Tacotron2, GST, Glow-TTS, Flow-TTS... вы освоили их все? В одной статье обобщены основные классические модели синтеза речи (2).
Колонна «Машинное сердце»
Спонсором этой колонки является Machine Heart SOTA! Созданный Model Resource Station, он постоянно обновляется каждое воскресенье на официальном аккаунте Machine Heart.
В этой колонке будут рассмотрены общие задачи в области обработки естественного языка, компьютерного зрения и других областей, а также подробно объяснены классические модели, которые достигли соответствия SOTA при решении этих задач. ИДИТЕ В СОТУ! Код реализации модели, модель предварительного обучения, API и другие ресурсы, включенные в эту статью, можно получить на станции ресурсов модели (sota.jiqizhixin.com).
Эта статья будет разделена на 2 Выходит в каждом выпуске и представлено всего 19существоватьсинтез речиПолучено на миссии SOTA классическая модель.
- Часть 1: BLSTM-RNN, WaveNet, SampleRNN, Char2Wav, Deep Voice, Parallel WaveNet, GAN, Tacotron, VoiceLoop
- 2 дня: Tacotron2, GST, DeepVoice3, ClariNet, LPCNet, Transformer-TTS, Glow-TTS, Flow-TTS, cVAE+Flow+GAN, PnG BERT
Вы читаете выпуск номер 2 этого. ИДИТЕ В СОТУ! Код реализации модели, модель предварительного обучения, API и другие ресурсы, включенные в эту статью, можно получить на станции ресурсов модели (sota.jiqizhixin.com).
Нет.1обзор периода:BLSTM-RNN、Deep Голос, Такотрон... ты освоил их все? В одной статье обобщены основные классические модели синтеза речи (1).
Краткий обзор моделей, включенных в этот выпуск.
Модель | СОТА! Статус коллекции ресурсной станции модели | Модель Исходный документ |
|---|---|---|
Tacotron2 | https://sota.jiqizhixin.com/project/tacotron-3 Количество включенных реализаций: 23 Поддерживаемые платформы: PyTorch, TensorFlow | Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions |
GST | https://sota.jiqizhixin.com/project/gst Количество включенных реализаций: 2 Поддерживаемые платформы: PyTorch, TensorFlow | Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis |
DeepVoice3 | https://sota.jiqizhixin.com/project/deepvoice3 Количество включенных реализаций: 1 Поддерживаемая платформа: PyTorch | Deep Voice 3: Scaling text-to-speech with convolutional sequence learning |
ClariNet | https://sota.jiqizhixin.com/project/clarinet Количество включенных реализаций: 1 Поддерживаемая платформа: PyTorch | ClariNet Parallel Wave Generation in End-to-End Text-to-Speech |
LPCNet | https://sota.jiqizhixin.com/project/lpcnet Количество включенных реализаций: 1 Поддерживаемая платформа: PyTorch | LPCNET: IMPROVING NEURAL SPEECH SYNTHESIS THROUGH LINEAR PREDICTION |
Transformer-TTS | https://sota.jiqizhixin.com/project/transformer-tts-mel-waveglow Количество включенных реализаций: 1 Поддерживаемая платформа: TensorFlow | Neural Speech Synthesis with Transformer Network |
Glow-TTS | https://sota.jiqizhixin.com/project/glow-tts Количество включенных реализаций: 1 Поддерживаемая платформа: PyTorch | Glow-TTS:A Generative Flow for Text-to-Speech via Monotonic Alignment Search |
Flow-TTS | Количество реализаций, включенных в https://sota.jiqizhixin.com/project/flow-tts: 1 | FLOW-TTS: A NON-AUTOREGRESSIVE NETWORK FOR TEXT TO SPEECH BASED ON FLOW |
VITS | https://sota.jiqizhixin.com/project/cvae-flow-gan Количество включенных реализаций: 2 Поддерживаемая платформа: PyTorch | Conditional variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech |
PnG BERT | https://sota.jiqizhixin.com/project/png-bert Количество включенных реализаций: 1 Поддерживаемая платформа: PyTorch | PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS |
синтез речи (речевой синтез) относится к технологии производства искусственной речи механическими и электронными методами. To Речь (TTS) преобразует текст в антропоморфную речь (синтез речи, при котором входными данными является текст), что является типичной и наиболее знакомой задачей синтеза речи. Синтез речи широко используется в таких бизнес-сценариях, как интеллектуальное обслуживание клиентов, чтение аудио, вещание новостей и взаимодействие человека с компьютером. Технология синтеза речи и распознавания речи — две ключевые технологии, необходимые для реализации голосовой связи человека и машины и создания системы разговорной речи с возможностями прослушивания и речи. Предоставление компьютерам возможности говорить, как люди, является важным конкурентным рынком в информационной индустрии в современную эпоху. По сравнению с распознаванием речи, технология синтеза речи является относительно зрелой и начала успешно двигаться к индустриализации. Известные iFlytek и Volcano Engine являются примерами индустриализации технологии синтеза речи. традиционный синтез Модель речи (также известная как синтез статистических параметров). речи(Statistical Parametric Speech Синтез) SPSS) включает в себя три отдельных этапа обработки: фронтальная обработка — акустическая модель — вокодер. Среди них фронтальная обработка и вокодер имеют некоторые общие решения, а точки улучшения для различных задач находятся в основном в части акустической модели. Внешняя обработка в основном относится к анализу текста, обычно к синтезу входных данных. Текст речевой системы предварительно обрабатывается, например, преобразуется в последовательность фонем, а иногда также выполняется сегментация, анализ ритма и т. д., и, наконец, из текста извлекаются произношение и ритм. Акустическая модель в основном генерирует акустические характеристики на основе лингвистических особенностей. Наконец, вокодер синтезирует голосовой сигнал на основе акустических характеристик. Создание этих модулей требует большого опыта и сложной инженерной реализации, что потребует много времени и усилий. Кроме того, неправильное сочетание каждого отдельного компонента может затруднить обучение Модели. К традиционному трехступенчатому синтезу Модель глубокого обучения (DNN) представлена в модели речи, которая может изучать функцию сопоставления языковых функций (входные данные) со звуковыми функциями (выходные данные). Акустическая модель на основе DNN обеспечивает эффективное распределенное представление сложных зависимостей между лингвистическими и акустическими характеристиками. Однако одним из ограничений метода моделирования акустических характеристик, основанного на DNN с прямой связью, является то, что он игнорирует непрерывность звука. Методы на основе DNN предполагают, что каждый кадр отбирается независимо, хотя существует корреляция между последовательными кадрами в голосовых данных. Рекуррентная нейронная сеть (RNN) обеспечивает эффективный способ моделирования корреляции между соседними кадрами, поскольку она может использовать все доступные входные функции для прогнозирования выходных функций каждого кадра. Исходя из этого, некоторые исследователи использовали RNN вместо DNN, чтобы уловить долговременную зависимость голосовых кадров и улучшить качество синтезированного голоса. В последние годы, с развитием глубокого обучения, точность моделей стремительно росла. Среди них способность глубокой нейронной сети к обучению суперфункций значительно упростила процесс извлечения признаков и снизила зависимость моделирования от опыта экспертов. Процесс моделирования постепенно перешел от предыдущего сложного многоэтапного процесса к простому сквозному. процесс конечного моделирования, сквозной нейронный сетевойсинтез. Речь также стала основным методом крупномасштабного промышленного применения. Сквозную модель можно рассматривать как два основных этапа: моделирование акустической модели и нейронный вокодер. Среди них моделирование акустической модели напрямую преобразует входную последовательность текста/фонем в голосовые характеристики на уровне кадра, а нейронный вокодер преобразует голосовые характеристики на уровне кадра в голосовые сигналы. Нейронный вокодер включает два типа: авторегрессионную модель и неавторегрессивный. Модель . Сквозной подход превосходит традиционные подходы с точки зрения производительности и возможности продвижения по пути развертывания.
В этом отчете мы суммируем результаты классического синтеза. речевой метод и сквозной синтез речи Глубокое обучение методамTOPМодель,Оба приложения включены во фронтальную обработку,Также включено внимание к модели акустики и модели глубокого обучения, применяемой в вокодерах.
Tacotron2
Базовая структура Tacotron2 аналогична Tacotron со следующими основными изменениями:
- Кодировщик: Tacotron2 использует 3-слойный слой, содержащий 512 индивидуальных слоев свертки фильтров 5X1 и индивидуальный двунаправленный 512-слойный слой LSTM.,Для замены модуля CBHG в Tacotron,Модуль кодера был упрощен.
- Tacotron2 использует внимание, чувствительное к местоположению, для улучшения механизма внимания в Tacotron и эффективного снижения вероятности утечки звука, поскольку положение каждого выравнивания в TTS должно быть рядом с последним выравниванием, а не искать его по всем блокам в памяти.
- Остановка добавлена в Tacotron2 Токен, который увеличивает потери прогнозирования конечной позиции голоса, чтобы определить, завершает ли декодер вывод прогнозирования, чтобы облегчить синтез. Возникает проблема с окончанием звука в процессе речи, а также это способствует ускорению сближения.
- Пост-сеть: Tacotron2 использует 5-слойный слой свертки вместо модуля CBHG, прогнозируя индивидуальный остаток, добавляемый к прогнозу для улучшения общей реконструкции. Каждый слой состоит из 512 индивидуальных фильтров формы 5×1, нормализованных по партиям и затем активированных на всех слоях, кроме последнего.
- Вокодер: Tacotron2 использует улучшенную WaveNet. Используйте 10-компонентную смесь логистических распределений (MoL), чтобы сгенерировать 16-битные выборки на частоте 24 к Гц. Для расчета распределения логистической смеси выходные данные стека WaveNet активируются ReLU, а затем линейно проецируются для прогнозирования параметров (среднее значение, логарифмический масштаб, вес смеси) каждого компонента смеси. Потери рассчитываются как отрицательная логарифмическая вероятность достоверной выборки.
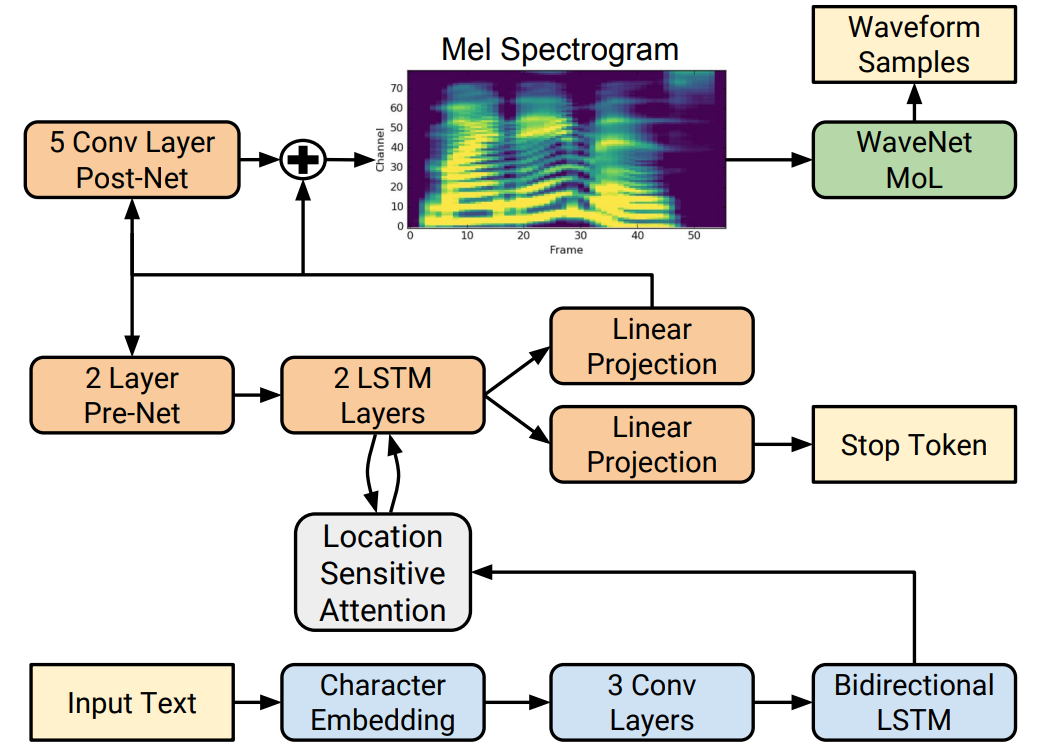
Рисунок 1. Структурная схема Tacotron2
текущий СОТА! Входит в состав платформы Tacotron2 общий 23 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
Tacotron2 | Перейти к СОТА! Модельная платформа получает ресурсы для реализации: https://sota.jiqizhixin.com/project/tacotron-3 |
GST
Чтобы передать голоса реальных людей,TTS должен научиться моделировать ритм. Ритм – это сочетание множества фонем в голосе.,Например, паралингвистическая информация,интонация,Акцент и стиль. GST – это индивидуальный стиль Модель,Его цель — предоставить Модели возможность выбирать стиль речи, подходящий для данного контекста. Правильная отрисовка стиля влияет на «эмоциональный ритм» общего восприятия.,Это важно для таких приложений, как аудиокниги и программы чтения новостей.。 “global style токены»GST относится к современному сквозному синтезу Встраивание библиотеки для такого же обучения в речевую систему Tacotron. Путем обучения вложений без явных меток изучаются крупномасштабные акустические представления ( acoustic выразительность). Мягко интерпретируемые «теги», генерируемые GST, можно использовать для управления композицией, например, для изменения скорости и стиля речи – независимо от текстового содержания. Их также можно использовать для передачи стиля, воспроизводя стиль речи одного аудиоклипа во всем корпусе длинного текста. При обучении на зашумленных, немаркированных данных обнаружения GST учится разлагать шум и личность говорящего, открывая путь к высокомасштабируемому, но мощному синтезу речи. интуитивно,GSTМодель можно рассматривать как сквозной подход, который разлагает ссылочные внедрения на набор базисных векторов или мягких кластеров (т.е. тегов стиля).,Вклад каждого жетона индивидуального стиля представлен оценкой внимания.,Но ее можно заменить любой желаемой мерой подобия. Внедрение GST также можно рассматривать как внешнюю память, в которой хранится информация о стиле, извлеченная из обучающих данных. Опорный сигнал управляет записью в память во время тренировки,А чтение памяти направляется во время вывода.
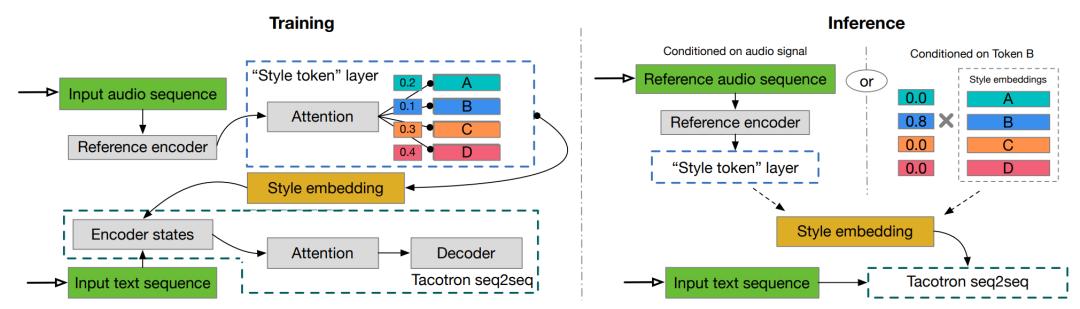
Рисунок 2. Моделькартина. В процессе обучения логарифмическая спектрограмма целевой обучающей цели подается в опорный кодер, за которым следует слой метки стиля. Полученные встраивания стилей используются для регулирования состояния кодировщика текста Tacotron. В процессе рассуждения может быть введен произвольный опорный сигнал для синтеза текста с его стилем речи. Кроме того, вы также можете удалить эталонный кодер и напрямую использовать изученные интерпретируемые маркеры для управления синтезом.
GSTModel основана на Tacotron, модели «последовательность-последовательность» (seq2seq), которая прогнозирует мелодические спектрограммы непосредственно на основе ввода букв или фонем. Эти мелодические спектрограммы преобразуются в сигналы с использованием малоресурсных алгоритмов инверсии или нейронного вокодера, такого как WaveNet. Для Tacotron выбор вокодера не влияет на просодию, которая моделируется seq2seqModel. GST использует ту же архитектуру и гиперпараметры, что и Tacotron. Используйте ввод фонем, чтобы ускорить обучение, и немного измените декодер, заменив блоки GRU двухслойным LSTM из 256 блоков. Они регуляризуются с использованием Zoneout с вероятностью 0,1. Декодер выводит 80-канальную логмель-спектрограмму с энергиями по два кадра за раз, которые пропускаются через расширенную сверточную сеть, которая выводит линейную спектрограмму. Запустите Griffin-Lim для быстрой реконструкции формы сигнала. Замена Griffin-Lim на вокодер WaveNet напрямую улучшает качество звука. Эталонный кодер состоит из сверточного стека и RNN, который принимает в качестве входных данных логарифмическую карту, сначала передаваемую в 6 2D-сверток с ядром 3×3, шагом 2×2, пакетной нормализацией и стеком слоев функции активации ReLU. Используйте 32, 32, 64, 64, 128 и 128 выходных каналов для 6 сверточных слоев соответственно. Результирующий выходной тензор затем преобразуется в трехмерный (с сохранением выходного временного разрешения) и подается в один слой 128-элементного однонаправленного GRU. Окончательное состояние GRU используется в качестве эталонного внедрения, которое затем предоставляется в качестве входных данных для стиля. слой токенов. стиль Слой токена состоит из набора стилей. token embeddings и модуль внимания. Чтобы соответствовать размерности кодировщика текста, каждое внедрение токена имеет размер 256-D. Аналогичным образом, кодировщик текста использует активацию tanh GST перед обращением внимания, что приводит к большему разнообразию токенов. Внимание к контенту использует активацию softmax для вывода набора комбинированных весов токенов. Полученная в результате взвешенная комбинация GST затем используется для определения условий. Авторы экспериментировали с различными комбинациями условных сайтов и обнаружили, что лучше всего работает копирование встраивания стиля и простое добавление его в каждое состояние кодировщика текста.
текущий СОТА! Входит в состав платформы GST общий 2 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
GST | Перейти к СОТА! Модельная платформа получает ресурсы для реализации: https://sota.jiqizhixin.com/project/gst |
Deep Voice3
Deep Voice 3 — это нейронная система преобразования текста в речь (нейронная TTS), полностью основанная на сверточном внимании.
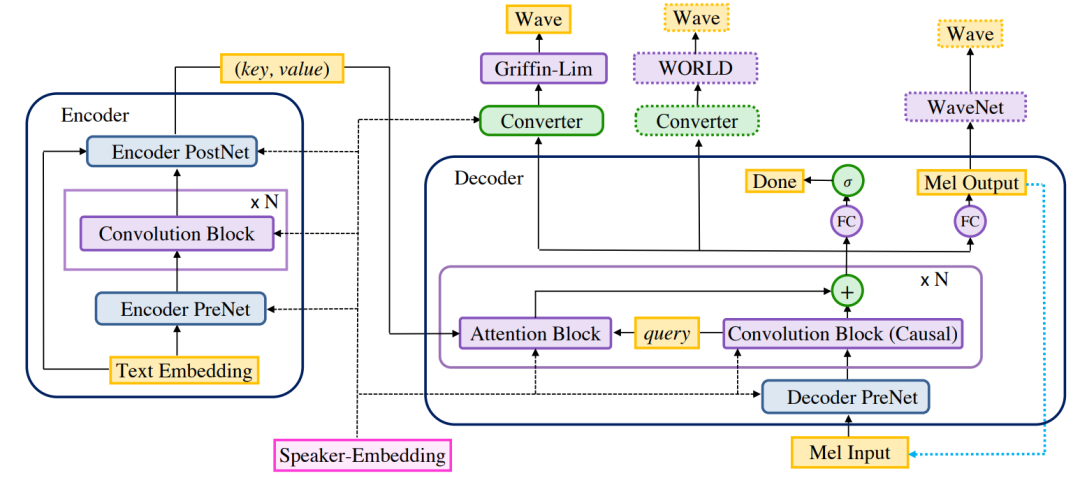
Рисунок 3. Deep Voice 3. Используйте остаточные сверточные слои для кодирования текста в векторы ключей и значений для каждого периода времени для декодера, основанного на внимании. Декодер использует их для прогнозирования объединенной спектрограммы логарифмической величины, соответствующей выходному аудио. (Светло-синие пунктирные стрелки описывают авторегрессионный процесс в процессе вывода). Скрытые состояния декодера затем передаются в сеть преобразователей для прогнозирования параметров вокодера, используемых для синтеза сигналов.
Архитектура Deep Voice 3 состоит из трёх частей.
- кодер Полностью сверточный кодер, преобразующий текстовые элементы во внутренние полученные представления.
- декодер Полностью сверточный причинный декодер, который декодирует изученное представление с помощью многошагового механизма сверточного внимания в низкомерное аудиопредставление (слитную спектрограмму) авторегрессионным способом.
- Конвертер: полностью сверточный постпроцессор, который прогнозирует окончательные параметры вокодера на основе скрытых состояний декодера (в зависимости от выбора вокодера). В отличие от декодеров, преобразователи являются акаузальными и поэтому могут полагаться на будущую контекстную информацию.
Общая целевая функция, подлежащая оптимизации, представляет собой линейную комбинацию потерь декодера и преобразователя. Разделите декодер и преобразователь и используйте многозадачное обучение, поскольку это облегчает обучение вниманию на практике. В частности, потеря предсказания спектрограммы мелодии управляет тренировкой механизма внимания, поскольку тренировка внимания также включает в себя градиенты предсказания спектрограммы мелодии в дополнение к предсказанию параметров вокодера. Предварительная обработка текста. Напишите все символы во входном тексте с заглавной буквы, удалите все промежуточные знаки препинания, завершите каждое предложение точкой или вопросительным знаком и замените пробелы между словами специальными разделителями, которые указывают, где говорящий вставляет паузы между словами. Используются четыре разных разделителя слов, обозначающие (i) Некогерентный; (ii) Получено произношение и пробелы (iii) Короткая пауза между словами (iv) Длинные паузы между словами. Совместное представление символов и фонем. Модель может напрямую преобразовывать символы (включая знаки препинания и пробелы) в акустические характеристики, тем самым изучая неявную графему-фонему Модель. В дополнение к символу Модель, чистая фонема Модель и смешанная фонема Модель также обучаются путем явного разрешения параметров ввода фонем. Эти модели идентичны модели простых символов, за исключением того, что входной слой для кодера иногда получает встраивания фонем и акцентов фонем вместо встраивания символов. Чистая модель фонем требует отдельного этапа предварительной обработки для преобразования слов в их представления фонем (либо с использованием внешнего словаря фонем, либо отдельно обученной модели графема-фонема). Смешение символов и фонем Модель требует аналогичных шагов предварительной обработки, за исключением слов, которых нет в словаре фонем. Эти слова за пределами словарного запаса вводятся как символы, что позволяет Модели использовать свою неявно изученную Модель преобразования графемы в фонему. При обучении модели гибридной фонемы в каждом отдельном слове представление фонемы заменяется с определенной вероятностью на каждой итерации обучения. Блоки свертки для последовательной обработки. Обеспечивая достаточно большое восприимчивое поле, составные сверточные слои могут использовать долговременную контекстную информацию в последовательности без введения какой-либо корреляции последовательностей в вычислениях. Используйте изображения Сверточный блок, показанный на рисунке 17, служит основным блоком последовательной обработки для кодирования скрытых представлений текста и звука.
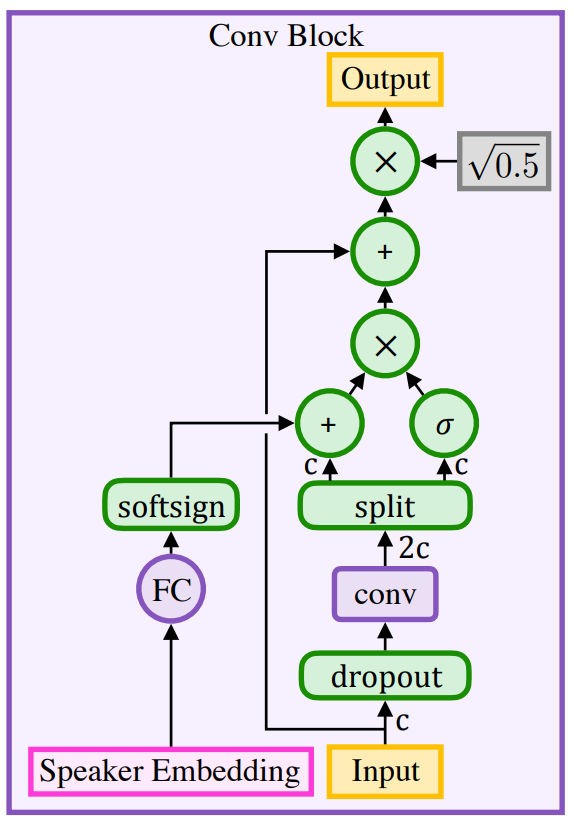
Рисунок 4. Сверточный блок состоит из вентильного линейного блока и остаточной связной одномерной свертки. Здесь c представляет размерность ввода. Выходные данные свертки размера 2-c разбиваются на части одинакового размера: вектор вентиля и входной вектор.
кодер. Сеть кодировщиков (рис. 16 (показано) начинается со слоя внедрения, который преобразует символы или фонемы в обучаемые векторы, представленные как he . Эти встроенные he Во-первых, полносвязный слой используется для сопоставления измерения внедрения с целевым измерением. Затем извлекается текстовая информация, которая меняется со временем. Наконец, они проецируются обратно во встраиваемые измерения, чтобы создать ключевые векторы внимания. hk . Вектор значения внимания рассчитывается на основе вектора ключа внимания и встраивания текста, hv. = √0.5— (he + он), всестороннее рассмотрение he местная информация в и hk Долгосрочная контекстная информация. Используйте ключевые векторы для каждого блока внимания. hk для расчета веса внимания, а окончательный вектор контекста рассчитывается как вектор значений hv средневзвешенное значение. декодер. Сеть декодера начинается с нескольких полностью связанных слоев и предварительно обрабатывает входную mel-спектрограмму с помощью нелинейности ReLU (рис. 1 6 выражено как PreNet ). За этим следует серия причинных извилин и блоков внимания. Эти сверточные блоки генерируют запросы на скрытые состояния кодера. Наконец, полностью связный слой выводит следующий набор r аудиокадры и двоичный файл «Финальный кадр» Прогнозирование (указывает, был ли синтезирован последний кадр высказывания). Выбывать Блок внимания применяется перед каждым полносвязным слоем, кроме первого. Двоичная кросс-энтропийная потеря рассчитывается с использованием выходной мел-спектрограммы и прогнозирования окончательного кадра. Модуль внимания. Механизм внимания использует вектор запроса от кодера (скрытое состояние декодера) и вектор ключа на каждом временном шаге для расчета веса внимания, а затем выводит вектор контекста, рассчитанный как средневзвешенное значение векторов значений.
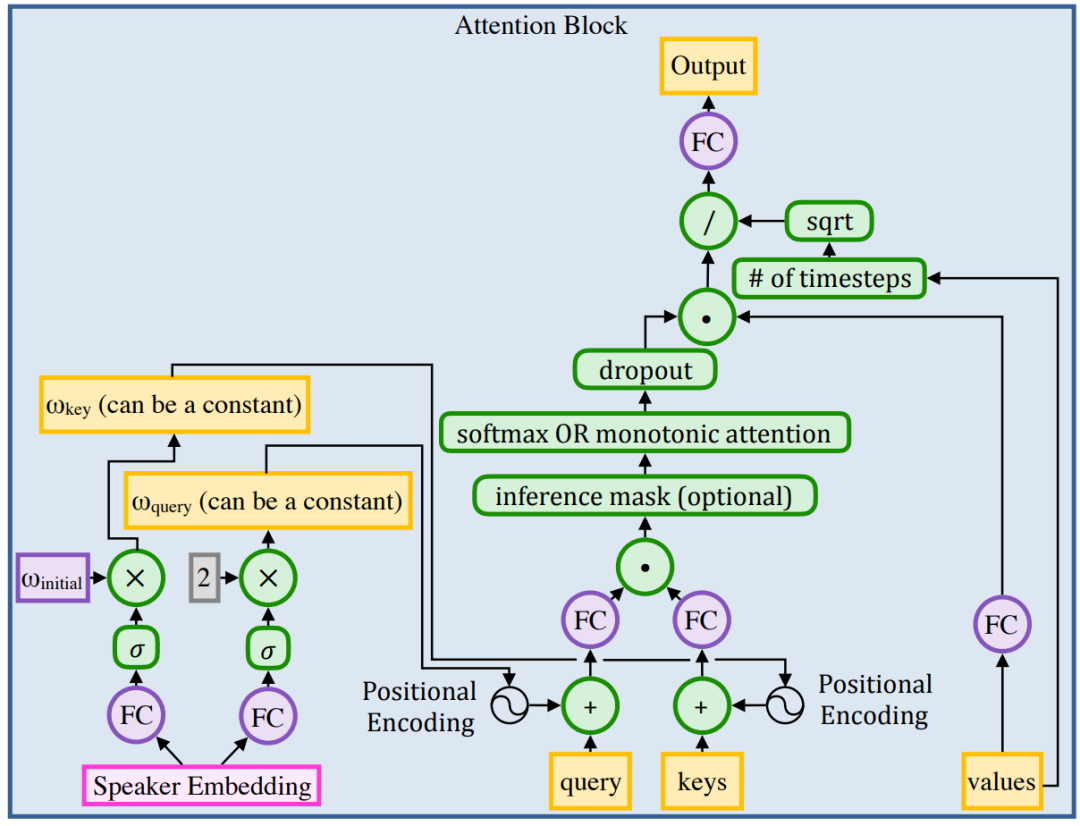
Рисунок 5. Добавьте позиционное кодирование к векторам ключа и запроса с соотношениями ω_key и ω_query соответственно. Обеспечение монотонности можно применить при выводе, добавив к логарифму маску больших отрицательных значений. Используйте одну из двух возможных схем внимания: softmax или монотонное внимание. Во время тренировки откажитесь от весов внимания
преобразователь. Сеть преобразователя принимает на вход активацию последнего скрытого слоя декодера, применяет несколько непричинных сверточных блоков, а затем прогнозирует параметры нисходящего вокодера. В отличие от декодера, преобразователь не является причинным и неавторегрессивным, поэтому он может использовать будущий контекст декодера для прогнозирования его выходных данных. Функция потерь сети преобразования зависит от типа используемого вокодера: (1) Гриффина-Лима Вокодер: Гриффин-Лим Алгоритм преобразует спектрограмму во временной звуковой сигнал путем итеративной оценки неизвестной фазы. (2) МИР Вокодер: в качестве параметра вокодера можно предсказать индивидуальное логическое значение (независимо от того, является ли текущий кадр глухим или невокализованным), индивидуальное F0 значение (если кадр невокализованный), спектральная огибающая и апериодические параметры. Речевое-неречевое прогнозирование с использованием перекрестной энтропийной потери, L1 потери используются для всех остальных прогнозов (см. рисунок 19). )。(3)WaveNet Вокодер: обучается отдельно WaveNet Сеть действует как вокодер, а логарифмическая спектрограмма в мел-шкале используется в качестве параметра вокодера. Эти параметры вокодера вводятся в сеть как внешние регуляторы. Обучение проводилось с использованием реальных мел-спектрограмм и звуковых сигналов. WaveNet сеть.
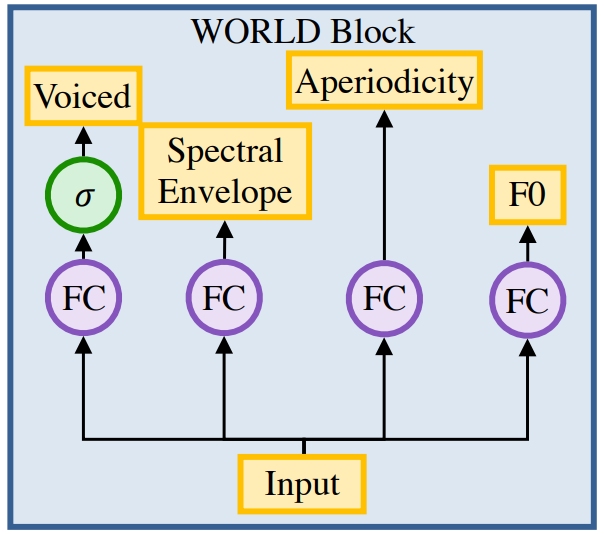
Рисунок 6. Генерация параметров вокодера WORLD с использованием полносвязных (FC) слоев.
текущий СОТА! Входит в состав платформыDeep Voice 3общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
Deep Voice 3 | Перейти к СОТА! Платформа модели получает ресурсы для реализации: https://sota.jiqizhixin.com/project/deepvoice3 |
ClariNet
ClariNet — это совершенно новая система, основанная на WaveNet Параллельная форма аудиосигнала (необработанный audio waveform) генерирует Модель. Параллельная генерация сигналов Модель основана на Гауссовском обратном авторегрессионном потоке (Гауссова inverse autoregressive flow), который может генерировать исходную звуковую волну, соответствующую фрагменту речи, полностью параллельно. По сравнению с авторегрессией WaveNet Модель, скорость ее синтеза увеличена в тысячи раз, и она может достигать десятикратного уровня в реальном времени. чем раз. контраст DeepMind поднятый ранее Parallel WaveNet,ClariNet дистилляция распределения вероятностей в density дистилляция) процесс проще и красивее, непосредственно рассчитывая целевую функцию обучения в замкнутой форме. KL Дивергенция (КЛ дивергенции), значительно упрощая алгоритм обучения и делая процесс дистилляции чрезвычайно эффективным — обычно 5 После десяти тысяч итераций можно получить хорошие результаты. В то же время автор также предложил регуляризацию KL Метод расчета дивергенции значительно повышает численную стабильность процесса обучения, делая результаты простыми и удобными для обучения (Примечание: Clari на латыни это clear, bright значение). и Parallel WaveNet Поскольку выборка Монте-Карло необходима для аппроксимации KL Дивергенция делает оценку градиента очень шумной, процесс обучения очень нестабильным, и внешнему миру его чрезвычайно трудно воспроизвести. DeepMind результаты экспериментов. Стоит отметить, что ClariNet Или синтезировать Речь Домен Нет. Полностью комплексная система, которая преобразует текст непосредственно в исходные звуковые сигналы через единую индивидуальную нейронную сеть. «Сквозной», как его раньше называли в отрасли. Система речи (Такотрон) фактически преобразует текст в спектр (спектрограмму), а затем генерирует Модель через форму волны. WaveNet или Griffin-Lim Алгоритм преобразования спектра в исходный выходной сигнал. Этот подход обусловлен моделью преобразования текста в спектр и WaveNet Они обучаются и оптимизируются отдельно, что часто приводит к неоптимальным результатам. и ClariNet полностью соединяет сквозное обучение — от текста до оригинального аудиосигнала, реализуя всю TTS Совместная оптимизация системы по сравнению с Моделью, обучаемой отдельно, лучше при синтезе. Естественность речи значительно улучшилась. Кроме того, ClariNet Он полностью сверточный, а скорость обучения выше, чем у рекуррентной нейронной сети (RNN). 10 Более чем раз.
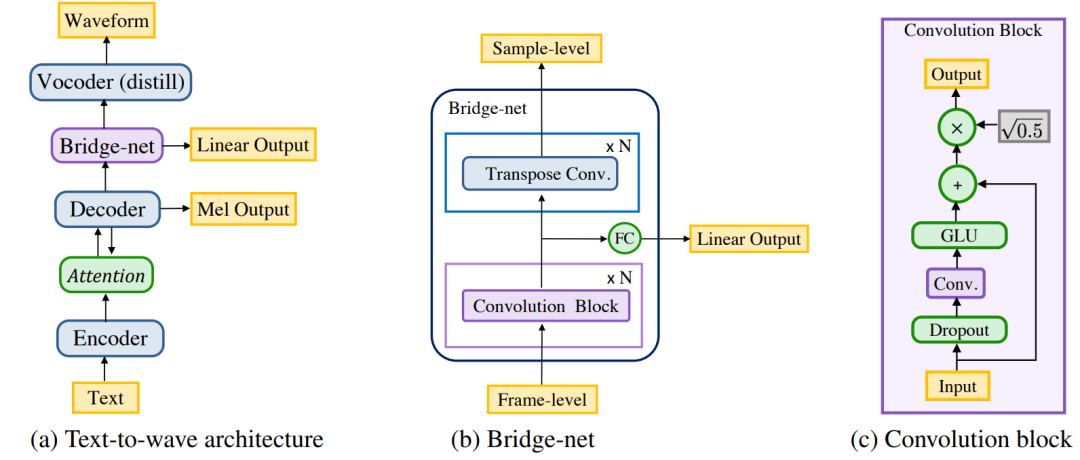
Рисунок 7 (a) Модель Text to Waveform преобразует текстовые объекты в сигналы. Все компоненты напрямую передают свои базовые представления другим компонентам. (б) Bridge-net сопоставляет скрытые представления на уровне кадра с уровнем выборки через несколько сверточных блоков и транспонированные сверточные слои, нелинейно чередующиеся с мягкими сигналами. (с) Блок свертки основан на логических линейных модулях.
ClariNet Структура сети похожа на Рисунок. 7 показано. Он использует модуль кодера-декодера, основанный на внимании, для изучения соотношения выравнивания между текстовыми символами и спектральными кадрами. Потенциальное состояние декодера (скрыто штаты) войдите в Bridge-net Для выполнения обработки временной информации и повышения дискретизации. Воля Bridge-net Потенциальное состояние вводится в модуль генерации звуковых сигналов (вокодер) для окончательного синтеза исходной формы звуковых сигналов.
- кодер.Like Deep Voice Сверточный кодер в версии 3, который кодирует текстовые элементы во внутреннее скрытое представление.
- декодер.Deep Voice Причинный сверточный декодер в 3 декодирует представление и внимание кодера в логарифмическую спектрограмму авторегрессионным способом.
- мостовая сеть. Блок сверточной промежуточной обработки, который обрабатывает скрытое представление от декодера и прогнозирует лог-линейную спектрограмму. В отличие от декодера, он является акаузальным и поэтому может использовать будущую контекстную информацию. Более того, он повышает дискретизацию скрытого представления с уровня кадра на уровень выборки.
- Вокодер. Гауссова авторегрессионная волновая сеть используется для синтеза формы сигнала, которая обусловлена повышенным скрытым представлением мостовой сети. Этот компонент может быть заменен IAF студента (обратный авторегрессионный поток), извлеченным из авторегрессионного вокодера.
текущий СОТА! Входит в состав платформы ClariNet общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
ClariNet | Перейти к СОТА! Модельная платформа получает ресурсы для реализации: https://sota.jiqizhixin.com/project/clarinet |
LPCNet
LPCNet — это вокодер, который сочетает в себе цифровую обработку сигналов (DSP) и нейронную сеть (NN) при синтезе речи. Он может синтезировать высококачественную речь в реальном времени на обычных процессорах.
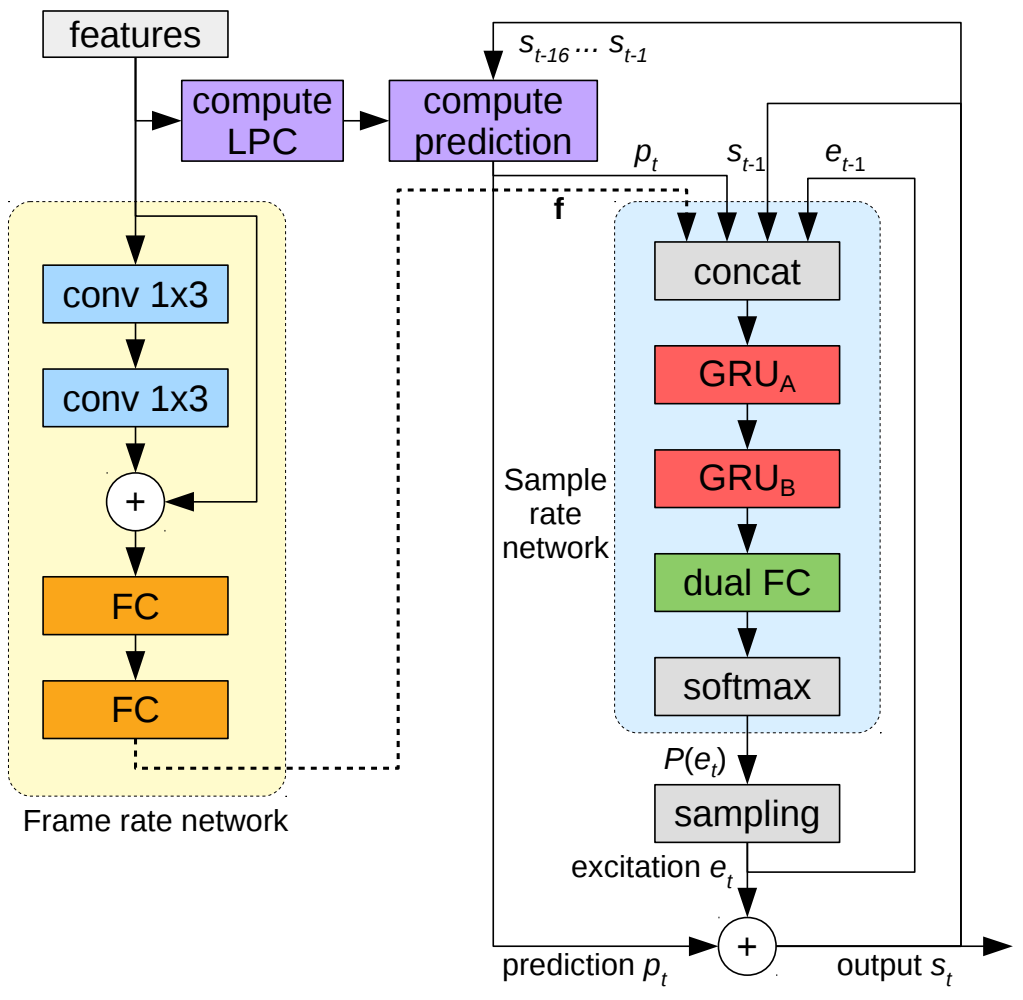
Рисунок 8. Обзор алгоритма LPCNet. Левая часть сети (желтая) рассчитывается один раз для каждого кадра, и ее результаты остаются постоянными для всех кадров для сети с частотой дискретизации справа (синяя). Вычислите блок прогнозирования, чтобы предсказать выборку в момент времени t на основе предыдущих выборок и коэффициентов линейного предсказания. Преобразования между µ-законом и линейным опущены для ясности.
Конструкция ядра LPCNet показана в образце в правой части рисунка 8. rate network часть. Рамка rate network В основном для Sample rate network Предоставляет входные данные вектора условий, который рассчитывается один раз для каждого кадра и остается неизменным в течение кадра. ЛПК Модуль вычислений вычисляет параметры линейного прогнозирования на основе входных признаков. LPC,LPC Он также рассчитывается один раз для каждого кадра и остается неизменным внутри кадра. LPCNet разделен на две части: одна — часть расчета признаков, которая рассчитывается один раз для каждого кадра, а другая — часть выборки, которая рассчитывается в каждой отдельной точке выборки. Входными данными для части вычисления функций являются BFCC и двумерная информация о шаге, а выходными данными — характеристики кадра. Входными данными части выборки являются выходные данные части расчета признака и линейной части текущей точки отбора проб, рассчитанной с помощью LPC, а также выходной сигнал сети выборки (нелинейная часть) предыдущей индивидуальной точки отбора проб и предыдущей индивидуальной точки отбора проб. Выходом является текущая точка. Наконец, просто сложите значение, рассчитанное LPC, и значение, выведенное образцом, чтобы получить окончательный результат LPCNet. Как показано на рисунке 8, вся система состоит из frame rate сеть (желтая часть) и уровень точки отбора проб sampling rate сеть (голубая часть). рамка rate network Рассчитывается один раз для каждого кадра с использованием 2 слой 1*3 Одномерная свертка , поэтому восприимчивое поле зрения этой сети 5 рамка. выборка rate network рассчитывается для каждого кадра 160 раз (например, при использовании звука 16 к Гц, сдвиг кадра 10 мс),эта часть autoregressive Модель,каждыйиндивидуальныйвозбуждение e Все предположения требуют предыдущего предположения e как условие.
текущий СОТА! Входит в состав платформы LPCNet общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
LPCNet | Перейти к СОТА! Платформа модели получает ресурсы для реализации: https://sota.jiqizhixin.com/project/lpcnet |
Transformer -TTS
Интегрируйте трансформатор и Tacotron2,Формируется Трансформатор-ТТС. Основной корпус модели представляет собой оригинальный Трансформер.,Изменения были внесены только во входной и выходной каскады, чтобы соответствовать характеристикам голосовых данных. Первый — это входной каскад кодировщика.,Сначала преобразуйте текст в токен посимвольно.,Удобное встраивание,Затем введите Encoder PreNet,этотслойсеть ЮичииндивидуальныйEmbedding Слой и трехслойный слой свертки, преобразованные в 512-мерный вектор, входят в Трансформер. Кодировщик. Далее идет декодерная часть Transformer, которая разделена на вход и выход. Входные данные преобразуются в 512-мерный вектор из 80-мерной мел-спектрограммы через PreNet, где PreNet представляет собой полностью связанную сеть из трех слоев. Выходная часть полностью соответствует конструкции Tacotron2. Модель TTS на основе трансформатора теперь является основной сквозной моделью. Базовая линия системы TTS незаменима для ее реализации, а благодаря превосходной структуре самого Трансформера она также может значительно ускорить эксперимент.
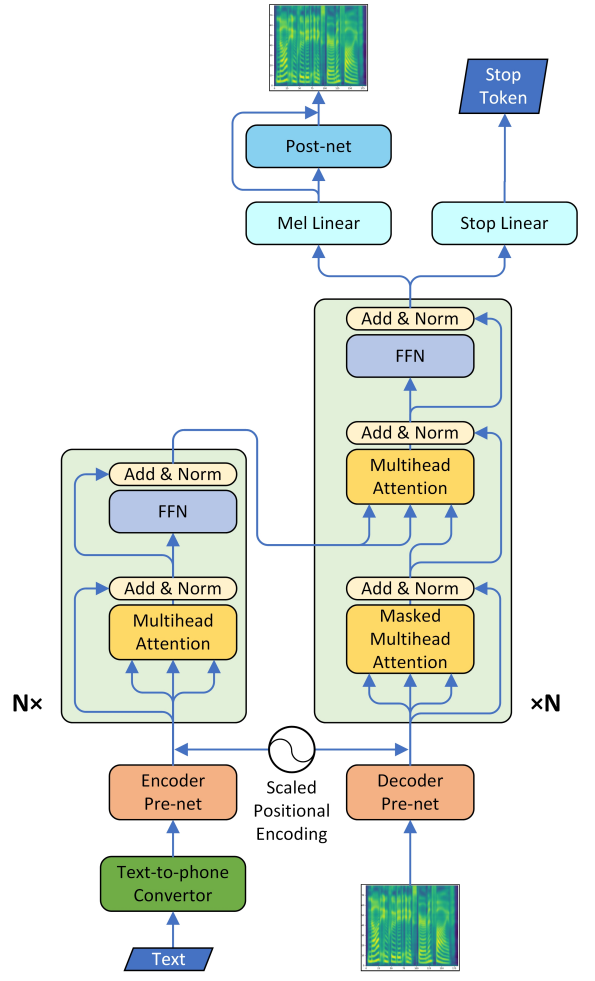
Рисунок 9. Архитектура системы Трансформатор-ТТС
текущий СОТА! Входит в состав платформы Transformer-TTS общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
Transformer-TTS | Перейти к СОТА! Модельная платформа получает ресурсы для реализации: https://sota.jiqizhixin.com/project/transformer-tts-mel-waveglow |
Glow-TTS — это параллельная генерация TTS на основе потоков, которая не требует какой-либо внешней обработки выравнивания. GLow-TTS представляет монотонный поиск выравнивания (MAS) для внутреннего выравнивания. вероятного монотонного соревнования между скрытыми представлениями текста и речи.
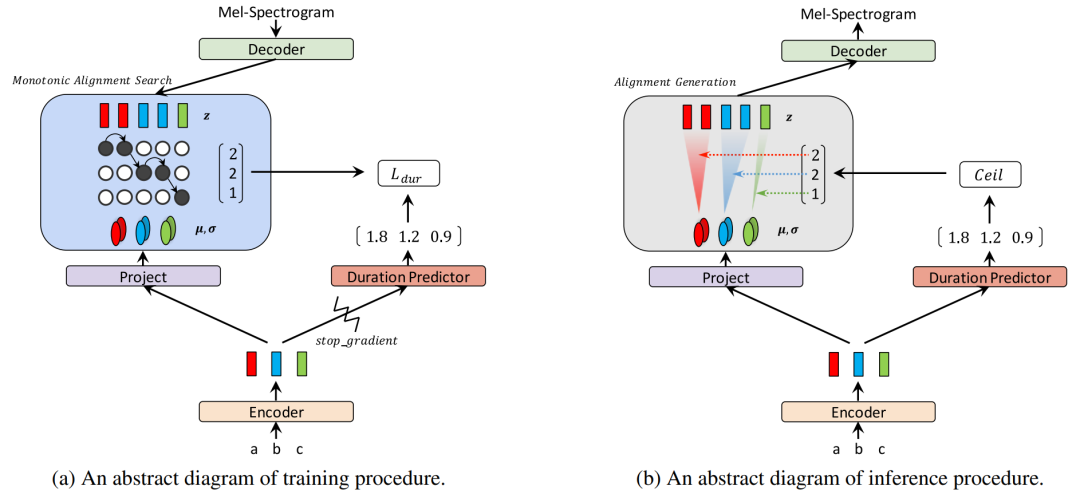
Рисунок 10. Процедуры обучения и вывода Glow-TTS.
Обычно метод использования потоков для условной оценки плотности вероятности заключается в том, чтобы сначала объединить заданные условия в поток, а затем сопоставить данные с потоком известных условий. Подход Glow отличается. Glow-TTS объединяет информацию об условиях со статистической информацией о потоке (например, среднее и стандартное отклонение распределения Гаусса) вместо непосредственного объединения ее с потоком. В частности, функция спектра аудиоинформации-Mel генерирует скрытую переменную z через сеть декодера fdec, и z подчиняется распределению Гаусса Pz, текстовая информация c генерирует скрытую переменную h через сеть fench кодера, а затем h генерирует среднее значение u; и распределение по Гауссу через тету стандартного отклонения сети. В это время звуковые характеристики каждого кадра сопоставляются с определенным распределением Гаусса, и каждый символ также сопоставляется с соответствующим распределением Гаусса. Следующая работа — найти матрицу отображения A, то есть матрицу выравнивания, между двумя типами распределений. Автор определяет, что когда скрытая переменная z_j, соответствующая аудиокадру j, подчиняется распределению Гаусса, соответствующему определенному символу i, аудиокадр считается соответствующим этому символу, то есть N(z_j;u_i,theta_i), то есть , А(j)= i. Когда известна матрица выравнивания A, вероятность правдоподобия можно рассчитать по следующей формуле:
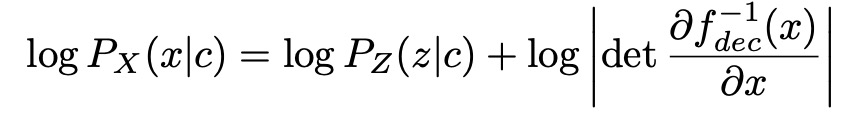
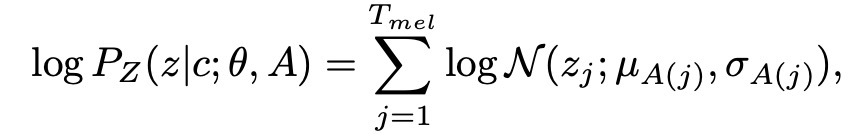
Следующий шаг — найти вероятность максимального правдоподобия. Автор использует идею EM-алгоритма для непосредственного получения нижней границы максимального правдоподобия. Таким образом, расчет максимального правдоподобия упрощается до двухэтапного расчета: (1) Когда тета параметра сети фиксирована, решите приведенную выше формулу (2) При фиксированной матрице выравнивания A получите параметр тета;
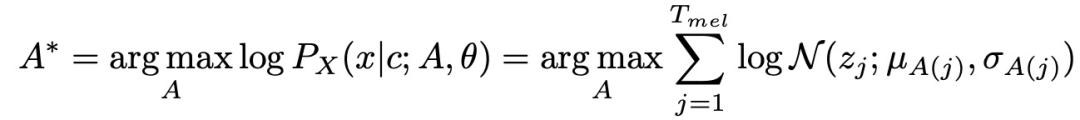
Для вычисления A автор предложил алгоритм поиска монотонного выравнивания MAS, как показано на рисунке 24. MAS на самом деле является алгоритмом динамического программирования. То есть сначала вычислите все вероятности совпадения, а затем найдите путь поиска максимальной вероятности. Поскольку во время обучения существуют соответствующие текстовые и аудиофункции, вы можете напрямую рассчитать, каким аудиокадрам должен соответствовать каждый входной символ, решив матрицу выравнивания A. Однако во время вывода аудиоинформация отсутствует, поэтому нет возможности выполнить обратный расчет. А. . Таким образом, необходима сеть прогнозирования количества кадров аудио, соответствующего символу, для прогнозирования количества аудиокадров, соответствующих каждому символу, а затем получения A. С помощью A и изученного параметра сети theta можно вычислить выходные данные.

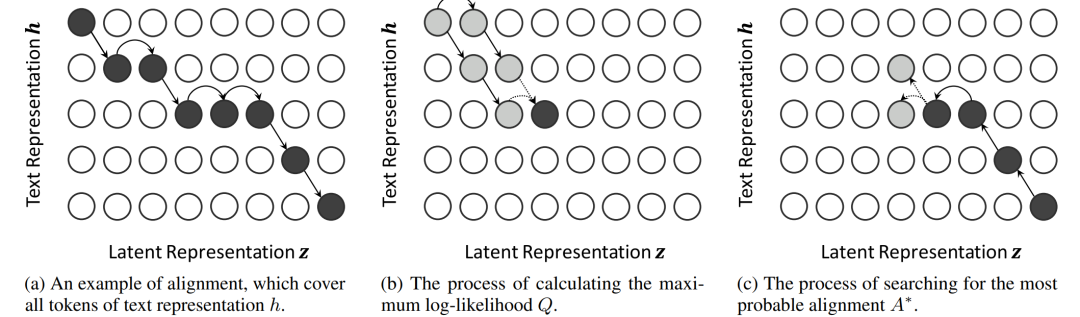
Рисунок 11. Пример монотонного поиска выравнивания
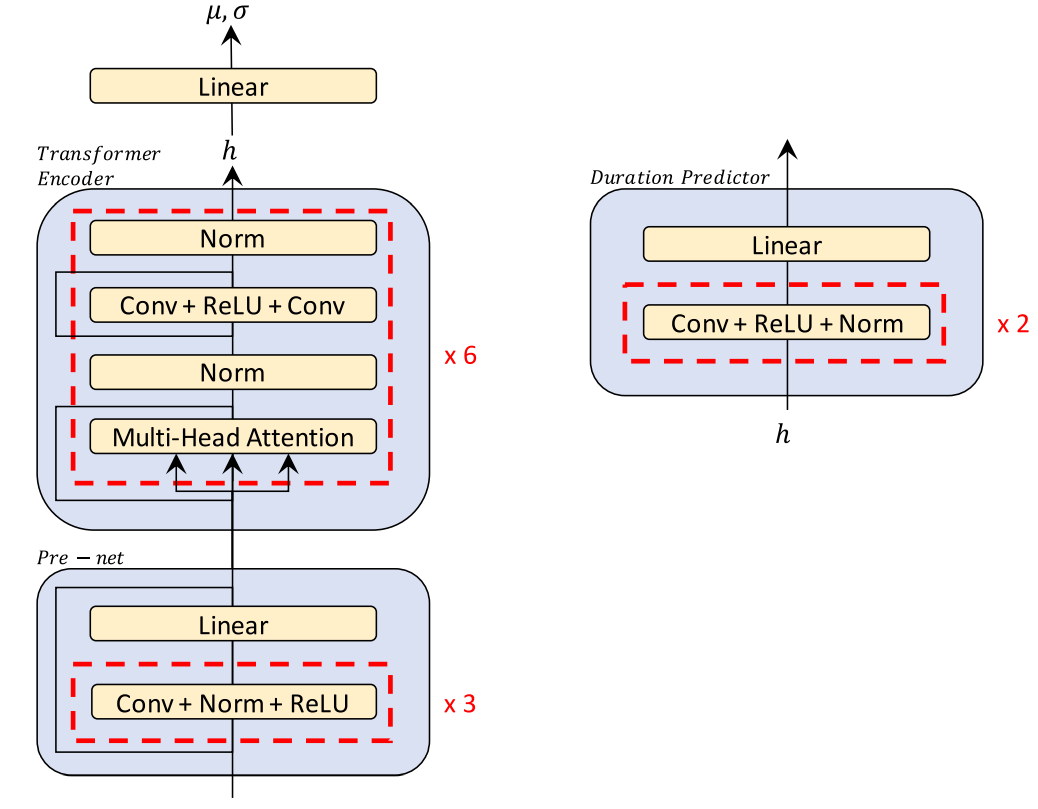
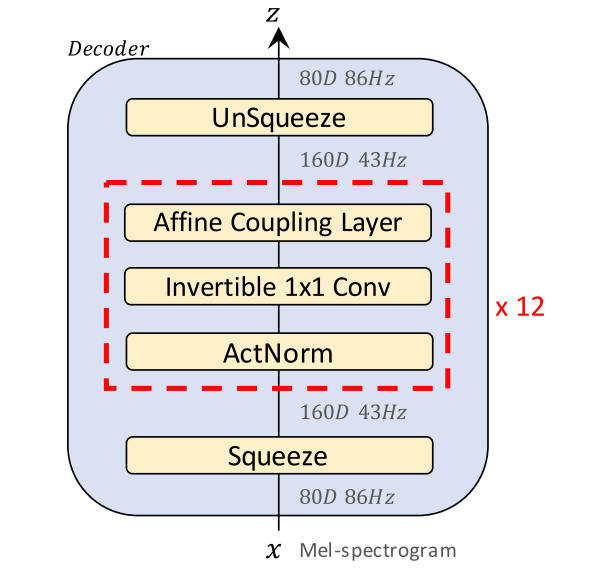
Рисунок 12. Примеры кодера (вверху) и декодера (внизу)
наконец,На рисунке 12 показана структура Glow-TTS. В свечении-ТТС,Декодер состоит из ряда процессов, которые могут параллельно выполнять прямое и обратное преобразования.,В частности, он включает в себя слой бионической связи, обратимую свертку 1x1 и нормализацию активации. Декодер представляет собой стек, состоящий из нескольких отдельных блоков.,Каждый отдельный блок состоит из нормализации активации, обратимой свертки 1x1 и слоя бионической связи. Часть декодера соответствует структуре кодера Transformer TTS.,И сделал две небольшие модификации: удалил кодировку позиции.,Представление относительного положения добавляется в модуль самообслуживания; остаточные соединения добавляются в предварительную сеть кодера. Чтобы оценить статистику предварительного распределения,Просто добавьте отдельный линейный слой в конце кодировщика. Предиктор продолжительности состоит из двух сверток: активации ReLU, нормализации и исключения.,Затем идет проекционный слой.
текущий СОТА! Входит в состав платформы Glow-TTS общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
Glow-TTS | Перейти к СОТА! Модельная платформа получает ресурсы для реализации: https://sota.jiqizhixin.com/project/glow-tts |
Flow-TTS
Flow-TTS — неавторегрессивная сквозная нейронная модель TTS. В отличие от других неавторегрессионных моделей,Flow-TTS может обеспечить высококачественную генерацию голоса, используя единую сеть прямой связи. Flow-TTS — это модель TTS, использующая поток при генерации спектра.,Это также неавторегрессивная модель, которая совместно изучает выравнивание и генерацию спектра через одну сеть.
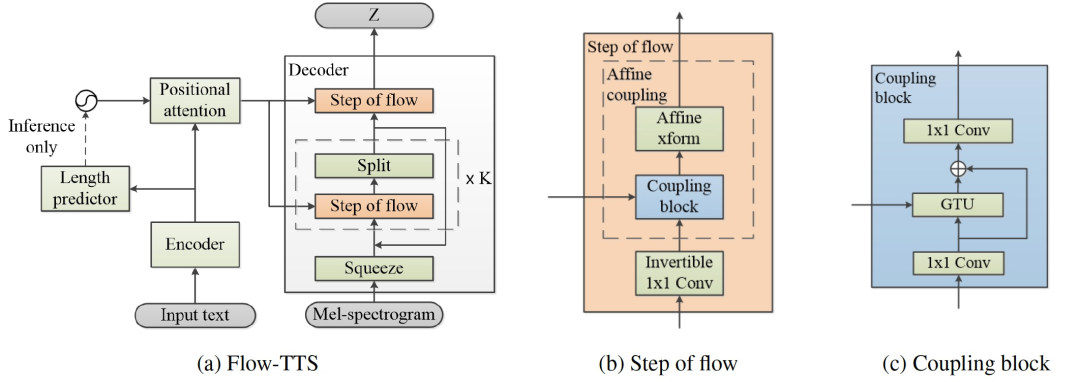
Рисунок 13 Общая архитектура модели. (а) Flow-TTS;(b) Этапы процесса (в) соединительный блок
Flow-TTS основан на генерации потоков (Glow). Общая архитектура Flow-TTS выглядит следующим образом. 13(а). Он состоит из индивидуального кодера, индивидуального декодера, индивидуального предсказателя длины и индивидуального позиционного уровня внимания. Encoder。 Кодер сначала преобразует текстовые символы в обучаемые встраивания, после чего следует серия сверточных блоков. Каждый сверточный блок состоит из одномерной свертки. Он состоит из активации ReLU, пакетной нормализации и исключения. В конце кодировщика добавляется отдельный слой LSTM для извлечения текстовой информации на большие расстояния. Учитывая, что длина текста намного короче длины выходного спектра, LSTMlayer не повлияет на скорость вывода и генерацию параллельных спектров, при этом значительно ускоряя скорость сходимости Модели. Length Predictor。 Предиктор длины используется для прогнозирования длины выходной спектральной последовательности. Однако Flow-TTS прогнозирует все выходные кадры параллельно. Поэтому длина вывода должна быть предсказана заранее. Предиктор длины Flow-TTS состоит из 2-й одномерной сети свертки, за каждым уровнем следует нормализованный уровень и слой исключения. Отдельный слой накопления добавляется в конец предсказателя длины, накапливая все длительности символов до окончательной длины. Прогнозируйте длину в логарифмической области для более стабильных потерь при обучении. Обратите внимание, что предиктор длины устанавливается после кодера и обучается вместе с другими частями Моделиобщий. Positional Attention。 Позиционное внимание является ключевым модулем в обучении согласованию между входными текстовыми последовательностями и выходными последовательностями спектрограмм. Он использует механизм внимания к скалярному произведению с несколькими головками, принимая скрытое состояние вывода кодера в качестве ключевого вектора и вектора значений и кодируя положение спектральной длины в качестве вектора запроса. Длина спектра берется из истинного спектра во время обучения и прогнозируется предсказателем длины во время вывода. Decoder。 Декодер соответствует архитектуре Glow, которая состоит из ряда этапов процесса и многомасштабной архитектуры. Каждый шаг процесса состоит из двух обратимых преобразований слоя и одного обратимого преобразования 1. x Он состоит из слоя свертки и отдельного слоя бионической связи. бионическая связьслой。БионическийAffineмуфтаслойэто одининдивидуальный Мощная обратимая трансформация,в Как прямые, так и обратные функции являются вычислительно эффективными.,Также существует логарифмический определитель:
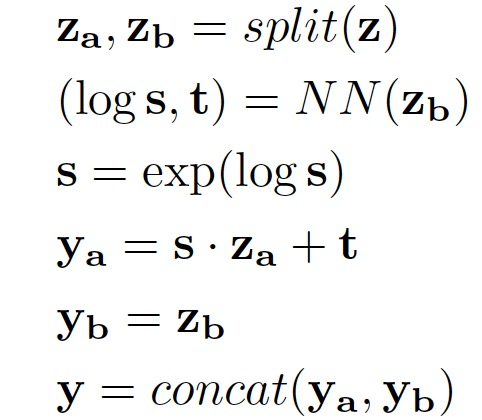
Здесь функции Split() и concat() разделяют входной тензор на две половины и объединяют выходные тензоры по размеру канала. NN() может быть любым нелинейным преобразованием без ограничений на обратимость.
Инвертируемый слой свертки 1x1。Чтобы изменить порядок каналов,Перед слоем бионического соединения вставляется деконвертируемый слой 1 × 1. Инициализировать матрицу весов случайной нормальной матрицей,Его логарифмический определитель равен 0.,Логарифмический определитель будет отклоняться от 0 после одного шага обучения.
многомасштабная структура。многомасштабная Было показано, что структура полезна при обучении шагам потока глубоких слоев. В реализации Flow-TTS каждая индивидуальная шкала представляет собой комбинацию 4 индивидуальных ступеней потока. После каждого индивидуального масштаба несколько индивидуальных каналов тензора удаляются из этапов процесса и объединяются вместе после того, как Модель проходит все этапы процесса.
соединительный блок。соединительный блок (на рисунке 26(c)) аналогичен приведенному выше преобразованию NN(). соединительный начинается с одномерного слоя свертки с размером ядра 1, за которым следует слой индивидуального модифицированного блока ворота (GTU):
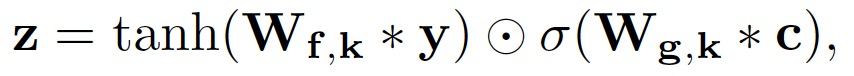
Добавить индивидуальное остаточное соединение на ГТУслой,Чтобы адаптироваться к глубоким слоям, добавьте одномерный слой свертки с размером ядра 1 в конце.,чтобы соответствовать размеру канала. Веса последнего слоя свертки инициализируются нулем.,этотгарантировал, что каждыйиндивидуальныйбионическая связьслой Первоначальное исполнениеиндивидуальныйidentity function。
текущий СОТА! Входит в состав платформы Flow-TTS общий 1 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
Flow-TTS | Перейти к СОТА! Платформа модели получает ресурсы для реализации: https://sota.jiqizhixin.com/project/flow-tts |
VITS
VITS — это полностью параллельный синтезатор. Модель речи, которая производит более естественный синтетический голос по сравнению с двухступенчатой моделью. Модель использует стандартизированный поток, основанный на модели (normalizing flows) вариационное рассуждение (variational inference) стратегии и стратегии состязательного обучения для повышения производительности создания Модели. Также предлагается модуль прогнозирования случайной длительности для улучшения ритмического разнообразия синтезируемого голоса. Используя скрытые переменные вариационного вывода и моделирование неопределенности модулей прогнозирования случайной продолжительности, VITS может очень хорошо справляться с синтезом. Проблема «один ко многим» в речи, при которой для данного текста может быть сгенерирован синтетический голос с широким спектром основных частот и просодических представлений.
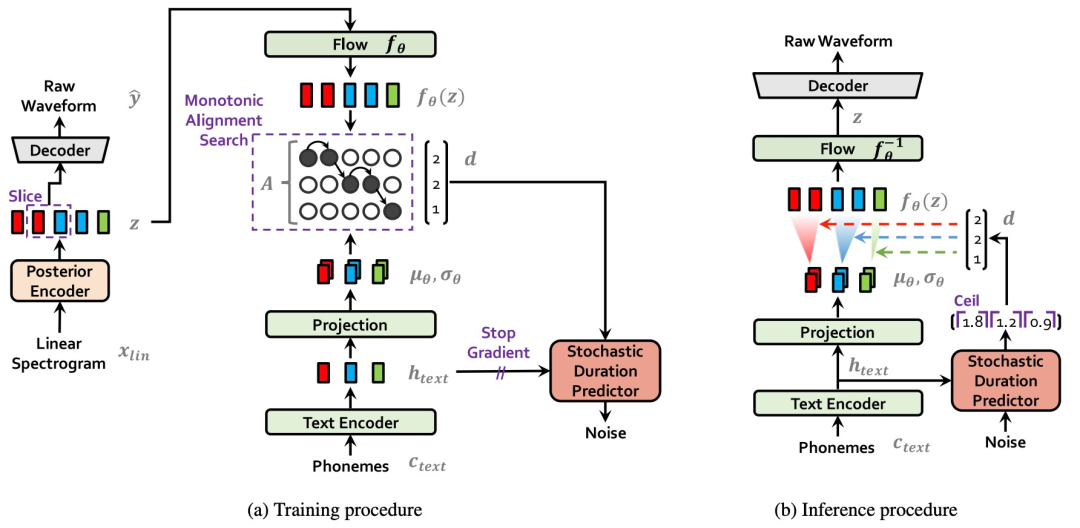
Рисунок 14. Схема системы, изображающая (а) процедуру обучения и (б) процедуру вывода. VITS можно рассматривать как условный посткодер, декодер и условный априор (зеленый блок); : индивидуальный нормализованный поток, слой линейной проекции и текстовый кодировщик) с индивидуальным предиктором случайной продолжительности на основе потока
Как показано на рисунке 14, VITS включает в себя: условную оценку выравнивания VAE, основанную на условном рассуждении и состязательном обучении. Общая структура Модели включает в себя: задний энкодер энкодер), априорный энкодер (априорный кодер), декодер, предиктор случайной длительности. Среди них апостериорный кодер и дискриминатор используются только на этапе обучения модели и не используются на этапе вывода модели. Posterior encoder: Во время обучения апостериорный кодер принимает линейный спектр в качестве входных данных и выводит скрытую переменную z. Скрытая переменная z на этапе вывода генерируется Моделью потока. Апостериорный кодер VITS использует некаузальный остаточный модуль WaveNet в WaveGlow и Glow-TTS. При применении к модели с несколькими людьми векторы динамиков могут быть добавлены к остаточному модулю. Prior encoder: Предыдущий кодер включает в себя текстовый кодер и поток нормализации, который улучшает разнообразие априорного распределения. Кодировщик текста представляет собой преобразователь кодирования, основанный на кодировании относительного положения. К последнему уровню кодировщика текста добавляется линейный слой для генерации среднего значения и дисперсии для построения предварительного распределения. Модуль нормализованного потока содержит несколько остаточных блоков WaveNet. При применении к модели с несколькими людьми векторы динамиков могут быть добавлены к остаточному модулю нормализованного потока. Decoder: Структура декодера и HiFi-GAN Структура генератора V1 такая же. При применении к модели с несколькими людьми вектор говорящего линейно преобразуется и объединяется со скрытой переменной z. Discriminator: Структура дискриминатора такая же, как структура многопериодного дискриминатора в HiFI-GAN. Stochastic duration predictor: Предиктор случайной продолжительности, представление скрытой текстовой фонемысуществоватьсостояниеhtextВведите условие,Оцените распределение фонем по продолжительности.。Применительно к нескольким людям Модель,Вектор динамика линейно преобразуется и склеивается с потенциальным текстом состояния. Структура, а также процедуры обучения и вывода предиктора случайной длительности показаны на рисунках 28 и 29.
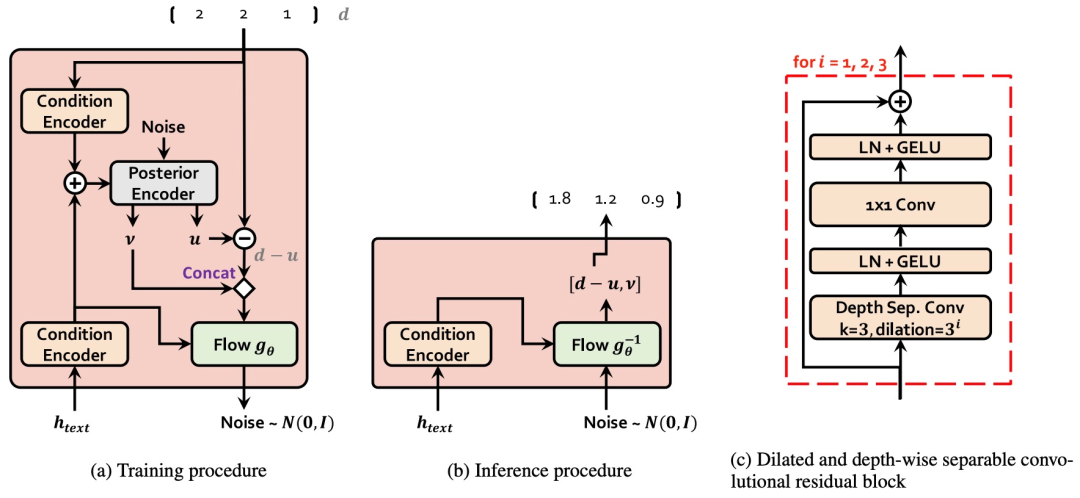
Рисунок 15. Блок-схема, изображающая (а) процедуру обучения и (б) процедуру вывода предиктора случайной длительности. Основными строительными блоками предсказателя случайной длительности являются (c) расширенные и разделяемые по глубине сверточные остаточные блоки.
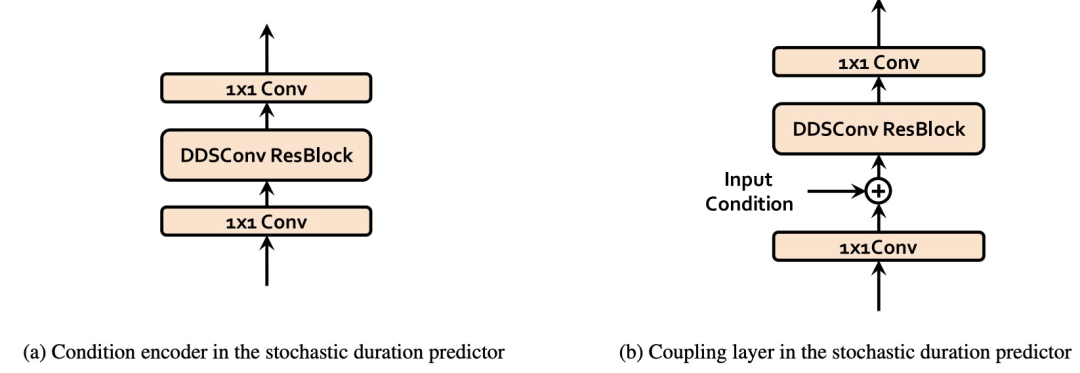
Рисунок 16. Структура (а) условного кодера и (б) связанного слоя, используемого в предикторе случайной длительности
текущий СОТА! Входит в состав платформы VITS общий 2 индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
VITS | Перейти к СОТА! Платформа модели получает ресурсы для реализации: https://sota.jiqizhixin.com/project/cvae-flow-gan |
PnG BERT
PnG BERT — это модель BERT, которая принимает фонемы и символы в качестве входных данных и в основном используется в качестве кодера.PnG для акустической модели. BERT можно предварительно обучить на корпусе, а затем обучить на TTSМодель Тонкая настройка.PnG Основанный на исходном BERT, BERT принимает фонему, графему и выравнивание текста на уровне слов в качестве входных данных, предварительно обучается в режиме самоконтроля на большом объеме текстового корпуса и выполняет точную настройку задачи TTS.
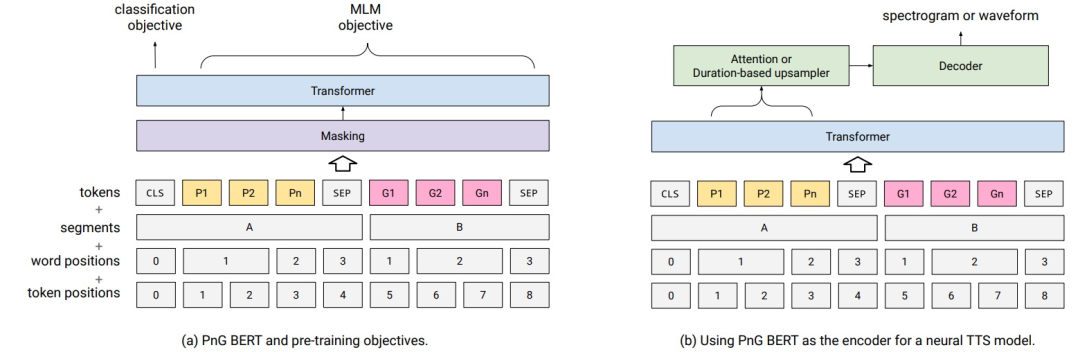
Рисунок 17. Предварительное обучение и тонкая настройка PnG BERT для нейронной TTS. Фонемы показаны желтым цветом, а глифы — розовым.
Входное представление. PnG BERT содержит два сегмента: Нет. Первый сегмент представляет собой последовательность фонем, а фонема IPA используется в качестве токена. Второй сегмент представляет собой поверхностную последовательность слов, а подслова используются в качестве токенов. Подобно BERT, добавляющему теги [CLS] и [SEP], все токены используют общую таблицу внедрения, а целью предварительного обучения является только MLM. В дополнение к исходным встраиваниям токенов, сегментов и позиций BERT существует также Нет.Четыреиндивидуальное встраивание позиции слова, которое обеспечивает фонему на уровне слова и выравнивание плоскости слова. Предварительная подготовка. В режиме самоконтроля фонемы получаются с помощью внешнего инструмента, слова можно сегментировать с помощью Word-Piece, SentencePieceилиBPE, а цель MLM используется только на этапе предварительного обучения. ННГ BERTПринятая стратегия маскировкисуществоватьсловослой Случайная маскировка лиц,Маскируйте по одному одновременноиндивидуальный Поверхность слова и соответствующая последовательность фонем.。12%слова будут заменены на<MSK>,1,5% заменены случайными,1,5% остается неизменным,MLMБудет только таргетингэтот15%слова для расчета。 тонкая настройка。 На рис. 17(б) показан PNG BERT Процесс тонкой настройки. Используйте PNG BERT заменяет кодер NAT и выполняет только точную настройку PnG. Высокий вес слоя BERT предотвращает проблемы, вызванные небольшим тренировочным набором TTS. настройка при переоснащении улучшает способность обобщения окончательной TTSМодели. Из-за особенностей глобального видения с множественным вниманием PnG BERT может получать информацию из текста и фонем. MLM не используется на этапе тонкой настройки.
текущий СОТА! Входит в состав платформы PnG BERT общий 1индивидуальный Модель Реализуйте ресурсы。
проект | СОТА! Страница сведений о проекте платформы |
|---|---|
PnG BERT | Перейти к СОТА! Платформа модели получает ресурсы для реализации: https://sota.jiqizhixin.com/project/png-bert. |
Перейти к СОТА! Ресурсная станция Модели (sota.jiqizhixin.com) может получить код реализации Модели, Модель предварительного обучения и API, включенные в эту статью. другие ресурсы.
Веб-доступ:существовать Введите новый адрес сайта в адресную строку браузера sota.jiqizhixin.com ,Вот и все Перейти к「SOTA!Модель」платформа,Проверятьсосредоточиться Есть ли какие-нибудь новые ресурсы, включенные в Модель на?
Мобильный доступ:существовать Поиск в мобильном терминале WeChatСервисный номеримя「Сердце машиныSOTAМодель」или ID 「sotaai」,сосредоточиться на СОТА! Модель Сервисный номер,Вы можете использовать функции платформы через строку меню внизу вашего сервисного аккаунта.,Регулярно публикуются новейшие технологии искусственного интеллекта, ресурсы для разработки и обновления сообщества.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
