Учебное пособие включено | GPT-SoVITS, модель клонирования тембра, может клонировать 95% похожий голос всего за 5 секунд.

Редактор: xixi, Ли Баочжу
Основатель РВК открыл открытый исходный код GPT-SoVITS, проекта клонирования тембра. Вам нужно всего лишь предоставить 5-секундный образец голоса, чтобы получить клонированный голос со сходством от 80% до 95%.
«Голос» — это «технология раннего образования», позволяющая людям вступить в контакт с ИИ. Это также одна из первых технологий ИИ, вышедшая из лабораторий и проникшая в тысячи домохозяйств. Первоначально исследования интеллектуальной речи в основном были сосредоточены на распознавании речи, то есть на том, чтобы заставить машины понимать человеческий язык.
Самая ранняя компьютерная система распознавания речи была разработана AT&T Разработано Bell Laboratories Одри, способная идентифицировать 10 Английские цифры. 1988 год В 2016 году Кай-Фу Ли реализовал первую систему распознавания речи с большим словарным запасом, основанную на скрытых марковских моделях. Sphinx。1997 Первая в мире система непрерывной голосовой диктовки для потребителей Dragon NaturallySpeaking Официально выпущен. 2009 год В 2016 году Майкрософт Windows 7 Голосовые функции интегрированы в операционную систему.
2011 год, знаковый продукт iPhone 4S Разместил: Сири Рождение умного голоса вывело интеллектуальный голос от распознавания на новый этап «взаимодействия».тот же год,Google объявляет о начале внутреннего тестирования Google Ищите и в ближайшие дни будет в Google.com Голосовой поиск запущен на .
Переход от слушания к разговору также является важным краеугольным камнем для процветания и развития взаимодействия человека и компьютера. В настоящее время, от умных домов до умного вождения и роботов, голосовое взаимодействие стало более плавным благодаря постоянному обновлению искусственного интеллекта, и различные приложения процветают. С технической стороны крупные поставщики облачных вычислений открыли исходные коды своих голосовых возможностей искусственного интеллекта в виде API-интерфейсов, что позволяет разработчикам в дальнейшем создавать приложения на их основе.
В последние годы, поскольку большие модели продолжают пользоваться популярностью, возможности открытого исходного кода непосредственно на уровне модели привлекают все больше внимания. Разработчики могут еще больше улучшить эффект развертывания между моделью и разрабатываемыми ею приложениями путем обучения и тонкой настройки модели. .
не так давно,RVC (Retrieval based Voice Conversion) Основатель (GitHub Аккаунт: РВК-Босс) выложил в открытый доступ проект клонирования звука GPT-SoVITS,Он приобрел большую популярность после запуска в Интернете.,Многие блогеры и разработчики используют звуки популярных героев кино и телевидения, а также героев аниме.,Индивидуальные линии для различных типов парусников.,Эффект ловли лошадей и простота управления,Это также заставило группу пользователей сети прийти, услышав эту новость.,Еще раз подливая масла в огонь своей популярности. По тесту крупных блогов,Просто предоставьте 5 За несколько секунд после прослушивания образца голоса вы можете получить подобие 80%~95% клонированный голос.
В настоящее время руководство по развертыванию модели доступно на официальном сайте HyperAI. Нажмите, чтобы начать клонирование:
https://hyper.ai/tutorials/29812
Редактор попросил оригинального персонажа-бога Паймэн сыграть эпизодическую роль королевы в «Легенде о Чжэнь Хуане» ↓
Учебное пособие по клонированию звука AI, созданное Джеком-Кюи, популярным мастером Station B, выглядит следующим образом:
Пошаговое руководство выглядит следующим образом. Подготовьте 5 секунд речи, чтобы начать обучение модели клонирования голоса!
Подготовка данных
В настоящее время в этом руководстве задано несколько классических звуков персонажей, которые каждый может испытать. Если вы хотите клонировать другие звуки, вам необходимо подготовить аудиофайл со звуком в формате MP3, предпочтительно один человеческий голос (около 30 секунд). Аудиофайлы высокого качества могут повысить реалистичность клонированных звуков.
1. Нажмите «Запустить это руководство онлайн», чтобы перейти на платформу OpenBayes.
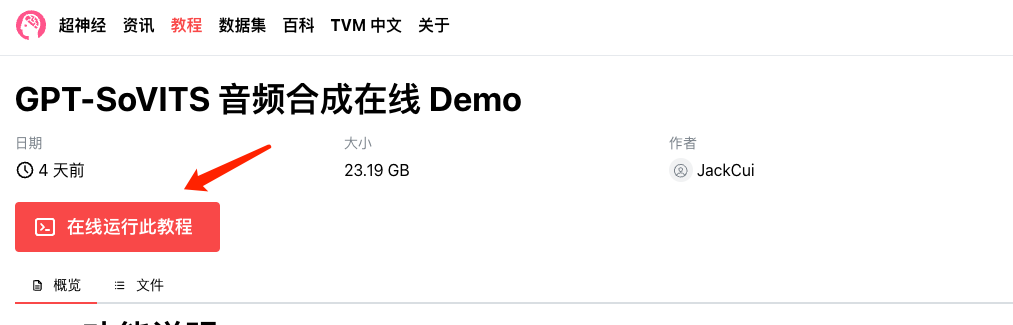
2. Нажмите «Клонировать», чтобы клонировать модель. (На этом этапе можно услышать только звуки, загруженные Джеком-Кюи, мастером станции B)
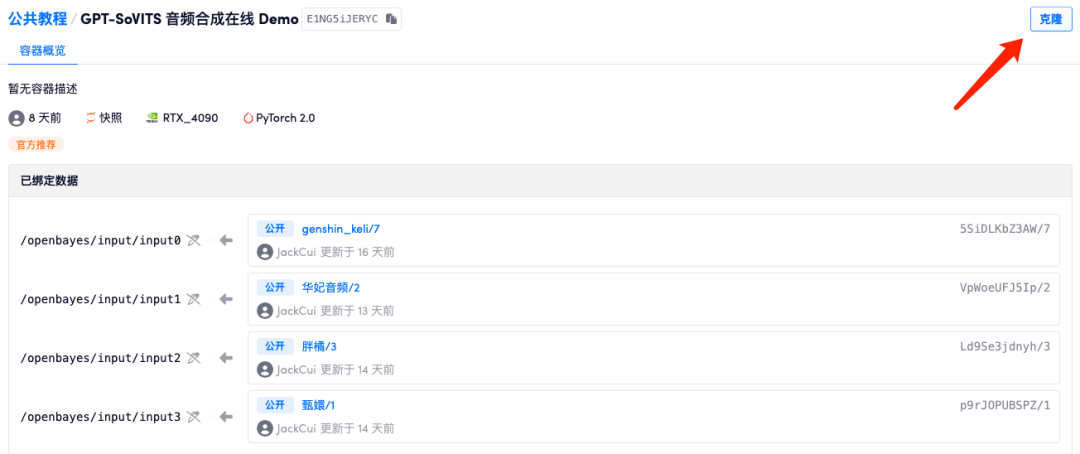
3. Если вы хотите настроить клонированный звук, вам необходимо создать новый набор данных. После перехода «Наборы данных» в левой строке меню нажмите «Создать новый набор данных».
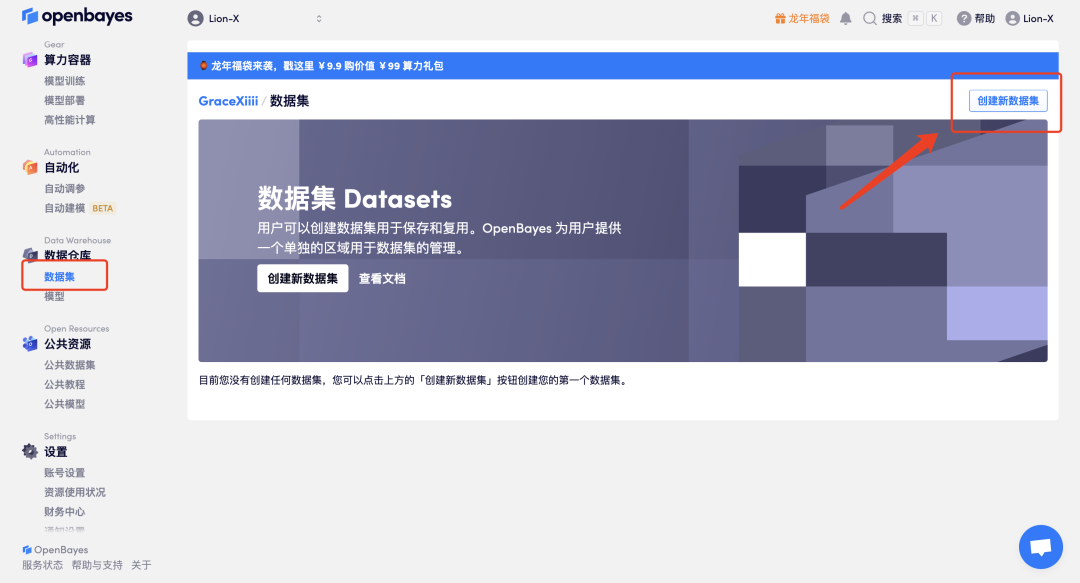
4. Заполните «Имя набора данных» и «Описание набора данных» по мере необходимости и нажмите «Создать набор данных».

5. После завершения создания нажмите «Загрузить новую версию» в правом верхнем углу, чтобы загрузить аудиофайл, который вы хотите клонировать.

Демо-запуск
1. Подготовка После заполнения данных, в левой строке меню «Общественное Учебное». пособие», открываем «ГПТ-СОВИТС» Синтез аудио онлайн Демо», вернитесь на страницу руководства и нажмите «Клонировать» в правом верхнем углу, чтобы клонировать руководство в свой собственный контейнер.
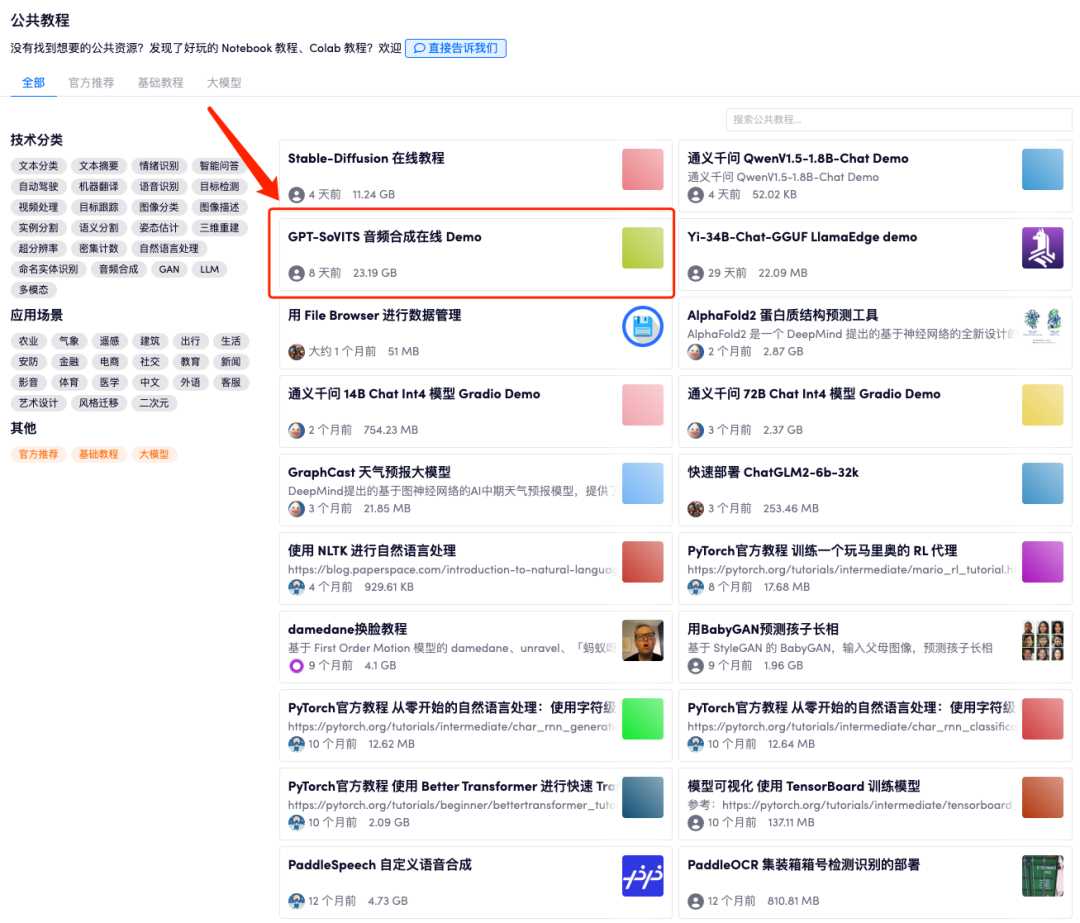
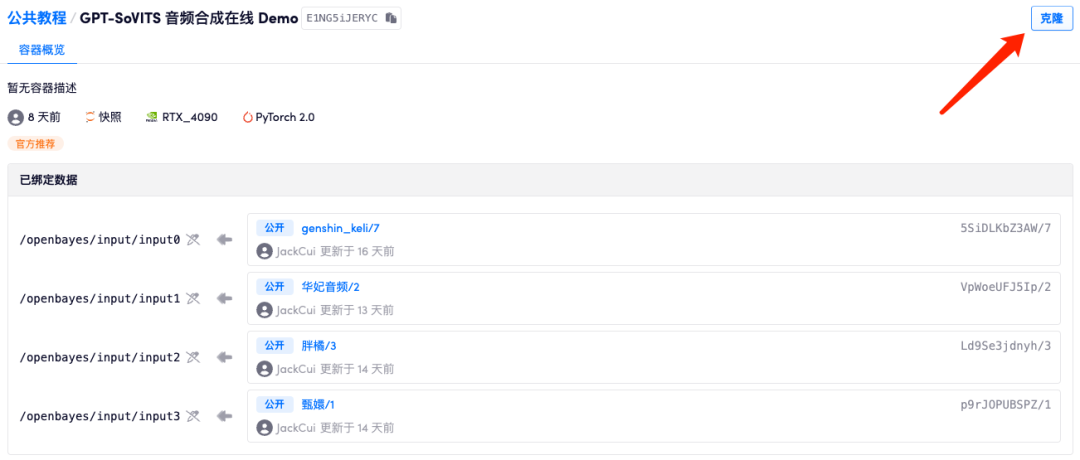
2. В настоящее время демо-версия привязана к аудиоданным Кели, Хуа Фей, Чжэнь Хуаня и Fat Orange. Объем привязанных данных в настоящее время заполнен. Вы можете удалить ненужные аудиоданные и добавить собственный созданный набор данных.
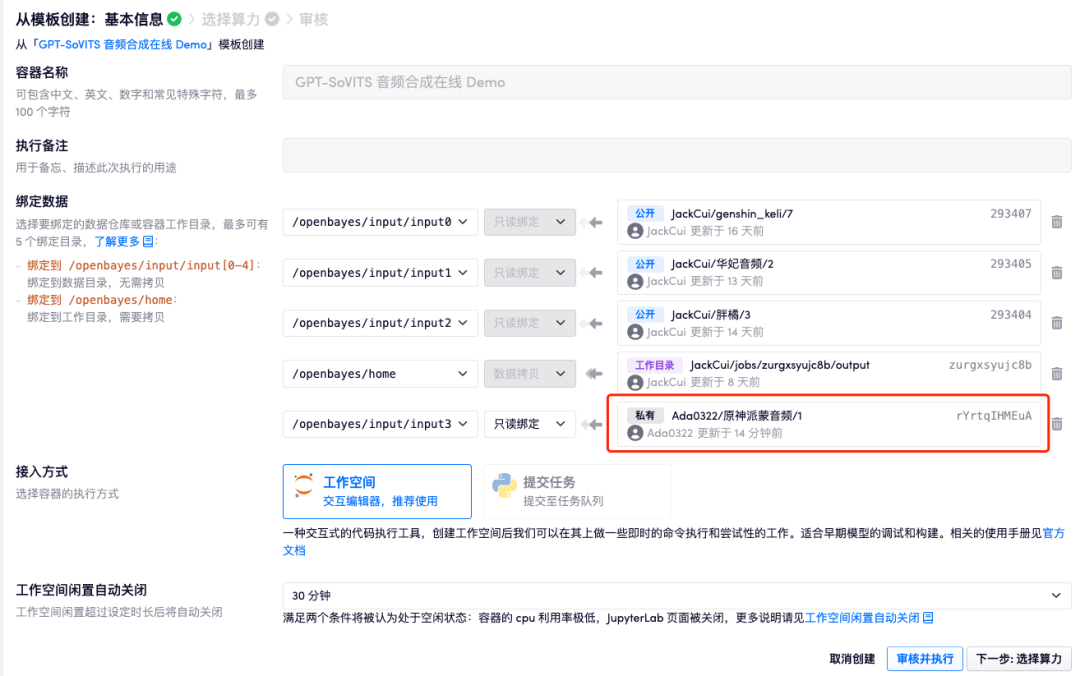
3. После завершения добавления нажмите «Проверить и выполнить».
4. После перехода на страницу нажмите «Продолжить». Рекомендуется RTX 4090.
Редактор обеспечил новые пользовательские преимущества для всех! Новые пользователи, которые зарегистрируются по ссылке-приглашению ниже, могут получить 4 часа RTX 4090 + 5 часов бесплатного вычислительного времени на процессоре.
Эксклюзивная ссылка-приглашение HyperAI Super Neuron (скопируйте ее прямо в браузер и откройте для регистрации):
https://openbayes.com/console/signup?r=Ada0322_QZy7
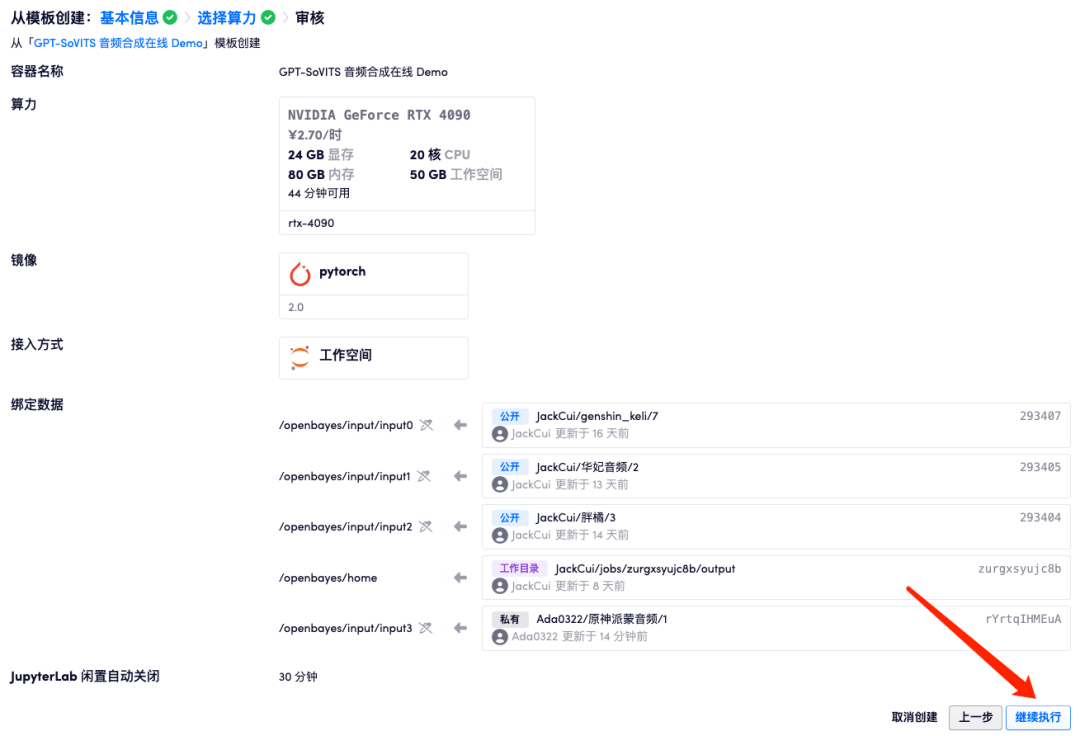
5. Подождите немного, пока статус не изменится на «Выполняется», затем нажмите «Открыть рабочую область». Клонирование и первый запуск контейнера занимает около 3-5 минут. Если он все еще находится в состоянии «Выделение ресурсов» более 10 минут, вы можете попытаться остановить и перезапустить контейнер. Если перезапуск по-прежнему не помогает. проблема, пожалуйста, свяжитесь со службой поддержки клиентов платформы на официальном сайте.
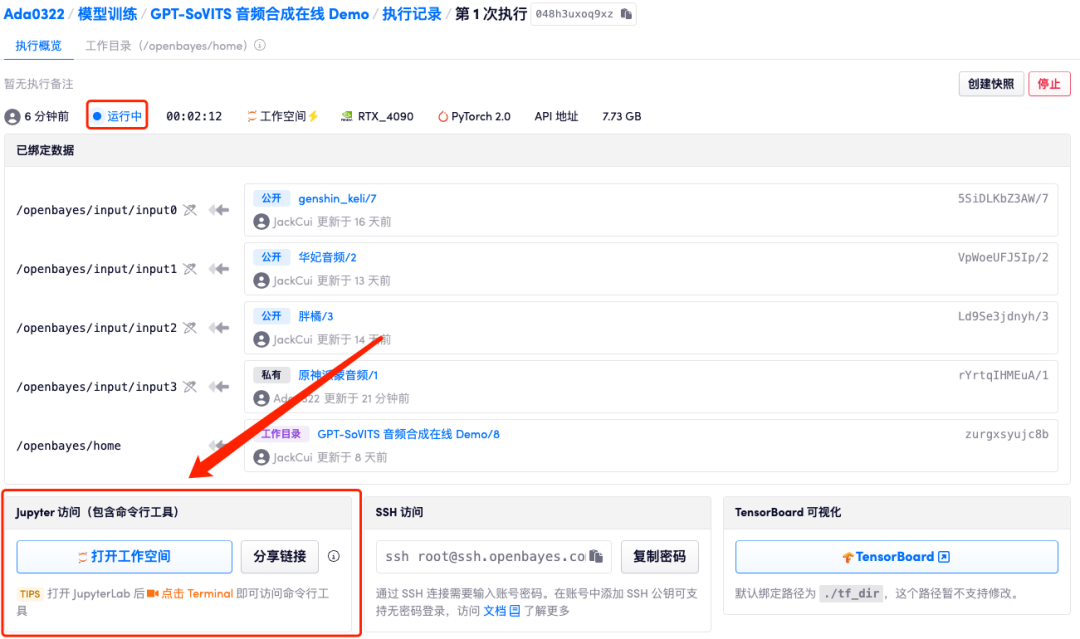
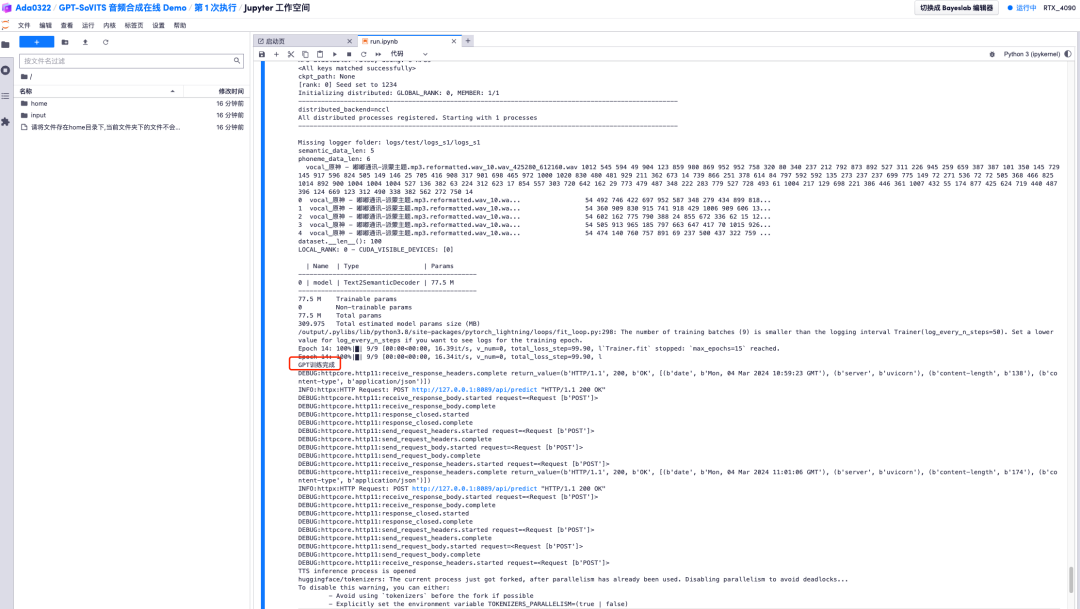
6. После открытия рабочей области нажмите «run.ipynb» слева, нажмите «Выполнить все ячейки» через кнопку «Выполнить» в строке меню.
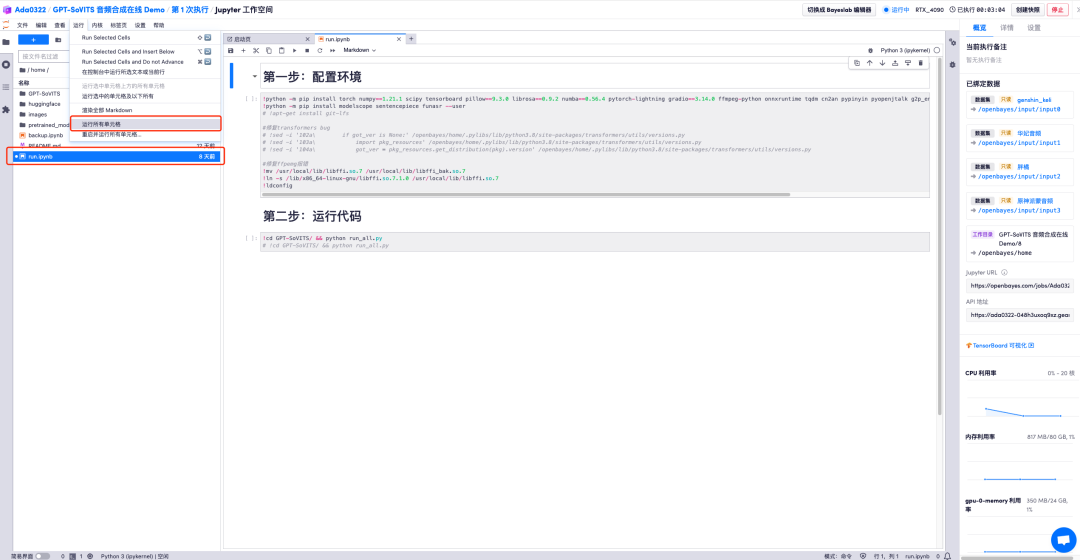
7. Найдите «Выполнение по общедоступному URL» и откройте ссылку.
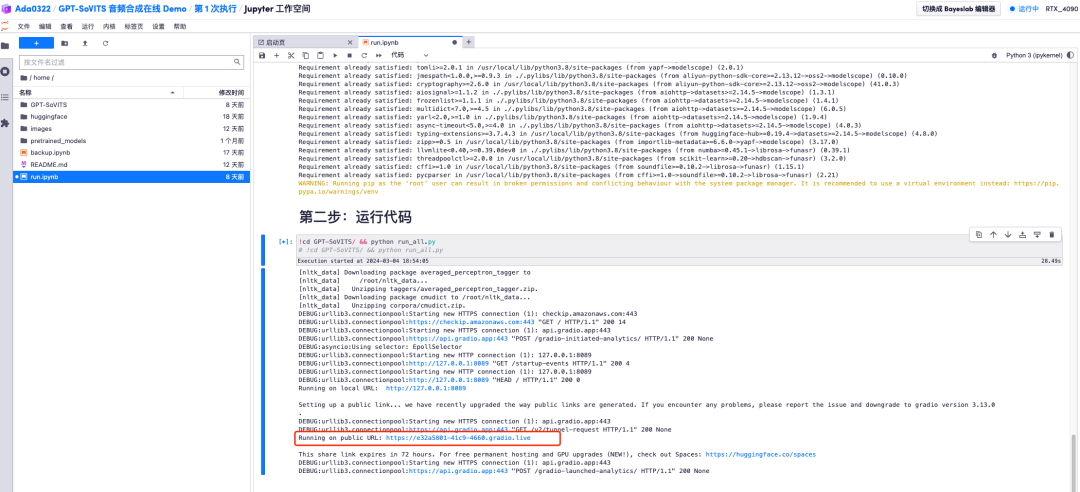
8. В модуле «Адрес набора данных» введите адрес набора данных, звук которого вы хотите клонировать на этот раз, выберите тип аудиоданных и нажмите «Начать обучение». Выходной результат будет отображаться как «Модель». начинает прогнозирование, подождите». Вернитесь к «run.ipynb», и вы увидите сообщение «Обучение GPT завершено».
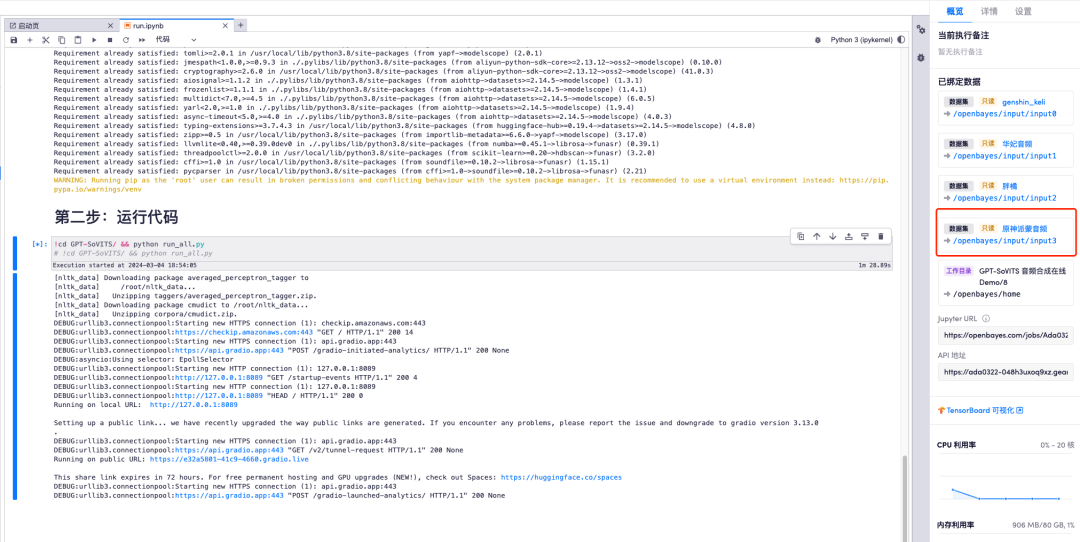
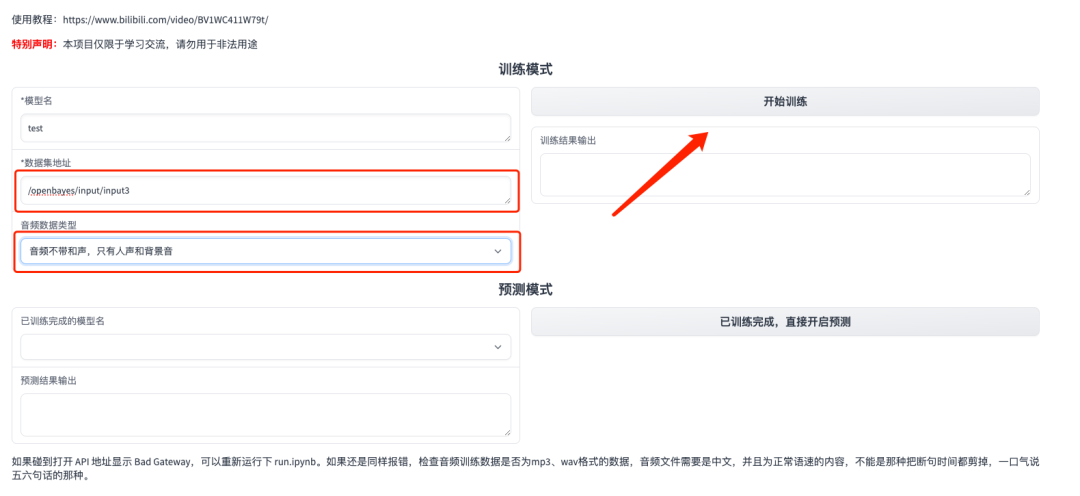
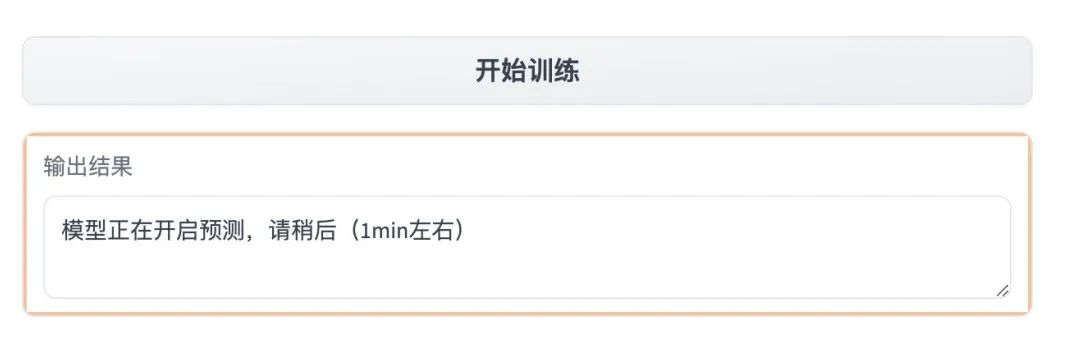
9. Откройте «Адрес API» справа. Обратите внимание, что пользователи должны пройти аутентификацию по настоящему имени, прежде чем они смогут использовать функцию доступа к адресу API.

Отображение эффектов
1. Выберите обученную модель в «Списке моделей GPT» и «Списке моделей SoVITS», затем введите текст в «Текст вывода», нажмите «Начать вывод», подождите немного, и вы можете играть счастливо!

В настоящее время на официальном сайте HyperAI опубликованы сотни избранных руководств по машинному обучению, организованных в формате блокнота Jupyter.
Щелкните ссылку, чтобы найти соответствующие учебные пособия и наборы данных:
https://hyper.ai/tutorials



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
