[Учитель Чжао Юцян] Интегрированная потоковая и пакетная архитектура на основе Flink

Поскольку Flink объединяет пакетные вычисления и потоковые вычисления, вы можете использовать Flink для построения интегрированной системной архитектуры потоково-пакетной обработки, которая в основном включает в себя интегрированную архитектуру потоково-пакетной интеграции данных, интегрированную поточно-пакетную архитектуру архитектуры хранилища данных и потоково-пакетная интегрированная архитектура озера данных.
1. Интегрированная поточно-пакетная архитектура интеграции данных.
В сценариях с большими данными часто требуется синхронизация или интеграция данных, то есть синхронизация данных в базе данных с хранилищем больших данных или другим хранилищем. Левая часть рисунка ниже представляет собой одну из традиционных классических моделей интеграции данных. Полная синхронизация и инкрементная синхронизация на самом деле представляют собой два набора технологий. Данные полной синхронизации и данные инкрементной синхронизации необходимо регулярно объединять и непрерывно выполнять итерацию. хранилище данных.
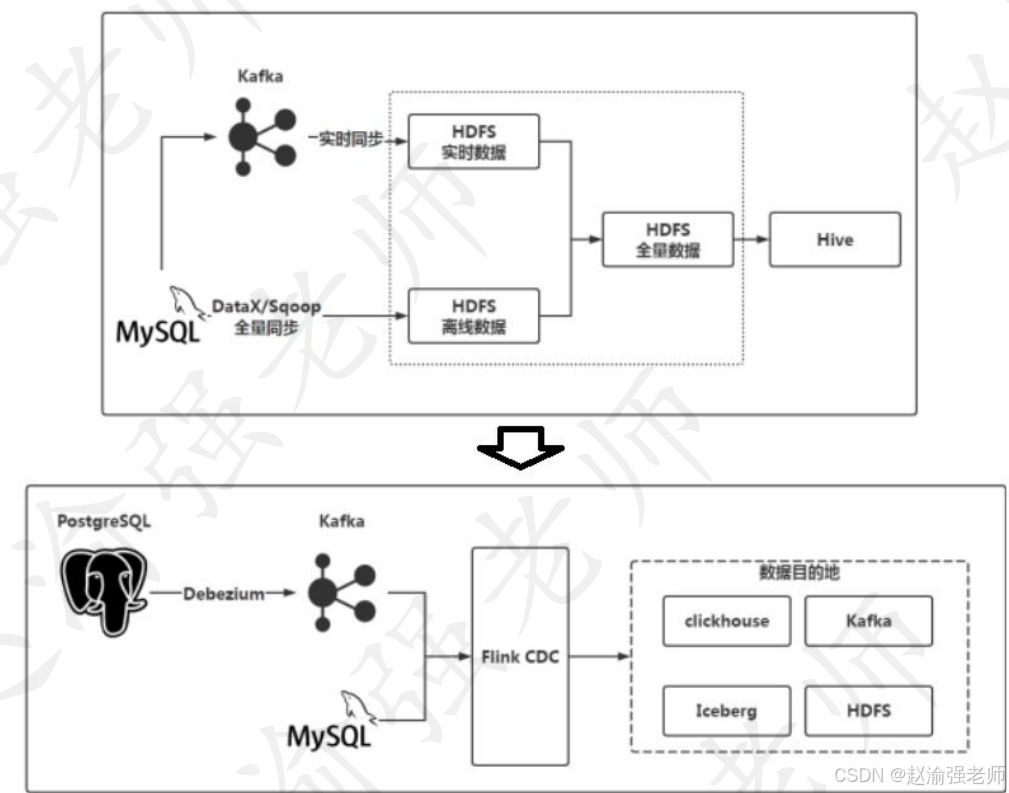
Вся архитектура интеграции данных, основанная на потоковой и пакетной интеграции Flink, будет другой. Поскольку Flink SQL также поддерживает семантику базы данных CDC, вы можете использовать Flink SQL для синхронизации данных базы данных с базами данных с открытым исходным кодом, такими как Hive, Click House и TiDB, или хранилищем KV с открытым исходным кодом одним щелчком мыши. Основанный на интегрированной потоковой пакетной архитектуре Flink, Flink CDC также представляет собой гибрид потоковой и пакетной обработки. Он может сначала считывать все данные базы данных и синхронизировать их с хранилищем данных, а затем автоматически переключаться в инкрементный режим. Flink CDC считывает журналы базы данных для инкрементной и полной синхронизации, а Flink может автоматически координировать свои действия внутри компании. В этом ценность потоковой и пакетной интеграции.
Видеообъяснение следующее:
2. Интегрированная поточно-пакетная архитектура архитектуры хранилища данных.
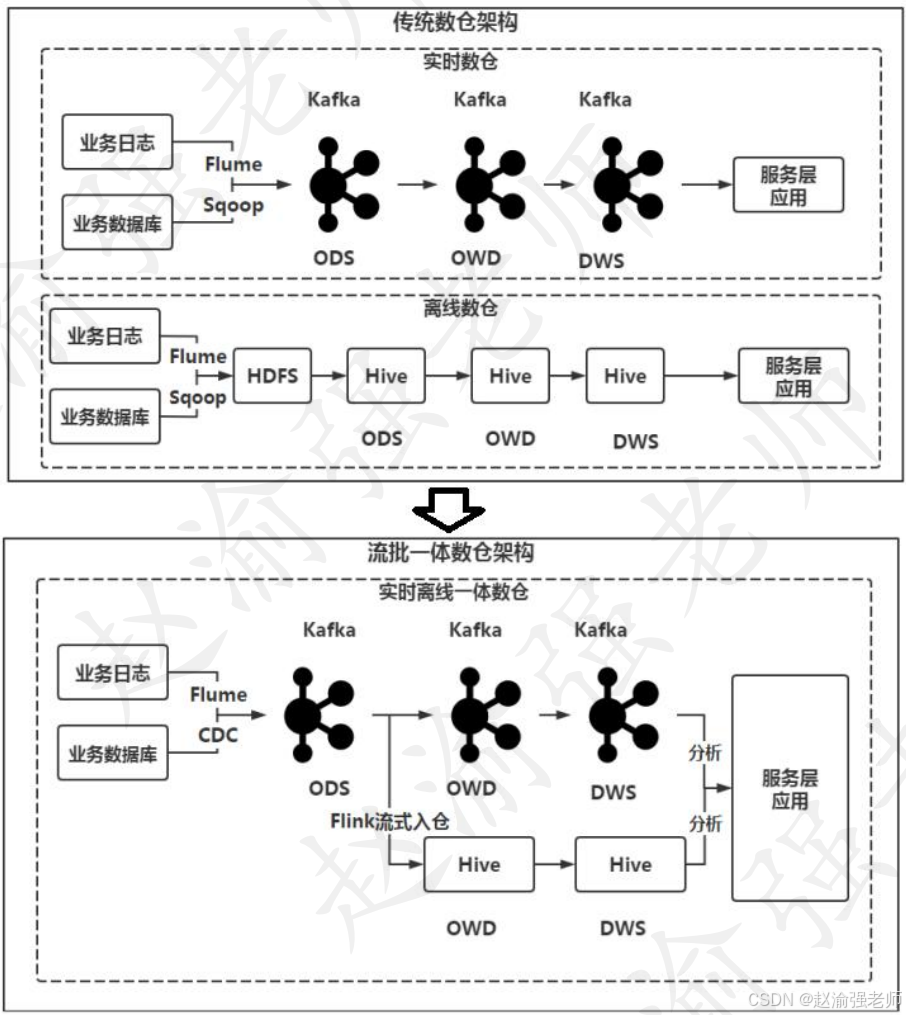
&emspТекущая архитектура основного хранилища данных представляет собой набор типичных автономных хранилищ данных и новый набор хранилищ данных реального времени.,Но эти два стека технологий различны. В автономном хранилище данных,Все еще привык к этому Hive или Spark используется в хранилище данных в реальном времени; Флинк и Кафка. Здесь необходимо решить три проблемы: два набора процессов разработки, высокие затраты; избыточность каналов передачи данных, два набора каналов выполняют операции, связанные с данными, трудно гарантировать согласованность калибра данных, поскольку они состоят из; два комплекта Двигатель разбирается. Использование интегрированной архитектуры потоковой передачи для решения вышеуказанных проблем будет значительно сокращено, а ее преимущества заключаются в следующем:
- Прежде всего, Flink — это набор спецификаций разработки, и не существует двух наборов затрат на разработку. Команда разработчиков и стек технологий могут решить все проблемы бизнес-статистики в автономном режиме и в реальном времени.
- Во-вторых, в канале передачи данных нет избыточности. Его можно рассчитать один раз, и его не нужно рассчитывать повторно в автономном режиме.
- В-третьих, калибр данных естественно согласован. Независимо от того, является ли это автономным процессом или процессом в реальном времени, это набор механизмов, набор SQL, набор UDF и набор разработчиков, поэтому он естественно согласован, и нет проблемы несогласованности между калибры данных в реальном времени и в автономном режиме.
Интегрированная потоково-пакетная архитектура хранилища данных показана на рисунке ниже.
Видеообъяснение следующее:
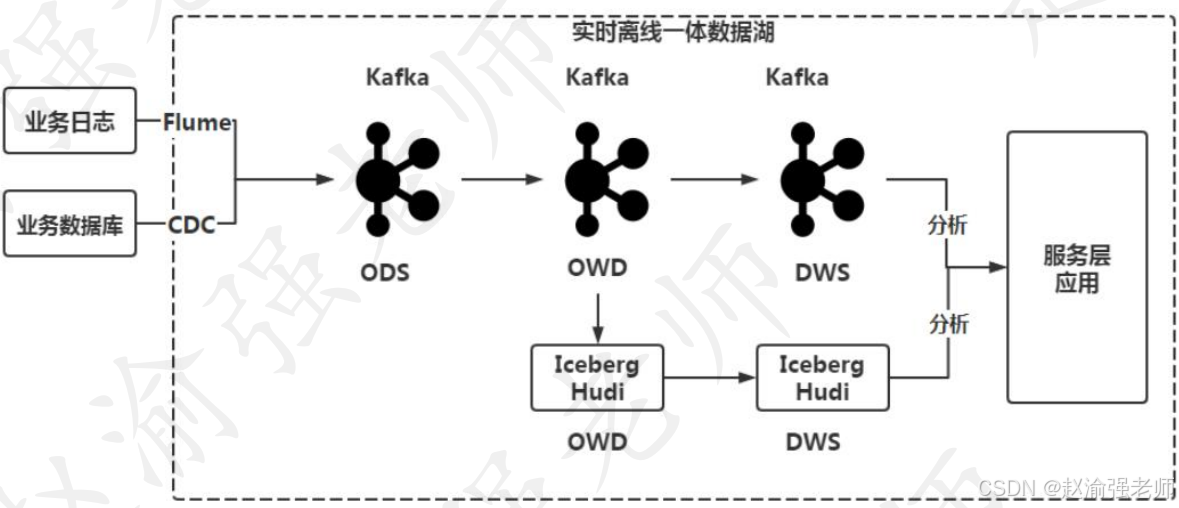
3. Интеграция потоковой передачи и пакетной обработки озера данных.
Управление метаданными Hive является узким местом производительности,В то же время Hive не поддерживает обновление данных в реальном времени. У Hive нет возможностей обработки данных, которые не могут обеспечить режим реального или квазиреального времени. Текущая относительно новая архитектура озера данных,Может решить проблему более масштабируемых метаданных,А хранилище озера данных поддерживает обновления данных.,Это интегрированное потоково-пакетное хранилище. Хранилище озера данных в сочетании с Flink,Интегрированная архитектура хранилища данных, работающая в режиме реального времени и в автономном режиме, может быть преобразована в интегрированную архитектуру озера данных, работающую в режиме реального времени и в автономном режиме. Интегрированная потоково-пакетная архитектура озера данных показана на рисунке ниже.
Видеообъяснение следующее:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
