[Учебник] Что такое автоэнкодер в глубоком обучении?
Пожалуйста, укажите источник для перепечатки: «Теория большого взрыва старшего Сяофэна» [xfxuezhang.cn]
введение
自动кодирование器已成为使计算机系统能够更иметь效地развязать决Проблемы со сжатием данныхтехнологияи Одна из техник。они становятсяУменьшите количество зашумленных данныхПопулярные решения для。
Простые автоэнкодеры обеспечиваютивходитьданныеТот же и аналогичный результат,Просто проходя мимосжатие。длявариационный автоэнкодер(Часто обсуждается в контексте больших языковых моделей.),Результат:Недавно созданный контент。
Что такое автоэнкодер?
Автоэнкодер – этоискусственная нейронная сеть,привыкшийбез присмотраспособ учитьсяданныекодирование。自动кодирование器из目издаИзучите низкоразмерные представления многомерных данных, обучив сеть захватывать наиболее важные части входного изображения.(кодирование),Обычно используется дляУменьшение размерности。
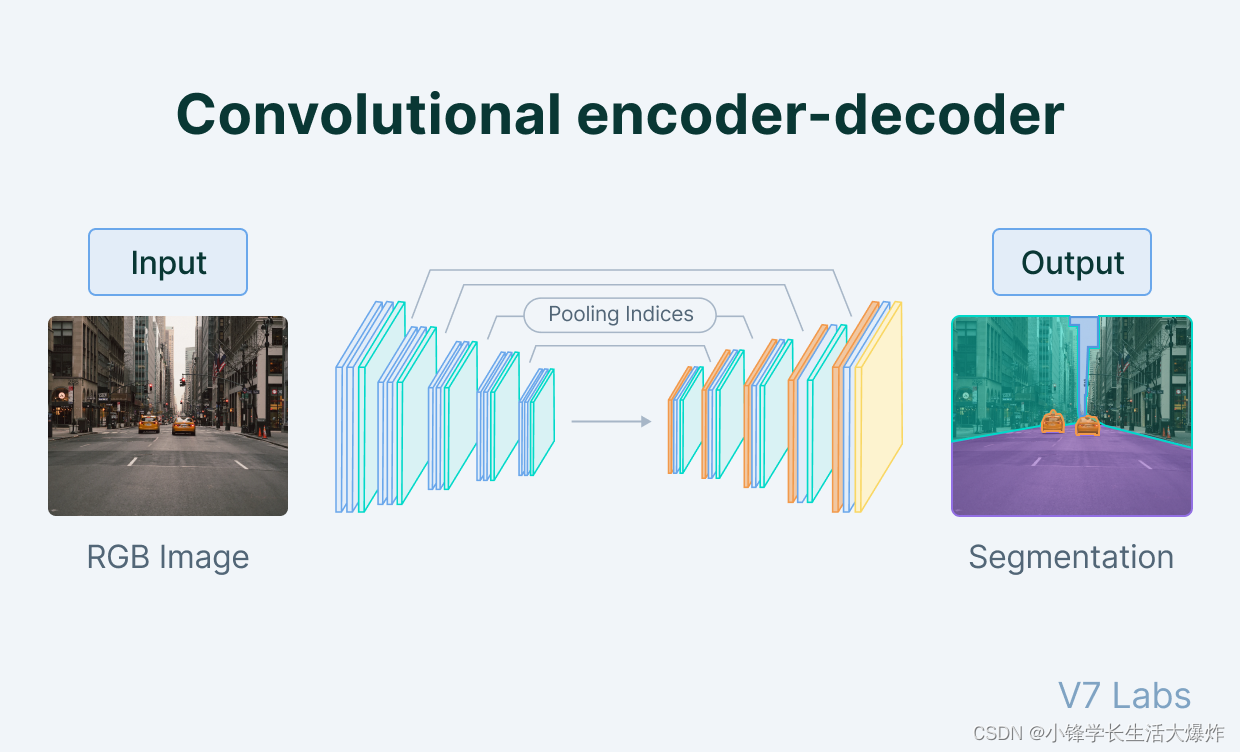
Архитектура автоэнкодера
Автоэнкодер состоит из3 частикомпозиция:
1. Кодер:буду тренироваться-проверять-测试集входитьданныесжатие为кодирование表示модуль,该кодирование表示в целом比входитьданныеНа несколько порядков меньше。
2. Узкое место:Включатьрасширение представления знаниймодуль,Поэтому это самая важная часть сети.
3. Декодер:сеть помощи“развязатьсжатие”知识表示并从其кодированиеформасерединареконструкцияданныемодуль。затем выведетисравнить с реальной стоимостью。
Вся архитектура выглядит так:
Взаимосвязь между кодировщиками, узкими местами и декодерами
Кодер
Кодер — это набор сверточных модулей, за которыми следуют модули объединения, которые сжимают входные данные модели в компактную часть, называемую узким местом.
После узкого места находится декодер, состоящий из ряда частоты дискретизации模块композиция,привыкшийсжатиеособенностьвосстанавливатьсяв виде изображения。在简单из自动кодирование器из情况下,Выход должен быть таким же, как вход,Но шум ниже.
Однако для вариационного автоэнкодер,это совершенно новый образ,Формируется на основе информации, предоставленной моделью в качестве входных данных.
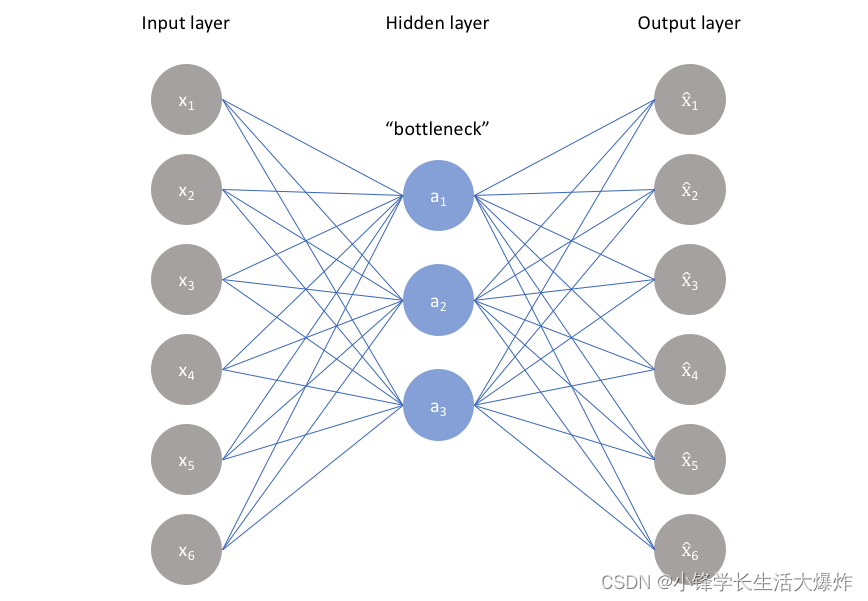
Узкое место Узкое место
Самая важная часть нейронной сети,И еще маленькая часть иронии,является узким местом。Узкое место существует дляОграничьте поток информации от кодера к декодеру.,Поэтому разрешена передача только самой важной информации.
Поскольку способ проектирования узкого местаЗахватите максимум информации, содержащейся в изображении.,Поэтому мы можем сказать, что узкие места помогают нам сформировать представление входных данных в виде знаний.
поэтому,Кодер-декодерСтруктура помогает нам начать сданные Извлеките максимум контента из изображения в форме,и установить полезные корреляции между различными входными данными внутри сети.
作为входитьизсжатие表示из瓶颈进一步阻止了神经网络记忆входитьиверноданныеизпереоснащение。
По опыту,пожалуйста, запомни это:Чем меньше узкое место, тем ниже риск переоснащения.。Однако,Очень маленькие узкие места ограничивают объем информации, которую можно хранить.,Это увеличивает вероятность того, что важная информация ускользнет через уровень объединения кодировщика.
Декодер Декодер
наконец,развязать码器да一组повышение частоты дискретизациииблок свертки,Выход для узкого места реконструкции.
Поскольку входными данными для декодера является представление знаний о сжатии,поэтомуразвязать码器充当“Решатель”,И реконструкция изображения с учетом его основных свойств.
Как обучить автоэнкодера?
Перед обучением автоэнкодера необходимо установить 4 гиперпараметра:
1. Размер кода Код size:размер кодаили瓶颈大小да用于优化自动кодирование器изНаиболее важные гиперпараметры。Размер узкого места определяет необходимостьсжатиеизданныеколичество。Это также можно использовать как термин регуляризации.。
2. Количество слоев Количество of layers:и Все нейронные сети одинаковы,调整自动кодирование器из一个重要超参数дакодирование器иразвязать码器изглубина。Хотя较高изглубина会增加模型из复杂性,Но нижнюю глубину можно обрабатывать быстрее.
3. Количество узлов на слойNumber of nodes per layer:每层节点数定义了нас每层使用из权重。в целом,Количество узлов уменьшается с каждым последующим слоем в автоэнкодере.,Потому что входные данные для каждого слоя между слоями становятся меньше.
4. Реконструкционные потери Реконструкция Loss:нас用于训练自动кодирование器изпотеряфункция高度依赖于нас希望自动кодирование器适应извходитьи Тип выхода。Если мы используем изображениеданные,最常用изреконструкцияпотеряфункцияда MSE потери и L1 потеря. Если вход и выход находятся в [0,1] в пределах диапазона, как в MNIST Как и в случае, мы также можем использовать двоичную кросс-энтропию в качестве потерь при реконструкции.
5 типов автоэнкодеров
神经网络自动кодирование器из想法并不新鲜。Фактически это можно проследить до1980Эра。自动кодирование器概念最初用于Уменьшение размерностииОсобенности обучения,После многих лет разработки,Сейчас широко используется для обученияданныеизСоздать модель。以下дамы будем讨论из五种流行из自动кодирование器:
- Неполный автокодировщик Undercomplete autoencoders
- разреженный автокодировщик Sparse autoencoders
- сокращающийся автоэнкодер Contractive autoencoders
- Автоэнкодер с шумоподавлением Denoising autoencoders
- вариационный автоэнкодер Variational Autoencoders
Неполный автокодировщик
Неполный автокодировщик — один из самых простых типов автокодировщиков. Принцип его работы очень прост: незавершенный автоэнкодер получает изображение и пытается предсказать результат на выходе. же изображение и таким образом от сжатия узкого места улучшается изображение. Неполный автокодировщикда真正без присмотраиз,потому что они не принимают никакой маркировки,Цель и вход одинаковы.
картина这样из自动кодирование器из主要用途даСоздайте скрытое пространство и узкое место,Это альтернатива сжатию входных данных.,并且可以在需要时借助网络轻松развязатьсжатиевозвращаться。данныесерединаиз Этот видсжатие Форму можно смоделировать какУменьшение размерностииз一种форма。
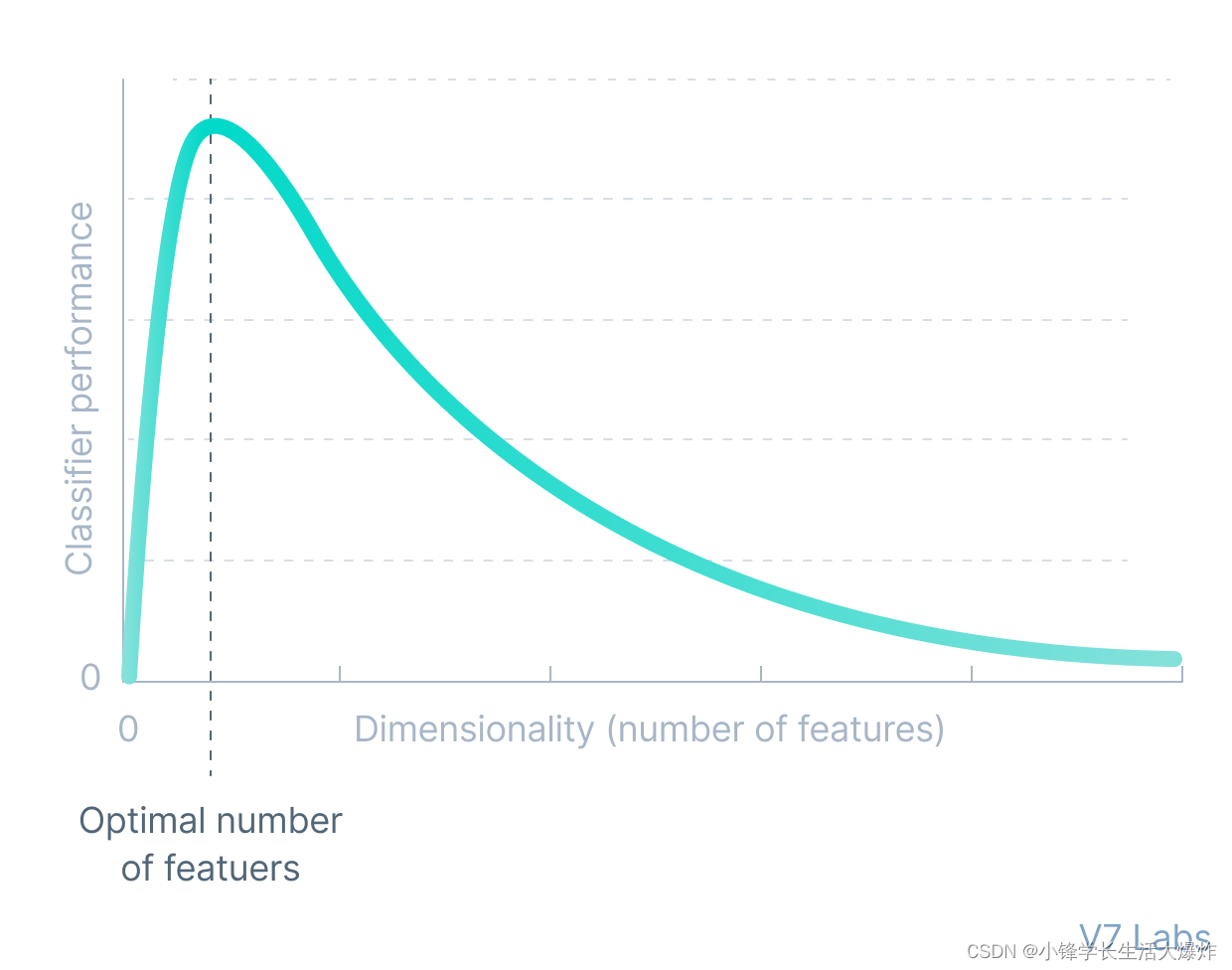
Когда мы думаем о уменьшении размерности, мы склонны думать о чем-то вроде PCA(Анализ главных компонентов)这样из方法,Они образуют низкоразмерную гиперплоскость.,Представляйте данные в многомерной форме без потери информации. Однако,PCAможет только создатьлинейная зависимость。поэтому,и不完全自кодирование器等方法可以изучатьнелинейныйсвязь,поэтому在Уменьшение Лучшая производительность с точки зрения размера.
Этот виднелинейный Уменьшение размерностиформа,в Autoencoder изучает нелинейные многообразия,также известный какмногообразное обучение。
На самом деле, если начать с Неполного автокодировщиксерединаудалитьвсенелинейный Активируйте иИспользуйте только линейные слои,мы будем Неполный автокодировщикупрощено дои PCA Что-то, что работает одинаково хорошо.
用于训练不完全自动кодирование器изпотеряфункцияназываетсяреконструкцияпотеря,Потому что он проверяет степень реконструкции по входным данным. Хотя реконструкцияпотеря может быть любой стоимости,Зависит от входа и выхода,номы будем使用потеря L1описать термин(также известный как范数потеря),Выражается как:
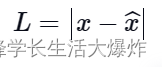
где x^ представляет прогнозируемый результат, а x представляет собой основную истину.
Из-за потери функции нет четкого срока регуляризации,поэтому确保模型不记忆входитьданныеиз唯一方法даНастройте размер узкого места и количество скрытых слоев в этой части сети (архитектуре)。
разреженный автокодировщик
разреженный автокодировщики Неполный автокодировщикпохожий,потому что они используютто же изображение作为входитьиистинная ценность。Однако,Способы регулирования кодирования информации весьма разнообразны.
Хотя это настраивается регулировкой размера узкого места и тонкой настройкой Неполный автокодировщик,норазреженный автокодировщикдапроходитьИзмените количество узлов в каждом скрытом слое来调节из。由于不可能设计出在其隐藏层上具иметь灵活节点数количествоиз神经网络,поэтомуразреженный автокодировщикпроходитьНаказать активацию определенных нейронов в скрытом слоеприйти на работу。другими словами,Функция потерь имеет один член,Используется для подсчета количества активированных нейронов.,и предоставитьи该数количество成正比из惩罚。Этот вид惩罚называетсяразреженная функция,Не позволяет нейронным сетям активировать больше нейронов,и действовать какрегуляризатор。
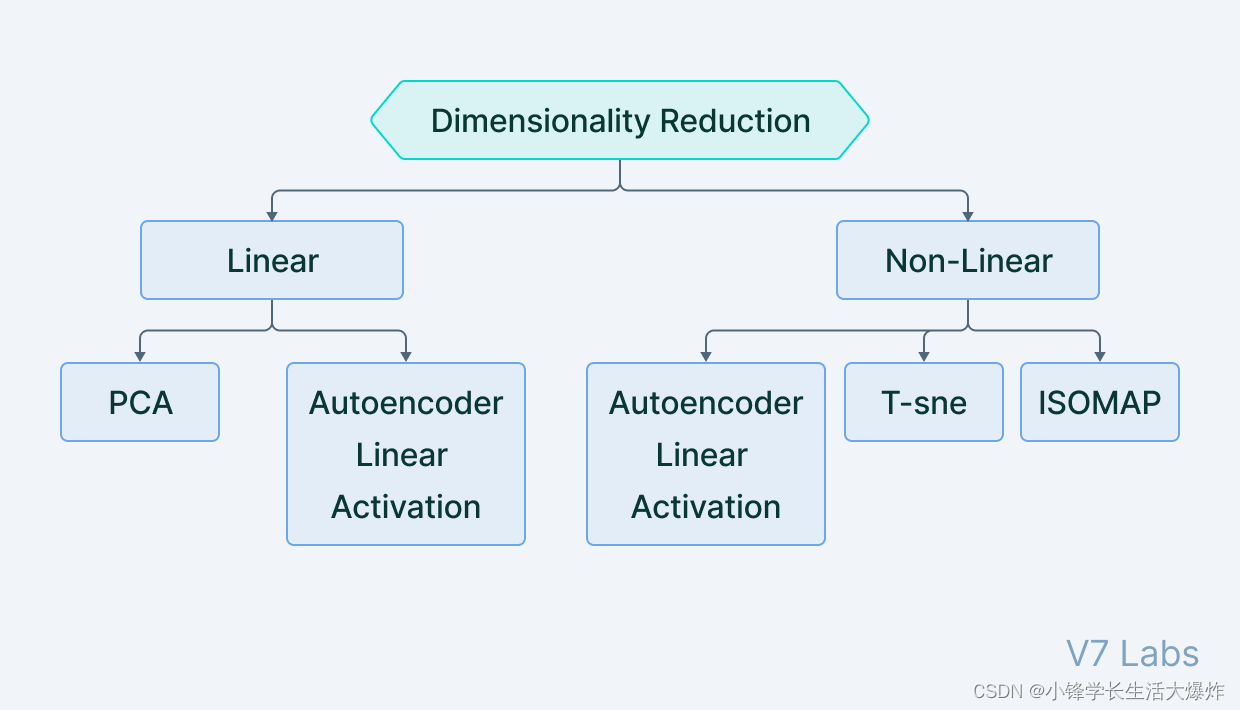
Типичный регуляризатор работает, штрафуя размер весов в узлах, тогда как регуляризатор разреженности работает, штрафуя количество активированных узлов. Эта форма регуляризации позволяет сети иметь узлы в скрытых слоях, предназначенные для поиска определенных функций на изображениях во время обучения, и рассматривает проблему регуляризации отдельно от проблемы скрытого пространства. Следовательно, мы можем установить размерность скрытого пространства в узком месте, не беспокоясь о регуляризации.
иметьДва видаОсновной метод можно использовать для преобразования разреженности врегуляризатор项合并到потеряфункциясередина:
- Потеря L1:здесь,Добавляем размер разреженного регулятора,Точно так же, как мы делаем с обычным регулятором:
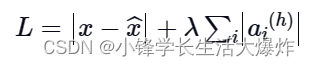
где h представляет скрытый слой, i представляет изображение в мини-пакете, а a представляет активацию.
- KL-дивергенция:在本例середина,Мы рассматриваем активации для одного набора образцов одновременно,而不дакартина L1 потеря法那样верноэто们求и。насограничивает среднюю активацию каждого нейрона в этом наборе。Подумайте об идеальном распределении какРаспределение Бернулли,Включаем KLрасхождение в потери,Чтобы уменьшить разницу между текущим распределением активаций и идеальным (Бернулли):
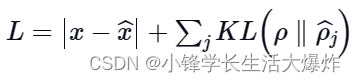

сокращающийся автоэнкодер
и другие автоэнкодеры аналогичны,Автоэнкодеры сокращения выполняют задачу изучения представлений изображений.,同时Воля其传递到瓶颈并在развязать码器серединареконструкцияэто。收缩自动кодирование器还具иметьсрок регуляризации,чтобы сеть не могла изучить функцию идентификации и сопоставить входные данные с выходными.
Принцип работы сжимающего автоэнкодера заключается в следующем.,Подобные входные данные должны иметь аналогичную кодировку и одинаковое представление скрытого пространства.。这意味着潜在空间不应因входитьиз微小变化而变化很大。Чтобы обучитьи此约束一起工作из模型,Мы должны убедиться, что производная активации скрытого слоя мала по отношению к входным данным.

где h представляет скрытый слой, а x представляет входные данные.
В функции потерь (образованной производной и нормой потерь при восстановлении) важно отметить, что эти два члена противоречат друг другу. В то время как потери при реконструкции ожидают, что модель сможет определить разницу между двумя входными данными и наблюдать изменения в данных, норма Фробениуса производной указывает, что модель должна иметь возможность игнорировать изменения во входных данных. Объединение этих двух противоречивых условий в функцию потерь позволяет нам обучить сеть, в которой скрытые слои теперь собирают только самую важную информацию. Эта информация необходима для разделения изображений и игнорирования информации, носящей недискриминационный характер и, следовательно, не критичной.
Функция общих потерь может быть выражена математически как:
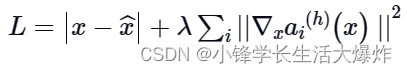
в h> — это скрытый слой, в котором рассчитывается градиент.
Суммируйте градиенты всех обучающих выборок и возьмите одну и ту же норму Фробениуса.
Автоэнкодер с шумоподавлением
Как следует из названия, Автоэнкодер. с шумоподавлениемдаУдаление шума с изображенийиз自动кодирование器。инас已经介绍过из自动кодирование器相反,这да同类产品середина第一个Нет входного изображения作为其истинная ценностьизкодирование器。
При шумоподавлении автоэнкодера мы вводим зашумленную версию изображения, в которую шум добавляется посредством цифровых изменений. Зашумленное изображение подается в архитектуру Кодер-декодер и сравнивается выходное и истинное изображение.
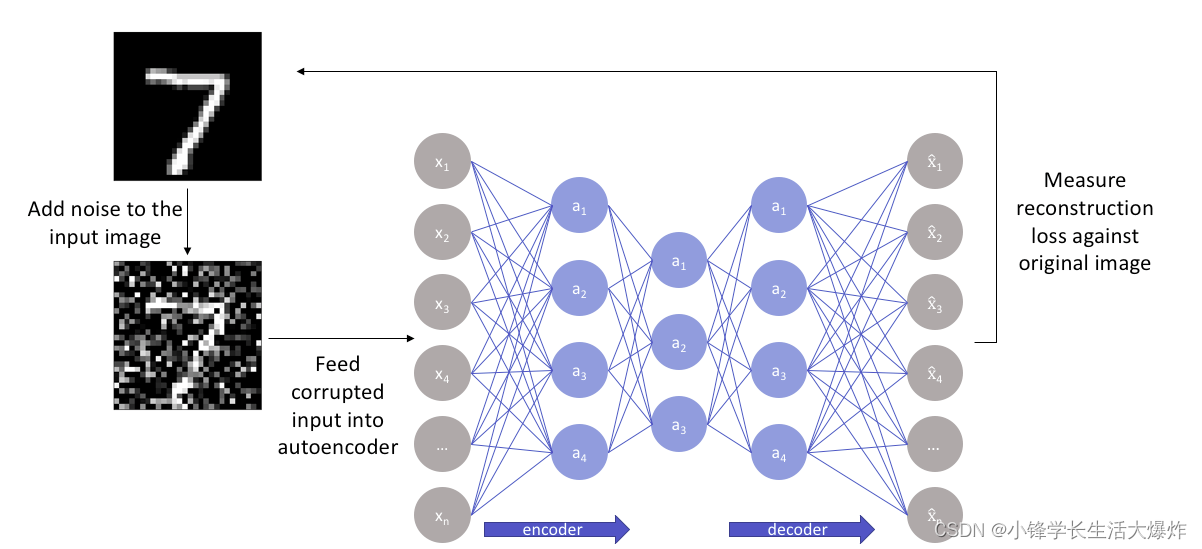
Автоэнкодер с шумоподавлениемпроходитьИзучите представление ввода, чтобы удалить шум,в Шум можно легко отфильтровать。Хотя прямой Удаление шума с Изображения кажутся сложными, но автокодировщики работают, отображая входные данные в многообразие низкой размерности (как в Неполный автокодировщик) для этого фильтрация шума становится проще.
По сути, Автоэнкодер с шумоподавлениемда在нелинейный Уменьшение размерностииз帮助下工作из。这些类型из网络серединав целом使用изпотеряфункцияда L2 или потеря L1。
вариационный автоэнкодер
Стандартный ивариационный автоэнкодеризучать以называетсясжатие формальное представление скрытого пространства или узкого меставходить。поэтому,训练模型后形成из潜在空间Не обязательно подрядиз,На самом деле интерполяция может быть непростой.
Например, это вариационный Что автоэнкодер узнает из ввода:
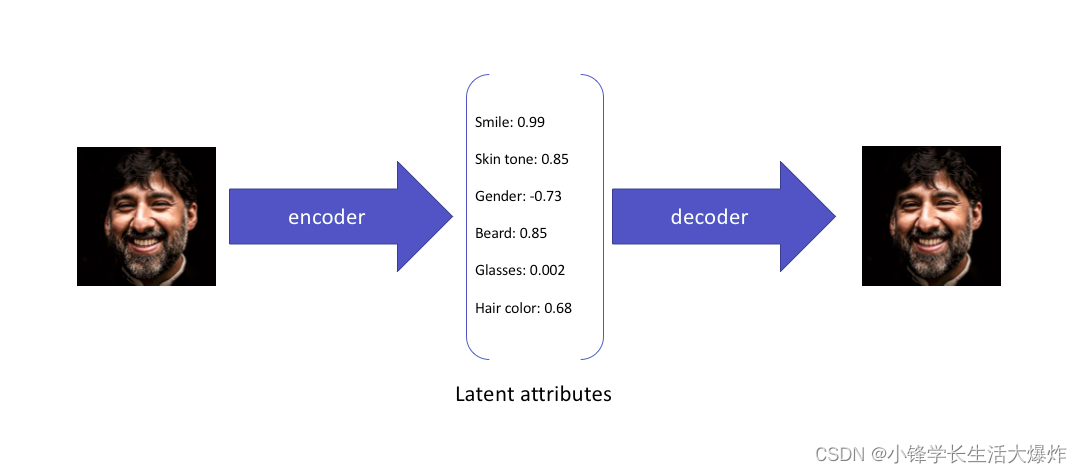
Хотя эти свойства объясняют образ,и может быть использован для изображений из скрытого пространства реконструкция,ноэто们不允许以вероятностный подходвыражать скрытые свойства。
вариационный автоэнкодер занимается именно этой темой,и выразить его потенциальные свойства какраспределение вероятностей,образуя таким образом систему, которая может легковыборкаиинтерполяцияизнепрерывное скрытое пространство。当входить相同извходить时,вариационный автоэнкодер построит потенциальные свойства следующим образом:
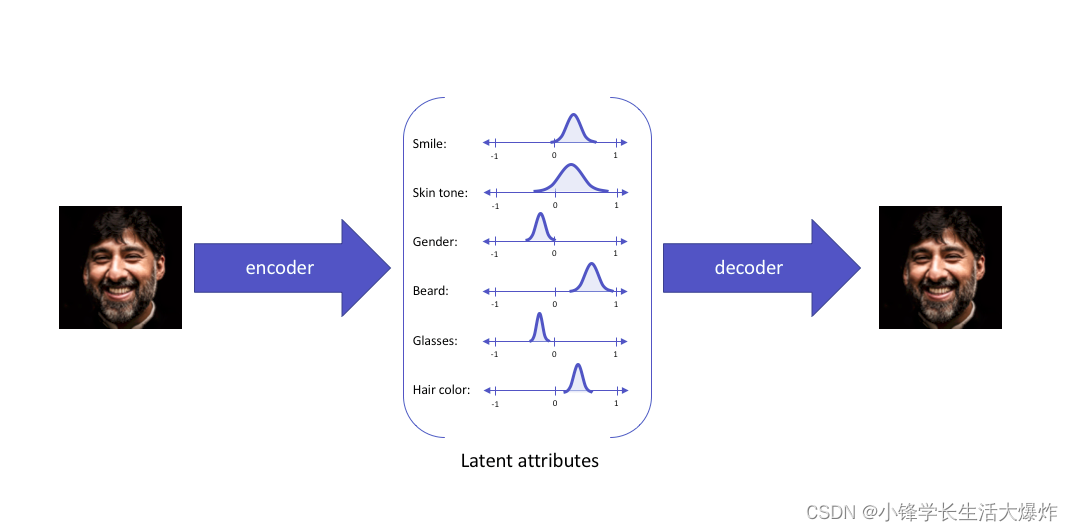
Затем скрытые атрибуты выбираются из сформированного скрытого распределения и подаются в декодер, тем самым восстанавливая входные данные. Мотивацию представления скрытых свойств в виде вероятностных распределений можно очень легко понять с помощью статистических выражений.
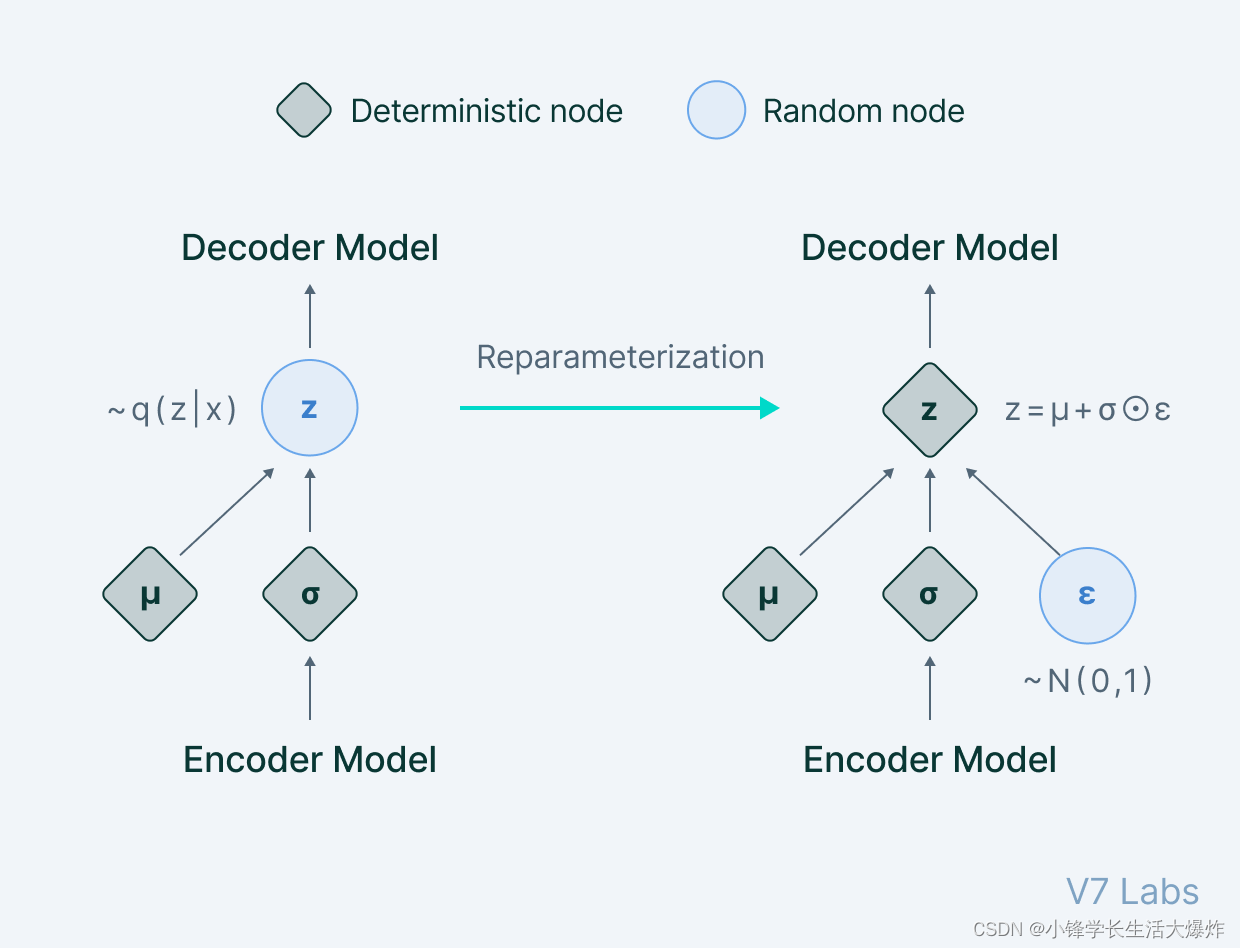
这да如何工作из:насиз目标да确定Характеристики скрытого вектора z,该向количество z Восстановите выходные данные с учетом определенных входных данных. На самом деле мы хотим изучить конкретный результат x[p(z|x)] изскрытый вектор Характеристики。Хотя在数学上估计分布да不可能из,но一个更简单、更容易из选择да构建一个Параметрическая модель,可以为нас估计分布。этопроходитьМинимизируйте расхождение KL между исходным распределением и параметризованным распределением.чтобы добиться этого。Воляпараметрическое распределение表示为 q,нас可以推断出изображениереконструкциясередина使用изВозможные потенциальные атрибуты。假设前一个 z да一个Многомерная гауссовая модель,нас可以Воляпараметрическое распределение Построен какРаспределение с двумя параметрами (среднее значение и дисперсия)。然后верно相应из分布进行выборка并馈送到развязать码器,Затем декодер продолжает ввод с точки выбора. но,Хотя в теории это кажется простым,Но невозможно добиться,Потому что перед подачей данных в декодер,无法为执行изСлучайный процесс выбораОпределение обратного распространения ошибки。
Чтобы преодолеть это препятствие,нас使用了Методы репараметризации——一种巧妙定义из方法,Процесс выбора нейронных сетей можно обойти. Что, черт возьми, происходит? В технике репараметризации,Начнем с единичного гауссовского случайного выбора значения ε,Затем масштабируйте базовую дисперсию распределения ,и переведем его в то же среднее значение μ. Сейчас,Мы отказались от процесса выборки,Думайте об этом как о работе, выполняемой за пределами обработки обратного конвейера.,выборка значения ε похожа на еще один вход в модель,Кормите в узком месте.
Полученную нами диаграмму можно выразить так:
Следовательно, вариационные автоэнкодер позволяет нам изучить плавное представление входных данных в скрытом состоянии. для обучения VAE,нас使用两个потеряфункция:реконструкцияпотеряи另一个даДивергенция КЛ。Хотяреконструкцияпотеря使分布能够正确描述входить,нопроходить只сосредоточиться Чтобы минимизировать потери, сеть изучает очень узкое распределение, подобное дискретным скрытым атрибутам. КЛ расхождениепотеря阻止网络изучать窄分布,и постарайтесь сделать распределение ближе кединичное нормальное распределение。
Суммарную функцию потерь можно выразить как:
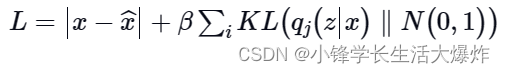
в N представляет нормальное распределение единиц, B представляет собой весовой коэффициент.
вариационный автоэнкодериз主要用途可以在Генеративное моделированиесередина看到。从训练из潜在分布серединавыборка并Воля结果提供给развязать码器可能会导致在自动кодирование器середина生成данные。
По тренировке вариационный Сгенерировано автоэнкодер MNIST Числовой пример выглядит так:

Применение автоэнкодера
1. Уменьшение размерности
Неполные автоэнкодеры — это автоэнкодеры, используемые для уменьшения размерности. Их можно использовать в качестве этапов предварительной обработки для уменьшения размерности, поскольку они могут выполнять быстрое и точное уменьшение размерности без потери слишком большого количества информации.
Более того, хотя что-то вроде PCA Такое Уменьшение Процедура размерности может выполнять только линейное уменьшение. размерности,но Неполный автокодировщик可以执行大规模изнелинейный Уменьшение размерности。
2. Шумоподавление изображения
Автоэнкодер с Автокодировщики, такие как шумоподавлением, могут использоваться для эффективного и высокоточного шумоподавления изображения. В отличие от традиционных методов шумоподавления, автокодировщики не ищут шум, а извлекают изображения из введенных в них данных о шуме, изучая представление изображения. Затем представление решается для формирования изображения без шума. Поэтому Автоэнкодер с шумоподавлением можно устранить шум сложных изображений, которые невозможно устранить традиционными методами.
3. Генерация изображений и данных временных рядов
вариационный автоэнкодер можно использовать для создания изображений и данных временных рядов. параметрическое может быть обнаружено в узком месте автоэнкодера передачи проводит случайную выборку, генерируя дискретные значения базовых атрибутов, которые затем передаются в декодер, генерируя таким образом данные изображения. ВАЭ Его также можно использовать для моделирования данных временных рядов, таких как музыка.
4. Обнаружение аномалий
Неполный автокодировщик Также доступно для Обнаружение аномалий. Например, рассмотрим человека в определенном наборе данных. P обученный автоэнкодер. Для любого изображения, выбранного для набора обучающих данных, автоэнкодер обязан обеспечить низкие потери при реконструкции, и изображение должно быть восстановлено как есть.
Однако для любого изображения, которого нет в наборе обучающих данных, автокодировщик не может выполнить реконструкцию, поскольку базовые свойства не применяются к конкретному изображению, которое сеть никогда не видела. Таким образом, изображения выбросов вызывают очень высокие потери при реконструкции и могут быть легко идентифицированы как аномалии с помощью соответствующих пороговых значений.
Введение в автоэнкодеры: основные выводы
Давайте быстро повторим все, что вы узнали в этом руководстве:
- Автоэнкодер — это тип без, используемый в нейронных сетях. присмотра метод обучения, который изучает эффективное представление данных (кодирование), обучая сеть игнорировать сигнал «шум».
- Автоэнкодеры доступны для удаления шума изображения、изображениесжатие,в некоторых случаях,Может даже использоваться для генерации данных изображений.
- Хотя на первый взгляд автоэнкодеры кажутся простыми (поскольку у них очень простая теоретическая основа), заставить их изучить осмысленные представления входных данных довольно сложно.
- и VAE и DAE по сравнению,картина Неполный автокодировщикиразреженный Автоэнкодеры, такие как автокодировщик, не имеют широкомасштабного применения в компьютерном зрении. 2013 Он до сих пор используется в работе с момента своего появления (автор Kingmaet предложенные другими).



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
