[Учитель Чжао Юйцян] RDD в Искре

RDD (Resilient Distributed Dataset) — устойчивый распределенный набор данных. Это самая базовая и важная модель данных в Spark. Он состоит из разделов, и каждый раздел обрабатывается подчиненным узлом Spark Worker, тем самым поддерживая распределенные параллельные вычисления. RDD обеспечивает автоматическую отказоустойчивость посредством контрольных точек, а также имеет функции планирования и масштабирования с учетом местоположения. RDD также предоставляет механизм кэширования, который может значительно повысить скорость обработки данных.
Видеообъяснение следующее:
1. Состав РДД
В примере WordCount каждый шаг генерирует новый RDD для сохранения результатов этого шага. Вы также можете создать RDD следующим образом:
scala> val myrdd = sc.parallelize(Array(1,2,3,4,5,6,7,8),2)Эта строка кода создает коллекцию RDD с именем myrdd, которая содержит массив, и этот RDD состоит из двух разделов. Вы можете проверить длину разделов, просмотрев оператор разделов RDD.
scala> myrdd.partitions.length
res0: Int = 2Какова же связь между RDD, разделом и рабочим узлом? Здесь мы возьмем только что созданный myrdd в качестве примера, чтобы проиллюстрировать взаимосвязь между ними, как показано на рисунке ниже.
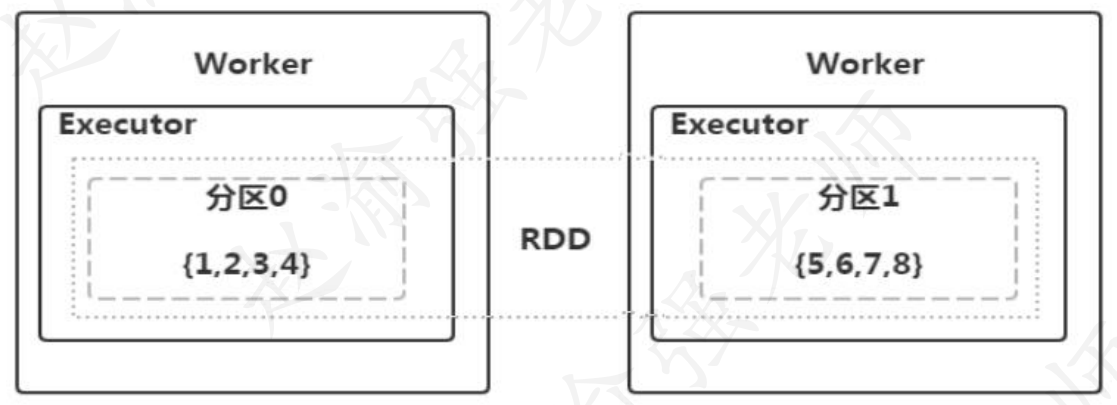
На рисунке предполагается, что имеется два рабочих подчиненных узла. myrdd содержит два раздела, каждый раздел будет иметь номер раздела, а номер раздела начинается с нуля. На рисунке 9.9 мы видим, что данные в разделе 0 обрабатываются на первом Worker, то есть: {1,2,3,4}, а данные в разделе 1 обрабатываются на втором Worker, то есть: {; 5,6,7,8}.
Совет: Под разделом можно понимать физическое понятие, а данные в нем обрабатываются задачами, выполняемыми Исполнителем на Worker. Крайний пунктирный прямоугольник представляет собой RDD. Видно, что на самом деле это логическая концепция.
2. Характеристики РДР
После понимания базовой концепции RDD, какими характеристиками обладает RDD? Исходный код Spark RDD объясняет характеристики RDD следующим образом.
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)Из этого комментария вы можете понять, что RDD имеет следующие пять основных характеристик:
- Состоит из набора перегородок
Для RDD каждый раздел будет обрабатываться вычислительной задачей и определяет степень детализации параллельных вычислений. Пользователи могут указать количество сегментов RDD при создании RDD. Если не указано, будет использоваться значение по умолчанию. Значением по умолчанию является количество ядер ЦП, выделенных программе.
- Функция, которая вычисляет каждый раздел
Расчет RDD в Spark основан на разделах. Каждый RDD должен реализовать функцию вычисления для достижения цели обработки данных.
- Зависимости между RDD
Программный код WordCount можно дизассемблировать и выполнить за один шаг. Во время каждого преобразования можно определить новый RDD для сохранения результатов этого шага, как показано ниже.
scala> val rdd1 = sc.textFile("hdfs://bigdata111:9000/input/data.txt")
scala> val rdd2 = rdd1.flatMap(_.split(" "))
scala> val rdd3 = rdd2.map((_,1))
scala> val rdd4 = rdd3.reduceByKey(_+_)
scala> rdd4.saveAsTextFile("hdfs://bigdata111:9000/output/spark/wc")Всего здесь определены 4 RDD, а именно: rdd1, rdd2, rdd3 и rdd4, среди которых: rdd4 зависит от rdd3, rdd3 зависит от rdd2 и rdd2 зависит от rdd1. По различным зависимостям этапы выполнения задачи могут быть разделены для поддержки механизма отказоустойчивости контрольных точек.
Совет: Если данные определенного раздела теряются во время расчета, Spark может выполнить пересчет с помощью этой зависимости вместо пересчета всех разделов RDD.
- разделитель
Partitioner — это функция разделения Spark RDD. Внутри Spark реализованы два типа функций секционирования: один — HashPartitioner, основанный на алгоритме хеширования, другой — RangePartitioner, основанный на диапазоне; Пользовательские функции разделов также могут быть реализованы путем наследования Partitioner. Функция разделения не только определяет количество разделов в самом RDD, но также определяет количество разделов в выводе RDD Shuffle.
- Список, в котором хранятся предпочтительные места для чтения каждого раздела.
На основе информации в этом списке Spark будет распределять вычислительные задачи как можно больше по местам хранения блоков данных, которые ему необходимо обработать при планировании задач, что может повысить эффективность обработки данных.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
