Тест интерфейса Python для решения проблем с параметрами и кодировкой экранированных символов.
Введение
Автор, будучи очень занятым на работе, решил выделить время на запись проблем, возникших при тестировании интерфейса, для дальнейшего использования. Его также можно предоставить тем партнерам, которые изучают тестирование интерфейса, чтобы избежать обходных путей. Если вам помогло, поставьте лайк, спасибо.
Сегодняшняя статья в основном посвящена обработке параметров запроса, содержащих escape-символы, и возвращаемых параметров, содержащих escape-символы, при тестировании интерфейса. Ранее я рассказывал о методе тестирования интерфейса.
Можно обратиться кИнтерфейс Python проверяет разницу между параметрами data и json в методе request.post.。
Обработка интерфейсов с escape-символами во входных параметрах
1. Во-первых, давайте посмотрим на стиль данных параметров в моем интерфейсе:

Параметры в этом теле включают два «тело» и «метод». Вся переменная данных представляет собой словарь, но «тело» представляет собой строку и содержит escape-символы. Проблем с написанием такого рода параметра в коде нет, но при использовании его в качестве запроса к интерфейсу иногда он не может быть разобран json, что в конечном итоге приводит к сбою запроса к интерфейсу.
Этот параметр не обрабатывается и запрашивается напрямую, как показано на рисунке ниже:

2. Цель определена, и следующим шагом является ее обработка. Сначала я деэкранировал данные. На самом деле я использую json-метод load(), как показано на рисунке.
При использовании этого метода вам необходимо заранее обработать данные, поскольку типы, поддерживаемые этим методом, ограничены, например:
def loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
"""Deserialize ``s`` (a ``str``, ``bytes`` or ``bytearray`` instance
containing a JSON document) to a Python object.
``object_hook`` is an optional function that will be called with the
result of any object literal decode (a ``dict``). The return value of
``object_hook`` will be used instead of the ``dict``. This feature
can be used to implement custom decoders (e.g. JSON-RPC class hinting).
``object_pairs_hook`` is an optional function that will be called with the
result of any object literal decoded with an ordered list of pairs. The
return value of ``object_pairs_hook`` will be used instead of the ``dict``.
This feature can be used to implement custom decoders that rely on the
order that the key and value pairs are decoded (for example,
collections.OrderedDict will remember the order of insertion). If
``object_hook`` is also defined, the ``object_pairs_hook`` takes priority.
``parse_float``, if specified, will be called with the string
of every JSON float to be decoded. By default this is equivalent to
float(num_str). This can be used to use another datatype or parser
for JSON floats (e.g. decimal.Decimal).
``parse_int``, if specified, will be called with the string
of every JSON int to be decoded. By default this is equivalent to
int(num_str). This can be used to use another datatype or parser
for JSON integers (e.g. float).
``parse_constant``, if specified, will be called with one of the
following strings: -Infinity, Infinity, NaN.
This can be used to raise an exception if invalid JSON numbers
are encountered.
To use a custom ``JSONDecoder`` subclass, specify it with the ``cls``
kwarg; otherwise ``JSONDecoder`` is used.
The ``encoding`` argument is ignored and deprecated.
"""Сначала я конвертирую данные в str, как показано на рисунке:

Причина, по которой я опубликовал скриншот отчета об ошибке, заключается в том, что у меня есть чему вас научить.
Строки Python имеют иерархическую структуру, например, используются ''' ''' и " " и ' ', поэтому вы не можете использовать два " ", как показано на рисунке выше.
После модификации выполните вызывающую интерфейсную программу:

Этот возвращаемый результат - это то, что я хочу.
Теперь, когда мы поговорили об экранировании входных параметров, что насчет экранирующих параметров? Оставьте это думать всем.
Обработка кодирования
Часто возвращаемые данные включают китайские и двоичные данные. Давайте сначала посмотрим на необработанные данные, возвращаемые интерфейсом, которые показаны следующим образом:

Такого рода данные во-первых неудобно просматривать, во-вторых сложно найти нужное значение.
print(r2.content.decode(),end=' ')Запустите скрипт:
UnicodeEncodeError: 'gbk' codec can't encode character '\xe2' in position 15788: illegal multibyte sequenceВ этом предложении говорится, что gbk не может кодировать, но моя кодировка — utf-8, что, очевидно, не является проблемой кода. Местоположение ошибки «\xe2» не может быть декодировано. Добавьте стандартный код вывода:
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #Изменяем кодировку стандартного вывода по умолчаниюЗапустите программу еще раз, и результат покажет успех:
Следует отметить, что если gb18030 не работает, используйте utf-8, например:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #Изменяем кодировку стандартного вывода по умолчаниюЕго также можно изменить на:
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gbk')Ниже приведены некоторые соответствующие таблицы кодировок для китайского языка:
имя кодировки | использовать |
|---|---|
utf8 | все языки |
gbk | Упрощенный китайский |
gb2312 | Упрощенный китайский |
gb18030 | Упрощенный китайский |
big5 | Традиционный китайский |
big5hkscs | Традиционный китайский |
Объяснение причины: если вам нужно распечатать символы Юникода, поскольку локальная система в Windows — cmd, кодовая страница по умолчанию — CP936, которая является кодировкой GBK, поэтому интерпретатору Python необходимо закодировать указанные выше символы Юникода в GBK. сначала, а потом в cmd отображается в . Однако, поскольку строка Unicode содержит некоторые символы, которые не могут быть отображены в GBK, в этот момент отображается сообщение об ошибке «Кодек 'gbk' не может кодировать». Фактически, ограничением функции print() является ограничение кодировки Python по умолчанию. Поскольку используется система Windows, кодировка Python по умолчанию не «utf-8». Просто измените кодировку Python по умолчанию на «utf-8». '.
Метод запроса интерфейса
Уже сказано во Введении,Если вы не понимаете запросы,Можно обратиться к Эта моя статьяИнтерфейс Python проверяет разницу между параметрами data и json в методе request.post.。В этой статье говорилось оpostЗапрашиваются два типа данныхтипdataиjson,Затем для данных с escape-символами в теле данных,Как использовать эти два параметра типа запроса одновременно? существовать, прежде чем говорить,Давайте сначала рассмотрим некоторые моменты знаний:
resp.text возвращает данные Юникода.
resp.content возвращает данные типа байтов.
resp.json() возвращает данные формата json
#Примечание:
#Если вы хотите получить текст, вы можете передать r.text.
#Если вы хотите получить изображения и файлы, вы можете передать r.content.
#если хочешьdictтипданные,Вы можете передать r.json().Конкретный сценарий:
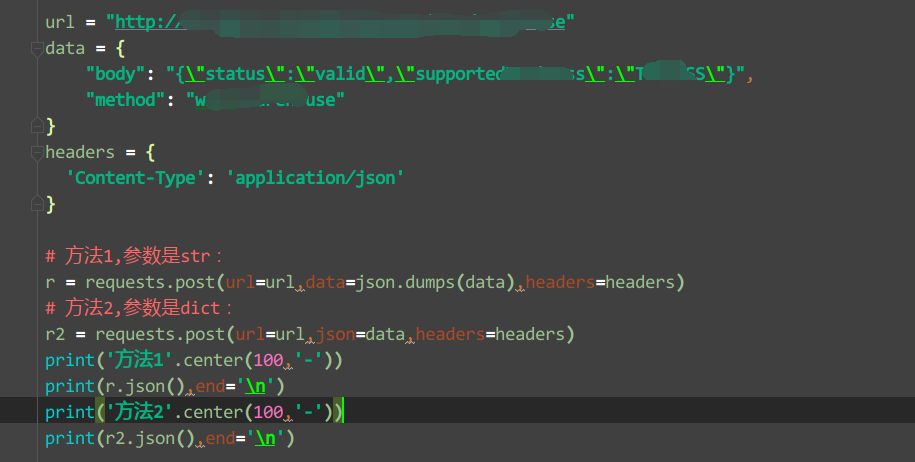
Результат следующий:


Независимо от того, выберете ли вы тип данных или тип json, если типы передаваемых параметров соответствуют друг другу, проблем не возникнет. Здесь нет непосредственного кода сценария. Его также могут набирать новички. Их нельзя напрямую копировать и использовать, что будет препятствовать их собственному совершенствованию кодирования.
Извлечь параметры из сообщения
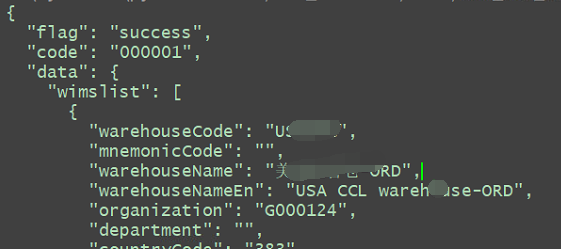
Как получить значения, соответствующие ключу в возвращаемом результате. Например, с помощью этого интерфейса я хочу получить значение поля StorageName, как показано на рисунке:

С точки зрения данных возвращаемый тип данных является словарем, а имя хранилища словаря, которое я хочу получить, находится в данных словаря, данные - это словарь, в нем есть список, а также в списке есть словарь. , что эквивалентно 4 уровням вложенности. Как насчет удаления медианного значения 4-го слоя? Это двухэтапная операция, подробности см. в коде:
# Получить значение, соответствующее ключу в словаре
a = r.json()
b =a['data']['wimslist']
# print(type(dict(b)))
c = json.dumps(b, ensure_ascii=False)
# Способ 1
for item in b:print (item['warehouseName'],end=' ')
# Способ 2
# Получить ключевое значение словаря в списке
list_result = []
for i in b:
list_result.append(i['warehouseName'])
print(list_result)
from common.loggers import Log
loggger = Log()выход Результат следующий:

Приложение
1. Вот точки знаний о (u, r, b перед строкой), чтобы углубить ваше впечатление. Если вы не поняли это раньше, просто выучите это и, естественно, будете использовать это в будущем.
1. Добавить перед строкой u
Пример: u"Я — строка, состоящая из китайских иероглифов."
эффект:
Следующая строка начинается с Unicode Формат Кодировать,Обычно используйте существование перед китайскими строками.,Предотвратите проблемы с хранением исходного кода,Это приводит к искажению символов при повторном использовании.
2. Добавить перед строкой r
Пример: r"\n\n\n\n" # Представляет обычную необработанную строку \n\n\n\n не означает разрыва строки.
эффект:
Удалите механизм экранирования обратной косой черты.
(Специальные символы: то есть обратная косая черта плюс соответствующие буквы, обозначающие соответствующее специальное значение, например, наиболее распространенный «\n» означает разрыв строки, «\t» означает Tab и т. д. )
приложение:
Часто используется в регулярных выражениях, соответствующих модулю re.
3. Добавить перед строкой b
пример: response = b'<h1>Hello World!</h1>' # b' ' означает, что это bytes объект
эффект:
b" «Префикс означает: следующая строка — это байты. тип.
полезность:
В сетевом программировании серверы и браузеры распознают только байты. тип данных.
Например: отправить параметры функции и recv Возвращаемое значение функции bytes тип
Прикрепил:
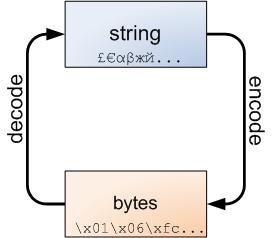
существовать Python3 средний, байты и str Метод взаимного преобразования
str.encode('utf-8')
bytes.decode('utf-8')2. Что касается базовых знаний кодирования Python, преобразование между строками и потоками байтов выглядит следующим образом:
Связанные детали Можно обратиться к Другая моя статья:https://cloud.tencent.com/developer/article/2213020
Если вы заинтересованы в технологиях, связанных с разработкой тестов на Python, вы можете присоединиться к группе QQ по обмену знаниями в области разработки тестов: 696400122. Если вы не будете делать маленькие шаги, вы не достигнете тысячи миль.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
