[Учитель Чжао Юцян] Архитектура платформы, основанная на компонентах больших данных

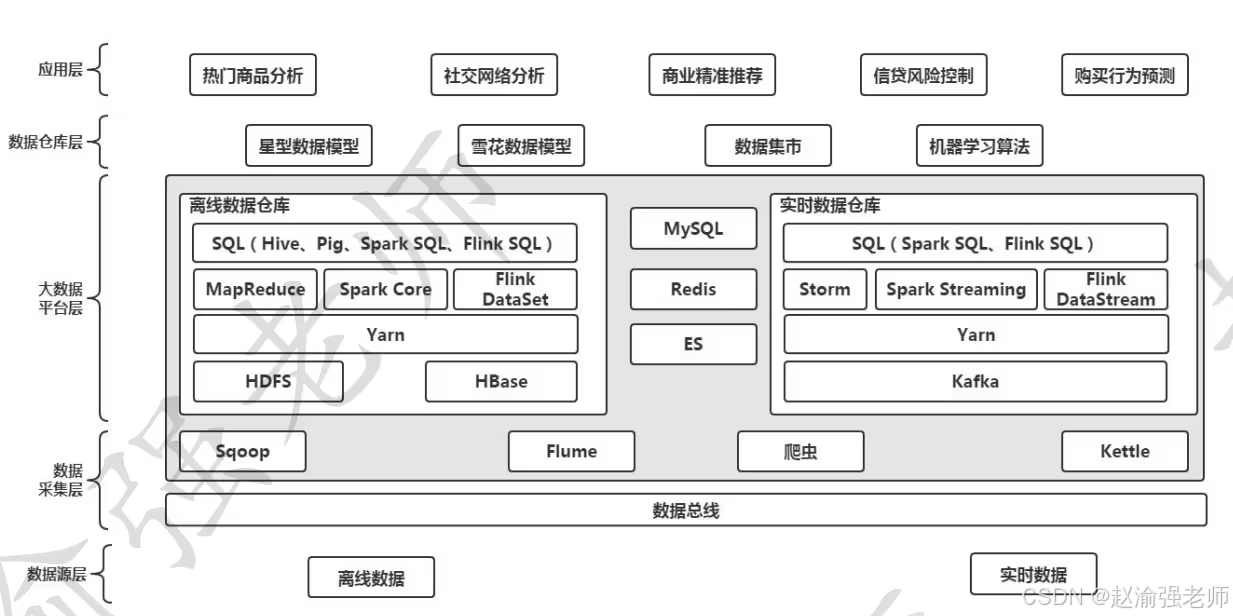
Поняв компоненты и функциональные характеристики, включенные в каждую экосистему больших данных, вы можете использовать эти компоненты для создания платформы больших данных для хранения и расчета данных. На рисунке ниже показана общая архитектура платформы больших данных.
Видео объяснение следующее:
Общую архитектуру платформы больших данных можно разделить на пять уровней: уровень источника данных, уровень сбора данных, уровень платформы больших данных, уровень хранилища данных и уровень приложений.
1. Уровень источника данных
Основная функция уровня источника данных — предоставление различных необходимых бизнес-данных, таких как данные пользовательских заказов, данные транзакций, данные системного журнала и т. д. Короче говоря, все данные, которые могут быть предоставлены, можно назвать источниками данных. Хотя существуют различные типы источников данных, их можно разделить на две основные категории в системе платформы больших данных, а именно: автономные источники данных и источники данных в реальном времени. Как следует из названия, автономные источники данных используются в автономных вычислениях больших данных, а источники данных в реальном времени используются в вычислениях больших данных в реальном времени.
2. Уровень сбора данных
Имея данные из базового источника данных, вам необходимо использовать инструменты ETL для завершения сбора, преобразования и загрузки данных. Такие компоненты предусмотрены в системе Hadoop. Например, вы можете использовать Sqoop для завершения обмена данными между платформой больших данных и реляционной базой данных, используя Flume для завершения сбора данных журнала; Помимо компонентов, предоставляемых самой системой платформы больших данных, типичным методом сбора данных также являются сканеры. Конечно, вы также можете использовать сторонние инструменты сбора данных, такие как DataX и CDC, для завершения работы по сбору данных.
Чтобы решить проблему связи между уровнем источника данных и уровнем сбора данных, между этими двумя уровнями можно добавить шину данных. Шина данных не обязательна. Она введена только для уменьшения связи между уровнями при проектировании архитектуры системы.
3. Уровень платформы больших данных
Это базовый уровень всей системы больших данных, который используется для хранения больших данных и вычислений с большими данными. Поскольку платформу больших данных можно рассматривать как метод реализации хранилища данных, ее можно разделить на автономное хранилище данных и хранилище данных в реальном времени. Они представлены отдельно ниже.
- Реализация автономного хранилища данных на основе технологии больших данных
После того как базовый уровень сбора данных получит данные, их обычно можно сохранить в HDFS или HBase. Затем автономные вычислительные механизмы, такие как MapReduce, Spark Core и Flink DataSet, завершают анализ и обработку автономных данных. Чтобы иметь возможность единообразно управлять и планировать различные вычислительные механизмы на платформе, эти вычислительные механизмы можно запускать на Yarn, а затем использовать программы Java или Scala для выполнения анализа и обработки данных; Чтобы упростить разработку приложений, система платформы больших данных также поддерживает использование операторов SQL для обработки данных, то есть предоставляются различные механизмы анализа данных, такие как Hive в системе Hadoop, а его поведение по умолчанию — Hive на MapReduce. Таким образом, стандартный SQL можно написать в Hive, а движок Hive преобразует его в MapReduce, а затем запускает в Yarn для обработки больших данных. Помимо Hive, распространенные механизмы анализа больших данных включают Spark SQL и Flink SQL.
- Реализация хранилища данных в режиме реального времени на основе технологии больших данных
После того, как базовый уровень сбора данных получает данные в реальном времени, чтобы сохранить данные и обеспечить их надежность, собранные данные могут быть сохранены в системе обмена сообщениями Kafka, а затем использованы различными вычислительными механизмами реального времени, такими как; как Storm, Spark Stream и Flink DataStream для обработки. Как и автономные хранилища данных, эти вычислительные механизмы могут работать на Yarn и поддерживать операторы SQL для обработки данных в реальном времени.
В процессе реализации автономного хранилища данных и хранилища данных в реальном времени могут использоваться некоторые общие компоненты, такие как использование MySQL для хранения метаинформации, использование Redis для кэширования, включая использование ElasticSearch (сокращенно ES) для завершения поиска данных. и т. д.
4. Уровень хранилища данных
При поддержке уровня платформы больших данных можно дополнительно построить уровень хранилища данных. При построении модели хранилища данных ее можно построить на основе модели звезды или модели снежинки. Витрины данных и алгоритмы машинного обучения, упомянутые ранее, также можно отнести к этому уровню.
5. Прикладной уровень
Благодаря различным моделям данных и данным на уровне хранилища данных на основе этих моделей и данных можно реализовать различные сценарии приложений. Например: анализ популярных продуктов в электронной коммерции, анализ социальных сетей в графовых вычислениях, внедрение рекомендательных систем, контроль рисков, прогнозирование поведения и т. д.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
