TimeGPT: В области прогнозирования временных рядов наконец-то появилась первая базовая большая модель
Исследователи полагают, что, несмотря на успех глубокого обучения в других областях, его эффективность при анализе временных рядов все еще остается спорной. Они подчеркивают проблемы, с которыми сталкиваются при оценке моделей глубокого обучения для прогнозирования временных рядов из-за отсутствия стандартизированных крупномасштабных наборов данных.
Будучи предварительно обученной моделью, TimeGPT способен генерировать точные прогнозы в различных областях без дополнительного обучения. Исследователи обсудили архитектуру TimeGPT, основанную на модели Transformer, и ее способность обрабатывать данные временных рядов различной частоты и характеристик.
Судя по статье, исследователи показали нам потенциал и преимущества TimeGPT как новой базовой модели в области прогнозирования временных рядов. Ожидается, что, преодолев ограничения текущих наборов данных и архитектур моделей, TimeGPT будет способствовать дальнейшему развитию анализа временных рядов и повышению точности и эффективности существующих методов прогнозирования.
Далее давайте посмотрим на архитектуру TimeGPT и его методы обучения.

Адрес статьи: https://arxiv.org/pdf/2310.03589.pdf.
История исследования
Сообщество прогнозистов в настоящее время разделено относительно превосходства методов глубокого обучения, и единый подход еще не создан. В последние годы борьба между этими различными парадигмами становится все более жесткой, ставя под сомнение практичность, точность и сложность новых разработок. Несмотря на успех архитектур глубокого обучения в других областях, некоторые практики временных рядов продемонстрировали, что некоторые предлагаемые инновации в этой области не соответствуют их заявлениям или ожиданиям.
Однако с появлением глубокого обучения анализ временных рядов претерпел сдвиг парадигмы. Методы глубокого обучения стали популярными в научных кругах и крупномасштабных промышленных приложениях прогнозирования. Хотя глубокое обучение демонстрирует большой потенциал в прогнозировании временных рядов, оно не является универсальным решением. В некоторых случаях простые статистические методы или традиционные модели машинного обучения могут лучше подойти для конкретной задачи.
В нынешнем историческом контексте превосходные возможности моделей глубокого обучения в области обработки естественного языка (NLP) и компьютерного зрения (CV) неоспоримы. Но стоит отметить, что в области анализа временных рядов по-прежнему скептически относятся к эффективности методов нейропрогнозирования. Исследователи полагают, что такое подозрение вызвано следующими причинами:
Одним из них являются неясные или незрелые настройки оценки: в отличие от других областей, которые получают выгоду от внедрения идеальных наборов тестовых данных (например, ImageNet в компьютерном зрении), общедоступные наборы данных временных рядов не имеют необходимого масштаба и объема, чтобы обеспечить глубину обучения. играть на своих сильных сторонах.
Второй — неоптимальные модели: даже хорошо спроектированные архитектуры глубокого обучения могут столкнуться с трудностями при обобщении или потребовать значительных усилий для поиска оптимальных настроек и параметров с учетом ограниченного и специфического набора данных.
Кроме того, прогрессу в этой области также может препятствовать отсутствие стандартизированных крупномасштабных наборов данных, отвечающих потребностям методов глубокого обучения. В то время как другие области извлекают выгоду из базовых наборов данных и четких показателей оценки, область временных рядов все еще нуждается в разработке этих ресурсов для продвижения инноваций и проверки новых технологий.
В статье исследователи использовали крупномасштабные наборы данных для обучения базовых моделей временных рядов, доказывая, что более крупные и разнообразные наборы данных могут повысить эффективность более сложных моделей в различных задачах.
Подробное объяснение TimeGPT
Time
01
Архитектура
На самом деле, введение в архитектуру TimeGPT в этой статье очень простое. TimeGPT — это модель временных рядов на основе преобразователя, которая использует окна исторических значений для прогнозирования и добавляет кодирование локального местоположения для обогащения входных данных. Модель состоит из многоуровневой структуры кодера-декодера, каждый уровень имеет остаточные связи и нормализацию уровня. Наконец, линейный уровень сопоставляет выходные данные декодера с размерами окна прогнозирования. В результате модель отражает разнообразие прошлых событий и правильно делает выводы о потенциальном будущем распределении.

Разработка больших моделей временных рядов сталкивается со многими проблемами, в первую очередь со сложной задачей обработки сигналов от широкого спектра основных процессов, таких как частота, разреженность, тенденции, сезонность, стационарность и гетероскедастичность, которые приносят такие характеристики, как частота, разреженность и гетероскедастичность. к локальным и глобальным моделям. Очевидная сложность. Следовательно, любая базовая прогностическая модель должна иметь возможность управлять этой неоднородностью. Исследователи разработали TimeGPT для обработки временных рядов с разными частотами и характеристиками, адаптируясь к различным размерам входных данных и горизонтам прогнозирования. Эта адаптивность во многом обусловлена базовой архитектурой Transformer, на которой основан TimeGPT.
TimeGPT не основан на существующих моделях больших языков (LLM). Хотя TimeGPT следует принципу обучения больших моделей Transformer на больших наборах данных, его архитектура специально разработана для обработки данных временных рядов и после обучения направлена на минимизацию ошибок прогнозирования.
02
набор обучающих данных
TimeGPT обучен на крупнейшем общедоступном наборе данных временных рядов, содержащем более 100 миллиардов точек данных. Этот обучающий набор охватывает временные ряды из широкого спектра областей, включая финансы, экономику, демографию, здравоохранение, погоду, данные датчиков Интернета вещей, энергетику, сетевой трафик, продажи, транспорт и банковское дело. Из-за такого разнообразия областей набор обучающих данных содержит временные ряды с различными характеристиками.
Что касается временных закономерностей, набор обучающих данных содержит ряды с различной сезонностью, циклами разной длины и различными типами трендов. Помимо временных закономерностей, набор данных также отличается шумом и выбросами, что обеспечивает мощную среду обучения. Некоторые последовательности содержат четкие, регулярные закономерности, в то время как другие последовательности содержат значительный шум или неожиданные события, что обеспечивает модели широкий спектр сценариев обучения. Большинство временных рядов включаются в необработанном виде; обработка ограничивается стандартизацией формата и заполнением пропущенных значений для обеспечения целостности данных.
Выбор такого разнообразного обучающего набора имеет решающее значение для разработки сильной базовой модели. Это разнообразие охватывает сложную реальность нестационарных реальных данных, где тенденции и закономерности могут меняться с течением времени из-за множества факторов. Обучение TimeGPT на этом богатом наборе данных позволяет ему обрабатывать различные сценарии, повышая его надежность и возможности обобщения. Это эффективно позволяет TimeGPT точно прогнозировать невидимые временные ряды, устраняя при этом необходимость в индивидуальном обучении и оптимизации модели.
03
Время обученияGPT
TimeGPT обучается на кластере графических процессоров NVIDIA A10G в течение нескольких дней. В ходе этого процесса исследователи провели обширное исследование гиперпараметров для оптимизации скорости обучения, размера пакета и других соответствующих параметров. Была обнаружена закономерность, согласующаяся с результатами исследования: больший размер партии и меньшая скорость обучения оказались полезными. TimeGPT, реализованный в PyTorch, использует алгоритм обучения Адама и применяет стратегию снижения скорости обучения, чтобы уменьшить ее до 12% от исходного значения.
04
Количественная оценка неопределенности
Вероятностное прогнозирование относится к оценке неопределенности прогноза модели. Прогнозирование соответствия — это непараметрическая структура, которая предоставляет эффективный метод создания интервалов прогнозирования с заранее заданной точностью покрытия. В отличие от традиционных методов, конформное прогнозирование не требует строгих предположений о распределении, что делает его более гибким и несмещенным по отношению к модели или области временных рядов. При выводе нового временного ряда исследователи выполняют скользящие прогнозы на основе последних доступных данных, чтобы оценить ошибку модели в прогнозировании конкретного целевого временного ряда.
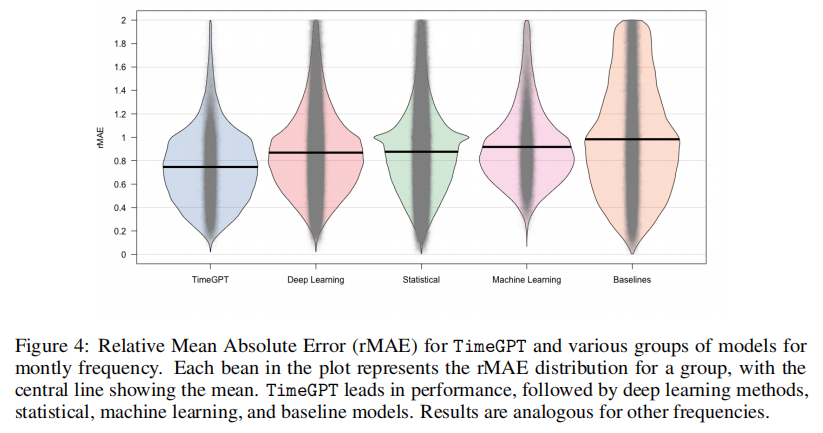
Результаты эксперимента
Time
Исследователи изучили возможности TimeGPT как базовой модели для прогнозирования, протестировав ее на большом и разнообразном наборе временных рядов. Набор тестов включает более 300 000 временных рядов из разных областей, включая финансы, сетевой трафик, Интернет вещей, погоду, спрос и электричество.
Оценка выполняется в последнем окне прогноза каждого временного ряда, длина которого варьируется в зависимости от частоты выборки. TimeGPT использует в качестве входных данных предыдущие исторические значения, как показано на рисунке 3, без переобучения своих весов (нулевые выборки). Укажите различные горизонты прогноза на основе частоты для представления общих практических применений: 12 для ежемесячного, 1 для еженедельного, 7 для ежедневного и 24 для ежечасного.
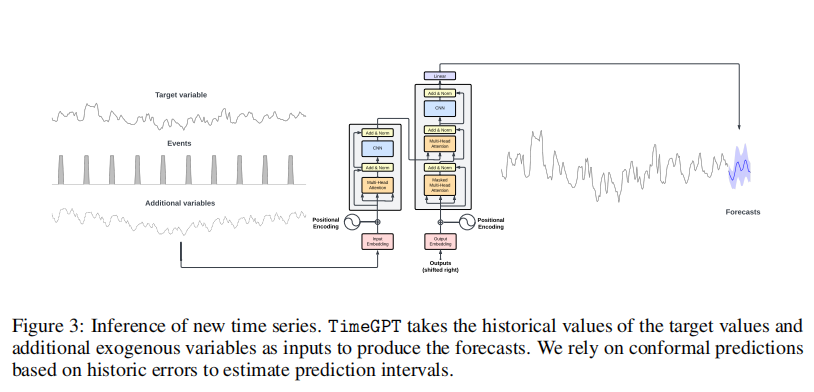
Этот метод оценки более точно моделирует реальные сценарии прогнозирования, где моделям часто приходится предсказывать совершенно невидимые временные ряды. С помощью этого метода можно лучше измерить производительность TimeGPT как базовой модели прогнозирования и оценить ее способность к обобщению для различных полей и различных частотных данных.
На рисунке ниже показаны результаты тестирования некоторых наборов данных с использованием rmse и rmae в качестве показателей оценки.
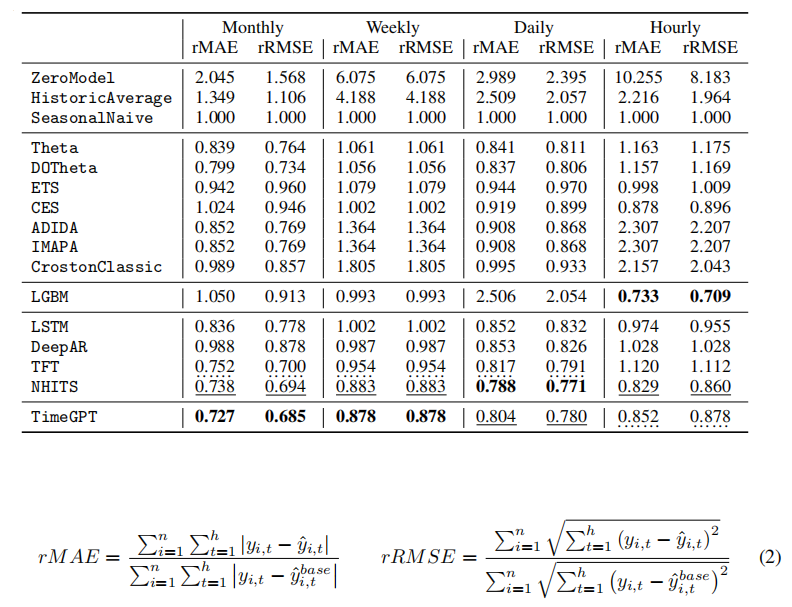
TimeGPT хорошо работает при выводе с нулевой выборкой, превосходя ряд протестированных в полевых условиях статистических моделей и методов глубокого обучения SoTA, входя в тройку лучших по каждой частоте.
Скорость нулевого вывода TimeGPT составляет в среднем 0,6 миллисекунды/последовательность, что сопоставимо с простым Seasonal Naive. Статистический метод, оптимизированный для параллельных вычислений, в сочетании с компиляцией Numba имеет среднюю скорость обучения и вывода 600 миллисекунд/последовательность, в то время как глобальные модели, такие как LGBM, LSTM и NHITS, имеют среднюю скорость 57 миллисекунд/последовательность. Благодаря возможности нулевой выборки TimeGPT превосходит традиционные статистические методы и глобальные модели по общей скорости.
Подвести итог
Time
Текущая практика прогнозирования часто включает в себя сложные процессы, включающие несколько этапов: от обработки данных до обучения и выбора модели. TimeGPT упрощает процесс до этапов вывода, значительно снижая сложность и затраты времени, сохраняя при этом самую современную производительность. Самое главное, что TimeGPT демократизирует преимущества моделей крупных преобразователей, которые сегодня доступны только организациям с большими объемами данных, вычислительными ресурсами и техническим опытом. Мы считаем, что базовая модель окажет глубокое влияние на область прогнозирования и изменит нынешнюю практику.
Два основных направления будущих исследований:
- Информационный прогноз: этот метод прогнозирования сочетает в себе знания Базы данных.,Например, физические законы, экономические принципы или медицинские факты и т. д.,интегрированы в процесс прогнозирования.
- Встраивание временных рядов. Традиционно сходство между последовательностями, взятыми из одной и той же категории (например, розничная торговля или финансы), должно быть выше, чем между областями, но предположения о классификации временных рядов требуют дальнейшей проверки. В этом исследовании предлагается мощная метрика для измерения сходства последовательностей, которая имеет важные последствия для этой области.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
