Структура данных Redis: комплексный анализ типа списка
Тип списка в Redis используется для хранения нескольких упорядоченных строк. Каждая строка в списке становится элементом. Список может хранить до 2^32-1 элементов. В Redis вы можете вставлять (push) и извлекать (pop) с обоих концов списка, а также вы можете получить список элементов в указанном диапазоне, получить элементы с указанным индексом индекса и т. д. Список — это относительно гибкая структура данных, которая может играть роль стека и очереди. В реальной разработке он имеет множество сценариев применения.
1. Тип данных списка
1.1. Знакомство с типом списка.
Тип списка в Redis используется для хранения нескольких упорядоченных строк. Каждая строка в списке становится элементом. Список может хранить до 2^32-1 элементов.
В Redis вы можете вставлять (push) и извлекать (pop) с обоих концов списка, а также вы можете получить список элементов в указанном диапазоне, получить элементы с указанным индексом индекса и т. д. Список — это относительно гибкая структура данных, которая может играть роль стека и очереди. В реальной разработке он имеет множество сценариев применения.
Типы списков имеют следующие характеристики:
- Элементы в списке упорядочены, то есть вы можете получить элемент или список элементов в определенном диапазоне через индексный индекс;
- Элементы в списке могут повторяться
1.2. Перечислите сценарии применения.
Согласно характеристикам двустороннего списка Redis, он также используется для асинхронных очередей. В реальной разработке структура задачи, которую необходимо отложить, сериализуется в строку и помещается в очередь Redis. Другой поток получает данные из этого списка для последующей обработки.
Сценарии использования:
- Очередь сообщений. При доступе к сообщениям очередь сообщений должна отвечать трем требованиям, а именно сохранению порядка сообщений, дублирующей обработке сообщений и надежности сообщений. Два типа данных Redis, List и Stream, могут удовлетворить этим трем требованиям очереди сообщений;
- Последняя функция очереди сообщений: аналогична очереди сообщений.
Но с другой стороны, использование Redis List в качестве очереди сообщений также имеет некоторые недостатки, такие как:
- Сохранение сообщений: Redis — это база данных в памяти. Хотя существует два механизма сохранения сообщений, Aof и Rdb, это лишь вспомогательные средства, и оба метода ненадежны. Когда сервер Redis выйдет из строя, некоторые данные будут потеряны, что неприемлемо для многих предприятий;
- Проблемы с производительностью «горячих клавиш». Независимо от того, используете ли вы кластерное решение, такое как Codis или Twemproxy, запросы на чтение и запись в определенную очередь в конечном итоге попадут в один и тот же экземпляр Redis, и проблему невозможно решить путем расширения емкости. Если одновременное чтение и запись определенного списка очень велико, будет сгенерирована неразрешенная горячая клавиша, что может серьезно привести к сбою системы;
- Всякий раз, когда Rpop выполняется для использования фрагмента данных, это сообщение навсегда удаляется из списка. Если потребитель не может получить сообщение, сообщение не может быть получено. Вы можете сказать, что потребитель может повторно доставить сообщение в очередь в случае сбоя, но это слишком идеально, а что, если потребительский процесс выйдет из строя напрямую, например, kill -9, паника, дамп памяти...
- Сообщение может быть использовано только одним потребителем, и оно исчезает после Rpop. Если журнал приложения хранится в очереди для одного и того же сообщения, система мониторинга должна использовать его для возможных сигналов тревоги, система BI должна использовать его для составления отчетов, а система отслеживания ссылок должна использовать его для построения взаимосвязей вызовов. .. Этот сценарий Redis List не поддерживается;
- Вторичное потребление не поддерживается: после Rpop сообщение исчезнет. Если вы обнаружите ошибку в коде в середине запуска потребительской программы, вы не сможете использовать ее снова с самого начала после ее исправления.
Что касается вышеперечисленных недостатков, то представляется, что первый из них (настойчивость) может быть решен в настоящее время. Во многих компаниях есть команды, которые ведут вторичную разработку на базе Rocksdb Leveldb и внедряют хранилище kv, поддерживающее протокол Redis. Эти магазины уже не Redis, но они почти такие же, как Redis. Они могут обеспечить постоянство данных, но ничего не могут сделать с другими недостатками, упомянутыми выше.
Фактически, в Redis 5.0 добавлен новый тип данных Stream. Это структура данных, специально разработанная для использования в качестве очереди сообщений. Она основана на многих конструкциях Kafka, но есть еще много проблем... Не правда ли, было бы неплохо напрямую. войти в мир Кафки?
2. Перечислите базовую структуру
2.1. Введение в базовую структуру списка.
До версии Redis3.2 список Redis использовал две структуры данных в качестве базовой реализации:
- сжатиесписок ZipList: если вы вставляете слишком много элементов или строка слишком велика, вам нужно вызвать Realloc Расширенная память;
- двустороннийсвязанный список LinkedList: необходимо добавить указатель Prev и Далее, это приводит к пустой трате места и увеличению фрагментации памяти.
Redis3.2 сначала сохраняет его в ZipList, а затем преобразует в список LinkedList, если он не соответствует требованиям хранения ZipList. Когда объект списка одновременно удовлетворяет следующим двум условиям, объект списка сохраняется с использованием ZipList, в противном случае он сохраняется с использованием LinkedList.
- Длина всех строковых элементов, сохраненных объектом списка, составляет менее 64 байт;
- Объект списка содержит менее 512 элементов.
После версии Redis3.2 список Redis использует структуру быстрого связанного списка QucikList в качестве базовой реализации.
2.2. Список сжатия ZipList.
До версии Redis3.2 сжатые списки были не только одной из базовых реализаций List, но также одной из базовых реализаций типов данных Hash и ZSet.
Ziplist — это непрерывное пространство памяти (как и непрерывный массив памяти, но каждый элемент имеет разную длину). Ziplist может содержать несколько узлов (записей). Элементы хранятся рядом друг с другом без лишних промежутков.

Суть сжатого списка — это массив, но к нему добавляются только «длина списка», «смещение хвоста», «количество элементов списка» и «идентификатор конца списка». Это поможет быстро найти начало и конец списка. Хвостовой узел. Сжатый список хранит каждый элемент таблицы в непрерывном адресном пространстве. Каждый элемент использует кодировку переменной длины, поскольку он занимает разное пространство. Поскольку память распределяется последовательно, обход выполняется быстро.
Когда объем данных в нашем списке относительно невелик, а хранимые данные легкие (например, небольшие целочисленные значения, короткие строки), Redis выполнит базовую реализацию, сжимая список.
+--------+--------+--------+-------+----+--------+-------+
| zlbytes| zltail | zllen | entry1 | .. | entryN | zlend |
+--------+--------+--------+-------+----+--------+-------+свойство | иллюстрировать |
|---|---|
“zlbytes” | Представляет длину сжатого списка (включая все байты). |
“zltail” | Указатель (смещение), представляющий конец сжатого списка. |
“zllen” | Представляет количество узлов (Entry) в сжатом списке. |
“entry” | Область хранения может содержать несколько узлов, и каждый узел может хранить целые числа или строки. |
“zlend” | Указывает конец списка |
Если вы хотите найти первый или последний элемент, вы можете быстро получить его через элементы заголовка «zlbytes» и «zltail_offset», а сложность равна O (1). Но при поиске других элементов это не так эффективно. Вы можете искать только по одному. Например, сложность записиN равна O(N).
2.3. Двусвязный список LinkedList.
LinkedList — это стандартный двусвязный список. Узел Node содержит указатели prev и next, которые указывают на узлы-преемники и предшественники соответственно. Таким образом, начиная с любого узла в двусвязном списке, вы можете легко получить доступ к его предшественникам и узлам-преемникам.

LinkedList можно перемещать в обоих направлениях; добавление и удаление элементов происходит быстро O(1), а поиск элементов — медленно O(n). Он эффективно реализует LPUSH, RPOP и RPOPLPUSH, но это будет тратить определенное количество времени. для каждого узла необходимо выделить дополнительное пространство памяти. Этот метод кодирования подходит для сцен с большим количеством элементов или крупных элементов.
Структура LinkedList предоставляет головной указатель, хвостовой указатель и длину расчета номера узла для связанного списка. На следующем рисунке показан связанный список, состоящий из структуры списка и трех узлов listNode:
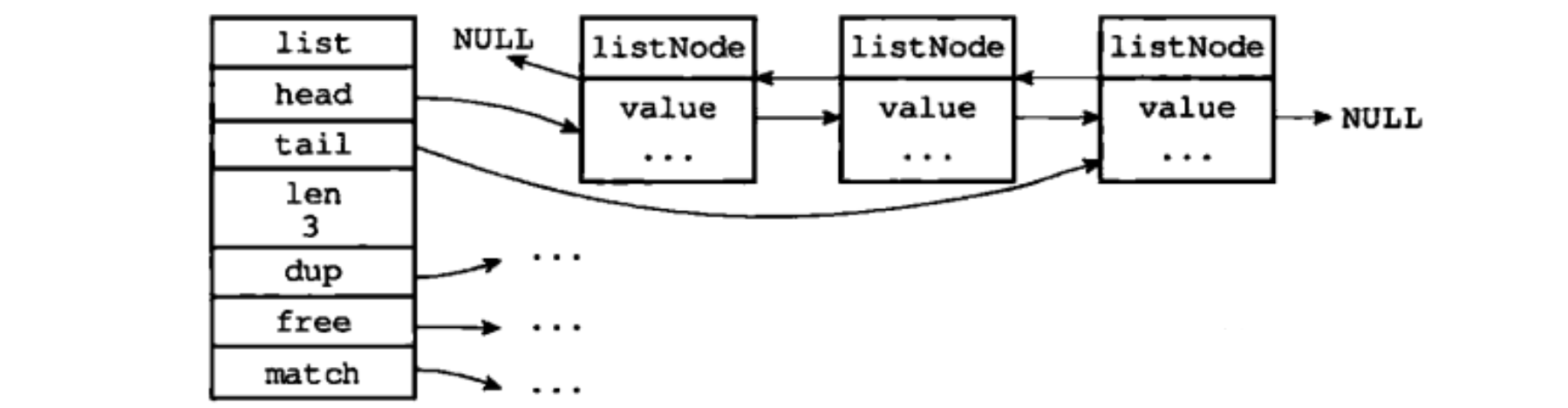
Особенности реализации связанного списка Redis можно резюмировать следующим образом:
- Двусторонний:связанный узел списка с prev и next Указатель, получить определенный узел из предыдущего узла и следующий узел по сложности - это все O(1);
- Ациклический: узел заголовка prev указатель и хвостовой узел таблицы next Все указатели указывают на NULL,верносвязанный списокизпосетить с NULL как конечная точка;
- Указатель головы/указатель хвоста: пас. list структурный head указатель tail Указатель, получить связанный Сложность списка из головного узла таблицы и хвостового узла таблицы составляет O(1);
- связанный Счетчик длины списка: Pass list структурный len свойство Приходитьверно list изсвязанный узлы списка подсчитываются, а сложность получения количества узлов равна O(1);
- Полиморфизм:связанный списокузелиспользовать void* указатель для сохранения значения узла и передачи list структурный dup、free、match трииндивидуальныйсвойство устанавливает специфичные для типа функции для значений узлов, поэтому связанный Список можно использовать для хранения значений различных типов. использоватьсвязанный список дополнительного места относительно слишком велик, потому что 64bit Указатель в системе 8 байты, поэтому prev и next указатель должен занимать 16 индивидуальныйбайт,При этом узел связанного списка существует в памяти отдельно.,Усугубит фрагментацию памяти,Влияет на эффективность управления памятью
2.4. Быстрый связанный список QucikList.
Начиная с Redis версии 3.2, базовая структура данных, используемая данными типа списка, представляет собой быстросвязный список. Быстрый список — это двусвязный список со сжатым списком в качестве узла. Двусвязный список разделен на сегменты, и каждый сегмент использует. сжатый список для непрерывного хранения в памяти. Сжатый список представляет собой двустороннюю цепочку, состоящую из указателей «предыдущий» и «следующий».
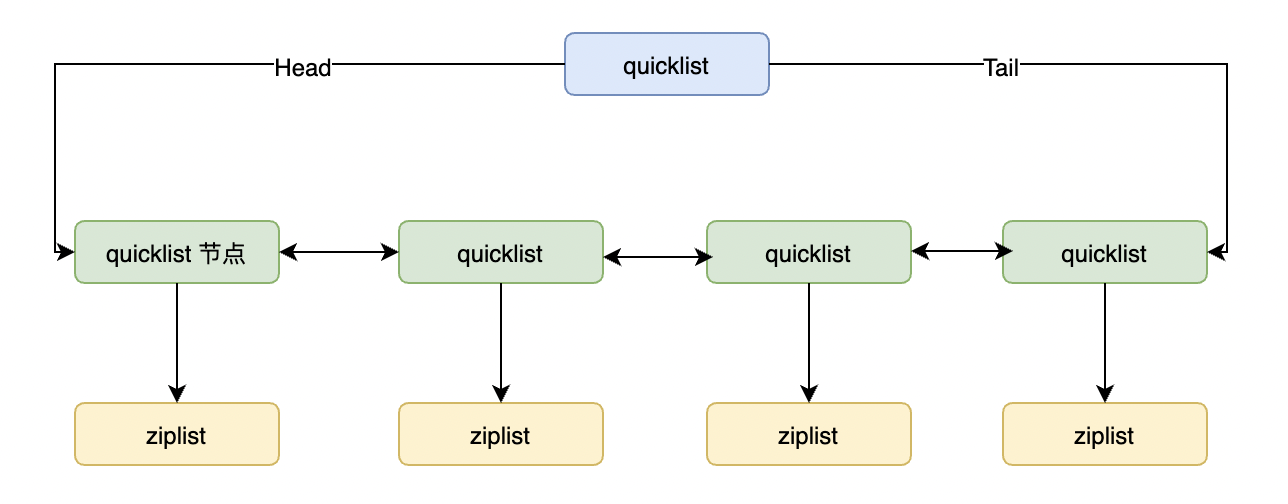
Учитывая вышеперечисленные недостатки связанных списков, последующие версии Redis преобразовали структуру данных списка и использовали QucikList вместо ZipList и LinkedList. Будучи гибридом ZipList и LinkedList, он разбивает LinkedList на сегменты, каждый сегмент использует ZipList для компактного хранения, а несколько ZipList соединяются последовательно с помощью двунаправленных указателей.
Таким образом, производительность значительно улучшается.
иллюстрировать | |
|---|---|
“head” | Представляет головной узел быстросвязного списка. |
“tail” | Представляет хвостовой узел быстросвязного списка. |
“count” | Представляет общее количество элементов во всех узлах быстросвязного списка. |
“len” | Представляет количество узлов в быстросвязном списке. |
“fill” | Максимальный размер узла ziplist. Значение по умолчанию равно 8 КБ. Если размер превышает, будет создан новый Ziplist, соответствующий параметру list-max-ziplist-size, который занимает 16 бит. |
“compress” | Глубина сжатия узла, указывающая, сжимается ли узел с использованием алгоритма LZF, соответствующая параметру list-compress-length, составляющая 1 6 бит. |
Для «заполнения», когда число отрицательное:
- -1: размер каждого узла ZipList не может превышать 4 КБ (рекомендуется).
- -2: размер каждого узла ZipList не может превышать 8 КБ (конфигурация по умолчанию).
- -3: Размер каждого узла ZipList не может превышать 16 КБ (обычно не рекомендуется).
- -4: Размер каждого узла ZipList не может превышать 32 КБ (не рекомендуется).
- -5: Размер каждого узла ZipList не может превышать 64 КБ (не рекомендуется для нормальной рабочей нагрузки).
Для «заполнения», когда число положительное: максимальное количество элементов, содержащихся в узле ZipList, максимальное значение — 215215.
Для узлов «сжатия» цифры означают следующее:
- 0: Не сжимать (по умолчанию)
- 1:QucikList списокиз На обоих концах имеются 1 индивидуальный узел зиплиста, не сжатие, а средний узел из сжатие.
- 2:QucikList На обоих концах списка есть 2 индивидуальных узла ziplist, а посередине есть узлы сжатия.
- 3:QucikList На обоих концах списка есть 3 индивидуальных узла ziplist, а посередине есть узлы сжатия.
- По аналогии максимум 216216
3. Перечислите распространенные команды
3.1. Добавьте новые значения в начало списка.
Используйте команду LPUSH, чтобы добавить новое значение в начало списка:
LPUSH list value [value2 ...]Вставляет одно или несколько значений в заголовок списка. Если значение ключа не существует, оно будет создано первым, а затем будет выполнена команда LPUSH. Если значение ключа существует, но не относится к типу списка, будет возвращена ошибка.

3.2. Добавьте новые значения в конец списка.
Используйте команду RPUSH, чтобы добавить новые значения в конец списка:
RPUSH list value [value2 ...]Вставляет одно или несколько значений в конец списка. Если значение ключа не существует, оно будет создано первым, а затем будет выполнена команда LPUSH. Если значение ключа существует, но не относится к типу списка, будет возвращена ошибка.

3.3. Получить значение определенного диапазона в списке.
Используйте команду LRANGE, чтобы получить значение диапазона в списке:
LRANGE списокимя start endПолучить элементы в указанном диапазоне в списке, 0 означает первый элемент в списке, -1 означает последний элемент в списке.

3.4. Удалить значение в начале списка и вернуть это значение.
Используйте команду LPOP, чтобы удалить значение в начале списка и вернуть это значение:
LPOP list
3.5 Удалить значение в конце списка и вернуть это значение.
Используйте команду RPOP, чтобы удалить значение в конце списка и вернуть это значение:
RPOP list
3.6. Получить значение в списке через индекс.
Используйте LINDEX для получения значений в списке по индексу:
LINDEX list index
3.7. Удалить указанное значение и количество значений элемента.
Используйте LREM для удаления указанного значения и количества значений элемента:
LREM list num value
3.8. Получите длину списка.
Используйте LLEN, чтобы получить длину списка
llen list
3.9. Сократить список.
Используйте LTRIM для усечения списка
LTRIM list start end
3.10. Перенос значений из одного списка в другой.
Используйте RPOPLPUSH для перемещения значений из одного списка в другой
RPOPLPUSH source distinationУдалите последний элемент в исходном списке и добавьте элемент в список назначения, что можно просто понять как «удаление хвоста и вставка заголовка».

3.11. Заменить значение в списке.
Используйте LSET для замены значения в списке
LSET list index value
3.12. Вставьте новые значения в список в указанную позицию.
Вставьте новое значение в список, используя LINSERT в указанной позиции.
LINSERT list BEFORE / AFTER old-value new-value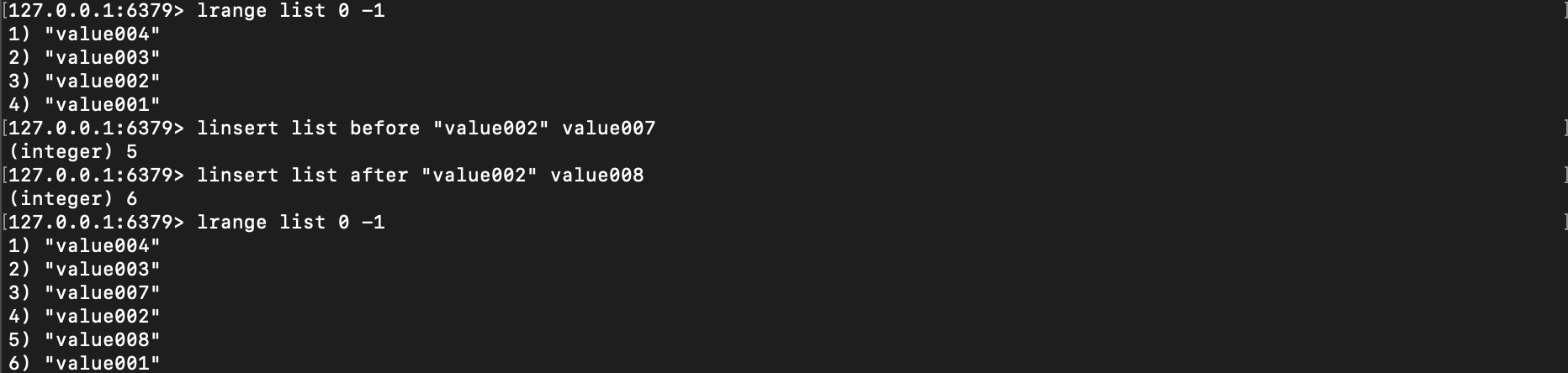



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
