Технологии, связанные с большими моделями: почему необходимо изменение ранга
В RAG (RetrivalAugmented Generation) векторный поиск модели внедрения может помочь улучшить эффект генерации текста, но для этого все еще требуется
переранжируйте модель для дальнейшей оптимизации результатов поиска и улучшения качества генерации. Преимущество этой двухэтапной комбинации моделей поиска и переранжирования состоит в том, что обе модели могут быть полностью использованы.
Преимущества предоставления более точных и релевантных результатов. В этой статье кратко проанализировано, что такое двухэтапный поиск и почему изменение ранжирования так важно, а также его сравнение с традиционным полнотекстовым поиском ES.
По сравнению с тем, почему у него есть преимущество.
Что такое двухэтапный поиск?
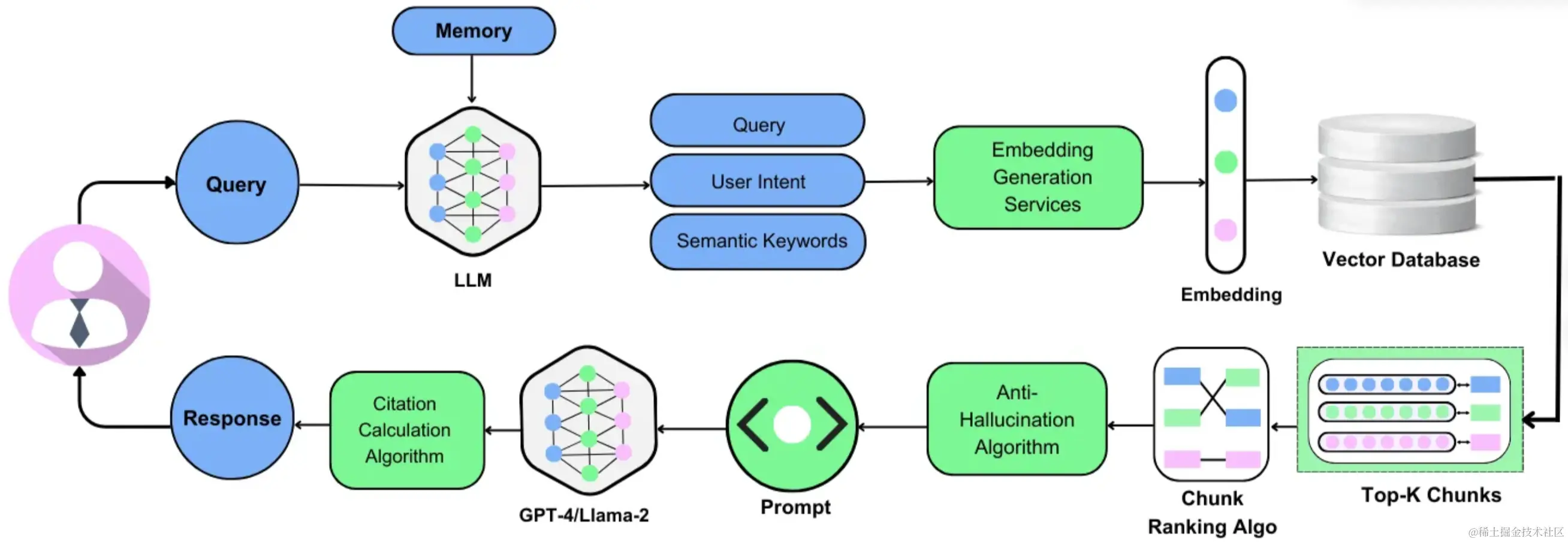
Двухэтапный поиск состоит из этапа поиска и этапа уточнения. Этот метод хорошо сочетает производительность и скорость поиска, поэтому он широко применяется в процессе RAG.
На этапе поиска обычно используется векторный метод интенсивного поиска для поиска фрагментов, семантически схожих с вопросом пользователя, путем извлечения семантических векторов вопросов пользователя и корпуса базы знаний.
При извлечении семантических векторов обычно используется структура двойного кодировщика для обработки огромного массива базы знаний в автономном режиме с целью извлечения вопросов пользователя в режиме реального времени.
Семантические векторы вопросов и использование векторных баз данных для семантического поиска. В этом процессе извлечение семантического вектора корпуса базы знаний выполняется статически и в автономном режиме, а модель извлекается.
Между вопросами пользователя и смысловыми векторами корпуса базы знаний отсутствует информационное взаимодействие. Преимуществом этого метода является высокая эффективность, но он также ограничивает верхний предел производительности семантического поиска.
Для решения проблемы информационного взаимодействия на этапе доработки принимается структура кросс-кодировщика. Изменение порядка моделей позволяет пользователям задавать вопросы и создавать базы знаний.
Информационное взаимодействие между корпусами, тем самым выявляя более точные семантические связи, верхний предел производительности алгоритма очень высок. Однако недостатком этого подхода является то, что он требует оперативного (онлайн)
Получение семантической связи между вопросами пользователя и корпусом базы знаний неэффективно и не позволяет обрабатывать весь корпус базы знаний в реальном времени.
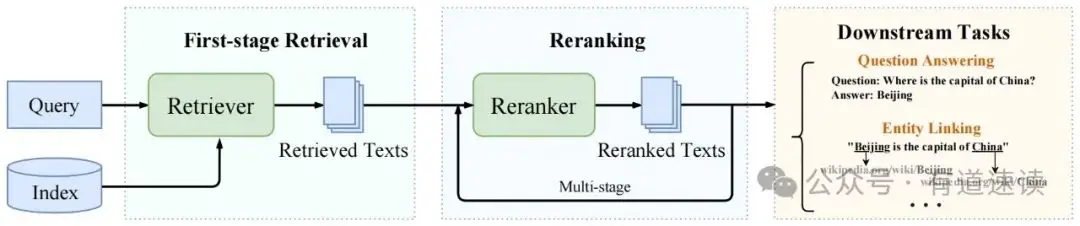
Таким образом, сочетая преимущества поиска и мелкозернистости, двухэтапный поиск может быстро извлечь фрагменты текста, связанные с вопросом пользователя, и поместить правильные релевантные фрагменты вперед, насколько это возможно.
столбцы при фильтрации клипов низкого качества. Этот метод позволяет хорошо оценить эффект и эффективность поиска и имеет огромную прикладную ценность.
Если говорить проще: первый этап реализует отзыв документов через модель внедрения, а второй этап реализует семантику вопросов пользователей и сортировку отозванных документов.
Зачем нам нужна модель реранга?
Повышение точности. Хотя модель внедрения может извлекать похожие фрагменты текста путем расчета сходства векторов, это может оказаться невозможным из-за сложности и неоднозначности семантики.
Есть некоторые избыточные или нерелевантные результаты. Модель переранжирования может дополнительно уточнять и оптимизировать результаты на этой основе, повышая точность и релевантность сгенерированного текста.
Семантическое сопоставление: модель переранжирования может выполнять сопоставление текста на основе более обширной семантической информации, такой как синтаксическая структура, семантическая ассоциация и контекстная информация, для лучшего понимания.
смысл текста и выбрать наиболее релевантный контент для генерации.
Персонализированная настройка: модель переоценки можно персонализировать в соответствии с предпочтениями и потребностями пользователя, что еще больше повышает адаптируемость полученных результатов и удовлетворенность пользователей, что полезно для
Это особенно важно для приложений в конкретных областях или сценариях.
Преимущества двухэтапных моделей поиска и переранжирования
Повышение точности: векторный поиск модели внедрения позволяет быстро отфильтровать похожие тексты, а модель переранжирования еще больше повышает точность поиска и генерации на этой основе.
свойства, что приводит к более качественному результату.
Экономия вычислительных ресурсов. Модель переранжирования работает с меньшим набором текста, отфильтрованным с помощью модели внедрения, что сокращает объем вычислений и повышает эффективность и производительность.
Гибкость: двухэтапный подход позволяет гибко обрабатывать различные типы запросов и запросов, позволяя при этом выбирать и корректировать различные модели переранжирования в соответствии с конкретными задачами и т. д.
Масштабируемый.
Сравнение с технологией elasticsearch
Ограничения эластичного поиска. По сравнению с традиционными инструментами поиска текста, такими как эластичный поиск, метод сопоставления ключевых слов может иметь семантический дрейф и недостаточную точность.
проблема. В некоторых сложных задачах традиционная технология поиска не может полностью удовлетворить потребности.
В сочетании с преимуществами RAG: по сравнению с эластичным поиском, двухэтапный поиск RAG уделяет больше внимания семантическому сопоставлению, что позволяет лучше понять текстовое содержимое и контекст, тем самым улучшая
Обеспечивает более точную и качественную генерацию текста. Сочетая модели глубокого обучения и функции данных из нескольких источников, RAG имеет явные преимущества в создании качества и релевантности текста.
Адаптивность: RAG можно гибко настраивать в соответствии с конкретными сценариями и потребностями, адаптируясь к различным требованиям задач, повышая практичность и адаптируемость генерируемого текста, оставаясь при этом традиционным;
Технологии текстового поиска трудно добиться таких точных персонализированных настроек.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
