Углубленный анализ принципа поиска вектора RAG большой модели.
Традиционный поиск в базе знаний обычно использует ключевые слова и сопоставление терминов. С появлением AGI все больше и больше при поиске в базе знаний начинают использовать технологию векторного поиска, особенно в области RAG, используется расширенный генеративный поиск вопросов и ответов. применение и продвижение.
Разницу в характеристиках векторного поиска и обычного поиска легко понять:
Обычный поиск:
Оптимизированный для поиска точных совпадений ключевых слов или фраз, он в основном полагается на сопоставление ключевых слов для предоставления результатов поиска. Он подходит для простых запросов и сценариев точного соответствия и не может обрабатывать семантические отношения и сложные типы данных.
Преимущества: высокая гибкость, прозрачная и понятная логика запросов, высокая простота сопровождения и низкие затраты на хранение и запросы.
Недостатки: соответствие ключевых слов, невозможность понять семантику и сложность улучшения качества запроса.
Векторный поиск:
Используйте математические векторы для представления данных и расчета сходства или расстояния между точками данных. Он может обрабатывать семантические отношения, контекст и богатую семантическую информацию данных. Он подходит для обработки различных типов данных, таких как изображения, аудио и видео, для обеспечения более точной информации. и релевантные результаты поиска не зависят только от соответствия ключевых слов.
Преимущества: сильная способность к семантическому пониманию, векторный поиск на основе векторного представления документов и более точная обработка многозначности и синонимов.
Недостатки: затраты на хранение данных и вычисления высоки, алгоритмы запросов для разных типов данных различны, алгоритмы запросов необходимо постоянно оптимизировать.
Судя по приведенному выше сравнительному анализу, традиционные методы поиска больше подходят для сценариев точного сопоставления, в то время как векторный поиск подходит для поиска сложных семантических сопоставлений, может понимать более сложные семантические отношения и обеспечивать более точные и полные результаты поиска. Особенно в некоторых сценариях вопросов и ответов на знания, таких как ручное обслуживание клиентов, поиск в базе знаний и т. д., существует множество способов описания вопроса, поэтому в методе векторного запроса все соответствующие ответы будут получены в соответствии с расчетом сходства с наибольшую степень, а затем вернуть наиболее идеальный результат в соответствии с наиболее подходящим весом, например, при использовании RAG в больших моделях.
Помимо упомянутой только что системы вопросов на основе базы знаний, в которой используется векторный поиск, существует множество сценариев применения векторного поиска, например:
- Система рекомендаций: рекламные рекомендации, угадывание того, что вам понравится и т. д.;
- Распознавание изображений: поиск изображений по изображению, поиск изображений по изображению. Конкретные приложения: поиск транспортных средств, поиск изображений продуктов и т. д.;
- Обработка естественного языка: поиск и рекомендации текста на основе семантики, аппроксимация текста посредством поиска текста;
- Сопоставление голосовых отпечатков, извлечение аудио. Дедупликация файлов: удаление дубликатов файлов с помощью отпечатков пальцев;
- Поиск новых наркотиков;
Однако для разных типов данных и логики сопоставления алгоритмы поиска, применяемые в разных сценариях поиска и получения данных, также различаются. Ниже приводится краткое введение в несколько основных алгоритмов поиска и сценариев применения.
Хеширование с учетом местоположения (LSH)
LSH (Locality Sensitive Hashing), называемый по-китайски «локально-чувствительным хешированием», представляет собой быстрый алгоритм поиска ближайшего соседа для массивных многомерных данных. Одна из проблем, с которыми мы часто сталкиваемся, — это поиск ближайшего соседа при работе с огромными многомерными данными. Если используется линейный поиск, эффективность приемлема для данных малой размерности, но для данных большой размерности он требует очень много времени. Чтобы решить эту проблему, люди разработали специальную хэш-функцию, чтобы два данных с высоким сходством могли быть сопоставлены с одним и тем же значением хеш-функции с высокой вероятностью, в то время как два данных с низким сходством могли быть сопоставлены с одним и тем же значением хеш-функции с очень высокой вероятностью. низкая вероятность. Вероятность отображается на одно и то же значение хеш-функции. Мы называем такую функцию LSH (локально-зависимое хеширование). Наиболее фундаментальной функцией LSH является эффективное решение задачи ближайшего соседа для массивных многомерных данных.
Сценарии применения: Приблизительный поиск ближайшего соседа для массивных многомерных векторных данных, таких как семантический поиск крупномасштабного текста, персонализированные рекомендации и т. д. Логика алгоритма: Создайте семейство нескольких хэш-функций, каждая из которых сопоставляет вектор со значением хеш-функции. Вычислите несколько значений хеш-функции для каждого вектора в качестве подписи вектора. Храните векторы с одинаковой сигнатурой в одном и том же ведре. При запросе вычисляется сигнатура вектора запроса, и векторы в соответствующем сегменте извлекаются как набор кандидатов. Выполните точные вычисления сходства в наборе кандидатов и верните K наиболее похожих векторов.
Пример: В системе семантического поиска, содержащей миллионы текстов новостей, LSH можно использовать для отображения текстов новостей в векторы и построения индексов. При запросе оператор пользовательского запроса также сопоставляется с вектором, и наиболее похожий текст новостей быстро извлекается через LSH.
Иерархический навигационный малый мир (HNSW)
Целью HNSW (Hierarchical Navigable Small Word) является быстрый поиск k элементов ближайшего соседа запроса в очень большом количестве наборов кандидатов. Алгоритм HNSW в настоящее время является широко используемым алгоритмом поиска. Это обновленная версия своего предшественника, алгоритма NSW. Связь графа определяется заранее для всех N элементов-кандидатов посредством соединения графа, так что вышеупомянутый алгоритм может быть N часть сложности снижается, тем самым оптимизируя общую эффективность поиска.
Сценарии применения: Приблизительный поиск ближайшего соседа для векторных данных миллиарда масштабов, таких как крупномасштабный поиск изображений, поиск видео и т. д. Логика алгоритма: Векторы создаются в многоуровневую графовую структуру в порядке вставки, и каждый уровень является объектом навигации предыдущего слоя. Вычисляется расстояние между вновь вставленным вектором и частичным вектором текущего слоя, и ближайший из них выбирается в качестве точки входа. Начиная с точки входа, жадно ищет ближайшего соседа и строит соединительное ребро нового вектора. При запросе начните жадный поиск с верхнего уровня и найдите вектор ближайшего соседа слой за слоем.
Пример: В системе поиска изображений, содержащей миллиарды изображений, HNSW можно использовать для индексации векторов признаков изображений. При запросе вводится вектор признаков загруженного изображения, и наиболее похожее изображение эффективно извлекается через HNSW.
Квантование векторного произведения (IVFPQ)
IVFPQ (инвертированное файловое квантование продукта) — это метод индексации для эффективного приблизительного поиска ближайшего соседа, который сочетает в себе две технологии: инвертированное файловое индексирование (IVF) и количественное определение продукта (PQ). IVFPQ обеспечивает компактное представление и быстрый поиск по сходству за счет разложения многомерных векторов на более мелкие подпространства и независимого квантования каждого подпространства. Этот подход хорошо работает при работе с большими наборами данных, снижая требования к хранению и ускоряя обработку запросов.
Сценарии применения: Приблизительный поиск ближайшего соседа для массивных многомерных векторных данных, таких как крупномасштабный поиск мультимедиа, поиск продуктов электронной коммерции и т. д. Логика алгоритма: Создайте предварительно вычисленные кластеры, содержащие большое количество центроидов, называемые списком. Разложите вектор на несколько низкоразмерных подвекторов и выполните кодирование квантования на каждом подвекторе. При запросе сначала найдите список, ближайший к вектору запроса, а затем вычислите расстояние между векторами в списке.
Пример: На платформе электронной коммерции, содержащей сотни миллионов продуктов, IVFPQ можно использовать для индексации векторов признаков, таких как изображения и тексты продуктов. При запросе введите пользовательский запрос и быстро получите наиболее похожие продукты через IVFPQ.
На данный момент у нас есть некоторое общее представление о технологии векторного поиска.,Может хорошо понимать векторные запросы к изображениям.,Но как использовать векторы, чтобы выразить сходство текста и смысловое понимание? Сходство текста выражает семантику,Здесь нам нужно ввести НЛП – векторизацию текста.,Прямо сейчасвекторная семантическая модель,В настоящее время общие векторные семантические модели имеют векторные семантические модели в разных областях по разным полям.,Если мы сможемmodelscopeТекстовые векторные модели встречаются во многих областях.,Эти текстовые векторные модели также создаются посредством целевого обучения на основе корпусных данных в текущей области.
нравиться:
Универсальный вектор китайского текста
text2vec-large-chinese
https://modelscope.cn/models/thomas/text2vec-large-chinese/summary
Вектор текста поля электронной коммерции
nlp_corom_sentence-embedding_chinese-base-ecom
https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base-ecom/summary
Текстовая векторная модель медицинского поля
nlp_corom_sentence-embedding_chinese-base-medical
https://modelscope.cn/models/iic/nlp_corom_sentence-embedding_chinese-base-medical/summary
Эти векторные модели будут преобразованы в векторные данные соответствующей модели на основе исходной информации, введенной пользователем.
Например, если вы введете предложение в медицинскую векторную модель, на выходе будет непрерывный вектор фиксированного размера:
- Ввод: Сколько времени занимает операция по поводу кровотечения из верхних отделов желудочно-кишечного тракта?
- Выход: 0,16549307, -0,1374592, -0,0132587, …, 0,5855098, -0,340697, 0,08829002]
Затем мы можем выполнить кластеризацию текста, вычисление сходства текста, сопоставление и поиск на основе выходного вектора.
Тогда здесь возникнет другой вопрос, как рассчитываются векторные данные текста? Затем нам нужно понять метод расчета сходства слов, то есть моделирование модели векторного пространства.
Модель векторного пространства представляет собой представление значения слова.。Основной отправной точкой является объединение словВстроитьв векторное пространство,Из-за этого,Мы называем векторное представление слова словом.Встроить(embedding),Слово представлено его индексом в словаре.,Или представлено строкой букв. Одним из больших преимуществ векторных моделей является то, что,Он может представлять семантику слова более детально.,а не как индекс,Строка рассматривает слово как атом.
Векторы слов обычно используют контекстные слова для описания слов, которые могут описывать слово более детально. Следовательно, наша матрица будет размерной матрицей |V|*|V|. Строки и столбцы представляют собой слова в корпусе, а элементы матрицы представляют количество раз, когда два слова появляются в одном и том же контексте, поэтому значение элемента матрицы — это количество раз, когда два слова появляются в одном и том же документе.
Чем я У нас есть абзац, в котором часто встречающиеся слова распределены в матрицу:
– | aardvark | computer | data | pinch | result | sugar |
|---|---|---|---|---|---|---|
apricot | 0 | 0 | 0 | 1 | 0 | 1 |
pineapple | 0 | 0 | 0 | 1 | 0 | 1 |
digital | 0 | 2 | 1 | 0 | 1 | 0 |
information | 0 | 1 | 6 | 0 | 4 | 0 |
Как видно из таблицы выше, абрикос и ананас похожи, поскольку в их контексте фигурируют щепотка и сахар, но в цифровом контексте эти слова не существуют. Таким образом, можно обнаружить, что отношения между словами как бы скрыты в этой матрице.
Это также можно понимать просто как:
Векторное значение абрикоса равно [0,0,0,1,0,1] Векторное значение ананаса равно [0,0,0,1,0,1]
Если два слова имеют один и тот же вектор, семантика этих двух слов одинакова или близка.
При реальном обучении и оптимизации модели словарный запас будет больше, а алгоритм оптимизации будет более сложным.
Как упоминалось выше, word2vec — это не один алгоритм, а серия моделей архитектур и оптимизаций.
Обычно используемые модели алгоритмов включают в себя
- Модель непрерывного мешка слов CBoW
Прогнозируйте средние слова на основе слов окружающего контекста. Контекст состоит из нескольких слов до и после текущего (среднего) слова. Эта архитектура называется моделью «мешка слов», поскольку порядок слов в контексте не имеет значения.
- Непрерывная модель Skip-Gram
Прогнозируйте слова в определенном диапазоне до и после текущего слова в том же предложении. Ниже приведен рабочий пример.
Полный процесс расчета векторной модели представляет собой процесс обучения нейронной сети, который можно выразить следующим образом:
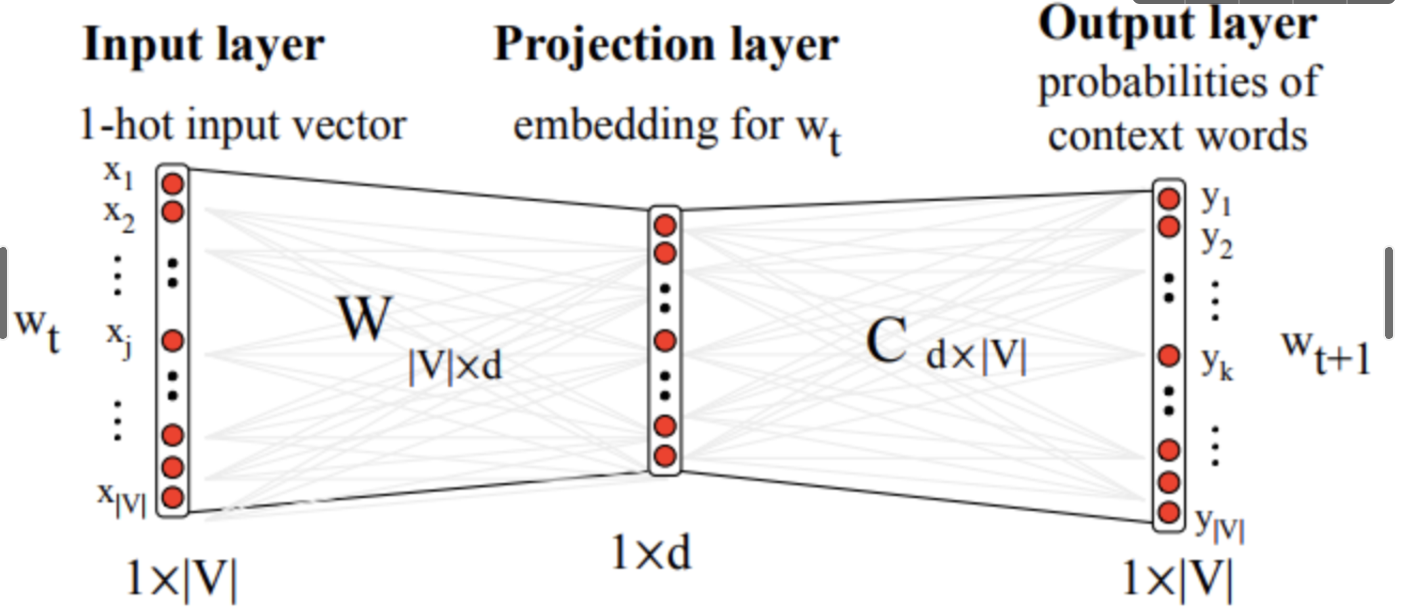
На входе находится 1-горячее кодирование слова (вектор только с одним измерением, общее количество измерений вектора равно размеру словаря), которое используется для извлечения вектора, соответствующего текущему слову, из вектора слова. W, где C — вектор контекстного слова. И W, и C инициализируются случайным образом и постоянно настраиваются в процессе обучения. Конечным продуктом, который мы надеемся получить, является векторная матрица слов W. Всего строк |V|, каждая строка соответствует вектору слова в словаре.
Наконец, выходной слой необходимо оптимизировать и сжать, чтобы облегчить хранение и извлечение векторов. Это также потребует некоторых знаний об оптимизации векторной модели. Если вам интересно, вы можете обратиться к word2vec, чтобы завершить модель алгоритма для исследования:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
