Сухая информация | Создание платформы инфраструктуры данных Ctrip 2.0, эволюция в рамках архитектуры с несколькими машинными залами
Об авторе
cxzl25, старший эксперт по технологиям программного обеспечения в Ctrip, специализируется на экологическом построении в области данных и проявляет большой интерес к распределенным вычислениям, хранению, планированию и т. д., член Apache Kyuubi PMC, Apache Celeborn / ORC Committer.
1. Предыстория
Основные компоненты платформы инфраструктуры данных Ctrip включают в себя: кластер распределенного хранения HDFS, вычислительный кластер YARN, а также вычислительные механизмы Spark и Hive. Архитектура версии 1.0 платформы основания данных постепенно формировалась с 2017 года. С 2018 по 2021 год команда основания данных провела оптимизацию производительности и исправления различных ошибок на основе архитектуры 1.0 для поддержки быстрого роста кластерных данных и вычислительных задач.
С наступлением 2023 года, когда бизнес возобновился, существующие данные на платформе данных также продолжали расти. Чистый прирост объема данных за один день превысил несколько петабайт. Темпы роста являются беспрецедентными, и физические стойки двух. Компьютерные залы для обработки данных IDC не хватает.
При активной поддержке команды OPS был запущен третий проект по строительству комнаты данных IDC, а новый IDC был сдан в течение 2 месяцев.
2. Проблемы, с которыми пришлось столкнуться
Поскольку масштабы кластера продолжают расти, в базовой платформе есть несколько основных болевых точек, которые необходимо срочно решить в 2022-2023 годах:
- Несколько компьютерных залов Архитектураподдерживатьтриданныецентр Архитектура,данныехранилищеи График расчета
- Данные быстро растут, и компьютерному залу необходимо организовать цикл оборудования.,Перемещение холодных объектов в облако может эффективно снизить общую нагрузку на ресурсы.,Сокращение общих затрат
- Данные Рост объемовпривести к Недостаток ресурсов вычислительных мощностей требует расширения масштабов офлайн-существования и возможности осуществления взаимного командирования.
- Вычислительный движок Spark2 необходимо плавно обновить до Spark3
3. Общая структура
В процессе непрерывной эволюции в 2022-2023 годах общая архитектура Data Platform 2.0 показана на рисунке ниже. Уровень хранения поддерживает архитектуру с несколькими машинными залами, трехуровневые данные (горячие/теплые/холодные), прозрачную миграцию, а также возможность чтения кэша и прозрачного ускорения. Уровень планирования поддерживает гибкое планирование приоритетов, смешивание узлов NodeManager, смешивание оффлайн и онлайн-узлов, а также представляет Celeborn в качестве новой службы Shuffle. Уровень движка был обновлен с Spark2 до Spark3 с использованием Kyuubi в качестве записи запроса для Spark.
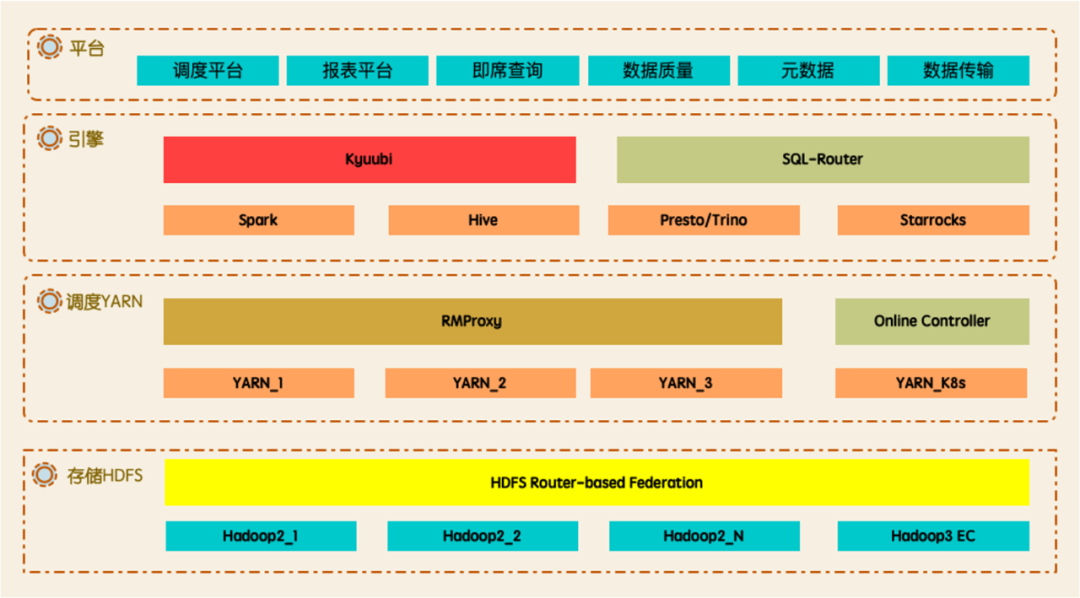
4. Хранение
4.1 Модернизация архитектуры многокомпьютерного зала:поддерживатьтрииндивидуальный Вот и вседанныецентр Архитектура
Была обновлена архитектура многомашинного зала Hadoop. Данные могут совместно использоваться IDC или несколькими IDC. Клиент поддерживает чтение и запись поблизости, чтобы избежать трафика между машинными залами. Недавно добавленный центр обработки данных не будет знать о пользователях, использующих данные. платформа.
4.2 Иерархическое хранение:горячий/температура/холодныйтрислоистыйданныехранилище Архитектураприземление,Подключение к объекту холодного архивирования на облачном хранилище,Снизить стоимость хранилища
Модернизация многосторонних связей и преобразование систем хранения и вычислений: поддерживается горячее/теплое/холодное многоуровневое хранение, «горячие» данные размещаются на «горячих» узлах частного облака, «теплые» данные размещаются на «холодных» узлах Erasure Coding (EC) частного облака, а «холодные» данные периодически перемещались в облачное объектное хранилище. Ультрахолодное архивное хранилище.
4.3 Прозрачная миграция
HDFS изначально поддерживает несколько инструментов миграции, что делает процесс миграции полностью прозрачным для пользователей.
- Balancer - баланс другой DataNode данныераспределенный
- Mover - мигрироватьданныеприезжатьожидатьизхранилищетип DataNode, например миграция в DISK типданныеприезжать ARCHIVE тип DataNode
- Disk Balancer - баланс такой же DataNode Раздача разных дисков
Однако в архитектуре федерации на основе маршрутизатора HDFS (RBF) из-за наличия верхнего предела количества файлов, хранящихся в одной группе NameNode, или из-за того, что RPC приводит к медленному реагированию NameNode, обычным подходом является добавление одного файла. или несколько групп NameNodes и добавление разных групп NameNodes. Данные отдела разделены на разные пространства имен, поэтому часто происходит миграция между пространствами имен кластера HDFS.
Или из-за нового IDC данные и вычислительные задачи определенного отдела необходимо перенести в новый IDC, чтобы устранить нехватку данных и вычислительных возможностей.
Или сохраненные данные преобразуются в данные, закодированные с помощью Erasure Coding, чтобы сэкономить затраты на хранение данных.
Это включает в себя различные виды миграции данных, которые не поддерживаются встроенным инструментом миграции HDFS. Как сделать миграцию более прозрачной для пользователей?
- Для новых данных вы можете использовать RBF из Mount Table Особенность: пусть новые изданные указывают на новые изданные Пространство имен, старые изданные можно постепенно переносить, или как Time to live (TTL) Старые изданные автоматически удаляются, мигрировать не нужно, но если они сохранены в разных каталогах. rename операция, может быть неприменима.
- На всю сумму данные, исходя из FaceBook Версия с открытым исходным кодом Автономная версия FastCopy, в DistCp из База на Расширятьdistributediz FastCopy из программы и исправлений иподдерживать индивидуальную версию с открытым исходным кодом из проблем, Скорректировать как не поддерживаемую DISK тип DataNode из FastCopy,addBlock RPC из Попробуйте еще разпривести к missing block。FastCopy из Принцип да Выберите исходный документиз Block переписыватьсяизмногоиндивидуальный DataNode осуществлять Hard ссылку и сообщите о прибытииновыйизкластер, чтобы добиться быстрой миграции HDFS кластер Юаньданные, но копировать не нужно Block данныеизглазиз。
- Миграция изданных между машинными залами, настройка конфигурации распределения копий между машинными залами, приемлемые пути изданные могут быть размещены как в одном машинном зале, так и в нескольких машинных залах. Стратегия, конфигурация Client Его можно читать и писать поблизости, и он нечувствителен к пользователям.
- изменять EC Кодирование, адаптивные инструменты миграции, конфигурация Сколько дней количество раз чтения было выполнено меньше, чем X Вторичные правила, активируйте автоматизацию, иммигрируйте коммутатор после завершения миграции. RBF из Mount Table,Client можно прочитать напрямую EC Кодирование изданных и поддерживаемых статических разделов, динамический раздел из исторических данных раздела возвращается назад.
4.4 Чтение прозрачного ускорения
Большая часть данных, хранящихся в кластере HDFS, записывается один раз и считывается много раз. Поскольку функция централизованного управления кэшем HDFS, предоставляемая самой HDFS, относительно ограничена, был введен компонент Alluxio для реализации прозрачного доступа по URI на основе версии сообщества. IDC автоматически выбирают главный, мультитенантный один кластер и другие функции, не меняя местоположения, интегрированные с вычислительным механизмом, пользователи могут напрямую и прозрачно использовать функцию чтения кэша.
5. Планирование
5.1 Приоритетное планирование
Благодаря соединению с платформой планирования заданий ETL и управления метаданными можно автоматически повышать приоритет связей задач на основе уровня важности таблицы, классифицировать задачи P0, P1 и PX, реализовывать планирование приоритетов в планировщике YARN и обеспечивать соглашение об уровне обслуживания задач.
5.2 Смешение узлов NodeManager
В нерабочие часы в течение дня кластер временно отключит некоторые узлы NodeManager и переключится на вычислительные узлы Presto, Trino и StarRocks для обработки большего количества специальных запросов и запросов отчетов в течение дня.
Это создает несколько проблем. Автономному NodeManager необходимо быстро очистить запланированные контейнеры, но служба Shuffle, на которую полагаются Spark или MapReduce, возможно, не сможет получить данные Shuffle, поскольку NodeManager останавливает службу, что приводит к остановке выполнения вычислительной задачи. частично завершиться неудачей и повторить попытку. Общее время выполнения длительных задач.
В связи с этим, когда NodeManager временно отключен от сети, поток службы и порт службы Shuffle по-прежнему сохраняются, что гарантирует, что процесс Shuffle не завершится сбоем. А для важных задач P0 и P1 реализован механизм черного списка совмещенных узлов NodeManager, чтобы гарантировать, что ресурсы контейнера, запрошенные важными заданиями, не будут запланированы для этих совмещенных вычислительных узлов, и предотвратить сбой выполнения задачи во время автономный процесс.
5.3 Смешение офлайн- и онлайн-узлов
Использование ресурсов онлайн-сервисными приложениями меняется в зависимости от количества посещений конечных пользователей. Многие приложения имеют низкую загрузку ЦП в ночное время и имеют приливные характеристики. Задачи по обработке данных обычно требуют более высоких ресурсов в кластерах YARN рано утром. Возникает проблема. недостаточности ресурсов, таких как ожидание приложения или контейнера.
Посредством портретного анализа автономных заданий Spark, MapReduce и Kyuubi Spark Engine мы собираем показатели чтения, перемешивания, записи и другие показатели заданий, расставляем приоритеты задач, связываемся с платформой планирования заданий ETL и отправляем их в онлайн-кластер YARN, развернутый на базе K8s. и реализовать гибкое планирование контейнеров с помощью функции метки узла YARN.
5.4 Remote shuffle service Celeborn
В решении Spark on YARN при включении динамического распределения ресурсов Spark часто необходимо развернуть внешнюю службу перемешивания Spark (ESS) в NodeManager, чтобы предоставить услуги чтения данных в случайном порядке после того, как исполнитель простаивает и перезапускается.
Хотя ESS претерпела ряд оптимизаций, таких как завершение записи в случайном порядке и объединение в один большой файл, чтобы избежать создания большого количества маленьких файлов в NM, некоторых проблем все же нельзя избежать. При случайном чтении большое количество случайных чтений, а у NM большое количество дисковых IOWait, что приводит к ошибке FetchFailed и необходимо пересчитывать этап. А чтение в случайном порядке создаст соединения M*N. Если разделы MapTask и Shuffle имеют большой размер, задание часто вызывает FetchFailed из-за тайм-аута соединения или сброса.
В решении Spark на K8s служба внешнего перемешивания в настоящее время не поддерживается. Поэтому, если вы хотите включить динамическое распределение ресурсов Spark в K8s, вы можете включить только spark.dynamicAllocation.shuffleTracking.enabled=true, чтобы у Исполнителя не было этого параметра. данные активного перемешивания могут быть освобождены и переработаны, а общее время высвобождения ресурса удлиняется.
В связи с вышеуказанными проблемами был представлен компонент Celeborn службы удаленного перемешивания (RSS) Celeborn, который был развернут в узлах NodeManager нескольких IDC, интегрирован с механизмом Spark и включен в оттенках серого на платформе специальных запросов и платформе планирования ETL. .
Сервис Celeborn может решить и оптимизировать текущие проблемы ESS. Преимущества Celeborn заключаются в следующем:
- использовать Push-Style Shuffle заменять Pull-Style, уменьшить Mapper издавление памяти
- поддерживать IO Агрегация, перемешивание Read из Номер подключенияот M*N вплоть до N, при этом случайное чтение меняется на последовательное чтение
- поддержка механизма двух копий, уменьшение вероятности Fetch Fail
- поддерживатьвычислитьихранилищеразделение Архитектура,ивычислитькластерразделение
- решать Spark on Kubernetes час Зависимость от локального дискаиз
6. Механизм расчета
6.1 Spark3
Apache Spark 2.2 был представлен в 2017 году. На основе этой версии было выполнено множество индивидуальных разработок для реализации мультитенантного Thrift Server, который по сути заменил Hive CLI/HiveServer2 SQL и стал основным механизмом SQL Ctrip, обслуживающим вычисления ETL и специальные Запросы и отчеты.
В июне 2020 года был официально выпущен Spark 3.0. Он имеет мощную функцию адаптивного выполнения запросов (Adaptive Query Execution). Благодаря оптимизации плана выполнения запроса во время выполнения Spark Planner может выполнять дополнительные планы выполнения во время выполнения. на основе статистики времени выполнения, такой как динамическое объединение случайных разделов, динамическая настройка стратегий объединения и динамическая оптимизация искаженных объединений для повышения производительности.
С выпуском Spark 3.2 в октябре 2021 года мы начали изучать возможность обновления. Наконец, после серии исследований, мы перенесли несколько требований по настройке Spark2 и завершили плавное обновление с Spark2 на Spark3.
6.1.1 Плавное обновление Spark3
1) Используйте режим «Только план Кьюби» для воспроизведения онлайн-SQL и классификации типов с несовместимым синтаксисом.
Kyuubi Spark Engine устанавливает kyuubi.operation.plan.only.mode=OPTIMIZE в сочетании с метаданными, чтобы получить оптимизированный план выполнения отправленного SQL, который можно классифицировать по типу ошибки SQL.
2) Совместимость с Hive SQL, метахранилищем Hive, Spark2 SQL.
- Расширять BasicWriteTaskStats собирает и записывает несекционированные таблицы, секционированные таблицы (статические секции, динамические секции). Несколько типов записи: запись по количеству строк, номеру документа, размеру данных. (numRows,numFiles,totalSize)。
- Spark создать представление Hive совместимый
Представление, созданное Spark после USE DB, приведет к тому, что Hive не сможет прочитать представление, поскольку viewExpandedText не полностью перезаписан. Текущая информация о базе данных хранится в свойствах таблицы представления в метахранилище Hive, считывающем таблицу, соответствующую. Вид, потому что нет USE БД Соответствующая таблица не найдена.
Выполнение DDL в Hive для изменения определения типа представления Spark приведет к тому, что Spark не сможет прочитать представление, поскольку Spark сохранит текущую схему в spark.sql.sources.schema свойств таблицы представления при создании представления. Когда Spark считывает представление, схема. При восстановлении из этого атрибута, поскольку Hive изменяет представление, он не будет изменять этот атрибут одновременно, что приводит к тому, что Spark не может прочитать представление, измененное Hive.
Здесь используется подход Hive для переписывания viewExpandedText, завершения текущей информации о БД и удаления схемы, хранящейся в свойствах таблицы, чтобы гарантировать, что несколько механизмов могут изменять и читать ее.
- Избегайте полной постоянной загрузки UDF.
Когда Spark запускается в некоторых режимах, он может извлечь постоянные определения UDF всех баз данных из хранилища метаданных Hive, что приводит к медленному запуску Spark и оказывает определенное влияние на загрузку хранилища метаданных Hive. Необходимо избегать прямой инициализации Hive Client, чтобы избежать полной постоянной загрузки UDF.
[SPARK-37561][SQL] Avoid loading all functions when obtaining hive's DelegationToken
- избегайте создания 0 Size из ORC документ
Реализация OrcOutputFormat в Hive находится в методе закрытия. Если в задаче нет данных для записи, во время закрытия будет создан файл ORC нулевого размера или более низкие версии ORC, на которые опирается Spark2.
Хотя патч ORC-162 (Обрабатывать файлы размером 0 байт как пустые файлы ORC) может решить эту проблему, обновить более ранние версии нескольких компонентов сложно, поэтому мы исправили версию Hive, от которой зависит Spark3. Создайте файл ORC с помощью . пустая схема без данных, чтобы гарантировать, что во время обновления в оттенках серого файл данных, созданный Spark3, последующим Spark и Hive, может нормально читать данные таблицы.
3) Пересадите пользовательские функции Spark2 и внедрите некоторые правила через SparkSessionExtensions.
На ранней стадии вторичной настройки и разработки Spark2 у Spark2 еще не было богатых интерфейсов API, позволяющих разработчикам внедрять собственные реализации. Это привело к тому, что некоторые персонализированные функции были напрямую связаны с исходным кодом Spark2, что создавало проблемы при обновлении трансплантации Spark3. Есть много неудобств, код разбросан по различным файлам кода, его можно пропустить при трансплантации, отсутствуют некоторые сквозные тесты.
В процессе обновления Spark3 индивидуальные требования были реорганизованы, новые файлы кода были максимально удалены, а некоторые правила SQL были извлечены, упакованы в подключаемые модули Spark и внедрены в SparkSessionExtensions для облегчения последующих обновлений и обслуживания.
4) Создайте CI/CD в GitLab на основе SBT для быстрой интеграции.
При вторичной разработке Spark или патче сообщества для резервного копирования Spark требуется полный рабочий процесс тестирования. Версия CI сообщества построена на основе действия GitHub. Внутренний GitLab относится к аналогичному рабочему процессу, поскольку скорость сборки и тестирования SBT намного выше, чем у Maven. , поэтому на основе SBT можно разбирать и тестировать более 10 модулей. После прохождения компиляции jar соответствующей ветки будет автоматически развернут в среду проверки для дальнейшей отладки разработчиками. Это значительно повышает стабильность запроса Spark Merge и эффективность проверки кода, а также делает Spark более надежным в производственной среде.
5) Стратегия обновления оттенков серого, переключение детализации задач
Связанный с платформой планирования ETL, он поддерживает уровень или процент задач в зависимости от приоритета задачи, переключение с Spark2 на Spark3 в оттенках серого и автоматический возврат в случае сбоя. Также существует платформа качества данных. После завершения каждой задачи появляется платформа. соответствующая гарантия проверки данных. Также есть сравнение времени работы и мониторинг ошибок.
6.1.2 Оптимизация функции фильтра разделов
Чтобы запросить таблицу с десятками тысяч разделов, механизм запросов Hive использует функцию substr для фильтрации поля раздела d. Он использует RPC get_partitions_by_expr, предоставленный хранилищем метаданных Hive, для выполнения обрезки разделов. получить небольшое количество разделов, удовлетворяющих условиям.
Однако сокращение разделов, реализованное в Spark, не поддерживает функции, поэтому, если существует функция SQL, где функция substr(d,1,10) = '2023-01-01' фильтрует разделы, это приведет к тому, что метахранилище Hive получит большое количество разделов. ЦП загружен до 100%, и клиент выйдет из строя, поскольку получение слишком большого количества сведений о разделах приведет к OOM.
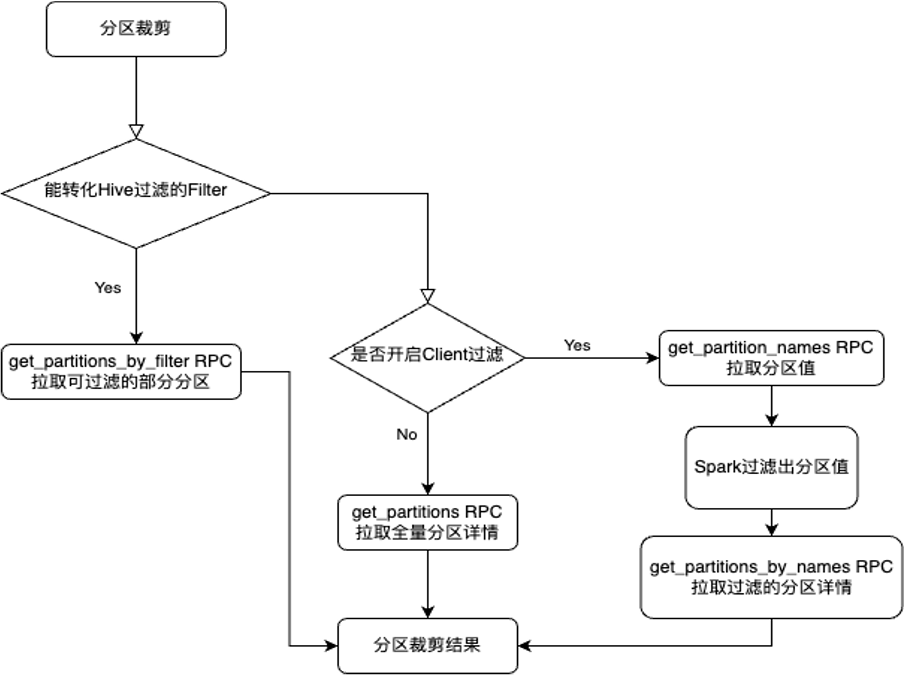
Анализируя вызывающую ссылку Spark для сокращения раздела, Spark сначала преобразует поддерживаемые операторы в Filter SQL, который Hive поддерживает фильтрацию. Если преобразование поддерживается, он напрямую использует get_partitions_by_filter RPC для получения сведений о разделе. Если преобразование не поддерживается, используйте RPC get_partitions, чтобы получить все сведения о разделе, а затем используйте операторы Spark для фильтрации значений раздела. Стоимость вызова слишком высока.
Если мы извлекем уроки из реализации Hive, поскольку функции Spark и определения функций, предоставляемые Hive, не обязательно совпадают, функции Spark могут быть не реализованы в Hive, поэтому реализация get_partitions_by_expr в Hive неприменима на стороне Spark.
[SPARK-33707][SQL] Support multiple types of function partition pruning on hive metastore
Здесь принята другая идея. Когда преобразование Filter SQL не поддерживается, сначала вызовите get_partition_names RPC, чтобы получить список разделов, затем отфильтруйте необходимые значения раздела через оператор Spark, а затем вызовите get_partitions_by_names RPC, чтобы получить соответствующее значение раздела после. В частности, время вызова сокращается с десятков минут до секунд, что значительно повышает эффективность очистки разделов.
Версия сообщества предоставляет элемент конфигурации, который необходимо включить с помощью spark.sql.hive.metastorePartitionPruningFastFallback=true.
[SPARK-35437][SQL] Use expressions to filter Hive partitions at client side
6.1.3 Неравномерность данных
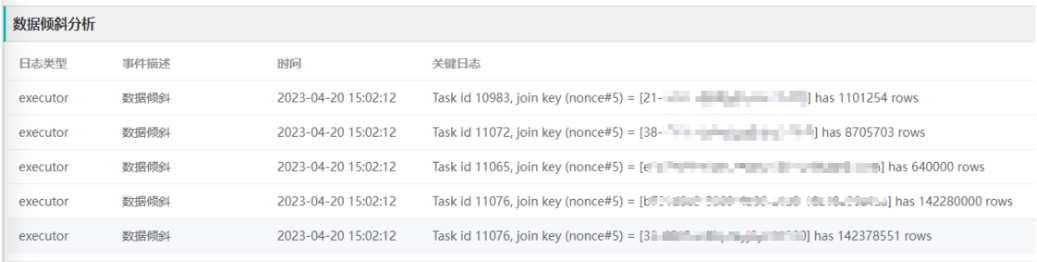
Хотя искаженное соединение можно автоматически оптимизировать в Spark3 AQE, в некоторых сценариях смещенные ключи все еще существуют. Например, на этапе нет функции «Перемешать» и отсутствует статистическая информация во время выполнения. Перед продолжением работы «Скошенное соединение» необходимо вычислить, имеют ли различные разделы асимметрию. оптимизация.
Сначала найдите ключ перекоса данных в Spark, внедрите JoinKeyRecorder в SortMergeJoin и соберите количество строк ключа каждого объединения задач и ключа максимального количества строк, аналогично реализации JoinOperator в Hive.
Затем выполните соответствующий анализ в анализаторе журнала событий диагностической платформы для извлечения ключа соединения и количества строк. Когда пользователь диагностирует задание, он может отображать наличие искаженного ключа и количество искаженных строк.
Диагностическая платформа основана на вторичной разработке компаса с открытым исходным кодом и представляет собой диагностического робота, интегрированного в пользовательский интерфейс Spark History и корпоративный IM. Пользователи могут выполнять самодиагностику, введя идентификатор задания или идентификатор приложения системы планирования, а бот может это сделать. сформировать диагностический отчет.
диагностический робот
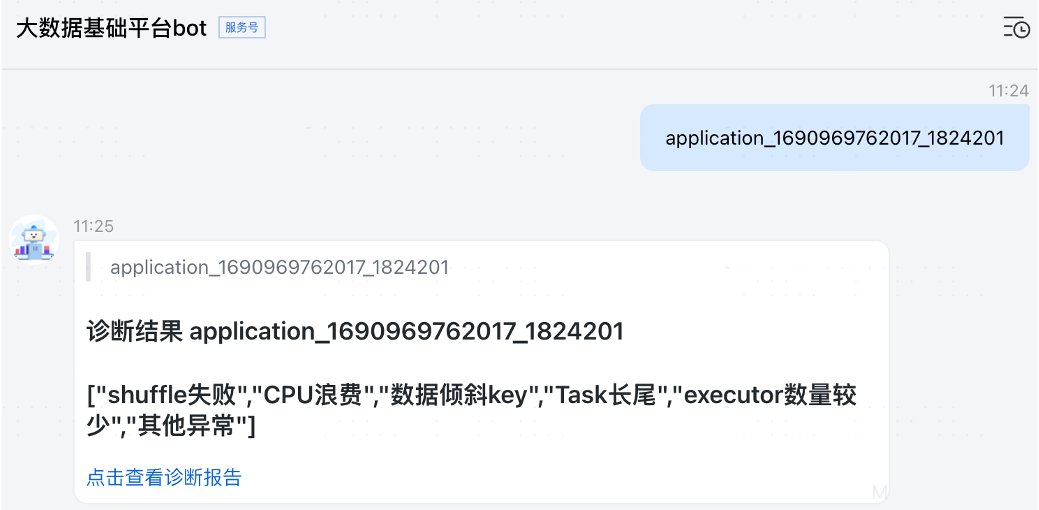
Созданный диагностический отчет
6.2 Kyuubi
6.2.1 Spark2 Thrift Server
Spark Thrift Server (STS), соответствующий HiveServer2, предоставляемый Hive, представляет собой службу Thrift, реализованную сообществом Apache Spark на основе HiveServer2. Цель состоит в том, чтобы обеспечить полную совместимость с HiveServer2. Как и в случае с HiveServer2, SQL передается на Thrift Server через интерфейс JDBC.
По сравнению с HiveServer2, Spark Thrift Server относительно хрупкий. Spark Driver немного загружен, чем Hive Driver. Hive отвечает за компиляцию и оптимизацию SQL, отправку заданий MapReduce и результаты опроса. Драйвер Spark не только выполняет аналогичные действия, что и Hive, но также должен управлять планированием ресурсов, увеличивать и уменьшать количество исполнителей по мере необходимости, планировать выполнение заданий и задач, а также управлять планированием ресурсов. широковещательные переменные и небольшая таблица, это также увеличивает вероятность возникновения проблем с OOM у драйвера Spark. Когда эта проблема возникает в одном и том же процессе, связанном драйвером и сервером, проблема становится более серьезной. Если сервер выходит из строя, запрос нескольких сеансов. может напрямую потерпеть неудачу.
Нативный STS по-прежнему имеет следующие проблемы:
- Проблема с одной точкой сервера
HiveServer2 не поддерживает высокую доступность через Zookeeper.
[SPARK-11100] HiveThriftServer HA issue,HiveThriftServer not registering with Zookeeper
- Нетподдерживатьмногоиндивидуальный Неттакой жеизпользователь
Thrift Server не может выполнять инструкции запроса с пользователем, отправившим запрос, вместо пользователя, запустившего Thrift Server, аналогично HiveServer2 hive.server2.enable.doAs.
[SPARK-5159] Thrift server does not respect hive.server2.enable.doAs=true
- Нетподдерживать Cluster режим, ограниченный Driver Запустите машину и память
Поскольку вышеупомянутый собственный Spark Thrift Server не может удовлетворить потребности, некоторые реализации были расширены в Spark2, например, поддержка мультитенантности и реализация высокой доступности на основе Zookeeper.
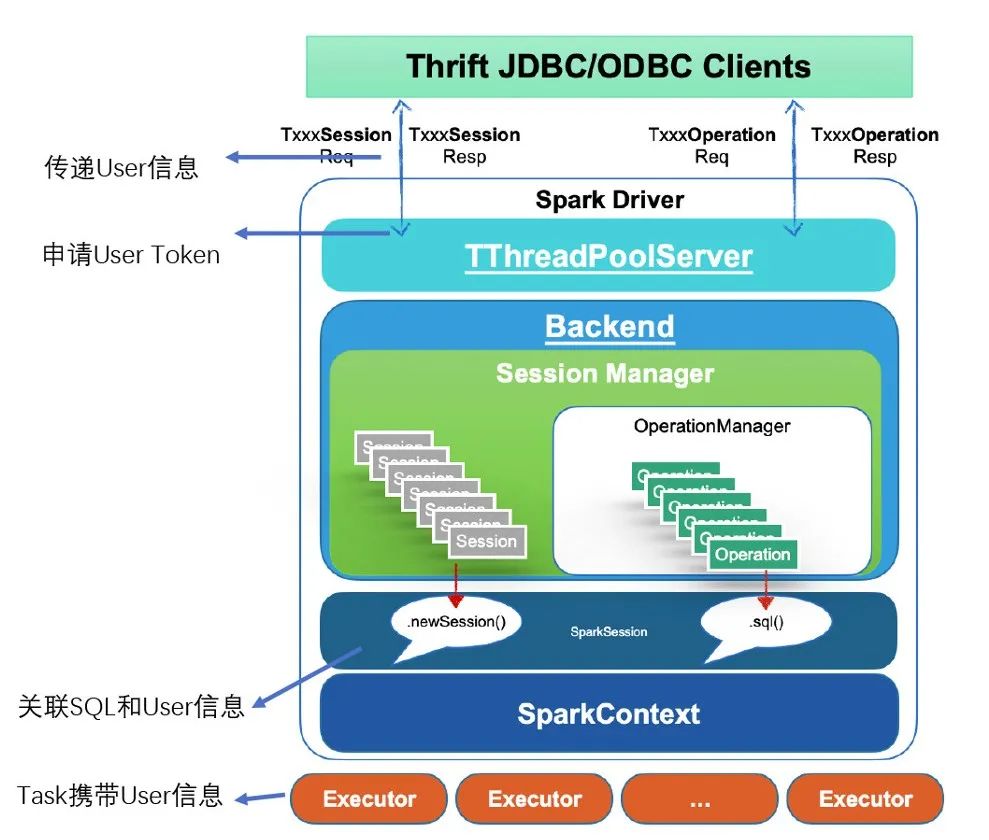
Чтобы реализовать функцию мультитенантности, когда Клиент инициирует openSession, Сервер подает заявку на токены делегирования HDFS и токены делегирования Hive для текущего пользователя сеанса в SparkSQLSessionManager.openSession. Эта передача и обновление токена аналогичны логике обновления токена Spark2 Streaming.
Затем свяжите SQL, JobId, информацию о пользователе, когда DAGScheduler отправит задание, и привяжите его к задаче.
Затем используйте действия UGI, соответствующие задаче в Executor для выполнения.
Поскольку существует множество реализаций Spark2, использующих пулы потоков, для выполнения их также необходимо моделировать как разных пользователей.
- BroadcastExchangeExec.executionContext Глобальный изпул потоков
- UnionRDD.partitionEvalTaskSupport Глобальный из ForkJoinPool
- HIVE-13120: propagate doAs when generating ORC splits
Такая реализация также имеет множество ограничений.
- существует уровень YARN Приложение соответствует изпользователюдасуперпользователю,Невозможно детально разделить ресурсы.
- Spark Jars、Files даглобальный обмен, это привело к UDF Изоляция не очень хорошая
- Расширять Пары функций Spark Core 、SQL、ThriftServer В модуле много изменений, и Spark Версия с глубокой привязкой
6.2.2 Kyuubi Spark3 Thrift Server
При обновлении Spark3 мы решили отказаться от исходной реализации преобразования Spark2 Thrift Server и внедрить проект Apache Kyuubi.
Кьюби имеет следующие преимущества
- изоляцияхороший секс,поддерживатьочередь ресурсовизоляция,Engine изоляция
- Проектирование для естественной мультиарендности,Удобство выставления счетов,поддерживать Cluster модель
- Не с Spark специфический Версияобязательность,поддерживать N размер Spark3 Версия
- использовать Explain модель, можно предварительно разобрать SQL
- поддерживать Server、Engine graceful stop
- Персонализированная конфигурация может быть выполнена для разных пользователей.
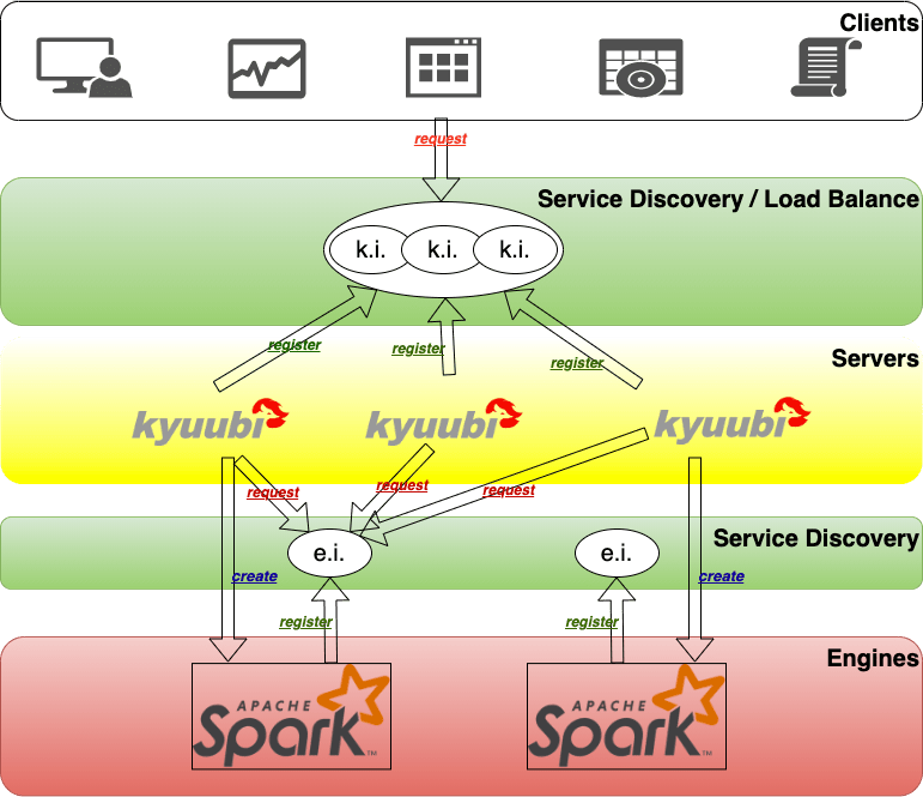
Архитектура Kyuubi разделена на два уровня: один — уровень сервера, а другой — уровень двигателя.
И уровень сервера, и уровень механизма имеют уровень обнаружения служб. Уровень обнаружения служб уровня сервера Kyuubi используется для случайного выбора сервера Kyuubi. Сервер Kyuubi является общим для всех пользователей.
Уровень обнаружения сервисов уровня Kyuubi Engine невидим для пользователей. Он используется сервером Kyuubi для выбора механизма Spark соответствующего пользователя. Когда поступает запрос пользователя, сервер Kyuubi случайным образом выбирает сервер Kyuubi и переходит на уровень обнаружения служб Engine, чтобы выбрать механизм. Если Engine не существует, он создаст Spark Engine. После запуска этого Engine он зарегистрируется на уровне обнаружения служб Engine, а затем будет установлено внутреннее соединение между сервером Kyuubi и Engine. Таким образом, сервер Kyuubi используется всеми пользователями, а Kyuubi Engine — это ресурс, изолированный между пользователями.
В настоящее время Kyuubi полностью заменил исходную службу Spark2 Thrift Server в качестве входа в Spark для систем мгновенных запросов, проверки качества и отчетности.
- Динамическая удаленная конфигурация На основе удаленного центра настройки различные конфигурации задаются и активируются пользователем и группой пользователей.
- Динамический механизм выхода из системы с разделением времени Дайте двигателю поработать на холостом ходу дольше в течение дня, чтобы избежать более медленного холодного запуска двигателя.
- динамическое планирование Engine кластер исторический портретанализировать,использовать ресурсы меньше из Engine Разрешить планирование прибытия в автономном режиме, существует онлайн-кластер со смешанным отделом
6.2.3 Отслеживание полносвязной родословной Кьюби
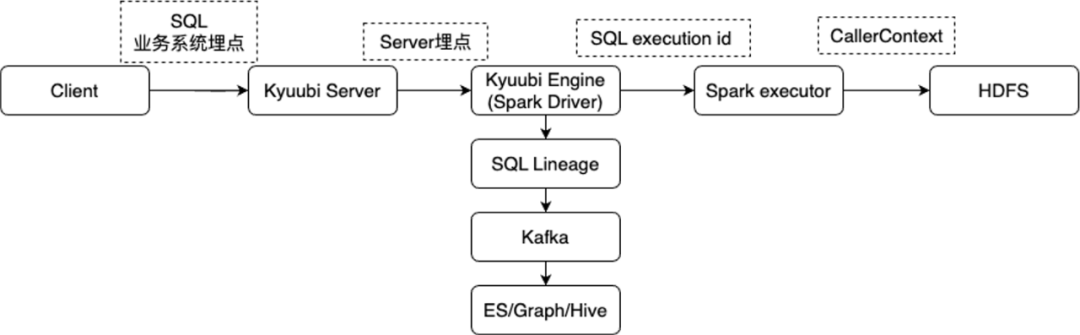
Как в случае многопользовательского общего механизма отслеживать каждый SQL-запрос? В связи с этим реализовано полнозвенное отслеживание родословной.
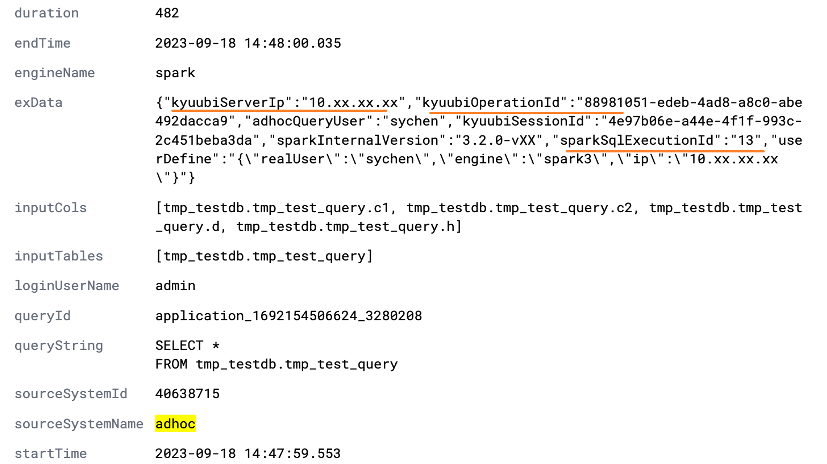
На уровне SQL Lineage, на основе реализации API spark.sql.queryExecutionListeners, собираются IP-адрес сервера/движка Kyuubi, идентификатор сеанса, идентификатор операции, а также текущий идентификатор приложения Spark YARN и идентификатор выполнения SQL.
На уровне журнала аудита HDFS реализация CallerContext задачи Spark расширена и внедрен идентификатор выполнения SQL.
Таким образом, вся ссылка может быть связана с каждым идентификатором выполнения SQL. На уровне происхождения SQL вы можете узнать, какой сеанс и какое выполнение прочитали, какие данные и какая таблица была записана. В журнале аудита HDFS вы можете увидеть. Подробности. Доступ к каким файлам данных осуществляется по соответствующему идентификатору SQL, чтобы достичь цели более точного отслеживания и работы.
SQL lineage
HDFS audit log

7. Резюме
Несколько базовых компонентов работают вместе для достижения следующих преимуществ:
1) Оптимизация доходов на архитектурном уровне
Архитектура платформы данных 1.0 стабильно работала в течение 5 лет с 2017 по 2022 год, прежде чем достигла узкого места. Ожидается, что новая архитектура 2.0 станет масштабируемой после завершения строительства в 2023 году. Ожидается, что она сможет защитить данные группы в режиме реального времени. в ближайшие несколько лет и обеспечить непрерывное, стабильное и эффективное выполнение групповых задач по обработке данных. В случае быстрого роста объема данных архитектура нескольких центров обработки данных + холодных данных в облаке также будет обладать высокой устойчивостью.
2) Преимущества оптимизации механизма хранения данных
Он поддерживает «горячие», «теплые» и «холодные» данные, возможности многоуровневого кэширования, а также поддерживает хранение и миграцию из нескольких центров обработки данных.
3) Планирование преимуществ оптимизации механизма
Приоритетное планирование обеспечивает общую своевременность выполнения задач P0 и P1. После разработки новой версии инструмента совместного размещения в автономном и онлайн-режиме в 2023 году среднее количество заимствованных логических ядер ЦП в день составит десятки тысяч. , а простаивающие ресурсы онлайн-кластера будут использоваться для ускорения оффлайн-расчетов.
4) Рассчитайте преимущества оптимизации двигателя
- Обновление с Spark2 до Spark3 поддерживает в среднем ежедневное выполнение более 600 000 задач Spark, увеличивая скорость выполнения примерно на 40%.
- приземленные Сервисный шлюз Kyuubi,Динамический анализ времени расширения и сжатия,динамическое планированиекластер, среднесуточное значение превышает 30 Тысячи запросов
- Реализован Alluxio для обеспечения прозрачного доступа к таблицам Hive, автоматического разделения на «горячие» и «холодные» и увеличения скорости чтения на 30–50 % в некоторых сценариях.
- приземление Келеборн, вычислительная машина Spark интегрированный,Можетподдерживатьболее мелкая детализацияиз Оффлайнсуществовать Линейно-смесительный отдел
- поддерживатьмногодобрыйданныекомпонент озера,поддерживатьмногодобрыйхранилищетип,горячийданные,EC Холодные данные, облачные холодные данныечитать имеют множество характеристик.
В будущем мы продолжим углублять экосистему компонентов данных и своевременно внедрять новые стеки технологий. Благодаря постоянным исследованиям и инновациям мы будем стремиться оптимизировать системную архитектуру, чтобы повысить стабильность кластера и повысить эффективность обработки данных. обеспечить надежность и производительность системы, а также удовлетворить растущие потребности бизнеса в предоставлении пользователям более качественного обслуживания.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
