Углубленный анализ технологии реферирования текста НЛП: подробное объяснение и практическое применение
В этой статье мы подробно рассмотрим технологию реферирования текста при обработке естественного языка, от ее определения и развития до ее основных задач и различных типов технических подходов. В статье подробно анализируются экстрактивные и генеративные сводки и предоставляется код реализации PyTorch для каждого метода. Наконец, в статье обобщаются значение и будущие проблемы технологии реферирования, подчеркивая ее важность в эпоху информационной перегрузки. Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.

1. Обзор

Резюмирование текста — важная отрасль обработки естественного языка (НЛП). Его основная цель — извлечь ключевую информацию из текста и создать краткие и лаконичные сводки содержания. Это не только помогает пользователям быстро получать информацию, но также эффективно организует и обобщает большие объемы текстовых данных.
1.1 Что такое реферирование текста?
Целью реферирования текста является извлечение основных идей из одного или нескольких текстовых источников для создания краткого, связного и соответствующего исходному тексту описательного текста.
пример: Предположим, есть новостная статья, описывающая визит лидера страны, включая его маршрут, иностранных лидеров, с которыми он встречался, и вопросы, которые они обсуждали. Задача резюмирования текста может заключаться в составлении следующего резюме: «Национальный лидер А посетил страну C в день B и обсудил вопрос E с лидером D».
1.2 Зачем нужно реферирование текста?
В условиях взрывного роста объема информации объем текстовых данных, которые людям необходимо обрабатывать, также быстро увеличивается. Обобщение текста предоставляет пользователям эффективный способ быстро добраться до основного содержания статьи, отчета или документа без необходимости читать весь документ.
пример: В академических исследованиях исследователям может потребоваться просмотреть десятки или сотни документов, чтобы написать обзор литературы. Если каждый документ имеет высококачественное текстовое резюме, исследователи могут быстро понять основное содержание и вклад каждого документа, тем самым более эффективно завершая написание обзора литературы.
Обобщение текста имеет широкий спектр сценариев применения, включая, помимо прочего, сводки новостей, сводки научной литературы, сводки бизнес-отчетов и сводки медицинских записей. Благодаря технологии автоматического обобщения текста она может не только повысить эффективность получения информации, но также принести огромную коммерческую ценность и социальные выгоды в различных приложениях.
2. Процесс разработки
История обобщения текста восходит к заре информатики и искусственного интеллекта. От первоначальных методов, основанных на правилах, до сегодняшних технологий глубокого обучения, исследования и применения в области реферирования текста достигли большого прогресса.
2.1 Ранние технологии
На заре информатики,Обобщение текста в основном опирается наоснованный на правилахиэвристикаметод。Эти методы в основном основаны на определенных ключевых словах.、Синтаксическая структура фразы или текста для извлечения ключевой информации.
пример: Предположим, что в новостном сообщении ключевым содержанием текста можно считать часто встречающиеся слова, такие как «президент», «визит» и «договор». Следовательно, на основе этих ключевых слов система может выбирать из текста предложения, содержащие эти слова, в качестве содержания резюме.
2.2 Распространение статистических методов
С помощью статистического метода обучения в обработке естественного языка Приложения в,Обобщение текста также начинает использовать преимуществаTF-IDF、тематическая модельи другие технологии для автоматического создания сводок。Эти методы в некоторой степени улучшают качество резюме.,Сделайте его ближе к человеческому мышлению.
пример: С помощью весов TF-IDF можно идентифицировать важные слова в тексте, а затем на основе весов этих слов подбирать предложения. Например, в статье об охране окружающей среды слова «изменение климата» и «возобновляемая энергия» могут иметь высокие веса TF-IDF, поэтому предложения, содержащие эти слова, могут быть выбраны как часть аннотации.
2.3 Применение глубокого обучения
в последние годы,С развитием технологий глубокого обучения,особенноРекуррентная нейронная сеть (RNN)иТрансформерыВнедрение,В области обобщения текста произошла революция. Эти методы способны улавливать глубокие семантические связи в тексте.,Создавайте более плавные и точные сводки.
пример: Используя модели преобразователей, такие как BERT или GPT, для обобщения текста, модель не просто выбирает на основе ключевых слов, но может понимать общий смысл текста и генерировать резюме, соответствующее исходному содержанию, но более краткое.
2.4 Эволюционные тенденции реферирования текста
Методы и приемы реферирования текста продолжают развиваться. В настоящее время направления исследований включают мультимодальное суммирование, интерактивное суммирование и применение состязательных генеративных сетей для генерации сводок.
пример: В задаче мультимодального обобщения системе может потребоваться сгенерировать сводку на основе заданного текста и изображений. Например, для статьи, рассказывающей об определенном спортивном событии, системе необходимо не только извлечь ключевую информацию из текста, но также извлечь важный контент из изображений, связанных со статьей, и объединить их для создания сводки.
3. Основные задачи
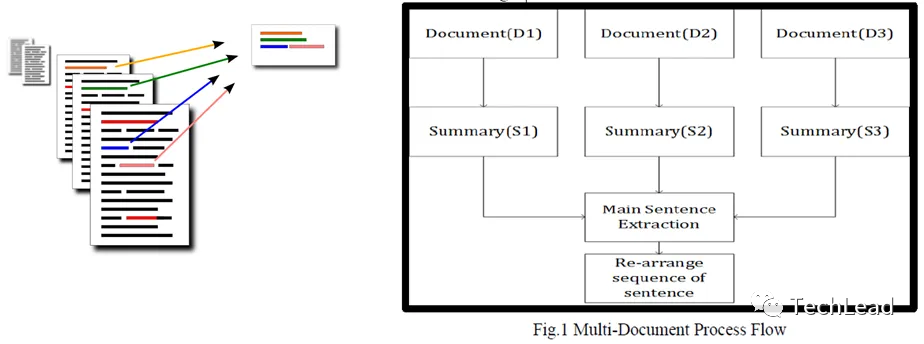
Основные задачи резюмирования текста, являющегося частью обработки естественного языка, включают в себя множество аспектов и предназначены для удовлетворения различных потребностей приложений. Ниже приведены несколько ключевых задач в текстовом виде, а также соответствующие определения и примеры.
3.1 Краткое изложение одного документа
Это самая базовая форма реферирования текста, при которой из данного документа извлекается ключевая информация и создается краткое изложение.
определение: Обработайте отдельный документ, чтобы извлечь из него основную информацию и составить сокращенное резюме.
пример: Извлеките ключевую информацию из новостного репортажа о землетрясении и создайте сводку: «Дата
3.2 Обобщение нескольких документов
Задача включает в себя извлечение и интеграцию ключевой информации из множества связанных документов для создания всеобъемлющего резюме.
определение: Обработайте набор связанных документов, объедините их основную информацию и подготовьте подробное резюме.
пример: Извлеките ключевую информацию из пяти отчетов об одной и той же технологической конференции и подготовьте сводку: «На технологической конференции в день X компании Y, Z и W соответственно представили свои новейшие продукты и обсудили будущие тенденции развития технологий».
3.3 Информационная аннотация по сравнению с фоновой аннотацией
Информативное резюме фокусируется на основных новостях или событиях в документе, тогда как контекстное резюме фокусируется на предоставлении читателю исходной или контекстной информации.
определение: Информационная сводка представляет основное содержание документа, а справочная сводка предоставляет справочную или контекстную информацию, связанную с этим содержимым.
пример:
- информативное резюме: «Страна А и страна Б подписали торговое соглашение».
- Краткое изложение история: «Страна А и страна Б с прошлого года участвуют в торговых переговорах с целью увеличения торговли товарами и услугами между двумя странами».
3.4 Сводка в реальном времени
Это задача создания динамических сводок, особенно когда источник информации постоянно обновляется.
определение: Сводки обновляются и генерируются в режиме реального времени на основе постоянного притока новой информации.
пример: В спортивном событии по ходу игры система может генерировать сводку в режиме реального времени, например: «По итогам первой четверти команда А лидирует над командой Б. 10 баллов. Игрок С команды А набрал 15 очков. "
4. Основные типы
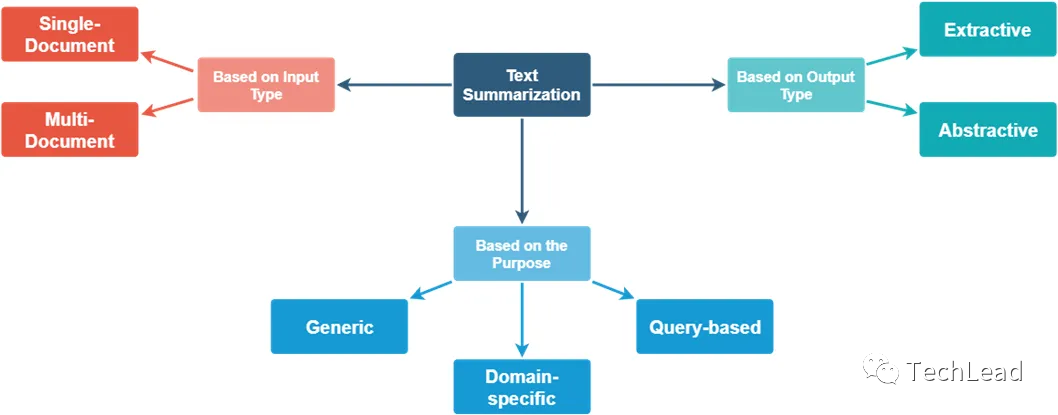
Текстовые резюме можно разделить на различные типы в зависимости от методов их создания и характеристик. Ниже приведены основные типы реферирования текста, а также их определения и примеры.
4.1 Извлекательное резюме
Этот тип резюме напрямую извлекает предложения или фразы из исходного текста для формирования резюме без создания новых предложений.
определение: Выборочно извлекайте предложения или фразы непосредственно из исходного документа для создания резюме.
пример: оригинал: «Пекин — столица Китая. Он имеет долгую историю и богатое культурное наследие. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности». Извлекательное резюме: «Пекин — столица Китая. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности».
4.2 Генеративное резюме
В отличие от экстрактивного реферирования, генеративное реферирование генерирует новые предложения, чтобы предоставить читателям более краткое и плавное изложение текста.
определение: На основе содержания исходного документа генерируются новые предложения для формирования резюме.
пример: оригинал: «Пекин — столица Китая. Он имеет долгую историю и богатое культурное наследие. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности». Генеративное резюме: «Пекин, столица Китая, известен своими историческими местами, такими как Запретный город, Великая стена и площадь Тяньаньмэнь».
4.3 Ориентировочное резюме
Этот тип резюме предназначен для обзора содержания документа и обычно краток.
определение: Предоставьте краткое изложение документа, давая краткое описание основного содержания.
пример: оригинал: «Корпорация Microsoft — это многонациональная технологическая компания со штаб-квартирой в США. Это крупнейший в мире производитель программного обеспечения и производит разнообразную бытовую электронику». Ориентировочное резюме: «Microsoft — крупная американская технологическая компания, производящая программное обеспечение и бытовую электронику».
4.4 Информативное резюме
Этот тип резюме предоставляет более подробную информацию, обычно длиннее и охватывает несколько аспектов документа.
определение: Предоставьте подробное резюме содержания документа, охватывающее основную информацию документа.
пример: оригинал: «Корпорация Microsoft — это многонациональная технологическая компания со штаб-квартирой в США. Это крупнейший в мире производитель программного обеспечения и производит разнообразную бытовую электронику». Информативное резюме: «Корпорация Microsoft, базирующаяся в США, является крупнейшим в мире производителем программного обеспечения, а также производит разнообразную бытовую электронику».
5. Извлекательное обобщение текста
Методы экстракционного обобщения текста формируют резюме путем прямого извлечения предложений или фраз из исходного документа без восстановления новых предложений.
5.1 Определение
определение: Извлекательное обобщение текста — это процесс выборочного извлечения предложений или фраз из исходных документов для создания резюме. Этот метод обычно опирается на оценки важности предложений в документе.
пример: оригинал: «Пекин — столица Китая. Он имеет долгую историю и богатое культурное наследие. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности». Извлекательное резюме: «Пекин — столица Китая. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности».
5.2 Основные технологии экстрактивного обобщения
- На основе статистики:Используйте частоту слов、методы статистики, такие как обратная частота документов, присваивают баллы важности предложениям в документе.
- На основе графика:нравитьсяTextRankалгоритм,Рассматривайте предложения как узлы в графе,Создавайте края на основе сходства между ними.,и присвойте оценку каждому предложению посредством итеративного процесса.
5.3 Реализация Python
Ниже приведена простая реализация извлекаемой сводки на основе статистики на языке Python:
import re
from collections import defaultdict
from nltk.tokenize import word_tokenize, sent_tokenize
def extractive_summary(text, num_sentences=2):
# 1. Tokenize the text
words = word_tokenize(text.lower())
sentences = sent_tokenize(text)
# 2. Compute word frequencies
frequency = defaultdict(int)
for word in words:
if word.isalpha(): # ignore non-alphabetic tokens
frequency[word] += 1
# 3. Rank sentences
ranked_sentences = sorted(sentences, key=lambda x: sum([frequency[word] for word in word_tokenize(x.lower())]), reverse=True)
# 4. Get the top sentences
return ' '.join(ranked_sentences[:num_sentences])
# Test
text = «Пекин — столица Китая. Он имеет долгую историю и богатое культурное наследие. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности».
print(extractive_summary(text))
входить:исходный текст выход:Извлеченное резюме Обработка:Код сначала вычисляет частоту каждого слова в документе.,Затем каждому предложению присваивается оценка важности в зависимости от частоты содержащихся в нем слов.,И верните предложение с наивысшим баллом в виде резюме.
6. Генеративное обобщение текста
В отличие от методов экстрактивного реферирования, которые извлекают предложения непосредственно из документов, генеративное реферирование текста направлено на создание новых, более кратких выражений исходного содержания документа.
6.1 Определение
определение: Генеративное обобщение текста предполагает использование исходного содержимого документа для создания новых предложений и фраз, которые предоставляют читателям более краткую и актуальную информацию.
пример: оригинал: «Пекин — столица Китая. Он имеет долгую историю и богатое культурное наследие. Запретный город, Великая стена и площадь Тяньаньмэнь — известные туристические достопримечательности». Генеративное резюме: «Пекин, столица Китая, известен своими историческими местами, такими как Запретный город, Великая стена и площадь Тяньаньмэнь».
6.2 Основные технологии
- Модель «последовательность-последовательность» (Seq2Seq):Это метод глубокого обучения,Часто используется для задач машинного перевода.,Но он также широко используется в Генеративном обобщении.
- механизм внимания:существоватьSeq2SeqМодель Присоединяйтесьмеханизм вниманияможет помочь Модельлучшесосредоточиться важная часть исходного документа.
6.3 Реализация PyTorch
Ниже приведен обзор простой модели Seq2Seq. Из-за ее сложности здесь представлена только упрощенная версия:
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hidden_dim)
def forward(self, src):
embedded = self.embedding(src)
outputs, hidden = self.rnn(embedded)
return hidden
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hidden_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, context):
input = input.unsqueeze(0)
embedded = self.embedding(input)
emb_con = torch.cat((embedded, context), dim=2)
output, hidden = self.rnn(emb_con, hidden)
prediction = self.out(output.squeeze(0))
return prediction, hidden
# Примечание: Это упрощенная модель, предназначенная только для демонстрационных целей. В реальном приложении вам необходимо рассмотреть возможность добавления дополнительных деталей, таких как механизм. внимание, оптимизатор, функция потерь и т.д.
входить: Последовательность векторов слов исходного документа выход: Последовательность векторов слов для сгенерированного резюме Обработка: Кодер сначала преобразует входной документ в скрытое состояние фиксированного размера. Затем декодер использует это скрытое состояние в качестве контекста для постепенной генерации последовательности суммированных векторов слов.
7. Резюме
С быстрым развитием технологий обработка естественного языка превратилась из исходных задач обработки текста в сложные мультимодальные задачи, и, как мы видели, обобщение текста является очевидным примером этого. От базового экстрактивного и генеративного обобщения до современного мультимодального обобщения, каждый этап отражает наше постоянное углубление и переопределение информации и знаний.
Важно, чтобы мы не только сосредоточились на том, как технология решает эти задачи обобщения, но и поняли, почему нам нужны эти методы обобщения. Резюме — это упрощение большого объема информации, которое может помочь людям быстро уловить основные моменты, сэкономить время и повысить эффективность. В эпоху информационной перегрузки эта способность стала еще более важной.
Однако в то же время перед нами также стоит задача: как обеспечить, чтобы создаваемые резюме были не только краткими, но и точными, объективными и без искажений. Это требует от нас постоянного улучшения и корректировки технологии, чтобы она могла предоставлять высококачественные сводки в различных сценариях.
Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в области архитектуры интернет-сервисов, опыт исследований и разработок продуктов искусственного интеллекта, а также опыт управления командой. Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud. , специалист по управлению проектами, а также занимается исследованиями и разработками продуктов искусственного интеллекта с доходом в сотни миллионов человек.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
