Углубленный анализ xLSTM: эволюция архитектуры LSTM и подробное объяснение реализации кода PyTorch.
Возможно, вы видели новости о xLSTM несколько дней назад. Первоначальный автор предложил более сильный xLSTM, который может расширить LSTM до миллиардов параметров. Сегодня мы проведем подробное сравнение с исходным lstm, а затем воспользуемся Pytorch для реализации. простой xLSTM.
xLSTM
xLSTM является расширением традиционного LSTM. Он улучшает LSTM за счет введения новых механизмов вентилирования и структур памяти с целью повышения производительности и масштабируемости LSTM при обработке крупномасштабных данных. Вот несколько ключевых отличий между xLSTM и исходным LSTM:
- Экспоненциальное стробирование:
- xLSTM 引入了Экспоненциальное механизм стробирования, представляющий собой новую технологию стробирования, с индикаторами sigmoid Гейттинг - это другое。Экспоненциальное стробирование может обеспечить более динамичную фильтрацию информации, помогая улучшить память и процесс забывания.
- Модификация структуры памяти:
- sLSTM:Новая гибридная технология памяти добавлена к архитектуре с единой памятью。Он по-прежнему обновляет скаляр,Однако улучшенный гибридный метод повышает эффективность хранения и использования информации.
- mLSTM:Представляем матричную память,Это обеспечивает параллельную обработку и увеличивает емкость хранилища. Он использовал правило обновления ковариации,Подходит для обработки крупномасштабных параллельных данных.,решено LSTM Ограничения при распараллеливании.
- Методы нормализации и стабилизации:
- чтобы предотвратить Экспоненциальное Проблемы с числовой стабильностью, вызванные стробированием, xLSTM. В расчетах стробирования были введены дополнительные этапы нормализации и стабилизации, например, использование метода максимальной записи для поддержания стабильности.
- Интеграция остаточных блоков:
- xLSTM улучшить эти LSTM Единицы объединяются в остаточные блоки, которые в дальнейшем складываются в полную архитектуру сети. Эта конструкция делает xLSTM Способность более эффективно обрабатывать данные сложной последовательности.
- Производительность и масштабируемость:
- xLSTM По производительности сравним с последними моделями Transformer Ее можно сравнить с моделью пространства состояний, особенно демонстрируя преимущества в крупномасштабных приложениях и обработке длинных последовательностей.
В целом, цель разработки xLSTM — устранить ограничения, с которыми сталкивается традиционный LSTM при обработке крупномасштабных данных и длинных последовательностей, таких как плохой параллелизм и ограниченная емкость хранилища, путем внедрения новых механизмов вентилирования и структур памяти, чтобы сделать его более эффективным при работе. современные глубины. Будьте более конкурентоспособными в учебных приложениях.
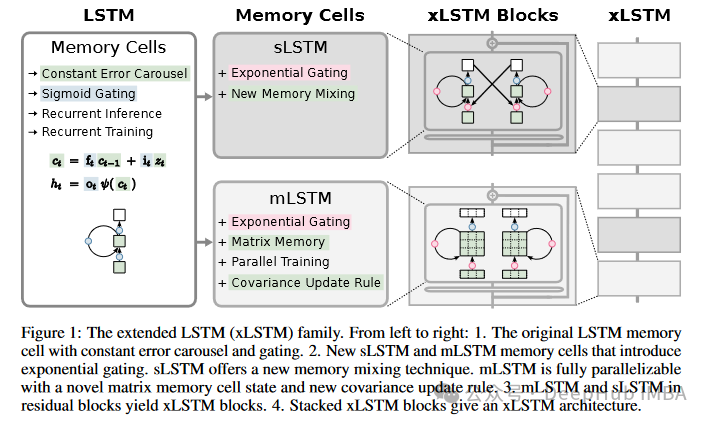
Основы LSTM
Чтобы объяснить xLSTM, мы сначала кратко рассмотрим LSTM. Формула LSTM также приведена в статье, которую мы цитируем напрямую.
Формула расчета традиционной LSTM (сети долговременной краткосрочной памяти) включает в себя несколько ключевых частей: входной вентиль (iti_tit), вентиль забывания (ftf_tft), выходной вентиль (oto_tot) и состояние устройства (ctc_tct). Ниже приведены стандартные шаги расчета для ячейки LSTM:
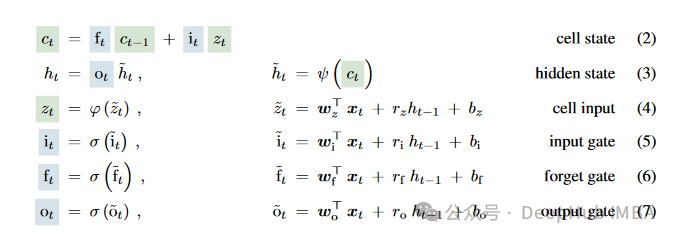
улучшения xLSTM
Причина, по которой xLSTM называется xLSTM, заключается в том, что он расширяет LSTM до нескольких вариантов LSTM, sLSTM и mLSTM. Каждый вариант оптимизирован для определенной производительности и функций для решения различных проблем с данными сложных последовательностей.
sLSTM
sLSTM(Scalar LSTM)существоватьтрадиционный Основы В LSTM добавлен механизм скалярного обновления. Эта конструкция оптимизирует механизм стробирования за счет детального управления внутренней памятью, что делает его более подходящим для обработки данных последовательности с небольшими изменениями во времени. sLSTM обычно использует Экспоненциальное стробированиеиметод нормализации,Повысить стабильность и точность модели при обработке данных длинных последовательностей. таким образом,sLSTM способен поддерживать низкую вычислительную сложность, в то же время,Обеспечить производительность, сравнимую со сложными моделями.,Особенно подходит для сред с ограниченными ресурсами или приложений, требующих быстрого реагирования.
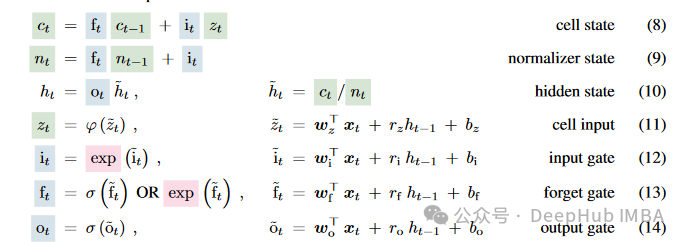
Можно сказать, что вышеизложенное — это всего лишь несколько простых модификаций традиционного LSTM, а основной процесс вычислений остался прежним.
mLSTM
mLSTM (Matrix LSTM) значительно увеличивает объем памяти и возможности параллельной обработки модели за счет расширения векторных операций в традиционном LSTM до матричных операций. Каждое состояние mLSTM больше не является одним вектором, а представляет собой матрицу, которая позволяет ему фиксировать более сложные взаимосвязи и закономерности данных за один временной шаг. mLSTM особенно подходит для обработки крупномасштабных наборов данных или задач, требующих очень сложного распознавания образов данных. Кроме того, конструкция mLSTM поддерживает высокую степень параллельной обработки, что не только повышает эффективность вычислений, но и позволяет модели лучше масштабироваться для крупномасштабных наборов данных.

Можно сказать, что mLSTM — последняя версия, но если внимательно посмотреть на код, есть ли там несколько знакомых слов? К, К, В, разве это не представление механизма внимания, который появляется в преобразователе? Да, это действительно так, но метод расчета другой.
Таким образом, LSTM можно распараллелить. Подробно мы объясним это позже.
остаточный сетевой блок
xLSTMвостаточный сетевой Блок является важной частью его архитектуры, и конструкция этих блоков позволяет xLSTM эффективно обрабатывать данные сложной последовательности, одновременно улучшая стабильность обучения модели в глубоких сетях. остаточный сетевой блок通过引入跳过连接来缓解深层神经网络训练过程в梯度消失问题。Это должно позволитьxLSTMОдна из причин, по которой можно накладывать несколько слоев。Потому что, если вы использовали его раньшеLSTMслова,ты должен знать,LSTM обычно требуется только два слоя.,Потому что никакое количество этого не будет иметь никакого эффекта,И скорость вычислений очень низкая.
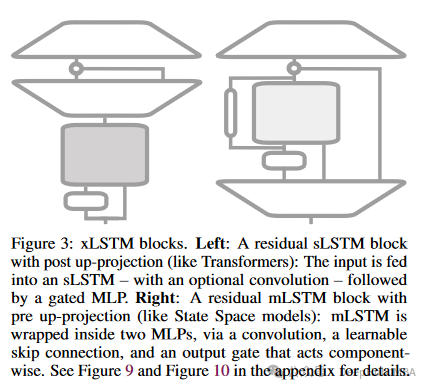
Остаточный сетевой блок xLSTM состоит из следующих частей:
- главный путь:
- главный путь содержит основной вычислительный блок xLSTM,Это может быть модуль sLSTM или mLSTM.,Отвечает за сложную обработку последовательностей и операции с памятью.
- Эти блоки принимают входные данные из предыдущего блока, выполняют необходимые операции стробирования и обновления состояния, а затем выводят данные на последующие этапы обработки.
- Пропустить соединение:
- Пропустить соединение передает вход непосредственно на выход блока, в отличие от главного путь Выводы добавлены.
- Такая конструкция помогает сети сохранять информацию без потерь во время глубокой передачи, одновременно смягчая проблему исчезновения градиентов.
- Слои нормализации (например, нормализация слоев или пакетная нормализация):
- Уровень нормализации обычно добавляется ко входному или выходному концу остаточного блока, чтобы стабилизировать распределение данных во время процесса обучения и повысить эффективность обучения и способность модели к обобщению.
- нелинейная функция активации:
- существовать将главный Выходной сигнал, добавленный к выходному сигналу пропускаемого соединения, обычно передается через нелинейную цепочку. функция активации,Например, ReLU или tanh,внедрить необходимые возможности нелинейной обработки,Повышайте выразительные способности модели.
Выше приведены некоторые пояснения к статье xLSTM. Перейдем непосредственно к коду.
Реализация Pytorch
Чтобы проиллюстрировать проблему, мы просто реализуем xLSTM.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalConv1D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation=1, **kwargs):
super(CausalConv1D, self).__init__()
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, padding=self.padding, dilation=dilation, **kwargs)
def forward(self, x):
x = self.conv(x)
return x[:, :, :-self.padding]
class BlockDiagonal(nn.Module):
def __init__(self, in_features, out_features, num_blocks):
super(BlockDiagonal, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.num_blocks = num_blocks
assert in_features % num_blocks == 0
assert out_features % num_blocks == 0
block_in_features = in_features // num_blocks
block_out_features = out_features // num_blocks
self.blocks = nn.ModuleList([
nn.Linear(block_in_features, block_out_features)
for _ in range(num_blocks)
])
def forward(self, x):
x = x.chunk(self.num_blocks, dim=-1)
x = [block(x_i) for block, x_i in zip(self.blocks, x)]
x = torch.cat(x, dim=-1)
return x
class sLSTMBlock(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, proj_factor=4/3):
super(sLSTMBlock, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.proj_factor = proj_factor
assert hidden_size % num_heads == 0
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.Wz = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wi = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wf = BlockDiagonal(input_size, hidden_size, num_heads)
self.Wo = BlockDiagonal(input_size, hidden_size, num_heads)
self.Rz = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Ri = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Rf = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.Ro = BlockDiagonal(hidden_size, hidden_size, num_heads)
self.group_norm = nn.GroupNorm(num_heads, hidden_size)
self.up_proj_left = nn.Linear(hidden_size, int(hidden_size * proj_factor))
self.up_proj_right = nn.Linear(hidden_size, int(hidden_size * proj_factor))
self.down_proj = nn.Linear(int(hidden_size * proj_factor), input_size)
def forward(self, x, prev_state):
assert x.size(-1) == self.input_size
h_prev, c_prev, n_prev, m_prev = prev_state
x_norm = self.layer_norm(x)
x_conv = F.silu(self.causal_conv(x_norm.unsqueeze(1)).squeeze(1))
z = torch.tanh(self.Wz(x) + self.Rz(h_prev))
o = torch.sigmoid(self.Wo(x) + self.Ro(h_prev))
i_tilde = self.Wi(x_conv) + self.Ri(h_prev)
f_tilde = self.Wf(x_conv) + self.Rf(h_prev)
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * z
n_t = f * n_prev + i
h_t = o * c_t / n_t
output = h_t
output_norm = self.group_norm(output)
output_left = self.up_proj_left(output_norm)
output_right = self.up_proj_right(output_norm)
output_gated = F.gelu(output_right)
output = output_left * output_gated
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class sLSTM(nn.Module):
# TODO: Add bias, dropout, bidirectional
def __init__(self, input_size, hidden_size, num_heads, num_layers=1, batch_first=False, proj_factor=4/3):
super(sLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.num_layers = num_layers
self.batch_first = batch_first
self.proj_factor_slstm = proj_factor
self.layers = nn.ModuleList([sLSTMBlock(input_size, hidden_size, num_heads, proj_factor) for _ in range(num_layers)])
def forward(self, x, state=None):
assert x.ndim == 3
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if state is not None:
state = torch.stack(list(state))
assert state.ndim == 4
num_hidden, state_num_layers, state_batch_size, state_input_size = state.size()
assert num_hidden == 4
assert state_num_layers == self.num_layers
assert state_batch_size == batch_size
assert state_input_size == self.input_size
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size)
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
return output, state
class mLSTMBlock(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, proj_factor=2):
super(mLSTMBlock, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.proj_factor = proj_factor
assert hidden_size % num_heads == 0
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.up_proj_left = nn.Linear(input_size, int(input_size * proj_factor))
self.up_proj_right = nn.Linear(input_size, hidden_size)
self.down_proj = nn.Linear(hidden_size, input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.skip_connection = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wq = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wk = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wv = BlockDiagonal(int(input_size * proj_factor), hidden_size, num_heads)
self.Wi = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wf = nn.Linear(int(input_size * proj_factor), hidden_size)
self.Wo = nn.Linear(int(input_size * proj_factor), hidden_size)
self.group_norm = nn.GroupNorm(num_heads, hidden_size)
def forward(self, x, prev_state):
h_prev, c_prev, n_prev, m_prev = prev_state
assert x.size(-1) == self.input_size
x_norm = self.layer_norm(x)
x_up_left = self.up_proj_left(x_norm)
x_up_right = self.up_proj_right(x_norm)
x_conv = F.silu(self.causal_conv(x_up_left.unsqueeze(1)).squeeze(1))
x_skip = self.skip_connection(x_conv)
q = self.Wq(x_conv)
k = self.Wk(x_conv) / (self.head_size ** 0.5)
v = self.Wv(x_up_left)
i_tilde = self.Wi(x_conv)
f_tilde = self.Wf(x_conv)
o = torch.sigmoid(self.Wo(x_up_left))
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * (v * k) # v @ k.T
n_t = f * n_prev + i * k
h_t = o * (c_t * q) / torch.max(torch.abs(n_t.T @ q), 1)[0] # o * (c @ q) / max{|n.T @ q|, 1}
output = h_t
output_norm = self.group_norm(output)
output = output_norm + x_skip
output = output * F.silu(x_up_right)
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class mLSTM(nn.Module):
# TODO: Add bias, dropout, bidirectional
def __init__(self, input_size, hidden_size, num_heads, num_layers=1, batch_first=False, proj_factor=2):
super(mLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.num_layers = num_layers
self.batch_first = batch_first
self.proj_factor_slstm = proj_factor
self.layers = nn.ModuleList([mLSTMBlock(input_size, hidden_size, num_heads, proj_factor) for _ in range(num_layers)])
def forward(self, x, state=None):
assert x.ndim == 3
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if state is not None:
state = torch.stack(list(state))
assert state.ndim == 4
num_hidden, state_num_layers, state_batch_size, state_input_size = state.size()
assert num_hidden == 4
assert state_num_layers == self.num_layers
assert state_batch_size == batch_size
assert state_input_size == self.input_size
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size)
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
return output, state
class xLSTM(nn.Module):
# TODO: Add bias, dropout, bidirectional
def __init__(self, input_size, hidden_size, num_heads, layers, batch_first=False, proj_factor_slstm=4/3, proj_factor_mlstm=2):
super(xLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_heads = num_heads
self.layers = layers
self.num_layers = len(layers)
self.batch_first = batch_first
self.proj_factor_slstm = proj_factor_slstm
self.proj_factor_mlstm = proj_factor_mlstm
self.layers = nn.ModuleList()
for layer_type in layers:
if layer_type == 's':
layer = sLSTMBlock(input_size, hidden_size, num_heads, proj_factor_slstm)
elif layer_type == 'm':
layer = mLSTMBlock(input_size, hidden_size, num_heads, proj_factor_mlstm)
else:
raise ValueError(f"Invalid layer type: {layer_type}. Choose 's' for sLSTM or 'm' for mLSTM.")
self.layers.append(layer)
def forward(self, x, state=None):
assert x.ndim == 3
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if state is not None:
state = torch.stack(list(state))
assert state.ndim == 4
num_hidden, state_num_layers, state_batch_size, state_input_size = state.size()
assert num_hidden == 4
assert state_num_layers == self.num_layers
assert state_batch_size == batch_size
assert state_input_size == self.input_size
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size)
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
return output, stateCausalConv1Dявляется причинным сверточным слоем,Используется для обеспечения того, чтобы временная причинно-следственная связь не была нарушена при обработке данных временных рядов. Реализация этого класса гарантирует, что операция свертки не увидит будущую информацию.,Эта задача прогнозирования последовательности очень важна.
BlockDiagonal Реализован специальный линейный (полносвязный) слой, весовая матрица которого состоит из множества независимых блоков, расположенных на главной диагонали и образующих блочную диагональную матрицу. Такая конструкция позволяет слою обрабатывать входные данные, при этом каждый блок взаимодействует только с соответствующей частью входных данных, моделируя таким образом набор нескольких независимых линейных преобразований.
для BlockDiagonal Мы также видим, что у него есть еще один параметр num_blocksто естькопироватьсколько внутренних линейных слоев,дляtransformer содержит количество голов внимания многоголового внимания.
sLSTMBlock
В документах sLSTM часто описывается как расширенная версия LSTM со скалярными обновлениями или обновлениями на уровне последовательности, которые могут включать улучшения механизма вентилирования (например, экспоненциальное вентилирование) и оптимизацию структуры памяти. В статье можно больше сосредоточиться на расширении функциональности LSTM посредством оптимизации алгоритма, а не на использовании сложных сетевых слоев и структур, как при реализации кода.
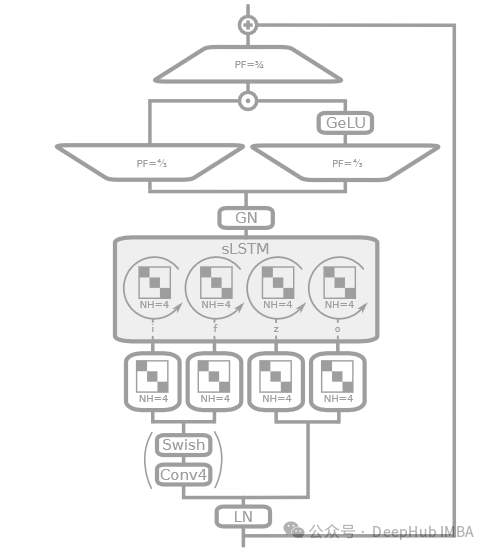
- Нормализация слоев (LayerNorm) используется в коде для стабилизации входных данных каждого слоя.
- Введена причинная свертка (CausalConv1D), которая может обеспечить временной порядок информации при обработке данных последовательности и избежать утечки информации в будущем.
- Матричное преобразование BlockDiagonal (BlockDiagonal) используется для параллельной обработки данных из разных заголовков.
- Остаточные соединения реализованы для повышения стабильности модели при обработке глубоких сетей.
- GELU и GroupNorm использовались для нелинейного преобразования и нормализации выходных данных.
mLSTMBlock
mLSTM описывается в статье как вариант LSTM с матричной памятью, которая может обрабатывать и хранить больше информации параллельно. Это часто связано с фундаментальным изменением структуры памяти, например использованием матриц вместо скаляров для хранения состояний модулей LSTM.
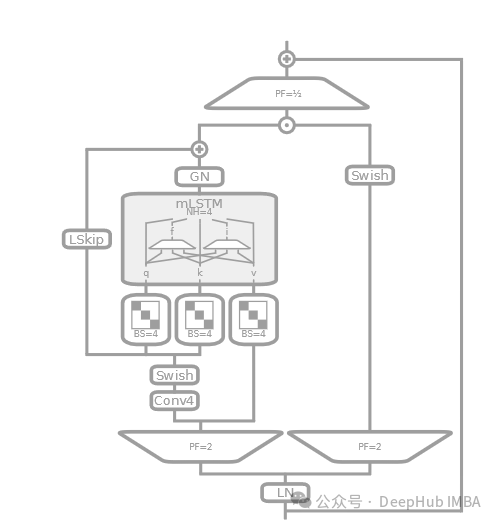
- Подобно sLSTMBlock, используются нормализация слоев и причинная свертка, а также остаточные связи.
- Применяется уникальная стратегия проецирования, такая как проецирование в пространство более высокого измерения и последующая его обработка с помощью функций активации и линейных преобразований.
- Акцент сделан на использовании матричной памяти, которая проявляется в mLSTM как матричные операции над входными и скрытыми состояниями, а также блокировка с помощью BlockDiagonal.
дляmLSTMBlock Параллельные матричные операции.
Вычисление запросов, ключей и значений по сути представляет собой операцию умножения матриц, которая является одной из наиболее часто оптимизируемых операций в параллельных вычислениях.
q = self.Wq(x_conv)
k = self.Wk(x_conv) / (self.head_size ** 0.5)
v = self.Wv(x_up_left)
---
c_t = f * c_prev + i * (v * k) # v @ k.T
n_t = f * n_prev + i * k
h_t = o * (c_t * q) / torch.max(torch.abs(n_t.T @ q), 1)[0] # o * (c @ q) / max{|n.T @ q|, 1}В МЛСТМ середина,Используйте матрицу вместо скаляра для обновления и сохранения скрытого состояния.,Итак, в статье упоминается противоположность трансформатора.,Сеть xLSTM имеет постоянную сложность памяти для линейных вычислений и фазы для длины последовательности.
Память mLSTM не требует параметров, но требует больших вычислительных затрат из-за матричной памяти d×d и обновления d×d. Мы жертвуем объемом памяти и вычислительной сложностью.
Это то, что я говорил ранее. Это очень похоже на внимание преобразователя. Другими словами, mLSTM также записывает скрытое состояние всех предыдущих последовательностей, а затем текущее состояние связано со всеми состояниями перед последовательностью.
sLSTM или mLSTM
В документе не указано, как sLSTM и mLSTM используются вместе, поэтому в нашем коде нет конкретных правил стекирования, а это означает, что нам, возможно, придется принимать собственные решения, но видно, что sLSTM следует использовать как можно меньше. Потому что его нельзя распараллелить, и в статье также говорится, что sLSTM не может быть распараллелен и работает в два раза медленнее.
sLSTM is not parallelizable due to the memory mixing (hidden-hidden connections).However, we developed a fast CUDA implementation with GPU memory optimizations to the registerlevel which is typically less than two times slower than mLSTM.
Подвести итог
Наконец, давайте подведем итоги. Можно сказать, что sLSTM — это обновленная версия предыдущего LSTM, и его нельзя распараллелить, поэтому расчет будет очень медленным.
Новый mLSTM — это новая архитектура, которая использует матрицу d×d для хранения скрытых состояний, поэтому mLSTM сталкивается с высокой вычислительной сложностью. Хотя процесс обновления и извлечения памяти в mLSTM не использует параметры и может быть распараллелен с использованием стандартных матричных операций, все же существуют небольшие затраты времени на настенные часы из-за сложности матричной памяти.
Еще один момент, упомянутый в статье, заключается в том, что, хотя mLSTM Память матрицы не зависит от длины последовательности, но может перегружаться при работе с контекстами большего размера. В статье указывается, что это для равно 16,000 Контекст тега не является ограничением.
Но независимо от того, является ли xLSTM расширенной моделью LSTM, предлагаются различные варианты, включая sLSTM и mLSTM, для повышения ее способности обрабатывать различные сложные данные последовательностей. sLSTM оптимизирует механизм стробирования и подходит для обработки последовательностей с небольшими изменениями во времени, в то время как mLSTM расширяет возможности памяти и параллельной обработки модели за счет использования матриц вместо традиционных векторов и особенно подходит для крупномасштабной обработки данных.
Итак, теперь у нас есть 4 основных базовых модуля: xLSTM, Mamba, RWKV и Transformer. Когда будет время, проведу подробное сравнение этих модулей.
Наконец, поскольку официальный код еще не предоставлен, все, что вы видите в Интернете, является неофициальными реализациями больших парней, и некоторые люди сделали соответствующие индексы. Если вам интересно, вы можете проверить это напрямую:
https://github.com/AI-Guru/xlstm-resources



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
