Учебное пособие RAG |Представление новой базы данных векторов эпохи RAG
Однако многие друзья не совсем понимают взаимосвязь и технические принципы векторных баз данных и RAG. Эта статья даст вам глубокое понимание новой векторной базы данных в эпоху RAG.
01.
Широкий спектр применения RAG и его уникальные преимущества
Типичную структуру RAG можно разделить на две части: извлекатель и генератор. Процесс извлечения включает в себя сегментацию данных (например, документы), встраивание векторов (вложение) и построение индексов (векторы фрагментов), а затем соответствующие результаты вызываются посредством векторного поиска. , а процесс генерации использует расширенный запрос на основе результатов поиска (Контекст) для активации LLM для генерации ответов (Результат).
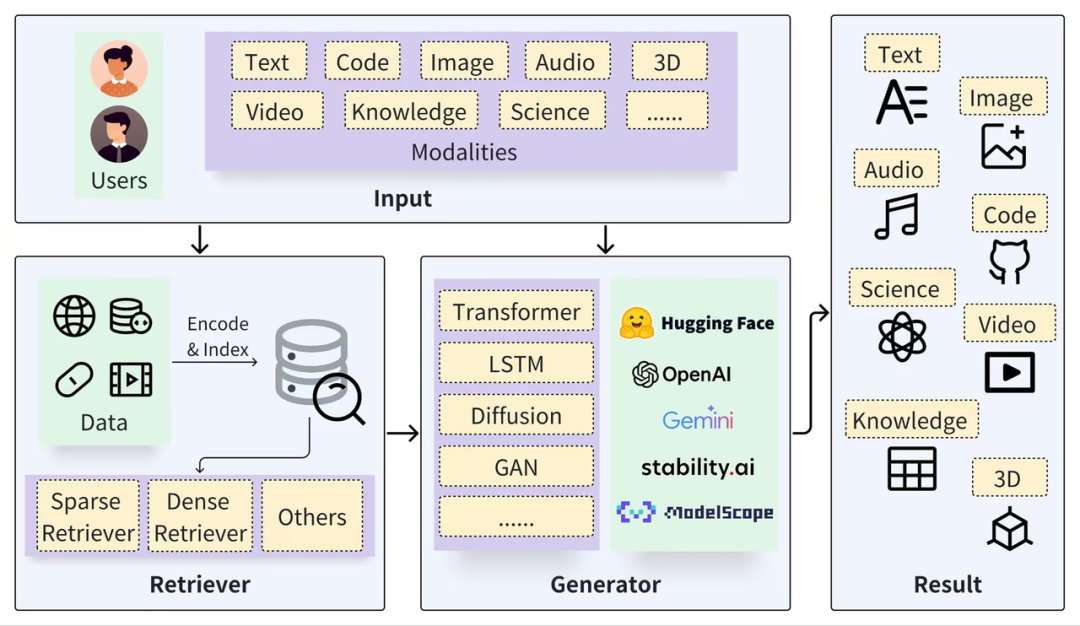
https://arxiv.org/pdf/2402.19473
Ключом к технологии RAG является то, что она сочетает в себе лучшее из обоих подходов:Поисксистема Могу предоставить конкретные、Связанныйизфактиданные,Генерирующая модель обеспечивает гибкое построение ответов.,и интегрироваться в более широкоеизконтекстиинформация。Эта комбинация делает RAG Модели очень эффективны при обработке сложных запросов и генерировании информативных ответов, что делает их полезными в вопросно-ответных системах, диалоговых системах и других приложениях, требующих понимания и генерации естественного языка. По сравнению с оригинальной большой моделью, с RAG Могут формировать естественные дополнительные преимущества:
- Избегайте проблем с «иллюзиями»:RAG Получая внешнюю информацию в качестве входной, помогая крупным экспертам отвечать на вопросы, этот метод может значительно уменьшить проблему неточной сгенерированной информации и повысить отслеживаемость ответов.
- Конфиденциальность и безопасность данных:RAG Базой знаний можно управлять как внешним приложением к частным компаниям или учреждениям, чтобы предотвратить ее неконтролируемую утечку после обучения.
- Информация в режиме реального времени:RAG разрешено снаружиданные Источник в реальном времени Поискинформация,Это обеспечивает доступ к новейшим знаниям по конкретной предметной области.,Решить проблему своевременности знаний.
Хотя передовые исследования крупномасштабных моделей также направлены на решение вышеупомянутых проблем, таких как точная настройка на основе частных данных и улучшение возможностей обработки длинных текстов самой модели, эти исследования помогают способствовать развитию крупномасштабных моделей. Технология масштабных моделей. Однако в более общих сценариях RAG по-прежнему остается стабильным, надежным и экономически эффективным выбором, главным образом потому, что RAG имеет следующие преимущества:
- модель белого ящика:По сравнению с тонкой настройкойи Обработка длинного текстаиз“черный ящик”эффект,RAG Связь между модулями становится более четкой и тесной, что обеспечивает более высокую работоспособность и интерпретируемость при оптимизации эффекта, кроме того, когда качество и достоверность (достоверность) извлекаемого и вызываемого контента не высоки, RAG; систему можно даже забанить LLMs Вмешательство, прямо ответьте «Я не знаю» вместо того, чтобы придумывать чепуху.
- Стоимость и оперативность:RAG По сравнению с точной настройкой он имеет преимущества короткого времени обучения и низкой стоимости по сравнению с обработкой длинного текста, имеет более высокую скорость ответа и гораздо более низкую стоимость вывода. На этапе исследований и экспериментов эффект и точность являются наиболее привлекательными, но с точки зрения промышленной реализации решающим фактором является стоимость, которую нельзя игнорировать;
- Управление личными данными:Объединив базы знаний с большими Модельразвязка,RAG Он не только обеспечивает безопасную и реализуемую практическую основу, но также лучше управляет существующими и новыми знаниями компании и решает проблему зависимости от знаний. Другим связанным аспектом является контроль и управление доступом, что очень важно для RAG Это легко сделать из базовой библиотеки данных, но сложно для большой Модели.
Поэтому, на мой взгляд, по мере углубления исследований крупномасштабных моделей технология RAG не будет заменена, а наоборот, сохранит важную позицию еще долгое время. В основном это связано с его естественной взаимодополняемостью с LLM, что позволяет приложениям, созданным на основе RAG, проявить себя во многих областях. Ключом к улучшению RAG является с одной стороны улучшение возможностей LLM, а с другой стороны оно опирается на различные улучшения и оптимизации поиска (Retrival).
02.
Основа для поиска RAG: векторные базы данных
В отраслевой практике поиск RAG обычно тесно интегрирован с векторными базами данных, что также привело к появлению решения RAG на основе ChatGPT + Vector Database + Prompt, называемого стеком технологий CVP. Это решение использует базы данных векторов для эффективного извлечения соответствующей информации для улучшения больших языковых моделей (LLM). Преобразуя запросы, сгенерированные LLM, в векторы, система RAG может быстро находить соответствующие записи знаний в базе данных векторов. Этот механизм поиска позволяет LLM использовать новейшую информацию, хранящуюся в базе данных векторов, при возникновении конкретных проблем, эффективно решая проблемы задержки обновления знаний и иллюзий, присущих LLM.
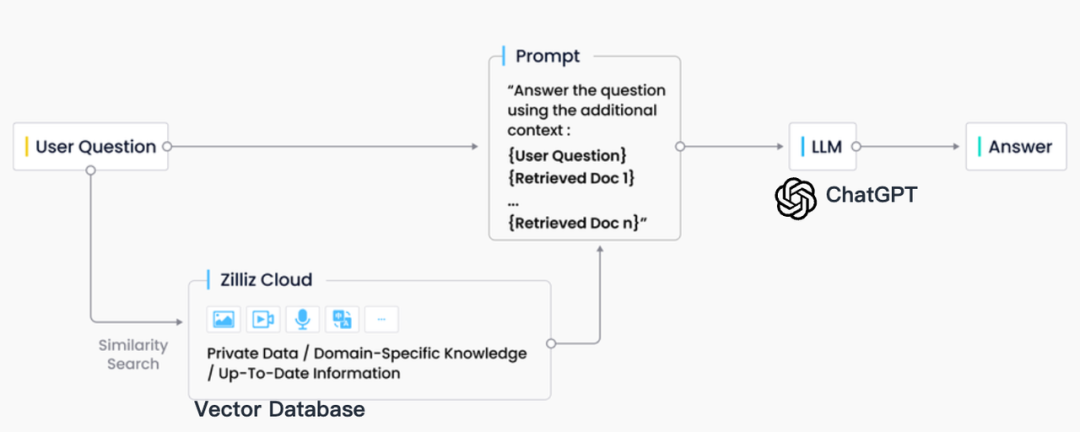
Хотя в области поиска информации существует множество технологий хранения и поиска, включая поисковые системы, реляционные базы данных, базы данных документов и т. д., векторные базы данных стали первым выбором в отрасли в сценариях RAG. За этим выбором стоит превосходная способность векторных баз данных эффективно хранить и извлекать большое количество встроенных векторов. Эти векторы внедрения генерируются моделями машинного обучения и способны не только характеризовать несколько типов данных, таких как текст и изображения, но также собирать их глубокую семантическую информацию. В системе RAG поисковой задачей является быстрый и точный поиск информации, наиболее соответствующей семантике входного запроса, а векторные базы данных выделяются существенными преимуществами при обработке многомерных векторных данных и выполнении быстрого поиска по сходству.
Ниже приводится горизонтальное сравнение векторных баз данных, представленных поиском векторов, с другими техническими вариантами, а также анализ ключевых факторов, которые делают их основным выбором в сценариях RAG:
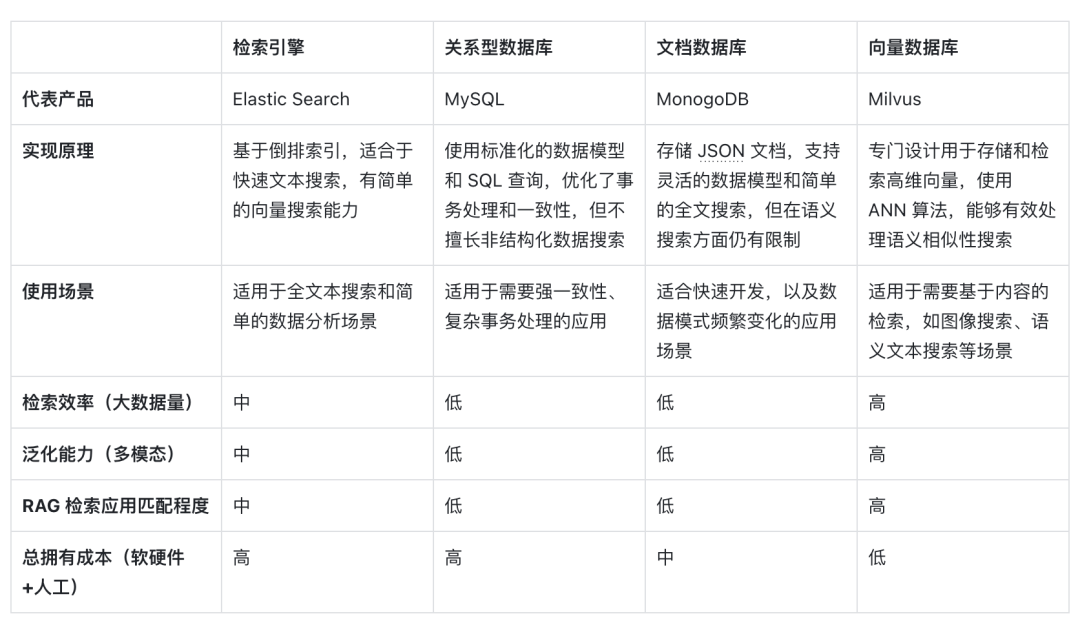
первый вПринцип реализацииаспект,Вектор – это Модель, кодирующая форму семантического значения.,Библиотека векторных данных позволяет лучше понять семантический контент запроса.,Потому что они используют возможности глубокого обучения для кодирования текстовых значений.,Не только соответствие ключевых слов. извлечь выгоду из AI В ходе разработки модели семантическая точность также постоянно улучшается. Благодаря использованию сходства векторов на расстоянии для представления семантического сходства она превратилась в. NLP Основная форма, такая идеографичная embedding Он стал первым выбором для обработки носителей информации.
Во-вторых вЭффективность поискааспект,Поскольку информацию можно представить в виде многомерного вектора,Добавлен специальный метод оптимизации индекса и метода квантования для векторов.,Может значительно улучшить эффективность поиск и сокращение затрат на хранение, поскольку по мере роста объема данных библиотеку векторных данных можно расширять по горизонтали, сохраняя при этом время отклика запроса, необходимое для обработки огромных объемов данных. RAG Системы имеют решающее значение, поэтому векторные базы данных лучше справляются с обработкой чрезвычайно крупных неструктурированных данных.
Что касаетсяспособность к обобщениюэто измерение,Большинство традиционных поисковых систем, реляционных библиотек или библиотек документов могут обрабатывать только текст.,Плохая способность обобщать и расширять,Библиотека векторных данных не ограничивается текстовыми данными.,Он также может обрабатывать изображения, аудио и другие неструктурированные типы данных из встроенных векторов.,Это делает RAG Системы могут быть более гибкими и универсальными.
последний вобщая стоимость владенияначальство,По сравнению с другими вариантами,Библиотека векторных данных из развертывания более удобна и проста в использовании.,Это также обеспечивает богатство API, упрощающий интеграцию с существующими платформами и рабочими процессами машинного обучения, что делает его популярным среди многих. RAG Его любят разработчики приложений.
Векторный поиск стал идеальным средством извлечения RAG в эпоху больших моделей благодаря своей способности к семантическому пониманию, высокой эффективности поиска и поддержке обобщения для мультимодальностей. С дальнейшим развитием искусственного интеллекта и моделей внедрения эти преимущества могут стать более заметными. в будущем.
03.
Требования к векторным базам данных в сценариях RAG
Хотя векторные базы данных стали важным способом поиска, с развитием приложений RAG и спросом людей на высококачественные ответы поисковые механизмы по-прежнему сталкиваются со многими проблемами. Здесь мы возьмем в качестве примера самый простой процесс построения RAG: в состав поисковика входит предварительная обработка корпуса, такая как сегментация, очистка данных, внедрение и т. д., затем построение и управление индексами и, наконец, поиск похожих элементов с помощью векторного поиска. предоставлено для запроса на расширенную генерацию. Функции большинства векторных баз данных сосредоточены только на управлении построением индексов и поисковых вычислениях и дополнительно включают функции внедрения моделей.
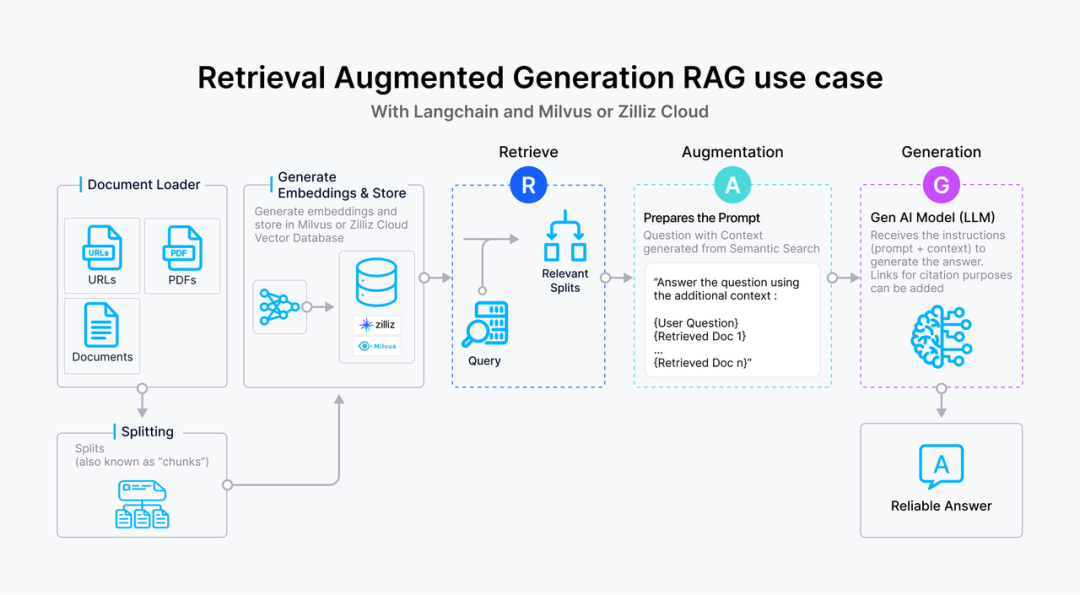
Но в более сложных сценариях RAG, поскольку качество отзыва напрямую влияет на качество вывода и релевантность сгенерированной модели, векторная база данных как основа средства извлечения должна нести большую ответственность за качество поиска. Чтобы улучшить качество поиска, здесь на самом деле существует множество методов инженерной оптимизации, таких как выбор chunk_size, нужно ли перекрытие для сегментации, как выбрать модель внедрения, нужны ли дополнительные теги контента, добавлять ли лексически основанные поиск для гибридного поиска и т. д. Выбор сортировки, переранжирования и т. д. Многие из этих задач могут быть учтены в векторной базе данных. Требования к поисковой системе векторных баз данных можно абстрактно описать так:
- Высокая точность отзыва:Библиотека векторных данных Необходимо уметь точно вспомнить наиболее релевантную семантику запроса.Связанныйиздокумент илиинформацияфрагмент。Это требуетданные Библиотека понимаети Работа с многомерными векторными пространствамиизсложные смысловые отношения,Убедитесь, что отозванный контент имеет прямое отношение к запросу. Здесь эффект включает в себя как векторный поиск с математической точностью, так и встраивание семантической точности Модели.
- Быстрый ответ:Чтобы не влиять на пользовательский опыт,Операцию отзыва необходимо завершить в течение очень короткого времени.,Обычно на уровне миллисекунд. Для этого требуется, чтобы библиотека векторных данных имела эффективные возможности обработки запросов.,Для быстрого извлечения и вызова информации из крупномасштабных коллекций данных. также,С ростом объема данных требования к запросам,Библиотека векторных данных должна иметь возможность гибко расширяться.,Для поддержки более изданных и более сложных запросов,В то же время сохраняется эффект отзыва, стабильность и надежность.
- Возможность обработки мультимодальных данных.:Со сценариями примененияиздиверсификация,Библиотеке векторных данных может потребоваться обрабатывать не только текст.,Существуют также мультимодальные данные, такие как изображения и видео. Для этого требуется, чтобы библиотека данных могла поддерживать различные виды вложений данных.,И он может выполнять эффективный вызов на основе различных модальных запросов.
- Интерпретируемость и возможность отладки:Когда эффект отзыва не идеален,Очень важно иметь возможность предоставить достаточно информации, чтобы помочь разработчикам диагностировать и оптимизировать. поэтому,Библиотеку векторных данных также следует разрабатывать с учетом системинтерпретируемости и возможности отладки.
Сценарий RAG предъявляет строгие требования к эффекту отзыва векторной базы данных. Он не только требует базовых возможностей, таких как высокоточный и быстрый отклик, но также требует способности обрабатывать мультимодальные данные и более продвинутых возможностей, таких как интерпретируемость. и возможности отладки, гарантирующие, что генеративные модели выдают точные и релевантные результаты на основе высококачественных результатов отзыва. С точки зрения мультимодальной обработки, интерпретируемости поиска и возможности отладки векторным базам данных еще предстоит многое изучить и оптимизировать, и разработчикам приложений RAG также срочно необходимо комплексное решение для достижения высококачественных результатов поиска.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
