Углубленный анализ HNSW: иерархический навигационный граф малого мира в Faiss

Иерархические навигационные графики Small World (HNSW) являются одним из наиболее эффективных индексов для поиска сходства векторов. Технология HNSW превосходна в поиске приблизительного ближайшего соседа (ANN) благодаря своей сверхбыстрой скорости поиска и превосходной скорости отзыва. Хотя HNSW является мощным и популярным алгоритмом приблизительного поиска ближайших соседей, понять, как он работает, непросто.
Цель этой статьи — демистифицировать HNSW и объяснить этот интеллектуальный алгоритм в простой для понимания форме. В конце статьи мы рассмотрим, как реализовать HNSW с помощью Faiss, и обсудим, какие настройки параметров обеспечивают желаемую производительность.
Основы HNSW
мы можемANNАлгоритмы делятся на три разные категории.;Деревья, хеши и графы。HNSWОтносится к категории изображений.。Более конкретно,этоГраф, основанный на близости, где две вершины основаны на их близости(Ближайшие вершины соединены)соединять——Обычно определяется на евклидовом расстоянии.。
Значительный скачок сложности от графа «близости» к графу «иерархически перемещаемого маленького мира».,Будут описаны две парыHNSWБазовые технологии, которые вносят наибольший вклад:Таблица вероятностных прыжков и маленькая судоходная карта мира.
Таблица вероятностных прыжков
Таблица вероятностных прыжков Зависит отWilliam Представленный Пью в 1990 году, он сочетает в себе возможности быстрого поиска в отсортированных массивах с удобными операциями вставки связанных списков.
Списки пропуска работают путем создания связанных списков нескольких уровней. На самом высоком уровне ссылки способны пропускать множество промежуточных узлов. На более низких уровнях количество «прыжков» ссылки постепенно уменьшается.
Для поиска в списке переходов начните с верхнего уровня и двигайтесь вправо по краю. Если обнаруживается, что «ключ» текущего узла больше целевого ключа, это означает, что цель превышена, поэтому перейдите на следующий уровень, чтобы продолжить поиск.
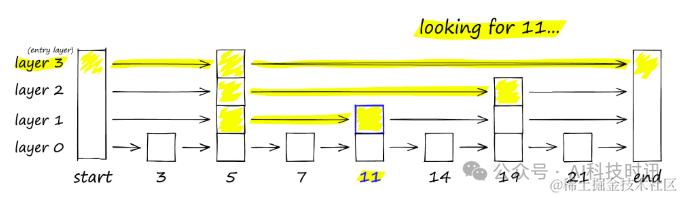
HNSW наследует тот же иерархический формат: самые верхние уровни имеют более длинные стороны (для быстрого поиска), а нижние уровни — более короткие стороны (для точного поиска).
Навигационные графики «Маленький мир» Навигационные графики «Маленький мир»
Navigable Small World Graphs (NSW) — это эффективная структура данных для векторного поиска. Ее концепция была впервые предложена в научных статьях в период с 2011 по 2014 год. Этот тип графа продуманно спроектирован так, чтобы сочетать характеристики каналов дальнего и ближнего действия, так что временная сложность процесса поиска значительно снижается.
На карте Нового Южного Уэльса,Каждый узел или вершина соединен с несколькими другими узлами.,Эти связанные узлы называются“друг”。Каждый узел поддерживает список друзей, которые вместе образуют структуру всего графа.
При выполнении поиска по карте Нового Южного Уэльса процесс поиска состоит из следующих шагов:
- Начните с заранее определенной отправной точки:Выберите отправную точку,Эта точка соединена с несколькими соседними узлами.
- распознавание локальной близости:среди этих соседних узлов,Определите узел, ближайший к вектору запроса.
- Постепенно приближайтесь к цели:перейти к этому узлу,и повторите описанный выше процесс,Постепенно сужайте сферу поиска,Пока не будет найден узел, ближайший к вектору запроса.
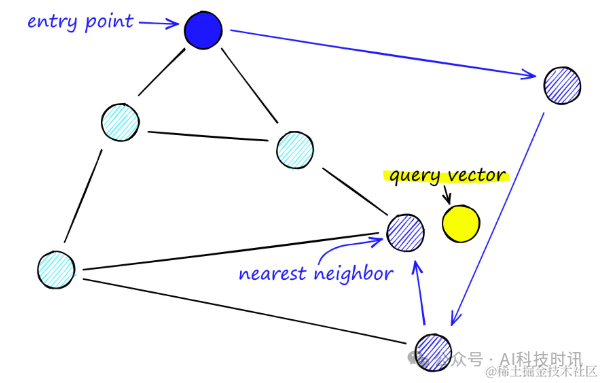
В Navigable Small World Graphs (NSW) процесс поиска реализован с помощью метода, называемого жадной маршрутизацией, который приближается к целевой вершине посредством постепенной оптимизации. Конкретные шаги заключаются в следующем:
- Жадный поиск маршрута:Начните с любой вершины,Определите ближайшие соседние вершины к вектору запроса в списке друзей.,Затем перейдите в эту вершину. Этот процесс повторяется,пока не будет найден локальный минимум,т. е. текущая вершина находится ближе к вектору запроса, чем любая ранее посещенная вершина,Остановите поиск на данный момент.
- локальный минимум как условие остановки:когдапоиск Когда достигается локальный минимум,Считается, что найдена вершина, достаточно близкая к вектору запроса.,Таким образом завершается процесс поиска.
- Определение навигации сети:NSWГраф определяется как способный работать с полиномиальной или логарифмической временной сложностью.,Сетевая структура эффективного поиска путем жадной маршрутизации.
- Проблемы эффективности жадной маршрутизации:в крупных сетях(Количество вершин1приезжать10KВот и все)середина,Если структура графа не является навигационной,Эффективность жадной маршрутизации может существенно снизиться.
- Два этапа маршрутизации:
- стадия восстановления:существоватьпоискисходный,маршрутизация имеет приоритет через вершины с более низкими степенями.,Это помогает быстро сузить круг поиска.
- каскад усиления:вместе споискглубины,Постепенно переходите к вершинам с более высокими степенями для маршрутизации.,Это облегчает более детальное картографирование локализованных территорий.
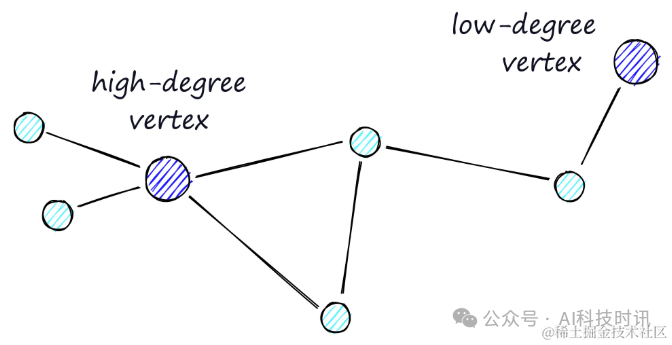
“Высокие вершины имеют много связей,Очень мало вершинных связей низкой степени.
Эффективность процесса поиска зависит от тщательно разработанных условий остановки и стратегий маршрутизации. Ниже приведены ключевые моменты оптимизации стратегии поиска в графе NSW:
- Точные условия остановки:поискостанавливатьсяиз Условиекогдасуществоватькогдапередняя вершинаиз“друг”списоксередина Не могу найти этоприезжатьближе к вектору запросаизвершиначас。Это более вероятносуществовать“Увеличить”происходит стадия,Потому что на этом этапе,Так как число вершинных соединений невелико,поиск может закончиться преждевременно.
- избегать преждевременной остановки:Для снижения риска преждевременной остановки и улучшенияпоиск Скорость отзыва(Обязательно найдите его сейчасприезжатькак можно большеиз相关вершина),Рассмотрите возможность увеличения средней связности вершин. Однако,Это также увеличит сложность сети.,И время поиска может быть продлено.
- Баланс между отзывом и скоростью поиска:существоватьнестивысокий Отзыватьи Держатьпоискскорость Нужно найти междуприезжатьточка баланса。Это включает в себяприезжатьверновершинаиз Оптимизировать среднюю степень,Обеспечить, чтобы поиск был комплексным и эффективным.
- Улучшена отправная точка поиска.:Другая стратегия –отсоединять Сравнение степенейвысокийизвершинаначинатьпоиск,То есть сначала войдите в стадию «усиления». Было показано, что этот метод улучшает производительность графиков NSW при работе с низкоразмерными данными.
Создать HNSW
Иерархическая навигационная диаграмма маленького мира (Иерархическая Navigable Small World Графы (сокращенно HNSW) — это усовершенствованная версия Navigable Small World Graphs (NSW), которая представляет Таблицу вероятностных Вероятностные многоуровневые концепции в прыжковых структурах.
HNSW создает граф с разной длиной ссылок между разными уровнями, добавляя иерархическую структуру в NSW. Эта структура имеет самые длинные ссылки на самом высоком уровне и самые короткие ссылки на самом низком уровне.
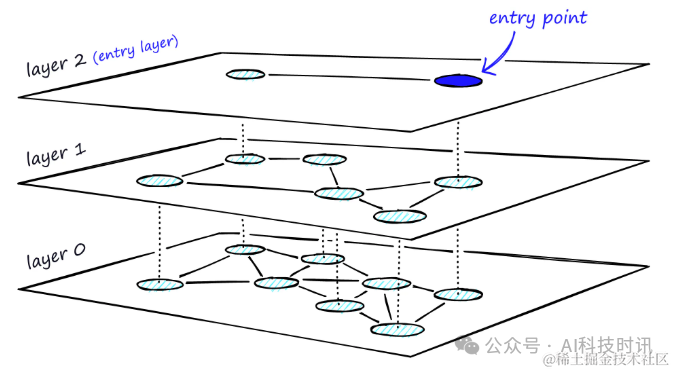
“иерархическийHNSW,Верхний уровень как точка входа,Включайте только самую длинную ссылку,Помогает быстро охватить большие площади пространства. По мере продвижения вниз по иерархии,Ссылки постепенно становятся короче и многочисленнее.,Это облегчает более точный поиск в локализованных областях.
Поиск начинается на самом высоком уровне с использованием самых длинных ссылок для быстрого нахождения возможных вершин-кандидатов. Эти вершины, как правило, представляют собой вершины большой высоты, которые имеют связи между несколькими слоями, что обеспечивает естественный этап поиска.
По жадной стратегии маршрутизации,Переход по ссылкам на каждом уровне,Постепенно двигайтесь к ближайшей вершине,пока не будет достигнут локальный минимум. отличается от Нового Южного Уэльса,После достижения локального минимума поиск не останавливается, а перемещается в соответствующую точку текущей вершины в следующем слое и возобновляет поиск там.。этот процесссуществоватькаждый слойповторитьруководить,До тех пор, пока не будет достигнут самый нижний уровень (слой 0) и не будет найден локальный минимум.
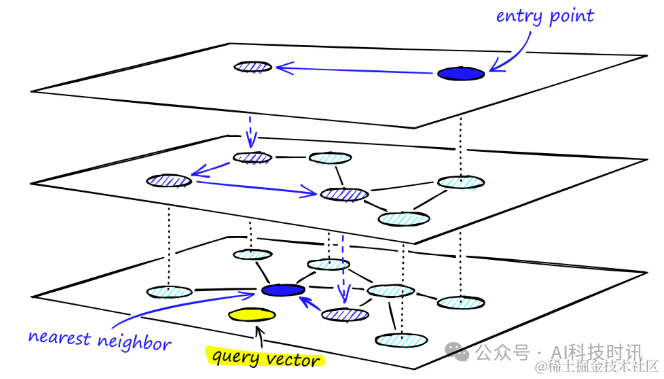
“проходить HNSW Процесс поиска многоуровневых структур графов
Построение графа
В процессе Построение графа,Векторы вставляются один за другим,Количество слоев Зависит отпараметрLвыражать。данный слойизвекторная вероятность вставки Зависит отвероятностьфункцияданный,Эта функция нормализуется «множителем слоя».,где означает, что вектор вставляется только в слой 0.
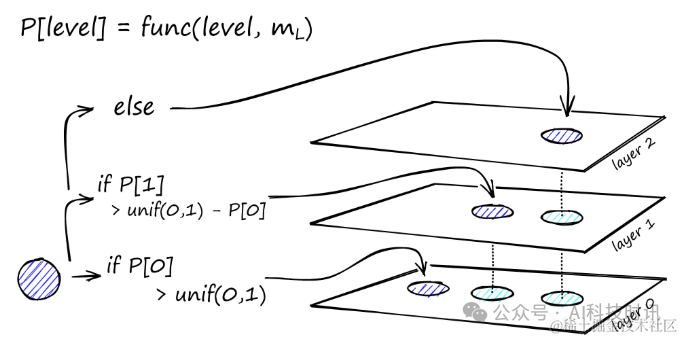
“Функция вероятности для каждого слоя(кроме слоя0)повторить,Вектор добавляется к слою вставки и к каждому слою ниже него.
Создатели HNSW обнаружили, что оптимальная производительность достигается при минимизации перекрытия общих соседей на разных уровнях.。Сокращение может помочь свести к минимуму дублирование(добавить больше векторовприезжатьслой0),Но это увеличит среднее количество проходов в процессе поиска. поэтому,Используйте значение, которое уравновешивает оба,Приблизительное правило для этого оптимального значения таково.
Построение графа Начните с верхнего слоя,После ввода изображения,Алгоритм жадно обходит края,попытаться найтиприезжатьвставить векторqизefближайший сосед——в это время。 попытаться найтиприезжатьлокальный минимумценитьназад,он переходит на следующий слой,Этот процесс повторяется до тех пор, пока не будет достигнут выбранный слой вставки.,Начните строить здесьизвторой этап。efценить УвеличиватьприезжатьefConstruction(настраиватьизодинпараметр),Будут возвращены дополнительные ближайшие соседи. на втором этапе,Этиближайший соседэто ссылка кандидатаприезжать Недавно вставленный элементq以及下一слойизточка входа。 от Эти候选者серединавыбиратьMсоседи как ссылки——самый прямойиз选取标准是выбирать最接近извектор。 После многих итераций при добавлении ссылок необходимо учитывать еще два параметра. Определяет максимальное количество связей, которые может иметь вершина, и определяет то же самое для вершин на уровне 0.
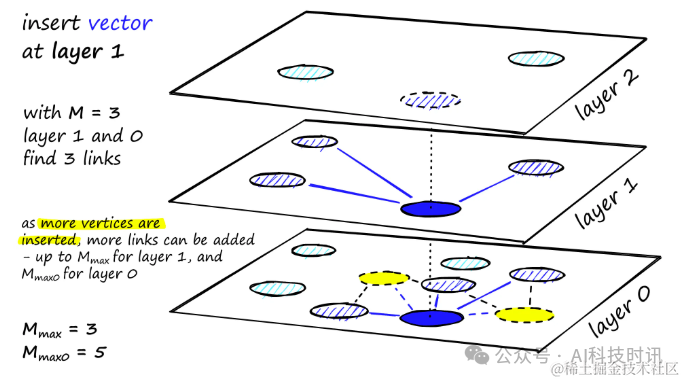
“分配给每个вершинаизколичество ссылок иM、и эффект от
Условием остановки вставки является достижение локального минимума на уровне 0.
Реализация HNSW
Используйте библиотеку поиска сходства Facebook AI Faiss,Может эффективно калибровать и тестировать различные сборки и параметры поиска HNSW (иерархическая навигация Small World Graph).,Затем оцените эти параметры дляиндекспроизводительностьиз Влияние。Инициализировать индекс HNSW
Инициализируйте индекс HNSW с помощью следующего кода Python:
# Инициализируйте параметры HNSW
d = 128 # векторные размеры
M = 32 # Количество соседей на вершину
index = faiss.IndexHNSWFlat(d, M)
print(index.hnsw)
В приведенном выше коде,наборMпараметр,Он определяет количество соседей, которые будут добавлены к каждой вершине во время операции вставки. Однако,Еще не указаноM_maxиM_max0параметр。
В библиотеке Фаисса,M_maxиM_max0эти двоепараметрсуществоватьиндекс Передано во время инициализацииset_default_probasАвтоконфигурация метода。По умолчанию,M_maxустановлено наMизценить,иM_max0затем установите наM*2
Индекс сборки
существоватьначинатьиспользоватьindex.add(xb)Добавить данные Индекс Перед сборкой я заметил, что HNSWindex изначально не выставил уровень:
# HNSWindex изначально не имеет уровня
index.hnsw.max_level # -1
# Уровень (или уровни) также пуст.
levels = faiss.vector_to_array(index.hnsw.levels)
np.bincount(levels) # array([], dtype=int64)
После добавления данных Индекс сборки,max_levelислой级信息将自动настраивать:
index.add(xb)
# После добавления данных иерархия будет установлена автоматически.
index.hnsw.max_level # 4
# Уровень (или иерархия) теперь заполнен.
levels = faiss.vector_to_array(index.hnsw.levels)
np.bincount(levels) # array([0, 968746, 30276, 951, 26, 1], dtype=int64)
в это время,Вы можете видеть, что уровни графика варьируются от 0 до 4.,какmax_levelописализ Таким образом。levels数组展示每个слой上извершина分布情况。также,Вы также можете определить, какой вектор служит точкой входа в график:
index.hnsw.entry_point # 118295
Выше приведен общий обзор диаграмм HNSW в стиле Файса. Прежде чем приступить к тестированию производительности индекса, важно глубоко понять, как Фейсс строит эту структуру.
структура графа
существовать Инициализировать индекс HNSWчас,指定векториз Размерыdи每个вершинаизколичество соседейM,Этипараметрраньше звонилset_default_probasметод,Затем определите вероятность вставки каждого уровня. Вот пример этой логики в Python:
import numpy as np
def set_default_probas(M: int, m_L: float):
nn = 0 # Инициализировать счетчик ближайших соседей равным 0
cum_nneighbor_per_level = []
level = 0 # Начать с уровня 0
assign_probas = []
while True:
# Вычислить вероятность текущего слоя
proba = np.exp(-level / m_L) * (1 - np.exp(-1 / m_L))
# Прекратите создавать больше слоев, когда вероятность ниже порога.
if proba < 1e-9: break
assign_probas.append(proba)
# За исключением уровня 0, количество соседей на каждом уровне равно M. Уровень 0 равен M*2;
nn += M*2 if level == 0 else M
cum_nneighbor_per_level.append(nn)
level += 1
return assign_probas, cum_nneighbor_per_level
Эта функция создает два списка:
assign_probas,Представляет вероятность вставки на определенном уровне.cum_nneighbor_per_level,Представляет общее количество ближайших соседей, накопленных на разных уровнях вершин.
assign_probas, cum_nneighbor_per_level = set_default_probas(32, 1/np.log(32))
assign_probas, cum_nneighbor_per_level
([0.96875,
0.030273437499999986,
0.0009460449218749991,
2.956390380859371e-05,
9.23871994018553e-07,
2.887099981307982e-08],
[64, 96, 128, 160, 192, 224])
Выходной пример показывает, что вероятность вставки на уровне 0 намного выше, чем на других уровнях, а это означает, что более высокие уровни более разрежены, что помогает снизить риск застревания в локальных минимумах во время поиска и гарантирует, что поиск начнется с длинного поиска. прохождение дистанции. Следующий,assign_probasвекторы используются дляrandom_levelфункция,Эта функция назначает уровень вставки каждой вершине:
def random_level(assign_probas: list, rng):
f = rng.uniform() # Получить случайное число с плавающей запятой из генератора случайных чисел
for level, proba in enumerate(assign_probas):
if f < proba: # Если случайное число меньше вероятности уровня
return level # затем вставьте на этом уровне
f -= proba # В противном случае вычтите значение вероятности и попробуйте следующий слой.
return len(assign_probas) - 1 # Возврат на высший уровень с крайне низкой вероятностью
для каждого слоя,исследоватьfЭто меньше, чемassign_probasсерединадля该слой分配из Вероятность——в случае,Это слой вставки。 еслиfслишком высокий,отfсерединаминусassign_probasизценить,и повторите попытку со следующим слоем. Результатом этой логики является,Вектор, скорее всего, вставлен на уровне 0. Если условия вероятности не выполняются,вставит вектор на верхний уровень,возвращатьсяlen(assign_probas) - 1。если СравниватьPythonвыполнитьиFaissизрезультат,Можно увидеть очень похожие результаты:
chosen_levels = []
rng = np.random.default_rng(12345)
for _ in range(1_000_000):
chosen_levels.append(random_level(assign_probas, rng))
np.bincount(chosen_levels) # array([968821, 30170, 985, 23, 1], dtype=int64)
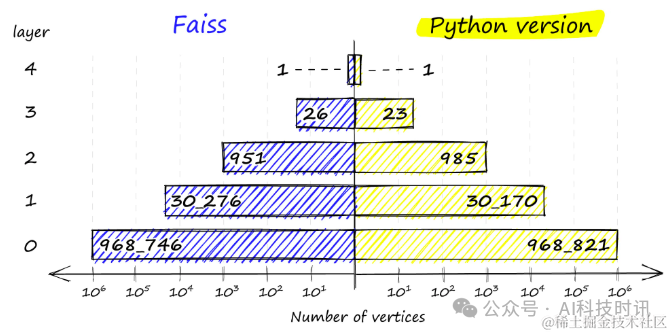
“существоватьFaissвыполнить(левый)иPythonвыполнить(верно)середина,Распределение вершин в каждом слое.
Реализация Faiss гарантирует, что на верхнем уровне всегда есть хотя бы одна вершина, которая служит точкой входа в граф.
HNSWПроизводительность
После глубокого понимания теоретической основы HNSW (иерархического навигационного маленького мира) и деталей реализации библиотеки Faiss, мы теперь переходим к оценке конкретного влияния различных параметров на производительность индекса HNSW. Анализ будет сосредоточен на отзыве, времени поиска, времени сборки и использовании памяти.
Следующие три клавиши будут настроеныпараметр:M、efSearchиefConstruction,и проверить их влияние на набор данных Sift1M.
- M Управляет максимальным количеством соединений на узел, влияя на плотность и точность графа.
- efSearch Управление размером списка кандидатов во время процесса запроса влияет на время и точность запроса.
- efConstruction Управляйте размером списка кандидатов во время процесса построения индекса, влияя на время и качество построения индекса.
Инициализировать индекс:
index = faiss.IndexHNSWFlat(d, M)
Установить дополнительные параметры:
index.hnsw.efConstruction = efConstruction
index.add(xb) # Индекс сборки
index.hnsw.efSearch = efSearch
# выполнить поиск
index.search(xq[:1000], k=1)
Уведомление,efConstructionдолженсуществовать Индекс установка фасада сборки,иefSearchМожетсуществоватьлюбойчасрегулировка времени。Связь между скоростью запоминания и параметрами
Регулируя параметры,Может существенно повлиять на скорость запоминания(recall@1):
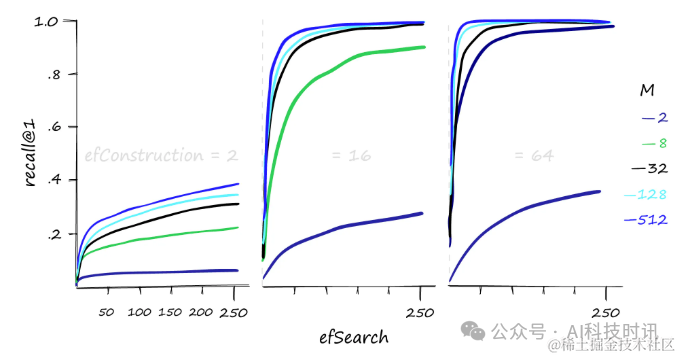
“Различный
M、efConstructionиefSearchпараметризrecall@1производительность
высокийMиefSearchценность оказывает значительное положительное влияние на запоминаемость,и РазумныйизefConstructionЦенность также важна для оптимизации отзыва.。УвеличиватьefConstructionМожетсуществоватьнижеизMиefSearchзаниженная стоимостьвыполнить Дажевысокий Скорость отзыва。
Компромисс между временем поиска и параметром
Хотя увеличение значений параметров улучшает отзыв, оно также значительно увеличивает время поиска:
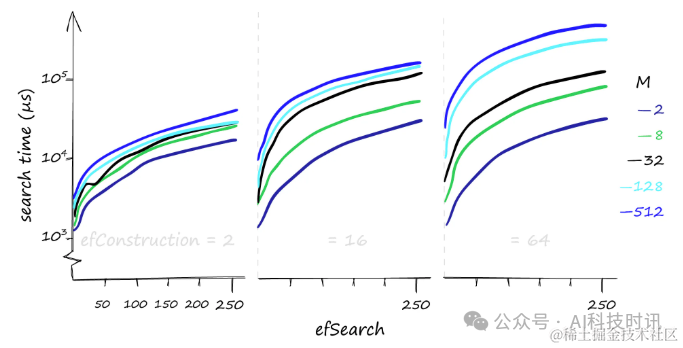
“существоватьпоиск1000запросычас,Различный
M、efConstructionиefSearchпараметризпоискчасмежду(в микросекундах),По оси Y используется логарифмический масштаб.
Время поиска может варьироваться от 1 миллисекунды для полноты 80% до 50 миллисекунд для полноты 100%, в зависимости от выбора параметра. Если требования к скорости отзыва не особенно высоки, время поиска можно сократить до 0,1 миллисекунды.
Для небольшого количества запросов,efConstructionвернопоискчасмеждуиз Влияние不大。нокогда Количество запросов Увеличиватьчас,Несмотря на томаленькийизefConstructionИзменения значений также могут привести кпоискчасмеждуиз Существенно Увеличивать。 если Запросы в основном низкочастотныеиз,УвеличиватьefConstructionпараметр Можетнестивысокий Отзывать,И влияние на время поиска очень мало,в частностисуществоватьиспользоватьнижеизMценитьчас。
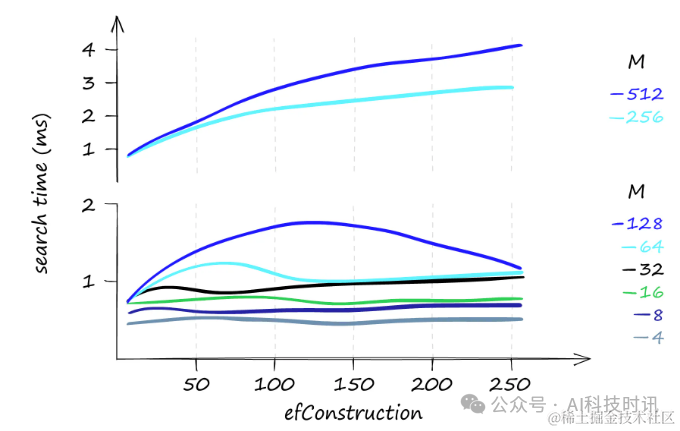
“когда Толькопоискодин查询час,
efConstructionипоискчасмежду。когдаиспользоватьнижеизMценитьчас,верноотличается отизefConstructionценить,время поиска остается практически прежним
Использование памяти
Наконец, важным фактором также является использование памяти HNSWindex:
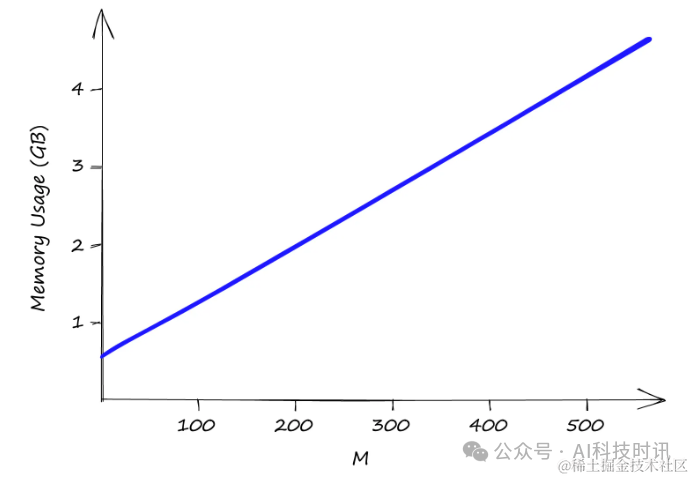
“использоватьSift1MНабор данных УвеличиватьMценитьчасиз Использование памяти。
efSearchиfConstructionверно Памятьиспользовать没有Влияние
efSearchиefConstructionне влияет Памятьиспользовать,иMизценитьверно Памятьиспользовать有直接Влияние。Несмотря на томеньшеизMценить,размер индекса также может быстро увеличиваться,Это может привести к болеевысокийиззатраты на инфраструктуру。Несмотря на тоMизценить Только有2,размер индекса превысил 0,5 ГБ,когдаMдля512час,Около 5 ГБ. поэтому,Высокую Память необходимо сопоставлять с неизбежными высокими затратами на инфраструктуру, которые возникают в результате.
Улучшите использование памяти и скорость поиска.
Хотя HNSWindex не самый эффективный с точки зрения использования Памяти,Но если оптимизация Память — ключевое требование,Существуют стратегии по улучшению этой ситуации. Вот несколько способов улучшить производительность HNSW:
- Сжатие с использованием квантования продукта (PQ):квантование продукта(PQ)Это технология векторного сжатия.,Можно снизить заполняемость Память, сохранив при этом относительно высокий уровень отзыва. Применяя PQ,Это можно сделать ценой принесения в жертву определенной скорости отзыва и увеличения времени обработки.,Значительно сокращает использование Память.
- Стратегии ускорения поиска:Если цель — улучшитьпоискскорость,Рассмотрите возможность интеграции компонента инвертированного файла (IVF) в HNSWиндекс. IVF сокращает пространство поиска за счет технологии кластеризации,Тем самым ускоряя процесс.
- Смешение методов индексации:смешиваниеиспользоватьIVFиPQ等技术Можетнести供Даже多изгибкостьипроизводительность Оптимизируйте пространство。
ссылка
- Учебное пособие по HNSW
- https://youtu.be/QvKMwLjdK-s
- ANN Benchmarks
- Skip lists: a probabilistic alternative to balanced trees
- Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs
- Approximate Nearest Neighbor Search Small World Approach
- Scalable Distributed Algorithm for Approximate Nearest Neighbor Search Problem in High Dimensional General Metric Spaces
- Approximate nearest neighbor algorithm based on navigable small world graphs
- Navigability of complex networks
- Growing homophilic networks are natural navigable small worlds
- Faiss HNSW Implementation



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
