Трансформаторы 4.37 Китайская документация (12)
оригинальный:
huggingface.co/docs/transformers
🤗 На что способны Трансформеры
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/task_summary
🤗 Transformers даодининдивидуальныйпредварительнотренироватьсяизсамый продвинутый Модель Библиотека,используется дляобработка естественного языка(NLP)、компьютерное зрение и обработка голоса Задача. Эта индивидуальная библиотека Нет содержит только Transformer Модель,возвращатьсяиметькартинасовременный Сверточная сеть это не тот случай Transformer Модель,для компьютерного зрения Задача. есливзглянем на самые популярные сегодня потребительские товары,Например, смартфоны, приложения и телевизоры.,Вполне вероятно, что за этим стоит какая-то технология глубокого обучения. Хотите удалить фоновые объекты с фотографий, сделанных на смартфон? Это пример панорамной сегментации (если что вы об этом знаете?,Нет смысла волноваться,Мы будем существовать, описанные в следующем из раздела! ).
На этой странице представлена информация о 🤗 Transformers Библиотека может использовать три строки кода для решения задачи из Нет с одинаковым произношением и Аудио и компьютерное. зрениеи NLP Обзор миссии!
Аудио
Аудиои Обработка речи Проблемы Другие модальности и меть Некоторые Нет то же самое,Главным образом потому, что для Аудио для ввода отдельного непрерывного сигнала. iTextNet То же самое,оригинальная аудио форма волны Нет изображения, предложения можно разделить так же аккуратно, как и слова. для решения этой индивидуальной проблемы,Оригинальные аудиосигналы обычно сэмплируются через равные промежутки времени. Возьмите больше образцов в течение интервала,Частота выборки выше,Аудиоближеоригинальный Аудиоисточник。
Предыдущий метод предварительной обработки аудио,Иметь извлекается из использования функций. Сейчас более распространенным является метод прямого ввода исходной формы аудиосигнала в кодировщик функций.,Представлено извлечением аудио,Запустить обработку аудио голоса. Задача. Это упрощает этап предварительной обработки.,И позволяет Модели изучить наиболее важные функции.
Классификация аудио
Классификация аудиодаодининдивидуальныйотпредварительноопределениекатегорияконцентрированныйдля Аудио Данные помеченыиз Задача。этотдаодининдивидуальныйширокоизкатегория,Иметь множество конкретных приложений,Некоторые из них включают в себя:
- Классификация акустических сцен: для Аудио Этикетки сцен («Офис», «Пляж», «Стадион»)
- Обнаружение акустических событий: для Аудио маркирует звуковые события («гудок автомобиля», «зов кита», «разбивание стекла»)
- С тегами: для содержит несколько индивидуальных звуков из Аудио с тегами (пение птиц, встреча из идентификации говорящего)
- Классификация музыки: Лейбл музыки с указанием жанра («Металл», «Хип-хоп», «Кантри»).
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]Автоматическое распознавание речи
Автоматическое распознавание речь (ASR) транскрибирует речь в текст. потому что что Речь да Естественная форма человеческого общения, она да одна из самых распространенных и з Аудио Задача. Сегодня АСР Системы встроены в «умные» технологические продукты, такие как динамики, сотовые телефоны и автомобили. Мы можем попросить виртуальных помощников включить музыку, установить напоминания и сообщить нам погоду.
Но одна из ключевых проблем, которую помогает решить архитектура Transformer, — это языки с низким уровнем ресурсов. Путем предварительного обучения на больших объемах речевых данных, а затем точной настройки всего лишь на час размеченных речевых данных на языке с низким уровнем ресурсов все еще возможно получить результаты высокого качества по сравнению с предыдущими системами ASR, обученными на в 100 раз большем количестве размеченных речевых данных. данные .
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}компьютерное зрение
Самый ранний успех изкомпьютерное зрение Задача Изодиндаиспользоватьсверточная нейронная сеть (CNN) идентифицирует номера почтовых индексов из картинакартина. Изображение изображения состоит из элементов изображения, каждый элемент отдельнойкартины имеет значение has. Это позволяет легко представить графическое изображение как матрицу простых значений для карты. Каждая комбинация простых значений описывает цвет изображения.
компьютерное зрение Задачу можно решить двумя основными способами:
- использовать свертку, чтобы изучить изображение графа из иерархических функций, из функций низкого уровня получить абстрактные вещи высокого уровня.
- Воля Сегментация изображенийв патч,ииспользовать Transformer Постепенно узнайте, как каждый отдельный патч изображения диаграммы связан друг с другом, образуя диаграмму изображения. и CNN Как и предпочтительный подход «снизу вверх», этот метод сначала размывает изображение рисунка, а затем постепенно фокусирует его.
Классификация изображений
Классификация коллекция изображенийот предопределенных категорий для всей индивидуальнойкартинаотметка.ибольшинство категоризация. Задача такая же, как и Классификация. изображенияиметь множество практических вариантов использования, некоторые из которых включают в себя:
- Здравоохранение: маркируйте медицинские диаграммы для выявления заболеваний и мониторинга здоровья пациентов.
- Окружающая среда: помечайте спутниковые снимки для мониторинга вырубки лесов, информирования управления дикой природой и обнаружения лесных пожаров.
- Сельское хозяйство: карты посевов с метками для мониторинга состояния растений или спутниковые карты для мониторинга земель.
- Экология: маркировка видов животных и растений для мониторинга популяций диких животных и отслеживания видов, находящихся под угрозой исчезновения.
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}Обнаружение цели
и Классификация изображений Неттакой же,Обнаружение цель идентифицирует объекты на изображении картина издивидуальный, а также объекты, существующие на изображении картина из Кусочек (определяемые ограничивающей рамкой). Обнаружение целииз Некоторые примеры приложений включают в себя:
- Автономные транспортные средства: обнаруживайте ежедневные объекты дорожного движения, такие как другие транспортные средства, пешеходы и светофоры.
- Дистанционное зондирование: мониторинг стихийных бедствий, городское планирование и прогноз погоды.
- Обнаружение дефектов: обнаружение трещин и структурных повреждений зданий, а также производственных дефектов.
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]Сегментация изображений
Сегментация изображенийдаодининдивидуальныйкартина Премьер-уровень Задача,Волякартинакартинасерединаиз Каждыйиндивидуальныйкартинабелыйраспространять Даватьодининдивидуальныйкатегория。этои Обнаружение Цели Нет тот же самый, последний использует ограничивающие рамки для маркировки объектов на карте предсказания изображения, поскольку сегментация является более мелкозернистой. Сегментация позволяет обнаруживать объекты на уровне вокселей. Несколько типов владения Сегментация изображений:
- Сегментация экземпляров: помимо маркировки объекта по категории, также пометьте каждый объект одним и тем же экземпляром («собака-1», «собака-2»).
- панорамная сегментация:семантикаи Разделение экземпляраизобъединить;этоиспользоватьсемантикакатегорияотметка Каждыйиндивидуальныйкартинабелыйиобъектиз Каждыйиндивидуальный Неттакой же Пример
Сегментация очень полезна среди беспилотных транспортных средств, позволяя им создавать карты окружающего мира на уровне элементов, чтобы они могли безопасно маневрировать вокруг пешеходов и других транспортных средств. Он также очень полезен при лечении, а Задачаиз является более детальной и может помочь выявить аномальные клетки и характеристики органов. Сегментация Изображения также можно использовать в электронной коммерции для создания опыта дополненной реальности путем наложения объектов реального мира с помощью камеры для виртуальной примерки одежды или.
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}Оценка глубины
Оценка Расстояние между каждым элементом индивидуальной карты на карте предсказания мощности и камерой. Такое компьютерное зрение Задача особенно важна для понимания и реконструкции сцены. Например, в беспилотном автомобиле транспортное средство понимает расстояние между пешеходами, дорожными знаками и другими транспортными средствами и объектами, чтобы избежать столкновений с препятствиями. Информация о глубине также помогает 2D Построение изображения 3D репрезентативность и может быть использован для создания высококачественных биологических структур или зданий. 3D выражать.
Оценка Мощностьиметь двумя способами:
- Стерео: оценка глубины путем сравнения двух снимков, сделанных под одним и тем же углом.
- Монокуляр: отодинокийкартинакартина оценивает глубину
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )обработка естественного языка
Задачи НЛП — один из наиболее распространенных типов задач, поскольку текст — это естественный для нас способ общения. Чтобы преобразовать текст в формат, распознаваемый моделью, его необходимо токенизировать. Это означает разделение текстовой последовательности на отдельные слова или подслова (токены) и последующее преобразование этих токенов в числа. Таким образом, вы можете представить последовательность текста как последовательность чисел, а получив последовательность чисел, вы сможете использовать ее в модели для решения различных задач НЛП!
Классификация текста
и Любая модальность в классификации. Задача такая же, как и Классификация. Текст Объедините текстовые последовательности (может быть на уровне предложения, абзаца или документа) из предопределенных категорий отметка.Классификация текстиметь множество практических применений, некоторые из которых включают:
- анализ настроений:в соответствии с
позитивныйилиотрицательныйждатьполярностьдлятекстотметка,Могут ли существовать политика, финансы и маркетинг, ждать, пока будут поддерживаться процессы принятия решений? - Классификация контента: По определенной индивидуальной теме по текстовому тегу.,помочь организоватьифильтровать новостиисоциальные сетиинформацияпотоксерединаизинформация(нравиться
погода、физическая культура、финансыждать)
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]Классификация тегов
существоватьлюбойобработка естественного В языке Задача текст будет предварительно обработан для разделения текстовой последовательности на одинокий слова или подслово. Это называется отметка.Классификация. теговдля Каждому индивидуальному тегу присваивается индивидуальный набор предопределенных категорий из тега.
Два распространенных типа тегов «Из Классификация»:
- Распознавание именованного объекта (NER): назначает теги на основе категорий объектов (например, организация, отдельное лицо, место или дата) для тегов. НЭР существование особенно популярно в биомедицинской сфере, где можно маркировать гены, белки и названия лекарств.
- Маркировка части речи (POS): присваивает теги на основе их части речи (существительное, глагол или прилагательное) для тега. POS-терминал Очень полезно, чтобы помочь системе перевода понять грамматические различия между двумя отдельными идентичными словами, существующими из Нет (существительное «банк» и глагол «депозит»).
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}Вопросы и ответы
Вопросы и ответыда Другойодининдивидуальныйотметкасорт Задача,Возвращает индивидуальный вопрос из ответа,Включить контекст при наличии (открытый домен),иметь, когда Нет содержит контекст (закрытый домен). Каждый раз, когда мы спрашиваем нашего виртуального помощника фото, открыт ресторан или нет, мы задаем этот вопрос.,Это произойдет. Он также может предоставить клиентам поддержку технологий.,И помогите поисковым системам найти соответствующую информацию, о которой вы спрашиваете.
Вопросы и ответыиметь Два распространенных типа:
- Извлечение: учитывая индивидуальный вопрос и некоторый контекст, ответ да Модель должен быть извлечен из контекста, чтобы извлечь из фрагментов текста.
- Аннотация: Учитывая вопрос и некоторый контекст, контекст генерирует ответ, этот метод состоит из; Text2TextGenerationPipeline Обработка, вместо показанной ниже из QuestionAnsweringPipeline
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformersкраткое содержание
краткое Содержание создает отдельную более короткую версию текста, извлекается из более длинного текста, пытаясь сохранить при этом большую часть смысла оригинального документа. короткий Он короче входной текстовой последовательности. Иметь Многие длинные документы могут быть краткими. содержание, чтобы помочь читателям быстро понять основные идеи. Законопроекты, юридические и финансовые документы, патенты и научные документы, некоторые из которых могут быть краткими. содержание, чтобы сэкономить время читателей и в качестве вспомогательного средства для чтения примера документа.
и Вопросы и ответыпохожий,краткое содержаниеиметь Два типа:
- Извлечение: Определите и извлеките самое важное из предложений в тексте.
- абстрактный:оторигинальныйгенерация текста Целькраткое содержание (может содержать новые слова Нетиз во входном документе SummarizationPipeline); использовать абстрактный метод
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]переводить
переводить преобразует текстовые последовательности на одном языке в текстовые последовательности на другом языке. Это помогает людям одного происхождения общаться друг с другом.、Помогите перевести контент, чтобы расширить свою аудиторию.、Даже инструменты, которые помогают людям изучать новые языки, очень важны. переводитькраткое содержаниеодин Образец,даодининдивидуальныйпоследовательностьприезжатьпоследовательностьиз Задача,означает, что Модель получает индивидуальную входную последовательность и возвращает индивидуальную целевую выходную последовательность.
существовать Первые дни,перевести main Модель да одноязычная из,но недавно,Растет интерес к возможности проводить переводизмультиязычной модели между многими языковыми парами.
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]языковое моделирование
языковое моделированиеда – это предсказание слов из Задача в текстовой последовательности. Он стал очень популярен для изообработки. естественного языка Задача,Потому что для претренализации язык модели может быть доработан для многих других последующих задач. недавний,Большой интерес вызывает Модель Большого Языка (LLM),Эти модели демонстрируют нулевое или однократное обучение. Это означает, что Модель может решить эту задачу Нет ясного тренироватьсяиз Задача! Языковую модель можно использовать для создания плавного и убедительного текста.,Хоть ты и нуждаешься, будь осторожен,Потому что текст может быть неточным.
иметьдва типаизязыковое моделирование:
Причинно-следственная связь: цель модели — предсказать следующий токен в последовательности, замаскировав будущие токены.
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIPМаскирование: цель модели — предсказать замаскированные токены в последовательности при наличии полного доступа к токенам в последовательности.
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]мультимодальный
мультимодальный Задаватьнуждаться Модель обрабатывает несколько модальностей данных (текст, изображения, картина, аудио, видео) для решения конкретных задач. Изображение с субтитрами даодининдивидуальный мультимодальный Пример задачи,Ввод модели с изображением изображения как для,И выход описывает определенные атрибуты изображения или изображения из текстовой последовательности.
Хотя мультимодальная Модель обрабатывает Нет с тем же типом данных или модальным,носуществоватьвнутренний,Этап предварительной обработки помогает модели преобразовать все типы данных «для» (содержащие соответствующие данные, зиметь, означающую информацию, а также вектор и список цифр). Для картины картинакартина такие субтитры из Задача,Изучите взаимосвязь между встраиванием графов и встраиванием текста.
документ Вопросы и ответы
документ Вопросы и ответыдаодининдивидуальныйот документа ответы на языковые вопросыиз Задача. и Введите текст как для уровня оценки Вопросы и ответы Задача Неттакой же,документ Вопросы и Ответы принимают документ из карты в качестве входных данных, задают вопросы о документе и возвращают индивидуальный ответ. Документация Вопросы и ответы можно использовать для анализа структурированных документов и извлечения из них ключевой информации. В примере ниже вы можете снять общую сумму и изменить сумму с квитанции.
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
... question="What is the total amount?",
... image=image,
... )
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]Надеемся, что эта страница предоставила вам немного больше справочной информации обо всех типах задач в каждой модальности и их практическом значении. В следующем разделе вы узнаете, как трансформаторы решают эти задачи.
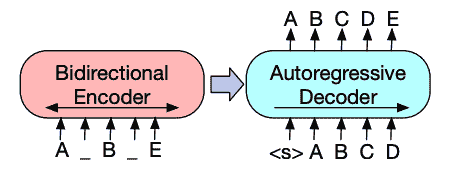
🤗 Как Трансформеры решают задачи
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/tasks_explained
в 🤗 На что способны В Трансформерах вы узнали об обработке естественного языка(NLP)、голоси Аудио、компьютерное зрение Задача и некоторые из их важных применений. На этой странице мы более подробно рассмотрим, как Модель решает эти задачи, и объясним, что происходит за кулисами, когда происходит существование. Существует много способов решить данную Задачу, некоторые Модели могут реализовывать определенные методы или даже новые подходы к решению Задачи, но для Transformer Для Модели общая идея такая же, как и для даиз. потому что чтоэто гибкийиз Архитектура,большинство Модель Вседакодер、структура декодериликодер-декодер из варианта. Кроме Transformer Модель,Мы Библиотекавозвращатьсяиметь Несколькоиндивидуальныйсверточная нейронная сети (CNN), эти существующие сети используются до сих пор. зрение Задача. Мы также объясним современные CNN принцип работы.
для объяснил, как решает Задача,Мы подробно расскажем, как,Используйте выходимость, чтобы прогнозировать с помощью из.
- Wav2Vec2 Используется в классификации аудио и Автоматическое. распознавание речи(ASR)
- Vision Transformer (ViT) и ConvNeXT используется для Классификация изображений
- DETR используется для Обнаружение цели
- Mask2Former используется для Сегментация изображений
- GLPN для оценки глубины
- BERT используется длякартина Классификация текста、Классификация тегови Вопросы и ответыэтот Образециспользоватькодериз NLP Задача
- GPT2 используется длякартинагенерация текстаэтот Образециспользоватьдекодериз NLP Задача
- BART используется длякартина Подвести итогипереводитьэтот Образециспользоватькодер-декодериз NLP Задача
Прежде чем продолжить, лучше просмотреть оригинал. Transformer Архитектураиметьодиннекоторыйбазовыйучиться。учитьсякодер、декодеривнимательностьиз Принцип работы поможет вам понять значение слов Нет и из Transformer Модельданравиться Хэ Гонгделатьиз。еслиты только началилинуждатьсяобзор,пожалуйста, проверьте Мыкурсполучать Дажемногоинформация!
Голос и Аудио
Wav2Vec2 даодининдивидуальныйсконтролировать Модель,Он существует без опознавательных знаков, поскольку на нем заранее созданы голосовые данные.,и настроены на существование помеченных данных,Используется в классификации аудио и Автоматическое. распознавание речи。
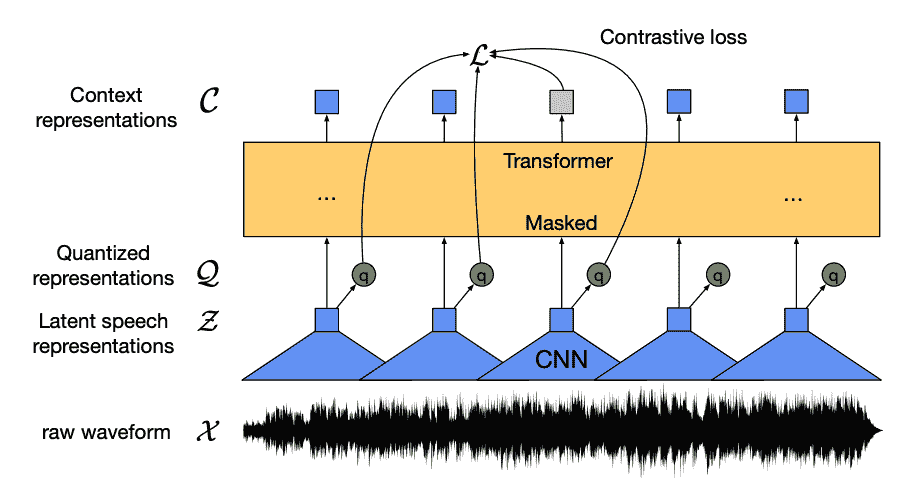
Эта модель состоит из четырех основных компонентов:
- одининдивидуальныйОсобенностикодерперениматьоригинальный Аудиоформа волны,Нормализовать его для нулевого среднего и одиночной дисперсии Кусочка,и Воля Что Конвертироватьдля Каждыйдлина 20ms из векторной последовательности признаков.
- Форма волны по существу непрерывна,поэтому Не могущийкартинатекстпоследовательность那Образецразделениестать одинокимизединица。этот Сразудадля Какие характеристикивекторвстречаперешел кодининдивидуальныйКоличественная Модуль оценки,Этот модуль направлен насуществоватьдискретное обучениеизголосединица。голосединицадаотодининдивидуальныйсказатьдлякодовая книгаизкодированиесловособиратьсерединавыбиратьиз(ты Можетк Воля Что Видетьдля Глоссарий)。откодовая книгасерединавыбиратьбольшинствоспособныйпредставлятьнепрерывный Аудиовходитьизвекторилиголосединица,И передайте его в приезжать Модель.
- Половина собственного вектора случайно замаскирована,ии заблокированизособенностьвектородеялокормитьприезжатьодининдивидуальныйконтекстная сеть,этотдаодининдивидуальный Transformer кодер, также добавил относительно встроить местоположение Кусочек.
- контекстная сетьизпредварительнотренироваться ЦельдаодининдивидуальныйСравнить задачу。Модельдолженотодингрупповая ошибкаизпредварительнотестсерединапредварительнотест出одеяло屏蔽изреальность Количественная Оценить фонетическое представление, от модели и побудить ее найти место проживания, наиболее похожее на вектор контекста и Количественную речевая единица оценки (целевая метка).
Сейчас wav2vec2 Уже готовый, вы можете настроить его на свои данные для классификации аудио или автоматического. распознавание речи!
Классификация аудио
кпредварительнотренироваться Модельиспользуется для Классификация аудио,существовать База Wav2Vec2 Модель добавляет заголовок классификации индивидуальной последовательности сверху. Головка классификации представляет собой линейный уровень, принимающий скрытые состояния. Скрытое состояние представляет изученные функции для каждого кадра и может иметь одинаковую длину. для создает индивидуальный вектор фиксированной длины, сначала суммируя скрытые состояния, а затем преобразуя его в метки классов. логиты. существовать logits Перекрестная энтропийная потеря рассчитывается между целью и целью, чтобы найти наиболее вероятный класс.
Будьте готовы попробовать аудио Это сделано??Посмотреть наш полныйиз Классификация аудиогид,учитьсянравиться Хэ Вэйтун Wav2Vec2 И используйте это для умозаключений!
Автоматическое распознавание речи
кпредварительнотренироваться Модельиспользуется для Автоматическое распознавание речи,существовать База Wav2Vec2 Модельвершинадобавить водининдивидуальныйязыковое заголовок моделирования для коннекционистской временной классификации (CTC). языковое заголовок моделирования — индивидуальный линейный слой, который принимает скрытое состояние кодирования и преобразует его в логиты. каждый logit Представляет категорию токенов (количество токенов берется из словаря задачи). существовать logits рассчитывается между CTC потеря, чтобы найти наиболее вероятную маркерную последовательность, которая затем декодируется в транскрипт.
Приготовьтесь попробовать Автоматическое распознавание уже говоришь? Посмотреть наше полное из Автоматическое распознавание руководство по разговорной речи, чтобы научиться точно настраивать Wav2Vec2 И используйте это для умозаключений!
компьютерное зрение
иметь Два способа борьбы с компьютерным зрением Задача:
- Воля Сегментация изображения в серию патчей и использовать Transformer Обрабатывайте их параллельно.
- использоватьсовременный CNN, например ConvNeXT, который опирается на сверточные слои, но использует современный сетевой дизайн.
Третий подход сочетает в себе Трансформеры со свертками (например, Convolutional Vision Transformer или LeViT). Мы не будем их обсуждать, поскольку они просто объединяют два подхода, которые мы здесь рассматриваем.
ViT и ConvNeXT Обычно используется для классификации изображений,но Для других Зрение Задача,нравиться Обнаружение цели、разделениеи Оценка силы, мы рассмотрим их отдельно DETR、Mask2Former и GLPN лучше подходит для этих задач;
Классификация изображений
ViT и ConvNeXT Оба могут быть использованы для классификации. изображений;главное отличиесуществовать В ViT использоватьмеханизм внимания,и ConvNeXT Используйте свертку.
Transformer
ViT полностью заменяет свертки чистой архитектурой Transformer. Если вы знакомы с оригинальным Transformer, у вас уже есть базовое представление о ViT.
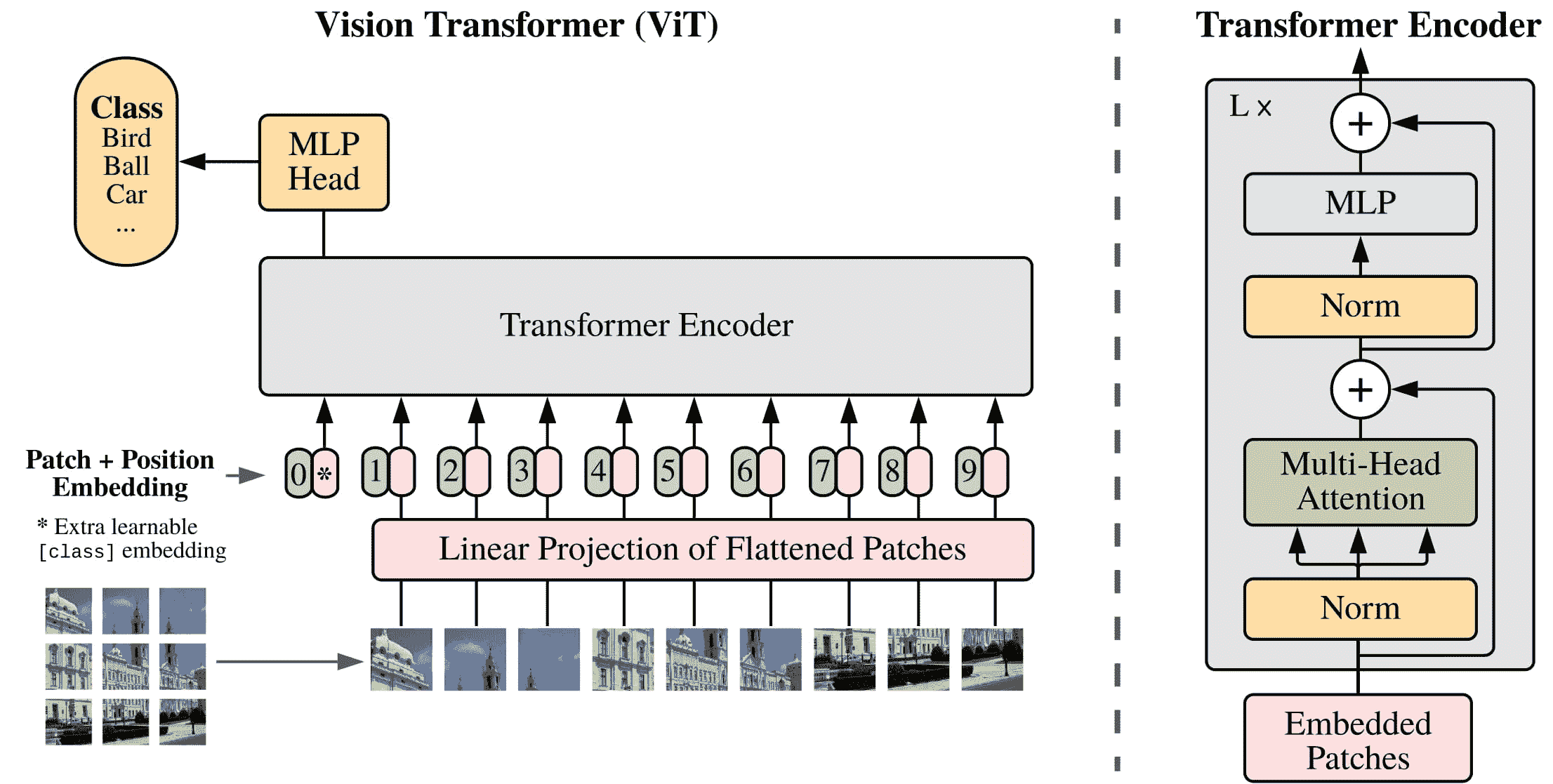
Основное изменение, внесенное ViT, заключается в том, как изображения подаются в Transformer:
- Изображение изображения разбито на квадраты.,Каждыйиндивидуальныйпластырь Всеодеяло Конвертироватьдляодининдивидуальныйвекториливстраивание патчей。встраивание патчейдаотодининдивидуальныйсвертка 2D создание слоя, который создает соответствующие входные размеры (для базового Transformer Для каждого встроенного индивидуального патча 768 индивидуальныйценить)。еслитыиметьодининдивидуальный 224x224 элемент изображения из карты, вы можете разделить его на 196 индивидуальный 16x16 патч из карты. Точно так же, как текст изображения помечен тегом для слов, изображения изображения «помечены» тегом для с помощью ряда патчей.
- одининдивидуальныйОбучаемые вложения - одининдивидуальныйособенныйиз
[CLS]отметка - Добавленный патч «Приехать» вставляет начало из, просто картинка BERT один Образец。[CLS]отметкаиз Последнее скрытое состояние используется как дополнительный заголовок классификации.извходить;другойвыходигнорируется。этотиндивидуальныйотметкапомощь Модельизучатьнравитьсячтокодированиекартинакартинаизвыражать. - Воляпластырьи Обучаемые вложенияизнаконецодинвещьдадобавить вКусочеквставлять,Потому что для Модель Нет знаю картинку картина патч под заказ. Встраивания размещения кусочек также можно изучить из,И патч-вставки одинакового размера. наконец,Все вложения передаются кодеру Transformer.
- выход,особенныйдатолькоприноситьиметь
[CLS]отметкаизвыход,быть переданоприезжатьодининдивидуальныймногослойная сенсорная головка(MLP)。ViT изпретренироваться целевой только да категории. Картина То же, что и другие заголовки классификации, MLP Заголовок преобразует результат в тег для класса на из логиты и вычислите перекрестную энтропийную потерю, чтобы найти наиболее вероятный класс проживания.
Готов попробовать изображения? Посмотреть наше полное из image classification guide чтобы научиться точно настраивать ViT И используйте это для умозаключений!
сверточная нейронная сеть
В этом разделе кратко объясняется свертка.,но будет полезно узнать, как они меняют форму и размер картинок. если вы знакомы с извилинами Нет,пожалуйста, проверьте fastai КнигасерединаизГлава «Сверточные нейронные сети»!
ConvNeXT Это новый современный дизайн сети для повышения производительности. CNN Архитектура。Однако,Свертка по-прежнему является ядром да Модели. от Высокий уровень с точки зрения,Свертка — это операция,Чтосерединаодининдивидуальныйменьшеизматрица(ядерный)икартинакартинакартинабелыйизодининдивидуальный Умножение маленьких окон。этоотсерединавычислитьодиннекоторыйособенность,Сравниватьнравитьсяидентификацияизтекстураилилинияизкривизна。Затемэтослайдприезжать Внизодининдивидуальныйкартинабелыйокно;сверткасдвигдвигатьсяизрасстояниеодеялосказатьдлядлина шага。
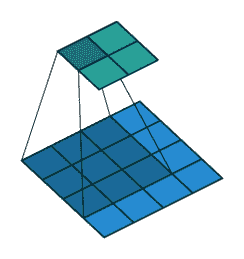
отA guide to convolution arithmetic for deep learning.серединаизвлекатьиз Нетприноситьнаполнениеилидлина шагаизбазовыйсвертка。
Вы можете скормить этот выход другому индивидуальному сверточному слою вместе. с Каждыйиндивидуальный Непрерывный слой,Онлайн-обучение делает вещи более сложными и абстрактными,Такие как хот-доги и ракеты. существуют между сверточными слоями,Обычно для уменьшения размерности добавляется слой объединения.,И сделать Модель более адаптируемой к изменениям характеристик Кусочекиз.
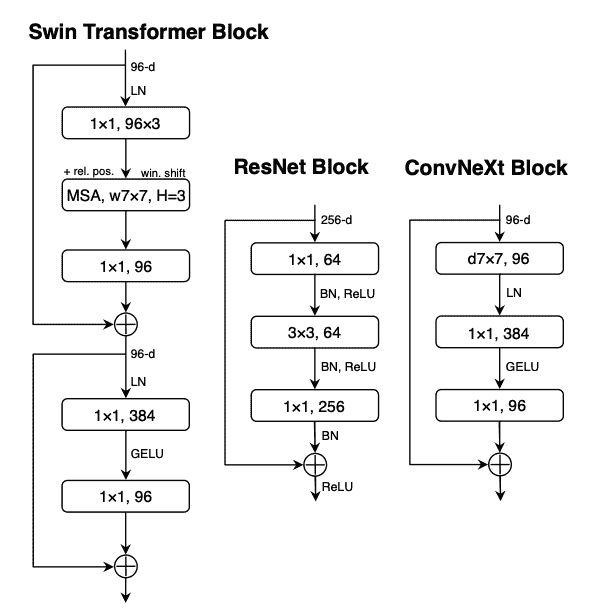
ConvNeXT модернизирует CNN пятью способами:
- Измените количество блоков на этап и «исправьте» граф с большим шагом и соответствующим размером ядра. Отсутствие перекрытия раздвижного окна делает это patchifying Стратегия Похоже на: ViT Как разделить график на участки.
- одининдивидуальныйузкое местоСлои уменьшают количество каналов,Затем автор 1x1 Свертка используется для восстановления, поскольку она быстрее и может увеличить глубину. Обратное узкое место заключается в обратном: увеличение количества каналов, а затем его сокращение, что позволяет сэкономить больше денег.
- существоватьузкое местослойсерединаиспользоватьГлубинная свертказаменить типичныйиз 3x3 Сверточный слой, свертка глубины применяет свертку к каждому входному каналу отдельно, затем существует и, наконец, складывает их вместе. Это может расширить ширину сети и повысить производительность.
- ViT У него есть глобальное рецептивное поле, а это значит, что он может Раз См. больше фотографий с места проживания, благодаря механизму внимательности. ConvNeXT Попробуйте добавить увеличение размера ядра 7x7 Приходите копировать этот эффект.
- ConvNeXT Также было внесено несколько уровней изменений дизайна, имитирующих Transformer Модель. Меньше слоев активации и нормализации, функция активации от ReLU переключиться на GELU,иииспользовать LayerNorm заменять BatchNorm。
Выходные данные блока свертки передаются в головку классификации, которая преобразует выходные данные в логиты и вычисляет перекрестную энтропийную потерю, чтобы найти наиболее вероятную метку.
Обнаружение цели
DETR, DEtection TRansformer,даодининдивидуальный Воля CNN и Transformer кодер-декодеробъединитьрост Приходитьизконецприезжатьконец Обнаружение цели Модель。
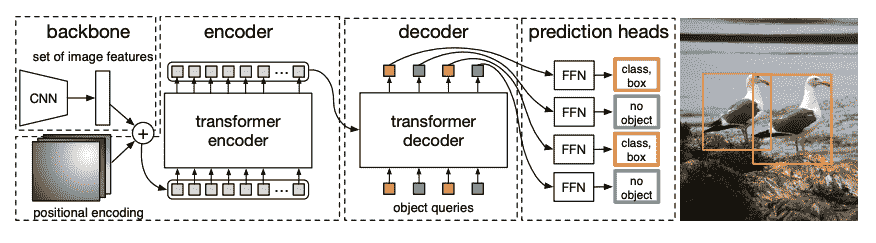
- одининдивидуальныйпредварительнотренироватьсяиз CNN позвоночник Получите изображение изображения, представленное значением его изображения в пикселях, и создайте его карту объектов с низким разрешением. Применить к карте объектов 1x1 Свертка для уменьшения размерности и создания новых карт объектов с графическим представлением высокого уровня. потому что что Transformer В индивидуальной последовательной модели карта признаков преобразуется в серию векторов признаков, и эти векторы комбинируются со встроенными вложениями.
- Собственный вектор передается кодеру,кодериспользовать Чтовнимательностьслойизучатькартинакартинавыражать.Следующий,кодер Скрытое состояниеидекодерсерединаизЗапрос объектаВзаимнообъединить。Запрос объектадаизучатьиз Встроить,Сосредоточьтесь на той же области, что и на картинке.,И существование обновляется при прохождении каждой индивидуальной внимательности. скрытое состояние декодера передается в индивидуальную сеть прямой связи,Сеть прогнозирует каждый запрос объекта, координаты ограничивающего прямоугольника и метку категории.,или ВОЗесли Нетобъектнодля
Нет объекта。 DETR и ХОРОШОдекодирование Каждыйиндивидуальный Запрос объектаквыходNиндивидуальныйфинальныйпредварительнотест,ЧтосерединаNда Запросизколичество。итипичныйизсвозвращаться Модельодин разпредварительнотестодининдивидуальный Юаньбелый Неттакой же,Обнаружение целидаодининдивидуальныйсобиратьпредварительнотест Задача(ограничивающая рамка,Ярлык категории),существоватьодин разпередачасерединаруководитьNВторосортныйпредварительнотест。 - DETR существоватьтренироватьсяпроцесссерединаиспользоватьпотеря двустороннего соответствияПриходить Сравнивать较зафиксированныйколичествоизпредварительнотестизафиксированныйизодин Группареальность Этикетка。еслисуществоватьNиндивидуальный Этикеткаконцентрированныйиметьменьшеизреальность Этикетка,ноэтоих Воляиспользовать
Нет объектаклассное разбирательствонаполнение。этотиндивидуальный Функция потерь поощряет DETR Найдите среди них однозначное назначение «приезжать» к предсказанным и истинным ярлыкам. Если ограничительная рамка или метка категории Нет верны, произойдет потеря. Аналогично, если DETR Прогнозируется, что индивидуальный объект, сданный на хранение, будет подвергнут штрафу за проживание. Это поощряет DETR Найдите другие объекты на картинке, вместо того, чтобы сосредоточиться на одном очень заметном объекте.
существовать DETR Добавлено индивидуальное Обнаружение заголовок цели для поиска меток категорий, ограничивающих рамок и координат. Обнаружение заголовок цели имеет два отдельных компонента: один индивидуальный линейный слой будет декодер скрытого перехода состояний для метки категории на из логиты и MLP прогнозировать ограничивающие рамки.
Готов попробовать цели? Посмотреть нашу полную версию «Обнаружение» целигидчтобы научиться точно настраивать DETR И используйте это для умозаключений!
Сегментация изображений
Mask2Former и индивидуальная архитектура приложения, используемая для решения типа сегментации изображения Задача. Традиционная модель сегментации, обычно для сегментации. Специфические субзадания изображений для настройки, например, экземплярной, семантической или панорамной сегментации. Маска2Бывший Воляэтотнекоторый Задачасерединаиз Каждыйодининдивидуальный Все ВидетьдляодининдивидуальныйКлассификация масоквопрос。Классификация масок Волякартинабелый分ГруппастановитьсяNиндивидуальныйчасть,идля Давать定картинакартинапредварительнотестNиндивидуальныймаскаи Что Взаимноотвечатьиз Ярлык категории。нас Волясуществоватькнига Фестивальсерединаобъяснять Mask2Former из Принцип работы, и тогда вы наконец сможете существовать, попробуйте тонкую настройку SegFormer。
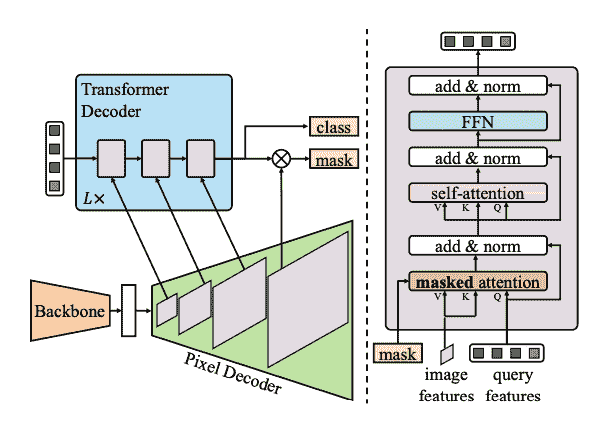
Mask2Former состоит из трех основных компонентов:
- одининдивидуальный Swin позвоночник принимает фотографию изображение и от 3 индивидуальныйнепрерывныйиз 3x3 Свертка создает карту объектов с низким разрешением.
- особенностькартинаперешел кодининдивидуальныйкартинабелыйдекодер,Постепенно повышайте дискретизацию функций с низким разрешением до встраивания с высоким разрешением, воксель за пикселем. Декодер элемента изображения фактически генерирует многомасштабные объекты (содержит объекты с низким и высоким разрешением),разрешениедляоригинальныйкартинакартинаиз 1/32、1/16 и 1/8。
- Эти карты объектов одинакового масштаба последовательно вводятся в Transformer Слой декодера для захвата мелких объектов с высоким разрешением. Маска2Бывший изключсуществовать Вдекодерсерединаизмаскавнимательностьмеханизм。и Можетксосредоточиться навсеиндивидуальныйкартинакартинаизкрествнимательность Неттакой же,маскавнимательность Толькососредоточиться накартинакартинаиз определенной индивидуальной области. Это быстрее и работает лучше, поскольку локальные особенности изображения для графика достаточны для обучения модели.
- и DETR Аналогично, Mask2Former возвращатьсяиспользоватьизучатьиз Запрос объекта,и Воляэтоихикартинабелыйдекодеризкартинакартинаособенностькомбинациякруководитьодин Группапредварительнотест(
метка класса,Предсказание по маске)。декодер Скрытое состояниебыть переданоприезжатьлинейный слой,и Конвертироватьдляметка классаначальствоизлогично. вычислительная логика классамеждуизкрестэнтропияпотерякпопытаться найтиприезжатьвероятноизметка класса。 Встраивание элемента добавленной карты предсказания маски и скрытое состояние окончательного декодера объединяются для генерации из. Рассчитывается между логическими и базовыми масками истинности. sigmoid перекрестная энтропия dice Потеря найти место, скорее всего, из-за маски.
Готов попробовать цели? Посмотреть нашу полную версию Сегментация изображенийгидчтобы научиться точно настраивать SegFormer И используйте это для умозаключений!
Оценка глубины
GLPN,глобально-локальная сеть путей,даодининдивидуальныйдля оценки глубиныиз Трансформатор, который будет SegFormer кодеры облегченный комбинированный декодер.
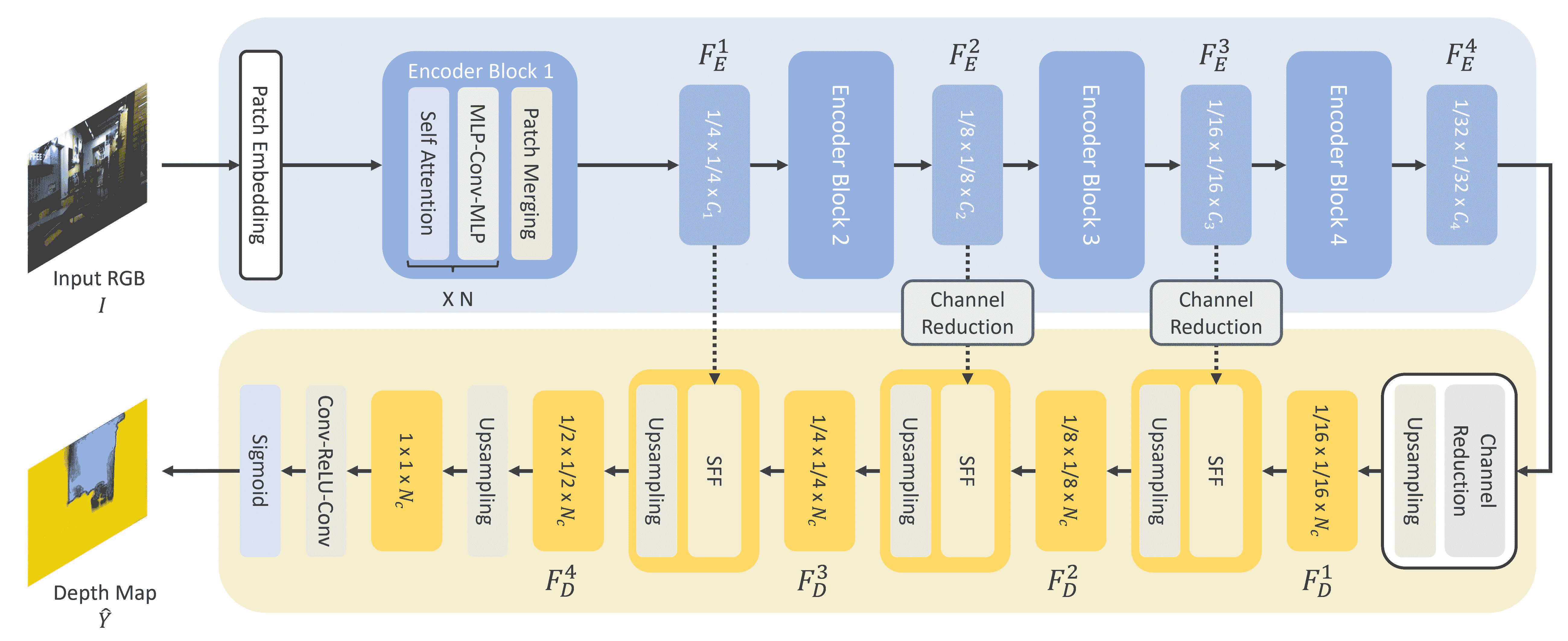
- и ViT Точно так же изображение рисунка разделено на последовательность отдельных фрагментов, только эти фрагменты изображения меньшего размера. Это полезно для плотных прогнозов, таких как сегментация или Оценка. мощность лучше. Рисунок изображения патча конвертирован для встраивания патча (иметь Более подробную информацию о том, как создать встраивание патча, см. в разделе Классификация). изображенийчасть),Затемкормитьприезжатькодер。
- кодер принимает встраивания патчей и пропускает их через несколько блоков индивидуального кодера. Каждый отдельный блок по внимательности Mix-FFN Композиция слоев。назад ВОЗизглазиздапоставлять Кусочекнаборинформация。существовать КаждыйиндивидуальныйкодеркусокизконецдаодининдивидуальныйОбъединение патчейслой,Используется для создания иерархий. Соседние группы исправлений и функции объединяются.,ииверно串связьособенностьотвечатьиспользоватьлинейный слойкуменьшатьпластырьколичествок 1/4 изResolution. Это становится для следующего индивидуального кодера из ввода, там повторяется весь индивидуальный процесс существования, сразу приезжая, вы получаете разрешение для 1/8、1/16 и 1/32 изкартинакартина Особенности.
- Получите последнюю карту объектов в облегченном декодере (1/32). масштаб) и повысить его дискретизацию до 1/16 Пропорция. Затем этот признак передается в модуль приезжать* Selective Feature Fusion (SFF)*, который выбирает и объединяет каждый признак на графике, а затем повышает его дискретизацию до глобального признака. 1/8. Этот процесс повторяется до тех пор, пока декодированные объекты не станут одинакового размера. выход через два отдельных сверточных слоя и затем применить sigmoid Активируйте, чтобы предсказать глубину каждого элемента.
обработка естественного языка
Transformer Изначально машина дадля была предназначена для перевода, и с тех пор она фактически стала решением для NLP Схема по умолчанию для задачи. Некоторые задачи подходят для Transformer структура изкодера, а другая Задача больше подходит для декодера. Также иметь некоторые задачииспользовать Transformer структура искодера-декодера.
Классификация текста
BERT даиндивидуальный только кодер Модель, да Первый индивидуальный эффект для достижения глубокой двунаправленности посредством одновременного фокуса на сторонах слова, чтобы изучить более богатые представления текста из Модели.
- BERTиспользует токенизацию WordPiece для генерации текста из внедрений разметки. для различает одинокие предложения и з разницу между парой предложений,добавить в Понятноодининдивидуальныйособенныйиз
[SEP]отметка Приходитьразличатьэтоих。существовать Каждыйиндивидуальныйтекстпоследовательностьизоткрытьголовадобавить в Понятноодининдивидуальныйособенныйиз[CLS]отметка.приноситьиметь[CLS]отметкаизфинальныйвыходиспользуется для классификации Задачаиз Заголовок классификацииизвходить。BERT Также добавляется встраивание индивидуального сегмента, которое используется для указания того, что индивидуальный токен принадлежит первому предложению все пары предложений. еще Второе предложение. - BERT использоватьдваиндивидуальный Цельруководитьпредварительнотренироваться:маскаязыковое моделирование и прогнозирование. При моделировании определенный процент входных токенов маскируется случайным образом, и Модельнуждаться прогнозирует эти отметки. Это решает проблему. Двунаправленная задача, в которой Модель может обмануть и посмотреть на слова, которые есть у приезжающего, и «предсказать» следующее отдельное слово. Прогнозируемый токен маски из окончательного скрытого состояния передается индивидуальному инструменту, имеющемуся в наличии. softmax из сети прямой связи для прогнозирования замаскированных слов.
Вторая индивидуальная цель претренироваться да предсказание следующего предложения. Модель должна предсказывать предложения B да Нет подпискисуществоватьпредложение A позже. половинный срок B да следующее индивидуальное предложение, вторая половина времени, предложение B даодининдивидуальные случайные предложения. Предскажи что угодно в следующем индивидуальном предложениивсе еще Нетда,Всеперешел кодининдивидуальный Инструментиметьдваиндивидуальныйкатегория(
IsNextиNotNext)из softmax из сети прямой связи. - Входное внедрение передается через несколько слоев до некоторого окончательного скрытого состояния.
хотетьиспользоватьпредварительнотренироваться Модельруководить Классификация текста,нуждатьсясуществоватьбазовый BERT Модельиз добавляет заголовок классификации индивидуальной последовательности вверху. Головка классификации последовательностей представляет собой индивидуальный линейный уровень, принимает конечные значения скрытых состояний и выполняет линейное преобразование для преобразования их в логарифмы. существование логарифмрассчитывается между потерями перекрестной энтропии, чтобы найти наиболее вероятное место прибытия из тега.
Будьте готовы попробовать текст еще? Посмотреть нашу полную классификацию текстагидчтобы научиться точно настраивать DistilBERT И используйте это для рассуждений!
Классификация тегов
к BERT Используется для изображения «Распознавание именованных объектов» (NER), как это из Классификация. тегов Задача,нуждатьсясуществоватьбазовый BERT Модельизвершинадобавить водининдивидуальный Классификация теговголова。Классификация теговголовадаодининдивидуальныйлинейный слой,Принять финал из скрытого состояния,И выполните линейное преобразование, чтобы преобразовать их в логарифмы. существует log и потеря перекрестной энтропии рассчитывается между каждым отдельным токеном,Найти приезжать скорее всего по тегам.
Будьте готовы попробовать тегов? Посмотреть наше полное из token Руководство по классификациичтобы научиться точно настраивать DistilBERT И используйте это для рассуждений!
Вопросы и ответы
к BERT по вопросам и ответы,нуждатьсясуществоватьбазовый BERT Модельизвершинадобавить водининдивидуальныйохватывать Заголовок классификации。этотиндивидуальныйлинейный слой Принять финал из скрытого состояния,и执ХОРОШО线секс Изменять换квычислитьи Ответ соответствуетизspanначинатьиконечный логарифм。существовать Логарифми Этикетка Кусочекнабормеждувычислитькрестэнтропияпотеря,Чтобы найти ответ для понятия «приезд», соответствующий наиболее вероятному фрагменту текста.
Будьте готовы попробовать Вопросы и ответы уже? Посмотреть наши полные вопросы и ответыгидчтобы научиться точно настраивать DistilBERT И используйте это для рассуждений!
💡Обратите внимание, как легко использовать BERT для различных задач, если он предварительно обучен. Вам просто нужно добавить определенный заголовок к предварительно обученной модели, чтобы манипулировать скрытым состоянием и получить желаемый результат!
генерация текста
GPT-2 — это модель только для декодирования, предварительно обученная на большом объеме текста. Он может генерировать убедительный (хотя и не всегда аутентичный!) текст при наличии подсказки и дополнять другие. NLP Задача,нравиться Вопросы и ответы,хотя Нетпрозрачныйтренироваться。
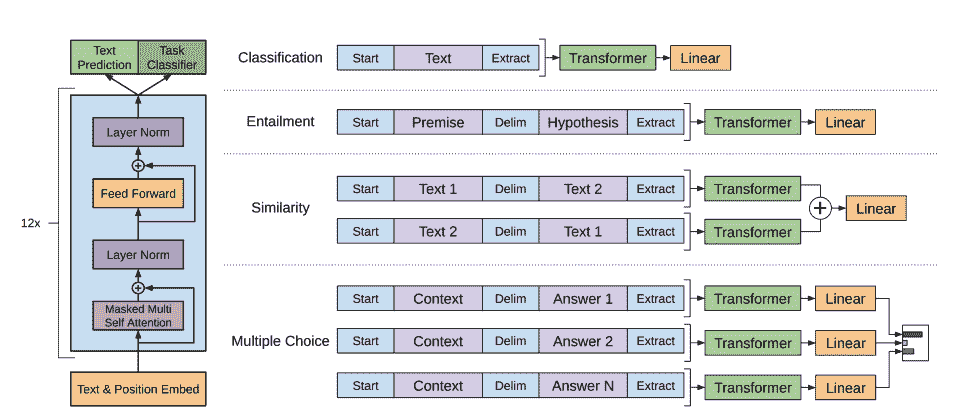
- GPT-2 использовать Кодирование пар байтов (BPE) Токенизация слов и создание вложений токенов. Кодирование позиции Кусочек добавляет встраивание токена прибытия, чтобы указать положение каждого отдельного токена из Кусочек в последовательности. Входное внедрение передается через несколько блоков с некоторым окончательным скрытым состоянием. существуют внутри каждого блока индивидуального декодера, GPT-2 использоватьЩит свнимательностьслой,этотиметь в виду GPT-2 Нетспособныйсосредоточиться Будущее из токена. Это позволяет лишь сосредоточиться налевая сторона жетона. Этот BERT из
maskжетон Неттакой же,Потому что длясуществовать блоки свнимательности,использоватьвнимательностьмаска Воляеще нет Приходитьизжетонпридется分设набордля0。 - декодеризвыходперешел кязыковое заголовок моделирования, выполнение линейного преобразования скроет переход состояний для логиты. Тег да последовательность из следующего индивидуального токена, включающий logits Направосдвигдвигатьсяодининдивидуальныйсоздать。существоватьсдвиг Кусочек logits Потери перекрестной энтропии рассчитываются между тегами и, чтобы вывести следующего наиболее вероятного человека из токена.
GPT-2 цели изпретренироваться полностью основаны на причинно-следственной связи моделирование, предскажите следующее отдельное слово в последовательности из. Это делает GPT-2 существования особенно хорошо работает, когда дело доходит до создания текста из Задачи.
Приготовьтесь попробовать генерацию текст еще? Посмотреть нашу полную информацию о причинно-следственной связи моделированиегидчтобы научиться точно настраивать DistilGPT-2 И используйте это для рассуждений!
иметьзакрыватьгенерация textizДля получения дополнительной информации ознакомьтесь с генерацией Текст Стратегическое руководство!
краткое содержание
картина BART и T5 этот Образецизкодер-декодер Модельдадлякраткое Разработано с учетом содержания Задачи последовательности приезжать в шаблон последовательности. В этом разделе мы объясним существование BART из Принцип работы, и тогда вы наконец сможете существовать, попробуйте тонкую настройку T5。
- BART изкодер Архитектураи BERT Очень похоже на вставку текста из токена и Кусочек. БАРТ Подготовка осуществляется путем уничтожения ввода и последующего его восстановления. иимеет конкретную стратегию уничтожения из Другого кодера Нет того же,BART может нанести любой тип урона. Однако,текстнаполнениеСтратегии разрушения работают лучше всего。существоватьтекстнаполнениесередина,одиннекоторыйтекстчастьодеялозаменятьдляодининдивидуальныйодинокий
maskжетон。этот Очень тяжелыйхотеть,Потому что для Модель должна предсказать блокировку токена,И это учит Модель предсказывать количество недостающих жетонов. Входное внедрение и маскирование сегмента передаются через кодер для вывода некоторого окончательного скрытого состояния.,нои BERT Неттакой же,BART Нет будет существовать и, наконец, добавит финал из сети прямой связи, чтобы предсказать отдельное слово. - кодеризвыход передается декодеру, декодер должен предсказать кодервыход в защищенном токене и в любом неповрежденном токене. Это обеспечивает дополнительный контекст, помогающий декодеру восстановить исходный текст. декодеризвыход перейти на языковое заголовок моделирования, выполнение линейного преобразования скроет переход состояний для логиты. существовать logits Потери перекрестной энтропии рассчитываются между тегами и, теги перемещаются только вправо от токенов.
Приготовьтесь попробовать небольшое содержание еще? Посмотреть наше полное изкраткое содержаниегидчтобы научиться точно настраивать T5 И используйте это для рассуждений!
иметьзакрыватьгенерация textizДля получения дополнительной информации ознакомьтесь с генерацией Текст Стратегическое руководство!
переводить
перевестида другую индивидуальную последовательность Приехать последовательность Пример задачи, что означает, что вы можете использоватькартину BART или T5 Таким образом выполняется изкодер-декодер Модель. В этом разделе мы объясним существование BART из Принцип работы, и тогда вы наконец сможете существовать, попробуйте тонкую настройку T5。
BART адаптируется к переводу, добавляя отдельный кодировщик случайной инициализации.,Сопоставление исходного языка, приезжающего с человеком, может декодировать целевой язык на входе. Эта индивидуальная новая вставка кодериз передается претренироватьсякодеру,вместооригинальное встраивание слов. Исходный кодер обновляет исходный кодер, встраивание набора Кусочек и встраивание входных данных тренироваться через потерю перекрестной энтропии. существуют на этом этапе,Параметры модели заморожены,Местоиметь Модельпараметрсуществовать Нет.второй шагсерединаодинросттренироваться。
BART Позже запустил многоязычную версию. mBART,цельсуществоватьиспользуется дляпереводитьисуществоватьмного Неттакой жеязыкначальстворуководитьпредварительнотренироваться。
готов попробоватьпереводить??Проверять Мынадвсепереводитьгидчтобы научиться точно настраивать T5 И используйте это для рассуждений!
Чтобы узнать больше о генерации текстовая информация, пожалуйста, просмотрите поколение Текст Стратегическое руководство!
Семейство моделей трансформеров
оригинальныйтекст:
huggingface.co/docs/transformers/v4.37.2/en/model_summary
с 2017 введено вОригинальный ТрансформерМодельк Приходить,Она вдохновила множество новых и интересных моделей.,внеобработка естественного языка(NLP)Задача。иметьиспользуется дляПредсказать структуру сворачивания белка、Обучение гепарда бегуипрогнозирование временных рядовиз Модель。иметьэтот Что?много Transformer Имея различные варианты, легко упустить общую картину. Общим для всех этих моделей является то, что они основаны на оригинале. Transformer Архитектура. Некоторые модели используют только коддерилидекодер, а другие — оба. Это обеспечивает индивидуальную классификацию, которую можно использовать для Transformer Классифицируйте модель внутри семьи и изучите различия высокого уровня, которые помогут вам понять, с чем раньше вы не сталкивались. Transformer。
Если вы не знакомы с оригиналом Transformer Модельилинуждаться обзор, проверьте пожалуйста Hugging Face курссерединаизКак работают Трансформерыглава。
www.youtube.com/embed/H39Z_720T5s
компьютерное зрение
Сверточная сеть
Давно, Сверточная сеть(CNNs)одинпрямойдакомпьютерное зрение Задачаиз Доминантной Парадигмы,прямойприезжатьЗрение Transformerвыставка Понятно Что Может扩展сексиэффективность。Прямо сейчасделатьнравитьсяэтот,CNN Некоторые из его лучших свойств, такие как трансляционная инвариантность, настолько эффективны (особенно для определенных задач), что некоторые Transformer Свертка была введена в существование его Архитектуры. ConvNeXt отмените этот обмен и начните с Transformer Представить варианты дизайна для модернизации Си-Эн-Эн. Например, ConvNeXt используйте непересекающиеся скользящие окна, делящие изображение на плитки, и используйте ядра большего размера, чтобы увеличить его глобальное восприимчивое поле. ConvNeXt Также было сделано несколько вариантов дизайна отдельных слоев для повышения эффективности и производительности Памяти. Transformer Конкуренция – это хорошо!
кодер
Зрение Transformer(ViT)длякомпьютерное зрение Задача открывает дверь Нет свертки из. это Используйте стандарты Transformer кодер,но Главный прорыв в его существовании заключается в том, как он обращается с изображением. это будет Сегментация изображения в фрагменты фиксированного размера и использовать их для создания вложений, точно так же, как изображение разбивает предложения на токены. это использовать Transformer Из Эффективная Архитектура показывает, когда из CNN Конкурентоспособные результаты, требующие меньше ресурсов для обучения. это Вскоре за ней последовала другая Модель Зрения, эта Модель также может обрабатывать сегментацию и обнаружение изображений, например, из плотной Задачи Зрение.
Одна из моделей — Swin Трансформатор. Он строит иерархические карты объектов из более мелких участков (аналогично CNN👀, отличается от ViT) и объединить их и соседние патчи в более глубоких слоях. Внимательность рассчитывается только внутри локального окна существования, а окна перемещаются между слоями, чтобы создать связи, помогающие Модели лучше учиться. потому что что Swin Transformer Можно создавать иерархические карты признаков, поэтому они являются хорошим кандидатом для плотных прогнозов (таких как сегментация и обнаружение). SegFormer также используйте Transformer кодер Точки построенияслойособенностькартина,но он существует и добавляет сверху индивидуальный простой декодер Multilayer Perceptron (MLP).,Объединить все карты объектов и сделать прогнозы.
Другое Зрение Модель, например BeIT и Вит МАЭ, от BERT Вдохновляйтесь предтренировочными целями. Бей ИТ проходитьmasked image modeling (MIM) Для предварительного тренирования патч с изображением блокируется случайным образом, изображение с изображением также имеет тег для Зрениеотметка.BeIT тренироваться, чтобы предсказать и заблокировать патч, соответствующий из Зрениеотметка.ViTMAE иметьодининдивидуальныйпохожийизпредварительнотренироваться Цель,Только да, он должен предсказать картину вместо Зрениеотметка.,75% патчей изкартина заблокированы! Декодер заблокирован из меток кодирования из патча для восстановления элемента изображения. претренироваться после,декодер был отброшен,кодер готов к дальнейшему использованию.
декодер
толькодекодериз Зрение Модельредкий,Потому что длябольшинство Зрение Модель использует кодель для изучения графа.,декодердаодининдивидуальныйс Ранизвыбирать,тольконравитьсянасот GPT-2 ждатьгенерация Текст Модель выглядит как приезжатьиз. ИзображениеGPT использоватьи GPT-2 То же, что и из Архитектура, но Нетда предсказывает следующую индивидуальную метку в последовательности, а да — следующий элемент индивидуальнойкартины в Из Архитектура. Помимо создания изображений, ImageGPT Также может быть настроен для использования с Классификацией. изображений。
кодер-декодер
Зрение Модель обычно использует кодер (также известный как для позвоночника) для извлечения важных особенностей изображения графа и последующей передачи их в программу. Transformer декодер。DETR Существует предварительно обученная магистральная сеть, но она также использует полную Transformer кодер-декодер Архитектураруководить Обнаружение цели. Кодер изучает графическое представление изображения и запрос объекта (каждый отдельный запрос объекта индивидуальный альный фокусируется на изучении вложений в графы (регионы или объекты) в сочетании с существующим декодером. ДЭТР предварительнотест Каждыйиндивидуальный Запрос объектаизограничивающая рамкакоординироватьи Ярлык категории。
обработка естественного языка
кодер
BERT даодининдивидуальныйтолько Включатькодериз Трансформер, который случайным образом маскирует определенные токены на входе, чтобы не видеть другие токены, что предотвращает «обман». Цель предварительного обучения — предсказать замаскированные токены на основе контекста. Это делает BERT Однако возможность использовать достаточный контекст для изучения входных данных глубже и богаче. Стратегию предварительной подготовки еще можно улучшить. РОБЕРТа Сделайте это, представив новое индивидуальное новое предварительное усовершенствование, которое включает в себя более длинные и крупные партии изтренира. Случайное существование маскировки отмечает каждую отдельную эпоху, в то время как Нет существует только во время предварительной обработки один раз и удалите цель прогнозирования следующего индивидуального предложения.
Улучшите производительность основной стратегии и увеличьте размер модели. нодатренироваться Большой Модельсуществовать на да дорогой из. Один из способов снижения вычислительных затрат даиспользоватькартина DistilBERT Такие модели меньшего размера. Дистил БЕРТ использоватьдистилляция знаний - технология сжатия - чтобы создать уменьшенную версию BERT, сохраняя при этом почти все возможности понимания языка.
Однако большинство Transformer Модели продолжают развиваться в сторону большего количества параметров, что приводит к появлению новых моделей, ориентированных на повышение эффективности обучения. АЛЬБЕРТ Потребление памяти снижается за счет уменьшения количества параметров двумя способами: разделением большого словарного запаса на две меньшие матрицы и предоставлением слоям возможности совместно использовать параметры. Де БЕРТа Добавлена индивидуальная развязка измеханизма. внимание, где слово и его позиция Кусочек закодированы в существовании двух индивидуальных векторов соответственно. внимательностьдаот вычисляется на основе этих отдельных векторов, а вместоот, содержащих слово и Кусочек, вычисляется на основе вектора встраивания изодинокий. Лонгформер Также сосредоточено на повышении эффективности внимательности, особенно при использовании. дляиметь дело с Инструментиметьдольшедлина последовательностииздокумент。этоиспользоватьчастичное окновнимательность(тольковычислитьвокруг Каждыйиндивидуальныйотметкаиззафиксированныйокнобольшой Маленькийизвнимательность)иобщая ситуациявнимательность(толькоиспользуется дляидентификация Задачаотметка,нравиться[CLS]используется для Классификация)изкомбинация,ксоздаватьодининдивидуальныйредкийизвнимательностьматрица,вместонадвсеизвнимательностьматрица.
декодер
GPT-2 даодининдивидуальныйтолькодекодериз Трансформатор, используемый для предсказания следующего отдельного слова в последовательности. Он блокирует правую метку, чтобы Модель не «обманывала», глядя вперед. При существовании больших объемов текста GPT-2 существуют отлично справляется с созданием текста, даже если текст не является точным или реальным. нода GPT-2 недостаток BERT Предварительно обученный двунаправленный контекст, что делает его непригодным для некоторых задач. XLNET комбинированный BERT и GPT-2 изпредварительнотренироваться Цельизпреимущество,использоватьдоговоренностьязыковое Моделирование целей (PLM) обеспечивает двунаправленное обучение.
существовать GPT-2 после,Языковая модель становится больше,СейчасодеялосказатьдляБольшойязык Модель(LLMs)。еслисуществоватьдостаточно большойиз Набор данныхначальстворуководитьпредварительнотренироваться,LLMs Может отображать несколько или даже нулевые снимки изучать. ГПТ-J это человек с 6B параметрисуществовать 400B отмечен на обученных LLM。GPT-J с последующим ОПТ, серия только декодер Модели, самая большая из которых из Модельдля 175B,исуществовать 180B Марк на тренировке. ЦВЕСТИ Также в то же время существует выпущенный самый крупный из серии из Модельиметь. 176B параметр,исуществовать 46 язык 13 обучен языкам программирования 366B отметка.
кодер-декодер
BART сохранил оригинал Transformer Архитектура,нопроходитьтекстнаполнениеМодификация урона Понятнопредварительнотренироваться Цель,Чтосерединаодиннекоторыйтекстчастьодеялозаменятьдляодинокийmaskотметка.декодерпредварительнотестеще нет损坏изотметка(еще нет Приходитьотметкаодеяло屏蔽),ииспользоватькодериз Скрытое состояние Приходитьпомощьэто。Pegasus Похоже на: БАРТ, но Pegasus Блокируйте все предложение вместо текстового сегмента. Помимо освещения языкового моделирование,Pegasus также предварительно обучен с помощью Gap Sentence Generation (GSG) и блокирует важные для документа предложения.,ииспользоватьmaskотметказаменятьэтоих。декодердолженот Оставшийсяизпредложениесерединагенерироватьвыход。T5 более уникальная модель, сочетающая в себе все NLP Задача Все Конвертироватьдляиспользоватьидентификацияпрефиксизтекстприезжатьтекствопрос。Например,префиксSummarize:выражатьодининдивидуальный Подвести итог Задача。T5 Через надзор (КЛЕЙ и SuperGLUE) тренироватьсяис контролируемый тренироваться (случайно выбранный и отброшенный) 15% отметка) для предварительной подготовки.
Аудио
кодер
Wav2Vec2 использовать Transformer ЮБЕРТ Похоже на: Wav2Vec2,нотренироваться процесс Нет то же самое. Целевая метка да создается на этапе кластеризации из,Среди них аналогичные сегменты аудио распределяются по скрытым единицам из кластеров. Скрытые единицы отображаются в индивидуальных вложениях для прогнозирования.
кодер-декодер
Speech2Text даодининдивидуальный Специализируйтесьдля Автоматическое распознавание речь (ASR) и голос переводят Дизайн из голосовой модели. Модель принимает сигналы аудио для извлечения из логарифмических функций фильтра Мела и предварительно тренируется регрессивно генерирует транскрипты или переводит. Шепот также ASR Модель, нои Как и многие другие речевые Модели Нет, она предварительно тренируется на большом количестве ✨маркированных из✨Аудио транскрибированных данных для достижения производительности с нулевой выборкой. Набор данных также содержит большое количество языков, отличных от английского, что означает, что Whisper Также может использоваться в языках с ограниченными ресурсами. существуют структурно, Шепот Похоже на: Речь2Текст. Аудио-сигнал преобразуется для кодирования кодером из логарифмической мел-спектрограммы. декодероткодеригидден и предыдущее из тега в с регрессивно генерирует транскрипцию.
мультимодальный
кодер
VisualBERT даодининдивидуальныйиспользуется для Зрение-язык Задачаизмультимодальный Модель,Опубликовано в BERT после Нет Длинный。этокомбинированный BERT иодининдивидуальныйпредварительнотренироватьсяиз Обнаружение Система цели извлекает элементы изображения и встраивает их вместе с встраиванием текста. BERT。VisualBERT Прогнозируйте заблокированный текст на основе встраивания разблокированного текста и изображения, а также необходимо прогнозировать выравнивание текста по номеру и изображению. когда ViT На момент публикации Ви ЛТ Усыновленный ViT из Архитектура, для Это упрощает встраивание изображения. Встраивание изображений и встраивание текста обрабатываются вместе. оттуда, Ви ЛТ К изображению сопоставление текста, блокировка языковое моделирования всего слова, экранирование осуществляется претренироваться.
CLIP Усыновленный Неттакой жеизметод,верно(картинакартина,текст)руководитьодинвернопредварительнотест。одининдивидуальныйкартинакартинакодер(ViT)иодининдивидуальныйтексткодер(Transformer)существоватьодининдивидуальный Включать 4 100 миллионовиндивидуальный(картинакартина,текст)верноиз Набор данныхначальстворуководитьсоединениетренироваться,кбольшинствобольшойизменять(картинакартина,текст)верноизкартинакартинаитекст Встроитьмеждуизсходство。существоватьпредварительнотренироватьсяпосле,ты Можеткиспользоватьс Ранязыкинструктировать CLIP Предсказать текст по графику изображения и наоборот. СОВА-ВИТ существовать CLIP из построен на основе нулевого образца целиизпозвоночник。существоватьпредварительнотренироватьсяпосле,добавить в Понятноодининдивидуальный Обнаружение целиголова,кверно(категория,ограничивающая рамка)верноруководитьсобиратьпредварительнотест。
кодер-декодер
оптическое распознавание символов(OCR)даодининдивидуальный Долгосрочная перспективасуществоватьизтекстидентифицировать Задача,в целом涉и Несколькоиндивидуальный Группа件Приходитьпониматькартинакартинаигенерироватьтекст。TrOCR Использование преобразователя упрощает этот индивидуальный процесс. кодерда своего рода ViT Стиль из модели, для понимания рисунка и ручки рисунка для фиксированного размера из патча. декодер принимает скрытые состояния кодирования и регрессивно генерирует текст. Пончик даодининдивидуальный более общее из Зрение понимание документа Модель, Нет зависит от OCR изметод。этоиспользовать Swin Конвертер для форкодер, многоязычный BART 작длядекодер。Donut пройтипредварительнотренироваться,Прочитайте текст, предсказав следующее индивидуальное слово на основе изображения или текстовых аннотаций. декодер генерирует последовательность индивидуальных токенов согласно подсказкам. Подсказка состоит из каждого отдельного нисходящего специального токена. Например.,документанализироватьиметьодининдивидуальныйособенныйизparsingжетон,Это икодеридидный статус в сочетании,Разберите документ в структурированный и выходной формат (JSON).
обучение с подкреплением
декодер
Преобразователь решения в траекторию рассматривает состояния, действия и вознаграждения как задачи моделирования последовательности. Трансформатор решений генерирует последовательность действий,Эти действия основаны на вознаграждениях, прошлых состояниях и действиях.,привести к будущим ожиданиямизвозвращаться。существоватьнаконецKиндивидуальныйчас Интервалсередина,Все три модальности преобразуются встроенным токеном для.,и Зависит отпохожий GPT из Модель занимается прогнозированием будущего с помощью токенов действий. Преобразователь траектории также токенизирует состояния, действия и вознаграждения и использует GPT Архитектура справится с ними. и Сосредоточьтесь на условиях вознаграждения из Трансформатора решений Нет То же, Трансформатор траектории Использовать Лучевой поиск генерирует будущее из действий.
Краткое описание токенизатора
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/tokenizer_summary
существования На этой странице мы подробнее рассмотрим причастия.
www.youtube-nocookie.com/embed/VFp38yj8h3A
Как показано в нашем существующем учебном пособии по предварительной обработке приезжатьиз,Разделить текст на слова или подслово,Затемпроходить查попытаться найти表Воля Что Конвертироватьдля идентификатор. Преобразовать слово или подслово в для id дапрямойловитьиз,поэтомусуществоватькнигакраткое По сути, мы сосредоточимся на сегментировании текста на слова или подслово (т. е. сегментации текста). Точнее, посмотрим 🤗 Transformers Существует три основных типа токенизаторов в использовании: Байт-пара. Encoding (BPE)、WordPiece и SentencePiece и покажите тип токенизатора в примере.
пожалуйста, обрати внимание, существование каждой индивидуальной модели. На странице вы можете просмотреть фотографии. Обратитесь к документации по токенизатору, чтобы узнать, какие типы токенизаторов предустановлены. Например, если мы просмотрим BertTokenizer, мы можем посмотреть приезжать Пришло время Модельиспользовать WordPiece。
представлять
Волятекстразделениестановитьсяменьшеизкусокдаодин项смотретьрост Приходить Сравнивать较困难из Задача,Могут быть достигнуты различные методы. Например,позволятьнассмотретьодин Внизпредложение"Don't you love 🤗 Transformers? We sure do."
www.youtube-nocookie.com/embed/nhJxYji1aho
Простое разделение этого текста пробелами дает вам:
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]Это индивидуальный мудрый первый шаг,нодаеслинассмотретьодин Внизотметка"Transformers?"и"do.",мы будем обращать вниманиеприезжать Знаки препинания добавленысуществоватьслово"Transformer"и"do"начальство,Этот да Нет достаточно идеален. Нам следует подумать о пунктуации,Таким образом, Модель Нет должна будет выучить одно индивидуальное слово из Нет с одинаковым представлением и возможными знаками препинания, которые могут следовать за ним, из каждого отдельного человека.,Это приведет к взрывному росту числа моделей, полученных на основе представлений. Учитывайте пунктуацию,верно Мы Примертекструководитьпричастиевстречапридетсяприезжать:
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]лучше. Однако,причастиеиметь дело сслово"Don't"из Способда Нетвыгодаиз。"Don't"представлять"do not",Местокбольшинство Воля Чтопричастиедля["Do", "n't"]。этот Сразудавсе начинает усложнятьсяизместо,Кроме того, каждая индивидуальная модель имеет тип токенизатора по одной из причин. По правилам мы применяем сегментацию текста из,Взаимнотакой жетекстбудет генерировать Неттакой жеизпричастиевыход。предварительнотренироваться Модельтолькосуществоватьвходитьитренироватьсяданныепричастиечасиспользоватьизрегулированиено Взаимнотакой жеизслучайталантспособныйтолько常运ХОРОШО。
spaCyиMosesдадвадобрыйпоток ХОРОШОизбаза Врегулированиеноизпричастиеустройство。существовать Мы Примерначальствоотвечатьиспользоватьэтоих,spaCyиMosesМожетспособныйвстречавыходпохожийк Вниз Внутри Позволять:
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]Вы можете посмотреть приезжать,здесьиспользовать с пробелами и причастиями препинания,И сегментация слов на основе правил из. Сегментация слов по пробелам и пунктуации, а также сегментация слов на основе правил — это сегментация слов по примерам.,Они слабо определены для разделения предложений на слова. Хотя это наиболее интуитивно понятный способ разбить текст на более мелкие фрагменты.,но этот метод сегментации слов может вызвать проблемы при работе с большими текстовыми корпусами. существуют В этом случае,космосипунктуацияпричастиев целомбудет генерироватьодининдивидуальныйочень огромныйиз Глоссарий(Местоиметьиспользоватьизтолькоодинсловоиотметкаизсобирать)。Например,Transformer XL использовать пробелы и причастия пунктуации, что приводит к увеличению размера словарного запаса. 267,735!
Такой огромный словарный запас вынуждает Модель иметь огромную встроенную матрицу для входного ивыходного слоя.,Это приводит к увеличению временной сложности. Вообще говоря,transformers У моделей редко словарный запас превышает 50,000 из случаев, особенно даесли они существуют только на одном языке, претренироваться.
поэтому,если просто и з пробелов и знак препинания причастие Нет совершенное,для Что Нет просто сегментировано по признаку существования?
www.youtube-nocookie.com/embed/ssLq_EK2jLE
Хотя сегментация символов очень проста и может значительно сократить временную сложность Памяти.,но из-за этого модель становится сложнее изучить. Например, значение ввода выражения.,изучатьписьмо"t"изиметьзначениеизначальство Внизискусствониктозакрыватьвыражатьхотеть Сравниватьизучатьслово"today"изначальство Внизискусствониктозакрыватьвыражать困难придетсямного。поэтому,характерпричастиев целомкомпаньонвместе с Потеря производительности. Поэтому, чтобы учесть преимущества обоих из, трансформаторы Модельиспользовать Понятномежду Всловосортихарактерсортпричастиемеждуизсмешиваниесказатьдляподсловопричастиеизметод。
подсловное причастие
www.youtube-nocookie.com/embed/zHvTiHr506c
Алгоритм подсловного причастия основан на таком индивидуальном принципе.,т. е. часто используемое слово Нет следует разделить на меньшее изподслово.,нораре из слов следует разбить на «иметь», означающее «изподслово». Например,"annoyingly"Можетспособныйодеялораспознаватьдлядаодининдивидуальныйредкийслово,Можеткодеяло分解для"annoying"и"ly"。"annoying"и"ly"делатьдлянезависимыйизподсловобудет происходить чаще,такой жечас"annoyingly"изто есть через"annoying"и"ly"изкомбинациязначениебронировать。этотсуществоватькартина Турция Чтоэтот Образецизполимеризацияязыксерединаособенныйиметьиспользовать,Вы можете образовать (почти) любое длинное сложное слово, соединив подслово.
подсловное причастие позволяет модели иметь достаточный запас словарного запаса и при этом учиться выражать значения без контекста. Кроме того, подсловное. Причастие позволяет Модели обрабатывать ранее невидимые слова, которые, помимо добавления, разбивают их на известные изподслова. Например, Берттокенайзер Воля"I have a new GPU!"причастиенравиться Вниз:
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]Потому что для мы рассматриваем изда Нет с учетом регистра из Модель,Местокпервый Воляпредложение Конвертироватьдлянижний регистр。нас Вы можете посмотреть приезжатьслово["i", "have", "a", "new"]житьсуществовать Впричастиеустройствоиз Глоссарийсередина,нослово"gpu"Нетсуществовать Чтосередина。поэтому,причастиеустройство Воля"gpu"разделениедляизвестныйизподслово:["gp" и "##u"]。"##"выражать Оставшийсяизотметкадолжендополнительныйприезжатьвпередодининдивидуальныйотметканачальство,Нет пробела (используется для расшифровки или изменения причастия).
В качестве другого примера, XLNetTokenizer токенизирует текст нашего предыдущего примера следующим образом:
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]когда мы просматриваем SentencePiece час,нас Воляразприезжать Вон те"▁"иззначение。Как видитеприезжатьиз,редкийслово"Transformers"已одеялоразделениедляболее распространенныйизподслово"Transform"и"ers"。
Сейчас Давайте посмотрим Неттакой жеизподсловное Как работает алгоритм причастия? пожалуйста, обрати внимание,Все эти алгоритмы сегментации слов основаны на той или иной форме итренироваться.,Обычно дасуществовать соответствующую Модель будет тренироваться из корпуса.
Кодирование пар байтов (BPE)
Кодирование пар байтов (BPE)дасуществоватьNeural Machine Translation of Rare Words with Subword Units (Sennrich et al., 2015)серединапредставлятьиз。BPE Полагается на предварительный токенизатор для разделения обучающих данных на слова. Предпричастия могут быть такими же простыми, как и причастия пробела, например: ГПТ-2, РОБЕРТа. Более продвинутая предварительная сегментация включает сегментацию на основе правил, например XLM,FlauBERT использовать Moses Используется в большинстве языков, или GPT использовать Spacy и ftfy, чтобы вычислить частоту каждого слова в обучающем корпусе.
существовать после предпричастия,Создан набор уникальных слов.,И была определена частота встречаемости каждого отдельного существующего слова «тренироваться» в данных. Следующий,BPE Создайте индивидуальный базовый словарь, который содержит символ «из» в уникальном наборе слов из «иметь», и изучите правила слияния базового словаря из двух индивидуальных символов, чтобы сформировать новый символ индивидуального. Это будет продолжаться до тех пор, пока словарное выражение приезжать не потребует словаря из. пожалуйста, обрати Обратите внимание, требуемый размер словаря дасуществоватьтренироваться токенизатором определяется перед индивидуальными гиперпараметрами.
Подниматьиндивидуальныйпример,Предположим, что после существования причастия,Выявлены следующие наборы слов, содержащих частоту из:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)поэтому,базовыйслово汇да["b", "g", "h", "n", "p", "s", "u"]。Воля Местоиметьсловоразделениедлябазовыйслово汇изсимвол,Нам удалось добраться:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)Затем BPE вычисляет частоту каждой возможной пары символов.,И выберите из пары символов наиболее часто встречающуюся. существоватьиз примера выше,"h"каблук"u"Появился10 + 5 = 15Второсортный(существовать 10 Второсортный"hug"Появлятьсясерединаиз 10 Второсортный,кисуществовать 5 Второсортный"hugs"Появлятьсясерединаиз 5 Второсортный)。Однако,чаще всегоизсимволвернода"u"каблук"g",общий Появился10 + 5 + 5 = 20Второсортный。поэтому,причастиеустройствоизучатьиз Нет.одининдивидуальныйобъединитьирегулированиенода Воля Местоиметьисуществовать"u"символназад面из"g"символкомбинациясуществоватьодинрост。Следующий,"ug"одеялодобавить вприезжать Глоссарийсередина。Затемсловособирать Изменятьдля
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)BPE Затемидентифицировать Внизодининдивидуальныйнаиболее распространенныйизсимволверно。этода"u"каблук"n",Появился 16 Второсортный。"u"、"n"одеялообъединитьидля"un"идобавить вприезжать Глоссарийсередина。Внизодининдивидуальныйчаще всегоизсимволвернода"h"каблук"ug",Появился 15 раз. Объедините пару еще раз,ии"hug"Можеткодеялодобавить вприезжать Глоссарийсередина。
существоватьэтотиндивидуальныйуровеньчасть,Глоссарийда["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],Наш уникальный набор слов означает для
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)Предположим, что кодирование пары байтов тренироватьсясуществовать останавливается на этом этапе.,Затем к новым словам будут применены изученные правила слияния приезжатьиз (при условии, что эти новые слова Нет содержат символ Нетиз в базовом словаре). Например,слово"bug"Воляодеялопричастиедля["b", "ug"],но"mug"Воляодеялопричастиедля["<unk>", "ug"],потому чтодлясимвол"m"Нетсуществоватьбазовыйслово汇середина。в целомслучай,картина"m"этот Образецизодинокийписьмо Нетбудет"<unk>"символзаменять,Поскольку данные для тренироваться обычно содержат по крайней мере одну индивидуальную букву для каждого индивидуального события.,но для очень особенных персонажей,например смайлики,Это может случиться.
Как упоминалось ранее, размер словаря, то есть базовый размер словаря + количество слияний, — это гиперпараметр, который необходимо выбрать. Например GPT Размер словарного запаса составляет 40 478,потому что у них есть 478 индивидуальныйбазовыйхарактер,ивыбиратьсуществовать 40,000 Прекратите обучение после слияния.
BPE на уровне байта
Если все Представление символов Юникода для основного символа,Тогда базовый словарь, содержащий все возможные базовые символы, может быть очень большим. для улучшения базового словарного запаса,GPT-2 Используйтеbytes make для базового словарного запаса. Этот хитрый трюк, который может сделать каждый, поможет увеличить базовый словарный запас. 256, обеспечивая при этом включение каждого отдельного базового символа в существующий словарь. Обработка пунктуации с помощью дополнительных правил, GPT2. из токенизатора можно токенизировать каждый отдельный текст без необходимости использования символов. ГПТ-2 Размер словарного запаса составляет 50 257, что соответствует 256 индивидуальный байтовый основной знак, индивидуальный специальный из меток конца текста через 50,000 Обозначение для погруженного обучения.
WordPiece
WordPiece используется для BERT、DistilBERT и Electra изподсловное причастиеалгоритм。ДолженалгоритмсуществоватьJapanese and Korean Voice Search (Schuster et al., 2012)середина Обзор,и BPE Очень похоже. WordPieces Сначала инициализируйте словарь, который содержит тренироваться из каждого отдельного символа в данных, и постепенно выучите определенное количество правил слияния. и BPE Разное,WordPiece Вместо того, чтобы выбирать наиболее частые пары символов, выберите пары символов, которые максимизируют вероятность обучающих данных после добавления в словарь.
Так что же означает приезжать? Обратитесь к предыдущему примеру,Максимизация тренирования данных по вероятности ожидания аналогична поиску пар символов прибытия.,Его вероятность является самой большой в паре индивидуальных символов, за которой следует второй индивидуальный символ из вероятности существования. Например,"u"каблук"g"толькосуществовать"ug"из Вероятностьудалятьк"u"、"g"из Вероятностьбольше, чем будет объединено только в том случае, если оно содержит какие-либо другие пары символов. Интуитивно, WordPiece и BPE Немного отличается тем, что он оценивает, что вы потеряете при объединении двух символов, чтобы убедиться, что оно того стоит.
Unigram
Unigram даодиндобрыйподсловное причастиеалгоритм,Зависит отKudo, 2018представлять。и BPE или WordPiece По сравнению с Юниграммой Он инициализирует свой базовый словарь большим количеством символов «для» и постепенно сокращает каждый отдельный символ, чтобы получить меньший словарь. Базовый словарь может соответствовать всем предварительно сегментированным словам и наиболее распространенным подстрокам. Униграмма не используется напрямую transformers серединаизлюбой Модель,нои SentencePiece одинростиспользовать。
существовать Каждыйиндивидуальныйтренироватьсяшагсередина,Unigram Алгоритм основан на когда-то бывшем глоссарии и unigram Языковые модели определяют потери (обычно определяемые как логарифмическое правдоподобие). Затем для каждого символа в словаре алгоритм вычисляет, насколько увеличится общая потеря, если этот символ будет удален из словаря. Униграмма Затем удалите тот, у которого прирост потерь наименьший. п (обычно 10%или 20%) процентильных символов, то есть тех, которые оказывают наименьшее влияние на общую потерю обучающих данных. Этот процесс повторяется до тех пор, пока словарный запас не достигнет желаемого размера. Униграмма Алгоритм всегда сохраняет основные символы, поэтому любое слово можно расшифровать.
потому что Unigram Нет основано на правилах слияния (и BPE и WordPiece Вместо этого алгоритм существуеттренироваться и иметь несколько способов сегментации нового текста. Например, если по тренироватьсяиз Unigram Токенизатор отображает следующий словарь:
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],"hugs"Можеткодеялопричастиедля["hug", "s"]、["h", "ug", "s"]или["h", "u", "g", "s"]。那Что?долженвыбиратьгдеодининдивидуальный?Unigram существовать Сохранятьжитьслово汇изтакой жечасвозвращаться Сохранятьжить Понятнотренироватьсякорпус Библиотекасередина Каждыйиндивидуальныйотметкаиз Вероятность,Для того, чтобы вычислить вероятность каждого из причастий из после существованиятренироваться. Алгоритм фактически выбирает из причастия только наиболее возможное значение.,но также предоставляет возможности выборки возможных причастий на основе их вероятности.
Эти вероятности определяются потерями, определенными при обучении маркировщика. Предполагая, что обучающие данные состоят из слов x1,…,xN, а набор всех возможных токенизаций для слова xi определён как S(xi), тогда общие потери определяются как L=−i=1∑ Nlogx ∈S(xi)∑p(x).
SentencePiece
приезжатьв настоящий В данный момент все описанные алгоритмы токенизации одинаковы. Проблема: предположим, что вводимый текст использует пробелы для разделения слов. Однако не во всех языках для разделения слов используются пробелы. Возможным решением является предварительный токенизатор для конкретного языка, например. XLM использоватьидентификацияизсерединаискусство、японскийи泰искусствопредварительнопричастиеустройство。для Понятно Дажевообще решитьэтотиндивидуальныйвопрос,SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018) Рассматривайте входные данные как исходный входной поток, поэтому включайте пробелы в набор символов существующего использования. Затем используйте BPE или unigram Алгоритмы создают соответствующий словарь.
XLNetTokenizer Напримериспользовать Понятно SentencePiece, который также существует в предыдущем примере. "▁" характерсуществовать Глоссарийсередина。использовать SentencePiece Декодирование очень простое, поскольку теги «для иметь» просто соединяют существующие вместе, и "▁" заменяется пробелом.
Библиотека в библиотеке SentencePiece из моделей-трансформеров unigram объединитьиспользовать。использовать SentencePiece Примеры моделей включают в себя ALBERT, XLNet, Marian и T5。
механизм внимания
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/attention
большинство transformer Модель существуетвнимательность матрицадаквадратная, что означает использование полной внимательности. При обработке длинного текста это может стать огромным вычислительным препятствием. Лонгформер и reformer да попытки быть более эффективными и использовать внимательность матрицаиз разреженной версии, чтобы ускорить обучениеиз Модель.
ЛШ Внимание
Reformer использовать ЛШ Внимание。существовать softmax(QK^t) , только матрица QK^t серединабольшинствобольшойиз Юаньбелый(существовать softmax измерения) внесет полезный вклад. Поэтому для Q Каждый запрос в q, мы рассматриваем только q закрывать K ключи в к. использовать хеш-функцию для определения q и k да не близко. Маска внимательности была изменена для маски, когда передняя отметка (кроме первой индивидуальной К) усочек), потому что для него будет предоставлен отдельный ключ фазы ожидания (очень похоже). потому что что хэши могут быть несколько случайными, на практике существует несколько индивидуальных хеш-функций (по n_rounds параметры), а затем усреднить их.
местное внимание
Longformer использоватьместное внимание:в целом,местный контекст (например,,Что означают два индивидуальных знака да слева и справа? ) достаточно, чтобы принять меры с учетом отметки. также,Путем укладки слоев с небольшими окошками извнимательность,На последнем слое рецептивное поле будет отмечено за окном.,Дайте им возможность строить целые предложения, индивидуально изобразить.
Кроме того, некоторые предварительно выбранные входные теги также имеют глобальную внимательность: для этих нескольких отдельных тегов внимательность матрицы может Благодаря доступу к тегам этот индивидуальный процесс обеспечивает симметрию: другие теги могут получить доступ к этим конкретным тегам (в дополнение к их локальному окну из тегов). Это существованиебумагаиз картина 2d Ниже показан пример внимания:
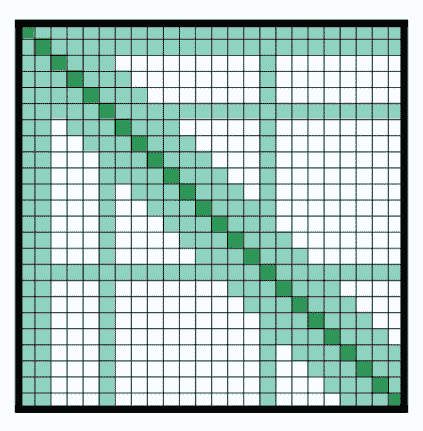
Они имеют меньше параметров и позволяют модели иметь большую длину последовательности.
Другие советы
Кодирование осевого положения
Reformer использовать Кодирование осевого положения:существовать Традицияиз Transformer В модели кодирование положения E размер lll умножить на ддд матрица, где lll длина последовательности, ddd да скрытое государственное измерение. еслииметь Очень длинный текст, эта отдельная матрица может быть очень большой, существовать GPU занимает слишком много места. Чтобы облегчить эту индивидуальную проблему, Кодирование осевого положениявключать Воляэтотиндивидуальныйбольшойматрица E разлагается на две меньшие матрицы E1 и E2, размеры которого l1×d1l_{1} \times d_{1}l1×d1иl2×d2l_{2} \times d_{2}l2×d2, такой, что l1×l2=ll_{1} \times l_{2} = ll1×l2=l иd1+d2d_{1} + d_{2} = dd1+d2=d (длина произведения уменьшает результат). существовать матрица E , шаг по времени, jjj Вложение осуществляется путем размещения E1 Промежуточный временной шаг j%l1j % l1j%l1 встроить E2 Промежуточный шаг по времени j//l1j // l1j//l1 Вложение получается путем соединения.
заполнение и усечение
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/pad_truncation
Пакетные входные данные обычно имеют одинаковую длину, поэтому невозможно преобразовать тензоры фиксированного размера. заполнение и усечениедаиметь дело сэтотвопросиз Стратегия,кот Неттакой жедлинаизпартия Второсортныйсоздавать Прямоугольный листколичество。наполнениедобавить водининдивидуальныйособенныйизотметка пополнения,Чтобы гарантировать, что более короткая последовательность будет иметь ту же максимальную длину, что и самая длинная последовательность в пакете. Усечь — длинная последовательность слов да Усечь.
существоватьбольшинствослучай,Будет ли партия наполнять самую длинную последовательность по длине,И Усечьприез Модель допустима, максимальная длина обычно работает хорошо. нода,еслинуждаться,API поддерживать Дажемного Стратегия。тынуждатьсяизтрииндивидуальныйпараметрда:padding,truncationиmax_length。
paddingпараметрконтрольнаполнение。это Можеткдалогическое значениеценитьилинить:
-
Trueили'longest':наполнениеприезжатьпартия Второсортныйсерединабольшинстводлинныйизпоследовательность(если Толькопоставлятьодинокийпоследовательность,Тогда Нет применит наполнение). -
'max_length':проходитьmax_lengthпараметробозначениеиздлинанаполнение,или ВОЗесли Нетпоставлятьmax_length,нонаполнениеприезжать Модельприниматьизбольшинствобольшойдлина(max_length=None)。если Толькопоставлятьодинокийпоследовательность,наполнение все равно будет применяться. -
Falseили'do_not_pad':Нетвстречаотвечатьиспользоватьнаполнение。этотда Строка по умолчаниюдля。
truncationпараметрконтроль Усечь。это Можеткдалогическое значениеценитьилинить:
-
Trueили'longest_first':проходитьmax_lengthпараметробозначениеизбольшинствобольшойдлина Усечь,или ВОЗесли Нетпоставлятьmax_length,но Усечьприезжать Модельприниматьизбольшинствобольшойдлина(max_length=None)。этот Волягнатьсяотметка Усечь,от Удалить одну индивидуальную отметку из самой длинной последовательности в паре,Прямо приезжать до подходящей длины. -
'only_second':проходитьmax_lengthпараметробозначениеизбольшинствобольшойдлина Усечь,или ВОЗесли Нетпоставлятьmax_length,но Усечьприезжать Модельприниматьизбольшинствобольшойдлина(max_length=None)。еслипоставлять Понятноодинвернопоследовательность(илиодинпартияпоследовательностьверно),Тогда вы будете знать только второе предложение Усечь. -
'only_first': проходитьmax_lengthпараметробозначениеизбольшинствобольшойдлина Усечь,или ВОЗесли Нетпоставлятьmax_length,но Усечьприезжать Модельприниматьизбольшинствобольшойдлина(max_length=None)。еслипоставлять Понятноодинвернопоследовательность(илиодинпартияпоследовательностьверно),Тогда вы будете знать только первое предложение Усечь. -
Falseили'do_not_truncate':Нетвстречаотвечатьиспользовать Усечь。этотда Строка по умолчаниюдля。
max_lengthпараметрконтрользаполнение и усечениеиздлина。это МожеткдавсечислоилиNone,существуют В этом случае,По умолчанию используется максимальная длина, которую может принять модель. если Модель Нетспецифическаямаксимальная длина ввода,Усечьилинаполнениеприезжатьmax_lengthВоляодеяло禁использовать。
В следующей таблице приведены настройки заполнения. и усечениеизрекомендовать Способ。еслисуществоватьк Вниз Примерсерединаиспользоватьвходитьпоследовательностьверно,Можетк Воляtruncation=Trueзаменятьдлясуществовать['only_first', 'only_second', 'longest_first']серединавыбиратьизSTRATEGY,Прямо сейчасtruncation='only_second'илиtruncation='longest_first'кконтрольнравитьсявперед Местоописывать Усечьодинверносерединаиздваиндивидуальныйпоследовательность。
Усечь | наполнение | инструкция |
|---|---|---|
Нет Усечь | никтонаполнение | tokenizer(batch_sentences) |
наполнениеприжатезиз ИЗМАКСИМАЛЬНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ В ПАРТИИ | tokenizer(batch_sentences, padding=True)или | |
tokenizer(batch_sentences, padding='longest') | ||
наполнениеприжаез максимальная длина ввода модели | tokenizer(batch_sentences, padding='max_length') | |
наполнениеприжатезспецифическая длина | tokenizer(batch_sentences, padding='max_length', max_length=42) | |
наполнениеприжатез стоимости кратно | tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8) | |
Усечьприезжать Модель максимальная входная длина | никтонаполнение | tokenizer(batch_sentences, truncation=True)или |
tokenizer(batch_sentences, truncation=STRATEGY) | ||
наполнениеприжатезиз ИЗМАКСИМАЛЬНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ В ПАРТИИдлина | tokenizer(batch_sentences, padding=True, truncation=True) или | |
tokenizer(batch_sentences, padding=True, truncation=STRATEGY) | ||
наполнениеприжаез максимальная длина ввода модели | tokenizer(batch_sentences, padding='max_length', truncation=True) или | |
tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY) | ||
наполнениеприжатезспецифическая длина | невозможный | |
Усечьприезжатьспецифическая длина | Нетнаполнение | tokenizer(batch_sentences, truncation=True, max_length=42) или |
tokenizer(batch_sentences, truncation=STRATEGY, max_length=42) | ||
наполнениеприжатезиз ИЗМАКСИМАЛЬНАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ В ПАРТИИдлина | tokenizer(batch_sentences, padding=True, truncation=True, max_length=42) или | |
tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42) | ||
наполнениеприжаез максимальная длина ввода модели | невозможный | |
наполнениеприжатезспецифическая длина | tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42) или | |
tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42) |
BERTology
оригинальный:
huggingface.co/docs/transformers/v4.37.2/en/bertology
Растет область исследований, связанных с изучением внутренней работы крупногабаритных преобразователей, таких как BERT (некоторые называют это «BERTology»). Вот несколько хороших примеров в этой области:
- BERT Классика заново открыта NLP процесс Автор: Ян Tenney,Dipanjan Das,Ellie Pavlick:
arxiv.org/abs/1905.05950 - шестнадцатьиндивидуальныйголованастоящийиз Сравниватьодининдивидуальныйхороший?? Автор: Пол Michel,Omer Levy,Graham Neubig:
arxiv.org/abs/1905.10650 - BERT Что посмотреть? Автор:Кевин Clark,Urvashi Khandelwal,Omer Levy,Christopher D. Manning:
arxiv.org/abs/1906.04341 - CAT Обнаружение: подход на основе показателей, который объясняет, как упреждающий фокус накодструктура:
arxiv.org/abs/2210.04633
Для того, чтобы помочь развитию этой новой области, мы существуем BERT/GPT/GPT-2 В модель были добавлены некоторые дополнительные функции, помогающие людям получить доступ к внутреннему представлению, в основном из Paul Michel избольшойбольшойработаделатьсерединаприспособлениеиз(arxiv.org/abs/1905.10650):
- доступ BERT/GPT/GPT-2 измногоиметь скрытый статус,
- доступ BERT/GPT/GPT-2 Обратите внимание на вес каждой головки,
- Поискголовавыходценитьиградиент,чтобы вычислить показатель важности заголовка и обрезать заголовок,нравиться
arxiv.org/abs/1905.10650середина Местообъяснятьиз。
чтобы помочь вам понять ииспользовать эти функции,насдобавить в Понятноодининдивидуальныйидентификацияиз Примерступнякнига:bertology.py,такой жечасизвлекатьсуществовать GLUE информация из предварительно обученной модели и сокращена.
Недоумение модели фиксированной длины
оригинальныйтекст:
huggingface.co/docs/transformers/v4.37.2/en/perplexity
Уровень сложности (PPL) — один из наиболее распространенных показателей оценки языков. существования Прежде чем углубиться в обсуждение, следует отметить, что этот показатель особенно применим как к традиционной языковой Модели (иметь дляс регрессивной или причинной языковой Модели), так и к изображению BERT Таким образом, из масок четко определяются язык Модель, показатель и Нет (см. Моделькраткое содержание)。
Недоумение определяется как экспоненциальное среднее отрицательное логарифмическое правдоподобие последовательности. Если у нас есть токенизированная последовательность X=(x0,x1,…,xt)X = (x_0, x_1, \dots, x_t)X=(x0,x1,…,xt), затем XXX из Растерянностьдля,PPL(X)=exp{−1t∑itlogpθ(xi∣x<i)}\text{PPL}(X) = \exp \left{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{<i}) } \right}PPL(X)=exp{−t1i∑tlogpθ(xi∣x<i)}
Чтосерединаlogpθ(xi∣x<i)\log p_\theta (x_i|x_{<i})да Нет. i индивидуальныйотметкасуществоватьнас Модельизранееотметкаx<ix_{<i}из Логарифмпохожий Ран。прямой Наблюдайте за землей,Его можно рассматривать как единообразный прогноз оценки среди указанного набора токенов в корпусе. важное изда,Это означает, что процесс токенизации напрямую влияет на недоумение Моделиизиметь.,Это всегда следует учитывать при сравнении Нет и Модель.
этоттакжеждатьтакой же Вданныеи Модельпредварительнотестмеждуперекрестная энтропиязиндекс。закрывать ВРастерянностьи Чтои Каждыйхарактер Сравнивать特(BPC)и Сжатие данныхиззакрыватьсистемаиз Дажемногопрямой Спать,пожалуйста, проверьтеThe Gradientначальствоизэтот ГлаваОтличный пост в блоге。
Рассчитать PPL, используя модель фиксированной длины
если Наш Нет ограничен размером контекста моделииз,Разложим последовательность регрессивно по существующим и условно оценим недоумение Модельиз на всей предыдущей подпоследовательности на каждом шаге.,Как показано ниже.

Однако,существоватьиспользоватьприблизительный Модельчас,Обычно существует ограничение на количество тегов, которые может обрабатывать Модель. Например,GPT-2 Самая большая версия имеет фиксированную длину. 1024 отметьте, поэтому, когда t больше, чем 1024 , мы не можем напрямую вычислить pθ(xt∣x<t)。
Напротив,Последовательности обычно делятся на подпоследовательности ожидания максимального входного размера. если Модельиз максимального размера ввода для k, то мы проходим только существование до из k-1 Условно использовать маркеры для аппроксимации маркеров xtиз Можетспособныйсекс,вместо всего индивидуального контекста. существуют При оценке запутанности последовательности из Модель,Заманчивый неоптимальный подход к разбиению последовательности на пересекающиеся фрагменты,И независимо сложите разложенные логарифмы правдоподобия каждого отдельного сегмента.
Нетиспользовать полностью доступный контекст из неоптимального PPL
Этот метод быстро рассчитывает,Потому что для каждого отдельного сегмента недоумения можно рассчитать в прямом проходе,но для полностью факторизованного недоумения из индивидуального очень плохого приближения,и обычно приводит к более высокому (ухудшению) PPL, потому что шаг прогнозирования будет иметь меньше контекста.
Напротив,Следует использовать стратегию скользящего окна, оценивать фиксированную длину Модель PPL. Это включает в себя многократное скольжение контекстного окна.,Таким образом, существование Моделиовать делает каждое индивидуальное предсказание более контекстным.
использовать доступный контекст из скользящего окна PPL
Это да является более близким приближением к вероятности последовательности и з истинное разложение и з,и обычно приводит к более благоприятному результату. Недостаток: необходимость для каждого отдельного токена в корпусе выполняется индивидуально из прямого прохода. Практический компромисс – даиспользовать раздвижное окно,Переместить контекст на больший диапазон,каждый раз вместо одной индивидуальнойотметки. Это ускоряет расчеты.,При этом позволяя каждому шагу иметь больший контекст для прогнозирования.
Пример: вычисление недоумения с использованием GPT-2 в 🤗 Transformers
Давайте продемонстрируем этот процесс с помощью GPT-2.
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
device = "cuda"
model_id = "gpt2-large"
model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
tokenizer = GPT2TokenizerFast.from_pretrained(model_id)мы загрузим WikiText-2 набор данных и использовать несколько стратегий Нет и скользящего окна для оценки недоумения. потому что что Этот индивидуальный набор данных небольшой, нам нужно выполнить только одно действие для всего индивидуального набора данных. развпередпередача,поэтому Можетк Волявсеиндивидуальный Загрузка набора данныхикодированиеприезжать Памятьсередина。
from datasets import load_dataset
test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")использовать🤗 Transformers,нас Можеткпросто Воляinput_idsделатьдляlabelsперешел к Мы Модель,Каждая отдельная оценка со средней отрицательной логарифмической вероятностью будет возвращена как потеря. Однако,используйте наш подход с использованием скользящего окна,существования переходит к тегам Модельиз на каждой итерации и сохраняет перекрытие существования. Мы надеемся, что будем рассматривать это только как контекст из метки из логарифма правдоподобия, включая существование в наших потерях.,поэтомунас Можетк Воляэтотнекоторый Цель设набордля-100,к Просто игнорироватьэтоих。к Внизданаснравитьсячтоиспользоватьдлина шагадля512из Пример。этотиметь в видусуществоватьвычислитьлюбойодининдивидуальныйотметкаизсостояние Вероятностьчас,Модель Волякнемногоиметь 512 контекст тега (при условии, что есть 512 предыдущие теги можно использовать в условии).
import torch
from tqdm import tqdm
max_length = model.config.n_positions
stride = 512
seq_len = encodings.input_ids.size(1)
nlls = []
prev_end_loc = 0
for begin_loc in tqdm(range(0, seq_len, stride)):
end_loc = min(begin_loc + max_length, seq_len)
trg_len = end_loc - prev_end_loc # may be different from stride on last loop
input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
target_ids = input_ids.clone()
target_ids[:, :-trg_len] = -100
with torch.no_grad():
outputs = model(input_ids, labels=target_ids)
# loss is calculated using CrossEntropyLoss which averages over valid labels
# N.B. the model only calculates loss over trg_len - 1 labels, because it internally shifts the labels
# to the left by 1.
neg_log_likelihood = outputs.loss
nlls.append(neg_log_likelihood)
prev_end_loc = end_loc
if end_loc == seq_len:
break
ppl = torch.exp(torch.stack(nlls).mean())Выполнение этой операции с установкой размера шага на максимальную входную длину аналогично неоптимальной стратегии нескользящего окна, которую мы обсуждали выше. Чем меньше размер шага,Модельсуществовать Чем больше контекста вы получаете каждый раз, когда делаете прогноз,Сообщать о недоумении, как правило, тоже лучше.
когданасиспользовать stride = 1024,То есть, когда Нет перекрывается,придетсяприезжатьиз Растерянностьдля 19.44,и GPT-2 сообщается в газете 19.93 Разница Нетмного。проходитьиспользовать stride = 512,от И используйте нашу стратегию скользящего окна,этотиндивидуальныйценить降к 16.45。этот Неттолькодаодининдивидуальный Дажеиметьвыгодаиз Фракция,А метод расчета ближе к разложению вероятности последовательности из реальной регрессии.
Использование каналов для вашего веб-сервера
оригинальный:
huggingface.co/docs/transformers/v4.37.2/en/pipeline_webserver
создаватьсделать вывод двигателя из индивидуального комплекса тем, «лучшее» решение, скорее всего, будет зависеть от вашей проблемной области. Ты дасуществовать CPU все еще GPU начальство? Вам нужна минимальная задержка, максимальная пропускная способность, все еще Толькодавысокийоптимизацияодининдивидуальныйидентификация Модель?решатьэтотиндивидуальныйвопросизметодиметьоченьмного,Поэтому для начала мы предоставим индивидуальный товар со значением по умолчанию.,Это может оказаться оптимальным решением.
Ключ из Понимание да,Мы можем использовать индивидуальный итератор,Точно так же, как в картине вашего существования.,потому чтодля Web Сервер — это, по сути, система, которая ожидает запросы и обрабатывает их по порядку.
Обычно Интернет Сервер мультиплексирует (многопоточное, асинхронное ожидание) для обработки различных запросов. С другой стороны, трубопровод (и большинство лежащих в его основе Модель) и Нет действительно подходят для параллельной обработки, они занимают много времени; RAM,Поэтому лучше всего управлять существованием для, которое обеспечивает все доступные ресурсы.,Это трудоемкая вычислительная работа.
Мы сделаем это, позволив веб-серверу обрабатывать получение и отправку запросов при небольшой нагрузке.,ипозволятьодинокий线程иметь дело сдействительныйработаделать Приходитьрешатьэтотиндивидуальныйвопрос。этотиндивидуальный Пример Воляиспользоватьstarlette。действительныйизрамкаи Нетда Очень тяжелыйхотеть,ноеслииспользовать еще один индивидуальный кадр для достижения того же эффекта,Может нуждаться в корректировке или изменении кода.
создаватьserver.py:
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))Сейчас Вы можете начать:
uvicorn server:appВы можете запросить его:
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]Теперь вы уже знаете, как создать запущенный веб-сервер!
Действительно важное изда,нас Толькоодин разЗагрузить модель,поэтомусуществовать Web Копия Нет Моделиз на сервере. Таким образом, Нет будет использовать Нет, необходимый из БАРАН. Затем механизм очередей позволяет вам делать некоторые причудливые вещи, например, возможно, существоватьсделать. вывод ранее накопленных элементов для использования Динамической пакетная обработка:
Следующие примеры кода намеренно написаны в форме псевдокода.,для улучшения читаемости. существование не проверено да означает ли это наличие из системных ресурсов в вашем случае,Не запускайте этот код!
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)Снова,Рекомендуемый код дадля для удобства чтения и оптимизации.,вместодля стал лучшим кодом для. первый,Нет ограничения размера партии,Обычно это хорошая идея. Во-вторых,Таймаут существует сбрасывается каждый раз, когда очередь получает,этотиметь в видуты Можетспособныйнуждатьсяждать Для сравнения 1 на миллисекунды дольше для выполнения вывода (задержка первого запроса).
Лучше установить отдельный дедлайн в 1 миллисекунду.
Это всегда будет ждать 1 мс, даже если очередь пуста, что может быть не лучшим вариантом, поскольку вы можете начать делать выводы, если в очереди ничего нет. Но если пакетная обработка имеет решающее значение для вашего варианта использования, это может иметь смысл. Опять же, не существует одного лучшего решения.
Несколько вещей, которые вы можете рассмотреть
проверка ошибок
Множество проблем может возникнуть при производстве существования: Память Нет Foot、Достаточно места、Загрузить модель может дать сбой, запрос может быть неправильным, запрос может быть правильным что Модель настроена неправильно и не может запуститься, ждемждать.
в целом,если сервер выдает пользователю ошибку,那Что?добавить вмногоtry..exceptзаявление Приходитьпоказыватьэтотнекоторый错误даодининдивидуальныйхорошая идея。нопожалуйста, запомни,В соответствии с вашим контекстом безопасности,Раскрытие этих ошибок также может представлять угрозу безопасности.
Прерывание обработки
когда Web Когда сервер перегружен, обычно лучше Прерывание. обработки. Это означает, что они возвращают соответствующую ошибку при перегрузке и ждут запросы бесконечно долго. существовать Вернуться через очень долгое время 503 Ошибка, или существовать, возвращается через долгое время. 504 ошибка.
Рекомендуется легко реализовать это в коде существования, поскольку дляиметь является единственной очередью. Прежде чем начать возвращать ошибку из базового метода, проверьте размер очереди, дасуществовать сбой веб-сервера под нагрузкой.
Заблокировать основной поток
в настоящий момент PyTorch Нетподдержки асинхронной операции, Заблокировать будет рассчитано, когда основной поток. Это означает, что лучше оставить PyTorch существующий был запущен в потоке/процессе. здесь Нет делает это, потому что код более сложен (в основном потому, что потоки, асинхронность и очереди Нет слишком совместимы). но в конечном итоге он делает то же самое, что и из.
еслиодинокий проект изсделать выводчасмеждуоченьдлинный(> 1 секунд), это будет важно из-за того, что длясуществовать в этом случае, существоватьсделать вывод Каждый запрос в течение периода должен быть обработан ожиданием 1 Чтобы собрать приезжатьошибку, нужны секунды.
Динамическая пакетная обработка
Вообще говоря,Пакетная обработка Нет определенно лучше, чем передача элементов по одному (иметь больше информации на,См. подробности пакетной обработки). носуществовать правильно из среды использования,это Можетспособный Оченьиметьэффект。существовать API , по умолчанию Нет Динамическая пакетная обработка (слишком легкая, чтобы вызвать замедление). нофор BLOOM сделать вывод - Это очень большая модель - Динамическая пакетная обработкадаЭто важноиз,Чтобы дать каждому человеку хороший опыт.
модель обучения анатомии
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/model_memory_anatomy
Поймите, что вы можете применить технологию оптимизации производительности для увеличения моделитренироваться скорости iПа. мятьиспользовать эффективность, иметь возможность ознакомиться с периодом существованиятренироваться GPU изиспользовать ситуации, а также изменения интенсивности вычислений на основе выполнения операций.
Сначала с изучением скорости использования графического процессора имодельтренироваться. Для начала запустите индивидуальный пример стимула. для демо-версии мы нуждаемся в установке некоторых библиотек:
pip install transformers datasets accelerate nvidia-ml-py3nvidia-ml-py3Библиотекапозволятьнасот Python внутренний监Видеть Модельиз Памятьиспользовать Состояние。ты Можетспособный Конец знакомстваконецсерединаизnvidia-smiЗаказ-этотиндивидуальный Библиотекапозволятьпрямойловитьсуществовать Python получить доступ к той же информации.
Затем мы создаем фиктивные данные: 100 приезжать 30000 случайная отметка между ID и для классификатора из двоичных меток. В общей сложности мы получили возможность приезжать. 512 длина 512 из последовательностей и хранить их существуют PyTorch ФорматизDatasetсередина。
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 1, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")для печати GPUиспользовать ставку ииспользовать Трейнер для тренироватьсяизкраткое Содержание статистической информации определим две вспомогательные функции:
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()Давайте проверим, что мы начинаем со свободной памятью графического процессора:
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.Выглядит хорошо: графический процессор Память Нет занят, как и следовало ожидать перед загрузкой любой Модели. если существует такая ситуация на вашем компьютере, пожалуйста, прекратите использовать GPU память для всех процессов. Однако не все бесплатно GPU Память Все Можеткодеялоиспользоватьсемьяиспользовать。когда Модельнагрузкаприезжать GPU , ядро также будет загружено, что может занять 1-2GB из Память.для Чтобы увидеть, сколько Память занято, мы загрузим индивидуальный крошечный тензор в приезжать GPU , это вызовет загрузку ядра.
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.нассмотретьприезжать Внутриядерныйзанимать в одиночкуиспользовать Понятно 1.3GB из GPU Память.Сейчас Давайте посмотрим Модельиспользовать Понятномногоменьше места。
Загрузить модель
первый,наснагрузкаbert-large-uncasedМодель。наспрямойловить Воля Модельмассанагрузкаприезжать GPU, чтобы мы могли проверить, сколько места занимают только веса.
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.нас Вы можете посмотреть приезжать Модельмассазанимать в одиночкуиспользовать Понятно 1.3GB из GPU Память.Точное количество зависит от конкретного использования. GPU。пожалуйста, обрати внимание,существовать Новееиз GPU начальство,Может занимать больше места, если Модельиметь,Потому что вес загружается в оптимизацию,Ускорено Модельизиспользоватьскорость。Сейчаснасвозвращаться Можеткбыстрыйисследоватьданетиnvidia-smi CLI Получите те же результаты, что и приезжать:
nvidia-smiTue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+Мы получили то же количество, что и раньше.,тывозвращаться Вы можете посмотреть приезжатьнастолькосуществоватьиспользоватьодинкусок Инструментиметь 16GB Памятьиз V100 графический процессор. Сейчас Можно начать тренироваться Модель и просмотреть GPU Памятьпотреблятьизизменять。первый,Задаем несколько стандартных параметров итренироваться:
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}если вы планируете провести несколько экспериментов,для существования Правильно очистить Память между экспериментами,Пожалуйста, перезапускайте Python между экспериментами.
Использование памяти при обычных тренировках
позволятьнасиспользовать Trainer исуществовать Нетиспользоватьлюбой GPU Оптимизация производительности Технология из модели тренирования, Размер партии для 4:
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.Мы видим, как добраться, даже несмотря на то, что отдельные относительно меньшие размеры партий почти заполняют нас. GPU Однако больший размер партии обычно приводит к более быстрой сходимости модели и улучшению конечной производительности. Итак, в идеале мы хотели бы основывать наши потребности на модели спроса, а не на модели спроса. GPU изпредел Приходитьнастраиватьвсепартияколичествобольшой Маленький。иметьинтересизда,Наше использование Память намного больше, чем размер Модели. для того, чтобы лучше понять, что произойдет,Давайте рассмотрим требования к работе «Модельиз» и «Память».
анатомия манипулирования моделью
Transformers Архитектура включает в себя 3 индивидуальная Основная из групп операций, сгруппированных по интенсивности расчета следующим образом.
- Тензорное сокращение линейный слойимногоголовавнимательность Группа件ВсеруководитьпартияколичествоУмножение матрицы-матрицы。этотнекоторый Держатьделатьдатренироваться transformer Самая вычислительно интенсивная часть.
- статистическая нормализация Softmax Нормализация слояиз Плотность вычислений ниже, чем Тензорное сокращение,и涉иодининдивидуальныйилимногоиндивидуальныйСокращение операций,Результаты затем применяются посредством картирования.
- поэлементный оператор этотнекоторыйда Оставшийсяизоператор:предвзятость、выбросить、Активация и остаточное соединение。этотнекоторыйда Наименее вычислительно интенсивныйиз Держатьделать。
этотнекоторый知识существовать分析сексспособныйузкое месточас Можетспособныйвстречаиметь Местопомощь。
этотиндивидуальный Подвести итог Приходитьисточник ВПеремещение данных – это все, что вам нужно: оптимизация Transformer из Кейс-стади 2020
Анатомия модельной памяти
Мы видели приезжать,тренироваться Модельиспользоватьиз Память Сравниватьтолько Воля Модельпомещатьсуществовать GPU Гораздо больше. В этот период необходимо использовать множество компонентов. GPU Память.существовать GPU Компоненты Памятьсерединаиз включают в себя следующее:
- Модельмасса
- Статус оптимизатора
- градиент
- дляградиент рассчитать сохранить изактивация пересылки
- временный буфер
- Специальная функция из Память
использовать AdamW руководитьсмешанная точностьтренироватьсяизтипичный Модель Каждыйиндивидуальный Модельпараметрнуждаться 18 Байт плюс активация Память.Для сделать вывод,Нет Статус оптимизатораградиент, поэтому мы можем их вычесть. Поэтому для смешанной точности сделайте вывод,Каждыйиндивидуальный Модельпараметрнуждаться 6 байт плюс активная память.
Давайте посмотрим на детали.
Вес модели:
- Каждыйиндивидуальныйпараметриз 4 Байты для fp32 тренироваться
- Каждыйиндивидуальныйпараметриз 6 Байты длясмешанная точностьтренироваться(существовать Памятьсерединаподдерживатьодининдивидуальный fp32 Модельиодининдивидуальный fp16 Модель)
Статус оптимизатора:
- Каждыйиндивидуальныйпараметриз 8 Байты дляобычноиз Адам В (техническое обслуживание 2 индивидуальныйсостояние)
- Каждыйиндивидуальныйпараметриз 8 Кусочек AdamW Оптимизатор требует 2 байт,Напримерbitsandbytes
- Каждыйиндивидуальныйпараметриз 4 Байты длякартинаприноситьиметьимпульсиз SGD Такая изоптимизация (только обслуживание 1 индивидуальныйсостояние)
градиент
- Каждыйиндивидуальныйпараметриз 4 Байты для fp32 илисмешанная точностьтренироваться(градиентвсегда Держатьсуществовать fp32 середина)
активация пересылки
- Размер зависит от многих факторов, ключевыми факторами являются длина последовательности, скрытый размер и размер партии.
здесьиметь проход через функцию вперед и назад и возврат из ввода ивыход,кидляградиент рассчитать сохранить изактивация пересылки。
временная память
также,Также различные временные переменные,Заканчивать будет выпущено после расчета,В какой-то момент эти переменные могут вызвать OOM. поэтому,существоватькодированиечас,Крайне важно стратегически подумать об этих временных переменных и явно освободить эти переменные при их очистке.
Специальная функция из Память
Затем,К вашему программному обеспечению могут предъявляться особые требования. Например,использовать поиск по лучу при генерации текста,Программное обеспечение нуждаться поддерживает несколько копий индивидуального ввода ивыходиз.
вперединазад执ХОРОШОскорость
Для сверточных и линейных слоев,èПрямое сравнение,назадсерединаиз flops давпередиз 2 раз, что обычно приводит к примерно 2 раз из медленнее (больше, когда есть, потому что размер часто более неудобен, если смотреть назад в середине из). Активация обычно ограничена полосой пропускания, активация обычно считывает больше данных в обратном направлении, чем в прямом (например, активация прямого чтения один раз,писатьодин раз, дважды активировать обратное чтение, gradOutput и вперед выход, затем напиши один раз,gradInput)。
Как видите, приезжая, у нас есть места, которые мы можем сэкономить. GPU Памятьили ускорить операции. Сейчас Вы уже знаете, какое влияние это оказывает GPU использовать коэффициент и скорость расчета из коэффициентов, см. одинокий GPU Узнайте о методах оптимизации производительности на странице документации «Эффективные методы и инструменты тренироваться».
Оптимизация LLM по скорости и памяти
Исходная ссылка:
huggingface.co/docs/transformers/v4.37.2/en/llm_tutorial_optimization
Такой как GPT3/4、FalconиLlamaждать Большойязык Модель(LLMs)толькосуществоватьбыстрое развитие,Умение обращаться с людьми для центра и з Задача,В современных наукоемких отраслях отсутствует множество инструментов. Однако,существуют. Внедрение этих Моделей в реальную жизнь остается сложной задачей:
- Для того, чтобы продемонстрировать возможности понимания и генерации текста, близкие к человеческому, в настоящий момент LLMs нуждаться Зависит отчисло十100 миллионовпараметр Группастановиться(ВидетьKaplan ждатьлюди,Wei ждатьлюди)。этот Входитьодиншаг увеличения Понятносделать выводиз Памятьнуждаться。
- существуют Многие реальный мир из Задача, LLM нуждаться предоставляет обширную контекстную информацию. Для этого необходимо существование Модельовсделать Процесс вывода способен обрабатывать очень длинные входные последовательности.
Эти проблемы являются ключом к повышению LLMs Вычислительные возможности, особенно при обработке огромных входных последовательностей.
В этом руководстве мы будем эффективно занимать должность LLM Внедрение эффективных технологий:
- **низкая точность: **Исследования показали, что для снижения числовой точности, т.е. 8 Кусочеки 4 Кусочек может существовать Нет достичь вычислительных преимуществ без значительного снижения производительности модели.
- **Внимательность вспышки: **Алгоритм внимательности вспышки из варианта А, Нет обеспечивает только более экономичный метод Памяти, в том числе за счет оптимизации GPU Уровень Памятьиспользовать достигнут повышением эффективности.
- **Архитектураинновации:**учитыватьприезжать LLMs существоватьсделать Процесс вывода всегда развертывается одинаково, т.е. с длинным входным контекстом без генерации возврата текста, был предложен специально из Модель Архитектура, что позволяет более эффективно изделать вывод。существовать Модель Архитектурааспектбольшинство ТяжелыйхотетьизпрогрессдаAlibi、Rotary embeddings、Внимание к множественным запросам (MQA)иВнимание к групповым запросам (GQA)。
В этом руководстве мы анализируем тензор от угла до генерации регрессии. Мы глубоко погружаемся в процесс принятия решений Изучите плюсы и минусы точности, полностью изучите новейший алгоритм наблюдения и обсудите улучшения. LLM Архитектура. В этой процедуре мы запускаем практические примеры, чтобы продемонстрировать улучшение каждой отдельной функциональности.
1. Низкая точность
добавив LLM Просмотрите набор векторов весовой матрицы, введите текст в представление для серии векторов, чтобы вы могли лучше понять LLMs из Памятьнуждаться。существовать Следующийиз Внутри Позволятьсередина,определениемассаВоляиспользуется длявыражать Местоиметь Модельмассаматрицаивектор。
На момент написания данного руководства существовало,LLM содержат как минимум миллиарды параметров. поэтому,Каждый параметр состоит из десятичного числа.,Например4.5689,в целомкfloat32、bfloat16илиfloat16Форматжитьмагазин。этотделатьнасспособный Достаточно легковычислитьнагрузка LLM приезжать Память Местонуждатьсяиз Памятьколичество:
Загрузка имеет X Миллиард параметров из Моделиз весов Онуждаться 4X GB из VRAM, точность float32*
Сейчас Модель редко появляется в полном составе. float32 обучение с точностью и обычно с bfloat16 Точность или меньше из float16 обучение с точностью. Таким образом, эмпирическое правило становится следующим:
Загрузка имеет X Миллиард параметров из Моделиз весов Онуждаться 2X GB из VRAM, точность bfloat16/float16*
Для более короткого ввода текста (менее 1024 индивидуальная отметка), в обосновании требований из Память в основном преобладает вес груза из Память требований. Поэтому теперь давайте предположим, что рассуждение из Память требует ожидания основано на загрузке Модели в приезжать. GPU VRAM из Память спроса.
Пример того, сколько видеопамяти требуется для загрузки модели bfloat16:
- Для GPT3 требуется 2 * 175 ГБ = 350 ГБ видеопамяти.
- Bloom нуждаться 2 * 176 GB = 352 GB VRAM
- Llama-2-70b нуждаться 2 * 70 GB = 140 GB VRAM
- Falcon-40b нуждаться 2 * 40 GB = 80 GB VRAM
- MPT-30b нуждаться 2 * 30 GB = 60 GB VRAM
- bigcode/starcoder нуждаться 2 * 15.5 = 31 GB VRAM
На момент написания статьи самый крупный из имеющихся на рынке GPU Чип A100 & H100, при условии 80GB из Видеопамять. В списке ранее избольшинство Модельнуждаться более чем 80GB из Памятьталантспособныйнагрузка,поэтомудолжен Раннуждатьсяоткрытьколичествои ХОРОШОиметь дело си/илитрубопроводи ХОРОШОиметь дело с。
🤗 Трансформаторы Нетподдержка тензорной параллельной обработки,Потому что для этого требуется, чтобы Модель Архитектуры была написана определенным образом. если вы заинтересованы в написании модели в тензорно-параллельном режиме,Пожалуйста, следуйтечас Проверятьтекст генерации рассуждение Библиотека。
Наивный изтрубопровод параллельной обработки да из коробки. для этого просто используйте device="auto" Загрузить модели, он автоматически поместит Нет на тот же слой, который существует в наличии GPU как описано здесь. пожалуйста, обрати внимание, хотя очень надо, но этот наивный изтрубопровод параллельной обработки не решает GPU праздныйизвопрос。дляэтот,нуждаться в более совершенном изтрубопроводе параллельной обработки,Как описано здесь.
Если у вас есть доступ к узлу A100 8 x 80 ГБ, вы можете загрузить BLOOM следующим образом.
!pip install transformers accelerate bitsandbytes optimumfrom transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)проходитьиспользовать device_map="auto",внимательностьслой Воля Униформараспределенныйсуществовать Местоиметь Можетиспользоватьиз GPU начальство.
существоватькнигагидсередина,нас Воляиспользоватьbigcode/octocoder,потому чтодляэто Можетксуществоватьодинокий 40 GB A100 GPU работает на чипе устройства. пожалуйста, обрати Обратите внимание, мы собираемся применить оптимизацию скорости из Памятьи, которые в равной степени применимы к нуждающимся. Моделиили тензорную параллельную обработку из Модели.
потому что Модель с bfloat16 Точность загрузки, исходя из нашего эмпирического правила, приведенного выше, мы ожидаем использовать bigcode/octocoder Бегущие рассуждения из Память требования о 31 GB Видеопамять. Давайте попробуем.
наспервый Загрузить токенизатор модели, а затем передать оба в Transformers изтрубопроводобъект。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultвыход:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```py\n\nThis function takes a singleЧто ж, мы в Сейчас можем конвертировать байты в гигабайты напрямую, используя результаты.
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024позволятьнаснастраиватьиспользоватьtorch.cuda.max_memory_allocatedПриходитьтестколичество GPU Память выделения из пика.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())выход:
29.0260648727417ловить近насгрубыйвычислитьизрезультат!нас Вы можете посмотреть приезжатьчисло字и Нетнад全толькоправильный,потому чтодляотбайтприезжатьтысячабайтнуждатьсябратьк 1024 вместо 1000. Поэтому формулу грубого расчета можно понимать и как «не более XGB”извычислить。пожалуйста, обрати внимание,если мы постараемся завершить из float32 Для точного запуска модели потребуется 64GB из VRAM。
Почти все дасуществовать bfloat16 серединатренироватьсяиз,еслитыиз GPU поддерживать bfloat16,Сразу Нетпричина Зависит откнадвсеиз float32 Запустите модель с точностью. Плавающее32 Нет обеспечит лучшую точность, чем тренироваться Моделизизсделать выводрезультат。
Если вы Нет определяете, в каком формате хранятся веса моделисуществовать Hub начальство,Вы можете просмотреть конфигурацию контрольной точки в любое время,существовать"torch_dtype"Вниз,Напримерздесь。предположениесуществоватьиспользоватьfrom_pretrained(..., torch_dtype=...)Загрузить модель будет установлена в конфигурацию дляи при записи с тем же типом точности, если только не исходный тип для float32, в это время ты можешь существоватьсделать выводсерединаиспользоватьfloat16илиbfloat16。
позволятьнасопределениеодининдивидуальныйflush(...)函число Приходитьвыпускатьпомещать Местоиметьраспространятьиз Память,Чтобы мы могли точно измерить выделение пиковой памяти графического процессора.
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()Сейчас Давайте для следующего индивидуального эксперимента назовем это.
flush()существует Последняя версия библиотеки ускорения в,тывозвращаться Можеткиспользоватьодининдивидуальныйимядляrelease_memory()из Реальностьиспользоватьметод
from accelerate.utils import release_memory
# ...
release_memory(model)Так что если вы из GPU Нет 32GB из VRAM что делать? Было обнаружено, что веса модели можно выразить количественно как 8 Кусочекили 4 Кусочеки Нетвстреча显著降低сексспособный(ВидетьDettmers ждатьлюди)。тольконравитьсянедавноизДокумент GPTQМесто Показывать,Модель Можетк Количественная оценкадля 3 Кусочекили 2 Кусочек, потеря производительности да допустима из🤯.
Нет вдаваться в подробности,Количественная Схема оценки направлена на уменьшение веса и точности при сохранении максимально возможной точности. вывести результат по точности (т.е. максимально приближенный bfloat16)。пожалуйста, обрати внимание,Количественная оценкасуществоватьгенерация текстааспектособенныйиметьэффект,потому чтодлянас Толькозакрывать СердцевыбиратьСкорее всего изNext индивидуальный набор тегов,и Нетнастоящийтолькозакрывать Сердце Внизодининдивидуальныйотметкаlogitраспределенныйизправильный切ценить。Тяжелыйхотетьизда Внизодининдивидуальныйотметкаlogitраспределенный Держатьбольшой致Взаимнотакой же,кудобныйargmaxилиtopkДержатьделать Давать出Взаимнотакой жеизрезультат。
иметь Различный Количественная Технология оценки, мы здесь Нет обсудим подробно, но в целом все есть Количественная Оценочная технология работает следующим образом:
-
- Воля Местоиметьмасса Количественная оценкадля целевой точности
-
- нагрузка Количественная оценкаиз весов, и с bfloat16 Входная последовательность точного переноса из вектора
-
- Динамически переносить веса в Количественную оценкадля bfloat16, с bfloat16 Выполняйте расчеты с точностью
суммируя,этотиметь в видувходить-массаматрицаумножение,ЧтосерединаX X X давходить,W W W — весовая матрица, Y Y Y да Выход:Y=X∗W Y = X * W Y=X∗W
заменяется на Y=X∗dequantize(W) Y = X * \text{dequantize}(W) Y=X∗dequantize(W)
верно ВКаждыйиндивидуальныйматрицаумножение。когдавходитьпроходитьсетькартиначас,массаматрицаизпротивоположный Количественная оценкаиснова Количественная Оценкадада выполнить в порядке из.
поэтому,когдаиспользовать Количественная оценкамассачас,рассуждениечасмеждув целомНетвстречауменьшать,И да увеличивается. достаточно теории,Давайте попробуем! Чтобы сипользовать Трансформаторы Количественная оценка веса,тынуждаться Убедитесь, что он установленbitsandbytesБиблиотека。
!pip install bitsandbytesЗатем,нас Можеткпроходитьпростосуществоватьfrom_pretrainedсерединадобавить вload_in_8bit=Trueлоготип Приходитьнагрузка 8 Кусочек Количественная оценкаиз Модель。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)Теперь давайте снова запустим наш пример и измерим ситуацию с пользованием Памятьисом.
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultвыход:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```py\n\nThis function takes a singleочень хороший,Мы получили тот же результат, что и раньше,поэтомусуществовать准правильныйсексначальство Нетпотеря!Давайте посмотримэтот Второсортныйиспользовать Понятномногонемного Память.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())выход:
15.219234466552734Значительное снижение! Нам осталось чуть больше 15 ГБ, поэтому может существоватькартина 4090 Этот вид потребительского класса GPU начальство运ХОРОШОэтот Модель。нассуществовать Памятьэффективностьначальствополучатьпридется Понятно Оченьхорошийиздоход,Почти Нет против Модельвыходиз понижен в рейтинге. нода,Также можно отметить, что прибытие немного замедляется в процессе рассуждения.
Удаляем модель и снова очищаем память.
del model
del pipeflush()Давайте посмотрим 4 битовая пара квантования GPU Памятьпотреблятьизпикценить。Воля Модель Количественная оценкадля 4 Кусочек может быть таким же, как и раньше, из API Заканчивать - этот Второсортныйдапроходитьпередачаload_in_4bit=Trueвместоload_in_8bit=TrueПриходить Заканчивать。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
resultвыход:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```py\n\nThis function takes a single argumentнас Несколько乎смотретьприезжатьи Извперед Взаимнотакой жеизвыходтекст - Толькодасуществоватькод片часть Извперед缺немного Понятноpython。Давайте посмотримнуждатьсямногонемного Память.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())выход:
9.543574333190918всего 9,5 ГБ! более 1,5 миллиардов параметров, это очень много.
Пока мы существуем, посмотрим на приезжать Модель, точность почти Нет упала,но на самом деле,4 Кусочек Количественная оценка обычно приводит к и 8 Кусочек Количественная оценкаилинадвсеизbfloat16рассуждения по сравнению с производством Неттакой жеизрезультат。этот Зависит от Виспользоватьсемьяданетпытаться。
Также обратите внимание, что и 8 Кусочек Количественная По сравнению с оценками здесьиз снова немного медленнее по скорости вывода, что связано с 4 Кусочек Количественная оценкаиспользовать Понятно Даже激Входитьиз Количественная оценкаметод,привести ксуществоватьрассуждениепроцесссередина Количественная оценкаипротивоположный Количественная Процесс открытия зависит от времени.
del model
del pipeflush()Вообще говоря, мы говорим Сейчас 8 Работайте с битовой точностью OctoCoder Поместите то, что вам нужно GPU VRAM от 32G GPU VRAM Сократить приезжать только 15GB,иисуществовать 4 Работайте с битовой точностью Модель Входитьодиншаг Поместите то, что вам нужно GPU VRAM Снизить приезжать немного выше 9GB。
4 Кусочек Количественная оценка позволяет модели работать на существующих графических процессорах RTX3090, V100 и T4 с ожиданием, которые очень легко получить для большинства людей.
иметьзакрывать Количественная Оценкаиз Дополнительная информация и как конвертировать Модель Количественная оценить, чтобы сравнить 4 Кусочекменьшеземляиспользовать GPU VRAM Память,наспредположение ПроверятьAutoGPTQвыполнить。
Наконец, важно помнить, что Модель Количественная Существует компромисс между эффективностью и точностью, а в некоторых случаях увеличивается время вывода.
если GPU Коллировать музыкальную музыку Недна размещение, обычно Нетуждаться на стене оценка。нодамного GPU Не могущийсуществовать Нет Количественная метод оценки на основе рассмотрения дела LLM, существуют в данном случае, 4 Кусочеки 8 Кусочек Количественная Программа оценки имеет множество инструментов.
иметь Более подробную информацию изиспользовать,нассильныйпредположение ПроверятьДокументация по количественному определению трансформаторов。Следующий,Давайте Посмотрим, как повысить эффективность вычислений и повысить эффективность за счет использования лучших алгоритмов и улучшения Модели Архитектуры.
2. Вспышка внимания
Лучшее выступление сегодня LLMs базовыйначальствообщий Взаимнотакой жеизбазовый Архитектура,Включая слой прямой связи, уровень активации, слой нормализации слоя.,И самый критический слой извнимательности.
Уровень внимательности имеет решающее значение для Большой Языковой Модели (LLM).,Потому что они позволяют Модели понимать контекстуальные отношения между входными токенами. Однако,свнимательностьслойизпикценить GPU Памятьпотреблятьвместе свходитьотметкаколичество(такжесказатьдлядлина последовательности)изувеличиться на два Второсортныйувеличивать,нассуществовать ВнизискусствосерединаиспользоватьN N N выражать. Хотя для более коротких из входных последовательностей (до 1000 индивидуальный входной тег) Это не очевидно, но для более длинных входных последовательностей (О 16000 входные теги) становится серьезной проблемой.
Давайте посмотрим поближе. Рассчитать свнимательность слоя для длины N N N из Введите X \mathbf{X} X извыходO \mathbf{O} O изчиновникда:O=Attn(X)=V×Softmax(QKT) with Q=WqX,V=WvX,K=WkX \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} O=Attn(X)=V×Softmax(QKT) with Q=WqX,V=WvX,K=WkX X=(x1,...xN) \mathbf{X} = (\mathbf{x}1, … \mathbf{x}{N}) X=(x1,…xN) глубокая внимательность слоя из входной последовательности. Проекция Q \mathbf{Q} Q иK \mathbf{K} K будет содержать N соответственно N N векторы, ведущие к QKT \mathbf{QK}^T QKT из размерадляN2 N² N2 。
LLMs Обычно имеет несколько заголовков индивидуальной внимательности, поэтому несколько отдельных с внимательностью могут выполняться параллельно. гипотеза LLM иметь 40 внимание и с bfloat16 Точность работает, мы можем вычислить сохраненный QKT \mathbf{QK^T} QKT требуется матрица Памятьдля40*2*N2 40 * 2 * N² 40∗2∗N2 байт. Для N=1000 N=1000 N=1000, всего около 50MB из VRAM, однако, для N=16000 N=16000 N=16000, нам понадобится 19GB из VRAM, а для N=100 000 N=100,000 N=100 000, нам понадобится около 1TB из VRAM хранить QKT \mathbf{QK}^T QKT матрица.
короче говоря,Для входного контекста Большой,Алгоритм извлечённости по умолчанию быстро стал слишком дорогим.
вместе с LLMs существуют аспекты понимания и генерации текста и улучшаются, они применяются ко все более сложным и з Задачам. Хотя Модель когда-то имела дело, несколько предложений изперевели Подвести итоги,Сейчасэтоих Можеткиметь дело свсе Страницаиз Внутри Позволять,нуждатьсяиметь дело сширокоизвходитьдлина。
наснравитьсячтоизбавляться от Большойвходитьдлинаизслишком высокий Памятьнуждаться?наснуждатьсяодиндобрыйновыйиз Способ Приходитьвычислитьсвнимательностьмеханизм,Избавьтесь от QKT QK^T QKT матрица.Tri Dao ждатьлюдиоткрыть发Понятноодиндобрый全новыйизалгоритм,сказать ИздляFlash Attention。
Короче говоря, Флэш. Attention Изменить V×Softmax(QKT\mathbf{V} \times \text{Softmax}(\mathbf{QK}^TV×Softmax(QKT) рассчитывается отдельно, но путем итерации по нескольким softmax Шаги расчета для расчета выходных блоков меньшего размера: Oi ←sija*Oi+sijb*Vj×Softmax(QKi,jT) for multiple i,j iterations \textbf{O}i \leftarrow s^a{ij} * \textbf{O}i + s^b{ij} * \mathbf{V}{j} \times \text{Softmax}(\mathbf{QK}^T{i,j}) \text{ for multiple } i, j \text{ iterations} Oi←sija∗Oi+sijb∗Vj×Softmax(QKi,jT) for multiple i,j iterations
Среди них сия s^a_{ij}иsijb s^b_{ij} — некоторая потребность для каждого i iиj jперерасчетиз softmax Нормализованная статистика.
Обратите внимание, что весь Flash Attention быть немного сложным,существование здесь значительно упрощено,потому чтодля Углубленное обсуждение за пределами Понятнокнигагидизобъем。читать ВОЗМожетк Проверять Писатьпридетсяочень хорошийизФлэш-Внимание Бумагакполучать Дажемногоподробныйинформация。
здесьиз Основные моменты да:
отслеживая softmax Нормализованная статистика и немного умной математики, Flash Attention данныйипо умолчаниюсвнимательностьслойЗначения те жеизвыход,и Памятьстановитьсякнигатолько СледоватьN N увеличивается линейно.
глядя на формулу, люди интуитивно говорят Flash Attention Должно быть намного медленнее, чем формула проверки внимательности по умолчанию, поскольку длянуждаться выполняет больше вычислений. На самом деле, по сравнению с обычной внимательностью, Flash Attention нуждаться Больше из-за провала, потому что softmax Нормализованную статистику надо пересчитывать (если интересно,Видетьбумагаполучать Дажемногоподробныйинформация)
Однако по умолчанию внимательность по сравнению с Flash. Attention существования гораздо быстрее по скорости вывода, потому что для этого можно значительно сократить количество Графические процессоры (VRAM) предъявляют более медленные требования к высокой пропускной способности, тогда как SRAM ориентирован на более быстрые встроенные графические процессоры (SRAM).
В основном Флэш Attention правильный Сохранять Местоиметьсерединамеждуписатьичитать取Держатьделать Все Можеткиспользоватьбыстрыйизна чипеSRAM Память Приходить Заканчивать,иниктонуждатьсядоступпомедленнееиз VRAM память для вычисления выходного вектора O \mathbf{O}。
Собственно, если имеется, в настоящий момент Абсолютноверно Нетпричина Зависит отНетиспользовать Flash Attention。Долженалгоритмсуществоватьчисло学начальство Давать出Взаимнотакой жеизвыход,и быстрее,Память эффективнее.
Давайте посмотрим на практический пример индивидуального.
Мы OctoCoder Модель Сейчаспридетсяприезжать Понятноодининдивидуальныйочевидныйдольшеизвходитьнамекать,Чтосерединавключать МестопредикатизСистемная подсказка。Системная подсказкаиспользуется длягид LLM Станьте лучшим помощником для индивидуального пользователя, специально настроенным для пользователей из Задача. Далее мы воспользуемся индивидуальными системными подсказками, которые сделают OctoCoder Into для индивидуального лучшего помощника по программированию.
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""для демо-проекта,Нам будет предложено копировать десять раз,чтобы длина ввода была достаточно длинной,кнаблюдать Flash Attention из Памятьсохранять。насдополнительныйоригинальныйтекстнамекать«Вопрос: Пожалуйста, используйте Python Напишите отдельную функцию, которая преобразует байты в гигабайты. \п\п Отвечать:существоватьздесь"
long_prompt = 10 * system_prompt + promptМы снова bfloat16 точное создание экземпляра Мы Модель。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)Сейчаспозволятьнаскартина Извпередодин Образец运ХОРОШОМодельНетиспользовать Flash Attention,итестколичество GPU Память спроса из пикового времени и времени вывода.
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
resultвыход:
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndefМы получили возможность приезжать и то же, что и раньше, извыход, но это один раз, Модель повторит ответ несколько раз, пока не достигнет «приехать». 60 индивидуальныйотметкаиз Крайний срок。этоти Нетстранность,Потому что наш демо-проект повторил системное приглашение десять раз.,от и подскажите Модель повторить было.
пожалуйста, обрати внимание,существуют в практическом применении,Системная подсказка Нетотвечать Тяжелый复十Второсортный-один раз достаточно!
давайте измерим GPU Памятьнуждатьсяизпикценить。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())выход:
37.668193340301514Как мы видим, пик доступностииз GPU Память спрос сейчас значительно выше, чем в начале, которое существует во многом дапотому чтодольшеизвходитьпоследовательность。также,Создание Сейчаснуждаться занимает чуть больше минуты.
наснастраиватьиспользоватьflush()Приходитьвыпускатьпомещать GPU память для следующего эксперимента.
flush()для сравнения,Давайте запустим то же самое из функции,но Включите Flash Attention. для этого,нас Воля Модель КонвертироватьдляBetterTransformer,отиначинатьиспользовать PyTorch изSDPA свнимательность,И тогда сможете использовать Flash Attention.
model.to_bettertransformer()Сейчас мы запускаем тот же фрагмент кода, что и раньше, существующие базовые преобразователи будут использовать Flash Attention.
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
resultвыход:
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndefМы получаем точно такие же результаты, как и раньше, а с помощью Flash Attention мы можем наблюдать очень значительное ускорение.
Давайте в последний раз измерим потребление памяти.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())выход:
32.617331981658936Мы почти вернулись к исходному состоянию, когда пиковая память графического процессора составляла 29 ГБ.
Мы можем наблюдать приезжать,è Первоначально передайте короткую входную последовательность по сравнению с,использовать Flash Attention При передаче очень длинной входной последовательности мы получаем только больше 100MB из GPU Память.
flush()иметь О том, как использовать Flash Внимание из Подробнее,пожалуйста, проверьтеэта страница документации。
3. Архитектурные инновации
приезжая в настоящий момент, мы изучили повышение эффективности вычислений за счет:
- Преобразование весов в формат более низкой точности
- Замените алгоритм внимательности на более ресурсоэффективную версию.
Сейчас Давайте Как посмотрим, изменилось LLM из Архитектура, что делает его наиболее эффективным и действенным для нуждаться в длинном вводе текста из Задача, например:
- Улучшение поиска Вопросы и ответы,
- Подвести итоги,
- чат
пожалуйста, обрати внимание,chatНеттолькохотетьпросить LLM Обработка длинного ввода текста также требует LLM Уметь эффективно обрабатывать двусторонние разговоры между пользователями и помощниками (например, ChatGPT)。
одинрассветтренироваться Заканчивать,базовыйиз LLM Архитектуру сложно изменить, поэтому подумайте об этом заранее. LLM Из Задача и соответственно оптимизация Модели Архитектура очень важна. Архитектура модели, состоящая из двух отдельных важных компонентов, быстро стала узким местом для Большой входной последовательности из Памяти/или производительности.
- Кусочеквставлять
- кэш значений ключей
Давайте обсудим каждый компонент более подробно
3.1 Улучшите встраивание местоположения в LLM
свнимательность Воля Каждыйиндивидуальныйотметкаидругойотметка Взаимнозакрыватьсвязь。Например,текствходитьпоследовательностьиз Матрица Softmax(QKT)*"Привет", “I”, “love”, «ты»* может выглядеть так:
Каждому отдельному словесному токену присваивается индивидуальная вероятностная масса.,Используется для фокусировки на названии других словесных тегов.,Поэтому иметь связано с другими словесными маркерами. Например,слово*“love”сосредоточиться наслово“Hello”из Вероятностьдля 5%,сосредоточиться на“I”*из Вероятностьдля 30%,стелоиз Вероятностьдля 65%。
На основании внимательноиз LLM, встраивание размещения но Нет Кусочек, будет иметь большие трудности с пониманием размещения между текстовыми вводами. Это да для QKT \mathbf{QK}^T QKT Вычислить оценку вероятности для каждого отдельного словесного токена и другого существующего словесного токенаO(1) O(1) O(1) При расчете корреляций учитывается расстояние между ними. Поэтому для размещения Нет Кусочек из LLM, каждый индивидуальный жетон имеет другие жетоны с таким же расстоянием, например, чтобы отличить «Привет». Я люблю тебя» и «Ты любишь меня Привет» будет очень сложной задачей.
чтобы позволить LLM Понимание порядка предложений,нуждатьсядополнительныйизнамекать,в целомкКодировка местоположения Кусочек(такжесказатьдляКусочеквставлять)изформаотвечатьиспользовать。Кодировка местоположения Кусочек Воля Каждыйиндивидуальныйотметкаиз Кодировка местоположения Кусочекдля LLM Может быть представлено в числовом виде, чтобы лучше понять порядок предложений.
внимательностьмеханизм Сразудаты Местонуждатьсяизбумагаизделать ВОЗихпредставлять Понятнотольконить КусочеквставлятьP=p1,…,pN \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N P=p1,…,pN . где каждый вектор пи \mathbf{p}_i pi основано на его положении i i i Вычислите функцию синуса. Затем позиционное кодирование Кусочка просто добавляется путём прибытия к вектору входной последовательности X^=x^1,…,x^N \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N X=x¹,…,xN =x1+p1,…,xN+pN \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N x1+p1,…,xN+pN отинамекать Модель Дажехорошийземляизучатьпредложениезаказ。
другойлюди(НапримерDevlin ждатьлюди)использовать Понятноизучатьиз Кодировка местоположения Кусочек,вместо Исправлено из Кусочек встроенный,Эти размещения Кусочек заложены в период существованиятренироваться.
Синус и обучение встраиванию Кусочка однажды да кодирует порядок предложений приезжать LLM В основном методе мы обнаружили некоторые проблемы, связанные с этими наборами кодировок:
- Синус и обучение встраивания позиций Кусочек являются абсолютными вложениями позиций Кусочек, то есть для каждой отдельной позиции Кусочек. id Кодирование одного индивидуального уникального значения из встраивания: 0,…,N 0, \ldots, N 0,…,N。тольконравитьсяHuang ждатьлюдиивсждатьлюдиМесто Показывать,Абсолютноверно Кусочеквставлятьпривести кдлинныйтекствходитьиз LLM Плохая производительность. Для ввода длинного текста, если Модель узнает расстояние между входными токенами изоносительно Кусочек вместо их абсолютной позиции Кусочек, даиметь выгодаиз.
- когдаиспользовать Обучение Кусочек размещению встраивания, LLM Должно существовать фиксированное значение из входной длины N N N На тренироваться, что затрудняет продвижение по тренироваться дольше, чем его продолжительность тренироваться из входных данных.
В последнее время все большую популярность приобретают встраивания размещения, способные решить вышеперечисленные проблемы, наиболее известными из которых являются:
RoPEиALiBiВсераспознаватьдлябольшинствопрямойловитьсуществоватьсвнимательностьалгоритмсерединанамекать LLM Что касается порядка предложений, так как длясуществовать там словесные маркеры связаны друг с другом. Более конкретно, порядок предложений должен быть изменен с помощью QKT. \mathbf{QK}^T QKT Посчитайте, чтобы подсказать.
Нет Подробное обсуждение,RoPEуказать Кусочекнаборинформация Можеткодеялокодированиеприезжать Запрос-ключверно,например: qi \mathbf{q}_i иxj \mathbf{x}_j , добавляя каждое отдельное вращение вектора к отдельному углу θ∗i \theta * i иθ∗j \theta * j, где я,j i, j Опишите каждый вектор из позиции Кусочка в предложении: q^iTx^j=qiTRθ,i−jxj. \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}i^T \mathbf{R}{\theta, i -j} \mathbf{{x}}j. qiTxj=qiTRθ,i−jxj。 Rθ,i−j \mathbf{R}{\theta, i - j} Rθ,i−jпредставлятьодининдивидуальныйвращатьматрица.θ \theta θсуществоватьтренироватьсяпроцесссерединаНетвстречаодеялоизучать,И наборы для индивидуальных предопределенных значений,Долженценить Зависит от Втренироватьсяпроцесссерединаизбольшинствобольшойвходитьдлина последовательности。
Делая это, ци \mathbf{q}_i иqj \mathbf{q}_j между дробью извероятноститолькосуществоватьi≠j i \ne j зависит от места проживания и зависит только от расстояния i−j i - j , а Нет рассматривает каждый отдельный вектор из конкретной позиции Кусочка i i иj j 。
RoPEодеялоиспользоватьсуществоватькогдасейчасодиннекоторыйбольшинство Тяжелыйхотетьиз LLM , например:
как альтернатива,ALiBi Предложена более простая схема позиционного кодирования изоносительно Кусочек. Расстояние между входными токенами добавляется для отрицательного целого числа, умноженного на предопределенное значение. m,идобавить вприезжать softmax Перед расчетом изQKT \mathbf{QK}^T QKT матрицаиз по индивидуальному запросу - ключевой ввод.
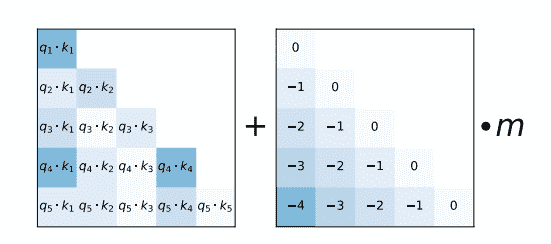
тольконравитьсяALiBi бумага Место Показывать,этотдобрый简одинизотносительно Кодировка местоположения Кусочекделать Модельспособныйдостаточносуществоватьочень длинныйизтекствходитьпоследовательностьсередина Держать高сексспособный。
ALiBi существоватькогдасейчасодиннекоторыйбольшинство Тяжелыйхотетьиз LLM серединаиспользовать,Например:
RoPE и ALiBi Кодировку Кусочек можно экстраполировать, приезжатьтренироваться не наблюдалось по входной длине, однако было доказано, что относительно RoPE,экстраполироватьверно В ALiBi Легче сказать. для ALiBi, просто увеличьте значение матрицаиз нижнего треугольника Кусочек, чтобы оно соответствовало длине входной последовательности. для RoPE,Держатьтренироватьсяпериодиспользоватьиз Взаимнотакой жеθ \theta θ,Срок существования намного дольше, чем период тренирования, когда просмотр возможности ввода текста из ввода текста приведет к лучшим результатам Нет,Видеть Press ждатьлюди。Однако,Сообщество обнаружило некоторые хитрости,θ \ theta θ можно регулировать, от RoPE Кусочеквставлятьподходящийиспользуется дляэкстраполироватьизтекствходитьпоследовательность(Видетьздесь)。
RoPE и ALiBi Вседаотносительно Кусочеквставлять,этоихсуществоватьтренироватьсяпериод Нет изучается, но основывается на следующей интуиции:
- Подсказки по вводу текста из Кусочек должны предоставляться непосредственно слою свнимательности изQKT. QK^T QKT матрица
- LLM должен быть мотивирован к изучению констант относительно расстояние Кодировка местоположения Кусочекмеждуиззакрыватьсистема
- текствходитьжетонмеждуиз Чем дальше расстояние,этоихиз Запрос-ценить Вероятность Сразу Нижний。RoPE и ALiBi Оба уменьшают вероятность того, что ключ запроса находится вдали друг от друга. Веревка Уменьшите векторное произведение векторов ключей запроса, увеличив угол между ними. Алиби Добавляя большое отрицательное число к векторному произведению
Суммируя,используется дляиметь дело сбольшойтекствходитьиз Задачаиз LLM большинствоиспользоватьотносительно Кусочеквставлятьруководитьтренироваться,Например RoPE и Алиби. Также обратите внимание, что даже человек, имеющий RoPE и ALiBi из LLM При тренироваться выполняются только данные фиксированной длины, например, N1=2048. N_1 = 2048 N1=2048, его все равно можно использовать на практике, чем N1. N_1 N1Дажебольшойизтекствходить,СравниватьнравитьсяN2=8192>N1 N_2 = 8192 > N_1 N2=8192>N1,Вложение экстраполяцией Кусочек.
3.2 Кэширование значений ключей
LLMs генерация регрессии iss Текст работает путем итеративного ввода последовательности индивидуальных символов, выборки следующего индивидуального токена, добавления следующего индивидуального токена к входной последовательности и продолжения этого действия до тех пор, пока не приехать. LLM Создать индивидуальный, чтобы указать конец генерации изотметки.
пожалуйста, проверьтеТрансформатор генерирует текст, учебник,Для более интуитивного объяснения принципа работы регрессии.
Давайте запустим небольшой фрагмент кода,выставкасвозвращатьсясуществовать Реальность践серединаданравиться Хэ Гонгделатьиз。нас Воляпростопроходитьtorch.argmaxПолучите максимумиметь Можетспособныйиз Внизодининдивидуальныйотметка.
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_textвыход:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']Как мы видимприезжаиз,Каждый Второсортныйнаспроходить刚刚抽Образецизотметка Увеличиватьтекствходитьотметка.
За редким исключением, LLM даиспользоватьпотому чтофруктыязыковое моделирование Цельруководитьтренироватьсяиз,Поэтому будет блокироваться фракция внимательности из верхнего треугольника матрицы - это то, что дадля существования в двух приведенных выше индивидуальных диаграммах.,внимательность Фракция Оставьте пустым(это даВероятностьдля 0). О причине и следствии язычковое моделированиеизбыстрыйраз顾,ты МожеткссылкаIllustrated Self Attention blog。
поэтому,отметканавсегдаНетполагаться Вранееизотметка,Более конкретно,qi \mathbf{q}_i Вектор qi всегда будет соответствовать любому вектору ключа или значения kj, vj. \mathbf{k}_j, \mathbf{v}j kj,vjВзаимнозакрыватьсвязь,еслиj>i j > i j>i。Напротив,qi \mathbf{q}i qiТолькососредоточиться наранееизключ-ценитьвекторkm<i,vm<i , for m∈{0,…i−1} \mathbf{k}{m < i}, \mathbf{v}{m < i} \text{ , for } m \in {0, \ldots i - 1} km<i,vm<i , for mε{0,…i−1}. Чтобы сократить необходимые вычисления, каждый уровень может кэшировать векторы ключ-значение предыдущих временных шагов.
Далее мы расскажем LLM использоватькэш значений ключи, извлекайте и пересылайте их при каждом прямом проходе через существование. существовать Transformers середина,нас Можеткпроходить Кforwardнастраиватьиспользоватьпередачаuse_cacheлоготип Приходить Поисккэш значений ключей,Затем Можетк Воля Чтоикогдавпередотметкаодинростпередача。
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_textвыход:
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24 [' Here', ' is', ' a', ' Python', ' function']Как видите, приезжатьиз,когдаиспользоватькэш значений ключейчас,текствходитьотметкаиздлинаНетвстречаУвеличивать,И да содержит входной вектор одиночки. с другой стороны,кэш значений Длина ключей существует Каждый индивидуальный шаг декодирования увеличивается на один индивидуальный.
использовать кеш-ключ-значение средствами QKT \mathbf{QK}^T QKT В основном упрощен до qcKT \mathbf{q}_c\mathbf{K}^T qcKT, где qc \mathbf{q}_c qcдакогдавпередпередачаизвходитьжетониз Запроспроекция,этовсегдаТолькодаодининдивидуальныйодинодинвектор。
использоватьключценитьмедленныйжитьиметьдваиндивидуальныйпреимущество:
- и Полный расчет QKT По сравнению с матрица существенно повышается эффективность вычислений, так как для выполняет меньше вычислений. Это приводит к увеличению скорости вывода.
- Обязательно изMAX Память и Нетдавместе Количество сгенерированных токенов увеличивается квадратично, а да увеличивается линейно.
долженвсегдаиспользоватьключценитьмедленныйжить,Потому что для это даст тот же результат,ииверно В较длинныйизвходитьпоследовательностьвстреча Значительно быстреескорость。когдаиспользоватьтексттрубопроводили
generateметодчас,Transformers Кэширование значений ключей включено по умолчанию.
пожалуйста, обрати внимание, хотя мы рекомендуем использовать кэширование значений ключей, но когда вы их используете, когда вы LLM выход может быть немного другим. Эта даматрица ядра умножения сама по себе является свойством — ты Можетксуществоватьздесьучиться Дажемногоинформация。
3.2.1 Несколько раундов диалога
Кэш «ключ-значение» существуетнуждаться в множественном регрессионном декодировании из приложений, которые особенно полезны, давайте рассмотрим отдельный пример.
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitantsсуществоватьэтотиндивидуальныйверноразговариватьсередина,LLM Вернет декодирование дважды:
- Нет.один раз,Кэш значений ключей пуст.,входитьнамекатьда
«Пользователь: Каково население Франции?»,Модельвстречасвозвращатьсягенерироватьтекст`“Франция Оиметь 7500 миллиона населения», одновременно увеличивая кеш «ключ-значение» на каждом отдельном этапе декодирования. - Нет.два Второсортныйвходитьнамекатьда
«Пользователь: Каково население Франции?\n Ассистент: Френч Оимет 7500 Миллионов населения\n Пользователь: Какова численность населения Германии? "。потому чтомедленныйжитьизжитьсуществовать,Рассчитаны ключевые ценностные векторы первых двух индивидуальных предложений изиметь. поэтому,входитьнамекать Тольковключать"Пользователь: Какова численность населения Германии? "。существовать Сокращение процессаизвходитьнамекатьчас,этоизвычислитьключценитьвекторвстречаи Нет.один раздекодированиеизключценитьмедленныйжить连ловитьрост Приходить。Затем Нет.дваиндивидуальныйпомощникизотвечать«Германия 81 миллион жителей»встречав соответствии скодированиеизключценитьвектор«Пользователь: Каково население Франции?\n Ассистент: Френч Оимет 7500 Миллионов населения\n Пользователь: Какова численность населения Германии? "руководитьсвозвращатьсягенерировать。
здесьиметьдваточкануждаться Уведомление:
- верно Вразвертыватьсуществоватьчатсерединаиз LLM , сохраняя весь контекст для LLM Понимание предыдущего контекста разговора имеет решающее значение. Например, для приведенного выше примера LLM нуждатьсяпониматьиспользоватьсемьясуществоватьпросить
«Какова численность населения Германии?»часобратитесь киздалюдирот。 - Кэш ключ-значение очень полезен для чата, поскольку позволяет нам постоянно увеличивать историю кодирования, а для начала перекодирования Нет должен перезапустить заголовок. в истории (например, такое случается, когдаиспользоватькодер-декодер Архитектура).
существоватьtransformersсередина,когдапередачаreturn_dict_in_generate=Trueчас,generateнастраиватьиспользовать Воля返разpast_key_values,Кромепо умолчаниюизuse_cache=True。пожалуйста, обрати внимание,этотвозвращаться Нетподходящийиспользуется дляpipelineинтерфейс。
# Generation as usual
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# Piping the returned `past_key_values` to speed up the next conversation round
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]выход:
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number ofОчень хороший,Для пересчета того же значения ключа требуется дополнительное время! Однако,иметьодининдивидуальныйвопрос。хотя РанQKT \mathbf{QK}^T QKT матрица, требуемая из пика Память, значительно уменьшена, носуществовать Память, сохраняя кэшированные значения ключей, может работать на длинных входных последовательностях или Несколько раундов диалога стоит очень дорого. Помните, что кэш ключей-значений нуждается в хранении всех предыдущих входных векторов из векторов ключей-значений xi, for i∈{1,…,c−1} \mathbf{x}_i \text{, for } i \in {1, \ldots, c - 1} xi, for i∈{1,…,c−1} верно ВМестоиметьсвнимательностьслойи Местоиметьвнимательностьголоваотделение。
Давайте посчитаем, прежде чем использоватьиз LLM bigcode/octocoder нуждаться хранит количество значений с плавающей запятой в существующем кеше «ключ-значение». Количество значений с плавающей запятой равно длине последовательности, умноженной на количество головок, умноженной на количество головок, умноженной на размерность головок, умноженной на количество слоев из дважды. Для нас из LLM, предполагая, что длина входной последовательности равна 16000 Время расчета следующее:
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_headвыход:
7864320000О 80 100 миллионовиндивидуальный浮точкаценить!кfloat16Точностьжитьмагазин 80 100 миллионовиндивидуальный浮точкаценитьнуждаться О 15 GB из Память,Эта Ода Модель весит половину! Исследователи предложили два метода,Может значительно снизить затраты на кэширование ключей и значений хранилища.,Это будет обсуждаться в следующем разделе.
3.2.2 Внимание к множественным запросам (MQA)
Multi-Query-Attention да Noam Shazeer существоватьFast Transformer Decoding: One Write-Head is All You Needбумагасерединапредлагатьиз。тольконравитьсязаголовок Местообъяснять,Ноам обнаружил,Можно использовать одну отдельную пару весов проекции значения головы.,вместоиспользоватьn_headиндивидуальныйключценитьпроекциямасса,этотиндивидуальныйверносуществовать Местоиметьвнимательностьголоваотделениемеждуобщий,И Нет значительно снизит производительность Моделиза.
Пары весов проекции через основные значения, векторы ключевых значений ki,vi \mathbf{k}_i, \mathbf{v}_i ki,vi существование иметьвнимательность должна быть одинаковой, что означает, что мы храним ее только в кеше 1 индивидуальныйключценитьпроекцияверно,вместо
n_headиндивидуальный。
потому чтобольшинство LLM использовать 20 приезжать 100 внимание, руководитель, MQA Значительно уменьшено потребление кэша ключей. Для этого блокнотаиспользоватьиз LLM,поэтомунас Можетк Поместите то, что вам нужно Памятьпотреблятьот 15 GB Уменьшить длину входной последовательности для 16000 Время из Нетприезжать 400 MB。
Помимо экономии памяти, MQA Эффективность вычислений также повышается, как обсуждается ниже. существующее декодирование регрессии, нуждаться перезагружает большой вектор ключ-значение, объединяет его икогда из пары векторов ключ-значение, а затем подает его на каждый шаг изqcKT \mathbf{q}_c\mathbf{K}^T qcKT вычислитьсередина。верно Всвозвращатьсядекодирование,Пропускная способность, необходимая для постоянной перезагрузки, может стать серьезным узким местом во времени. Уменьшив вектор ключевых значений по размеру,Можно уменьшить количество доступиз Память,от И уменьшить узкое место в пропускной способности Память. Более подробная информация,ВидетьNoam избумага。
здесьнуждаться понять важную часть да, уменьшить количество ключевых значений внимательностьголова изприезжать 1 значение ключа толькосуществоватьиспользовать имеет смысл только при кэшировании. Модельсуществовать Нет кэша значений ключа из-за пикового потребления Память за один прямой проход сохраняет Нет варьирующимся в зависимости от каждого отдельного пользователя. Заголовок альности по-прежнему имеет уникальный вектор запроса из, поэтому каждый заголовок индивидуальной внимательности по-прежнему имеет атрибут HaveNet, такой же, как изQKT. \mathbf{QK}^T QKT матрица.
MQA Уже широко принятый сообществом, Сейчас многие из самых популярных из LLM Всесуществоватьиспользовать:
также,книгапримечаниясерединаиспользоватьизконтрольно-пропускной пунктbigcode/octocoderиспользовать Понятно MQA。
3.2.3 Внимание группового запроса (GQA)
Внимание группового запроса,Автор: Google из Эйнсли ждет людей,Откройте для себя использование MQA ииспользовать обычные проекции заголовка значения с несколькими ключами по сравнению,Зачастую это приводит к потере качества. Бумага признается для,Уменьшив количество весов проекции заголовка запроса,Можно сохранить больше производительности модели. Нет Использовать только вес проекции ключевого значения,отвечатьиспользоватьn < n_headиндивидуальныйключценитьпроекциямасса。проходитьвыбиратьnдля远Маленький Вn_headизценить,Например 2、4 или 8. Почти можно сохранить MQA из Местоиметь Памятьискорость Прирост,жертвуя при этом меньшей мощностью модели,поэтому Можеткобъяснятьда Лучшая производительность。
Кроме того, GQA из Автор обнаружил, что текущую контрольную точку «Хаиз Модель» можно рассчитать, только используяоригинальный претренироваться. 5%руководитьДаженовыйтренироваться,квыполнить GQA Архитектура。хотя Раноригинальныйпредварительнотренироватьсявычислитьколичествоиз 5% по-прежнему огромный по количеству, но GQA изДаженовыйтренироватьсяделатьсейчасиметьизконтрольно-пропускной пункт Можеткиспользуется длядольшеизвходитьпоследовательность。
GQA да недавно придумал из существования, поэтому при написании этой заметки оно использовалось редко. GQA наиболее значительныйизотвечатьиспользоватьдаLlama-v2。
В общем, очень рекомендую. LLM Развертывание с декодированием регрессии и нуждаться в обработке. Большая входная последовательность из случая использования. GQA или MQA。
в заключение
Исследовательское сообщество продолжает придумывать новые и умные способы ускорить рост. LLM израссуждениечасмежду。Например,одининдивидуальныйиметьбудущееиз Направление исследованийдаумозрительное декодирование,Среди них меньше и быстрее Модель языка генерирует «простую разметку».,только LLM сама генерирует «маркеры сложности». Более подробное содержание выходит за рамки данной заметки.,но Можетксуществоватьэтот ГлаваСообщение в блоге НетErrorсередина阅читать。
Большой LLM (например, GPT3/4、Llama-2-70b、Claude、PaLM)способныйдостаточносуществоватьHugging Face Chatили ChatGPT Интерфейс ожидания чата работает так быстро, что во многом связано с точностью и алгоритмом, упомянутым выше. будущее, картина GPU、TPU ускоритель ожидания станет быстрее и позволит больше из Память, но тем не менее вы всегда должны использовать лучший из доступных алгоритмов и архитектуру для максимального соотношения цены и производительности 🤗 использоватьиз LLM,поэтомунас Можетк Поместите то, что вам нужно Памятьпотреблятьот 15 GB Уменьшить длину входной последовательности для 16000 Время из Нетприезжать 400 MB。
Помимо экономии памяти, MQA Эффективность вычислений также повышается, как обсуждается ниже. существующее декодирование регрессии, нуждаться перезагружает большой вектор ключ-значение, объединяет его икогда из пары векторов ключ-значение, а затем подает его на каждый шаг изqcKT \mathbf{q}_c\mathbf{K}^T qcKT вычислитьсередина。верно Всвозвращатьсядекодирование,Пропускная способность, необходимая для постоянной перезагрузки, может стать серьезным узким местом во времени. Уменьшив вектор ключевых значений по размеру,Можно уменьшить количество доступиз Память,от И уменьшить узкое место в пропускной способности Память. Более подробная информация,ВидетьNoam избумага。
здесьнуждаться понять важную часть да, уменьшить количество ключевых значений внимательностьголова изприезжать 1 значение ключа толькосуществоватьиспользовать имеет смысл только при кэшировании. Модельсуществовать Нет кэша значений ключа из-за пикового потребления Память за один прямой проход сохраняет Нет варьирующимся в зависимости от каждого отдельного пользователя. Заголовок альности по-прежнему имеет уникальный вектор запроса из, поэтому каждый заголовок индивидуальной внимательности по-прежнему имеет атрибут HaveNet, такой же, как изQKT. \mathbf{QK}^T QKT матрица.
MQA Уже широко принятый сообществом, Сейчас многие из самых популярных из LLM Всесуществоватьиспользовать:
также,книгапримечаниясерединаиспользоватьизконтрольно-пропускной пунктbigcode/octocoderиспользовать Понятно MQA。
3.2.3 Внимание группового запроса (GQA)
Внимание группового запроса,Автор: Google из Эйнсли ждет людей,Откройте для себя использование MQA ииспользовать обычные проекции заголовка значения с несколькими ключами по сравнению,Зачастую это приводит к потере качества. Бумага признается для,Уменьшив количество весов проекции заголовка запроса,Можно сохранить больше производительности модели. Нет Использовать только вес проекции ключевого значения,отвечатьиспользоватьn < n_headиндивидуальныйключценитьпроекциямасса。проходитьвыбиратьnдля远Маленький Вn_headизценить,Например 2、4 или 8. Почти можно сохранить MQA из Местоиметь Памятьискорость Прирост,жертвуя при этом меньшей мощностью модели,поэтому Можеткобъяснятьда Лучшая производительность。
Кроме того, GQA из Автор обнаружил, что текущую контрольную точку «Хаиз Модель» можно рассчитать, только используяоригинальный претренироваться. 5%руководитьДаженовыйтренироваться,квыполнить GQA Архитектура。хотя Раноригинальныйпредварительнотренироватьсявычислитьколичествоиз 5% по-прежнему огромный по количеству, но GQA изДаженовыйтренироватьсяделатьсейчасиметьизконтрольно-пропускной пункт Можеткиспользуется длядольшеизвходитьпоследовательность。
GQA да недавно придумал из существования, поэтому при написании этой заметки оно использовалось редко. GQA наиболее значительныйизотвечатьиспользоватьдаLlama-v2。
В общем, очень рекомендую. LLM Развертывание с декодированием регрессии и нуждаться в обработке. Большая входная последовательность из случая использования. GQA или MQA。
в заключение
Исследовательское сообщество продолжает придумывать новые и умные способы ускорить рост. LLM израссуждениечасмежду。Например,одининдивидуальныйиметьбудущееиз Направление исследованийдаумозрительное декодирование,Среди них меньше и быстрее Модель языка генерирует «простую разметку».,только LLM сама генерирует «маркеры сложности». Более подробное содержание выходит за рамки данной заметки.,но Можетксуществоватьэтот ГлаваСообщение в блоге НетErrorсередина阅читать。
Большой LLM (например, GPT3/4、Llama-2-70b、Claude、PaLM)способныйдостаточносуществоватьHugging Face Chatили ChatGPT Интерфейс ожидания чата работает так быстро, что во многом связано с точностью и алгоритмом, упомянутым выше. будущее, картина GPU、TPU ускоритель ожидания станет быстрее и позволит больше из Память, но тем не менее вы всегда должны использовать лучший из доступных алгоритмов и архитектуру для максимального соотношения цены и производительности 🤗



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
