Углубленный анализ принципов хранения данных MongoDB.
MongoDB, как популярная база данных NoSQL, получила широкое внимание благодаря своей модели документа, горизонтальной масштабируемости и превосходной производительности. В этом подробном техническом блоге мы углубимся в принципы хранения данных MongoDB, включая такие ключевые аспекты, как модель данных, формат хранения, механизм хранения, механизм сегментирования, стратегия индексации и высокая доступность.
1. Модель данных и формат BSON.
Модель данных MongoDB основана на документах.,Это структура данных, состоящая из пар ключ-значение.,Похоже на:JSON。Каждый документ имеет уникальный_idПоле как первичный ключ,Используется для уникальной идентификации документа в коллекции. Документы могут быть вложенными.,Эта гибкая структура данных делает MongoDB идеальным хранилищем полуструктурированных данных.
На уровне хранилища MongoDB использует формат BSON (двоичный JSON) для сериализации документов. BSON — это двоичное представление, которое расширяет функциональность JSON, поддерживает больше типов данных и является более эффективным. Формат BSON позволяет передавать документы непосредственно в двоичной форме по сети, сокращая накладные расходы на сериализацию и десериализацию и тем самым повышая эффективность передачи данных.
2. Механизм хранения данных
Принцип хранения MongoDB тесно связан с используемым механизмом хранения. Начиная с версии MongoDB 3.2, WiredTiger стал механизмом хранения по умолчанию. WiredTiger — это высокопроизводительный механизм хранения с поддержкой транзакций, который сочетает в себе преимущества индексов B-дерева и деревьев LSM (дерево слияния с лог-структурой), обеспечивая MongoDB превосходную производительность чтения и записи.
В частности, WiredTiger обеспечивает быстрый поиск данных через структуру индекса B-дерева. В то же время он использует принцип проектирования дерева LSM, чтобы сначала записать данные в структуру данных (MemTable) в памяти, а затем в соответствующее время объединить данные в постоянное хранилище на диске. Такая конструкция позволяет WiredTiger эффективно обрабатывать большое количество операций записи и особенно подходит для сценариев приложений, требующих высокой производительности записи.
3. Шардинг данных и кластерная архитектура
Для поддержки хранения и запроса больших объемов данных MongoDB использует технологию сегментирования. Шардинг — это процесс горизонтального разделения данных на несколько серверных узлов, при этом каждый узел хранит подмножество набора данных. Эта архитектура позволяет MongoDB масштабироваться горизонтально и преодолевать ограничения хранилища на одной машине.
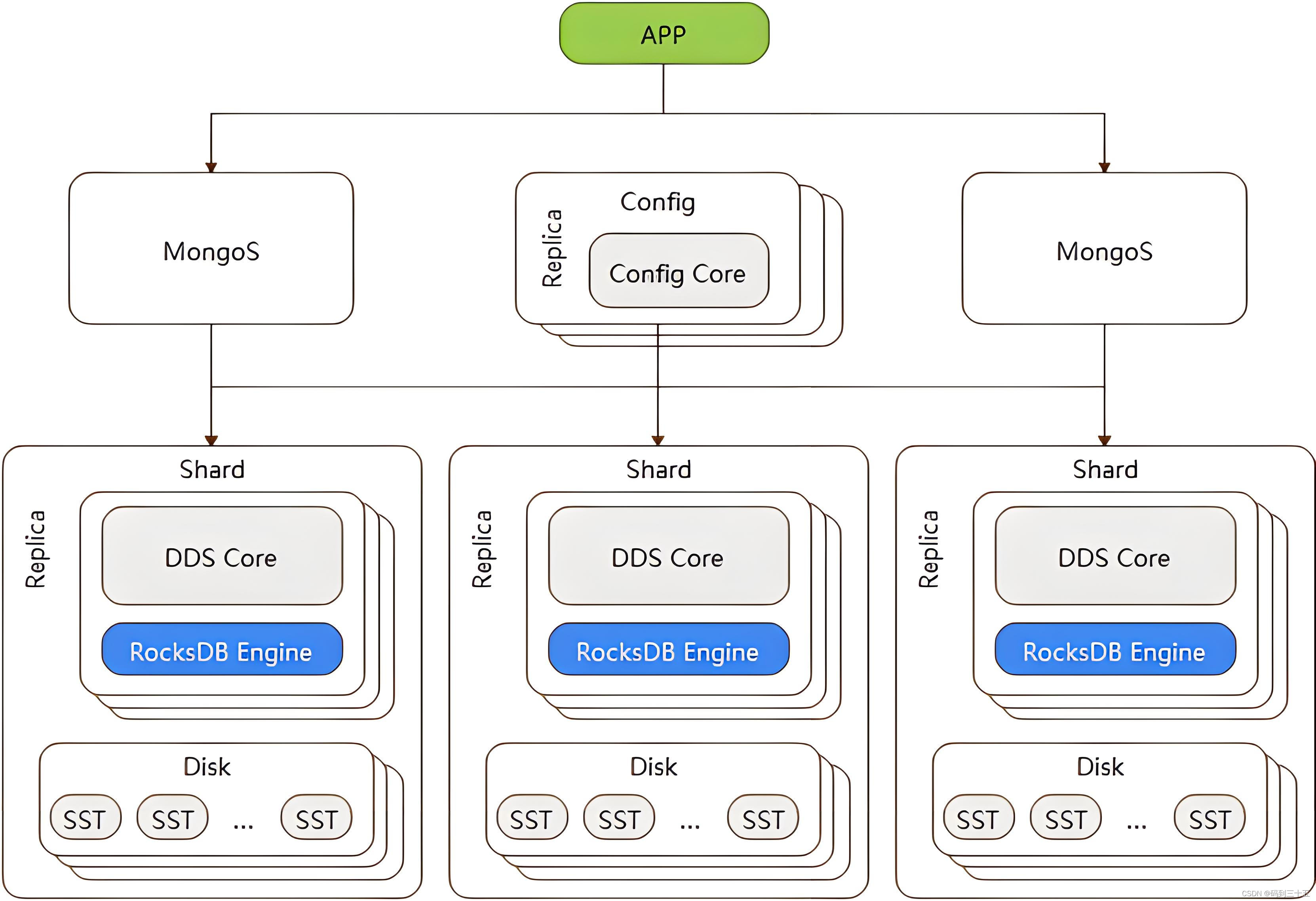
В кластерной архитектуре MongoDB имеется несколько ключевых компонентов: шард-сервер, сервер конфигурации и маршрутизатор запросов (mongos). Сервер сегментов отвечает за хранение фактических сегментов данных, сервер конфигурации хранит метаданные кластера, а маршрутизатор запросов действует как посредник между клиентом и сервером сегментов, отвечающий за маршрутизацию запроса клиента на правильный сервер сегментов. .
4. Индексная стратегия и оптимизация
Индексы играют ключевую роль в повышении производительности запросов к базе данных. MongoDB поддерживает несколько типов индексов, включая индексы с одним ключом, составные индексы, полнотекстовые индексы и т. д., для удовлетворения различных потребностей запросов. Эти индексы создаются с использованием структур данных, таких как B-деревья, для обеспечения эффективной производительности запросов.
При создании индекса MongoDB выберет подходящий тип индекса в зависимости от распределения данных и режима запроса. Например, для полей, которые часто используются в условиях запроса, вы можете создать индексы с одним ключом, чтобы повысить скорость запроса. Для условий запроса, которые должны соответствовать нескольким полям одновременно, вы можете использовать составные индексы для оптимизации производительности.
Кроме того, MongoDB также предоставляет некоторые предложения по оптимизации индексов, например, избегать создания слишком большого количества индексов для уменьшения использования пространства хранения и накладных расходов на операции записи, а также регулярно переоценивать и корректировать индексы для адаптации к изменениям данных.
5. Высокая доступность и репликация данных
Чтобы обеспечить доступность и долговечность данных, MongoDB использует наборы реплик для достижения высокой доступности данных. Набор реплик состоит из набора экземпляров MongoDB с одним и тем же набором данных, включая основной узел и несколько вторичных узлов. Первичный узел отвечает за обработку запросов на запись и синхронизацию изменений данных со вторичным узлом. Вторичный узел используется для обработки запросов на чтение и обеспечения резервного копирования данных.
При выходе из строя основного узла MongoDB автоматически запускает механизм аварийного переключения и выбирает новый основной узел, который возьмет на себя его работу. Такая конструкция обеспечивает доступность и надежность данных, а также снижает риск возникновения единых точек отказа. В то же время MongoDB также поддерживает функции автоматического резервного копирования и восстановления данных для дальнейшего повышения надежности данных.
6. Заключение
Принципы хранения MongoDB включают в себя множество аспектов, в том числе гибкую модель данных, эффективный формат BSON, мощный механизм хранения, масштабируемый механизм сегментирования, оптимизированную стратегию индексации и дизайн с высокой доступностью. В совокупности эти функции обеспечивают MongoDB превосходную производительность и масштабируемость, что позволяет ей хорошо работать в различных сценариях приложений.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
