Центр обработки данных OneID: Подробное объяснение ID-Mapping!
01 | Введение в сопоставление идентификаторов
При содействии профилированию пользователей и контролю рисков самой большой проблемой, с которой приходится сталкиваться, является путаница в идентификационной информации пользователя:
- Переключайтесь между разными учетными записями на одном устройстве
- Один и тот же пользователь имеет разные учетные записи в разных каналах, таких как мини-программа WeChat и приложение.
- Один и тот же пользователь входит в систему с разных производителей устройств.
- …
ID-Mapping — это очень простое, но важное звено в анализе больших данных. С точки зрения непрофессионала, ID-Mapping заключается в идентификации нескольких фрагментов данных из разных источников как одного и того же объекта или субъекта с помощью различных технических средств, таких как одно и то же устройство (прямое). ), того же пользователя (косвенно), той же компании (косвенно) и т. д. можно наглядно понимать как процесс «головоломки» портретов пользователей.
Информация о поведении пользователя и данные об атрибутах разбросаны по множеству различных источников данных. Таким образом, с точки зрения единых данных это эквивалентно «слепому, касающемуся слона». пользователь, а ID-Mapping может разделить фрагменты. Все данные соединяются последовательно, устраняя островки данных, предоставляя пользователям полное представление информации и в то же время позволяя данным в одном поле превращаться в огромную ценность в другом поле.
ID-Mapping имеет множество применений, например:
- Межэкранное отслеживание и отслеживание между устройствами, конвертация данных пользователя телефон(App、апплет)、PC、Поведенческая информация на планшетах и других устройствах связана воедино.
- На уровне предотвращения и контроля рисков модели можно использовать для выявления возможных проблем с подделкой пользователей и устройств.
02 | Отраслевые решения для ID-картографии
1. Алибаба OneID
Типы идентификаторов пользователей в Alibaba включают: телефон, файлы cookie ПК, IMEI и IDFA, учетную запись Taobao, учетную запись Alipay, электронную почту и т. д. По каждой БЕ они знают только односторонние атрибуты этого клиента. При проведении маркетинговых мероприятий ориентируются только на номер мобильного телефона или адрес электронной почты, но не могут идентифицировать стоящее за этим физическое лицо или компанию. Чтобы преодолеть разрозненность данных и повысить ценность данных, Alibaba использует OneData в качестве своей основной методологии.
Система OneData включает в себя:
- OneModel: создание и управление информационными активами
- OneID: подключение объекта и профилирование
- OneService: логический сервис

Подход OneID заключается в том, чтобы разрушить разрозненность данных и обеспечить размещение данных посредством унифицированной идентификации объектов и подключения. Проще говоря, бизнес-объекты, такие как пользователи и устройства, будут сопоставлены с уникальными идентификаторами (UID) в соответствующих бизнес-данных, и данные в каждом измерении связаны через этот UID. Различные отделы, предприятия и продукты имеют разные определения и реализации UID для бизнес-субъектов, что делает невозможным прямую корреляцию данных и превращает их в «острова данных». На основе номера мобильного телефона, удостоверения личности, электронной почты, идентификатора устройства и другой информации в сочетании с бизнес-правилами, машинным обучением, графовым алгоритмом и другими алгоритмами выполняется сопоставление идентификаторов для сопоставления различных UID с единым идентификатором. Благодаря этому унифицированному идентификатору данные из различных «островков» данных могут быть связаны для достижения согласованности данных и обеспечения точности и полноты приложений данных, таких как бизнес-анализ и портреты пользователей.
2. Сопоставление идентификаторов NetEase
Линейки продуктов NetEase включают NetEase Cloud Music, NetEase Mailbox, NetEase News, NetEase Selections и т. д. Различные приложения имеют разные идентификаторы, например yanxuanid, oaid, musicid, телефон, электронная почта, idfa, imei и т. д.
Чтобы идентифицировать уникальный идентификатор, NetEase использует следующие идеи и решения: объединение пар отношений между различными учетными записями, различными моделями устройств и пользовательскими данными, такими как шаблоны использования устройств, с использованием правил и алгоритмов интеллектуального анализа данных (разделение связанного графа + обнаружение сообщества). чтобы определить, принадлежит ли учетная запись одному и тому же лицу.

В процессе ID-Mapping возникают следующие общие проблемы и соответствующие решения:
- Пользователь имеет информацию о нескольких устройствах. Решение: Определите соответствующие пороговые значения для корреляции. Сообщество обнаружило, что в настоящее время он используется в маркетинговых сценариях и еще не использовался в сценариях контроля рисков или действий пользователей, поскольку этот метод будет связывать вместе некоторые ненормальные учетные записи, и будет информация об устройстве, которая была зарегистрирована и использована только один раз. .
- Срок годности оборудования обычно составляет около 2 с половиной лет. Решение: установите коэффициент затухания, чтобы увеличить затухание для отдельных пользователей и нескольких устройств.
Примечание. Обычно сценарии, когда у одного человека есть несколько устройств, включают одолжение устройства друга, загрязнение данных устройства, считывание учетной записи и т. д.
3. ID-карта 58 городов
58 имеет богатые бизнес-сценарии, а ее продуктовые линейки включают 58 City, Ganji, Anjuke, China Talent Network, Zhuanzhuan, 58 Home и т. д. В этой ситуации с несколькими пользователями, несколькими направлениями бизнеса и множеством дочерних компаний типы пользовательских данных являются сложными. Данные для построения портретов поступают из таких источников данных, как журналы, базы данных резюме, базы данных сообщений, базы данных пользователей, базы данных торговцев и т. д. Базы данных сертификационной информации. Среди них только журналы включают журналы ПК/M/APP различных подпродуктов, таких как 58, Ganji и Anjuke. Как соединить множество источников данных вместе — это первая проблема, с которой приходится сталкиваться при построении портретов пользователей. Ниже представлена схема модели ID-Mapping, построенная 58.
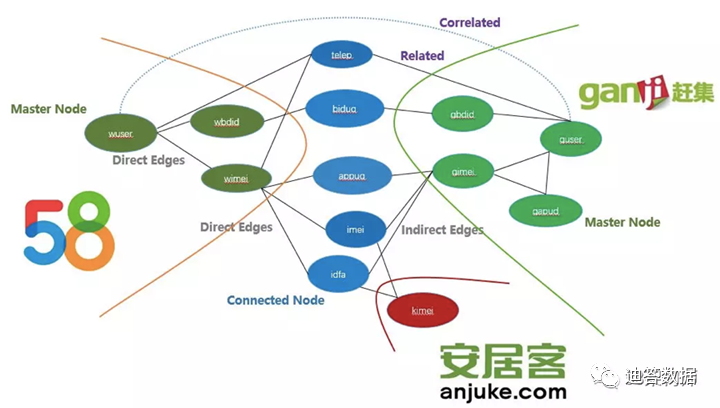
Как видно из рисунка, разные направления бизнеса имеют разные идентификаторы:
- 58 в этом же городе: wuser, wbdid, wimei
- 58 Идти на рынок: гусер, гбдид, гапуд, гимей
- Анджуке: Кимей
Среди них они могут быть связаны через телеп, бидуа, аппуа, imei и idfa, тем самым устанавливая отношения сопоставления ассоциаций между различными идентификаторами, что представляет собой процесс сопоставления идентификаторов.
4. ID-картирование Meituan
Meituan и Dianping объединились. Если один и тот же пользователь имеет разные идентификаторы в двух приложениях, как Meituan их однозначно идентифицирует? Давайте посмотрим на системы учета Мэйтуань и Дяньпин. Meituan использует метод входа в систему по номеру мобильного телефона, WeChat, Weibo и учетной записи Meituan, использует метод входа по номеру мобильного телефона, WeChat, QQ и Weibo; их пересечением является номер мобильного телефона, WeChat и Weibo; Наконец, для системы учетных записей зарегистрированных пользователей Meituan приняла номер мобильного телефона в качестве уникального идентификатора пользователя.
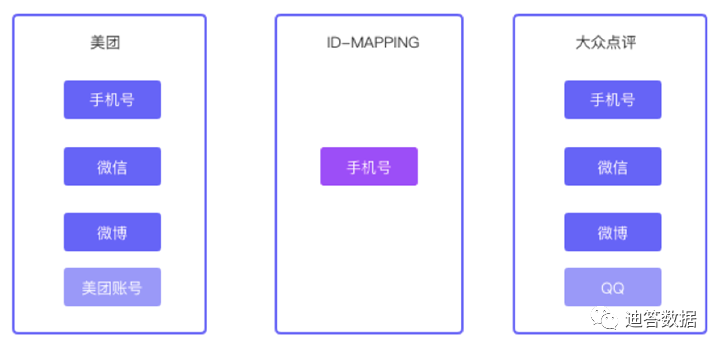
Как видно из приведенных выше случаев, существует три распространенных метода ID-мэппинга:
- Наиболее часто используемая система на основе учетных записей на предприятиях заключается в подключении идентификаторов на основе системы учетных записей. Когда пользователь регистрируется, ему присваивается идентификатор uid, который используется для строгой связи информации всех зарегистрированных пользователей.
- На основе устройства: незарегистрированных пользователей можно точно идентифицировать по идентификатору терминального устройства, включая идентификацию двух основных терминалов: Android/iOS. Различные идентификаторы собираются и передаются через SDK, а библиотека взаимосвязей идентификаторов и алгоритм калибровки используются в фоновом режиме для генерации/получения уникального идентификатора терминала в режиме реального времени и его выдачи.
- На основе аккаунта&оборудование:Объедините разные аккаунты、Различныйоборудование Отношения между моделями,И пользователи, такие как данные о шаблонах использования устройств.,Используйте правила и методы для майнинга алгоритма,Пары отношений выходного идентификатора со стабильными отношениями,И сгенерируйте UID в качестве идентификационного кода, который однозначно идентифицирует объект.
03 | план внедрения сопоставления идентификаторов
1. сопоставление идентификаторов: в соответствии с приоритетом учетной записи.
Сопоставление идентификаторов на основе приоритета учетной записи является самым простым решением. Номер мобильного телефона/uid/deviceid и т. д. в базе данных идентифицируются в соответствии с приоритетом как уникальный идентификатор пользователя для этих данных. Но в этом плане есть серьезные недостатки.
В реальных данных журнала, поскольку пользователи могут использовать различные устройства и иметь разные внешние входы или даже один и тот же пользователь имеет несколько устройств и использует несколько внешних входов, это приведет к тому, что для одного и того же человека количество и типы идентификаторов которые могут быть получены из журналов, данные, собранные в разные периоды времени, различны.
Например, пользователи могут использовать различные устройства и каналы:
- сотовый телефон, планшетный компьютер
- Андроидсотовый телефон、iosсотовый телефон
- Есть ПК, приложение и небольшие программы.
Возникает проблема: идентификация пользовательского устройства не может быть легко настроена с помощью правила выбора одного из них в качестве уникального идентификатора:
- cookieid: идентификатор сайта ПК в файлах cookie пользователя, который будет восстановлен при очистке компьютера.
- Unionid: уникальная аутентификация личности, предоставляемая WeChat.
- mac:сотовый физический адрес сетевой карты телефона, Доступно несколько ранних версий iOS, Winphone и Android.
- imei (серийный номер лицензии доступа к сети): его можно получить в системе Android, некоторых ранних версиях iOS и Winphone, а также его могут получить операторы.
- imsi(сотовый телефон Серийный номер SIM-карты): его можно получить в системе Android, некоторых ранних версиях iOS и Winphone, а также его могут получить операторы.
- androidid: идентификатор системы Android
- openuuid (серийный номер, сгенерированный самим приложением): он изменится при удалении и переустановке приложения.
- idfa (код отслеживания рекламы): сбрасывается пользователем
- deviceid (сбор журналов приложений и скрытые точки разработчик самостоятельно определяет логический идентификатор, который может быть взят из android, imei, openudid и т. д.): логический идентификатор
Это приводит к тому, что в некоторых сценах есть определенные данные, а в некоторых нет, поэтому нет возможности интегрировать данные. Чтобы отличить идентификаторы, принадлежащие одной и той же аудитории (устройству), от этих различных типов сложных идентификаторов, трудно добиться с помощью простой условной логики, такой как «где x=y».
2. id-маппинг: расчет с помощью графика
Используйте методы расчета графов, чтобы найти корреляцию между различными идентификаторами и тем самым определить, какие идентификаторы принадлежат одному и тому же человеку.
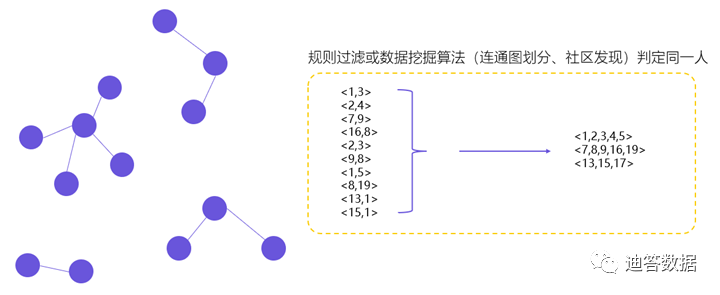
Основная идея графовых вычислений: выражать данные в виде «точек», а между точками можно устанавливать «ребра», имеющие определенное бизнес-значение. Затем мы можем найти различные типы связей данных из точек и ребер: такие как связность, планирование кратчайшего пути, а конечная цель id_mapping (открытие идентификаторов) — сформировать словарь сопоставления идентификаторов:
Общий процесс:
- Преобразование всех полей идентификатора пользователя в сегодняшние данные,и связь между полями флагов,точка появлениясобирать 、сторонасобирать
- предыдущий деньids->guidОтображение отношений,такжеточка появлениясобирать、сторонасобирать
- Объедините два вышеупомянутых типа сбора точек и сбора ребер вместе, чтобы создать график.
- Затем выполните алгоритм «максимально связанный подграф» на приведенном выше графике, чтобы получить результат связанного подграфа.
- Получите идентификаторы, принадлежащие к одной и той же группе, из карты результатов и сгенерируйте уникальный идентификатор.
- Сравните уникальный идентификатор, созданный на вышеуказанных этапах, с идентификатором предыдущего дня.ids->guidтаблица сопоставления(если человек уже существуетguid,тогда будет использоваться оригинальное руководство)
Конкретные решения по реализации могут быть реализованы с использованием графовых вычислений или графовых баз данных.
04 | Резюме
Основная ценность One ID — открыть острова данных и соединить системы, созданные изолированно в разное время, с помощью единого идентификатора. Функция One ID подобна построению моста. После соединения различных островов данных эти острова становятся одним. После того, как хранилища данных будут разбиты, мы сможем получить более полное и полное представление о наших пользователях, продуктах и продавцах, более точно оценить их ценность, провести дальнейшее обнаружение ценности и заложить прочную основу данных для усовершенствованных операций.
Основной технологией One ID является ID-Mapping. Ее принцип заключается в том, чтобы абстрагировать ключевые элементы каждой системы на «точки» и «ребра» для графовых вычислений. Один и тот же «объект» можно легко определить с помощью алгоритмов графовых вычислений, тем самым построив. Неориентированный связный граф генерирует словарь сопоставления идентификаторов. Этот словарь сопоставления идентификаторов является мостом к каждому острову данных. Через эти мосты мы можем соединить данные одного и того же «объекта» на разных островах.
Источник этой статьи: https://www.biaodianfu.com/id-mapping.html.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
