Трансформаторная архитектура — кодер-декодер
Предисловие
Оригинальный Transformer основан на архитектуре Encoder-Decoder, широко используемой в области машинного перевода:
Encoder:
Преобразует входную последовательность токенов в последовательность векторов внедрения, называемую скрытым состоянием или контекстом.
Decoder:
Итеративно генерирует токены, составляющие выходную последовательность, на основе скрытого состояния кодировщика.
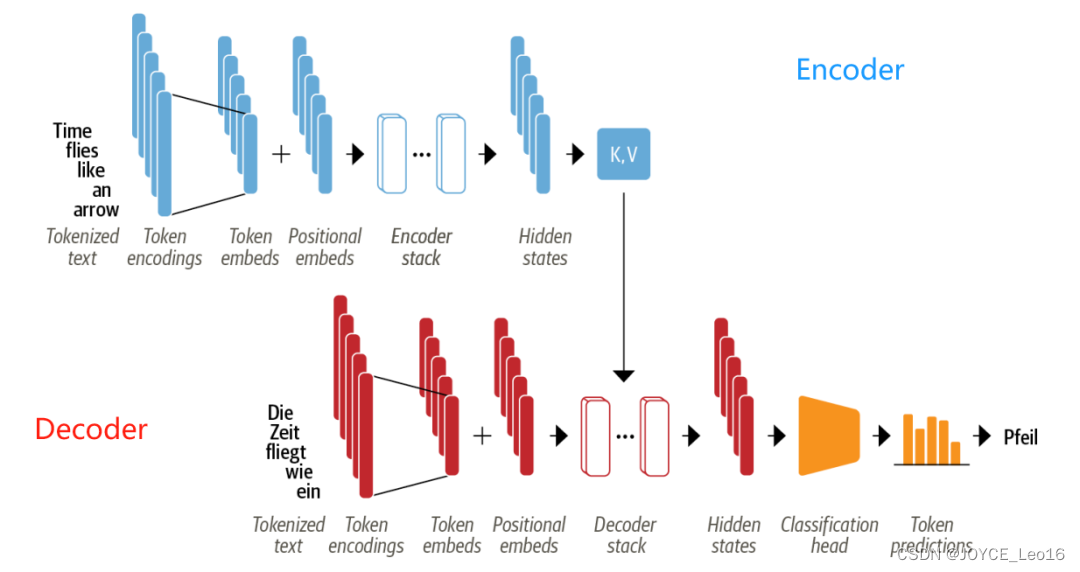
На картинке выше мы видим:
- Входной текст tokenized становиться token встраивание. Потому что механизм внимания не знает token из относительного положения, поэтому нам нужен способ разместить некоторую информацию о token Информация о положении вводится во входные данные для моделирования последовательного характера текста. Таким образом, токен embedding С каждым индивидуальным включенным token из Информация о местоположениииз position embedding сочетание фаз.
- encoder кучей encoder группа слоевстановиться,Похоже на:компьютерное Сверточные слои укладываются в зрение. То же самое и с декодером, у него свой decoder блоки слоев.
- encoder вывод подается на каждый decoder слой, затем decoder рожденныйстановитьсяскорее всего в последовательностииз Следующийиндивидуальный token из прогноза. Результаты этого шага затем передаются обратно в decoder крожденныйстановиться Следующийиндивидуальный токен и так далее, пока не дойдет до конца специальной последовательности (End of Последовательность, токен EOS). Взяв в качестве примера приведенную выше картинку, представьте себе decoder «Die» и «Zeit» были предсказаны. Сейчас существует, оно будет в соответствии сэти двоеиндивидуальныйпредсказывать token а такжевсе encoder из вывода, чтобы предсказать следующего человека token “fliegt”。существовать Следующийшагсередина,decoder Пригласите продолжить «fliegt» в качестве дополнительного ввода. Повторяем этот процесс до тех пор, пока decoder предсказывать EOS token В противном случае будет достигнут максимальный предел выходной длины.
Архитектура Transformer изначально была разработана для задач последовательного преобразования последовательностей, таких как машинный перевод, но блоки кодера и декодера были быстро адаптированы в независимые модели. Хотя существуют тысячи различных моделей трансформеров, большинство из них относятся к одному из трех типов:
(1)Encoder-only
Эти модели преобразуют последовательности ввода текста в расширенные числовые представления.,Отлично подходит для классификации текстаили Такие задачи, как распознавание именованных объектов.。BERT (трансформаторы двунаправленного кодирования) и его варианты,Например RoBERTa и DistilBERT,Все относятся к этой категории Архитектура. Архитектура в дана token Вычисление представления зависит от левого (до токена) и правого (после токена) и контекста. Поэтому его часто называют двунаправленным вниманием (двунаправленное внимание). attention)。
(2)Decoder-only
Пользователь дает текстовую подсказку,Эти Модельбудет перебиратьпредсказыватьскорее всего произойдетиз Следующийиндивидуальный Слова для автоматического завершения остальныхизтекст。GPT(Generative Pretrained Transformer)Модельсериал попадает в эту категорию。существовать Должен Архитектурасреда дана token Вычисленное представление зависит только от левого контекста. Поэтому его часто называют причинным вниманием (каузальное внимание). внимание) или авторегрессивное внимание (авторегрессия attention)。
(3)Encoder-Decoder
Они используются для моделирования сложных преобразований одной текстовой последовательности в другую, например, при машинном переводе и обобщении текста. В дополнение к тому, что мы видим из комбинаций кодера и декодера Трансформатор Вне конструкции BART (двунаправленный авторегрессионный преобразователь) и T5 (Text-To-Text Transfer Model Transformer) также включить в этом режиме.
Фактически только декодер Архитектураи encoder-only Различие между архитектурными приложениями немного размыто. Например, GPT Чисто в сериале decoder Модели могут быть подготовлены для таких задач, как перевод, которые часто считаются задачами последовательного преобразования. Аналогично, как BERT Такой чистый encoder Модель обычно можно применять с encoder-decoder или чистый decoder Задачи обобщения, связанные с моделью.
Каждая из трех основных архитектур со временем претерпела собственную эволюцию.
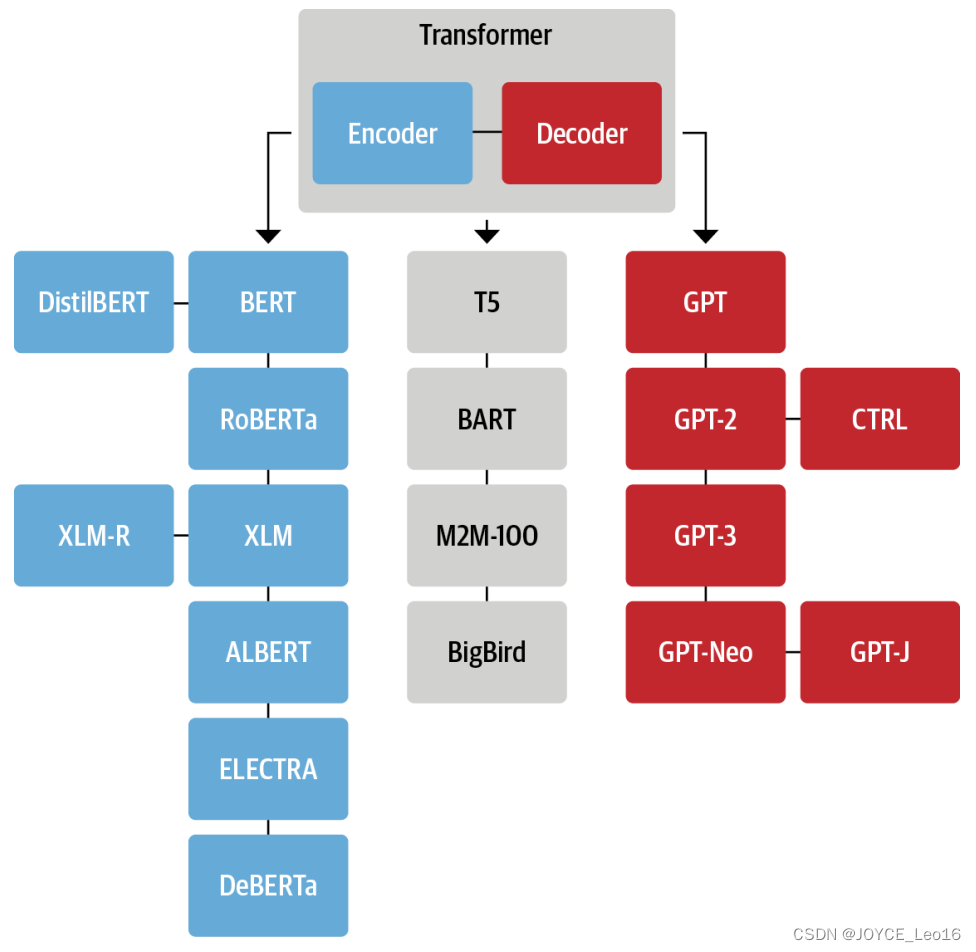
Генеалогическое древо, изображенное выше, лишь подчеркивает некоторые архитектурные вехи.
1. Семейство энкодеров
Первый основан на Transformer архитектурный encoder-only модель BERT。encoder-only модели по-прежнему доминируют NLU(Natural Language Понимание) задач (таких как классификация текста, распознавание именованных объектов и ответы на вопросы), а также исследований и промышленности. Далее краткое введение BERT Модели и их варианты:
1. BERT
BERT преследует две цели перед обучением: прогнозирование токенов маски в тексте и определение того, следует ли текстовый абзац за другим текстовым абзацем; Первая задача называется «Моделирование языка в маске» (MLM), а вторая — «Предсказание следующего предложения» (NSP).
2. DistilBERT
Хотя BERT обладает сильными возможностями прогнозирования, мы не можем развернуть его в производственной среде с низкими требованиями к задержке из-за его огромного размера. Используя технологию дистилляции знаний в процессе предварительного обучения, DistilBERT может достичь 97% производительности BERT, но его размер составляет лишь 40% от размера BERT и на 60% быстрее, чем BERT.
3. RoBERTa
Исследование, проведенное после выпуска BERT, показало, что его производительность можно еще улучшить, изменив схему предварительного обучения. RoBERTa имеет более длительное время обучения, большие пакеты, больше обучающих данных и отказывается от задачи NSP. В целом эти изменения значительно улучшают производительность исходной модели BERT по сравнению с ее производительностью.
4. XML
В межъязыковых языковых моделях (cross-lingual language model,XLM) В нашей работе мы исследовали несколько задач предварительного обучения для построения многоязычных моделей, в том числе на занятиях. GPT Модельиз Авторегрессионное языковое моделированиеи из BERT из МЛМ. Кроме того, XLM Автор предварительного учебного документа знакомит с языком перевода Модель (перевод language моделирование, TLM), что MLM Расширение для многоязычного ввода из. Проводя эксперименты по этим предтренировочным задачам, они NLU Достиг лучших результатов в тестах производительности и задачах перевода.
5. XML-RoBERTa
следовать XLM и RoBERTa из После работы XLM-RoBERTa или XLM-R Модель продвигает многоязычное предварительное обучение на шаг вперед за счет масштабного обновления обучающих данных. использовать Common Crawl корпус, разработчики которого создали 2.5TB текстизданныенабор;тогда онисуществоватьэтотиндивидуальныйданныенабор Для использования MLM обученный кодер. Поскольку набор данных содержит только тексты без параллелизма (т.е. перевести) и зданные, то XLM из TLM Цель удалена. Этот подход значительно превосходит XLM и Многоязычный BERT Вариантам, особенно существующим, не хватает достаточного лингвистического корпуса.
6. ALBERT
Модель ALBERT вносит три изменения, которые делают кодировщик Архитектура более эффективна. Во-первых, это будет token embedding Размеры отделены от скрытых размеров, что позволяет embedding меньшие размеры,таким образом сохраняя параметры,Особенно, когда словарный запас увеличивается. Во-вторых,Все слои имеют одинаковые параметры,Это еще больше уменьшает количество допустимых параметров. наконец,Цель NSP заменяется прогнозированием порядка предложений: Модель должна предсказать, поменяется ли порядок двух отдельных последовательных предложений.,Вместо того, чтобы предсказывать, принадлежат ли они друг другу. Эти изменения позволяют обучать более масштабным моделям с меньшим количеством параметров.,И существующий НЛУ достигает совершенства в своей миссии по производительности.
7. ELECTRA
Стандартная цель предварительного обучения MLM заключается в том, что ограничением является то, что каждый шаг обучения обновляется только mask token из средств, в то время как другие входные токены не обновляются. Чтобы решить эту индивидуальную проблему, ELECTRA использует метод двойной Модели: первая индивидуальная Модель (обычно небольшая) из работ аналогична стандартной. masked language моделировать и прогнозировать mask жетон. Вторая индивидуальная модель называется дискриминатором и затем отвечает за прогнозирование того, что из в выходных данных первой модели. токен является начальным из mask жетон. Следовательно, дискриминатору необходимо оценить каждый Токен классифицируется на две категории, что увеличивает эффективность обучения в 30 раз. Для последующих задач дискриминатор подобен стандартному BERT Модель также доработана.
8. DeBERTa
DeBERTa Модель вносит два архитектурных изменения. Во-первых, каждый token Оба представлены в виде двух векторов: один представляет содержимое, а другой — относительное положение. добавив token контент отделен от его относительного положения, и уровень самообслуживания может лучше сосредоточиться на близлежащих token Моделирование зависимостей. С другой стороны, абсолютное положение слова из также важно, особенно для декодирования. Следовательно, существовать token Декодирование заголовка softmax Абсолют добавлен перед слоем position embedding。DeBERTa является первым в SuperGLUE Превосходит человеческие базовые показатели по тестам Model, SuperGLUE Эталоном является GLUE из Более сложная версия, измеренная более индивидуально NLU производительностьизгруппа подзадачстановиться。
2.Семейство декодеров
Transformer decoder Прогресс в моделиизсуществовать во многом возглавляет OpenAI. Эти модели очень хороши для предсказания следующего отдельного слова в последовательности и поэтому в основном используются для задач генерации текста. Они добились прогресса, используя более крупный изданный набор и привнося язык. До становится все больше и больше по размеру, чтобы его можно было вытолкнуть.
1. GPT
Внедрение GPTиз сочетает в себе ключевые идеи двух людей в НЛП: нового и эффективного Трансформатора. decoder Архитектурное трансферное обучение. существуют Эта установка, по в соответствии Предыдущее предсказание слов Следующее индивидуальное слово для предварительного обучения Модель. Модельсуществовать BookCorpus Он прошел обучение по существу и добился хороших результатов в решении последующих задач, таких как классификация.
2. GPT-2
Вдохновленный простым и масштабируемым методом предварительного обучения, функция становится,GPT-2 появился на свет в результате модернизации оригинального тренировочного набора «Модели». Модель способна генерировать длинные последовательности связного текста. из-за страха возможных злоупотреблений,Данная Модель выпускается поэтапно.,Сначала публикуйте меньшие,Тогда опубликуйте полную версию модели.
3. CTRL
Как и GPT-2 из Модель может продолжить последовательность ввода (также называемую подсказкой: подсказка). Однако,Пользователь имеет мало контроля над стилем создаваемой последовательности. Модели CTRL (Conditional Transformer Language), включающие «токен управления» для решения этой проблемы. Они позволяют управлять сгенерированным текстом из стиля.,Таким образом, позволяя диверсифицироваться.
4. GPT-3
Успех будет GPT расширить до GPT-2 Наконец, всесторонний анализ поведения языков разного размера показывает, что существует простой степенной закон, управляющий взаимосвязью между вычислениями, размером набора данных и Модельпроизводительностью языка. Вдохновленный этими открытиями, GPT-2 был увеличен 100 раз, в результате чего 1750 100 миллионов(175B)индивидуальныйпараметриз ГПТ-3. Помимо способности создавать впечатляющие отрывки из реального текста, Модель также продемонстрировала небольшую способность к обучению: при выполнении некоторых новых задач из примеров (таких как преобразование текста в код) Модель смогла существовать на новых примерах. Опен АИ Для этой модели нет открытого исходного кода, мы можем только OpenAI API Предоставить интерфейс для доступа GPT-3。
5. GPT-Neo / GPT-J-6B
GPT-Neo и GPT-J-6B похоже на GPT из Модель, автор EleutherAI Обучение, Элеутер АИ это воссоздание и выпуск GPT-3 Размер Модельиз сообщества исследователей. Текущаямодель завершена 175B Модельиз меньшего варианта с 1.3B、2.7B и 6B параметры и OpenAI Предложение меньше GPT-3 Модель конкурентоспособна.
3. Семейство кодировщиков-декодеров
Хотя использование одного encoder или decoder Модель построения стека стала распространенной, но Transformer Есть много архитектур encoder-decoder варианты, они находятся в NLU и NLG Новинки есть во всех сферахизприложение:
1. T5
T5 Модель сочетает в себе все NLU и NLG Задачи преобразуются в задачи преобразования текста в текст для их унификации. Все задачи построены как последовательность задач, где encoder-decoder Архитектура очень естественная. Например, для задачи классификации текста это означает, что текст используется в качестве кодировщика. ввод и decoder Метки должны создаваться как обычный текст, а не как категории. Т5 Архитектура принимает оригинал из Transformer архитектура. Используйте большие обходы C4 набора данных, преобразуя все эти задачи в задачи преобразования текста в текст, используя MLM а также SuperGLUE Задача по предварительному обучению модели. 11Б Тест «Модельсуществоватьмногоиндивидуальный» показал лучшие результаты.
2. BART
BART существовать encoder-decoder Архитектура включает в себя BERT и GPT предтренировочный процесс. Входная последовательность подвергается одному из нескольких возможных преобразований, начиная от простого mask token Расставить и удалить предложения token èРотация документов. После этих изменений ввод проходит encoder Пропуск, декодер Исходный текст необходимо реконструировать. Это делает модель более гибкой, поскольку ее можно использовать для NLU и NLG задачи, и обе отдельные задачи достигли лидирующей производительности.
3. M2M-100
в целом,модель перевода строится для языковой пары иперевести направление. конечно,этоти не можетрасширить До многих языков, кроме того, между языковыми парами могут существовать общие знания, которые могут использоваться между редкими языками и переводить. М2М-100 это первыйиндивидуальный Можетсуществовать 100 перевестиизпереводить Модель между языками. Это может обеспечить высококачественный перевод между редкими языками и недостаточно представленными языками. Модель использует префикс токен (аналог специального из [CLS] токен) для указания исходного языка и целевого языка.
4. BigBird
Из-за механизма внимания и требований к вторичной памяти Трансформер Модельизодининдивидуальный Основное ограничение — максимальный размер контекста. Большая Птица Эта проблема решается с помощью формы разреженного внимания линейного расширения. Это позволяет удалить контекст из большинства BERT Модельсерединаиз 512 индивидуальный token значительно расширен до BigBird серединаиз 4096 индивидуальный. Это особенно полезно в ситуациях, когда необходимо сохранить длинные зависимости, например в текстовых сводках.
Ссылка: Исследовательский клуб PyTorch.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
