talkGPT4All 2.5 - Больше моделей и более реалистичная TTS
1. Обзор
talkGPT4Allоснован наGPT4Allодин изголосчатпрограмма,Работает на локальном процессоре,Поддержка Linux,Мак и Винда. Он использует модель Whisper от OpenAI для преобразования введенного пользователем голоса в текст.,Затем вызовите языковую модель GPT4All, чтобы получить текст ответа.,Наконец, используйте программу Text to voice (TTS), чтобы прочитать текст ответа вслух.
В апреле и мае этого года я выпустил talkGPT4All версии 1.0 и версии 2.0. Ссылки следующие:
talkGPT4All: Программа интеллектуального голосового чата на основе GPT4All talkGPT4All 2.0: теперь поддерживает 8 языковых моделей.
Самая большая проблема, о которой все говорили, заключалась в том, что TTS был слишком механическим и неудобным для прослушивания (подробности см. в комментариях к двум предыдущим статьям). В последнее время появилось много разработок в области TTS, таких как очень популярный coqui-aiизTTS Библиотека предоставляет функции TTS, клонирования звука и преобразования звука. Я попробовал это на прошлых выходных и обнаружил, что есть несколько встроенных моделей TTS, которые можно использовать «из коробки», и которые можно интегрировать в talkGPT4All , для решения принятых в настоящее время pyttsx3Синтетический звук слишком механический.извопрос。
Также проверьте документацию GPT4All. Начиная с версии 2.5.0, предыдущие файлы моделей формата .bin больше не поддерживаются, поддерживаются только модели формата .gguf. Поэтому я также слил обновления из вышестоящего хранилища и модифицировал интерфейс talkGPT4All.
Поскольку GPT4All несовместим со старой моделью формата .bin, начиная с версии 2.5.0, это серьезное изменение. Ради унификации я также назвал обновлённый talkGPT4All версии 2.5.0.
2.5.0Посмотреть видео с эффектом версииздесь。
2. Как использовать
Если вы хотите использовать его напрямую, просто используйте pip для установки пакета talkGPT4All:
pip install talkgpt4allПосле установки войдите в чат:
talkgpt4ll talkGPT4All в настоящее время поддерживает 15 моделей. Вы можете использовать -m, чтобы переключить модель GPT, которую вы хотите использовать. Список всех моделей см. в главе 3.2.
talkgpt4all -m gpt4all-13b-snoozy-q4_0.gguf3. Детали реализации
Здесь мы сосредоточимся на двух моментах, связанных с этим обновлением: как использовать coqui-ai/TTS и как вызывать модель GPT после GPT4All 2.5.0.
3.1 использование coqui-ai/TTS
Непосредственно используйте pip install TTS для установки пакета coqui-ai/TTS, который содержит множество функций. Здесь мы лишь кратко покажем, как вызвать существующую модель TTS.
Сначала перечислите все модели TTS:
from TTS.api import TTS
print(TTS().list_models()) Выход:
'tts_models/multilingual/multi-dataset/xtts_v2',
'tts_models/multilingual/multi-dataset/xtts_v1.1',
'tts_models/multilingual/multi-dataset/your_tts',
'tts_models/multilingual/multi-dataset/bark',
'tts_models/bg/cv/vits',
'tts_models/cs/cv/vits',
'tts_models/da/cv/vits',
'tts_models/et/cv/vits',
'tts_models/ga/cv/vits',
'tts_models/en/ek1/tacotron2',
'tts_models/en/ljspeech/tacotron2-DDC',
'tts_models/en/ljspeech/tacotron2-DDC_ph',
'tts_models/en/ljspeech/glow-tts',
'tts_models/en/ljspeech/speedy-speech',
'tts_models/en/ljspeech/tacotron2-DCA',
'tts_models/en/ljspeech/vits',
'tts_models/en/ljspeech/vits--neon',
'tts_models/en/ljspeech/fast_pitch',
'tts_models/en/ljspeech/overflow',
'tts_models/en/ljspeech/neural_hmm',
'tts_models/en/vctk/vits',
'tts_models/en/vctk/fast_pitch',
'tts_models/en/sam/tacotron-DDC',
'tts_models/en/blizzard2013/capacitron-t2-c50',
'tts_models/en/blizzard2013/capacitron-t2-c150_v2',
'tts_models/en/multi-dataset/tortoise-v2',
'tts_models/en/jenny/jenny',
'tts_models/es/mai/tacotron2-DDC',
'tts_models/es/css10/vits',
'tts_models/fr/mai/tacotron2-DDC',
'tts_models/fr/css10/vits',
'tts_models/uk/mai/glow-tts',
'tts_models/uk/mai/vits',
'tts_models/zh-CN/baker/tacotron2-DDC-GST',
'tts_models/nl/mai/tacotron2-DDC',
'tts_models/nl/css10/vits',
'tts_models/de/thorsten/tacotron2-DCA',
'tts_models/de/thorsten/vits',
'tts_models/de/thorsten/tacotron2-DDC',
'tts_models/de/css10/vits-neon',
'tts_models/ja/kokoro/tacotron2-DDC',
'tts_models/tr/common-voice/glow-tts',
'tts_models/it/mai_female/glow-tts',
'tts_models/it/mai_female/vits',
'tts_models/it/mai_male/glow-tts',
'tts_models/it/mai_male/vits',
'tts_models/ewe/openbible/vits',
'tts_models/hau/openbible/vits',
'tts_models/lin/openbible/vits',
'tts_models/tw_akuapem/openbible/vits',
'tts_models/tw_asante/openbible/vits',
'tts_models/yor/openbible/vits',
'tts_models/hu/css10/vits',
'tts_models/el/cv/vits',
'tts_models/fi/css10/vits',
'tts_models/hr/cv/vits',
'tts_models/lt/cv/vits',
'tts_models/lv/cv/vits',
'tts_models/mt/cv/vits',
'tts_models/pl/mai_female/vits',
'tts_models/pt/cv/vits',
'tts_models/ro/cv/vits',
'tts_models/sk/cv/vits',
'tts_models/sl/cv/vits',
'tts_models/sv/cv/vits',
'tts_models/ca/custom/vits',
'tts_models/fa/custom/glow-tts',
'tts_models/bn/custom/vits-male',
'tts_models/bn/custom/vits-female',
'tts_models/be/common-voice/glow-tts'Я родом из английского («en») TTS Среди моделей я выбрал ту, которая звучала лучше. tts_models/en/ljspeech/glow-tts, как talkGPT4Все по умолчанию TTS, метод вызова следующий:
from TTS.api import TTS
# Инициализировать TTSМодель
tts = TTS(model_name="tts_models/en/ljspeech/glow-tts", progress_bar=False)
# Или используйте путь к модели для автономной загрузки.
tts = TTS(model_path="/path/to/model")
# Синтезируйте текст, соответствующий Аудио, и сохраните его в файл.
tts.tts_to_file(text="Hello there", file_path="hello.wav")Если модель не может быть загружена в коде Python по сетевым причинам, вы можете загрузить модель вручную, а затем указать model_path при инициализации TTS в качестве локального пути к модели.
3.2 Вызов моделей после GPT4All 2.5.0
На данный момент в формате gguf существует 15 моделей, каждая со своими особенностями:
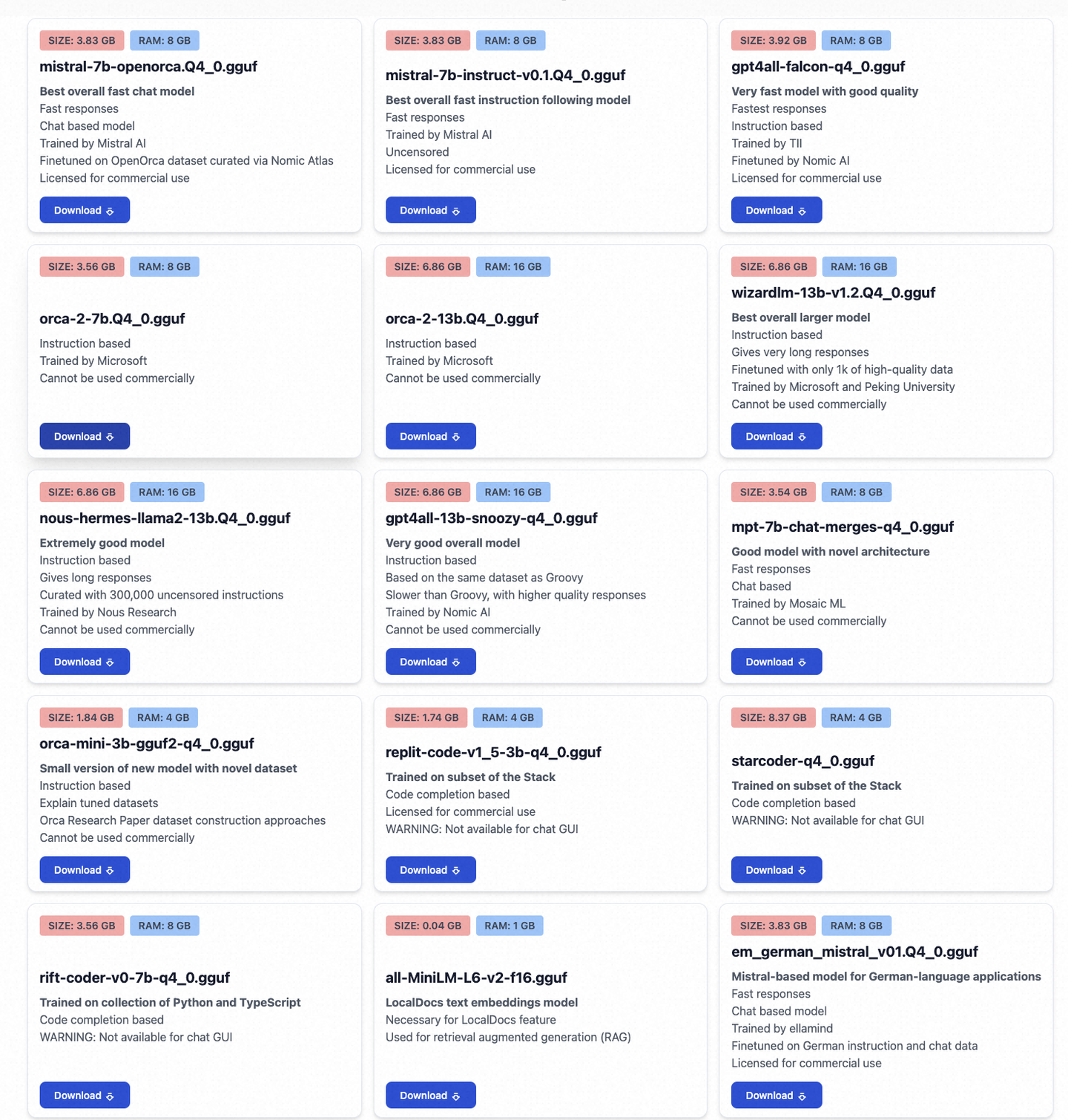
все Модельиз Подробности наздесь,Ниже я перечисляю все поддерживаемые модели.,Для справки при вызове из командной строки:
mistral-7b-openorca.Q4_0.gguf
mistral-7b-instruct-v0.1.Q4_0.gguf
gpt4all-falcon-q4_0.gguf
orca-2-7b.Q4_0.gguf
orca-2-13b.Q4_0.gguf
wizardlm-13b-v1.2.Q4_0.gguf
nous-hermes-llama2-13b.Q4_0.gguf
gpt4all-13b-snoozy-q4_0.gguf
mpt-7b-chat-merges-q4_0.gguf
orca-mini-3b-gguf2-q4_0.gguf
replit-code-v1_5-3b-q4_0.gguf
starcoder-q4_0.gguf
rift-coder-v0-7b-q4_0.gguf
all-MiniLM-L6-v2-f16.gguf
em_german_mistral_v01.Q4_0.ggufМетод вызова режима чата GPT4All также изменился. Новую версию нужно вызывать так:
gpt_model = GPT4All("mistral-7b-openorca.Q4_0.gguf", allow_download=True)
with gpt_model.chat_session():
answer = gpt_model.generate(prompt="hello")Необходимо создать явноchat_session context manager。
4. Резюме
Вышеупомянутое является основным содержанием этого обновления. Вообще говоря, оно использует более естественный TTS и обновляет код для поддержки последних изменений GPT4All.
Каждый может опробовать его и сообщить об ошибках.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
