Сухая вещь! Идея для построения анализа журнала мониторинга и агента раннего предупреждения.
В 2017 году я тогда участвовал в техническом форуме моей компании и упомянул, что с помощью искусственного интеллекта журналы мониторинга могут обеспечить более своевременные оповещения и даже ранние предупреждения. Однако на тот момент была только идея по этому направлению и не было представления о том, как это реально сделать и реализовать. Прошло семь лет, и даже сегодня эта тема по-прежнему является основной темой в области исследований и разработок, но общедоступного технического решения до сих пор не существует. Когда два дня назад я изучал доводку модели, у меня внезапно появилось вдохновение. Возможно, это идея, способная воплотить в жизнь ожидания, которые у меня были на протяжении многих лет.
Давайте сначала поговорим о выводе: используйте идеи мультимодального обучения, используйте журналы как временные ряды и согласовывайте их с текстом.
Самый ранний метод использования искусственного интеллекта для мониторинга также является основным в современной области мониторинга. Он в основном использует большие данные для сопоставления правил, а затем дополняет их анализом соответствующих моделей для достижения эффектов раннего предупреждения. Однако это решение всегда имеет недостатки: не только недостаточную точность, но и недостаточную своевременность.
После того, как LLM стал мейнстримом, я просто подумал, что раз логи текстовые, то все логи надо отдать большой модели, а затем надо добавить некоторые текстовые описания, чтобы большая модель могла активно реализовывать закономерности между логами. Однако эффект от этого решения очень плохой, поскольку понимание журналов большой моделью все еще остается на текстовом уровне, и она не может по-настоящему понять связь между журналами. Это еще дальше от достижения нашей цели раннего предупреждения.
Два дня назад у меня внезапно появилось вдохновение. Поскольку мультимодальность может понимать изображения, даже видео и временные ряды, почему журналы мониторинга, которые представляют собой естественные временные ряды, должны рассматриваться как текст? Позвольте ему вернуться к своей исходной природе, использовать журналы мониторинга в качестве исходного домена, текст в качестве целевого домена, согласовать и сопоставить последовательности журналов с текстами на естественном языке и реализовать тот же процесс обучения, что и мультимодальность.
Точно так же, как когда мы обучаем статистические диаграммы текстовым описаниям, мы сначала токенизируем материалы исходной области. Здесь мы в основном полагаемся на разделение временных интервалов в качестве токенов. Затем мы реализуем выравнивание текста и используем текст для описания характеристик самого интервала и изменений между ними. особенность интервалов. Приведем простой для понимания пример, если у нас есть следующая картина:
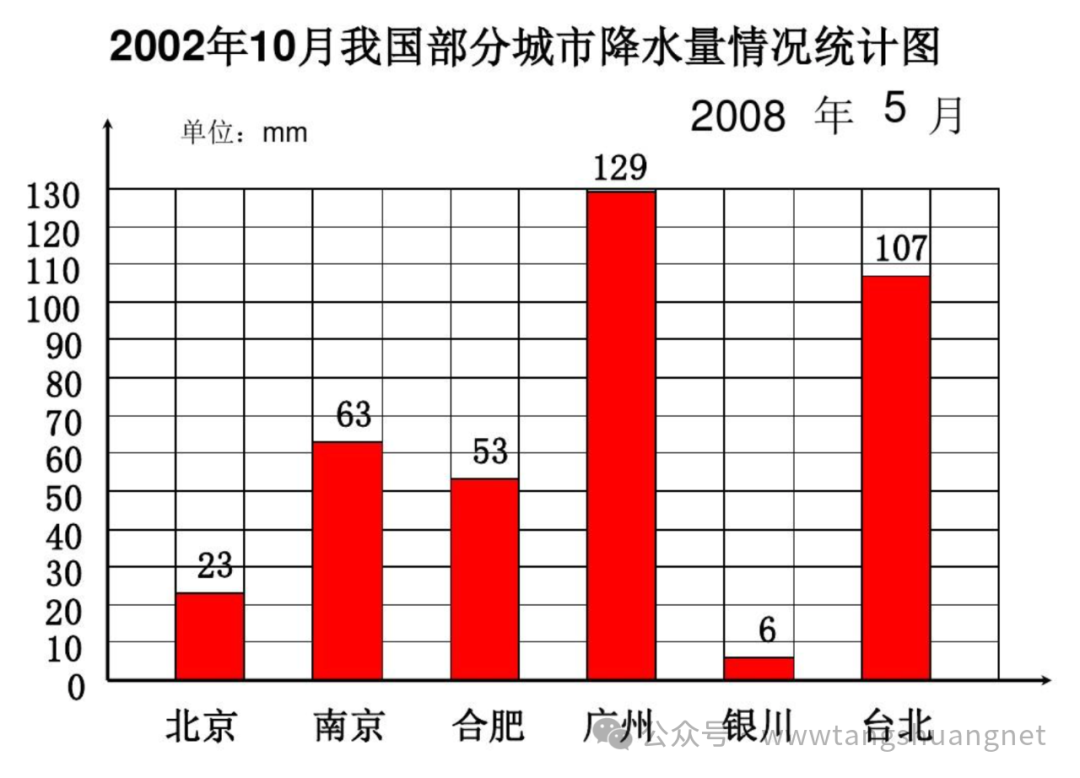
Нам нужно обучить модель, чтобы она соответствовала тексту, который можно полностью выразить на естественном языке. Например
В октябре 2002 года осадки были распределены неравномерно в некоторых городах моей страны, в том числе 23 мм в Пекине и 23 мм в Нанкине... Осадки в восточных городах были значительно выше, чем в западных городах...
Я помню, что на уроке китайского языка в средней школе у нас был специальный урок о том, как описывать содержимое таких диаграмм и анализировать их. По сути, я думаю, что это похоже на тот класс, описывающий диаграммы на естественном языке. Среди них необходимо описать не только явные числовые значения, но и невидимые правила. Например, в данных за год необходимо описать не только значение xx в xx году, но также соотношение и степень подъема и падения между предыдущим и последующим годами, например, такое описание, как «внезапное увеличение на xx%». ".
Когда мы получим соответствующий весовой параметр посредством такого обучения, завершим механизм перекрестного внимания и сопоставим журнал временных рядов с описанием в текстовой области, тогда мы сможем позволить большой модели понять период времени, в котором я прошел. Какой контент хотите ли вы отображать журналы интервального мониторинга? На этом основании для большой модели будет легче судить, соответствуют ли эти журналы определенным правилам, требующим раннего предупреждения.
Мы также можем использовать архитектуру рабочего процесса для разделения понимания последовательностей журналов и анализа ранних предупреждений, чтобы мы могли использовать небольшие модели для более профессиональных задач, тем самым достигая повышения производительности.
Конечно, это всего лишь идея, и я ее не реализовал. Если вам это интересно, пожалуйста, оставьте свои мысли в разделе комментариев ниже.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
