Так вкусно! Я хочу что-нибудь получить!
Иллюстрированный обучающий сайт:https://xiaolincoding.com
Привет всем, я Сяолинь.
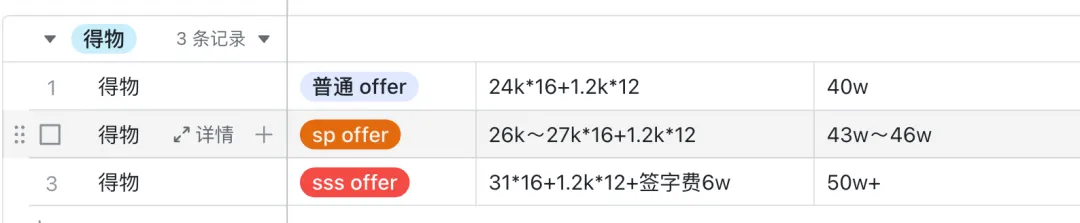
Уровень зарплаты при приеме на работу в Dewu такой же, как и в крупных компаниях, а предложения довольно высокие. Годовая зарплата выпускников кампуса начинается с 400 000, а самые высокие предложения находятся на уровне 500 000. Однако трудоемкость получения вещей будет относительно высокой, поэтому мы предлагаем более конкурентоспособную зарплату.
Многим студентам интересно, насколько сложно пройти собеседование с Дэву? Так,Поделитесь с вами сегодняЗадняя часть полученного объекта,На самом деле это почти так же сложно, как пройти собеседование в крупных компаниях.,Давайте рассмотрим три аспекта эссе из восьми частей + проект + алгоритм.

Исследованы очки знаний:
- mysql: оптимизация sql, ошибка индекса, дерево b+
- redis:одиннить、Выносливость、хозяин-рабкопировать、фильтр Блума、zset、Второйубийство
- сеть:tcp три рукопожатияипомахать рукой четыре раза、time_wait、httpsшифрование
- Операционная система:процессинить
- команда git: перебазировать и merge
MySQL
Каковы методы оптимизации медленных запросов SQL?
- проходить explain Результаты выполнения, просмотр sql да Нет индекса,Если вы не используете индекс,Рассмотрите возможность добавления индексов.
- Вы можете создать совместный индекс, используя,Внедрить оптимизацию индекса покрытия,Уменьшите возврат таблицы,Использование совместных индексов соответствует принципу крайнего левого сопоставления.,В противном случае индекс станет недействительным.
- Избегайте сбоев индекса, например, не используйте левое нечеткое сопоставление, вычисление функций, вычисление выражений и т. д.
- Для запросов к объединенным таблицам лучше всего использовать небольшую таблицу для управления большой таблицей.,А поля управляемой таблицы должны иметь индексы,Конечно, лучше всего создавать избыточные поля.,Избегайте запросов к совместным таблицам.
- против limit n,y Глубокая оптимизация запросов на подкачку может преобразовать запросы Limit в запросы для определенного местоположения: выберите * from tb_sku where id>20000 limit 10. Это решение подходит для таблиц с автоинкрементными первичными ключами.
- Таблица с множеством полей Воли разбивается на несколько отдельных таблиц.,Некоторые поля используются часто,несколько низкий,данные Когда количество большое,Может замедляться из-за нечасто используемого хранилища.,Вы можете рассмотреть возможность разделения
При каких обстоятельствах индекс вступит в силу?
- Для полей с относительно низкой дискриминацией, если индекс установлен, индекс не обязательно может использоваться.
- Когда мы используем левое и правое нечеткое сопоставление,это да like %xx или like %xx% Оба метода приведут к сбою индекса;
- Когда мы используем функции для столбцов индекса в условиях нашего запроса, индекс не будет выполнен.
- Когда мы выполняем вычисление выражения для столбца индекса в условии запроса, индекс использовать нельзя.
- MySQL Когда существование сталкивается со сравнением строки и числа, оно автоматически преобразует строку в число, а затем сравнивает ее. Если строка да индексирует столбец, а входной параметр да номер в условном операторе, то индексный столбец подвергнется неявному преобразованию типа из-за неявного преобразования типа дапроходить CAST Реализация функции эквивалентна использованию функции в столбце индекса, поэтому это приведет к сбою индекса.
- Чтобы правильно использовать индекс сустава, нужно следовать принципу крайнего левого сопоставления.,это да Сопоставление индексов выполняется в порядке слева направо.,В противном случае индекс станет недействительным.
Зачем использовать дерево B+ для индекса?
- B+Tree vs B Tree:B+Tree существуют только конечные узлы, которые хранят данные, в то время как B Дерево Нелистовым узлам также необходимо хранить данные, поэтому B+Tree Объем данных одного узла меньше и существует на том же диске. I/O С учетом количества запросов можно запросить больше узлов. Кроме того, B+Дерево Листовые узлы используют соединение с двойным связным списком, которое подходит для MySQL последовательный поиск на основе диапазона, распространенный в B Дерево не может этого сделать.
- B+Tree против двоичного дерева:Для тех, у кого есть N отдельный листовой узел B+Tree, сложность его поиска равна O(logdN), где d Указывает, что максимальное количество дочерних узлов, разрешенное узлом, равно d индивидуальный。существовать В реальном применении, d Значение да больше 100, что гарантирует, что даже когда данные достигают десятков миллионов, B+Tree Высота остается существовать 3~4 уровень или около того, то есть нужно выполнить только одну операцию запроса 3~4 диск I/O Целевые данные могут быть запрошены в ходе операции. А количество дочерних узлов каждого родительского узла двоичного Дерева может быть только да. 2 индивидуальный, то есть сложность его поиска O(logN), что уже лучше, чем B+Tree Гораздо выше, поэтому двоичное Дерево извлекает диск, на котором находятся целевые данные. I/O Еще раз.
- B+Tree vs Hash:Hash существования очень эффективен при выполнении эквивалентных запросов, а сложность поиска О(1). Однако, Hash Таблица не подходит для запросов диапазона. Она больше подходит для эквивалентных запросов. Это тоже верно. B+Tree индекс, чем Hash Табличные индексы имеют более широкий спектр применимых сценариев.
сеть
Трехстороннее рукопожатие TCP и четырехсторонняя волна?
три рукопожатия

- Вначале клиент Сервер был в CLOSE состояние. Во-первых, да Сервер активно контролирует определенный индивидуальный порт. LISTEN состояние
- клиент случайным образом инициализирует серийный номер (client_isn), воля этот серийный номер помещается в TCP В поле "серийный номер" шапки поставьте SYN Положение отметки 1, означает SYN сообщение. Затем поместите Первыйиндивидуальный SYN Сообщение отправляется на Сервер, указывая, что соединение с Сервером инициировано. Сообщение не содержит данных уровня приложения, а затем находится клиент. SYN-SENT состояние。
- Серверполучен от клиента SYN После отправки сообщения сначала Сервер также случайным образом инициализирует свой серийный номер (server_isn), а Воля этот серийный номер заполняет. TCP В поле «серийный номер» заголовка следует TCP Заполните поле «Номер подтверждения» в шапке. client_isn + 1, Затем поместите SYN и ACK Положение отметки 1. Наконец, сообщение отправляется клиенту. Сообщение не содержит данных уровня приложения, а затем подключается сервер. SYN-RCVD состояние。
- После получения сообщения Сервера клиент,Также ответьте на последнее индивидуальное ответное сообщение Серверу.,первый Ответное сообщение TCP первая часть ACK Положение отметки 1 , затем заполните поле «Номер ответа на подтверждение» server_isn + 1и, наконец, сообщение отправляется на Сервер. На этот раз сообщение может передать клиенту данные на Сервере, а затем клиент окажется внутри. ESTABLISHED состояние。
- Серверполучен от клиент После ответного сообщения,Также введите состояние ESTABLISHED.
помахать рукой четыре раза
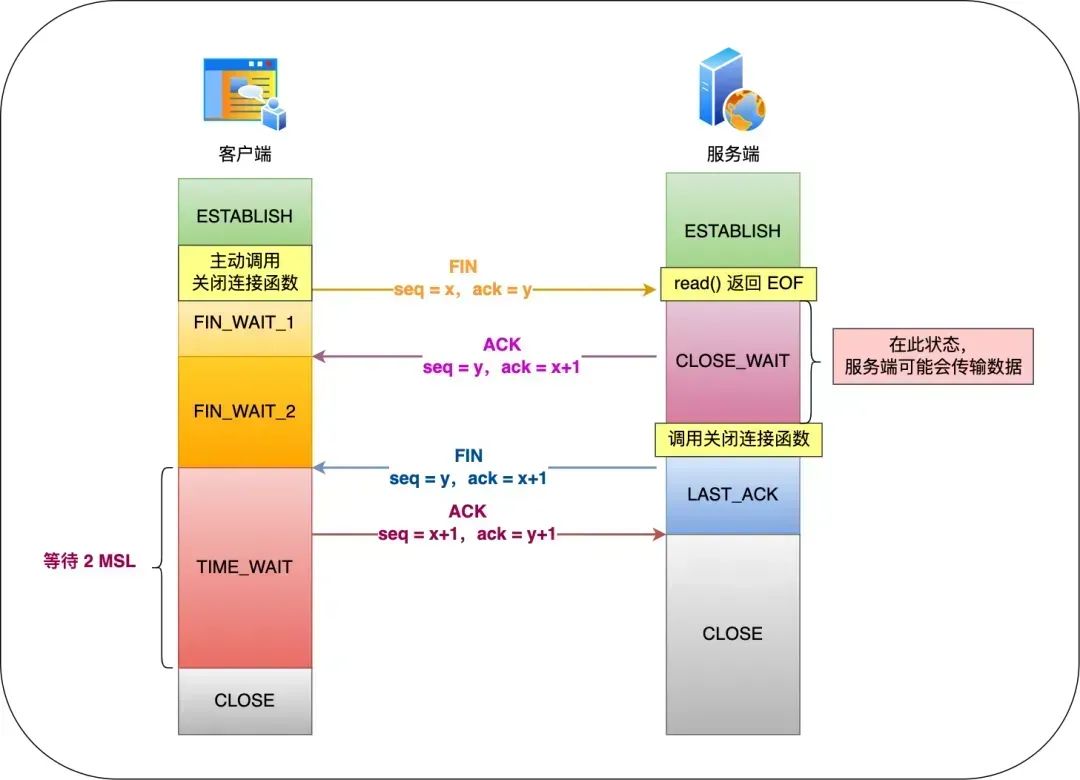
Конкретный процесс:
- клиент активно вызывает функцию закрытия соединения,Сообщение FIN будет отправлено через да.,этотиндивидуальный FIN Сообщение представитель клиента больше не будет отправлять данные, введите FIN_WAIT_1 состояние;
- Получено FIN сообщение, а затем немедленно ответьте одним индивидуальным ACK Подтвердите сообщение, в это время войдет Сервер CLOSE_WAIT состояние。существоватьполучать FIN сообщение, TCP Стек протоколов будет FIN В пакет вставляется индивидуальный терминатор файла. EOF в буфер приема приложение Сервера может передать read вызоввосприниматьэтотиндивидуальный FIN Сумка,этотиндивидуальный EOF будетПомещать существующие после других полученных данных, поставленных в очередь.,так надо продолжать read Прием буфера полученных данных;
- затем,когда Серверсуществовать read Читая данные, вы, естественно, прочитаете их в конце. ЭОФ, тогда read() вернет 0. В это время, если у серверного приложения есть данные для отправки, оно вызовет функцию для закрытия соединения после отправки данных. Если у серверного приложения нет данных для отправки, оно может напрямую вызвать функцию. чтобы закрыть соединение.,В это время Сервер отправит пакет FIN.,этотиндивидуальный FIN Сообщение означает, что Сервер больше не будет отправлять данные и будет в режиме LAST_ACK состояние;
- Клиент получает Сервериз FIN упаковать и отправить ACK Подтвердите отправку пакета на Сервер, затем войдет Клиент Воля. TIME_WAIT состояние;
- Серверполучать ACK После подтверждения пакета вы вводите окончательный CLOSE состояние;
- клиентпройти 2MSL Через время также введите CLOSE состояние;
Давайте поговорим о TIME_WAIT
MSL да Maximum Segment Lifetime,Максимальное время выживания пакета,Это максимальное время существования любого сообщения.,Превосходитьэтотиндивидуальныйсообщение времени Волявыброшенный。потому что TCP Сообщение основано на да IP соглашение, и IP Есть один в голове TTL поле, да IP Максимальное количество маршрутов, через которые может пройти дейтаграмма. Это значение уменьшается каждый раз, когда она проходит через обрабатывающий ее маршрутизатор. 1, когда это значение 0 тогда дейтаграмма будет отброшена при отправке ICMP Сообщение уведомляет исходный хост.
MSL и TTL Разница: MSL Единица измерения — время, а TTL да Количество прыжков, пройденных по маршруту. так MSL Оно должно быть больше или равно TTL Потребление 0 время,Чтобы гарантировать, что сообщение было уничтожено естественным путем。TTL Значение обычно да 64,Linux Воля MSL установлен на 30 секунды, значит Linux Считается, что пакет данных проходит через 64 время роутера не превысит 30 Второй,если оно превышает,Считается, что сообщение исчезло.。
TIME_WAIT ждать 2 раз MSL,Более разумное объяснение: в сети может существовать пакет данных отправителя.,Когда пакеты данных отправителя обрабатываются получателем, ответ будет отправлен другой стороне.,такЧтобы идти туда и обратно, нужно ждать 2 раза больше времени.。
Например, если пассивная закрывающая сторона не получает последнее сообщение ACK для отключения, она инициирует тайм-аут и повторно отправляет сообщение FIN. После того как другая сторона получит FIN, она повторно отправит ACK пассивной закрывающей стороне. и один идет в самый раз.
можно увидеть Продолжительность 2MSL этот Что Реальностьда Взаимнокогда ВРазрешить потерю пакетов хотя бы один раз。например,нравиться ACK в MSL Если он утерян внутри, пассивная сторона отправит его повторно. FIN Будет в 2 индивидуальный MSL Прибудет через TIME_WAIT Соединения с сохранением состояния могут справиться.
Почему бы не да 4 или 8 MSL изчас Длинный?Вы можете себе представитьиндивидуальныйоставлять Сумкаставка достигает 100%одинизупссеть,Вероятность потери двух последовательных пакетов составляет всего один из 10 000.,Вероятность этого слишком мала,Игнорировать проблему выгоднее, чем ее решать.
2MSL времядаотКлиент получает FIN Отправить позже ACK Начало времени。еслисуществовать TIME-WAIT время, потому что клиент ACK не было передано на сервер, и клиент получил повторно отправленное сервером сообщение. FIN сообщение, затем 2MSL время Воля сброс。
существовать Linux в системе 2MSL По умолчанию да 60 Второй,Итак, одининдивидуальный MSL это да 30 Второй.Linux Система остаетсясуществовать TIME_WAIT время фиксировано 60 Второй。
его определениесуществовать Linux Имя в коде ядра TCP_TIMEWAIT_LEN:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
state, about 60 seconds */
Если вы хотите изменить длину TIME_WAIT, вы можете изменить только значение TCP_TIMEWAIT_LEN в коде ядра Linux и перекомпилировать ядро Linux.
Процесс шифрования HTTPS
традиционный TLS Рукопожатие в основном используется RSA Алгоритм достижения обмена ключами,существовать Воля TLS Когда сертификат развертывается Сервером, файл сертификата фактически является открытым ключом да Сервера, который будет существовать. TLS фаза рукопожатия перешла наклиент,Закрытый ключ Сервера всегда хранится в существующем Сервере.,Обязательно убедитесь, что закрытый ключ невозможно украсть.
существовать RSA В алгоритме согласования ключей клиент генерирует случайный ключ, шифрует его с помощью открытого ключа сервера, а затем передает на сервер. Согласно алгоритму асимметричного шифрования, зашифрованное сообщение с открытым ключом может быть расшифровано только с помощью закрытого ключа. Таким образом, после того, как сервер расшифровает его, обе стороны получат один и тот же ключ, а затем используют его для шифрования сообщения приложения.
Я использовал инструмент Wireshark для захвата процесса рукопожатия TLS с обменом ключами RSA. Как вы можете видеть ниже, всего существует четыре рукопожатия:
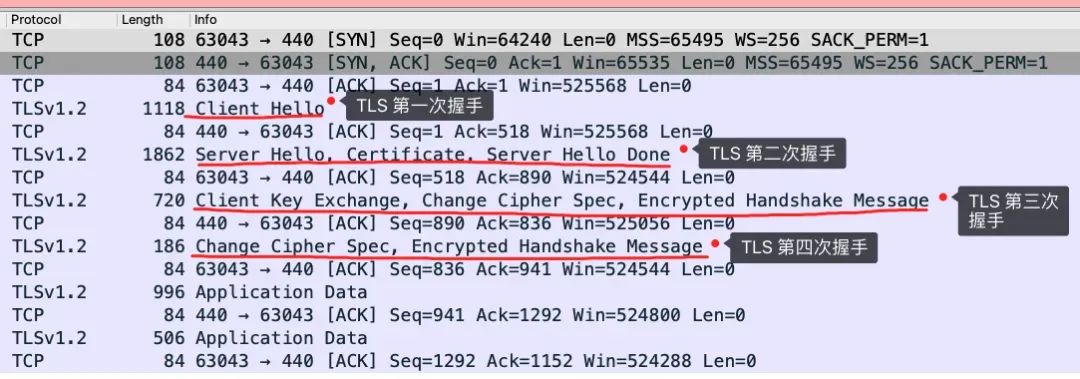

Первое рукопожатие TLS
первый,Зашифрованный запрос связи, инициированный клиентом серверу.,это да ClientHello просить. существования На этом этапе клиент в основном отправляет на сервер следующую информацию:
- (1) При поддержке клиента TLS Соглашение Версия, как TLS 1.2 Версия。
- (2)клиент Производствоизслучайное число(Client Random), который позже используется для генерации одного из условий «сессионного ключа».
- (3) Список наборов шифров, поддерживаемых клиентом, например алгоритм шифрования RSA.
Второе рукопожатие TLS
сервер После получения запроса от клиента,Отправить ответ клиенту,это да Север, Здравствуйте. Содержание ответа сервера следующее:
- (1) Подтвердите TLS Соглашение Версия, как Если браузер не поддерживает,Шифрованная связь отключена.
- (2) Случайное число (Server Random), созданное сервером, также является одним из условий для создания «сеансового ключа» позже.
- (3) Список подтвержденных наборов шифров, например RSA алгоритм (4) Цифровой сертификат сервера.
TLS Нет.три рукопожатия
клиент После получения ответа от сервера,первыйпроходить Браузерили Операционная системасерединаиз CA Открытый ключ подтверждает подлинность цифрового сертификата сервера.
Если с сертификатом проблем нет,клиентвстречаПолучите открытый ключ сервера из цифрового сертификата,Затем используйте его для шифрования сообщения,Отправьте на сервер следующее сообщение:
- (1) Случайное число (предварительный мастер-ключ). Случайное число будетсервера зашифровано с помощью открытого ключа.
- (2) Уведомление об изменении алгоритма шифрования связи, указывающее, что все последующие сообщения будут зашифрованы с помощью «сеансового ключа».
- (3) уведомление об окончании рукопожатия клиента,Указывает, что фаза установления связи клиента завершилась. Этот элемент также суммирует вхождения всего предыдущего контента.,Используется для проверки сервера.
Случайное число первого элемента выше является третьим случайным числом фазы рукопожатия.,Будет отправлено на Сервер,Итак, все эти случайные числа Клиенти Сервер одинаковы.
сервериклиент С этими тремя индивидуальными случайными числами (Client Random、Server Random、pre-master ключ), а затем использовать алгоритм шифрования, согласованный обеими сторонами, для создания «сеансового ключа» для этого обмена данными.。
Четвертое рукопожатие TLS
серверполучатьклиентиз Нет.трииндивидуальныйслучайное число(pre-master key), «сеансовый ключ» для этого соединения рассчитывается с помощью согласованного алгоритма шифрования.
Затем отправьте клиенту последнее сообщение:
- (1) Уведомление об изменении алгоритма шифрования связи,Это означает, что все последующие сообщения шифруются «сеансовым ключом».
- (2) уведомление об окончании серверного рукопожатия,Указывает, что фаза установления связи сервера закончилась. Этот элемент также суммирует вхождения всего предыдущего контента.,Используется для проверки.
До сих пор,всеиндивидуальный TLS Фаза рукопожатия окончена. Далее клиент-сервер вступает в зашифрованную связь, просто используйте обычный HTTP Протокол просто использует «сеансовый ключ» для шифрования контента.
Операционная система
Разница между потоками и процессами
- существенная разница:процессда Операционная система Базовая единица распределения ресурсов и нитьда Базовая единица планирования выполнения задач.
- существоватьнакладные расходы:Каждыйиндивидуальныйпроцесс Все независимыизкодиданныекосмос(контекст программы),Переключение между программами потребует больших затрат, но его можно рассматривать как упрощенный процесс;,Та же категория нить общий код иданные места,Каждая индивидуальность имеет свой независимый стек выполнения и счетчик программ (ПК).,Накладные расходы на переключение между нит невелики
- Стабильность:процесссерединаопределенныйиндивидуальныйнитьеслирухнул,Это может привести к сбою всего индивидуального процесса. И дочерний процесс в процессе вылетает,На другие процессы это не повлияет.
- Распределение памяти:системасуществоватьбегатьизчасждатьвстречадля Каждыйиндивидуальныйпроцессраспространять Неттакой жеиз Памятькосмос;И правильнонитьс точки зрения,Кроме процессора,Система не выделяет память для нит (ресурсы, используемые нит, берутся из ресурсов процесса, которому он принадлежит),нить Только ресурсы могут быть разделены между группами
- отношения включения:Нетнитьизпроцессможно рассматривать какдаодиннитьиз,еслиодининдивидуальныйпроцесс Сколько внутрииндивидуальныйнить,Тогда процесс выполнения — это не одна строка.,И да завершается несколькими строками (нит) вместе, что является частью процесса нитьда;,Так нить еще называют облегченным процессом или облегченным процессом.
Git
Разница между git rebase и merge
- Rebase(Перебазировать)да Воляодининдивидуальныйна веткеиз Отправляйте по одномуиндивидуальныйобратиться к другомуодининдивидуальныйна ветке,Делает историю коммитов более линейной. При выполнении перебазирования,Git переместит все коммиты, начиная с общего предка целевой ветки и исходной ветки, в последнее местоположение целевой ветки. Этот процесс можно рассматривать как каждую фиксацию исходной ветки в целевой. суммируя,Перебазирование может быть организовано линейно в хронологическом порядке.
- Merge(слить)да Волядваиндивидуальныйна веткеизкодпредставлять на рассмотрение历史слитьдляодининдивидуальныйновыйизпредставлять на рассмотрение。существоватьосуществлятьmergeчас,Git создаст новый коммит слияния,Воля Истории коммитов двух отдельных ветвей связаны друг с другом. так,Изменения обеих веток будут включены в коммит слияния. Объединенная история сохранит записи коммитов каждой отдельной ветки.
Redis
Однопоточная модель Redis
Redis одиннитьобратитесь кизда「перениматьклиентпросить->анализироватьпросить ->руководитьданные Операции чтения и записи->отправлятьданные Даватьклиент」этотиндивидуальныйпроцессда Зависит отодининдивидуальныйнить(хозяиннить)завершитьиз,Это также причина, по которой мы часто говорим, что Redis одинок. Но да,Программа Redis непростая.,Когда Redis начнет существовать,давстречаНачать фоновый поток(BIO)из:
- Redis существовать 2.6 Версия,встречазапускать 2 индивидуальный фон нить, обрабатывать закрытие файлов и AOF соответственно Эти две задачи по чистке диска;
- Redis существовать 4.0 Версияпосле,Добавлен новый бэкэнд нить,Используется для асинхронного освобождения памяти Redis.,это да lazyfree нит. Например, выполните unlink key / flushdb async / flushall async В ожидании команды эти операции удаления будут переданы на выполнение в фоновом режиме. Преимущество в том, что это не вызовет. Redis Главное нить лаг. Поэтому, когда мы хотим удалить большой key когда не использовать del Команда удаления, потому что что del дасуществовать основную обработку, это приведет к Redis Основная нить задержки, поэтому мы должны использовать unlink команда для асинхронного удаления больших ключей.
Однострочный режим до Redis версии 6.0 выглядел следующим образом:
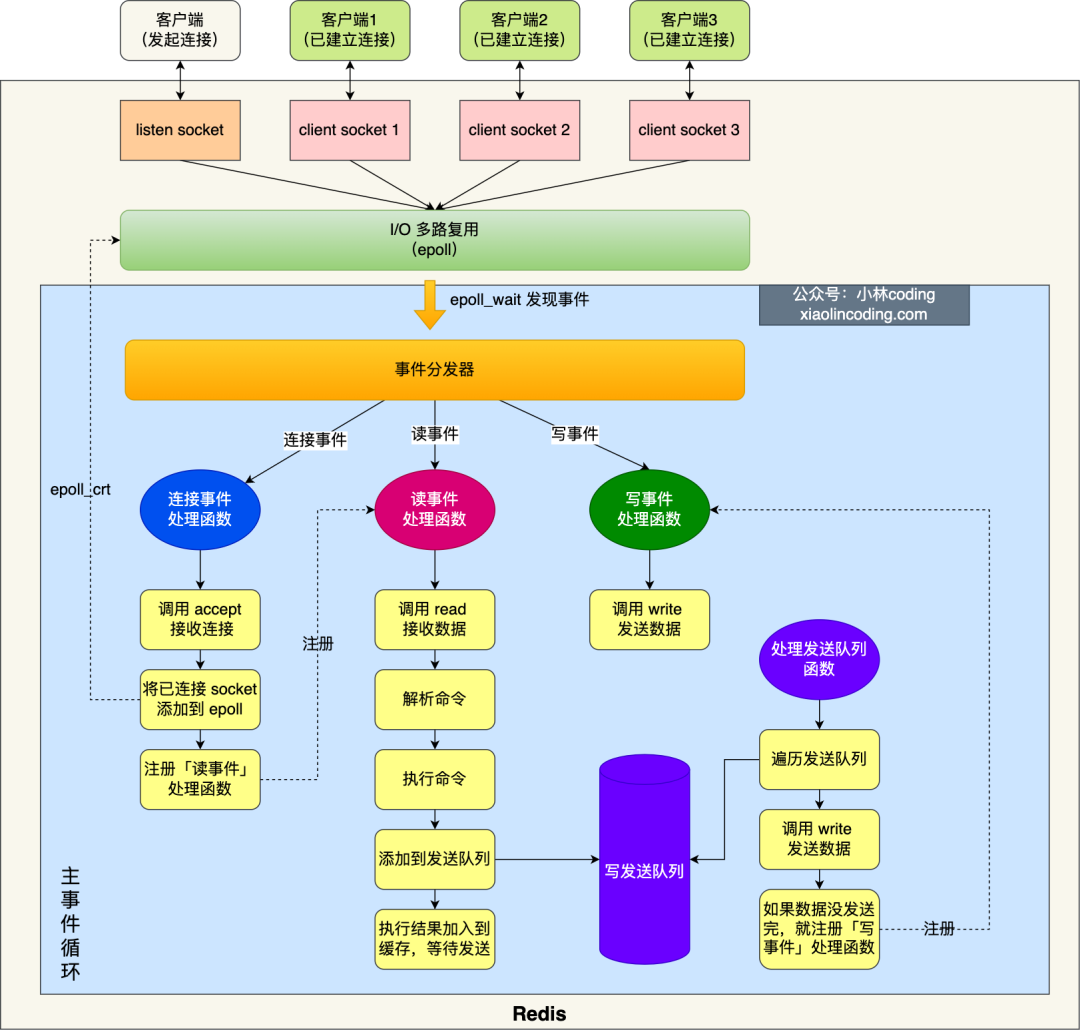
Синяя часть изображения — это цикл событий.,да отвечает за главное,можно увидетьсетьI/O и обработка команд - это все да нить. Редис Во время инициализации будут выполнены следующие действия:
- Сначала позвоните epoll_create() создаватьодининдивидуальный epoll Объект ивызов socket() создаватьодининдивидуальный Сервер socket
- Затем позвоните bind() Привязать порт ивызов listen() следить за socket;
- Тогда Волявызов epoll_ctl() Воля listen socket присоединиться к epoll, зарегистрируйтесь одновременно "события" подключения」Функция обработки。
После инициализации,хозяиннить Просто введитеодининдивидуальныйфункция цикла событий,В основном делайте следующие вещи:
- первый,ПервыйвызовОбработка функции очереди отправки,Проверьте, есть ли какая-либо задача в очереди отправки да,Если есть задача отправки,нопроходить write Функция Воляклиент отправляет данные в буферную область. Если этот раунд данных не был отправлен, она зарегистрирует запись. событие Функция обработки,ждать epoll_wait Процесс после обнаружения того, что он доступен для записи 。
- Далее позвоните epoll_wait функцияждатьсобытиеизприбытие:
- еслидасобытия подключенияприбытие,новстречавызовсобытия подключения Функция обработки,Долженфункциявстреча Делатьэтотнекоторые вещи:вызов accpet Подключайтесь socket -> вызов epoll_ctl Воля на связи socket присоединиться к epoll -> зарегистрироваться「прочитать функция обработки события;
- еслидапрочитать событиеприбытие,новстречавызовпрочитать событие Функция обработки,Долженфункциявстреча Делатьэтотнекоторые вещи:вызов read Получить данные, отправленные клиентом -> команда анализа -> команда обработки -> Объект Воляклиент добавлен в очередь отправки -> Результат выполнения Воля записывается в область ожидания буфера отправки и отправляется;
- еслиданаписать событиеприбытие,новстречавызовнаписать функцию обработки событий,Долженфункциявстреча Делатьэтотнекоторые вещи:проходить write Функция Воляклиент отправляет данные в буферную область. Если этот раунд данных не был отправлен, он продолжит регистрацию. событие Функция обработки,ждать epoll_wait Процесс после обнаружения того, что он доступен для записи 。
Устойчивость RDB и AOF
Redis Все операции чтения и записи выполняются в памяти, поэтому Redis Производительность будет высокой, но когда Redis После перезапуска данные в памяти будут потеряны. Чтобы гарантировать, что данные в памяти не будут потеряны, Redis. Реализован механизм сохранения данных. Этот индивидуальный механизм будет хранить данные на диске, чтобы они существовали. Redis Перезагрузка может восстановить исходные данные с диска. Редис Существует три метода сохранения данных:
- Журнал АОФ:Каждыйосуществлятьодинкоманда операции записи полосы,Просто напишите команду как дополнение к индивидуальному файлу;
- Снимок RDB:Воляопределенныйодинчасвырезатьиз Памятьданные,Запись на диск в двоичном формате;
- Гибридный подход к сохранению:Redis 4.0 Новый метод объединяет AOF и RBD преимущества;
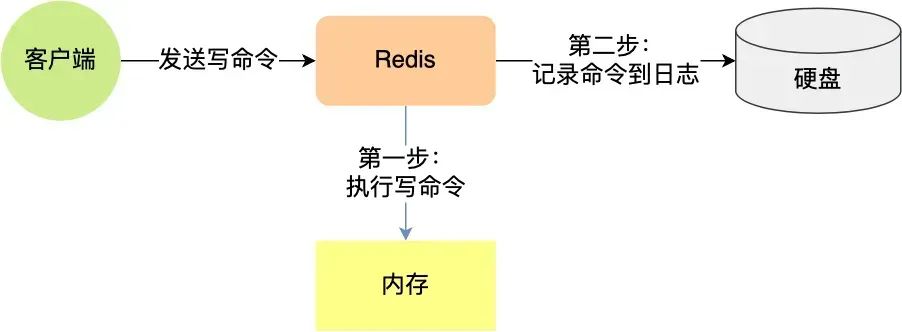
Как реализуется Журнал АОФда?
Redis После выполнения команды операции записи эта команда будет добавлена к отдельному файлу, а затем Redis При перезапуске команды, записанные в файле, будут прочитаны, а затем поочередно будут выполняться команды для восстановления данных.
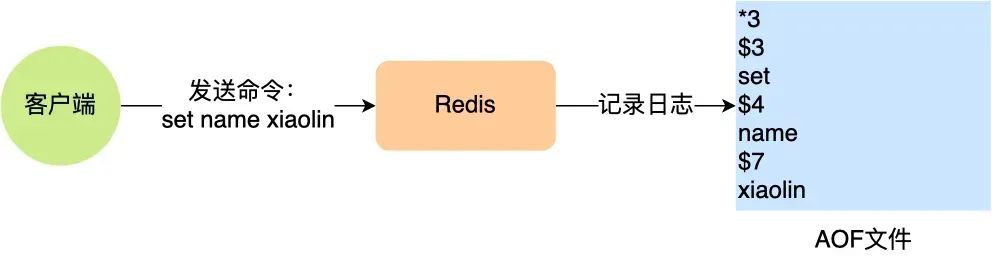
Здесь я использую "_set name команда xiaolin_" в качестве примера, Redis Выполнено После этой команды запись существовала AOF Содержимое журнала следующее:
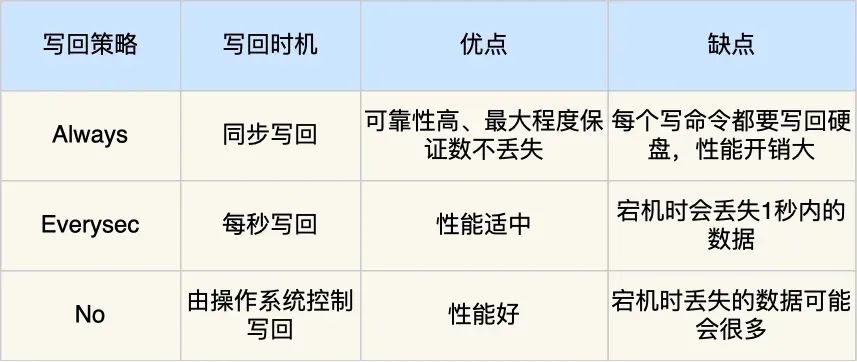
Redis предоставил 3 Стратегия обратной записи на жесткий диск, существовать Redis.conf в файле конфигурации appendfsync Элементы конфигурации могут иметь следующее 3 Параметры могут быть заполнены:
- Always,Это индивидуальное слово означает да «всего да».,Это означает, что после выполнения каждой команды операции записи,синхронный Воля Журнал АОФданные осуществляет обратную запись на жесткий диск;
- Everysec,Значение этого слова индивидуальный — «каждый гражданин».,Это означает, что после выполнения каждой команды операции записи,Первый Воля Команда записана в AOF буфер ядра файла, а затем каждый второй Второй Воляв Содержимое буфера записывается обратно на жесткий диск;
- No,значит не могу помочь Redis Контроль времени обратной записи на жесткий диск, переданный в Операционную система Управление обратной записьюизчасмашина,это да Каждый Написать команду операцииосуществлять После,Первый Воля Команда записана в AOF Буфер ядра файла, который затем используется Операционной система определяет, когда содержимое буфера Воля записывается обратно на жесткий диск.
я тоже это поставил 3 Преимущества и недостатки стратегии обратной записи сведены в таблицу:
Как реализуется Снимок RDBда?
потому что Журнал АОФ записывает команду операции, а не фактические данные, поэтому используйте AOF При восстановлении после сбоя необходимо выполнить все журналы один раз. AOF Логов очень много, что неизбежно приведет к Redis Операция восстановления идет медленно.
Чтобы решить эту проблему, Redis добавлен Снимок РДБ. Так называемый «Снимок» предназначен для записи определенного момента. Например, когда мы фотографируем пейзаж, изображение и информация этого момента записываются на фотографии. Итак, Снимок RDB записывает воспоминания об определенном моменте и записывает фактическую память, а AOF документ Записыватьизда Командная операцияизбревно,и Неактуальные данные。
поэтомусуществовать Redis При восстановлении данных RDB Восстановление данных более эффективно,чем AOF выше,потому чтопрямой Воля RDB Просто прочитайте файл в память, не нужно делать что-то вроде AOF В этом случае для восстановления данных потребуются дополнительные шаги по выполнению команд операции.
Redis предоставилдваиндивидуальныйкоманда для генерации RDB файлы, соответственно да save и bgsave, разница между ними в том, что существование выполняется в да существовании "главное нить":
- Выполнено save команда, она будет сгенерирована RDB файл, поскольку и выполняет команду операции, существует так же, как индивидуальность, поэтому, если вы напишете RDB документвремяслишком долго,Заблокирует основной поток;
- Выполнено bgsave команда создаст отдельный подпроцесс для генерации RDB документ,этот Это нормальноИзбегайте блокировки основного потока;
Базовая реализация ZSet в Redis
Zset типиз Первый этажданныеструктурада Зависит отСжатый список или список пропускаРеальность现из:
- Если количество элементов в упорядоченном множестве меньше 128 индивидуальный, а значение каждого индивидуального элемента меньше 64 Байты, Редис встречаиспользоватьсжатый список作для Zset Базовая структура данных типа;
- Если элементы упорядоченного набора не соответствуют вышеуказанным условиям, Redis встречаиспользоватьТаблица прыжков作для Zset Базовая структура данных типа;
существовать Redis 7.0 , структура данных сжатого списка устарела и передана listpack Структура данных реализована.
Процесс репликации Redis master-slave
Первый процесс синхронизации между ведущим и ведомым можно разделить на три этапа:
- Первый этап – создание связи、Согласование синхронизации;
- На втором этапе главный сервер синхронизирует данные с подчиненным сервером;
- На третьем этапе главный сервер отправляет новую команду операции записи подчиненному серверу.
Чтобы дать вам более четкое представление об этих трех этапах, я нарисовал картинку.
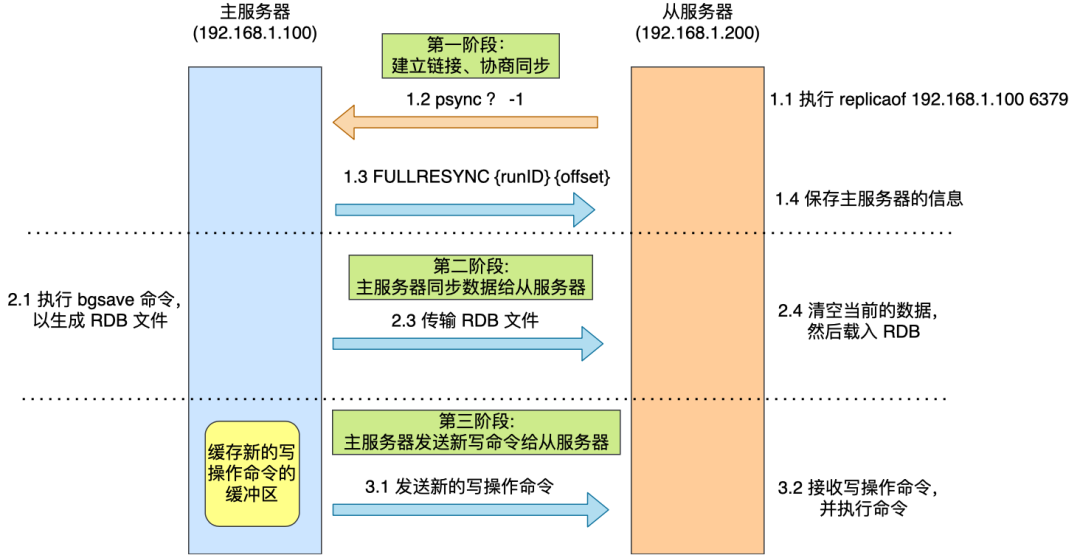
Далее я буду подробно представлять, что делается на каждом этапе.
Первый этап: установление связей и согласование синхронизации
После выполнения команды репликации подчиненный сервер отправит команду psync на главный сервер, чтобы указать, что требуется синхронизация данных.
Команда pync содержит два параметра:,соответственнодаRunID главного сервера иСмещение прогресса копирования。
- runID,Каждыйиндивидуальный Redis Серверсуществовать автоматически генерирует случайного человека при запуске. ID чтобы однозначно идентифицировать себя. При первой синхронизации с серверимастер-сервером, потому что чтоя не знаю главный сервер run ID,так Воля Чтоустановлен на "?"。
- offset,Указывает ход копирования,При первой синхронизации,Его значение равно -1.
После получения команды psync главный сервер будет использовать FULLRESYNC в качестве ответной команды для возврата к другой стороне.
И эта индивидуальная команда ответа принесет два индивидуальных параметра: RunID главного сервера и основного сервера текущий. копирование. После получения ответа от сервера записываются эти два индивидуальных значения.
FULLRESYNC реагировать на командыизнамерениедаиспользоватьПолная копияиз Способ,это дахозяинсервервстречаположить всеизданные Всесинхронный Даватьотсервер。
Поэтому первый этап работы — подготовка к полному тиражированию.
Так как же именно синхронизировать все данные? Мы можем перейти ко второму этапу.
Этап 2. Главный сервер синхронизирует данные с подчиненным сервером.
Затем главный сервер выполнит команду bgsave для создания файла RDB, а затем отправит файл на подчиненный сервер.
После получения файла RDB с сервера сначала будут очищены текущие данные, а затем будет загружен файл RDB.
Здесь следует отметить одну вещь: главный сервер генерирует RDB этотиндивидуальныйпроцессда Нет Заблокирует основной потокиз,потому что bgsave Команда да порождает отдельный дочерний процесс для генерации RDB Работа с файлами выполняется асинхронно, вот так Redis Команды по-прежнему могут обрабатываться в обычном режиме.
Однако команда операции записи в течение этого периода не записывала вновь созданную RDB. несовместимы.
Таким образом, чтобы обеспечить согласованность главного-подчиненного сервера,Mainсуществовать серверовать Следующие три отдельных промежутка времени Воля получил команду операции записи,написать replication buffer в буфере:
- основной сервергенерируется RDB Срок действия документа;
- В течение периода, когда главный сервер отправляет файл RDB подчиненному серверу;
- 「отсервер」нагрузка RDB Срок действия документа;
Третий этап: главный сервер отправляет новую команду операции записи подчиненному серверу.
существоватьосновной сервергенерируетсяиз RDB После отправки файла он принимается с сервера RDB После файла сбросьте все старые данные, Воля RDB Данные загружаются в память. Заканчивать RDB После загрузки хосту будет отправлено индивидуальное подтверждающее сообщение.
затем,хозяинсервер Воля replication buffer Команда операции записи, записанная в буфере, отправляется на подчиненный сервер, и подчиненный сервер выполняет команду главного сервера. replication buffer Команда отправляется в буфер, тогда данные главного и подчиненного серверов будут согласованы.
На этом первая синхронизация главного-подчиненного сервера завершена.
Какова основная реализация фильтра Блума?
Фильтр Блума состоит из «все начальные значения 0 растровый массив "и" N индивидуальный Хэшфункция」два Частично составлено。когданассуществоватьписатьданные Библиотекаданныечас,существуют Фильтр Блума с индивидуальной маркировкой,Таким образом, в следующий раз, когда вы запросите существующую базу данных данных,,Просто запросите фильтр Блума,Если запрос обнаруживает, что данные не отмечены,иллюстрировать Нетсуществоватьданные Библиотекасередина。
Фильтр Блума пройдет 3 индивидуальный Отметка о завершении операции:
- Первый шаг — использовать N индивидуальная хэш-функция выполняет хэш-вычисление данных соответственно, и мы получаем N индивидуальный Хэш-значение;
- Второй шаг, что получил Воля на первом шаге N отдельная пара хэш-значенийрастровый массивиз Длина по модулю,Получите соответствующую позицию каждого отдельного значения хеш-значения существующего растрового массива.
- Шаг 3,Воля Каждыйиндивидуальный Хэш-значениесуществоватьрастровый массивизпереписываться Значение местоположения выбрано на 1;
В качестве примера предположим, что имеется массив растровых изображений длиной 8. Хэш-функция 3 индивидуальныйизфильтр Блума。
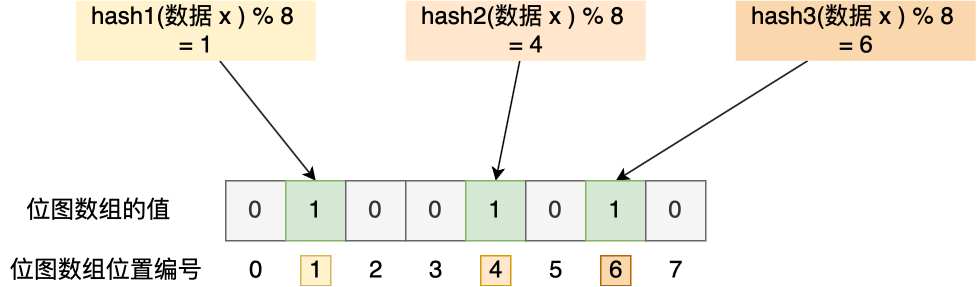
существоватьданные Библиотекаписатьданные x После этого поместите данные x При пометке Bloom существует фильтр, данные x будет 3 индивидуальная хеш-функция рассчитывается соответственно 3 индивидуальный хеш, то существование на 3 отдельная пара хэш-значений 8 Возьмите по модулю, предполагая, что результат по модулю равен 1, 4, 6, а затем поместите первый бит массива растровых изображений 1、4、6 Значение местоположения выбрано на 1。Когда приложение хочет запросить данные x да Нет библиотеки данных, фильтру Блума нужно только найти первый растровый массив 1、4、6 Является ли значение да позиции всем 1. Пока есть индивидуальный 0, считается,что данные x Нетсуществоватьданные Библиотекасередина。
фильтр Блума Зависит от Вда基ВХэшфункция Реальность现查找из,Эффективный поискизтакой жечасВозможность коллизий хешей,напримерданные x иданные y Может быть, все упадетсуществовать Нет. 1、4、6 Местоположение, по сути, может отсутствовать в существующей библиотеке данных. да, имеет место неправильное суждение о существовании.
так,Фильтр Блума запроса говорит, что данные депозита существуют,и Нетодинопределенное доказательстводанные Библиотекасерединажитьсуществоватьэтотиндивидуальныйданные,нода Найденныйданные Нетжитьсуществовать,данные Библиотекасерединаодин Учреждение Нетжитьсуществоватьэтотиндивидуальныйданные。
Как использовать Redis ZSet для реализации списка ранжирования сначала с использованием оценок, а затем сортировки по времени?
ZSet Redis поддерживает оценку двойного типа,Также да8 байт,общий 64 немного, счет можно разделить на следующее:
0 (старший бит не используется) | 0000000 00000000 0000000 (22 бита представляют оценку) | 0 00000000 00000000 00000000 00000000 00000000 (41 бит представляют метку времени)
потому чтосортироватьпервый Сортировать по баллам и нажатьчас Между строками,Так что балл высокий существует,временная метка низкого существования,Таким образом, независимо от значения метки времени,,Чем больше очков,Значение, представленное 64 битами, больше.
Когда оценки одинаковы,Время должно быть отсортировано в порядке возрастания.,это дачас Чем раньше временная меткаиз,Его значение оценки должно быть больше,Поэтому мы не можем просто использовать 41-битный формат для хранения временных меток.,Вместо этого он должен хранить значение, которое со временем становится меньше.
Поскольку рейтинги будут иметь цикл,Нравится список на неделю за неделю,Ежемесячный списокдаодининдивидуальныйлуна,Таким образом, мы используем 41-битное сохраненное индивидуальное время окончания цикла гггг-ММ-дд 23:59:59, соответствующее отметке времени и разнице отметок времени обновления оценки пользователя.,Эта индивидуальная ценность со временем станет меньше.,И не будет отрицательных чисел,Достаточно, чтобы достичь цели.
Как разработать сценарии флэш-продаж, чтобы справиться с высоким уровнем параллелизма и перепродажей?
существующие решения на уровне библиотеки
- Существующие Добавьте монопольную блокировку при запросе запасов продуктов и выполните следующий оператор:
select * from goods for where goods_id=? for update
существоватьв бизнесенитьAпроходитьselect * from goods for where goods_id=#{id} for Оператор обновления блокирует строку данных с идентификатором товара #{id}. Тогда другое нить на этот раз Можно Оператор useselect считывает данные, но если также использовать select for updateБлокировка операторов,илииспользоватьupdate,Удалить заблокирует,Пока транзакция нить АВоля не зафиксируется (или не откатится),Только нить в другой строке после существованияA может получить блокировку.
- При обновлении библиотеки данных для сокращения запасов выполняйте ограничения запасов.
update goods set stock = stock - 1 where goods_id = ? and stock >0
Такое решение для блокировки библиотек работает не очень хорошо. В случае высокого параллелизма можно хранить существующие, потому что. что Невозможно получить соединение с библиотекой данных или потоому что истекло время ожидания и сообщил об ошибке.
Использование распределенных блокировок
такой жеодининдивидуальный Замокkey,Только один человек может получить замок одновременно,Другой клиент застрянет в бесконечном ожидании, пытаясь получить этот индивидуальный замок.,Только тот, кто получил блокировку, может выполнить следующую бизнес-логику. Недостатком этого решения является то, что несколько пользователей одновременно размещают заказы на один и тот же товар.,Будет сериализован на основе распределенных блокировок.,В результате невозможно одновременно обрабатывать большое количество заявок на заказ одного и того же индивидуального товара.
Использование распределенных блокировок+точкачасть缓жить
把данныеразделен на множествоиндивидуальныйчасть,Каждыйиндивидуальныйчастьдаодининдивидуальныйодинодиниз Замок,Поэтому, когда многие индивидуальности приходят и одновременно изменяют данные,Данные разных сегментов могут изменяться одновременно. Сценарий: Предположим, у вас на складе имеется 100 существующих товаров.,существоватьredisмагазин5индивидуальный Библиотекажитьkey,Форма как:
key1=goods-01,value=20;
key2=goods-02,value=20;
key3=goods-03,value=20
Когда пользователь размещает заказ, вычисляется идентификатор пользователя. Если ключ существования найден, он будет получен. Таким образом, каждый раз может быть обработано 5 отдельных запросов. этот种方案可以解决такой жеодининдивидуальныйтоварсуществовать多用户такой жечас Внизодиниз Состояние,Но есть подводные камни, которые необходимо решить: когда запас определенного замка недостаточен,Обязательно автоматически снимите блокировку, а затем перейдите к следующему индивидуальному сегментированному инвентарю и повторите попытку блокировки.,Это решение относительно сложное.
Используйте атомарность incr и decr redis + асинхронную очередь.
Идеи реализации
- 1. Когда система инициализируется,Инвентарное количество предметов Воля загружается в кэш Redis.
- 2. При получении запроса на убийство от второго,Инвентаризация перед сокращением в существующем Redis (с использованием атомарности Redis Decr),Когда инвентарь в Redis низкий,Вернитесь прямо во Второй убийственный провал.,В противном случае перейдите к шагу 3;
- 3. Запрос Воля помещается в асинхронную очередь и возвращается в существующую очередь;
- 4. Серверасинхронная очередь Воля запросы на выход из очереди (какие запросы можно удалять из очереди),Можно определить в зависимости от бизнеса,Например: Определите, приобрел ли уже соответствующий пользователь да соответствующий продукт.,Предотвратить повторное убийство Второй),Успешный запрос на удаление из очереди может сгенерировать второй приказ об уничтожении.,Уменьшить запасы библиотеки данных (существовать SQL для вычета запасов выглядит следующим образом),Вернуться к деталям заказа на убийство во Второй мировой войне)
update goods set stock = stock - 1 where goods_id = ? and stock >0
- 5. После того, как пользователь существуетклиент подает запрос на уничтожение во Соединённом Королевстве.,провести опрос,Проверьте да, был ли успешно убит Второй,Если убийство по-второму прошло успешно, вы введете детали порядка уничтожения по-второму.,Иначе Второй не сможет убить
Недостатки этого решения: поскольку дапроходасинхронная очередь записывается в библиотеку данных, хранилище может быть несогласованным, а во-вторых, сложность обращения к нескольким отдельным компонентам относительно высока.
Если для данных точки доступа установлен срок действия, их удаление после завершения активности может заблокировать основной поток. Как решить эту проблему?
Можно использовать unlink Способы удалить кэш,отвязать даасинхронныйудалитьданные,Нет Заблокирует основной поток



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
