В это время многие люди говорят о некоторых базовых моделях алгоритмов.
Сегодня мы поделимся популярным алгоритмом XGBoost! !
Сегодняшний контент очень подробный! Если вам нужен PDF-файл этой статьи, не забудьте скачать его в конце статьи~
XGBoost, полное имя eXtreme Gradient Boosting,это оптимизированная распределенная библиотека повышения градиента,Разработан для эффективного, гибкого и портативного машинного обучения. Модель.
Основная идея XGBoost — это алгоритм повышения, основанный на деревьях решений градиентного повышения (GBDT), который повышает производительность прогнозирования за счет постепенного построения серии слабых учеников (обычно деревьев решений) и объединения их в сильного ученика.
историческая справка
Предложен и разработан Тяньци Ченом в 2014 году.
Основная цель заключалась в решении проблем эффективности и производительности, существовавших в то время в машинном обучении.
XGBoost добился значительного улучшения скорости и производительности благодаря множеству технических усовершенствований, в том числе:
регуляризация:путем спаривания Модельсложностьрегуляризацияиметь дело с,Предотвратите переоснащение.
параллельная обработка:Путем параллельных вычислений в распределенной среде,Улучшена скорость Модельного обучения.
Алгоритм обрезки деревьев:использоватьжадный алгоритм выполняет обрезку, чтобы гарантировать оптимальность сгенерированного дерева.
Блочная структура с поддержкой кэша:путем оптимизацииданныехранилищеи Метод доступа,Увеличение памятииспользоватьэффективность。
Источник бумаги
XGBoostПодробное введениеи Техническая реализация была впервые опубликована в2016Статья под названием“XGBoost: A Scalable Tree Boosting System”в газете。Среди авторов статьи Чэнь Тяньци.(Tianqi Чен и Карлос Гослин Guestrin)。
Цитаты на бумаге
Эта статья была опубликована на конференции KDD 2016 (Knowledge Discovery and Data Mining), которая является очень важной конференцией в области машинного обучения и интеллектуального анализа данных.
Полная цитата из статьи:
Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '16), 785–794. DOI: https://dl.acm.org/doi/10.1145/2939672.2939785
В этой статье подробно описывается конструкция алгоритма, техническая реализация и влияние XGBoost на различные фактические наборы данных.
Теоретическая основа
Математические принципы XGBoost
XGBoost создает мощную прогнозирующую модель путем интеграции нескольких слабых обучающихся (обычно деревьев решений).
Основная идея повышения градиента
Повышение градиента — это метод ансамблевого обучения, который формирует сильного обучающегося путем итеративного обучения нескольких слабых обучающихся и взвешивания результатов их прогнозирования. Цель каждого раунда обучения — уменьшить остаточную ошибку предыдущего раунда прогнозирования.
Предположим, у нас есть набор обучающих данных
{(x_i, y_i)}_{i=1}^n
,в
x_i
это входная функция,
y_i
является целевым значением. Наша цель — изучить модель
F(x)
, делая прогнозируемое значение
\hat{y}_i = F(x_i)
как можно ближе к истинному значению
y_i
。
В рамках системы повышения градиента глава
t
модель колеса
F_t(x)
Это впереди
t-1
На основе модели колеса добавлен новый слабый обучающийся
h_t(x)
:
F_t(x) = F_{t-1}(x) + h_t(x)
Для оптимизации модели минимизируем функцию потерь
L(y, \hat{y})
, например квадратичная ошибка:
L(y, \hat{y}) = \frac{1}{2} (y - \hat{y})^2
Целевая функция XGBoost
XGBoost расширяет базовый алгоритм повышения градиента, и цель его оптимизации состоит из следующих двух частей:
\Omega(h) = \gamma T + \frac{1}{2} \lambda \sum_{j=1}^T w_j^2
здесь,
T
количество конечных узлов дерева,
w_j
- вес листового узла,
\gamma
и
\lambda
– параметр регуляризации.
Расширение Тейлора второго порядка
Для того, чтобы эффективно оптимизировать целевую функция,XGBoostиспользовать Расширение Тейлора второго порядок приближенной функции потерь. Предположим, что в В раунде наше прогнозируемое значение равно \hat{y}i^{(t)} = F{t-1}(x_i) + h_t(x_i) . Целевую функцию можно записать как:
Разделить баллы кандидатов:Рассчитайте выигрыш от всех возможных точек разделения для всех функций.,Выберите точку разделения с наибольшим усилением.
жадный алгоритм:использоватьжадный алгоритмруководитьстроительство объектов, выберите объект и точку разделения с наибольшим коэффициентом разделения.
обрезка:минимизируяцелевая Функция, позволяющая решить, сохранять ли текущее разделение.
Процесс алгоритма XGBoost
Инициализировать модель:
Установите начальное прогнозируемое значение на константу, обычно среднее целевого значения.
итеративное обучение:
Рассчитайте выигрыш для каждой точки разделения-кандидата.
Жадно выбирает оптимальную точку разделения до тех пор, пока не будет достигнута максимальная глубина или другое условие остановки.
Установите веса конечных узлов нового дерева
w_j^*
Присоединяйтесь к модели.
за каждый раунд
t
:
Рассчитать ток Модельизпредсказыватьценить
\hat{y}_i^{(t-1)}
。
Вычислить первую и вторую производные
g_i
и
h_i
。
Построить новое дерево, свернуть целевую функция:
возобновлять Модель:
Выходные данные модели:
Финальная модель состоит из деревьев со всех раундов.,предсказывать时将所有树изпредсказыватьценить加权求и。
Целое можно увидеть,XGBoost улучшается благодаря ряду технологий,нравитьсярегуляризацияэлемент、二阶导数изиспользовать、Параллельные вычисления и т. д.,实现了在计算эффективностьипредсказыватьпроизводительность上из显著提升。Эти характеристики делаютXGBoostВо многих соревнованиях по машинному обучениюи Отличные характеристики в практическом применении。
Сценарии применения
Проблемы с приложением XGBoost
XGBoost подходит для многих типов задач машинного обучения, особенно в задачах классификации и регрессии.
структурированные данные:XGBoost在иметь дело сструктурированные Он хорошо работает с данными (например, табличными данными) и может обрабатывать большое количество функций и образцов.
Высокоразмерные данные:XGBoost能够有效地иметь дело с Высокоразмерные данных, не требует чрезмерной разработки функций.
крупномасштабные данные:XGBoostиметьпараллельная обработки Функции, оптимизирующие использование памяти, подходящие для крупномасштабной обработки. данныенабор。
Высокие требования к точности:XGBoostОтличные характеристики с точки зрения точности,通常能够获得较高изпредсказыватьпроизводительность。
Плюсы и минусы XGBoost
преимущество:
Высокая точность:XGBoostво многихданныенабор上都能够获得很高изпредсказыватьточность。
Масштабируемость:XGBoostиметьпараллельная способность обработки эффективно обрабатывать крупномасштабные данные。
гибкость:XGBoostПоддержка нескольких Функция потерьирегуляризацияметод,Возможна корректировка в зависимости от конкретных задач.
Важность функции:XGBoost可以自动计算特征из重要性,Помогите разобраться в данных.
недостаток:
Настройка параметров:XGBoostЕсть много параметров, которые необходимо настроить.,Неправильные настройки параметров могут привести к переоснащению или недостаточному оснащению.
Требования к вычислительным ресурсам:XGBoostна тренировкеипредсказывать时需要较多из计算资源。
Не очень хорошо справляется с текстовыми данными.:относительно другихалгоритм(нравиться深度学习Модель),XGBoost не очень хорошо справляется с обработкой текстовых данных.
Случай с Python
Ниже мы используем набор данных по жилищному строительству Калифорнии, чтобы продемонстрировать полный процесс регрессионного анализа XGBoost.
весь процесс,включатьданныенагрузка、предварительная обработка、Модельное обучение、предсказывать、Визуализация и алгоритм Оптимизация~
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
Загрузка и подготовка данных
Язык кода:javascript
копировать
# Загрузка набора данных о ценах на жилье в Калифорнии
california = fetch_california_housing()
X = pd.DataFrame(california.data, columns=california.feature_names)
y = pd.Series(california.target, name='MedHouseVal')
# Разделите набор данных на обучающий набор и тестовый набор.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape)
Модельное обучение
Язык кода:javascript
копировать
# создавать DMatrix данные结构
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# Установить параметры
params = {
'objective': 'reg:squarederror',
'max_depth': 4,
'eta': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'seed': 42
}
# Модель обучения
model = xgb.train(params, dtrain, num_boost_round=100)
# предсказывать
y_pred = model.predict(dtest)
Весь код демонстрирует полный процесс регрессионного анализа XGBoost с использованием набора данных о ценах на жилье в Калифорнии.
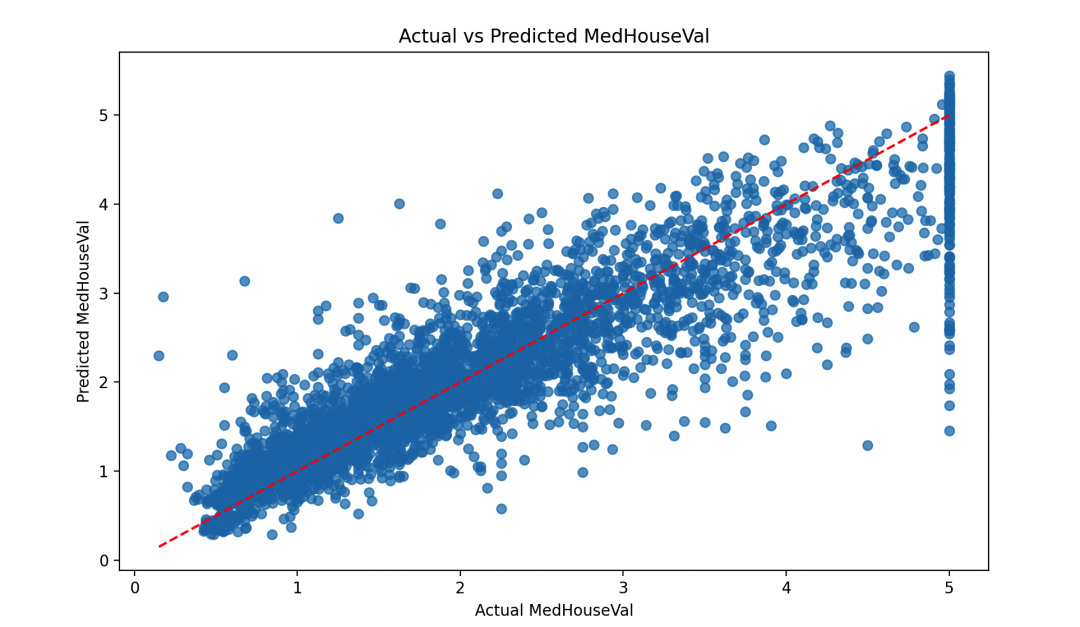
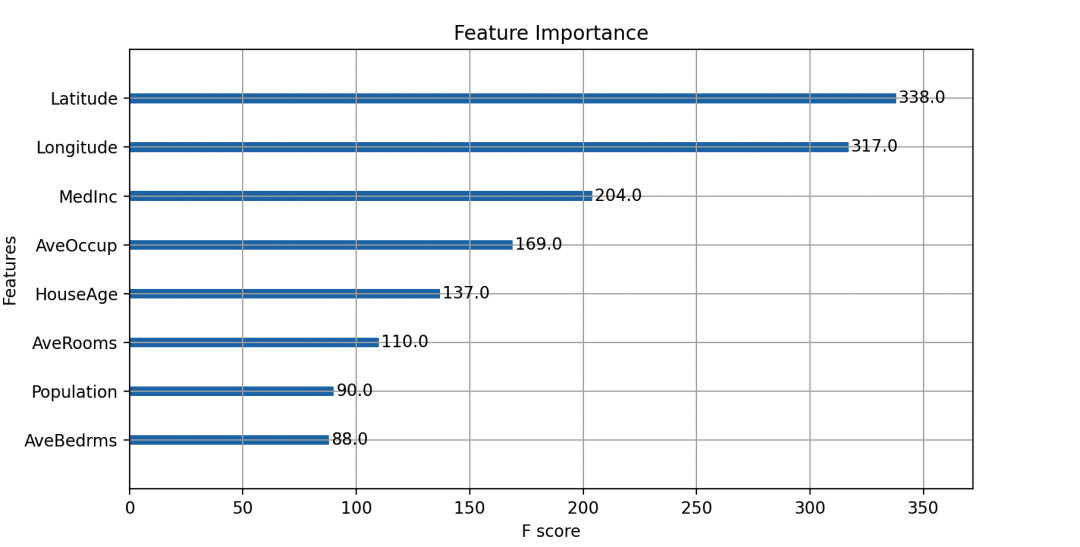
Супер настройка от GridSearchCV параметров,может быть улучшено Модельизпроизводительность。可视化部分включать实际ценитьипредсказыватьценитьиз散点图,а также Важность Диаграмма функций может помочь каждому лучше понять важность производительности и характеристик модели.