Углубленный анализ основных компонентов экосистемы Hadoop: HDFS, MapReduce и YARN.
Статья, объясняющая три основных компонента экосистемы Hadoop.
Выход на этап больших данных означает переход на этап NoSQL, который больше ориентирован на сценарии OLAP, то есть хранилища данных, BI-приложения и т. д. Развитие технологий больших данных не случайно. Централизованные базы данных или распределенные базы данных, основанные на архитектуре MPP, часто используют стабильные, но дорогие миникомпьютеры, компьютеры «все в одном» или P Серверы C и т. д. имеют относительно плохую масштабируемость, в то время как среда вычислений больших данных может быть построена на основе недорогих обычных аппаратных серверов и теоретически поддерживает неограниченное расширение для поддержки сервисов приложений.
Наиболее известной в области больших данных является экосистема Hadoop. В целом она в основном состоит из трех частей: базовой системы хранения файлов HDFS (Hadoop Distributed File System, Распределенная файловая система Hadoop) и платформы планирования ресурсов и вычислений Yarn. (Еще один переговорщик ресурсов, еще один координатор ресурсов) и компоненты приложений верхнего уровня на основе HDFS и Yarn, такие как HBase, Hive и т. д. Типичное приложение на базе Hadoop показано на рисунке ниже.
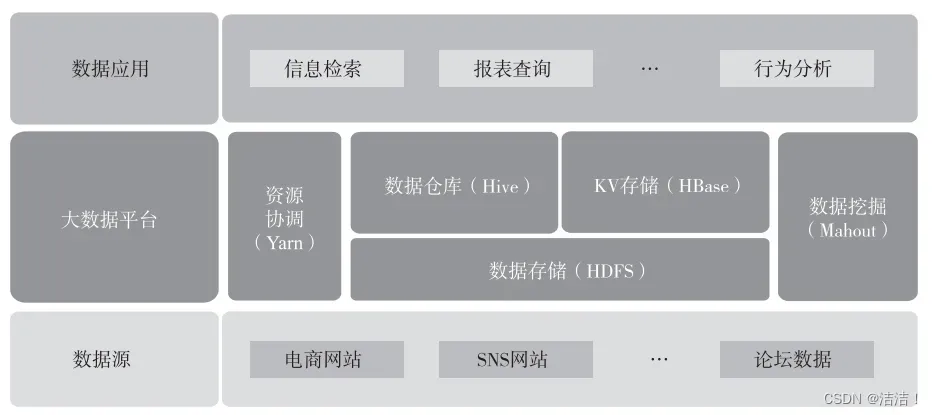
Типичное приложение Hadoop
01HDFS
HDFS спроектирована как распределенная файловая система, подходящая для работы на обычном оборудовании. Она имеет много общего с существующими распределенными файловыми системами, например, с типичной архитектурой Master-Slave (которая здесь не будет представлена). Она также имеет отличия. HDFS является высокоотказоустойчивой системой и подходит для развертывания на дешевых машинах. Что касается HDFS, я хочу отметить два основных момента: настройку количества реплик по умолчанию и Rack Awareness.
Число копий HDFS по умолчанию — 3. Это связано с тем, что Hadoop обладает высокой отказоустойчивостью. С точки зрения избыточности и распределения данных данные необходимо хранить в разных шкафах в одном компьютерном зале и в разных центрах обработки данных, чтобы обеспечить максимальный объем данных. доступность. Следовательно, для достижения вышеуказанной цели блоки данных необходимо хранить как минимум на разных стойках в одном компьютерном зале (2 копии) и в стойке по всему дата-центру (1 копия), всего 3 копии. данных.
Целью осведомленности о стойках является попытка обеспечить возможность связи между различными вычислительными узлами внутри одной стойки, а не между стойками, тем самым уменьшая передачу данных между различными сетями в распределенных вычислениях и уменьшая потребление ресурсов пропускной способности сети. Например, когда чтение данных происходит в кластере, клиент определяет, какой узел данных отправляет данные клиенту в порядке приоритета от ближнего к дальнему, поскольку в распределенной среде сетевой ввод-вывод стал основным узким местом производительности.
Только глубоко поняв эти два момента, мы сможем понять, почему Hadoop обладает высокой отказоустойчивостью. Высокая отказоустойчивость является основой для работы Hadoop на оборудовании общего назначения.
02Yarn
Yarn — еще один подпроект Hadoop после Common, HDFS и MapReduce. Он был предложен в MapReduceV2.
В Hadoop1.0 JobTracker состоит из двух частей: диспетчера ресурсов (реализуемого модулем TaskScheduler) и управления заданиями (реализуемого несколькими модулями в JobTracker).
В Hadoop 1.0 JobTracker не отделял функции, связанные с управлением ресурсами, от функций, связанных с приложениями, и постепенно стал узким местом кластера, что, в свою очередь, привело к плохой масштабируемости, снижению использования ресурсов и недостаточной поддержке нескольких платформ в кластере. проблема.
В MapReduceV2 Yarn отвечает за управление ресурсами (памятью, процессором и т. д.) в MapReduce и их упаковку в контейнеры. Это позволяет MapReduce сосредоточиться на задачах обработки данных, с которыми он хорошо справляется, не беспокоясь о планировании ресурсов. Эта слабосвязанная архитектура обеспечивает гибкость всей платформы Hadoop.
03Hive
Hive — это инфраструктура хранилища данных, основанная на Hadoop. Она использует простые операторы SQL (сокращенно HQL) для запроса и анализа данных, хранящихся в HDFS, а также преобразует операторы SQL в программы MapReduce для обработки данных. Основные различия между Hive и традиционными реляционными базами данных отражены в следующих моментах.
1) Место хранения. Данные Hive хранятся в HDFS или HBase, причем последние данные обычно хранятся на необработанных устройствах или в локальных файловых системах. Поскольку Hive построен на HDFS, он опирается на отказоустойчивую функцию таблиц данных HDFS. естественно избыточно.
2) Обновление базы данных. Hive не поддерживает обновления. Обычно он записывается один раз, а читается и записывается несколько раз (эта часть начинает поддерживать транзакционные операции после Hive 0.14, но существует множество ограничений, поскольку Hive основан на HDFS). в качестве базового хранилища. Чтение и запись HDFS не поддерживает функции транзакций, поэтому поддержка транзакций Hive должна разделять файлы данных и файлы журналов для поддержки функций транзакций.
3) Задержка выполнения SQL. Задержка Hive относительно высока, поскольку каждое выполнение требует анализа оператора SQL в программе MapReduce.
4) По масштабу данных Hive обычно находится на уровне TB, тогда как последний относительно невелик.
5) Что касается масштабируемости, Hive поддерживает UDF, UDAF и UDTF, причем последний имеет относительно плохую масштабируемость.
04HBase
HBase (база данных Hadoop) — это высоконадежная, высокопроизводительная, столбцово-ориентированная, масштабируемая распределенная система хранения. Его базовая файловая система использует HDFS, а ZooKeeper используется для управления связью между HMaster кластера и каждым сервером региона, мониторинга состояния каждого сервера региона и хранения адреса входа каждого региона.
1. Функции
HBase — это база данных в форме «ключ-значение» (аналог Map в Java). Поскольку это база данных, в ней должны быть таблицы. Таблицы в HBase, вероятно, имеют следующие характеристики.
1) Большой: таблица может иметь сотни миллионов строк и миллионы столбцов (при наличии большого количества столбцов вставка замедляется).
2) Ориентация на столбцы: управление хранением и разрешениями на основе столбцов (семейств), независимый поиск по столбцам (семействам).
3) Разреженность: пустые (нулевые) столбцы не занимают места для хранения, поэтому таблицу можно сделать очень разреженной.
4) Данные в каждой ячейке могут иметь несколько версий. По умолчанию номер версии назначается автоматически и является меткой времени при вставке ячейки.
5) Все данные в HBase представляют собой байты, и не существует конкретного объекта данных, определенного по типу (поскольку системе необходимо адаптироваться к различным типам форматов данных и источникам данных, схема не может быть строго определена заранее).
Здесь следует отметить, что HBase также основан на HDFS, поэтому он также имеет характеристики трех копий по умолчанию и избыточности данных. Кроме того, HBase также использует характеристики WAL для обеспечения согласованности чтения и записи данных.
2. хранилище
HBase использует столбчатое хранилище для хранения данных. Традиционные реляционные базы данных в основном используют хранилище строк для хранения данных. Характеристика чтения данных заключается в чтении записей данных с диска в соответствии с степенью детализации строк, а затем их обработке в соответствии с фактически необходимыми данными полей. число большое, но требуется обрабатывать меньше полей (особенно в сценариях агрегации). Из-за основного принципа хранения строк данные по-прежнему необходимо запрашивать в строках (все поля). В этом процессе дисковый ввод-вывод, требования к памяти и сетевой ввод-вывод, генерируемые приложением, вызовут определенное количество отходов; метод чтения данных из хранилища столбцов в основном считывает данные в соответствии с детализацией столбца. Подход к чтению по требованию снижает дисковый ввод-вывод, требования к памяти и сетевой ввод-вывод, выполняемый приложениями при запросе данных.
Кроме того, поскольку данные одного и того же типа хранятся единообразно, выбор и эффективность алгоритмов сжатия будут дополнительно улучшены в процессе сжатия данных, что еще больше снижает требования к ресурсам в распределенных вычислениях.
Метод столбчатого хранения больше подходит для сценариев приложений OLAP, поскольку этот тип сценария имеет характеристики большого объема данных и небольшого количества полей запроса (часто агрегатных функций). Например, недавно популярный ClickHouse также использует столбчатое хранилище для хранения данных.
05Sparkи Потоковое вещание Spark
Spark был разработан и открыт Twitter для решения проблемы анализа массивных потоков данных. Spark сначала импортирует данные в кластер Spark, затем быстро сканирует данные с помощью управления на основе памяти и использует итерационные алгоритмы для минимизации глобальных операций ввода-вывода для повышения общей производительности обработки. Это похоже на идею реализации Hadoop по поиску «данных» из «вычислений» и обычно подходит для сценариев, в которых несколько запросов и анализов записываются один раз.
Spark Streaming — это платформа потоковых вычислений, основанная на Spark. Она обрабатывает и контролирует данные в реальном времени, а также может записывать результаты вычислений в HDFS. Он похож на популярную платформу вычислений в реальном времени Flink, но они существенно отличаются, поскольку Spark Streaming обрабатывает данные на основе микропакетов, а не построчно.
Об авторе:
Ли Ян, старший архитектор данных, имеет более 10 лет опыта работы в областях, связанных с данными. Руководитель группы разработчиков торговой системы технологической платформы ведущей компании по управлению страховыми активами, отвечающий за создание, оптимизацию и миграцию множества приложений и платформ данных. Когда-то он работал техническим партнером в компании, занимающейся данными, и отвечал за работу, связанную с хранилищем данных или платформой данных, для нескольких финансовых учреждений. Автор книги «Архитектура корпоративных данных: основные элементы, модель архитектуры, управление данными и построение платформы».
Причины рекомендации:
В этой книге систематически объясняется архитектура данных уровня предприятия с точки зрения архитектуры предприятия. В ней систематически разбираются и объясняются базовые знания об архитектуре предприятия, а также теоретические знания о компонентах архитектуры данных, архитектурных моделях, управлении данными и активах данных. управление.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
