ЦВПР 2024 | Круто! ! Последний обзор модели диффузии-диффузии! 100+ статей, 40+ направлений исследований!
1. Улучшение модели диффузии.
1、Accelerating Diffusion Sampling with Optimized Time Steps

Диффузионно-вероятностные модели (DPM) показали замечательную эффективность при создании изображений с высоким разрешением, но их эффективность выборки все еще нуждается в повышении, поскольку обычно требуется большое количество шагов выборки. Последние достижения в применении решателей ОДУ более высокого порядка к DPM позволяют генерировать высококачественные изображения с меньшим количеством шагов выборки. Однако большинство методов выборки по-прежнему используют одинаковые временные шаги, что неоптимально при использовании небольшого количества шагов.
Чтобы решить эту проблему, предлагается общая структура для разработки задачи оптимизации, которая ищет более подходящий временной шаг для конкретного численного решателя ОДУ в DPM. Целью этой задачи оптимизации является минимизация расстояния между фундаментальным решением и соответствующим численным решением. Эффективное решение этой задачи оптимизации занимает не более 15 секунд.
Обширные эксперименты с DPM в пиксельном и скрытом пространстве, безусловной и условной выборке показывают, что в сочетании с современным методом выборки UniPC в сочетании с равномерным временным шагом для таких данных, как CIFAR-10. и ImageNet Set, согласно оценке FID, оптимизация временного шага значительно повышает производительность генерации изображений.
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models

Создание изображений высокого разрешения с использованием диффузионных моделей требует больших вычислительных затрат, что приводит к неприемлемой задержке для интерактивных приложений. DistriFusion предлагается решить эту проблему, используя параллелизм между несколькими графическими процессорами. Метод разделяет входные данные модели на несколько патчей и назначает каждый графическому процессору. Однако простая реализация этого алгоритма нарушит взаимодействие между патчами и приведет к потере точности, а учет этого взаимодействия приведет к огромным накладным расходам на связь.
Чтобы решить эту дилемму, наблюдается большое сходство между входными данными соседних этапов диффузии и предлагается параллелизм патчей смещения, который использует последовательный характер процесса диффузии путем повторного использования предварительно вычисленной карты признаков предыдущего временного шага, поскольку текущий шаг обеспечивает контекст . Таким образом, методы поддерживают асинхронную связь и могут передаваться по конвейеру посредством вычислений. Обширные эксперименты показывают, что этот метод можно применить к последнему Stable Diffusion XL без потери качества и добиться ускорения до 6,1 раз по сравнению с устройством NVIDIA A100. Исходный код уже открыт по адресу: https://github.com/mit-han-lab/distrifuser.
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models
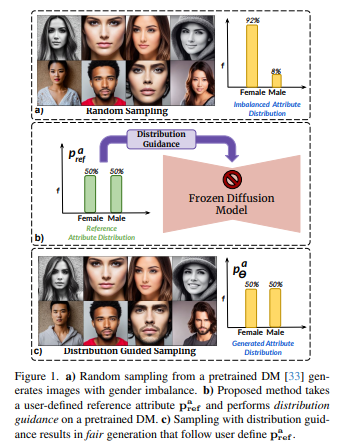
Модели диффузии (DM) отражают смещение, присутствующее в наборе обучающих данных. Особое беспокойство вызывает случай с лицами, когда DM отдают предпочтение определенным демографическим группам перед другими (например, женщины перед мужчинами). В этой работе предлагается метод устранения смещения DM, не полагаясь на дополнительные данные или переобучение модели.
В частности, предлагается метод управления распределением, который заставляет сгенерированное изображение следовать заданному распределению атрибутов. Для достижения этой цели скрытые функции шумоподавления UNet созданы с использованием богатой семантики групп населения, и эти функции можно использовать для управления созданием debias. Обучите предиктор распределения атрибутов (ADP), небольшой многоуровневый персептрон, который сопоставляет скрытые функции с распределениями атрибутов. ADP обучается с использованием псевдометок, созданных существующими классификаторами атрибутов. Введенные Руководство по распределению и ADP обеспечивают справедливое производство.
Этот метод уменьшает смещение по одному/множеству атрибутов и обеспечивает значительно лучшую базовую производительность, чем предыдущие методы, с точки зрения моделей безусловного и текстового распространения. Кроме того, предлагается следующая задача по обучению классификатора справедливых атрибутов путем генерации данных, которые перебалансируют обучающий набор.
4、Few-shot Learner Parameterization by Diffusion Time-steps
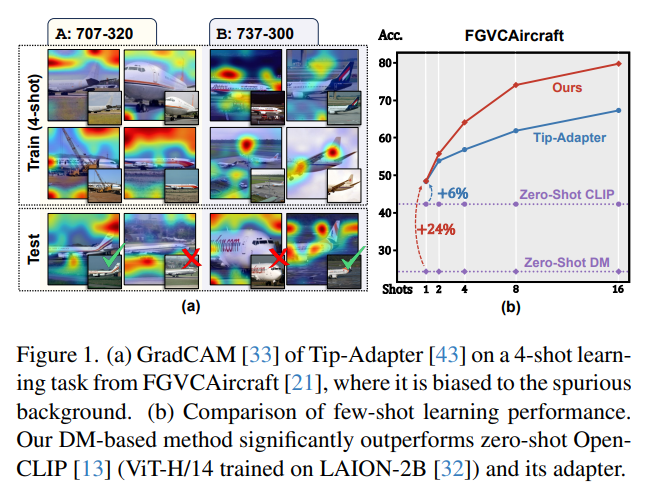
Даже при использовании больших мультимодальных базовых моделей обучение в несколько этапов остается сложной задачей. Без соответствующего индуктивного смещения трудно сохранить тонкие атрибуты класса, удаляя при этом заметные визуальные атрибуты, не имеющие отношения к метке класса.
Было обнаружено, что временные шаги модели диффузии (DM) могут изолировать тонкие атрибуты класса, т. Е. Поскольку прямая диффузия добавляет шум к изображению на каждом временном шаге, тонкие атрибуты часто теряются на более ранних временных шагах, чем существенные атрибуты. На основании этого предлагается обучающийся алгоритм с несколькими шагами по времени (TiF). Адаптеры низкого ранга для конкретного класса обучены для DM с текстовым условием, чтобы компенсировать недостающие атрибуты, позволяя точно реконструировать исходное изображение из зашумленного изображения с учетом подсказок. Таким образом, на меньших временных шагах адаптеры и подсказки по сути представляют собой параметризации с лишь тонкими свойствами класса. Для тестового изображения эту параметризацию можно использовать для извлечения только тонких атрибутов класса для классификации. При выполнении различных мелкодетализированных и настраиваемых задач обучения, состоящих из нескольких шагов, учащийся TiF значительно превосходит OpenCLIP и его адаптеры по производительности.
5、Structure-Guided Adversarial Training of Diffusion Models

Модели диффузии продемонстрировали превосходную эффективность в различных генеративных приложениях. Существующие модели в основном сосредоточены на моделировании распределения данных посредством минимизации взвешенных потерь, но их обучение в основном делает упор на оптимизацию на уровне экземпляра, игнорируя ценную структурную информацию в каждом мини-пакете данных.
Чтобы устранить это ограничение, введен метод состязательного обучения диффузионных моделей (SADM), ориентированный на структуру. Заставляет модель изучать структуру многообразия между выборками в каждом обучающем пакете. Чтобы гарантировать, что модель отражает реальную структуру многообразия в распределении данных, предлагается новый дискриминатор структуры, позволяющий различать реальную структуру многообразия и сгенерированную структуру многообразия, играя в игру с генератором диффузии посредством состязательного обучения.
SADM значительно улучшает существующие диффузионные преобразователи, превосходя существующие методы на 12 наборах данных в задачах генерации изображений и междоменной точной настройки для генерации изображений с учетом классов с разрешениями 256×256 и 512×512. Новые записи FID составляют 1,58 и 2,11 соответственно. .
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

Большинство моделей диффузии предполагают, что обратный процесс подчиняется распределению Гаусса. Однако это приближение не было строго проверено в особых точках (t=0 и t=1), особенно в сингулярностях. Неправильное обращение с этими точками может вызвать проблемы со средней яркостью в приложениях и ограничить создание изображений с чрезмерной яркостью или глубокой темнотой.
В данной статье рассматривается этот вопрос с теоретической и практической точки зрения. Во-первых, устанавливается граница погрешности аппроксимации обратного процесса и демонстрируются его гауссовы характеристики на сингулярных шагах по времени. На основе этого теоретического понимания подтверждается, что особая точка при t=1 может быть устранена условно, тогда как особая точка при t=0 является внутренним свойством. На основе этих важных выводов предлагается новый метод plug-and-play SingDiffusion для обработки выборки начальных сингулярных временных шагов, который может не только эффективно решить проблему средней яркости без дополнительного обучения, но и улучшить возможности их генерации, тем самым достигая значительно более низкий показатель FID. https://github.com/PangzeCheung/SingDiffusion
7、Boosting Diffusion Models with Moving Average Sampling in Frequency Domain
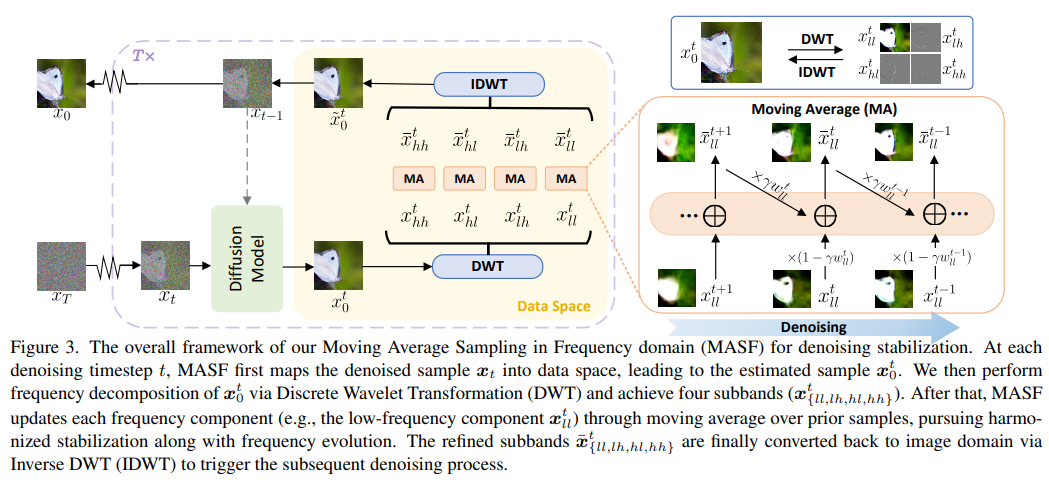
Модели диффузии в основном полагаются на текущую выборку для шумоподавления следующей выборки, что может привести к нестабильности. В этой статье итеративный процесс шумоподавления интерпретируется как оптимизация модели и используется механизм скользящего среднего для агрегирования всех предыдущих выборок. Вместо того, чтобы просто применять скользящее среднее к выборкам с шумоподавлением на разных временных шагах, выборки с шумоподавлением сначала сопоставляются с пространством данных, а затем выполняется скользящее среднее, чтобы избежать сдвигов распределения между временными шагами.
Поскольку диффузионная модель восстанавливает детали от низкочастотных компонентов к высокочастотным компонентам, выборка далее разбивается на различные частотные компоненты и скользящее среднее выполняется для каждого компонента отдельно. Полный метод называется «Выборка скользящего среднего в частотной области (MASF)». MASF можно легко интегрировать в основные предварительно обученные диффузионные модели и планы отбора проб. Обширные эксперименты с моделями безусловной и условной диффузии показывают, что MASF демонстрирует превосходную производительность по сравнению с базовыми моделями практически без дополнительных затрат на сложность.
8、Towards Memorization-Free Diffusion Models

Предварительно обученные диффузионные модели и их результаты широко и легко доступны благодаря их превосходной способности синтезировать высококачественные изображения и их открытому исходному коду. Пользователи могут столкнуться с риском судебных разбирательств в процессе вывода, поскольку модели имеют тенденцию запоминать и копировать данные обучения.
Чтобы решить эту проблему, представлена новая структура под названием «Руководство по борьбе с запоминанием (AMG)», которая использует три целевые стратегии управления памятью для борьбы с повторением изображений и подписей, а также с высокоспецифичными пользовательскими подсказками и другими основными причинами запоминания. Таким образом, AMG обеспечивает вывод без использования памяти, сохраняя при этом высокое качество изображения и выравнивание текста, используя синергию своих методов наведения, каждый из которых незаменим в своей области.
AMG также имеет инновационную систему автоматического обнаружения для обнаружения потенциальных воспоминаний на каждом этапе процесса вывода, что позволяет выборочно применять стратегии управления с минимальным вмешательством в исходный процесс выборки, чтобы сохранить полезность выходных данных. Применяйте AMG для различных задач генерации предварительно обученной вероятностной модели диффузии шумоподавления (DDPM) и стабильной диффузии. Результаты экспериментов показывают, что AMG является первым методом, позволяющим успешно устранить все экземпляры памяти с незначительным или незначительным влиянием на качество изображения и выравнивание текста, о чем свидетельствуют оценки FID и CLIP.
9、SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
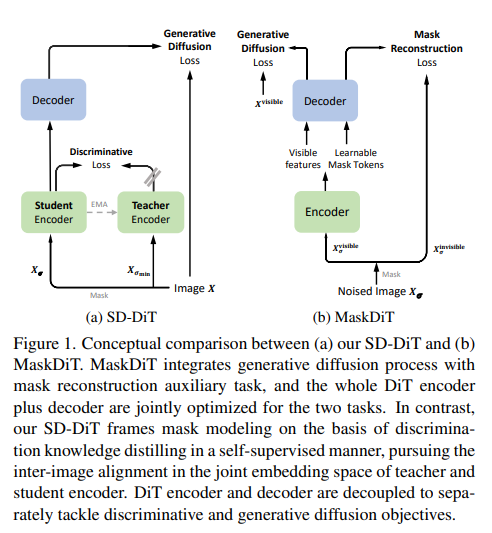
Диффузионный преобразователь (DiT) стал тенденцией в создании изображений. Учитывая чрезвычайно медленную конвергенцию типичного DiT, недавние прорывы были обусловлены стратегиями маскировки, которые повышают эффективность обучения за счет дополнительного обучения контексту внутри изображения. Однако стратегия маски по-прежнему имеет два ограничения: (а) различия в выводах обучения и (б) неоднозначная связь между реконструкцией маски и процессами генеративной диффузии, что приводит к неоптимальному обучению DiT.
Эта работа устраняет эти ограничения, раскрывая дискриминационные знания с самоконтролем для облегчения обучения DiT. Технически говоря, DiT построен по принципу «учитель-ученик». Дискриминантные пары учитель-ученик строятся на основе диффузного шума по одному и тому же вероятностному потоку обыкновенного дифференциального уравнения (PF-ODE). Вместо применения потерь реконструкции маски к кодеру и декодеру DiT, кодер и декодер DiT разъединяются для раздельной обработки дискриминативных и генеративных целей. В частности, новая дискриминационная потеря предназначена для поощрения выравнивания изображений в самоконтролируемом пространстве встраивания путем кодирования дискриминационных пар с использованием кодеров DiT учащихся и учителей. После этого выборки студентов подаются в студенческий декодер DiT для выполнения типичной задачи генеративного распространения. С набором данных ImageNet проводятся обширные эксперименты, и этот метод обеспечивает конкурентоспособный баланс между стоимостью обучения и генерационной мощностью.
2. Управляемая диаграмма Винсента.
10、ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models

Генерации 3D-ресурсов уделяется много внимания, вдохновленное недавним успехом создания 2D-контента с текстовым управлением. Существующие методы преобразования текста в 3D используют предварительно обученные модели диффузии текста в изображение для решения проблем оптимизации или точной настройки. синтетические данные, что часто приводит к созданию нефотореалистичных 3D-объектов без фона.
В этой статье предлагается использовать предварительно обученную модель преобразования текста в изображение в качестве априорной и научиться генерировать многовидовые изображения из одного процесса шумоподавления на реальных данных. В частности, объемный 3D-рендеринг и межкадровые уровни внимания интегрированы в каждый блок существующей модели преобразования текста в изображение. Кроме того, авторегрессионная генерация предназначена для визуализации более согласованных трехмерных изображений с любой точки зрения. Модель обучена с использованием набора данных реальных объектов и продемонстрировала свою способность генерировать экземпляры с различными высококачественными формами и текстурами.
Полученные результаты являются последовательными и имеют хорошее визуальное качество по сравнению с существующими методами (снижение FID на 30% и снижение KID на 37%). https://lukashoel.github.io/ViewDiff/
11、NoiseCollage: A Layout-Aware Text-to-Image Diffusion Model Based on Noise Cropping and Merging
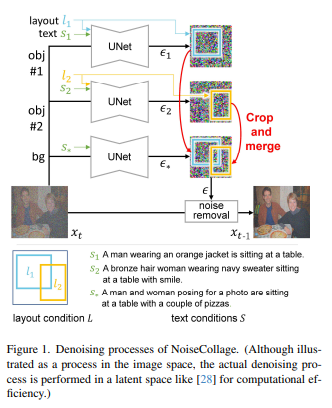
Генерация текста в изображение с учетом макета — это задача создания многообъектных изображений, которые отражают условия макета и условия текста. Текущие модели распространения текста в изображения с учетом макета по-прежнему страдают от некоторых проблем, включая несоответствие между текстом и условиями макета и снижение качества генерируемых изображений.
В этой статье для решения этих проблем предлагается новая модель диффузии текста в изображение с учетом макета, называемая NoiseCollage. В процессе шумоподавления NoiseCollage независимо оценивает шум каждого объекта, затем обрезает и объединяет их в один шум. Эта операция помогает избежать несоответствия условий, другими словами, она помещает нужный объект в нужное место.
Результаты качественной и количественной оценки показывают, что NoiseCollage превосходит по производительности некоторые современные модели. Также было показано, что NoiseCollage можно интегрировать с ControlNet, используя края, эскизы и скелеты поз в качестве дополнительных условий. Результаты экспериментов показывают, что эта интеграция может повысить точность компоновки ControlNet. https://github.com/univ-esuty/noisecollage
12、Discriminative Probing and Tuning for Text-to-Image Generation

Несмотря на достижения в области генерации текста в изображение, предыдущие методы часто страдают от проблем несовпадения текста и изображения, таких как путаница отношений в сгенерированных изображениях. Существующие решения включают операции перекрестного внимания для лучшего понимания комбинаций или интеграцию больших языковых моделей для улучшения планирования помещений. Однако возможности выравнивания, присущие моделям T2I, все еще недостаточны.
Рассматривая связь между генеративным и дискриминативным моделированием, мы предполагаем, что дискриминационная способность моделей T2I может отражать их возможности выравнивания текста и изображения во время генеративного процесса. Ввиду этого рекомендуется повысить различительную способность моделей T2I для достижения более точного выравнивания текста и изображения при генерации.
Предлагается дискриминационный адаптер, основанный на модели T2I, для изучения их дискриминационных возможностей в двух репрезентативных задачах и использования дискриминационной точной настройки для улучшения калибровки текста и изображения. Преимущество дискриминационного адаптера заключается в том, что механизм самокорректировки может использовать дискриминантный градиент для лучшего согласования сгенерированного изображения с текстовыми подсказками во время вывода.
Комплексная оценка трех эталонных наборов данных (включая сценарии распределения и выхода из распределения) демонстрирует превосходную генеративную эффективность метода. В то же время он обеспечивает самые современные дискриминационные характеристики при решении двух дискриминационных задач по сравнению с другими генеративными моделями. https://github.com/LgQu/DPT-T2I
13、Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with LLMs
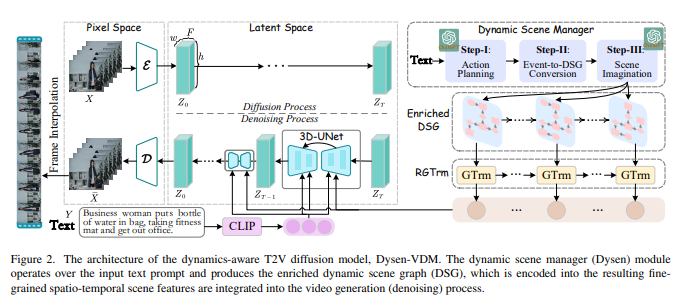
Синтез текста в видео (T2V) привлекает все большее внимание в научных кругах, где новая диффузионная модель (DM) оказалась более эффективной по производительности, чем предыдущие методы. Хотя существующие современные DM хорошо справляются с созданием видео высокого разрешения, они все еще имеют значительные ограничения при моделировании сложной временной динамики (например, неупорядоченное движение, грубое видеодвижение).
В этой работе изучаются методы улучшения восприятия DM динамики видео для генерации высококачественного T2V. Вдохновленный человеческой интуицией, разработан новый модуль динамического менеджера сцен (называемый Dysen), включающий (шаг 1) извлечение ключевых действий в соответствующем временном порядке из входного текста (шаг 2) преобразование плана действий в граф динамической сцены (DSG). представление и (шаг 3) обогатить сцену в DSG, чтобы предоставить достаточные и разумные детали. Используя существующие мощные LLM (такие как ChatGPT) для контекстного обучения, Dysen достигает (почти) динамического временного понимания на человеческом уровне. Наконец, видео DSG с богатой детализацией боевых сцен кодируется в мелкозернистые пространственно-временные функции и интегрируется в базовый T2V DM для генерации видео.
Эксперименты с популярным набором данных T2V показывают, что Dysen-VDM неизменно превосходит предыдущие методы, имея значительные преимущества, особенно в сложных боевых сценах.
14、Face2Diffusion for Fast and Editable Face Personalization

Персонализация лиц направлена на вставку конкретных лиц с изображений в предварительно обученный текст в модели распространения изображений. Однако предыдущие методы по-прежнему имеют проблемы с сохранением сходства идентичности и редактируемости, поскольку они подходят для обучающих выборок.
В этой статье предлагается метод Face2Diffusion (F2D) для легко редактируемой персонализации лица. Основная идея F2D — удалить из процесса обучения информацию, не имеющую отношения к личности, чтобы предотвратить проблемы переобучения и улучшить редактируемость закодированных лиц. F2D содержит следующие три новых компонента: 1) Многомасштабный кодировщик идентификационных данных обеспечивает четкое разделение идентификационных функций, сохраняя при этом преимущества многомасштабной информации, тем самым улучшая разнообразие поз камеры. 2) Управление выражением лица отделяет выражение лица от личности, улучшая управляемость выражения лица. 3) Регуляризация шумоподавления на основе категорий побуждает модель научиться шумоподавлять лица, тем самым улучшая текстовое выравнивание фона.
Обширные эксперименты с набором данных FaceForensics++ и различными подсказками показывают, что этот метод обеспечивает лучший баланс между идентичностью и точностью текста по сравнению с предыдущими современными методами. https://github.com/mapooon/Face2Diffusion
15、LeftRefill: Filling Right Canvas based on Left Reference through Generalized Text-to-Image Diffusion Model

В этой статье предлагается LeftRefill, новый метод, который эффективно использует большие модели диффузии текста в изображение (T2I) для синтеза изображений на основе ссылок. Как следует из названия, LeftRefill объединяет эталонное представление и целевое представление по горизонтали в качестве общего ввода. Эталонное изображение занимает левую сторону, а целевой холст — правую. Затем LeftRefill рисует целевой холст справа на основе левой ссылки и конкретных инструкций по задаче. Эта форма задачи похожа на восстановление контекста, похожее на то, что сделал бы человек-художник.
Эта новая форма эффективно изучает структурные и текстурные соответствия между эталоном и целью без необходимости использования дополнительных кодировщиков изображений или адаптеров. Информация о задачах и представлениях вводится через модуль перекрестного внимания в модели T2I, а эталонная возможность множественного представления дополнительно демонстрируется через переработанный модуль собственного внимания. Это позволяет LeftRefill выполнять согласованную генерацию в качестве общей модели без необходимости тонкой настройки или модификации модели во время тестирования. Таким образом, LeftRefill можно рассматривать как простую и унифицированную структуру для решения проблемы синтеза по ссылкам.
Например, LeftRefill используется для решения двух различных задач: восстановления на основе эталонов и синтеза новой перспективы на основе предварительно обученной модели StableDiffusion. https://github.com/ewrfcas/LeftRefill
16、InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
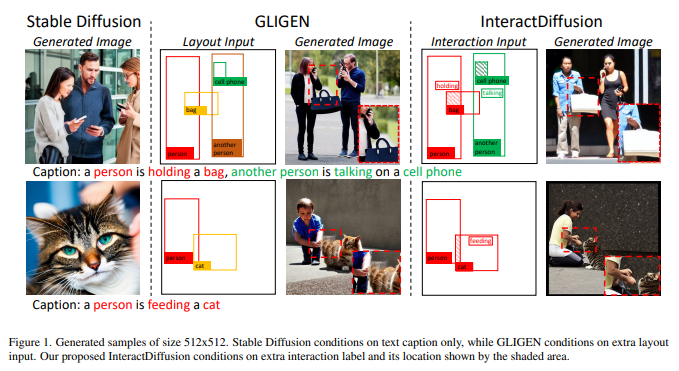
Крупномасштабная модель диффузии изображения в текст (T2I) демонстрирует способность генерировать связные изображения на основе текстовых описаний, обеспечивая широкий спектр приложений для создания контента. Несмотря на то, что существует некоторый контроль над такими аспектами, как положение объекта, поза и контуры изображения, все еще существует пробел в управлении взаимодействием между объектами в сгенерированном контенте. Управление взаимодействием между объектами в сгенерированных изображениях может привести к значимым приложениям, таким как создание реалистичных сцен с интерактивными персонажами.
В этой работе изучается проблема согласования моделей диффузии T2I с информацией о взаимодействии человека и объекта (HOI), которая состоит из троичных меток (человек, действие, объект) и соответствующих ограничивающих рамок. Предлагается модель управления взаимодействием под названием InteractDiffusion, которая расширяет существующую предварительно обученную модель диффузии T2I, чтобы обеспечить лучший условный контроль взаимодействий. В частности, информация HOI токенизируется, и взаимосвязь между ними изучается посредством интерактивного внедрения. Уровень условного самообслуживания, который обучает токены HOI визуальным токенам, обучается для лучшего кондиционирования существующих моделей диффузии T2I.
Модель обладает способностью контролировать взаимодействие и положение и намного превосходит существующие базовые модели по показателям обнаружения HOI, а также по более высокой точности FID и KID. https://jiuntian.github.io/interactdiffusion/
17、MACE: Mass Concept Erasure in Diffusion Models

Быстрое распространение крупномасштабных моделей распространения текста в изображения вызвало растущую обеспокоенность по поводу их потенциального неправильного использования для создания вредного или вводящего в заблуждение контента. В этом документе предлагается структура тонкой настройки под названием MACE для задачи стирания концепции MASS (MACE). Эта задача предназначена для предотвращения создания моделью изображений с нежелательными концепциями при появлении соответствующего запроса. Существующие методы исключения понятий обычно позволяют обрабатывать менее пяти понятий, при этом трудно найти баланс между устранением синонимов понятий (широта) и сохранением нерелевантных понятий (специфичность). Напротив, MACE изменил ситуацию, успешно расширив объем исключения до 100 концепций и добившись эффективного баланса между общностью и конкретикой. Это достигается за счет использования уточнения перекрестного внимания в закрытой форме и тонкой настройки LoRA, совместно исключая информацию из нежелательных концепций.
Более того, MACE объединяет несколько LoRA без взаимного вмешательства. MACE тщательно оценивается по четырем различным задачам: устранение объектов, устранение знаменитостей, устранение явного контента и устранение художественного стиля. Результаты показывают, что MACE превосходит предыдущие методы во всех задачах оценки. https://github.com/Shilin-LU/MACE
18、MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis

предложить задачу создания нескольких экземпляров (MIG) для одновременного создания нескольких экземпляров с разнообразным управлением в одном изображении. Учитывая предопределенный набор координат и соответствующие им описания, задача состоит в том, чтобы гарантировать, что сгенерированные экземпляры расположены точно в указанных местах и чтобы все свойства экземпляров соответствовали соответствующим описаниям. Это расширяет сферу текущих исследований генерации единичных экземпляров, поднимая их до более разнообразного и практического измерения.
Вдохновленный идеей «разделяй и властвуй», для решения задач MIG представлен инновационный подход под названием Multiple Instance Generation Controller (MIGC). Сначала задача MIG разбивается на несколько подзадач, каждая из которых предполагает затенение одного экземпляра. Для обеспечения точной раскраски каждого экземпляра введен механизм расширенного внимания. Наконец, все цветные экземпляры объединяются, предоставляя необходимую информацию (SD) для точного создания стабильного распространения между несколькими экземплярами. Для оценки эффективности генеративной модели при выполнении задачи MIG предоставляются тест COCO-MIG и процесс оценки.
Обширные эксперименты проводятся с предлагаемым тестом COCO-MIG, а также с различными широко используемыми тестами. Результаты оценки демонстрируют отличные возможности управления моделью с точки зрения количества, местоположения, атрибутов и взаимодействий. https://migcproject.github.io/
19、One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications

Широкое использование коммерческих моделей диффузии и моделей распространения с открытым исходным кодом (DM) при преобразовании текста в изображение привело к снижению рисков и предотвращению нежелательного поведения. Все существующие в академическом сообществе методы исключения концепций основаны на полной настройке параметров или на основе спецификаций, в результате чего наблюдаются следующие проблемы: 1) Изменения генерации в направлении эрозии: дрейф параметров в процессе целевого исключения приведет к изменения в процессе генерации и потенциальная деформация даже в той или иной степени разрушат другие концепции, что более очевидно в случае исключения нескольких концепций. 2) Невозможность переноса и неэффективное развертывание: устранение предыдущей концепции, специфичной для модели, препятствует гибкому сочетанию; концепции и бесплатное использование других моделей. Перенос, в результате чего стоимость развертывания растет линейно по мере увеличения количества сценариев развертывания.
Чтобы добиться неинтрузивного, точного, настраиваемого и переносимого исключения, структура исключения построена на 1D-адаптере, позволяющем одновременно исключать несколько концепций из большинства DM в нескольких сценариях применения исключения. Концепция. Полупроницаемые структуры вводятся в любую твёрдую ткань в виде мембраны (СПМ), чтобы научиться целенаправленному устранению и эффективно смягчить изменения и явления эрозии с помощью новой стратегии тонкой настройки скрытого закрепления. После получения SPM можно гибко комбинировать и вставлять в другие DM без специальной доводки, а также своевременно и эффективно адаптировать к различным сценариям. В процессе генерации механизм активации транспорта динамически регулирует проницаемость каждого СЗМ в ответ на различные входные сигналы, еще больше сводя к минимуму влияние на другие концепции.
Количественные и качественные результаты примерно по 40 концепциям, 7 DM и 4 приложениям по исключению демонстрируют превосходные возможности SPM по исключению. https://lyumengyao.github.io/projects/spm
20、FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
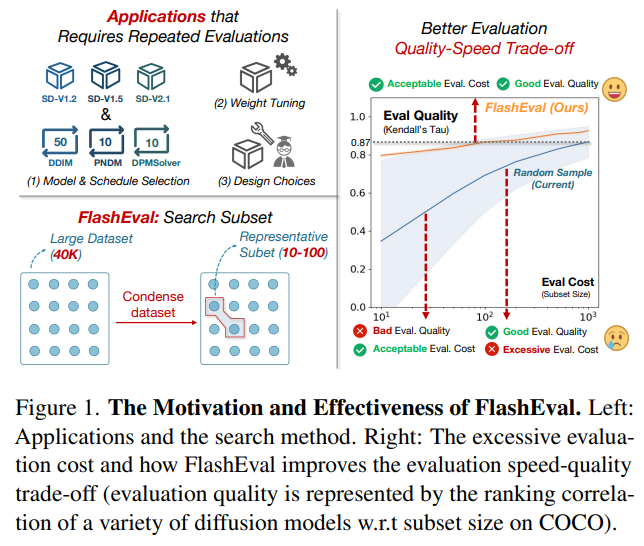
В последние годы был достигнут значительный прогресс в разработке генеративных моделей преобразования текста в изображение. Оценка качества создаваемых моделей является одним из важных этапов процесса разработки. Процесс оценки может потребовать значительных вычислительных ресурсов, что делает нецелесообразным проведение необходимой регулярной оценки производительности модели (например, мониторинг прогресса обучения). Поэтому стремятся повысить эффективность оценки путем выбора репрезентативного подмножества набора данных текстового изображения.
В этой статье систематически изучаются варианты дизайна, включая критерии выбора (особенности текстуры или метрики на основе изображений) и степень детализации выбора (уровень сигнала или уровень набора). Обнаружив, что выводы из предыдущей работы по выбору подмножества обучающих данных не применимы к этой проблеме, был предложен FlashEval, алгоритм итеративного поиска, предназначенный для оценки выбора данных. Продемонстрируйте эффективность FlashEval при ранжировании моделей диффузии с различными конфигурациями, включая архитектуру, уровень квантования и сэмплер, в наборах данных COCO и DiffusionDB. Подмножество из 50 элементов, в котором осуществляется поиск, обеспечивает качество оценки, сравнимое с подмножеством из 500 элементов, выбранным случайным образом для аннотаций COCO на невидимых моделях, что приводит к десятикратному ускорению оценки. Сжатые подмножества этих часто используемых наборов данных будут выпущены, чтобы облегчить разработку и оценку алгоритмов распространения, а FlashEval будет открыт с открытым исходным кодом в качестве инструмента для сжатия будущих наборов данных.
3. Миграция стилей
21、DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations

Модели, основанные на диффузии текста в изображение, имеют большой потенциал в передаче эталонных стилей. Однако современные методы, основанные на кодировании, существенно ухудшают управляемость текста моделями преобразования текста в изображение при передаче стилей. В данной статье DEADiff предлагает решить эту проблему, приняв следующие две стратегии: 1) Механизм разделения стиля и семантики эталонного изображения. Представление разделенного объекта сначала извлекается с помощью Q-Formers на основе различных текстовых описаний. Затем они вводятся во взаимоисключающие подмножества слоя перекрестного внимания для достижения лучшего разложения. 2) Нереконструктивный метод обучения. Q-Formers обучается с использованием пар изображений вместо идентичных целей, где эталонное изображение и реальное изображение имеют одинаковый стиль или семантику.
Показано, что DEADiff достигает наилучших результатов в визуальной стилизации и показывает лучший баланс между управляемостью текста и стилистическим сходством с эталонными изображениями как количественно, так и качественно. https://tianhao-qi.github.io/DEADiff/
22、Deformable One-shot Face Stylization via DINO Semantic Guidance

В данной статье рассматривается проблема стилизации лица One-shot, уделяя особое внимание как внешнему виду, так и структуре. Изучение стилизации лица с учетом деформации, которая отличается от традиционных эталонных стилей с одним изображением. Суть метода заключается в использовании визуального преобразователя с самоконтролем, в частности DINO-ViT, для создания мощного и последовательного представления структуры лица, охватывающего как реальные, так и стилизованные поля. Процесс стилизации сначала реализуется путем интеграции пространственного преобразователя (STN) путем адаптации генератора StyleGAN к состоянию с учетом деформации. Затем, руководствуясь семантикой DINO, вводятся два инновационных ограничения для точной настройки генератора: i) потери при деформации направления, которые корректируют вектор направления в пространстве DINO; ii) относительная структурная согласованность, основанная на самоподобии; Токены DINO Ограничения для обеспечения разнообразия генерации. Кроме того, используется смешение стилей, чтобы генерация цветов соответствовала эталонному изображению, уменьшая несогласованные соответствия.
Этот метод обеспечивает лучшую деформируемость при однократной стилизации лица и достигает значительной эффективности примерно за 10 минут точной настройки. Обширные качественные и количественные сравнения демонстрируют превосходство нашего подхода в стилизации лица. https://github.com/zichongc/DoesFS
23、One-Shot Structure-Aware Stylized Image Synthesis

Хотя модели на основе GAN успешно справляются с задачами стилизации изображений, им часто сложно сохранить структурную целостность при стилизации различных входных изображений. В последнее время для стилизации изображений используются диффузионные модели, но они по-прежнему не способны поддерживать исходное качество входного изображения.
В этой статье предлагается OSASIS: новый метод стилизации One-Shot, обеспечивающий надежность, сохраняющую структуру. Мы демонстрируем, что OSASIS может эффективно отделить семантику и структуру изображения, позволяя контролировать уровень содержания и стиля в заданных входных данных. Применяйте OSASIS к различным экспериментальным настройкам, включая стилизацию с использованием эталонных изображений вне домена и стилизацию с использованием текстовых операций. Результаты показывают, что OSASIS хорошо работает в качестве метода стилизации, особенно для входных изображений, редко встречающихся при обучении, что представляет собой многообещающее решение для стилизации диффузионной модели.
4. Создание портрета
24、Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis

Модели диффузии использовались при синтезе изображений человека с учетом позы. Однако существующие методы только выравнивают внешний вид человека с целевой позой. Из-за отсутствия высокого уровня семантического понимания исходного изображения человека могут возникнуть проблемы с переподгонкой.
В этой статье предлагается новый метод синтеза изображений человека с учетом позы — латентная диффузия от грубого к мелкому (CFLD). Парадигма обучения, основанная исключительно на изображениях, разработана для управления процессом генерации предварительно обученной модели распространения текста в изображение при отсутствии пар изображение-текст и текстовых подсказок. Разработайте декодер улучшения восприятия, который постепенно уточняет набор обучаемых запросов и извлекает семантическое понимание изображений людей в виде крупнозернистых сигналов. Это позволяет разделить детализированный внешний вид и обеспечить контроль информации на разных этапах, избегая тем самым потенциальных проблем переобучения.
Для создания более реалистичных деталей текстуры предлагается гибридный модуль детального внимания, который кодирует многомасштабные мелкозернистые особенности внешнего вида в термины смещения для улучшения крупнозернистых сигналов. Количественные и качественные эксперименты на бенчмарке DeepFashion демонстрируют превосходство метода над существующими методиками с точки зрения PGPIS. https://github.com/YanzuoLu/CFLD
25、High-fidelity Person-centric Subject-to-Image Synthesis

Методы создания целевых предметных изображений сталкиваются с серьезными проблемами при создании личностно-ориентированных изображений. Причина в том, что они изучают семантическую сцену и генерацию персонажей путем точной настройки общей предварительной тренировки, которая включает в себя неустранимые дисбалансы обучения. Для создания реалистичных персонажей требуется достаточная настройка предварительно обученных моделей, что неизбежно приводит к тому, что модели забывают богатые априорные семантические сцены и подгоняют генерацию сцены под обучающие данные. Более того, даже после достаточной тонкой настройки эти методы по-прежнему не могут генерировать персонажей с высокой точностью, поскольку совместное изучение сцены и генерации персонажей также приводит к компромиссам в качестве.
В этой статье предлагается Face-diffuser, эффективный конвейер совместной генерации, позволяющий устранить вышеупомянутый дисбаланс обучения и компромиссы в качестве. В частности, для генерации сцен и персонажей сначала разрабатываются две специализированные предварительно обученные модели диффузии, а именно модель диффузии, управляемая текстом (TDM) и модель диффузии с расширенным субъектом (SDM). Процесс выборки разделен на три последовательных этапа, а именно построение семантической сцены, слияние агента и сцены и улучшение агента. Первый и заключительный этапы выполняются TDM и SDM соответственно. Этап слияния субъекта и сцены реализован с помощью нового и эффективного механизма, а именно адаптивного слияния шума на основе значимости (SNF). В частности, он основан на основном наблюдении этой статьи о том, что существует тесная связь между независимыми от классификатора ответными указаниями и значимостью сгенерированных изображений. На каждом временном этапе SNF использует уникальные сильные стороны каждой модели и автоматически выполняет пространственное смешивание двух шумов прогнозирования модели таким образом, чтобы адаптироваться к значимости, и все это можно легко интегрировать в процесс выборки DDIM.
Эксперименты подтверждают превосходный эффект Face-diffuser при создании высококачественных изображений человека. https://github.com/CodeGoat24/Face-diffuser
26、Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
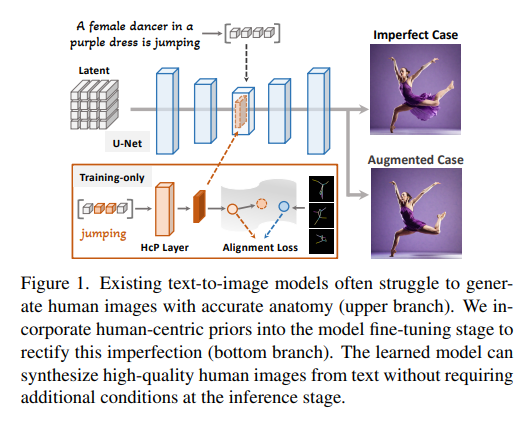
Традиционные модели диффузии текста в изображение с трудом создают точные изображения людей, например, неестественные позы или непропорциональные конечности. Существующие методы в основном решают эту проблему путем добавления дополнительных изображений или телесно-центрированных априорных данных (таких как карты позы или глубины) на этапе точной настройки модели. В этой статье исследуется интеграция этих телесно-центрированных априорных данных непосредственно на этапе точной настройки модели, что устраняет необходимость в дополнительных условиях на этапе вывода.
Эта идея реализуется путем введения потери выравнивания центра человека для улучшения информации, связанной с человеком, из текстовых подсказок на картах перекрестного внимания. Чтобы обеспечить богатство семантических деталей и точность структуры человеческого тела в процессе тонкой настройки, вводятся масштабные и пошаговые ограничения на основе углубленного анализа уровня перекрестного внимания.
Результаты экспериментов показывают, что этот метод позволил значительно улучшить создание высококачественных изображений персонажей на основе подсказок, написанных пользователями. https://hcplayercvpr2024.github.io/
27、A Unified and Interpretable Emotion Representation and Expression Generation
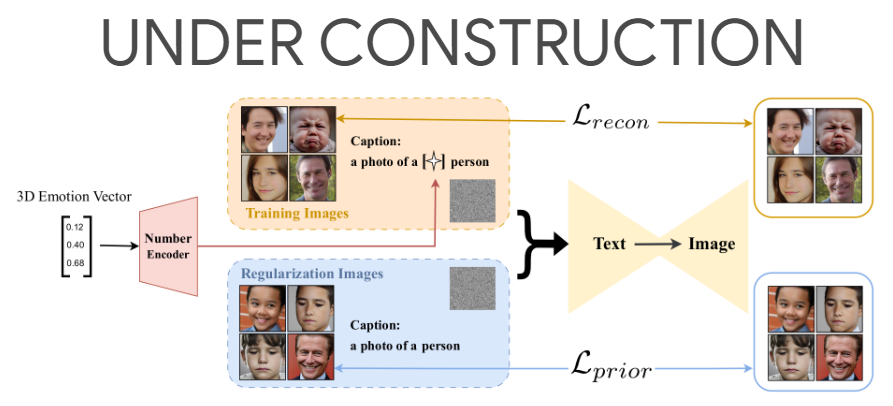
Эмоции, такие как счастье, печаль и страх, легко понять и обозначить. Эмоции часто бывают сложными, например, счастливое удивление, и их можно сопоставить с единицами действия (ЕД), используемыми для выражения эмоций. Эмоции непрерывны и представлены моделью валентности возбуждения (AV). Для лучшего представления и понимания эмоций предполагается объединить эти четыре модальности, а именно классическую, составную, AU и AV. Однако это объединение остается неизвестным.
В этой работе предлагается интерпретируемая и унифицированная модель эмоций под названием C2A2. Также был разработан метод использования меток неунифицированных моделей для аннотирования новых унифицированных моделей. Наконец, модель диффузии, обусловленная текстом, модифицируется для понимания непрерывных цифр, а затем используется единая модель эмоций для генерации непрерывных выражений.
Количественные и качественные эксперименты показывают, что создаваемые изображения богаты и передают тонкие выражения. Эта работа позволяет более детально генерировать выражения в сочетании с другими текстовыми данными и в то же время предоставляет новое пространство для обозначения эмоций. https://emotion-diffusion.github.io/
28、CosmicMan: A Text-to-Image Foundation Model for Humans

Мы предлагаем CosmicMan, базовую модель преобразования текста в изображение для создания высококачественных изображений человека. В отличие от текущих базовых моделей, которые привязаны к качеству изображения человеческого тела и несовпадению текста и изображения, CosmicMan способен генерировать реалистичные изображения человеческого тела с детальным внешним видом, рациональной структурой и точным выравниванием текста и изображения, а также предоставлять подробные и плотные описания. Ключом к CosmicMan являются новые размышления и взгляды на данные и модели:
(1) Обнаружение высококачественных данных и масштабируемых процессов генерации данных имеют решающее значение для конечных результатов моделей обучения. Поэтому предлагается новая парадигма генерации данных — «Аннотировать кого угодно» — как непрерывный процесс генерации данных для создания высококачественных данных посредством экономичного аннотирования. На основе этого был создан набор данных CosmicMan-HQ 1.0, который содержит 6 миллионов высококачественных реальных изображений человеческого тела со средним разрешением 1488×1255 и снабжен точными текстовыми аннотациями из 115 миллионов атрибутов, охватывающих разные уровни.
(2) Базовая модель преобразования текста в изображение, специально разработанная для создания изображений человеческого тела, должна быть практичной, легко интегрируемой в последующие задачи и в то же время эффективной для создания высококачественных изображений человеческого тела. Поэтому предлагается моделировать взаимосвязь между плотным текстовым описанием и пикселями изображения в разложенном виде, а также предлагается структура обучения «Разложение-перефокусировка внимания (Смелость)». Он плавно разлагает функции перекрестного внимания в существующих моделях диффузии текста в изображение и обеспечивает настройку фокуса внимания без добавления дополнительных модулей. С помощью Daring мы показываем, что явная дискретизация непрерывного текстового пространства на несколько основных групп, соответствующих структуре человеческого тела, является ключом к легкому решению проблем смещения. https://cosmicman-cvpr2024.github.io/
29、DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
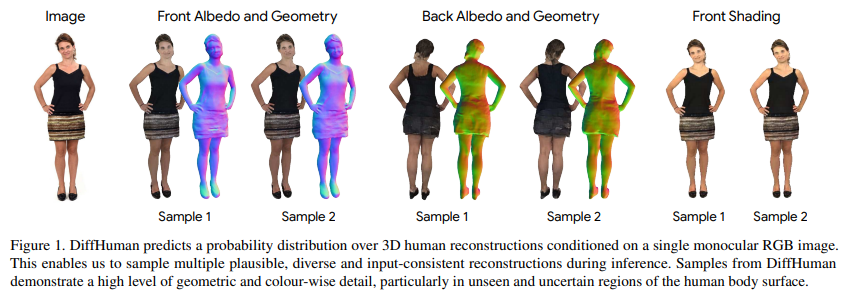
Мы предлагаем DiffHuman — метод реалистичной реконструкции человеческого тела по одному RGB-изображению. Эта проблема по своей сути неразрешима, и большинство методов являются детерминистическими и выдают единственное решение, что часто приводит к появлению невидимых или неопределенных областей с отсутствием геометрических деталей и размытием. DiffHuman прогнозирует распределение вероятностей при условии 3D-реконструкции на основе входного 2D-изображения, которое может отбирать несколько подробных 3D-персонажей, соответствующих входному изображению.
DiffHuman реализован как модель условной диффузии для шумоподавления 2D-наблюдений с выравниванием по пикселям и выборки 3D-персонажей путем итеративного шумоподавления 2D-рендеринга прогнозируемых 3D-представлений. Кроме того, введена нейронная сеть-генератор, позволяющая значительно сократить время работы (ускорение в 55 раз), тем самым реализуя новую структуру диффузии с двумя ветвями.
Результаты экспериментов показывают, что DiffHuman способен выдавать разнообразные и подробные результаты реконструкции невидимых или неопределенных частей тела человека на входном изображении, при этом конкурируя с современными методами реконструкции видимых поверхностей.
30、Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-On

Виртуальная примерка изображений становится все более важной для онлайн-шоппинга. Цель состоит в том, чтобы синтезировать образ указанного человека в указанной одежде. Методы, основанные на моделях диффузии, в последнее время стали популярными благодаря их превосходной эффективности в задачах синтеза изображений. Однако эти методы обычно используют дополнительные кодеры изображений и полагаются на передачу текстуры с одежды на изображения человека через механизмы внимания, что влияет на эффективность и точность подгонки.
Для решения этих проблем предлагается модель диффузии с сохранением текстуры (TPD) для виртуальной примерки, чтобы повысить точность результатов без введения дополнительного кодировщика изображений. Итак, внесите свой вклад двумя способами. Во-первых, изображения человека в маске и эталонной одежды объединяются по пространственному измерению, а выходное изображение UNet с шумоподавлением генеративной модели используется в качестве входных данных. Это позволяет исходному слою самообслуживания в модели диффузии добиться эффективной и точной передачи текстуры. Во-вторых, предлагается метод, основанный на диффузии, для прогнозирования точной ремонтной маски на основе портретных и эталонных изображений одежды, чтобы еще больше повысить надежность результатов примерки. Кроме того, предсказание маски и синтез изображений интегрированы в компактную модель.
Результаты экспериментов показывают, что метод можно применять для решения различных задач по подгонке, таких как подгонка одежды к персонажам и подгонка между персонажами, и значительно превосходит существующие методы в популярных базах данных VITON, VITON-HD.
5. Супер оценка изображения
31、Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder

Суперразрешение (SR) и генерация изображений являются важными задачами компьютерного зрения и широко применяются в реальных приложениях. Однако большинство существующих методов генерируют изображения только с фиксированным увеличением и склонны к чрезмерному сглаживанию и артефактам. Кроме того, существуют недостатки в разнообразии выходных изображений и согласованности в разных масштабах. В большинстве связанных работ неявные нейронные представления (INR) применяются к моделям шумоподавления диффузии для получения разнообразных и высококачественных результатов СР при непрерывном разрешении. Поскольку модель работает в пространстве изображений, для создания изображений с более высоким разрешением требуется больше памяти и времени вывода, и она не может поддерживать согласованность в зависимости от масштаба.
В этой статье предлагается новый конвейер для сверхразрешения входных изображений в произвольных масштабах или создания новых изображений из случайного шума. Метод состоит из предварительно обученного автокодировщика, модели скрытой диффузии и неявного нейронного декодера, а также их стратегий обучения. Этот метод использует процесс диффузии в скрытом пространстве и, следовательно, эффективен и остается согласованным с пространством выходного изображения, декодируемым MLP, в любом масштабе. Более конкретно, декодер произвольного масштаба объединяется предварительно обученным симметричным декодером без повышения дискретизации автокодировщика и локальной неявной функцией изображения (LIIF). Совместное изучение скрытых процессов диффузии посредством шумоподавления и потерь выравнивания. Ошибки в выходном изображении распространяются обратно через фиксированный декодер для улучшения качества вывода.
Благодаря обширным экспериментам с использованием нескольких общедоступных тестов для решения двух задач, включая сверхразрешение изображений и генерацию новых изображений в произвольных масштабах, этот метод превосходит аналогичные методы по таким показателям, как качество изображения, разнообразие и согласованность масштаба. Это значительно лучше, чем аналогичные предыдущие методы с точки зрения скорости вывода и использования памяти.
32、Diffusion-based Blind Text Image Super-Resolution

Восстановление испорченных текстовых изображений с низким разрешением — сложная задача, особенно при работе с текстовыми изображениями на китайском языке со сложными штрихами и серьезной деградацией в реалистичных сложных ситуациях. Гарантия точности текста и аутентичности стиля очень важна для высококачественного текстового изображения со сверхвысоким разрешением. В последнее время диффузионные модели добились успеха в синтезе и восстановлении естественных изображений благодаря своим мощным возможностям моделирования распределения данных и возможностям генерации данных.
В этой работе предлагается метод восстановления текстовых изображений, основанный на модели распространения изображений (IDM), который может восстанавливать текстовые изображения с реалистичными стилями. Для диффузионных моделей они подходят не только для моделирования распределения реальных изображений, но и для изучения распределения текста. Поскольку априоры текста очень важны для обеспечения правильности восстановленной текстовой структуры на основе существующих произведений искусства, для распознавания текста также предлагается модель распространения текста (TDM), которая может помочь IDM генерировать текстовые изображения с правильной структурой. Также предлагается мультимодальный гибридный модуль (MoM), позволяющий этим двум моделям диффузии взаимодействовать друг с другом на всех этапах диффузии.
Обширные эксперименты на синтетических и реальных наборах данных показывают, что сверхразрешение изображений слепого текста на основе диффузии (DiffTSR) может одновременно восстанавливать текстовые изображения с более точной текстовой структурой и более реалистичным внешним видом.
33、Text-guided Explorable Image Super-resolution

В этой статье рассматривается проблема создания решений сверхразрешения для изображений в открытой области с нулевым кадром и текстовым управлением. Цель состоит в том, чтобы позволить пользователям исследовать различные семантически точные реконструкции, которые остаются совместимыми с входными данными с низким разрешением, без явного обучения этим конкретным ухудшениям.
Предлагаются два метода суперразрешения с нулевым управлением текстом: один заключается в изменении процесса генерации модели диффузии текста в изображение (T2I) для обеспечения согласованности с входными данными с низким разрешением, а другой заключается в включении языкового руководства. в метод диффузионного восстановления с нулевым выстрелом. Мы показываем, что эти методы дают разнообразные решения, которые соответствуют семантическому значению, обеспечиваемому текстовыми подсказками, и поддерживают согласованность данных с ухудшенными входными данными. Оценивается производительность предложенного базового метода для задач с экстремальным сверхвысоким разрешением и демонстрируются преимущества с точки зрения качества восстановления, разнообразия и возможности исследования решения.
34、Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model
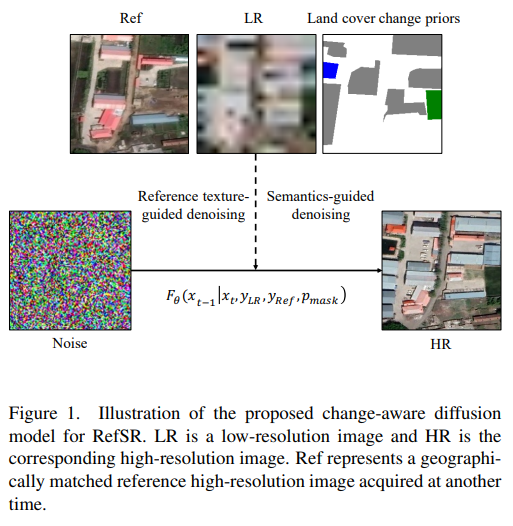
Сверхразрешение на основе эталонов (RefSR) может построить мост между пространственным и временным разрешением изображений дистанционного зондирования. Однако существующие методы RefSR ограничены точностью реконструкции контента и эффективностью передачи текстур при больших масштабных факторах. Модели условной диффузии открывают новые возможности для создания реалистичных изображений с высоким разрешением, но эффективное использование эталонных изображений в этих моделях остается областью для дальнейших исследований. Кроме того, точность содержания трудно гарантировать в тех областях, где нет соответствующей справочной информации.
Для решения этих проблем предлагается диффузионная модель с учетом изменений под названием Ref-Diff для RefSR, которая использует априорные изменения земного покрова для явного управления процессом шумоподавления. В частности, априорные значения вводятся в модель шумоподавления, чтобы улучшить использование справочной информации в неизмененных регионах и стандартизировать реконструкцию семантически релевантного контента в измененных регионах. Благодаря этому мощному руководству процессы шумоподавления на основе семантики и шумоподавления на основе эталонной текстуры разделены, что повышает производительность модели.
Эксперименты показывают, что предлагаемый метод обладает превосходной эффективностью и надежностью как в количественных, так и в качественных оценках по сравнению с современными методами RefSR. https://github.com/dongrunmin/RefDiff
6. Восстановление изображения
35、Boosting Image Restoration via Priors from Pre-trained Models
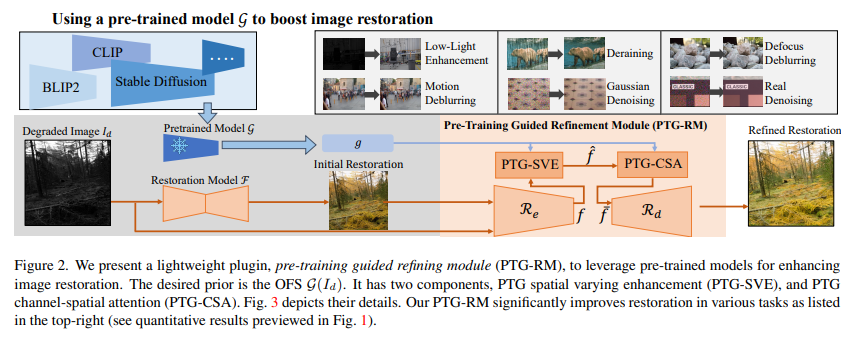
Предварительно обученные модели с использованием крупномасштабных обучающих данных, представленных CLIP и стабильной диффузией, демонстрируют значительную эффективность в понимании и создании изображений на основе языковых описаний. Однако их потенциал в задачах низкого уровня, таких как восстановление изображений, относительно недостаточно изучен. В этой статье рассматриваются эти модели для улучшения восстановления изображений.
Поскольку готовые функции (OSF) предварительно обученной модели не могут быть напрямую использованы для восстановления изображений, для обучения предлагается дополнительный облегченный модуль — Pre-Train-Guided Refinement Module (PTG-RM). улучшение результатов восстановления целевой сети восстановления посредством OSF. PTG-RM состоит из двух компонентов: пространственно-изменяющегося улучшения с предварительным обучением (PTG-SVE) и пространственно-пространственного внимания с предварительным обучением (PTG). PTG-SVE обеспечивает оптимальные нейронные манипуляции на коротких и дальних дистанциях, а PTG-CSA усиливает внимание к пространственным каналам, связанное с восстановлением.
Эксперименты доказали, что PTG-RM благодаря своему компактному объему (менее 1M параметров) эффективно повышает эффективность восстановления различных моделей при выполнении различных задач, включая улучшение качества при слабом освещении, удаление дождя, устранение размытия и шумоподавление.
36、Image Restoration by Denoising Diffusion Models with Iteratively Preconditioned Guidance

Обучение глубоких нейронных сетей стало распространенным методом решения задач восстановления изображений. Альтернативой обучению сети, «специфичной для конкретной задачи» для каждой модели, является использование предварительно обученных глубоких шумоподавителей, чтобы вводить только априорные значения сигналов в итеративный алгоритм без дополнительного обучения. В последнее время варианты этого подхода, основанные на выборке, стали популярными с появлением генеративных моделей, основанных на диффузии/оценке.
В этом документе предлагается новый метод начальной загрузки, основанный на предварительной обработке, который может переходить от начальной загрузки на основе BP к начальной начальной загрузке на основе наименьших квадратов в процессе восстановления. Предлагаемый метод устойчив к шуму и его проще реализовать, чем альтернативные методы (например, не требует SVD или обширных итераций). Он применяется к схемам оптимизации и схемам, основанным на выборке, и демонстрируются его преимущества перед существующими методами устранения размытия изображения и сверхразрешения.
37、Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks

Замечательный прогресс в моделях диффузии, обученных на крупномасштабных наборах данных. Однако из-за стохастичности процесса распространения им часто сложно справиться с различными низкоуровневыми задачами, требующими сохранения деталей. Чтобы преодолеть это ограничение, мы предлагаем новую структуру Diff-Plugin, которая позволяет одной предварительно обученной модели диффузии генерировать высокоточные результаты в различных задачах низкого уровня.
В частности, впервые предлагается облегченный модуль Task-Plugin, который использует двухветвевую конструкцию для предоставления предварительных знаний по конкретной задаче для управления сохранением содержимого изображения в процессе распространения. Затем предлагается селектор плагинов, который может автоматически выбирать различные плагины задач в соответствии с текстовыми инструкциями, позволяя пользователям выполнять редактирование изображений нескольких задач низкого уровня с помощью инструкций на естественном языке.
Обширные экспериментальные результаты по восьми задачам низкоуровневого зрения показывают, что Diff-Plugin превосходит существующие методы в реальных сценариях. Эксперименты по абляции подтвердили стабильность, возможность планирования и надежные возможности обучения Diff-Plugin при различных размерах наборов данных. https://yuhaoliu7456.github.io/Diff-Plugin/
38、Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
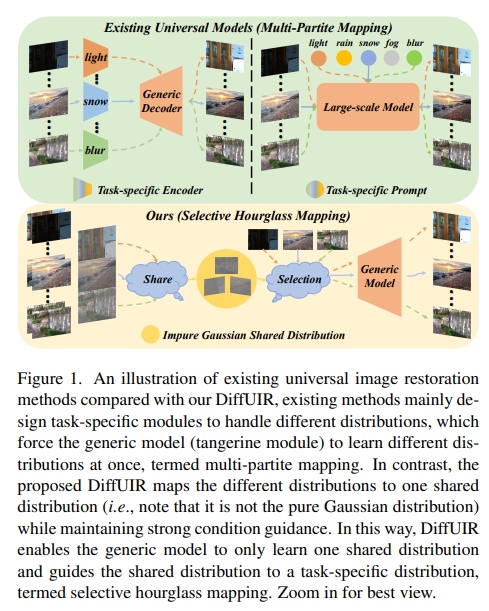
Общее восстановление изображений — практическая и многообещающая задача компьютерного зрения, имеющая практическое применение. Основная задача этой задачи — одновременно обрабатывать различные распределения деградации. Существующие методы в основном используют условия, специфичные для конкретной задачи (например, сигналы), чтобы направить модель на индивидуальное изучение различных распределений, что называется многочастным сопоставлением. Однако этот подход не подходит для общего обучения моделей, поскольку он игнорирует общую информацию между различными задачами.
В этой работе предлагается усовершенствованная стратегия выборочного картирования песочных часов под названием DiffUIR, основанная на модели диффузии. У DiffUIR есть два новых соображения. Во-первых, обеспечьте модели мощное условное руководство, чтобы получить точное направление генерации диффузионной модели (селективность). Что еще более важно, DiffUIR умело интегрирует гибкий термин общего распределения (SDT) в алгоритм распространения, постепенно отображая различные распределения в общее распределение. В обратном процессе, в сочетании с SDT и мощным условным руководством, DiffUIR итеративно направляет общее распределение к распределению для конкретной задачи (песочные часы) с высоким качеством изображения.
Изменяя только стратегию картографии, достигается высочайшая производительность при выполнении пяти задач восстановления изображений, 22 эталонных наборов данных с универсальной настройкой и настройкой генерализации с нулевым выстрелом. Удивительно, но отличные характеристики достигаются только с помощью облегченной модели (всего 0,89М). https://github.com/iSEE-Laboratory/DiffUIR
39、Shadow Generation for Composite Image Using Diffusion Model

В области композиции изображений создание реалистичных теней для вставленного переднего плана остается огромной проблемой. В предыдущих исследованиях были разработаны модели, основанные на преобразованиях между изображениями, которые обучаются на парах обучающих данных. Однако они сталкиваются с трудностями при создании теней точной формы и интенсивности из-за нехватки данных и сложности самой задачи.
В этой статье используется базовая модель с богатыми предварительными знаниями об изображениях естественных теней. В частности, сначала под задачу адаптируется ControlNet, а затем предлагается модуль модуляции интенсивности для увеличения интенсивности теней. Кроме того, был использован новый конвейер сбора данных для расширения небольшого набора данных DESOBA до DESOBAv2. Экспериментальные результаты на наборах данных DESOBA и DESOBAv2, а также реальные синтетические изображения показывают, что модель обладает более сильными возможностями в задаче генерации теней. https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2
7. Отслеживание цели
40、Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
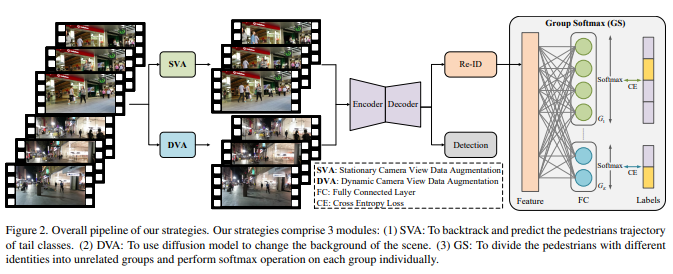
Отслеживание нескольких объектов (MOT) является ключевой областью в области компьютерного зрения и имеет широкое применение. Текущие исследования сосредоточены на разработке алгоритмов отслеживания и совершенствовании методов постобработки. Однако глубоких исследований характеристик самих данных отслеживания не хватает.
В этом исследовании впервые изучается структура распределения данных отслеживания и обнаруживается, что в существующем наборе данных MOT существует очевидная проблема распределения с длинным хвостом. Установлено, что существует существенный дисбаланс в распределении различных пешеходов, который получил название «длиннохвостое распределение пешеходных траекторий». Для решения этой проблемы предлагается стратегия, специально разработанная для смягчения последствий такого распределения. В частности, предлагаются две стратегии увеличения данных, включая увеличение статических данных обзора камеры (SVA) и динамическое увеличение данных обзора камеры (DVA) для состояний точки обзора, а также модуль Group Softmax (GS) для Re-ID. SVA предназначен для отслеживания и прогнозирования траекторий пешеходов для хвостовых категорий, в то время как DVA использует модель диффузии для изменения фона сцены. GS делит пешеходов на несвязанные группы и выполняет операцию softmax для каждой группы.
Эту стратегию можно интегрировать во многие существующие системы отслеживания, и эксперименты подтверждают эффективность метода в снижении влияния распределений с длинным хвостом на производительность отслеживания с несколькими целями. https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT
8. Обнаружение цели
41、SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
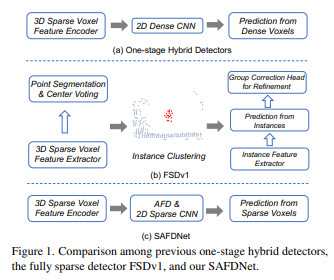
Обнаружение трехмерных объектов на основе LiDAR играет ключевую роль в автономном вождении. Существующие высокопроизводительные детекторы 3D-объектов обычно создают плотные карты объектов в магистральной сети и в головке прогнозирования. Однако по мере увеличения дальности обнаружения вычислительные затраты, связанные с плотными картами объектов, увеличиваются квадратично, что затрудняет расширение этих моделей для обнаружения на больших расстояниях. В некоторых недавних исследованиях предпринимались попытки создать полностью разреженные детекторы для решения этой проблемы, однако полученные модели либо полагаются на сложные многоступенчатые конвейеры, либо работают плохо.
В этой статье предлагается SAFDNet, которая является простой и эффективной и предназначена для обнаружения полностью разреженных трехмерных объектов. В SAFDNet стратегия адаптивного распространения функций предназначена для решения проблемы потери центральных функций. Обширные эксперименты с наборами данных Waymo Open, nuScenes и Argoverse2 доказывают, что SAFDNet работает немного лучше, чем предыдущий SOTA, на первых двух наборах данных, но лучше работает на последнем наборе данных с характеристиками обнаружения на больших расстояниях, проверка. Эффективность SAFDNet в сценариях, требующих больших расстояний. обнаружение.
В Argoverse2 SAFDNet в 2,1 раза быстрее, чем предыдущий лучший гибридный детектор HEDNet, и улучшает mAP на 2,1% по сравнению с предыдущим лучшим разреженным детектором FSDv2, который в 1,3 раза быстрее. https://github.com/zhanggang001/HEDNet
42、DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
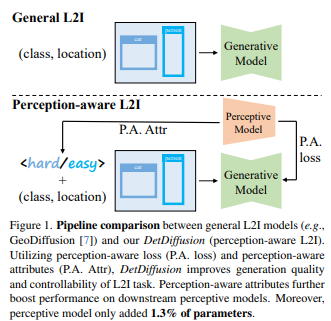
Современные модели восприятия в значительной степени полагаются на ресурсоемкие наборы данных и поэтому требуют инновационных решений. Используя последние достижения в области диффузионных моделей и синтетических данных, синтетические данные облегчают последующие задачи, создавая различные входные помеченные изображения. Хотя предыдущие методы решали проблему генеративных и перцептивных моделей отдельно, DetDiffusion является первым, кто интегрировал аспекты перцептивной модели для генерации достоверных данных.
Чтобы улучшить возможности генерации изображений в модели восприятия, вводятся потери восприятия (потери PA) для улучшения качества и управляемости за счет сегментации. Чтобы улучшить производительность конкретной модели восприятия, метод настраивает увеличение данных путем извлечения и использования атрибутов восприятия (P.A. Attr). Экспериментальные результаты задачи обнаружения объектов подчеркивают превосходную производительность DetDiffusion при генерации на основе макета, что значительно повышает производительность последующего обнаружения.
43、SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection

В области поэтапного обучения (CIL) генеративное воспроизведение стало методом облегчения катастрофического забывания и привлекает все больше и больше внимания по мере совершенствования генеративных моделей. Однако его применение при обнаружении дополнительных объектов по категориям (CIOD) сильно ограничено, главным образом из-за сложности сценариев, включающих несколько меток.
В этой статье предлагается новый метод CIOD, называемый стабильным диффузионным глубоким генеративным воспроизведением (SDDGR). В этом методе используется генеративная модель, основанная на диффузии, в сочетании с предварительно обученной сетью преобразования текста в диффузию для создания реалистичных и разнообразных синтетических изображений. SDDGR использует стратегию итеративной оптимизации для создания высококачественных образцов старых категорий. Кроме того, используется технология дистилляции знаний L2 для улучшения сохранения предыдущих знаний в синтезированных изображениях. Кроме того, метод включает псевдомаркировку старых объектов в новых изображениях задач, чтобы предотвратить их ошибочную классификацию как фоновые элементы.
Обширные эксперименты на наборе данных COCO 2017 показывают, что SDDGR значительно превосходит существующие алгоритмы в различных сценариях CIOD и выходит на новый технический уровень.
9. Обнаружение ключевых точек
44、Pose-Guided Self-Training with Two-Stage Clustering for Unsupervised Landmark Discovery
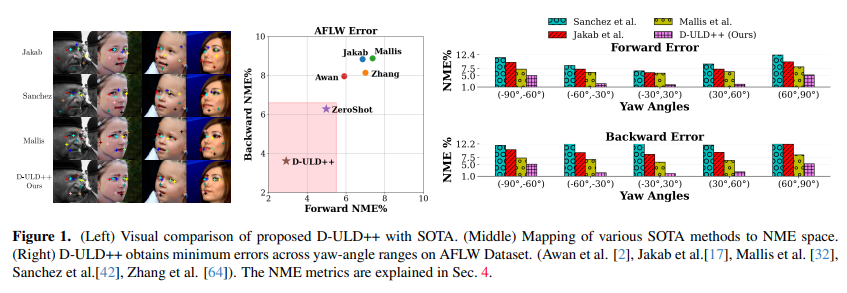
Неконтролируемое обнаружение ориентиров (ULD) — сложная задача компьютерного зрения. Чтобы использовать потенциал моделей диффузии в задачах ULD, во-первых, предлагается базовая линия ULD с нулевым выстрелом, основанная на простой кластеризации случайных расположений пикселей, которая обеспечивает лучшие результаты, чем существующие методы ULD, за счет сопоставления ближайших соседей. Во-вторых, на основе нулевой производительности алгоритм ULD на основе диффузионных признаков разрабатывается посредством самообучения и кластеризации, что значительно превосходит предыдущие методы. В-третьих, представлена новая задача агента, основанная на генерации скрытых кодов положения, и предложен двухэтапный механизм кластеризации для облегчения эффективной генерации псевдометок, тем самым значительно улучшая производительность.
В целом, этот метод неизменно превосходит существующие современные методы в четырех сложных тестах (AFLW, MAFL, CatHeads и LS3D).
10. Обнаружение дипфейков
45、Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection
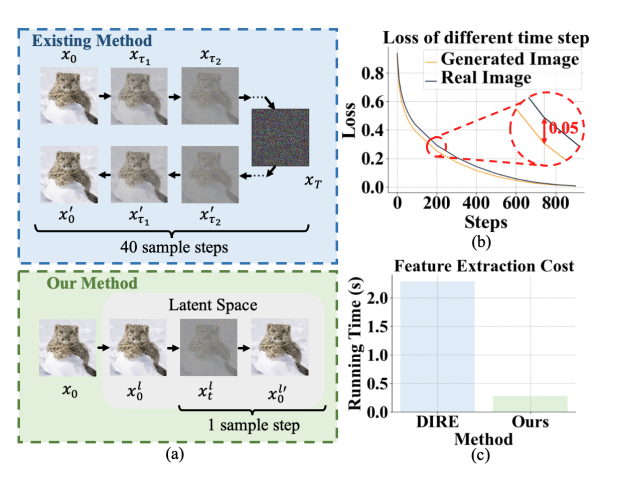
Модели диффузии значительно улучшают качество генерации изображений, что затрудняет различие между реальными и сгенерированными изображениями. Однако это развитие также вызывает серьезные проблемы конфиденциальности и безопасности. Чтобы решить эту проблему, для обнаружения сгенерированных изображений предлагается новый метод оптимизации функций с учетом ошибок реконструкции скрытых переменных (скрытая функция REfinement с ошибками REconstruction, LaRE2).
Предлагается скрытая ошибка реконструкции (LaRE), функция скрытого пространства, основанная на ошибке реконструкции, для генерации обнаружения изображения. LaRE превосходит существующие методы по эффективности извлечения признаков, сохраняя при этом ключевые признаки, необходимые для того, чтобы отличить настоящие изображения от поддельных. Для использования LaRE предлагается метод с модулем оптимизации функций с учетом ошибок (EGRE), который управляет оптимизацией функций изображения с помощью LaRE для повышения различимости функций.
EGRE использует механизм выравнивания и последующего уточнения, который может эффективно уточнять характеристики изображения с пространственной и канальной точки зрения для генеративного обнаружения изображений. Обширные эксперименты с крупномасштабным тестом GenImage демонстрируют превосходство LaRE2, превосходя лучшие методы SoTA на 8 различных генераторах изображений со средним значением ACC/AP, достигающим 11,9%/12,1%. LaRE также превосходит существующие методы по стоимости извлечения признаков и работает в 8 раз быстрее.
11. Обнаружение аномалий
46、RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection

Методы самостоятельной реконструкции объектов показывают многообещающий прогресс в обнаружении и локализации аномалий на промышленных изображениях. Эти методы по-прежнему сталкиваются с проблемами при синтезе реалистичных и разнообразных выборок аномалий и устранении избыточности функций и систематической ошибки предварительно обученных функций.
В этой работе предлагается RealNet, сеть реконструкции объектов с реалистичными синтетическими аномалиями и адаптивным выбором функций. Он содержит три ключевых нововведения: во-первых, он предлагает синтез диффузионных аномалий с контролируемой интенсивностью (SDAS), стратегию синтеза, основанную на процессе диффузии, которая может генерировать образцы с различной интенсивностью аномалий, имитируя распределение реальных образцов аномалий. Во-вторых, разрабатывается метод выбора признаков с учетом аномалий (AFS) — метод выбора репрезентативных и различительных предварительно обученных подмножеств признаков для повышения производительности обнаружения аномалий при одновременном контроле вычислительных затрат. В-третьих, представлен выбор остатков реконструкции (RRS) — стратегия, которая адаптивно выбирает дискриминационные остатки для всестороннего выявления аномальных областей на нескольких уровнях детализации.
RealNet оценивается на четырех эталонных наборах данных, и результаты показывают улучшения как в AUROC изображения, так и в пиксельном AUROC по сравнению с современными методами. https://github.com/cnulab/RealNet
12. Вырез/сегментация
47、In-Context Matting
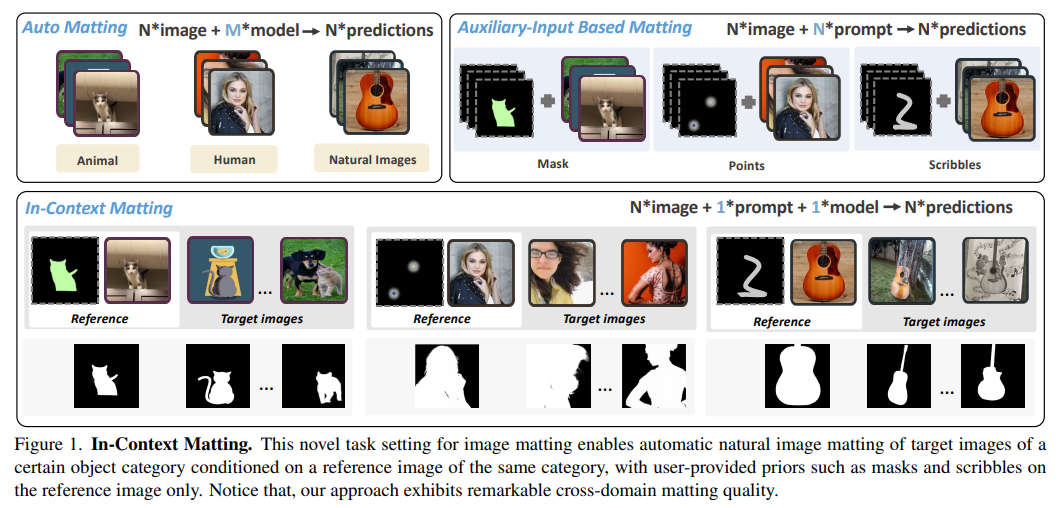
Предложите In-Context Matting — новую постановку задач по матированию изображений. Учитывая определенное эталонное изображение переднего плана и управляемые априорные значения, такие как точки, граффити и маски, контекстное сопоставление позволяет автоматически оценивать альфа-канал для пакета целевых изображений с одной и той же категорией переднего плана без дополнительных вспомогательных входных данных. Этот параметр хорошо работает при матировании на основе вспомогательных входных данных и обеспечивает хороший баланс между простотой использования автоматического матирования.
Чтобы решить проблему точного сопоставления переднего плана, введена IconMatting — модель контекстного матирования, построенная на предварительно обученной модели диффузии текста в изображение. Вводя внутреннее и внешнее сопоставление по сходству, IconMatting может полностью использовать ссылочный контекст для создания точных целевых альфа-подложек. Для сравнения этой задачи также представлен новый набор тестовых данных ICM-57, включающий 57 наборов реальных изображений. https://github.com/tiny-smart/in-context-matting/tree/master
13. Сжатие изображения
48、Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis
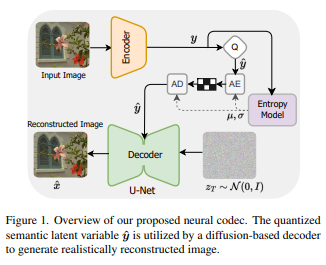
Замена гауссовых декодеров моделями условной диффузии может повысить качество восприятия реконструированных изображений при нейронном сжатии изображений, но отсутствие индуктивного смещения в данных изображения ограничивает их способность достигать современных уровней восприятия.
Чтобы устранить это ограничение, на стороне декодера используется модель неизотропной диффузии. Модель накладывает индуктивный сдвиг на различение частотного содержания, тем самым облегчая генерацию высококачественных изображений. Он также оснащен новой энтропийной моделью, которая ускоряет этап энтропийного декодирования за счет использования корреляций пространственных каналов в скрытом пространстве для точного моделирования распределения вероятностей скрытого представления. Эта энтропийная модель на основе каналов использует локальный и глобальный пространственный контекст внутри каждого блока канала. Глобальный пространственный контекст построен на основе Transformer и специально используется для задач сжатия изображений. Разработанный преобразователь использует кодирование положения в форме Лапласа, а его обучаемые параметры адаптивно настраиваются в соответствии с каждым кластером каналов.
Эксперименты показывают, что эта структура способна обеспечить лучшее качество восприятия и что предлагаемая энтропийная модель приводит к значительной экономии битрейта.
14. Понимание видео
49、Abductive Ego-View Accident Video Understanding for Safe Driving Perception

Предлагается новый набор данных для мультимодального понимания видео происшествий MM-AU (Понимание мультимодального видео происшествий). MM-AU содержит 11 727 видео происшествий с эго-видом в естественных сценах, каждое из которых снабжено текстовым описанием, синхронизированным по времени. Аннотировано более 2,23 миллиона кадров объектов и 58 650 пар видео причин происшествий, охватывающих 58 категорий происшествий. MM-AU поддерживает различные задачи по анализу аварий, особенно понимание причинно-следственных цепочек аварий для безопасного вождения посредством мультимодального распространения видео.
С использованием MM-AU предлагается система понимания видео с абдуктивными авариями для восприятия безопасного вождения (AdVersa-SD). AdVersa-SD — метод объектно-центрической диффузии видео (OAVD), основанный на модели CLIP. Модель включает в себя изучение контрастных потерь взаимодействия между нормальными, предаварийными и аварийными кадрами и соответствующими текстовыми описаниями, такими как причины аварий, рекомендации по предотвращению и категории аварий. OAVD обеспечивает изучение причинно-следственных связей при создании видео, одновременно фиксируя содержимое фона исходного кадра при создании видео, чтобы найти основные причинно-следственные цепочки определенных происшествий.
Эксперименты демонстрируют возможности вывода AdVersa-SD и преимущества OAVD перед современными диффузионными моделями. Кроме того, были тщательно проверены обнаружение объектов и реагирование на причины происшествий, поскольку AdVersa-SD полагается на точную информацию об объектах и причинах происшествий. http://www.lotvsmmau.net/
15. Генерация видео
50、FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation

Модели диффузии текста в изображение вдохновляют на исследование их потенциальных приложений в видеосфере. Методы нулевого кадра расширяют модели диффузии изображений на видеообласть, не требуя обучения модели. Последние методы в основном сосредоточены на включении межкадрового соответствия в механизмы внимания. Однако мягкие ограничения, определяющие, на чем следует сосредоточиться на действительных функциях, иногда могут быть недостаточными, что приводит к временным несоответствиям.
В этой статье предлагается FRESCO, которая сочетает внутрикадровую и межкадровую корреспонденцию для установления более мощных пространственно-временных ограничений. Это улучшение гарантирует, что между кадрами сохраняются согласованные переходы с семантически схожим содержимым. Помимо управления вниманием, метод также включает явное обновление функций для достижения высокой пространственно-временной согласованности с входным видео, тем самым значительно улучшая визуальную связность сгенерированного видео.
Эксперименты демонстрируют эффективность предлагаемой структуры в создании высококачественных связных видеороликов, что обеспечивает значительные улучшения по сравнению с существующими методами нулевого кадра.
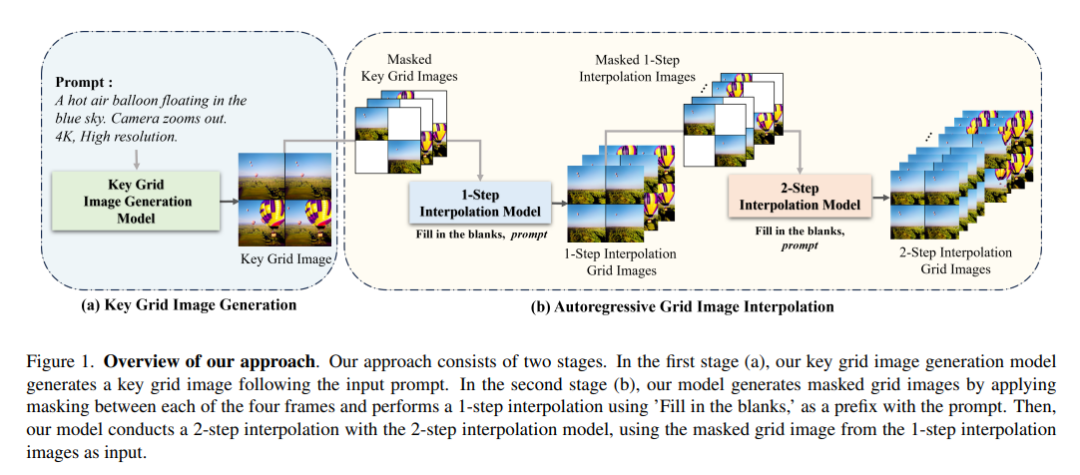
51、Grid Diffusion Models for Text-to-Video Generation
Создание видео из текста является более сложной задачей, чем создание изображений из текста, поскольку для этого требуются большие наборы данных и более высокие вычислительные затраты. Большинство существующих методов генерации видео используют 3D-архитектуру U-Net или авторегрессионную генерацию, учитывающую временное измерение. По сравнению с генерацией текста в изображение, эти методы требуют больших наборов данных и ограничены с точки зрения вычислительных затрат.
Для решения этих проблем предлагается простой и эффективный новый метод генерации текста в видео, который не учитывает временное измерение в архитектуре и требует большого набора парных данных «текст-видео». Высококачественное видео можно генерировать, используя фиксированный объем памяти графического процессора, независимо от количества кадров, представляя видео в виде изображения сетки. Кроме того, поскольку этот метод уменьшает размерность видео до размерности изображения, к видео можно применять различные методы на основе изображений, такие как манипулирование видео с помощью текста из манипулирования изображением. Этот метод превосходит существующие методы как в количественных, так и в качественных оценках, демонстрируя, что модель подходит для практической генерации видео.
52、TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models
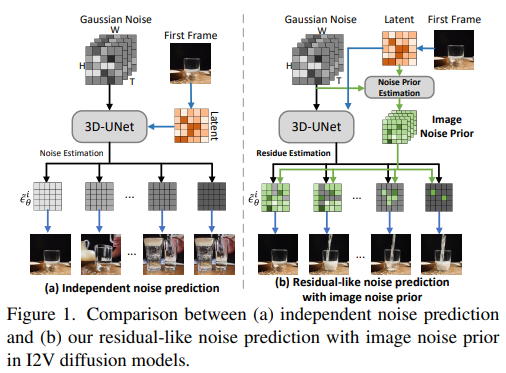
Применение моделей диффузии для преобразования статических изображений в динамические (т. е. генерация изображения в видео) является нетривиальной задачей. Трудность заключается в том, что процесс распространения сгенерированных последовательных кадров анимации должен не только поддерживать соответствие данному изображению, но также обеспечивать временную когерентность между соседними кадрами.
Чтобы облегчить эту проблему, предлагается TRIP, новый метод, основанный на парадигме диффузии изображения в видео, основанной на априорном уровне шума изображения. Априорный шум изображения получается из статических изображений посредством одноэтапного процесса обратной диффузии на основе статических изображений и скрытых видеокодов с шумом. Затем TRIP выполняет двухпроходную схему, аналогичную остаточной для прогнозирования шума: 1) кратчайший путь напрямую использует шум изображения в качестве эталонного шума для каждого кадра, чтобы улучшить согласованность между первым кадром и последующими кадрами; 2) остаточный; В разностных путях используется 3D-UNet для изучения скрытых кодов зашумленных видео и неподвижных изображений, чтобы обеспечить возможность межкадрового реляционного анализа, тем самым уменьшая остаточный шум, полученный для каждого кадра. Кроме того, опорный шум и остаточный шум каждого кадра динамически объединяются с помощью механизма внимания для окончательного создания видео.
Обширные эксперименты с наборами данных WebVid-10M, DTDB и MSRVTT демонстрируют эффективность TRIP для создания изображения в видео. https://trip-i2v.github.io/TRIP/
53、Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model

Совместные речевые жесты, представленные в виде ярких видеороликов, позволяют достичь лучших визуальных эффектов при взаимодействии человека с компьютером. Предыдущие исследования в основном генерировали структурированные человеческие скелеты, в результате чего информация о внешнем виде опускалась. В этой статье основное внимание уделяется непосредственному созданию звуковых видеороликов с совместными жестами.
Две основные проблемы: 1) Для описания сложных действий человека с использованием важной информации о внешнем виде необходимы подходящие характеристики движения. 2) Жесты и речь демонстрируют внутреннюю зависимость и должны оставаться согласованными во времени, даже если они имеют произвольную длину. Для решения этих проблем предлагается новая система разделения движений для создания видеороликов с совместными жестами. Во-первых, вводится тщательно разработанное нелинейное преобразование TPS для получения скрытых характеристик движения, сохраняющих ключевую информацию о внешнем виде. Затем предлагается диффузионная модель на основе Трансформера, позволяющая изучить временную корреляцию между жестами и речью и генерировать их в пространстве скрытых движений, а затем генерировать долгосрочные когерентные и последовательные видео жестов с помощью модуля выбора оптимального движения.
Для лучшего визуального восприятия дополнительно разрабатывается сеть уточнений, фокусирующаяся на недостающих деталях в определенных областях. Результаты экспериментов показывают, что он значительно превосходит существующие методы при оценке движения и видео. https://github.com/thuhcsi/S2G-MDDiffusion
54、Video Interpolation With Diffusion Models

предложить VIDIM, генеративную модель интерполяции видео, которая может генерировать короткие видеоролики с учетом начального и конечного кадров. Чтобы добиться высокой точности и генерировать движение, невидимое во входных данных, VIDIM использует модель каскадной диффузии, чтобы сначала генерировать целевое видео с низким разрешением, а затем генерировать видео с высоким разрешением на основе сгенерированного видео с низким разрешением.
Мы сравниваем VIDIM с предыдущими современными методами интерполяции видео и показываем, как эти методы не работают в большинстве случаев из-за сложного, нелинейного или неопределенного движения, в то время как VIDIM может легко справиться с этими случаями. Мы также демонстрируем руководство без классификатора для начальных и конечных кадров и приводим модель сверхвысокого разрешения в соответствие с исходными кадрами высокого разрешения без дополнительных параметров, что приводит к результатам с высокой точностью.
Скорость выборки VIDIM высока, он совместно удаляет шумы из всех генерируемых кадров, требует менее миллиарда параметров на модель диффузии для получения убедительных результатов и по-прежнему масштабируется при большем количестве параметров и улучшенном качестве. https://vidim-interpolation.github.io/
16. Слушайте рождение жизни
55、CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
Целью генерации головы слушателя является синтез невербальной реактивной головы слушателя путем моделирования отношений между говорящим и слушателем во время процесса динамического преобразования. Применение технологии генерации прослушивающих агентов в виртуальных взаимодействиях способствовало множеству работ по достижению разнообразной и детальной генерации движений. Однако они могут манипулировать действиями только посредством простых ярлыков эмоций и не могут свободно контролировать действия слушателя. Поскольку прослушивающие агенты должны иметь человеческие атрибуты (такие как личность, личность) и могут свободно настраиваться пользователями, это ограничивает их реализм.
В этой статье предлагается удобная для пользователя платформа под названием CustomListener для реализации текста произвольной формы перед управляемой генерацией прослушивателя. Для достижения координации между говорящим и слушателем разработан статически-динамический портретный модуль (SDP), который взаимодействует с информацией говорящего и преобразует статический текст в динамический портретный токен с дополнительной информацией о ритме и амплитуде. Чтобы обеспечить согласованность между фрагментами, модуль прошлой управляемой генерации (PGG) предназначен для поддержания согласованности настроенных атрибутов слушателя с помощью априорных данных движения и использует маркеры портрета и априорные данные движения в качестве условий для достижения управляемой генерации.
Для обучения и оценки модели на основе ViCo и RealTalk создаются два набора данных прослушивающих голов с текстовыми аннотациями, которые предоставляют парные метки «текст-видео». Большое количество экспериментов подтвердило эффективность этой модели. https://customlistener.github.io/
17. Цифровое человеческое поколение
56、Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework

Несмотря на достигнутый прогресс в решениях на основе «говорящей головы», создание видео в стиле якоря с движением всего тела остается сложной задачей. В этом исследовании предлагается новая система под названием Make-Your-Anchor, которой для обучения требуется всего одна минута видеоклипов с участием человека, а затем она может автоматически генерировать видеоролики с точными движениями туловища и рук.
В частности, предлагаемая модель диффузии на основе структуры точно настраивается на входном видео для условной визуализации трехмерной сетки в виде человеческого тела. Для обучения модели диффузии используется двухэтапная стратегия обучения, эффективно привязывающая действия к конкретным проявлениям. Чтобы генерировать произвольно длинные видео, двумерная U-сеть в диффузионной модели на уровне кадров расширяется до трехмерного стиля без дополнительных затрат на обучение, а в выводе вводится простое и эффективное временное удаление с перекрытием пакетов. Модуль Noise, обходящий ограничения на длину видео. Наконец, представлен новый модуль улучшения лица для улучшения визуального качества областей лица в выходном видео.
Сравнительные эксперименты показывают, что система эффективна и превосходит с точки зрения качества изображения, временной когерентности и защиты личности, превосходя современные методы диффузии/недиффузии. https://github.com/ICTMCG/Make-Your-Anchor
18. Новое поколение представлений
57、EscherNet: A Generative Model for Scalable View Synthesis

Предложите EscherNet, модель условного распространения с несколькими представлениями для синтеза представлений. EscherNet изучает неявно сгенерированные 3D-представления, которые в сочетании со специализированными кодировками положения камеры обеспечивают точный и непрерывный контроль преобразований камеры между любым количеством эталонных и целевых изображений.
EscherNet обладает превосходной универсальностью, гибкостью и масштабируемостью в синтезе представлений и может генерировать более 100 согласованных целевых представлений одновременно на одном обычном графическом процессоре потребительского уровня, несмотря на то, что он обучает только фиксированный набор из 3 эталонных представлений для 3 целевых представлений. Таким образом, EscherNet не только решает проблему синтеза нового изображения с нуля, но и естественным образом объединяет 3D-реконструкцию одного и нескольких изображений в единую структуру.
Эксперименты показывают, что EscherNet достигает самых современных показателей производительности в нескольких тестах, даже по сравнению с методами, специально разработанными для каждой отдельной проблемы. Эта замечательная универсальность открывает новые направления для проектирования масштабируемых трехмерных визуальных нейронных архитектур. https://kxhit.github.io/EscherNet
19. Связанные с 3D
58、Bayesian Diffusion Models for 3D Shape Reconstruction
Предложите модель байесовской диффузии (BDM), алгоритм прогнозирования, который тесно интегрирует нисходящую (априорную) информацию с восходящими (управляемыми данными) процессами посредством совместного процесса диффузии для достижения эффективного байесовского вывода. Продемонстрируйте эффективность BDM в задачах реконструкции трехмерных форм. По сравнению с типичными методами глубокого обучения, основанными на данных, обученными на парных (контролируемых) наборах данных меток данных (например, облако точек изображения), BDM вводит богатую априорную информацию из независимых меток (например, облака точек) для улучшения трехмерной реконструкции снизу вверх. на. В отличие от стандартных байесовских схем, которые требуют явных априорных значений и вероятностей, BDM выполняет плавное объединение информации, изучая сеть вычислений градиента, которая протекает через процесс совместного распространения.
BDM характеризуется способностью участвовать в активном и эффективном обмене информацией и интеграции нисходящих и восходящих процессов, каждый из которых сам по себе является диффузионным процессом. Демонстрация самых современных результатов в синтетических и реальных тестах реконструкции 3D-форм.
59、DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
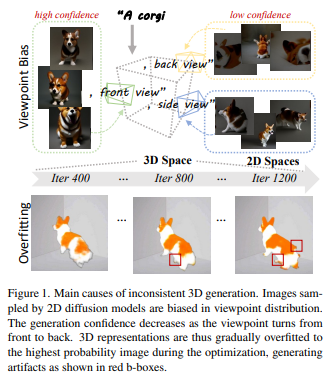
В последние годы 3D-генерация привлекла большое внимание. Благодаря успеху модели диффузии текста в изображение, 2D-технология стала многообещающим путем для управляемой генерации 3D-изображений. Однако эти методы часто демонстрируют противоречивую геометрию, что также известно как проблема Януса. Замечено, что эта проблема в основном вызвана двумя аспектами, а именно смещением перспективы в двумерной диффузионной модели и переоснащением цели оптимизации.
Для решения этой проблемы предлагается двухэтапная структура 2D-лифтинга, а именно DreamControl, которая оптимизирует грубую сцену NeRF как 3D-априорную, а затем использует дистилляцию скоринга на основе управления для генерации мелкозернистых объектов. В частности, предлагаются адаптивная выборка представлений и меры целостности границ, чтобы гарантировать согласованность сгенерированных априорных значений. Эти априорные значения затем рассматриваются как входные условия для поддержания разумной геометрии, где дополнительно предлагаются условный LoRA и взвешенная оценка для оптимизации детальных текстур.
DreamControl генерирует высококачественный 3D-контент с высокой геометрической согласованностью и точностью текстур. Кроме того, рекомендации по оптимизации на основе элементов управления применимы к более поздним задачам, включая создание инструкций для пользователей и 3D-анимацию. https://github.com/tyhuang0428/DreamControl
60、DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
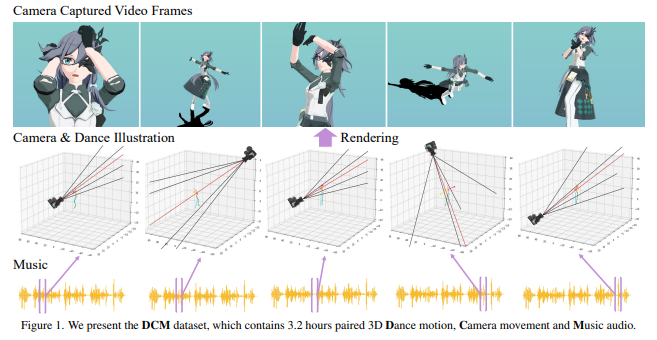
Хореограф определяет внешний вид танца, а оператор определяет финальную подачу танца. Недавно различные методы и наборы данных продемонстрировали возможность создания танца. Однако синтез движений камеры для музыки и танца остается нерешенной сложной задачей из-за нехватки парных данных.
представляют DCM, новый мультимодальный набор 3D-данных, который впервые сочетает в себе движение камеры с танцевальными движениями и музыкальным звуком. Этот набор данных включает парные данные «танец-камера-музыка» для 108 танцевальных сцен (3,2 часа) аниме-сообщества, охватывающих 4 музыкальных жанра. Благодаря этому набору данных выяснилось, что движение танцевальной камеры многослойно, ориентировано на человека и имеет множество влияющих факторов, что делает синтез движения танцевальной камеры более сложным по сравнению с синтезом только камеры или танца.
Чтобы преодолеть эти трудности, предлагается DanceCamera3D — диффузионная модель на основе Трансформера, которая сочетает в себе новую стратегию потери внимания к телу и стратегию условного разделения. Для оценки разработаны новые показатели, позволяющие измерить качество, разнообразие и аутентичность танцоров в движениях камеры. Используя эти индикаторы, было проведено большое количество экспериментов с набором данных DCM, чтобы количественно и качественно продемонстрировать эффективность модели DanceCamera3D. https://github.com/Carmenw1203/DanceCamera3D-Official
61、DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis
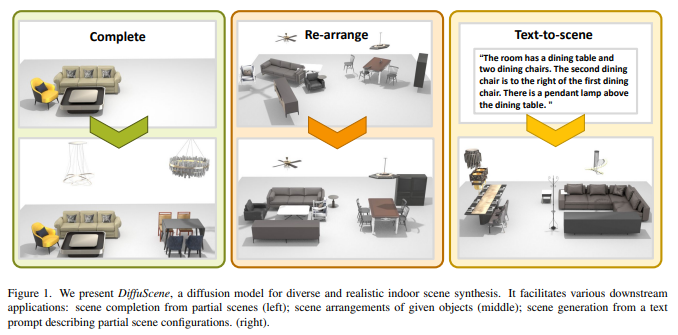
Предлагается метод синтеза 3D-сцен в помещении DiffuScene, основанный на новой модели диффузии шумоподавления конфигурации сцены. Он генерирует атрибуты трехмерного экземпляра, хранящиеся в неупорядоченном наборе объектов, и извлекает для каждой конфигурации объекта наиболее похожую геометрическую форму, которая описывается как объединение различных атрибутов, включая положение, размер, ориентацию, семантические и геометрические особенности.
Введена диффузионная сеть для синтеза набора трехмерных внутренних объектов путем шумоподавления неупорядоченных атрибутов объекта. Неупорядоченная параметризация упрощает аппроксимацию совместного распределения. Распространение признаков формы способствует естественному расположению объектов, включая симметрию. Этот метод способен поддерживать множество последующих приложений, включая завершение сцены, размещение сцены и синтез сцены на основе текста. Эксперименты с набором данных 3DFRONT доказывают, что этот метод может синтезировать более физически последовательные и разнообразные сцены в помещении, чем современные методы.
Исследования абляции подтверждают эффективность выбора дизайна в модели диффузии сцены. https://tangjiapeng.github.io/projects/DiffuScene/
62、IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images
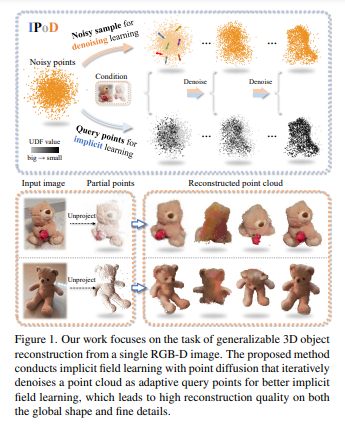
Универсальная реконструкция трехмерных объектов по однопроекционным изображениям RGB-D остается сложной задачей, особенно для реальных данных. Существующие методы используют неявное обучение полей на основе преобразователя, что требует парадигмы плотного обучения с плотным контролем запросов, равномерно выбранным по всему пространству.
Предлагается новый метод IPoD, который сочетает в себе неявное обучение в поле и диффузию точек. Этот подход рассматривает точки запроса, используемые для неявного обучения полей, как облака точек шума для итеративного шумоподавления, что позволяет им динамически адаптироваться к форме целевого объекта. Такие адаптивные точки запроса используют возможности грубого восстановления формы диффузного обучения и расширяют возможности неявных представлений для изображения более мелких деталей.
Кроме того, дополнительные механизмы самообусловливания предназначены для использования неявного предсказания в качестве руководства для диффузного обучения с целью формирования кооперативной системы. Эксперименты, проведенные с набором данных CO3D-v2, подтвердили превосходство IPoD по сравнению с существующими методами, показатель F был улучшен на 7,8%, а расстояние фаски — на 28,6%. Универсальность IPoD также была проверена на наборе данных MVImgNet. https://yushuang-wu.github.io/IPoD/
63、Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Несмотря на значительный прогресс в синтезе текста в действие, все еще существуют некоторые проблемы в создании управляемых языком действий человека в трехмерных средах. Эти проблемы в основном проистекают из двух аспектов: во-первых, из-за отсутствия мощных генеративных моделей, которые могут совместно моделировать естественный язык, трехмерные сцены и действия человека; во-вторых, потребность в данных для генеративных моделей велика, а существующий комплексный, высококачественный язык-сцена; Наборы данных о действиях очень скудны.
Для решения этих проблем вводится новая двухэтапная структура, которая использует достоверность сцены в качестве промежуточного представления для эффективного соединения заземления 3D-сцены и генерации условных действий. Эта структура включает в себя модель диффузии возможностей (ADM) для прогнозирования явных карт эффективности и модель диффузии возможностей (AMDM) для генерации разумных движений человека. Используя карты достоверности сцен, метод преодолевает трудности генерации человеческих действий в соответствии с мультимодальными условными сигналами, особенно когда обучающие данные ограничены и не хватает широкого спектра пар язык-сцена-действие.
Эксперименты показывают, что этот метод неизменно превосходит все методы управления по установленным тестам, включая HumanML3D и HUMANISE. Кроме того, способность модели к обобщению проверяется на специально подобранном наборе оценок, который содержит ранее не встречавшиеся описания и сценарии. https://afford-motion.github.io/
64、MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections
MicroDiffusion предлагается для достижения высококачественной глубинной реконструкции 3D из ограниченных 2D проекций. Хотя существующие модели неявного нейронного представления (INR) часто дают неполные выходные данные, диффузионно-вероятностные модели с шумоподавлением (DDPM) превосходно улавливают детали - метод, который сочетает в себе структурную согласованность INR с возможностями повышения детализации DDPM.
Предварительно обучите модель INR для преобразования 2D-изображения, проецируемого по оси, в предварительный 3D-объем. Эта предварительно обученная модель INR служит глобальной основой для управления процессом генерации DDPM посредством линейной интерполяции между выходным сигналом INR и входным шумом. Эта стратегия обогащает структурированную 3D-информацию в процессе распространения, улучшает детализацию и снижает шум в локальных 2D-изображениях. Приспосабливая модель диффузии к ближайшей 2D-проекции, MicroDiffusion значительно повышает точность генерируемых результатов 3D-реконструкции, превосходя результаты INR и стандартного DDPM. https://github.com/UCSC-VLAA/MicroDiffusion
65、Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior

Недавние исследования по генерации текста в 3D показывают, что использование только 2D-контроля диффузии для генерации 3D часто приводит к непоследовательному внешнему виду (например, лицам на видах сверху) и неправильным формам (например, животным с дополнительными ногами).
Существующие методы в основном решают эту проблему путем переобучения диффузионных моделей с использованием изображений, созданных на основе трехмерных данных, для обеспечения согласованности нескольких представлений, одновременно стремясь сбалансировать качество генерации двухмерных изображений с согласованностью трехмерных изображений. В этом документе предлагается новая платформа Sculpt3D, которая предоставляет возможности сборки для текущих процессов путем явного внедрения 3D-априорных данных из извлеченных эталонных объектов без необходимости переобучения 2D-модели диффузии. В частности, с помощью метода выборки разреженных лучей мы демонстрируем, что высококачественная и разнообразная трехмерная геометрия может быть гарантирована посредством контроля ключевых точек.
Кроме того, чтобы обеспечить точный внешний вид под разными углами просмотра, выходные данные 2D-модели диффузии дополнительно корректируются для соответствия правильному шаблону представления шаблона без изменения результирующего стиля объекта. Эти две несвязанные конструкции эффективно используют трехмерную информацию эталонного объекта для создания трехмерных объектов, сохраняя при этом качество генерации двумерной диффузионной модели. Эксперименты показывают, что этот метод может значительно улучшить согласованность нескольких представлений, сохраняя при этом точность и разнообразие. https://stellarcheng.github.io/Sculpt3D/
66、Score-Guided Diffusion for 3D Human Recovery

Метод восстановления человеческой сетки с учетом оценок (ScoreHMR) предложен для решения обратной задачи трехмерной реконструкции позы и формы человека. ScoreHMR имитирует методы подбора модели, но обеспечивает согласование с наблюдениями за изображениями за счет управления оценкой в скрытом пространстве диффузионной модели. Целью обучения диффузионных моделей является получение условного распределения параметров модели человеческого тела с учетом входного изображения. Используя оценки для конкретных задач для управления процессом шумоподавления, ScoreHMR эффективно решает обратную задачу для различных приложений без необходимости переобучения моделей диффузии, не зависящих от задачи.
Методы оцениваются по трем параметрам/приложениям. Это: (i) подбор модели одного кадра; (ii) реконструкция из нескольких некалиброванных изображений; (iii) реконструкция человеческого тела в видеопоследовательностях. При всех настройках ScoreHMR неизменно превосходит все оптимизированные базовые показатели в популярных тестах. https://statho.github.io/ScoreHMR/
67、Towards Realistic Scene Generation with LiDAR Diffusion Models
Модели диффузии хорошо работают при создании фотореалистичных изображений, но их применение к созданию сцен LiDAR сопряжено со значительными трудностями. Это происходит главным образом потому, что диффузионные модели, работающие в точечном пространстве, с трудом поддерживают стиль кривой и трехмерную геометрию сцен LiDAR, что потребляет их возможности представления.
В этой статье предлагаются диффузионные модели LiDAR (LiDM) для создания сцен, соответствующих реальным сценам LiDAR, путем включения геометрических априорных данных в скрытое пространство процесса обучения. Метод создан для достижения трех целей: реализм шаблонов, геометрический реализм и реализм объектов.
Метод обеспечивает конкурентоспособную производительность при безусловной генерации LiDAR и достигает современного состояния в условной генерации LiDAR, сохраняя при этом высокую эффективность (до 107 раз быстрее) по сравнению с моделями точечной диффузии. Кроме того, за счет сжатия сцены LiDAR в скрытое пространство модель диффузии становится управляемой в различных условиях, таких как семантические карты, виды с камеры и текстовые подсказки. https://github.com/hancyran/LiDAR-Diffusion
68、VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation

Инновация в области преобразования текста в 3D представляет собой Score Distillation Sampling (SDS), которая реализует обучение с нуля неявных 3D-моделей (NeRF) путем прямого извлечения предварительных знаний из 2D-диффузионной модели. Однако текущие модели на основе SDS по-прежнему испытывают трудности с обработкой сложных текстовых сигналов и часто приводят к тому, что 3D-модели искажены, имеют нереалистичные текстуры или непостоянные углы обзора.
В этой работе представлена новая модель диффузии текста в 3D, управляемая визуальными подсказками (VP3D), которая явно включает знания о визуальном внешнем виде в 2D-визуальные подсказки для улучшения генерации текста в 3D. Вместо того, чтобы просто контролировать SDS с помощью текстовых подсказок, VP3D сначала использует 2D-модель диффузии для создания высококачественных изображений из входного текста, которые затем используются в качестве визуальных подсказок для улучшения оптимизации SDS за счет явного визуального оформления. В то же время оптимизация SDS сочетается с дополнительной функцией дифференцируемого вознаграждения, которая побуждает изображения визуализированных 3D-моделей лучше согласовываться с 2D-визуальными подсказками и семантически соответствовать текстовым подсказкам.
Обширные эксперименты показывают, что 2D-визуальные подсказки в VP3D значительно упрощают изучение внешнего вида 3D-моделей и, таким образом, имеют более высокую визуальную точность и более детальные текстуры. Когда автоматически сгенерированные визуальные подсказки заменяются заданным эталонным изображением, VP3D может запустить новую задачу, а именно генерацию стилизованного текста в 3D. https://vp3d-cvpr24.github.io/
20. Восстановление изображения
69、Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting
Диффузионно-вероятностные модели шумоподавления (DDPM) для закрашивания изображения предназначены для добавления шума к текстуре изображения в прямом процессе и восстановления замаскированных областей в немаскированные области текстуры посредством обратного процесса шумоподавления. Хотя существующие методы могут генерировать значимую семантику, они страдают от семантического несоответствия между маскированными и немаскированными областями.
В этой статье рассматривается вопрос о том, как немаскированная семантика может направлять процесс шумоподавления текстур и как можно решить проблему семантических различий, чтобы обеспечить последовательную и содержательную генерацию семантики. Модель диффузии на основе структуры для восстановления изображений, называемая StrDiffusion, предлагается переформулировать традиционный процесс шумоподавления текстур под руководством структуры и получить упрощенную цель восстановления изображения и шумоподавления: 1) На ранней стадии помогает семантическая разреженная структура. Чтобы решить проблему семантических различий, плотные текстуры генерируют разумную семантику на более поздних этапах: 2) Семантика немаскированных областей по существу обеспечивает структурное руководство для процесса шумоподавления текстуры, которое получается из разреженности текстуры, связанной со временем; структурная семантика полезна. Для процесса шумоподавления структурно-ориентированная нейронная сеть обучается оценивать упрощенные цели шумоподавления, используя согласованность структуры шумоподавления между маскированными и немаскированными областями.
Более того, стратегия адаптивной повторной выборки разработана как формальный критерий того, может ли структура управлять процессом шумоподавления текстур, одновременно регулируя семантическую корреляцию между ними. Обширные эксперименты подтверждают преимущества StrDiffusion перед современными методами. https://github.com/htyjers/StrDiffusion
21. Связанные с эскизами
70、It’s All About Your Sketch: Democratising Sketch Control in Diffusion Models

В этой статье раскрывается потенциал эскизов в диффузионных моделях и рассматривается вводящая в заблуждение проблема прямого управления эскизами в генеративном искусственном интеллекте. Это позволяет любительским эскизам создавать точные изображения, понимая, что «что вы рисуете, то и получаете».
Мы предлагаем структуру для иерархий осведомленности, которая использует различительное руководство от адаптера эскиза, адаптивную временную выборку и предварительно обученную модель поиска мелкозернистых изображений эскизов, работая вместе для улучшения мелкозернистых ассоциаций эскиза и фотографии. Метод может беспрепятственно работать в процессе рассуждения без текстовых подсказок; нам, обычным людям, достаточно простого и грубого наброска!
71、Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Эта статья является первой, в которой исследуются модели диффузии текста в изображение при поиске изображений на основе эскизов с нулевым выстрелом (ZS-SBIR). Подчеркивая способность модели диффузии текста к изображению плавно соединять эскизы и фотографии. Эта возможность подкреплена их надежными кросс-модальными возможностями и предвзятостью формы, результаты подтверждены предварительными исследованиями.
Для эффективного использования предварительно обученных моделей диффузии представлена простая, но мощная стратегия, которая фокусируется на двух ключевых аспектах: выборе лучшего слоя признаков и использовании визуальных и текстовых подсказок. В первом случае определите, какие уровни насыщены информацией и лучше всего подходят для конкретных требований к поиску (уровень категории или детальный уровень). Затем визуальные и текстовые подсказки используются для управления процессом извлечения признаков модели, что позволяет ей генерировать более различительные и контекстуальные кросс-модальные представления. Обширные эксперименты с несколькими базовыми наборами данных подтверждают значительное улучшение производительности.
22. Конфиденциальность авторских прав
72、CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
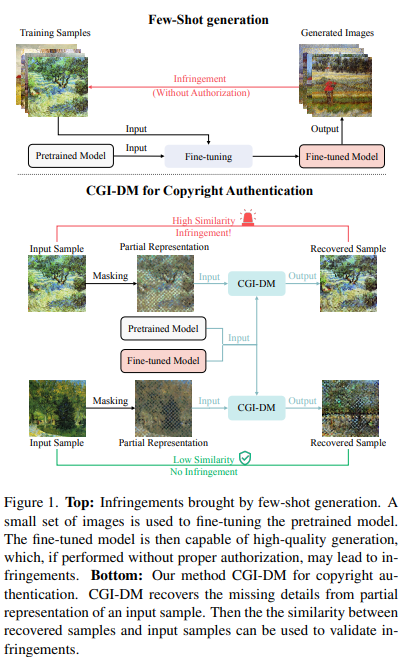
Модели диффузии (DM) используются для генерации нескольких кадров, когда предварительно обученная модель точно настраивается на небольшом количестве образцов изображений для захвата определенного стиля или объекта. Несмотря на успех, существуют опасения, что использование несанкционированных данных может привести к нарушению авторских прав. Поэтому для цифровой аутентификации авторских прав предлагается новый метод модели диффузии с инверсией контрастного градиента под названием CGI-DM с ярким визуальным представлением.
Метод предполагает удаление части информации из изображения и восстановление утраченных деталей за счет использования концептуальных различий между предварительно обученными и точно настроенными моделями. Разница между двумя скрытыми переменными формализуется как расхождение KL, которое можно максимизировать с помощью выборки Монте-Карло и прогнозируемого градиентного спуска при наличии одного и того же входного изображения. Сходство между оригинальным и восстановленным изображениями может служить убедительным индикатором потенциального нарушения прав.
Обширные эксперименты с наборами данных WikiArt и Dreambooth демонстрируют высокую точность CGI-DM в цифровой аутентификации авторских прав, превосходящую другие методы проверки. https://github.com/Nicholas0228/Revelio
73、CPR: Retrieval Augmented Generation for Copyright Protection

Поисковая дополненная генерация (RAG) — это гибкий и мощный метод, который адаптирует модели к частным данным пользователя без обучения, управляет атрибуцией кредитов и позволяет эффективно отучиваться машинам в масштабе. Однако метод RAG для генерации изображений может привести к копированию частей полученной выборки в выходные данные модели.
Чтобы снизить риск утечки частной информации, содержащейся в поисковой коллекции, мы предлагаем генерацию с защитой от копирования с поиском (CPR), новый метод RAG с надежной гарантией защиты авторских прав в смешанной частной среде, подходящий для модели диффузии.
CPR связывает выходные данные диффузионной модели с набором полученных изображений, гарантируя при этом, что в сгенерированных выходных данных не содержится никакой однозначно идентифицируемой информации об этих примерах. В частности, он делает это путем выборки из смеси общедоступных (безопасности) и частных (пользовательских) распределений путем объединения оценок распространения общедоступных (безопасности) и частных (пользовательских) распределений во время вывода. CPR удовлетворяет почти независимости доступа (NAF), свойству, которое ограничивает объем информации, которую злоумышленник может извлечь из сгенерированного изображения. Предусмотрено два алгоритма защиты авторских прав: CPR-KL и CPR-Choose. В отличие от ранее предложенных методов NAF, основанных на отбраковке выборки, наш метод обеспечивает эффективную выборку, защищенную авторскими правами, с помощью одного прогона обратной диффузии.
Показывает, как этот метод можно применить к любой предварительно обученной модели условной диффузии, такой как Stable Diffusion или unCLIP. В частности, экспериментально показано, что применение CPR к unCLIP может улучшить качество генерируемых результатов и выравнивание текста к изображению (с 81,4 до 83,17 по тесту TIFA).
23. Увеличение данных
74、SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation
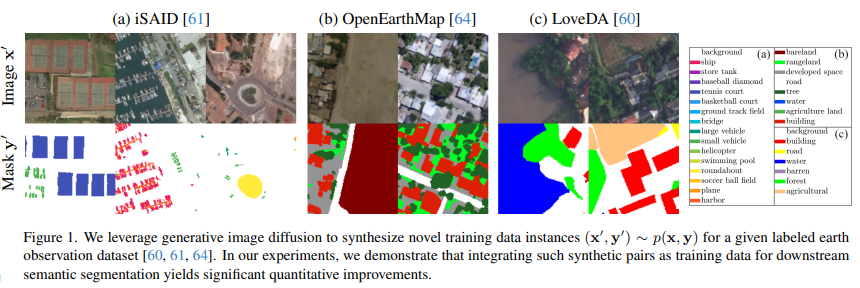
В последние годы семантическая сегментация стала ключевым инструментом обработки и интерпретации спутниковых изображений. Однако основным ограничением методов контролируемого обучения остается необходимость обширного ручного аннотирования экспертами. В этом исследовании изучается потенциал использования генеративной диффузии изображений для решения проблемы нехватки аннотированных данных в миссиях по наблюдению Земли. Основная идея состоит в том, чтобы изучить совместное многообразие данных изображений и меток, используя последние достижения в области шумоподавления диффузионно-вероятностных моделей.
Эта статья претендует на звание первой работы по созданию изображений и соответствующих масок для спутниковой сегментации. Полученные пары изображения и маски не только имеют высокое качество с точки зрения детализации функций, но и обеспечивают широкое разнообразие выборки. Эти два аспекта имеют решающее значение для данных наблюдения Земли, поскольку семантические категории могут сильно различаться по масштабу и частоте появления. Используйте новые экземпляры данных для последующей сегментации в качестве формы увеличения данных.
Эксперименты сравниваются с предыдущими работами, основанными на моделях дискриминационной диффузии или GAN. Показано, что интеграция сгенерированных выборок позволяет значительно улучшить количественные результаты спутниковой семантической сегментации не только по сравнению с базовыми показателями, но и при обучении с использованием только необработанных данных.
75、ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object

Эта статья устанавливает строгие критерии надежности зрительного восприятия. Синтетические изображения, такие как ImageNet-C, ImageNet-9 и Stylized ImageNet, обеспечивают оценку конкретного типа на предмет синтетического разрушения, фона и текстуры, однако эти тесты надежности ограничены с точки зрения заданных изменений, а также качества синтеза. В этой работе генеративные модели представлены в качестве источника данных для обеспечения надежности глубоких моделей синтетического обнаружения.
Используя модель диффузии, мы генерируем изображения с более разнообразным фоном, текстурами и материалами, чем любая предыдущая работа, и называем этот тест ImageNet-D. Результаты экспериментов показывают, что ImageNet-D приводит к значительному снижению точности — до 60 % — для ряда визуальных моделей, от стандартного визуального классификатора ResNet до новейших базовых моделей, таких как CLIP и MiniGPT-4. Работа показывает, что диффузионные модели могут быть эффективным источником данных для тестирования моделей видения. https://github.com/chenshuang-zhang/imagenet_d
24. Медицинские изображения
76、MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant
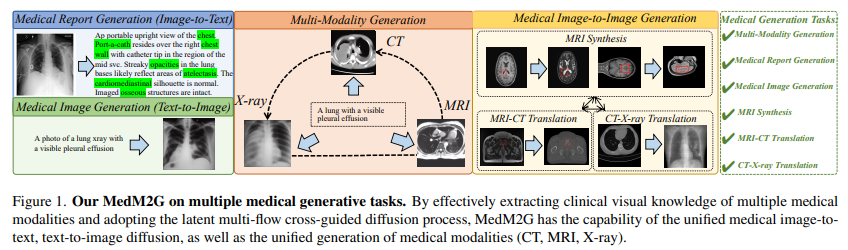
Генеративные модели в медицине ускорили быстрый рост медицинских приложений. Однако недавние исследования были сосредоточены на отдельных медицинских генеративных моделях, причем разные модели предназначены для разных медицинских задач, и имеют серьезные ограничения в медицинских мультимодальных знаниях, что ограничивает комплексную медицинскую диагностику.
В этом документе предлагается MedM2G, медицинская мультимодальная структура генерации, ключевое новшество которой заключается в согласовании, извлечении и генерации медицинских мультимодальностей в единой модели. Эффективно согласуйте медицинские мультимодальности с помощью методов централизованного согласования в едином пространстве, а не просто один или два медицинских метода. Примечательно, что эта система извлекает ценные клинические знания, поддерживая медицинскую визуальную инвариантность каждого метода визуализации, тем самым улучшая конкретную медицинскую информацию, генерируемую мультимодальностью. Включая адаптивные условия с перекрестными параметрами в многопоточную диффузионную структуру, модель способствует гибкому взаимодействию между медицинскими мультимодальностями для генерации.
MedM2G — это первая унифицированная модель медицинского поколения, которая может выполнять унифицированное преобразование текста в изображение, изображение в текст и медицинские методы (КТ, МРТ, рентген). Она может выполнять 5 медицинских задач на 10 наборах данных и продолжает это делать. превосходить различные современные работы.
25. Вождение в пробке
77、Controllable Safety-Critical Closed-loop Traffic Simulation via Guided Diffusion
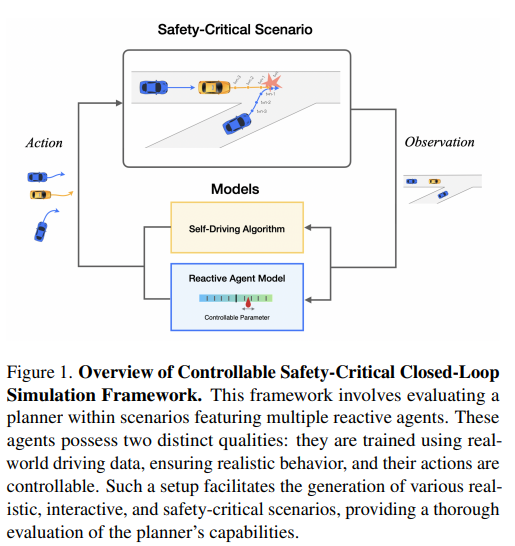
Оценка эффективности алгоритмов планирования автономного вождения требует моделирования сценариев дорожного движения с длинным хвостом. Традиционные методы создания ключевых сцен часто не обеспечивают реалистичности и управляемости. Более того, эти методы обычно игнорируют динамические взаимодействия между агентами. Чтобы смягчить эти ограничения, предлагается новая система моделирования с замкнутым контуром, основанная на модели управляемой диффузии.
Этот метод имеет два очевидных преимущества: 1) создание реалистичных сценариев с длинным хвостом, которые очень близки к реальным условиям, и 2) повышение управляемости, позволяющее проводить более полную и интерактивную оценку. Это достигается за счет улучшения движения по дорогам, уменьшения количества столкновений и отключений от сети. Разработка нового подхода путем моделирования критических для безопасности сценариев путем введения состязательных условий в процесс шумоподавления позволяет бросить вызов планировщикам транспортных средств и гарантирует, что все агенты в сценарии демонстрируют отзывчивое и реалистичное поведение.
Эмпирическая проверка была проведена на основе набора данных NuScenes, продемонстрировав улучшение точности и управляемости. Эти результаты подтверждают, что модель управляемой диффузии обеспечивает мощную и гибкую основу для критически важного для безопасности интерактивного моделирования дорожного движения, расширяя ее полезность в области автономного вождения. https://safe-sim.github.io/
78、Generalized Predictive Model for Autonomous Driving
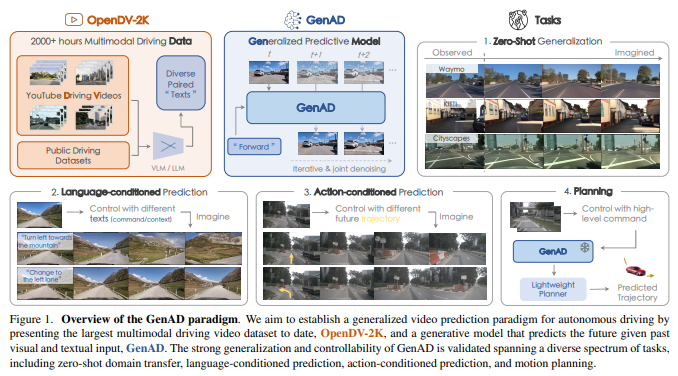
В этой статье предлагается первая крупномасштабная модель прогнозирования видео в области автономного вождения. Чтобы устранить ограничения, связанные с дорогостоящим сбором данных, и расширить возможности обобщения модели, большие объемы данных получаются из Интернета и сопровождаются разнообразными и высококачественными текстовыми описаниями.
В наборе данных собрано более 2000 часов видеозаписей вождения, охватывающих различные погодные условия и сценарии дорожного движения по всему миру. Унаследовав преимущества последних моделей скрытой диффузии, модель под названием GenAD справляется со сложной динамикой в сценариях управления с помощью нового модуля временного вывода. Показано, что он может с нулевым результатом обобщать различные невидимые наборы данных о вождении, превосходя по эффективности общие или только вождение противники видеопрогнозирования. Кроме того, GenAD можно настроить как модель прогнозирования или планировщик действий для условий действия, что имеет большой потенциал в практических приложениях для вождения.
26. Связанные с голосом
79、FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
Предлагается FaceTalk1, метод нового поколения для генерации высококачественных трехмерных последовательностей движений головы человека на основе входных аудиосигналов. Чтобы уловить выразительные, детальные особенности человеческой головы, включая волосы, уши и тонкие движения глаз, предлагается объединить речевые сигналы со скрытым пространством нейронной параметризованной модели головы для создания высокоточных, согласованных во времени последовательностей движений.
Для этой задачи предлагается новая модель потенциальной диффузии, действующая в пространстве выражений нейронной параметризованной модели головы, для синтеза реалистичных последовательностей головы, управляемых звуком. При отсутствии набора данных с соответствующими выражениями NPHM для звука эти соответствия оптимизируются для создания набора наборов данных аудио- и видеозаписи, которые совместимы с постоянно оптимизированными выражениями NPHM говорящих. В этой статье утверждается, что впервые предложен метод генерации для реализации реалистичного и высококачественного синтеза движений объемных человеческих голов, что представляет собой важный прогресс в области трехмерной анимации, управляемой звуком.
Метод хорошо работает при создании правдоподобных последовательностей движений, которые создают высококачественную анимацию головы, связанную с пространством форм NPHM. Результаты экспериментов подтверждают эффективность FaceTalk, превосходя существующие методы на 75% по перцептивной оценке пользователей. https://shivangi-aneja.github.io/projects/facetalk/
80、ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis
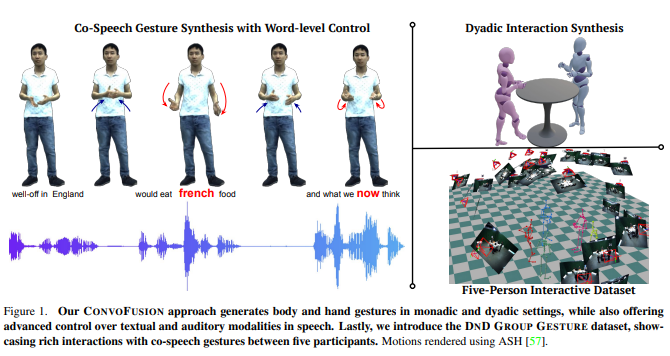
Жесты играют ключевую роль в человеческом общении. Современные методы позволяют генерировать действия, соответствующие ритму речи, но по-прежнему испытывают трудности с созданием жестов, соответствующих семантике высказывания. В отличие от ритмических жестов, которые естественным образом соответствуют звуковым сигналам, семантически последовательные жесты требуют моделирования сложного взаимодействия между языком и движениями человека, и ими можно управлять, сосредоточив внимание на конкретных словах.
Предлагается CONVOFUSION — метод мультимодального синтеза жестов на основе диффузии, который может не только генерировать жесты на основе мультимодального речевого ввода, но и обеспечивать управляемость при синтезе жестов. Метод предлагает две цели руководства, позволяя пользователям регулировать влияние различных условных модальностей (например, звука или текста) и выбирать подчеркивание определенных слов во время жестов. Этот метод очень гибок, и его можно обучить генерированию монологических или диалоговых жестов. В целях дальнейшего продвижения исследований многосторонних интерактивных жестов был выпущен набор данных DND GROUP GESTURE, который содержит 6 часов данных о жестах и взаимодействиях между 5 людьми. Метод сравнивается с рядом последних работ и показана эффективность метода на различных задачах. https://vcai.mpi-inf.mpg.de/projects/ConvoFusion/
81、Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners
Создание видео и аудио контента — основная технология для киноиндустрии и профессиональных пользователей. В последнее время существующие методы, основанные на диффузии, обрабатывают генерацию видео и аудио отдельно, что затрудняет передачу технологий из академических кругов в промышленность. В этой работе предлагается тщательно разработанная структура перекрестного аудиовизуального и совместного аудиовизуального производства, основанная на оптимизации.
Предлагается использовать существующие мощные модели и общее скрытое пространство для построения мостов вместо обучения огромных моделей с нуля. В частности, предлагается мультимодальный выравниватель скрытого пространства, аналогичный предварительно обученной модели ImageBind. Выравниватель скрытого пространства имеет ядро, аналогичное начальной загрузке классификатора, направляя процесс диффузионного шумоподавления во время вывода.
Благодаря тщательно разработанным стратегиям оптимизации и функциям потерь демонстрируется превосходная производительность метода в задачах совместной генерации видео-аудио, видео-ориентированной генерации звука и аудио-ориентированной визуальной генерации. https://yzxing87.github.io/Seeing-and-Hearing/
27. Оценка осанки
82、Object Pose Estimation via the Aggregation of Diffusion Features
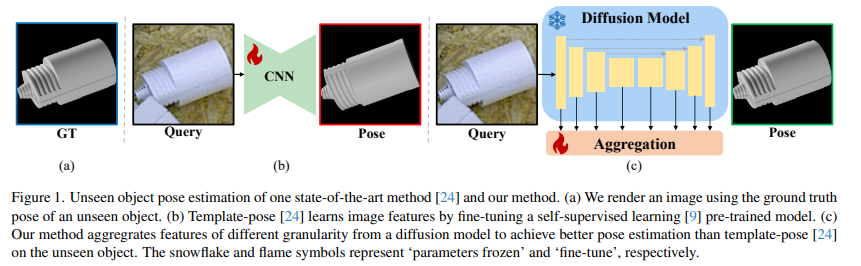
Оценка позы объектов по изображениям является ключевой задачей для понимания трехмерных сцен, и последние методы позволили добиться многообещающих результатов на очень больших наборах контрольных данных. Однако производительность этих методов существенно падает при работе с невидимыми объектами. Это вызвано ограниченной обобщаемостью признаков изображения.
Для решения этой проблемы проводится углубленный анализ особенностей моделей диффузии, таких как стабильная диффузия, которые имеют значительный потенциал в моделировании невидимых объектов. На основе этого анализа эти диффузионные характеристики вводятся для оценки позы объекта. Для достижения этой цели предлагаются три различные архитектуры, которые могут эффективно захватывать и агрегировать диффузионные характеристики с разной степенью детализации, что значительно повышает универсальность оценки позы объекта.
Производительность метода на трех часто используемых наборах эталонных данных: LM, O-LM и T-LESS лучше, чем существующие методы, особенно на невидимых объектах, он обеспечивает более высокую точность: на невидимых объектах. На наборе данных LM точность метода составляет 98,2%, в то время как предыдущий лучший метод составляет 93,5%; на невидимом наборе данных O-LM точность составляет 85,9%, тогда как предыдущий лучший метод составляет 76,3%, что демонстрирует высокую универсальность метода. https://github.com/Tianfu18/diff-feats-pose
28. Изображение, связанное с изображением
83、DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
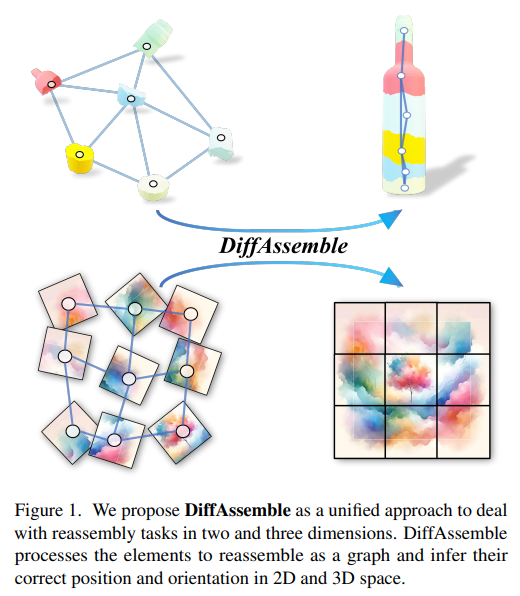
Задачи повторной сборки играют фундаментальную роль во многих областях, и существует множество методов решения конкретных проблем. В этом контексте общая унифицированная модель может эффективно решить все эти проблемы независимо от типа входных данных: изображение, 3D и т. д.
Предложите DiffAssemble, архитектуру на основе графовой нейронной сети (GNN), которая обучается с помощью диффузионных моделей. Метод рассматривает элементы 2D-патча или фрагмента 3D-объекта как узлы пространственного графа. Во время обучения в положение и вращение элементов вносится шум, а согласованная начальная поза восстанавливается посредством итеративного шумоподавления. DiffAssemble обеспечивает самые современные результаты в большинстве 2D- и 3D-задач и является первым методом обучения, позволяющим решать 2D-головоломки вращения и перемещения. Кроме того, мы подчеркиваем значительное сокращение времени работы: оно до 11 раз быстрее, чем самый быстрый метод, основанный на оптимизации. https://github.com/IIT-PAVIS/DiffAssemble
29. Обнаружение или генерация действий
84、Action Detection via an Image Diffusion Process

Обнаружение действий направлено на определение начальных и конечных точек экземпляров действий в видео и прогнозирование категорий этих экземпляров. В этой статье отмечается, что результаты задач обнаружения действий могут быть выражены в виде изображений. Таким образом, начиная с новой точки зрения, с помощью предложенной структуры распространения изображений обнаружения действий (ADI-Diff) прогнозируемые изображения начальной точки, конечной точки и категории действия генерируются с помощью трех процессов генерации изображений.
Кроме того, поскольку изображения, упомянутые в этой статье, отличаются от естественных изображений и обладают особыми свойствами, процесс диффузии обнаружения дискретных действий и конструкция преобразователя строк и столбцов дополнительно изучаются, чтобы лучше обрабатывать их. Платформа ADI-Diff обеспечивает самые современные результаты на двух широко используемых наборах данных.
85、Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
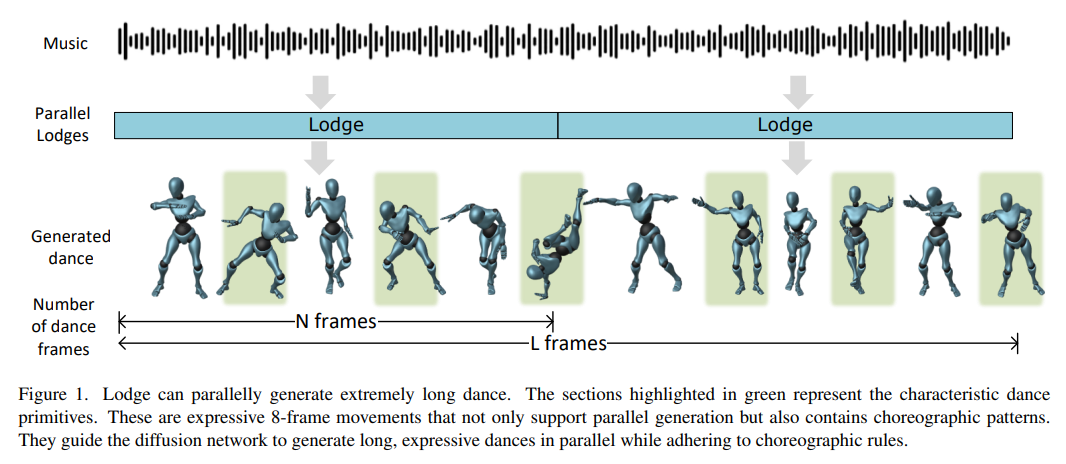
Предлагайте Lodge, сеть, которая генерирует чрезвычайно длинные танцевальные эпизоды на основе заданной музыки. Лодж спроектирован как двухэтапная архитектура диффузии от грубой к тонкой, а характерные танцевальные примитивы предлагаются в качестве промежуточного представления между двумя моделями диффузии.
Первый этап – это глобальное распространение, направленное на понимание общих корреляций между музыкой и танцем и создание характерных танцев. Второй этап — локальное распространение, основанное на правилах танца и хореографии при создании детальных последовательностей действий. Кроме того, предлагается модуль уточнения стопы для оптимизации контакта стоп с землей, повышения физической реалистичности движений.
Этот подход уравновешивает взаимосвязь между глобальными хореографическими моделями и локальным качеством и выразительностью движений. Большое количество экспериментов подтвердило эффективность метода. https://li-ronghui.github.io/lodge
86、OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
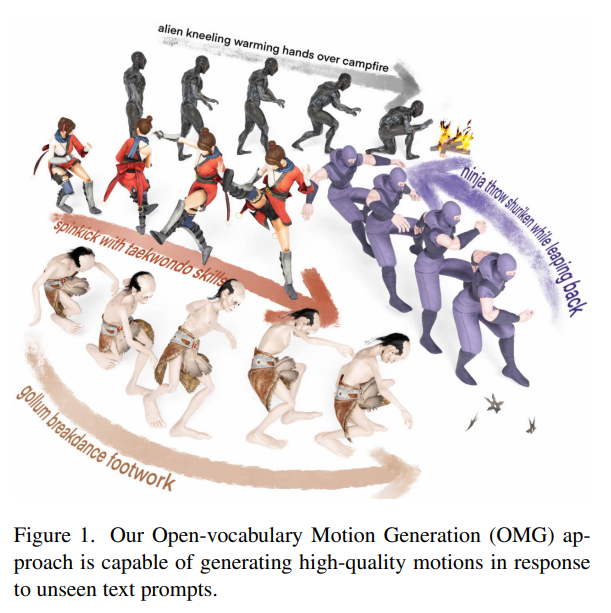
Недавний прогресс в создании фотореалистичного преобразования текста в движение. Однако существующие методы часто терпят неудачу или производят необоснованные действия при обработке невидимого ввода текста, что ограничивает область применения.
В этой статье предлагается новая структура OMG для генерации убедительных действий из текстовых подсказок с открытым словарем. Основная идея заключается в точной настройке парадигмы предварительной подготовки и точной настройки для генерации текста в движение. На этапе предварительного обучения модель улучшает генеративные возможности, изучая богатые внешние функции внутреннего движения. С этой целью крупномасштабная модель безусловной диффузии масштабируется до 1 миллиарда параметров и позволяет использовать более 20 миллионов немаркированных данных экземпляра движения. На последующем этапе тонкой настройки вводится сеть управления движением (ControlNet), которая объединяет текстовые сигналы в качестве нормативной информации с помощью обучаемой предварительно обученной модели и предлагаемого нового блока гибридного контроллера (MoC). Блок MoC адаптивно идентифицирует различные диапазоны поддвижений с помощью механизма перекрестного внимания и выполняет обработку сегментации с использованием экспертов, специализирующихся на текстовых токенах. Такая конструкция эффективно встраивает токены CLIP с текстовыми подсказками в широкий спектр компактных и выразительных функций движения.
Обширные эксперименты показывают, что OMG достигает значительных улучшений в генерации текста в движение с нулевым кадром, превосходя по производительности самые современные методы. https://tr3e.github.io/omg-page/
30. Планирование роботов/интеллектуальное принятие решений
87、SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
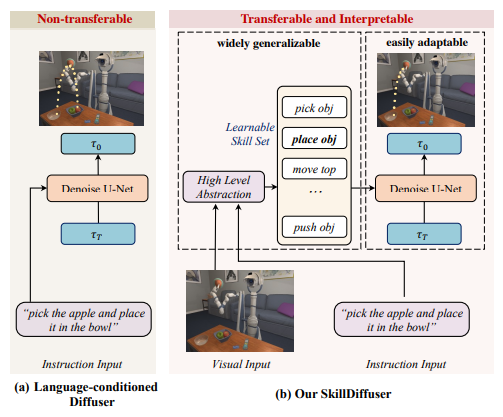
Диффузионные модели показали потенциал в планировании траектории движения роботов. Однако создание последовательных траекторий из инструкций высокого уровня остается сложной задачей, особенно для комбинаторных задач дальнего действия, требующих нескольких последовательных навыков.
Предложите SkillDiffuser, комплексную иерархическую структуру планирования, которая сочетает в себе интерпретируемое обучение навыкам с планированием условного распространения. На более высоком уровне модуль абстракции навыков изучает дискретные, понятные человеку представления навыков на основе визуальных наблюдений и устных инструкций. Эти внедрения приобретенных навыков затем используются для настройки модели распространения для создания индивидуальных скрытых траекторий, соответствующих навыкам. Это генерирует разнообразные траектории состояний, соответствующие обучаемым навыкам. Объединив обучение навыкам с созданием условной траектории, SkillDiffuser способен генерировать согласованное поведение, следуя абстрактным инструкциям в различных задачах.
Эксперименты с многозадачными тестами манипулирования роботами, такими как Meta-World и LOReL, демонстрируют достижения SkillDiffuser в производительности и интерпретируемом человеком представлении навыков. https://skilldiffuser.github.io/
31. Генерация визуального повествования-истории
88、Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models

Генеративные модели недавно продемонстрировали отличные возможности преобразования текста в изображение, но все еще испытывают трудности с последовательной генерацией последовательностей изображений. Эта работа посвящена новой и сложной задаче создания связной последовательности изображений на основе заданной сюжетной линии, известной как открытое визуальное повествование.
Были внесены следующие три вклада: (i) Для выполнения задачи визуального повествования предлагается авторегрессионная модель генерации изображений StoryGen, основанная на обучении, с использованием нового модуля визуально-лингвистического контекста, чтобы сгенерированный текущий кадр мог быть сгенерирован с соответствующими текстовые подсказки и предыдущие пары изображений и подписей используются в качестве условий; (ii) чтобы решить проблему нехватки визуальных повествовательных данных, мы собрали данные из онлайн-видео и электронных книг с открытым исходным кодом; Для последовательностей изображений и текста был создан конвейер обработки крупномасштабных наборов данных, содержащих разнообразные персонажи, сюжетные линии и художественные стили, под названием StorySalon (iii) количественные эксперименты и человеческие оценки подтвердили превосходство StoryGen, продемонстрировав возможность обобщения невидимого; символы без какой-либо оптимизации и генерировать последовательности изображений с последовательным содержанием и согласованностью. https://haoningwu3639.github.io/StoryGen_Webpage/
32. Причинная атрибуция
89、 ProMark: Proactive Diffusion Watermarking for Causal Attribution
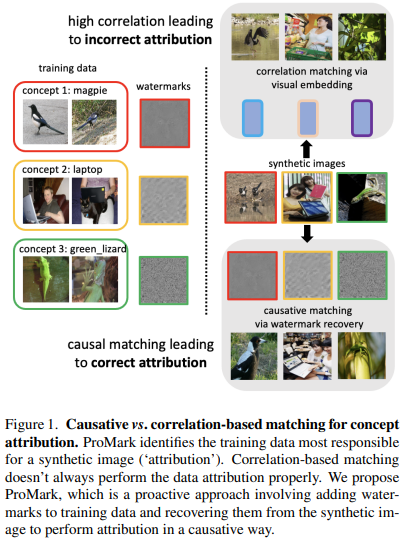
Генеративный искусственный интеллект (GenAI) трансформирует творческие рабочие процессы благодаря возможности расширенных подсказок, синтеза и манипулирования изображениями. Однако творческим людям не хватает поддержки для получения признания или вознаграждений за контент, который они используют в обучении GenAI. С этой целью предлагается ProMark — метод причинно-следственной атрибуции, который приписывает сгенерированные изображения понятиям в обучающих данных, таким как объекты, предметы, шаблоны, художники или стили. Концептуальная информация активно внедряется во входные обучающие изображения с использованием незаметных водяных знаков, а модели диффузии (безусловные или условные) обучаются сохранять соответствующие водяные знаки в сгенерированных изображениях.
Демонстрирует, что в обучающие данные можно внедрить до 2^16 уникальных водяных знаков, а каждое обучающее изображение может содержать несколько водяных знаков. ProMark сохраняет качество изображения, превосходя при этом атрибуцию на основе корреляции. Наконец, представлены некоторые качественные примеры, при которых наличие водяного знака передает причинно-следственную связь между обучающими данными и синтетическими изображениями.
33. Оценка состязательной защиты конфиденциальности
90、Robust Imperceptible Perturbation against Diffusion Models
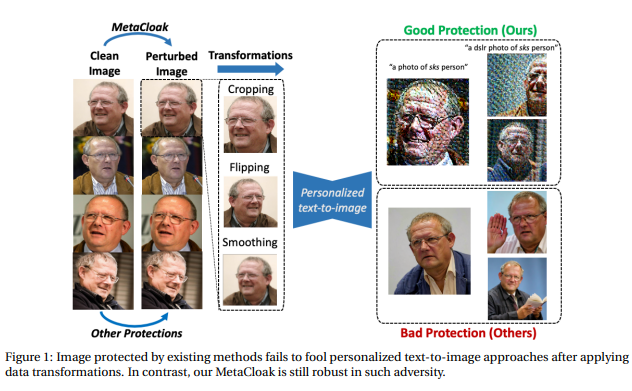
Модель диффузии текста в изображение генерирует персонализированные изображения из эталонных фотографий. Однако в чужих руках эти инструменты могут создать вводящий в заблуждение или вредный контент и поставить под угрозу личную безопасность. Чтобы решить эту проблему, существующие методы защиты тонко изменяют изображения пользователей, делая их «необучаемыми» для злоумышленников. Эти методы имеют два ограничения: во-первых, неоптимальные результаты из-за эвристики, разработанной вручную; во-вторых, недостаточная устойчивость к простым преобразованиям данных (таким как фильтрация по Гауссу).
Для решения этих проблем предлагается MetaCloak, использующий структуру метаобучения для создания переносимых и надежных возмущений посредством дополнительного процесса выборки преобразования. В частности, набор альтернативных моделей диффузии используется для построения переносимых и независимых от модели возмущений. Кроме того, путем введения дополнительного процесса преобразования, разработки простого шумоподавления, максимизирующего потери, достаточно, чтобы вызвать устойчивые к преобразованию семантические искажения и деградацию при генерации персонализации.
Эксперименты с наборами данных VGGFace2 и CelebA-HQ показывают, что MetaCloak превосходит существующие методы. Стоит отметить, что MetaCloak может успешно обманывать сервисы онлайн-обучения, такие как Replication, демонстрируя эффективность MetaCloak в реальных сценариях в виде «черного ящика». https://github.com/liuyixin-louis/MetaCloak
34. Дополнение-улучшение диффузионной модели.
91、Condition-Aware Neural Network for Controlled Image Generation
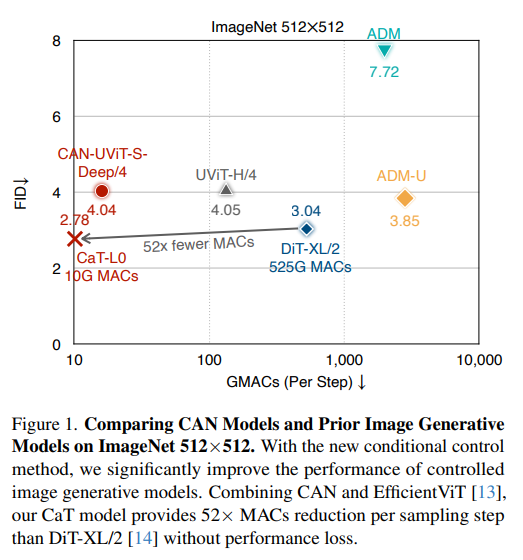
Предложите нейронную сеть с учетом условий (CAN), новый метод добавления контроля к моделям генерации изображений. Параллельно с предыдущими методами условного управления CAN управляет процессом генерации изображения, динамически манипулируя весами нейронной сети. С этой целью вводится модуль генерации весов с учетом условий для генерации условных весов для сверточных/линейных слоев на основе входных условий.
Генерация изображений с учетом классов выполнялась в ImageNet, а генерация текста в изображение тестировалась в COCO. CAN последовательно обеспечивает значительные улучшения моделей диффузионных трансформаторов, включая DiT и UViT. В частности, CAN в сочетании с EfficientViT (CaT) достигает 2,78 FID в ImageNet 512×512, превосходя DiT-XL/2, при этом уменьшая количество MAC, необходимых для каждого шага отбора проб, в 52 раза. https://github.com/mit-han-lab/efficientvit
35. Интерактивная управляемая генерация
92、Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation

Точечное интерактивное редактирование — важный инструмент, дополняющий управляемость существующих генеративных моделей. DragDiffusion обновляет скрытую карту диффузии на основе пользовательского ввода, что приводит к неточному сохранению исходного содержимого и сбоям при редактировании. Предлагается DragNoise, обеспечивающий надежное и ускоренное редактирование без необходимости отслеживать скрытый граф.
Суть DragNoise заключается в использовании прогнозируемого выходного шума каждой сети U-Net в качестве семантического редактора. Этот подход основан на двух ключевых наблюдениях: во-первых, узкими местами U-Net являются по своей сути семантически богатые функции, подходящие для интерактивного редактирования; во-вторых, семантика высокого уровня устанавливается на ранних стадиях процесса шумоподавления и впоследствии демонстрирует минимальные изменения. Используя эти знания, DragNoise редактирует семантику диффузии за один шаг шумоподавления и эффективно распространяет эти изменения, обеспечивая стабильность и эффективность редактирования диффузии.
Сравнительные эксперименты показывают, что по сравнению с DragDiffusion DragNoise обеспечивает лучший контроль и сохранение семантики, а также сокращает время оптимизации более чем на 50%. https://github.com/haofengl/DragNoise
тридцать6. Восстановление изображения-Пополнить
93、Generating Content for HDR Deghosting from Frequency View
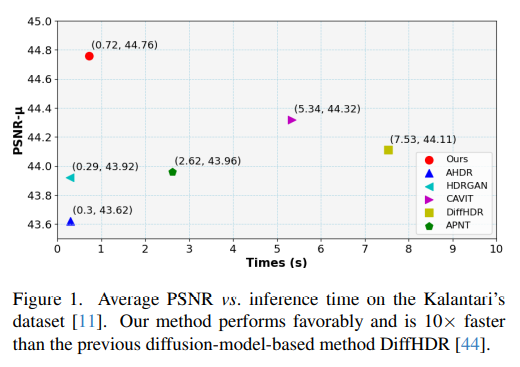
Восстановление изображения с высоким динамическим диапазоном (HDR) из нескольких изображений с низким динамическим диапазоном (LDR) является сложной задачей, когда изображения LDR насыщены и демонстрируют значительное движение. Недавно диффузионная модель (DM) была внедрена в области HDR-изображений. Однако DM требует обширных итераций с большими моделями для оценки всего изображения, что приводит к неэффективности и затруднению практического применения.
Для решения этой проблемы предлагается модель низкочастотной перцептивной диффузии (LF-Diff), подходящая для HDR-изображений. Ключевая идея LF-Diff — реализовать DM в очень компактном скрытом пространстве и интегрировать его в модель на основе регрессии для улучшения деталей реконструированного изображения. В частности, учитывая, что низкочастотная информация тесно связана со зрительным восприятием человека, DM используется для создания компактных низкочастотных априоров для процесса реконструкции. Кроме того, чтобы в полной мере использовать вышеупомянутые низкочастотные априорные данные, выполняется сеть динамической реконструкции HDR (DHRNet) на основе регрессии для получения окончательного изображения HDR.
Обширные эксперименты на синтетических и реальных наборах эталонных данных показывают, что LF-Diff превосходит некоторые современные методы и работает до 10 раз быстрее, чем предыдущие методы на основе DM.
37. Адаптация/перенос обучения предметной области
94、Unknown Prompt, the only Lacuna: Unveiling CLIP’s Potential for Open Domain Generalization
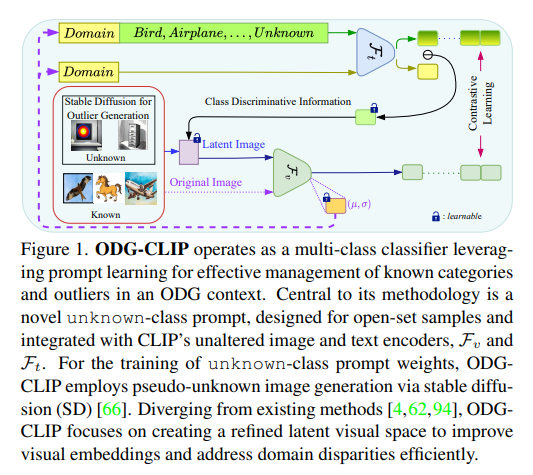
Углубленное исследование генерализации открытого домена (ODG), которое характеризуется преобразованием домена и класса между обучением аннотированных исходных доменов и тестированием неаннотированных целевых доменов. Существующие решения ODG сталкиваются с ограничениями из-за ограниченного обобщения традиционных магистральных сетей CNN и неспособности обнаруживать ошибки в целевых открытых выборках без предварительного знания. Для решения этих проблем предлагается ODG-CLIP, использующий семантические возможности визуально-языковой модели CLIP. Эта структура содержит три основных нововведения:
Во-первых, в отличие от существующих парадигм, ODG концептуализируется как задача классификации нескольких классов, включая известные классы и новые классы. Суть метода заключается в разработке уникального сигнала для обнаружения образцов неизвестного класса, а для обучения этого сигнала используется легкодоступная модель диффузии для элегантной генерации прокси-образов открытого класса.
Во-вторых, новый механизм обучения подсказкам, ориентированный на визуальный стиль, предназначен для получения весов классификации для конкретной предметной области, обеспечивая при этом баланс точности и простоты.
Наконец, знания о различении категорий, полученные из пространства сигналов, вводятся в изображение для повышения точности визуального внедрения CLIP. Введена новая цель — обеспечить непрерывность этого введенного семантического интеллекта в разных областях, особенно для общих категорий.
Благодаря тщательному тестированию на нескольких наборах данных, охватывающих контексты DG с закрытым и открытым набором, ODG-CLIP демонстрирует явные преимущества: повышение производительности варьируется от 8% до 16%, всегда опережая аналогичные методы. https://github.com/mainaksingha01/ODG-CLIP
Тридцать восемь, взаимодействие рук
95、Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
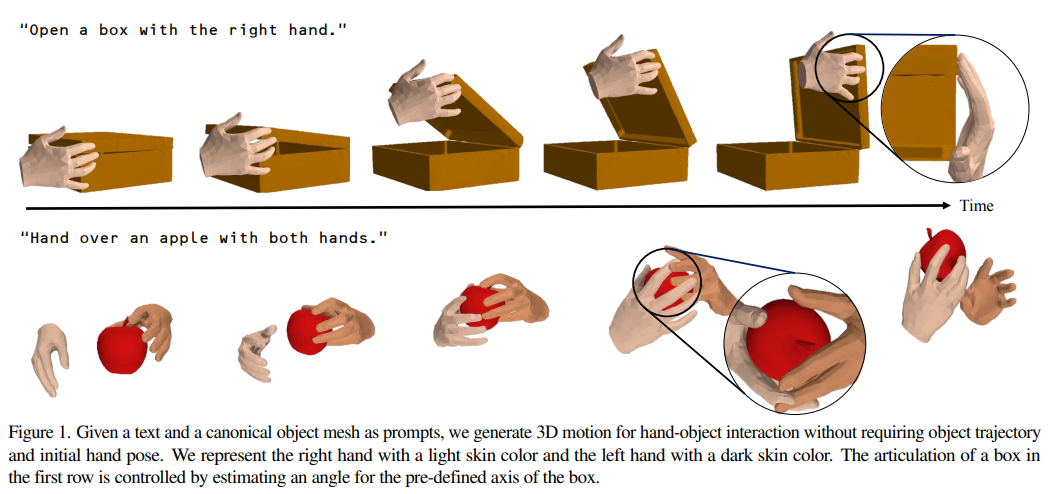
В этой статье представлена первая текстово-ориентированная работа по созданию последовательностей взаимодействия рук и предметов в 3D-средах. Основная проблема заключается в отсутствии маркированных данных. Существующие практические наборы данных не универсальны как по типам взаимодействия, так и по категориям объектов, что ограничивает правильные физические выводы на основе текстовых подсказок для моделирования различных трехмерных взаимодействий рук и объектов (например, контакта и семантики).
Для решения этой проблемы задача генерации взаимодействия разбивается на две подзадачи: генерация контакта руки с предметом и генерация движения руки с предметом. Для генерации контактов сеть на основе VAE принимает в качестве входных данных текст и сетки объектов, чтобы генерировать вероятность контакта между рукой и поверхностью объекта во время взаимодействия. Сеть изучает локальные изменения геометрической структуры различных объектов независимо от категории объектов и поэтому подходит для общих объектов. Для генерации движения модель диффузии на основе Transformer использует эту трехмерную карту контактов в качестве мощного предварительного средства для генерации возможных движений предметов рук на основе текстовых подсказок путем обучения на расширенном наборе помеченных данных.
Эксперименты показывают, что этот метод способен генерировать более реалистичные и разнообразные взаимодействия, чем другие базовые методы. Также покажите, что метод работает с невидимыми объектами. https://github.com/JunukCha/Text2HOI
96、InterHandGen: Two-Hand Interaction Generation via Cascaded Reverse Diffusion
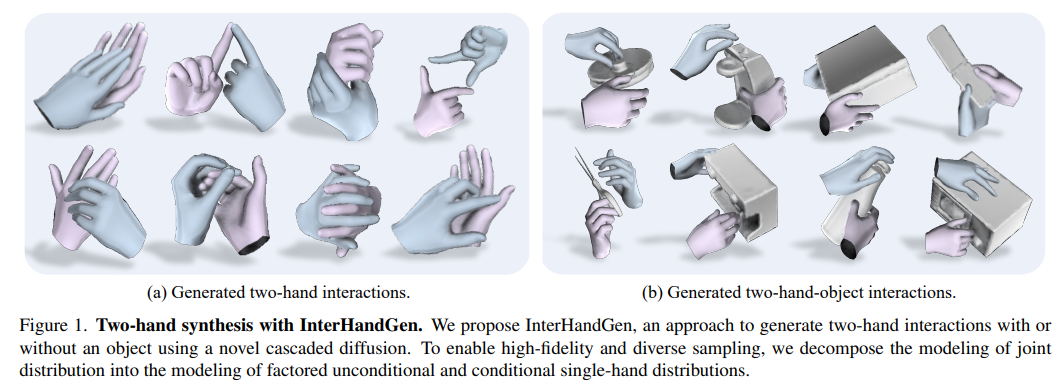
Предложите InterHandGen, новую структуру для изучения генеративных априорных принципов взаимодействия двумя руками. Выборка из модели дает форму рук для взаимодействия с объектами или без них. Приоритеты могут быть включены в любой метод оптимизации или обучения, чтобы уменьшить двусмысленность в некорректных задачах. Ключевое наблюдение заключается в том, что прямое моделирование совместного распределения нескольких экземпляров приводит к высокой сложности обучения из-за его комбинаторного характера. Поэтому предлагается декомпозировать совместное моделирование распределений на безусловное и условное моделирование декомпозированных единичных распределений. В частности, представлена диффузионная модель, которая изучает безусловное и условное распределение отдельных рук посредством условного исключения. При отборе проб для достижения разумной генерации сочетаются рекомендации по предотвращению проникновения и без классификатора.
Кроме того, установлен строгий протокол комплексной двуручной оценки, в котором метод значительно превосходит базовую генеративную модель с точки зрения реализма и разнообразия. Также продемонстрировано, что априорная диффузия может улучшить производительность реконструкции руки по монокулярным изображениям в поле, достигая самой современной точности. https://jyunlee.github.io/projects/interhandgen/
Тридцать девять, обнаружение камуфляжа
97、LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion

Маскировка зрительного восприятия — важная задача зрения, имеющая множество практических применений. Из-за высокой стоимости сбора и аннотирования эта область сталкивается с серьезным узким местом, поскольку категории видов в ее наборах данных ограничены лишь несколькими видами. Однако существующие методы создания камуфляжа требуют ручного указания фона и, следовательно, не могут расширить разнообразие образцов камуфляжа экономичным способом.
В этой статье предлагается метод диффузии на основе скрытого фона (LAKE-RED) для генерации камуфляжного изображения. Основной вклад включает в себя: (1) Впервые предложение парадигмы создания камуфляжа, не требующей получения каких-либо предварительных данных. (2) LAKE-RED — это первый интерпретируемый метод улучшения поиска знаний, предлагающий идею четкого разделения поиска знаний и улучшения рассуждений для облегчения проблем, связанных с конкретными задачами. Более того, метод не ограничивается конкретными объектами переднего плана или фона, предоставляя возможность расширить визуальное восприятие камуфляжа на более разнообразные области. (3) Результаты экспериментов показывают, что этот метод лучше существующих методов и создает более реалистичные камуфляжные изображения. https://github.com/PanchengZhao/LAKE-RED
40. Многозадачное обучение
98、DiffusionMTL: Learning Multi-Task Denoising Diffusion Model from Partially Annotated Data
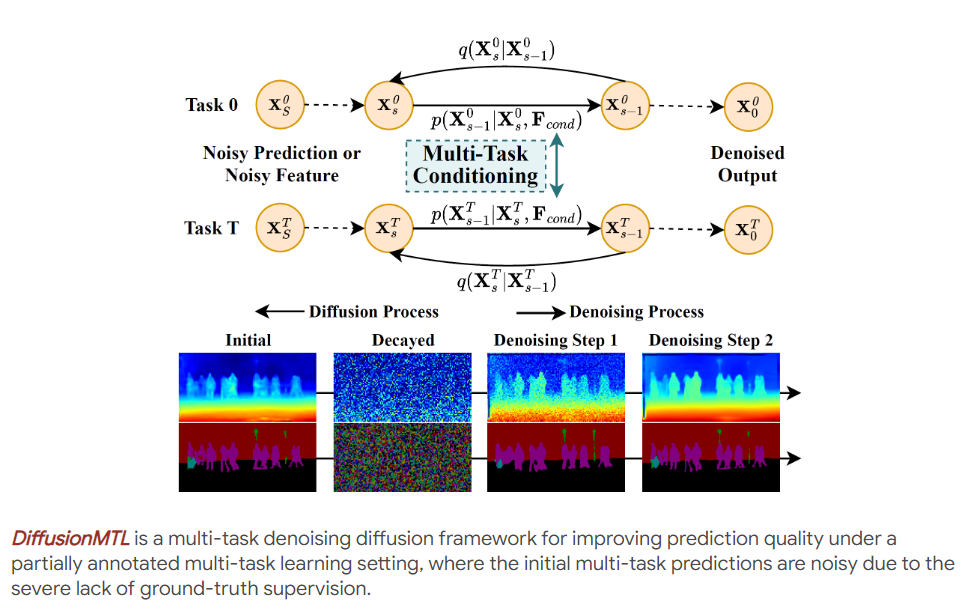
В последнее время растет интерес к практической проблеме обучения множеству задач понимания плотных сцен на основе частично помеченных данных, где каждая обучающая выборка помечена только для подмножества задач. Отсутствие меток задач в обучении приводит к низкому качеству и зашумленности прогнозов.
Чтобы решить эту проблему, частично помеченное многозадачное плотное предсказание переопределяется как проблема шумоподавления на уровне пикселей, и предлагается новая структура диффузии многозадачного шумоподавления под названием DiffusionMTL. Разработайте совместный режим диффузии и шумоподавления, чтобы смоделировать основное распределение шума в прогнозах задач или картах объектов и генерировать скорректированные выходные данные для различных задач. Чтобы использовать многозадачную согласованность при шумоподавлении, дополнительно вводится многозадачная условная стратегия, которая может неявно использовать взаимодополняемость задач, чтобы помочь изучить немаркированные задачи, тем самым улучшая производительность шумоподавления различных задач.
Количественные и качественные эксперименты показывают, что предложенная модель многозадачной диффузии с шумоподавлением может значительно улучшить производительность многозадачных карт прогнозирования и превзойти современные методы при двух разных настройках оценки аннотаций деталей. https://prismformore.github.io/diffusionmtl/
41. Прогнозирование траектории
99、SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model
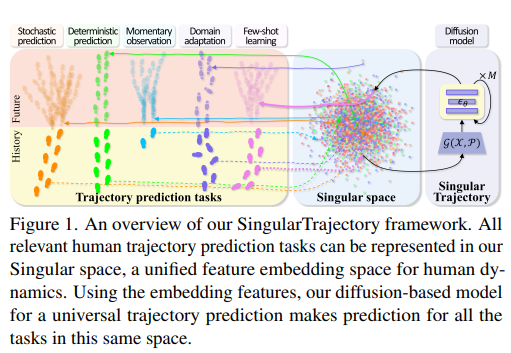
Существует пять типов задач прогнозирования траектории: детерминированные, стохастические, адаптация области, мгновенное наблюдение и малократные. Эти задачи корреляции определяются различными факторами, такими как длина входного пути, разделение данных и методы предварительной обработки. Интересно, что хотя они обычно принимают в качестве входных данных непрерывные координаты наблюдений и выводят будущие траектории с теми же координатами, для каждой задачи все равно необходимо разрабатывать специализированные архитектуры. Для других задач проблемы обобщения могут привести к неоптимальной производительности.
В этой статье предлагается SingularTrajectory, общая система прогнозирования траекторий на основе диффузии, позволяющая сократить разрыв в производительности между этими пятью задачами. Суть SingularTrajectory заключается в объединении различных представлений динамики человека в связанных задачах. Для этого сначала создается сингулярное пространство для проецирования всех типов моделей движения в каждой задаче в пространство внедрения. Затем введите адаптивный якорь для работы в сингулярном пространстве. В отличие от традиционных методов фиксированной привязки, которые иногда создают неприемлемые пути, адаптивные привязки могут включать в себя неправильно размещенные правильные привязки на основе графа проходимости. Наконец, используется предиктор на основе диффузии для дальнейшего улучшения пути прототипа посредством процесса каскадного шумоподавления.
Унифицированная структура обеспечивает обобщение при различных настройках тестов, таких как модальность входных данных и длина траектории. Обширные эксперименты с пятью общедоступными тестами показывают, что SingularTrajectory значительно превосходит существующие модели в оценке общей динамики движения человека, подчеркивая ее эффективность в оценке общей динамики движения человека. https://github.com/inhwanbae/SingularTrajectory
Сорок два, генерация сцены
100、SemCity: Semantic Scene Generation with Triplane Diffusion
предложить «SemCity», трехмерную диффузионную модель для создания семантических сцен в реальных условиях на открытом воздухе. Большинство 3D-моделей диффузии ориентированы на создание отдельных объектов, синтетических сцен в помещении или синтетических сцен на открытом воздухе, в то время как исследований по созданию реальных сцен на открытом воздухе мало. В этой статье основное внимание уделяется созданию реальных сцен на открытом воздухе путем изучения моделей диффузии на реальных наборах данных на открытом воздухе. В отличие от синтетических данных, реальные наборы данных на открытом воздухе обычно содержат больше пустых мест из-за ограничений датчиков, что создает проблемы при изучении реальных распределений на открытом воздухе.
Чтобы решить эту проблему, в качестве прокси-формы распределения сцен используется трехплоскостное представление, которое изучается с помощью модели диффузии. Экспериментальные результаты: трехплоскостная диффузионная модель показывает значимые результаты генерации по сравнению с существующей работой над реальным набором данных SemanticKITTI на открытом воздухе. Объекты на сцене также можно легко добавлять, удалять или изменять, а сцену также можно расширить до масштаба города. Наконец, метод оценивается при уточнении завершения семантической сцены, где модель диффузии улучшает прогнозы сети завершения семантической сцены путем изучения распределения сцен. https://github.com/zoomin-lee/SemCity
43. 3D корреляция/оценка потока
101、DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
Оценка потока сцены — основная задача в области компьютерного зрения, целью которой является прогнозирование трехмерного смещения каждой точки динамической сцены. Однако предыдущие работы часто приводили к ненадежным корреляциям из-за локально ограниченных диапазонов поиска и кумулятивных ошибок из-за структур от грубого к мелкому.
Чтобы облегчить эти проблемы, предлагается новая сеть оценки потока сцены (DifFlow3D), основанная на модели вероятности диффузии, позволяющая сделать вывод о неопределенности. Процесс уточнения итеративного распространения предназначен для повышения надежности корреляции и устойчивости к сложным ситуациям (таким как динамические сцены, шумные входные данные, повторяющиеся шаблоны и т. д.). Чтобы подавить генеративное разнообразие, в качестве условий в модели диффузии используются три ключевые особенности, связанные с потоком.
Кроме того, в диффузии разработан модуль оценки неопределенности для оценки надежности оцененного потока сцены. DifFlow3D обеспечивает высочайшую производительность, сокращая EPE3D на 6,7% и 19,1% в наборах данных FlyingThings3D и KITTI 2015 соответственно. Примечательно, что этот метод обеспечивает беспрецедентную точность на уровне миллиметра для набора данных KITTI (0,0089 м для EPE3D). Кроме того, парадигма уточнения на основе диффузии может быть легко интегрирована в существующие сети потока сцен в виде модуля plug-and-play, повышая точность их оценки.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
