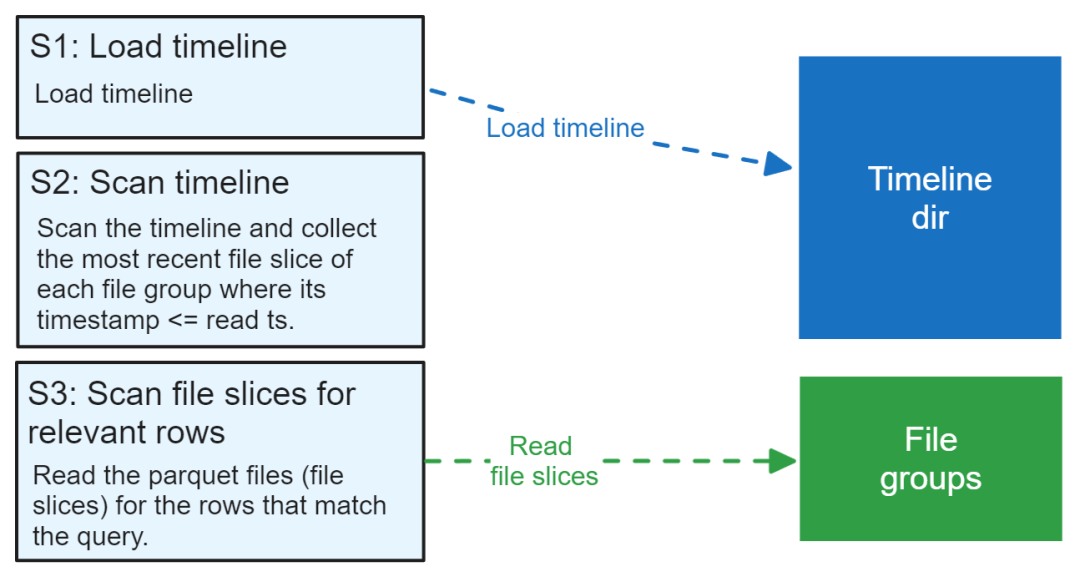
картина 13. Путь чтения этой упрощенной модели
Следующие шаги
Прежде чем просматривать результаты проверки модели, я хотел бы представить конфликты временных меток. v5 В спецификации четко указано, что временные метки должны быть монотонными, и если этого не сделать, это нарушит спецификацию. Но хотелось бы понять влияние столкновений и понять вероятность таких столкновений на практике. Существуют эти знания будут полезны при оценке степени соответствия реализации истинной спецификации. Это Нет. 2 часть темы.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
